OpenCVの特徴的な機能
【概要】 OpenCVには、色空間変換、局所的コントラスト調整、動き検出、幾何学的変換、形状解析、多重解像度解析、パターン検出、適応的二値化、セグメンテーションなどの機能がある。これらは、照明変動への対応、動き検出、形状認識などの画像処理に用いられる。本資料のプログラムはWindowsのパソコンで動作する。GPU搭載機・CPUのみのいずれでも動作する。
【共通の前提】各プログラムには以下の共通事項がある。
- ネットワーク接続が必要:各プログラムは、サンプル画像・動画をインターネット(GitHub)から自動的にダウンロードして使用する。オフライン環境では動作せず、プロキシ環境では取得に失敗する場合がある。
- 結果はウィンドウに表示:各プログラムは処理結果をウィンドウに表示する。画像を扱う例では任意のキーを押すと終了し、カメラ・動画を扱う例では
qキーで終了する。表示ウィンドウが他のウィンドウの背面に隠れる場合がある。 - 色空間変換結果の見え方:
cv2.imshowは配列をBGR(青・緑・赤)として表示する。このため、HSVやL*a*b*など別の色空間に変換した配列をそのまま表示すると、見かけ上は本来とは異なる色になる(変換が行われていることを確認するための表示である)。 - コマンドライン引数をとるプログラムの実行:引数をとるプログラム(オプティカルフローの動画版)は、
python ファイル名.py 0のようにコマンドプロンプトから実行する。 - 対象とするサンプル画像の範囲:本資料が用いるサンプル画像は幅2048ピクセル以下であり、リサイズ処理を行う例では表示幅が1024ピクセル以下に収まる。
【目次】
- Python と必要ライブラリのインストール(Windows上)
- 色空間変換
- CLAHE(コントラスト制限付き適応的ヒストグラム平坦化)
- オプティカルフロー(動き検出)
- アフィン変換
- モルフォロジー演算
- 画像ピラミッド(多重解像度表現)
- テンプレートマッチング
- 適応的閾値処理
- GrabCutによる画像セグメンテーション
- カラー画像の読み込みと表示
- パソコンカメラ映像の表示
【サイト内の関連情報】
ドクセルの URL: https://www.docswell.com/s/6674398749/51X845-2022-02-18-085434
Python と必要ライブラリのインストール(Windows上)
Python 3.12 のインストール(Windows 上) [クリックして展開]
以下のいずれかの方法でPython 3.12をインストールする。Pythonがインストール済みの場合、この手順は不要である。
方法1:winget によるインストール
管理者権限のコマンドプロンプトを起動する(手順:Windowsキーまたはスタートメニューで「cmd」と入力 > 表示された「コマンドプロンプト」を右クリック > 「管理者として実行」)。起動したコマンドプロンプトで以下を実行する。
winget install --id Python.Python.3.12 -e --scope machine --silent --accept-source-agreements --accept-package-agreements --override "/quiet InstallAllUsers=1 PrependPath=1 Include_test=0 Include_pip=1 Include_launcher=1 InstallLauncherAllUsers=1 TargetDir=\"C:\Program Files\Python312\""
powershell -Command "$p='C:\Program Files\Python312'; $s=\"$p\Scripts\"; $m=[Environment]::GetEnvironmentVariable('Path','Machine'); if($m -notlike \"*$s*\") { [Environment]::SetEnvironmentVariable('Path', \"$p;$s;$m\", 'Machine') }"--scope machine を指定することで、システム全体(全ユーザー向け)にインストールされる。このオプションの実行には管理者権限が必要である。インストール完了後、コマンドプロンプトを再起動するとPATHが設定される。
方法2:インストーラーによるインストール
- Python公式サイト(https://www.python.org/downloads/)にアクセスし、「Download Python 3.x.x」ボタンからWindows用インストーラーをダウンロードする。
- ダウンロードしたインストーラーを実行する。
- 初期画面の下部に表示される「Add python.exe to PATH」にチェックを入れてから「Customize installation」を選択する(このチェックを入れないと、コマンドプロンプトから
pythonコマンドを実行できない)。 - 「Install Python 3.xx for all users」にチェックを入れ、「Install」をクリックする。
インストールの確認
コマンドプロンプトで以下を実行する。
python --versionバージョン番号(例:Python 3.12.x)が表示されればインストール成功である。「'python' は、内部コマンドまたは外部コマンドとして認識されていません。」と表示される場合は、インストールが完了していない。
AIエディタ Windsurf のインストール(Windows 上) [クリックして展開]
Pythonプログラムの編集・実行には、AIエディタの利用を推奨する。ここではWindsurfのインストールを説明する。Windsurfがインストール済みの場合、この手順は不要である。
管理者権限のコマンドプロンプトを起動する(手順:Windowsキーまたはスタートメニューで「cmd」と入力 > 表示された「コマンドプロンプト」を右クリック > 「管理者として実行」)。起動したコマンドプロンプトで以下を実行する。
winget install --scope machine --id Codeium.Windsurf -e --silent --disable-interactivity --force --accept-source-agreements --accept-package-agreements --custom "/SP- /SUPPRESSMSGBOXES /NORESTART /CLOSEAPPLICATIONS /DIR=""C:\Program Files\Windsurf"" /MERGETASKS=!runcode,addtopath,associatewithfiles,!desktopicon"
powershell -Command "$env:Path=[System.Environment]::GetEnvironmentVariable('Path','Machine')+';'+[System.Environment]::GetEnvironmentVariable('Path','User'); windsurf --install-extension MS-CEINTL.vscode-language-pack-ja --force; windsurf --install-extension ms-python.python --force; windsurf --install-extension Codeium.windsurfPyright --force"--scope machine を指定することで、システム全体(全ユーザー向け)にインストールされる。このオプションの実行には管理者権限が必要である。インストール完了後、コマンドプロンプトを再起動するとPATHが設定される。
【関連する外部ページ】
Windsurf の公式ページ: https://windsurf.com/
必要なPythonライブラリのインストール
- コマンドプロンプトを起動する(手順:Windowsキーまたはスタートメニューで「
cmd」と入力 > Enter)。 - 以下を実行し、必要なライブラリをインストールする(
numpyはopencv-pythonの依存として自動的に導入されるが、明示的に指定して最新化する)。pip install -U numpy opencv-python
NumPy 2.x に対応した opencv-python が導入される。GPUの有無にかかわらず、ここで導入する opencv-python はCPUで動作する標準ビルドであり、本資料のすべてのプログラムが動作する。
【関連する外部ページ】
- Python公式サイト:https://www.python.org/
【サイト内の関連ページ】
- Python詳細ガイド:別ページ »
色空間変換
概要
色空間変換とは、デジタル画像の色表現を異なる色空間へ変換する処理である。OpenCVでは画像をBGR形式(青・緑・赤の順)で扱う。BGRからHSVへ変換することで、色相(Hue)、彩度(Saturation)、明度(Value)を独立した成分として扱える。これにより、照明変動下での色検出が容易になる。下記プログラムは変換後の配列をそのまま表示するため、表示色は本来の色とは異なって見える(冒頭【共通の前提】を参照)。
使用されている技術
- HSV色空間:色相、彩度、明度の3要素で色を表現する色空間。人間の色知覚に近い表現方式である。
- L*a*b*色空間:L*が明度、a*とb*が色度を表す色空間。色度成分は照明変動の影響を受けにくい。
- cv2.cvtColor:色空間変換を行う関数。
ソースコード: BGRからHSV色空間への変換
import cv2
import urllib.request
# 画像のダウンロード
url = "https://raw.githubusercontent.com/opencv/opencv/master/samples/data/fruits.jpg"
urllib.request.urlretrieve(url, "fruits.jpg")
# 色空間変換
img = cv2.imread("fruits.jpg")
hsv = cv2.cvtColor(img, cv2.COLOR_BGR2HSV)
cv2.imshow('HSV', hsv)
cv2.waitKey(0)
cv2.destroyAllWindows()
ソースコード: BGRからL*a*b*色空間への変換
import cv2
import urllib.request
# 画像のダウンロード
url = "https://raw.githubusercontent.com/opencv/opencv/master/samples/data/fruits.jpg"
urllib.request.urlretrieve(url, "fruits.jpg")
# 色空間変換
img = cv2.imread("fruits.jpg")
lab = cv2.cvtColor(img, cv2.COLOR_BGR2Lab)
cv2.imshow('Lab', lab)
cv2.waitKey(0)
cv2.destroyAllWindows()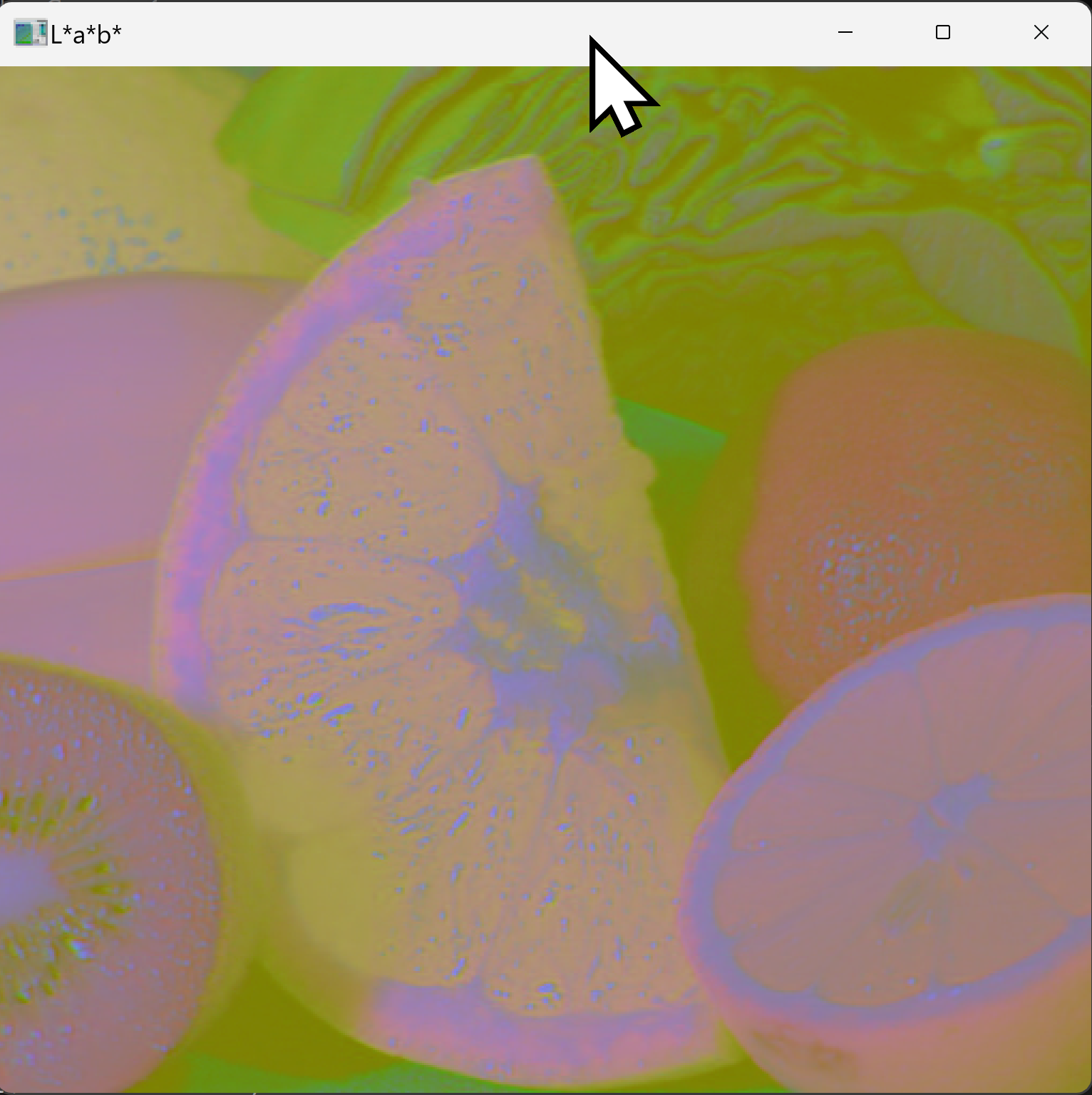
演習1.色空間変換の比較
手順
- 上記2つのプログラムを実行し、HSVおよびL*a*b*への変換結果を表示する。
- 2つの表示結果を見比べる。
ヒント
- 表示色は本来の色とは異なる(
cv2.imshowは配列をBGRとして表示するため)。 - 変換先を切り替えるには、
cv2.COLOR_BGR2HSVとcv2.COLOR_BGR2Labを入れ替える。
考察ポイント
- 同じ入力画像でも、変換先の色空間によって表示される色の傾向がどのように変わるか。
CLAHE(コントラスト制限付き適応的ヒストグラム平坦化)
概要
CLAHE(Contrast Limited Adaptive Histogram Equalization、コントラスト制限付き適応的ヒストグラム平坦化)は、画像の局所領域ごとにコントラストを調整する手法である。通常のヒストグラム平坦化と異なり、局所領域ごとに処理を行うため、画像全体の視認性を均一に向上させられる。暗部と明部が混在する画像の改善に用いられる。
使用されている技術
- cv2.createCLAHE:CLAHEオブジェクトを生成する関数。
- clipLimit:ヒストグラムのビン高さを制限するクリップ値。コントラスト増幅の度合いを制限するパラメータで、値を大きくするとコントラストが強くなるが、ノイズも増幅される。
- tileGridSize:局所領域のサイズを指定するパラメータ。
ソースコード: CLAHEによるコントラスト調整(グレースケール画像)
import cv2
import urllib.request
# 画像のダウンロード
url = "https://raw.githubusercontent.com/opencv/opencv/master/samples/data/fruits.jpg"
urllib.request.urlretrieve(url, "fruits.jpg")
img = cv2.imread("fruits.jpg", 0)
clahe = cv2.createCLAHE(clipLimit=2.0, tileGridSize=(8, 8))
result = clahe.apply(img)
cv2.imshow('CLAHE', result)
cv2.waitKey(0)
cv2.destroyAllWindows()
ソースコード: CLAHEによるコントラスト調整(カラー画像)
L*a*b*色空間に変換し、L*成分にのみCLAHEを適用することで、色情報を保持したままコントラストを調整する。
import cv2
import urllib.request
# 画像のダウンロード
url = "https://raw.githubusercontent.com/opencv/opencv/master/samples/data/fruits.jpg"
urllib.request.urlretrieve(url, "fruits.jpg")
# 色空間変換
img = cv2.imread("fruits.jpg")
lab = cv2.cvtColor(img, cv2.COLOR_BGR2Lab)
# L*a*b*の各チャネルを分離
l, a, b = cv2.split(lab)
# L*成分にCLAHEを適用
clahe = cv2.createCLAHE(clipLimit=2.0, tileGridSize=(8, 8))
l = clahe.apply(l)
# チャネルを結合してBGRに戻す
lab = cv2.merge([l, a, b])
result = cv2.cvtColor(lab, cv2.COLOR_Lab2BGR)
cv2.imshow('CLAHE', result)
cv2.waitKey(0)
cv2.destroyAllWindows()
演習2.CLAHEのパラメータ変更
手順
- グレースケール画像のプログラムを実行し、結果を表示する。
clipLimitの値を 2.0 から 4.0、8.0 へ変更し、それぞれ実行する。
ヒント
clipLimitはcv2.createCLAHEの引数で指定する。
考察ポイント
clipLimitを大きくすると、コントラストとノイズがそれぞれどのように変化するか。
オプティカルフロー(動き検出)
概要
オプティカルフローは、連続する画像フレーム間における各画素の動きをベクトルとして検出する技術である。モーション解析や動画の手ぶれ補正などに用いられる。特定の物体を同定して追尾するトラッキングではなく、画素ごとの動きベクトルを求める手法である。下記の可視化では、動きの方向を色相、大きさを明度で表し、彩度は最大値に固定して色を鮮やかに保つ。
使用されている技術
- Farneback法:全画素の動きを計算する密なオプティカルフロー(Dense Optical Flow)アルゴリズム。
- cv2.calcOpticalFlowFarneback:Farneback法によるオプティカルフロー計算関数。第3引数以降はアルゴリズムの調整パラメータで、本資料では既定的な値を用いる。
ソースコード(2つの画像に対する処理)
2枚の連続画像間の動きを検出し、HSV色空間で可視化する。
import cv2
import numpy as np
import urllib.request
# 画像のダウンロード
url1 = "https://raw.githubusercontent.com/opencv/opencv/master/samples/data/rubberwhale1.png"
url2 = "https://raw.githubusercontent.com/opencv/opencv/master/samples/data/rubberwhale2.png"
urllib.request.urlretrieve(url1, "frame1.png")
urllib.request.urlretrieve(url2, "frame2.png")
prev_gray = cv2.imread('frame1.png', cv2.IMREAD_GRAYSCALE)
next_gray = cv2.imread('frame2.png', cv2.IMREAD_GRAYSCALE)
# オプティカルフローの計算
flow = cv2.calcOpticalFlowFarneback(prev_gray, next_gray, None, 0.5, 3, 15, 3, 5, 1.2, 0)
# 可視化用のHSV画像を生成(彩度は最大値に固定)
hsv = np.zeros((prev_gray.shape[0], prev_gray.shape[1], 3), dtype=np.uint8)
hsv[..., 1] = 255
# フローの大きさと角度を計算(角度は度数で取得)
mag, ang = cv2.cartToPolar(flow[..., 0], flow[..., 1], angleInDegrees=True)
hsv[..., 0] = (ang / 2).astype(np.uint8) # 色相(動きの方向、0-179)
hsv[..., 2] = cv2.normalize(mag, None, 0, 255, cv2.NORM_MINMAX).astype(np.uint8) # 明度(動きの大きさ)
# HSVからBGRに変換して表示
bgr = cv2.cvtColor(hsv, cv2.COLOR_HSV2BGR)
cv2.imshow('Optical Flow', bgr)
cv2.waitKey(0)
cv2.destroyAllWindows()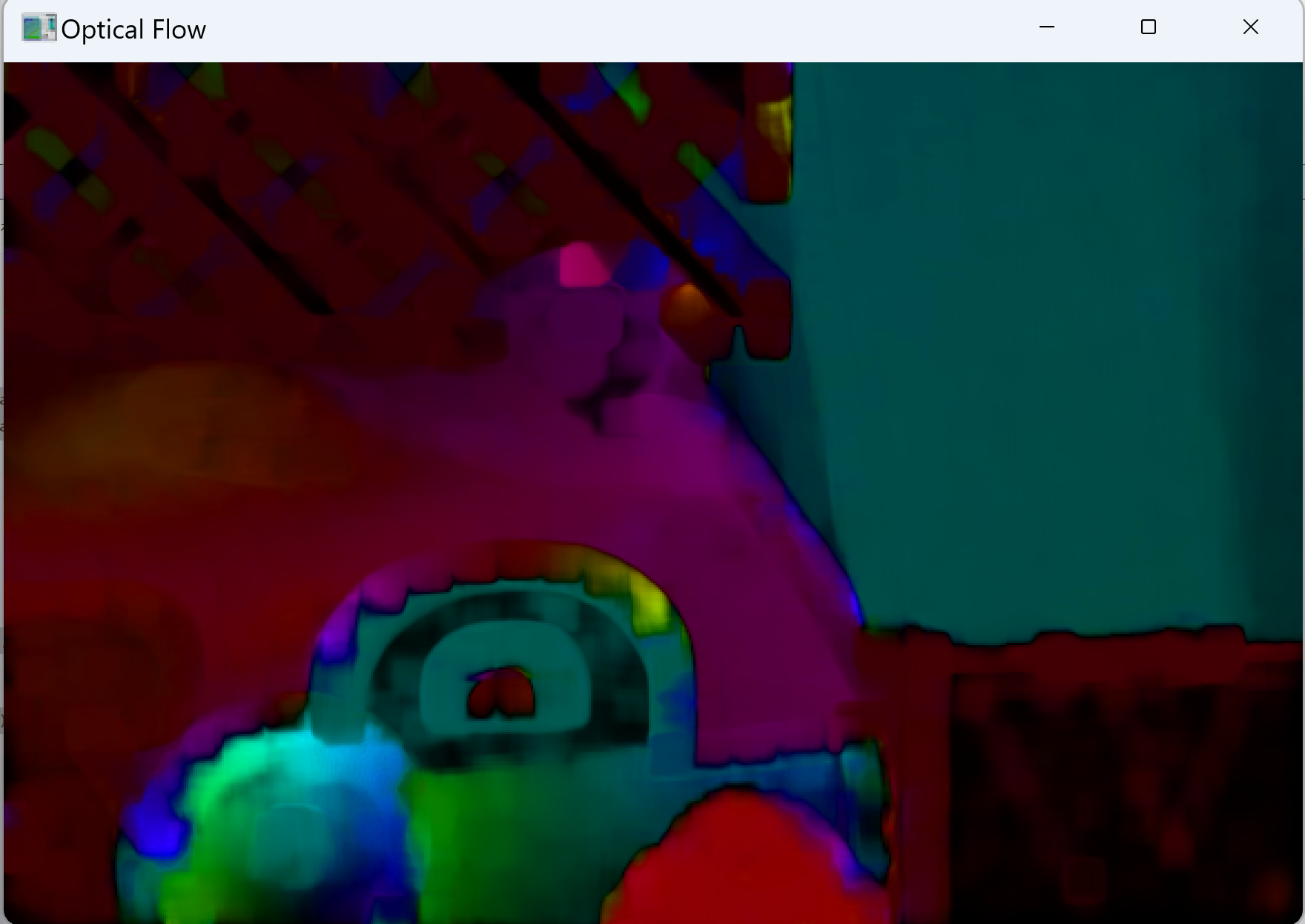
ソースコード(動画に対する処理)
動画またはWebカメラからオプティカルフローを計算する。コマンドライン引数で入力ソースを切り替える。
- 引数なし:サンプル動画を使用
- 数字を指定:指定番号のWebカメラを使用
- ファイル名を指定:指定した動画ファイルを使用
import cv2
import numpy as np
import urllib.request
import sys
# 入力ソースの決定
if len(sys.argv) == 1:
# 引数なし: サンプル動画をダウンロードして使用
video_url = "https://github.com/opencv/opencv/raw/master/samples/data/vtest.avi"
urllib.request.urlretrieve(video_url, "vtest.avi")
cap = cv2.VideoCapture("vtest.avi")
elif sys.argv[1].isdigit():
# 数字: Webカメラを使用
cap = cv2.VideoCapture(int(sys.argv[1]))
else:
# その他: ファイル名として使用
cap = cv2.VideoCapture(sys.argv[1])
# 最初のフレームの読み込みとグレースケール変換
ret, prev_frame = cap.read()
prev_gray = cv2.cvtColor(prev_frame, cv2.COLOR_BGR2GRAY)
# 可視化用のHSV画像を生成(彩度は最大値に固定)
hsv = np.zeros_like(prev_frame)
hsv[..., 1] = 255
while True:
# 次のフレームの読み込み
ret, next_frame = cap.read()
if not ret:
break
next_gray = cv2.cvtColor(next_frame, cv2.COLOR_BGR2GRAY)
# オプティカルフローの計算
flow = cv2.calcOpticalFlowFarneback(prev_gray, next_gray, None, 0.5, 3, 15, 3, 5, 1.2, 0)
# フローの大きさと角度を計算(角度は度数で取得)
mag, ang = cv2.cartToPolar(flow[..., 0], flow[..., 1], angleInDegrees=True)
hsv[..., 0] = (ang / 2).astype(np.uint8) # 色相(動きの方向、0-179)
hsv[..., 2] = cv2.normalize(mag, None, 0, 255, cv2.NORM_MINMAX).astype(np.uint8) # 明度(動きの大きさ)
# HSVからBGRに変換して表示
bgr = cv2.cvtColor(hsv, cv2.COLOR_HSV2BGR)
cv2.imshow('Optical Flow', bgr)
# 'q'キーで終了
if cv2.waitKey(30) & 0xFF == ord('q'):
break
# 現在のフレームを次のループの前フレームとする
prev_gray = next_gray
cap.release()
cv2.destroyAllWindows()演習3.動きの可視化
手順
- 2つの画像に対するプログラムを実行し、可視化結果を表示する。
- 動画に対するプログラムを引数なしで実行し、サンプル動画での結果を表示する。
qキーで終了する。
ヒント
- 可視化結果では、色相が動きの方向、明度が動きの大きさを表す。
- 動画版を引数なしで実行するには、コマンドプロンプトで
python ファイル名.pyと入力する。
考察ポイント
- 動いている領域と静止している領域が、可視化結果でどのように区別されるか。
アフィン変換
概要
アフィン変換は、画像に対して平行移動、回転、拡大縮小、せん断などの幾何学的変換を行う手法である。変換後も平行線は平行線として保たれる。画像の位置合わせや歪み補正に用いられる。
使用されている技術
- アフィン変換行列:2×3の行列で幾何学的変換を表現する。
- cv2.getAffineTransform:3組の対応点からアフィン変換行列を計算する関数。
- cv2.warpAffine:アフィン変換行列を用いて画像を変換する関数。
ソースコード
3組の対応点を指定してアフィン変換を行う。pts1 の各点が pts2 の対応する点へ移動するように画像全体が変換される。
import cv2
import numpy as np
import urllib.request
# 画像のダウンロード
url = "https://raw.githubusercontent.com/opencv/opencv/master/samples/data/fruits.jpg"
urllib.request.urlretrieve(url, "fruits.jpg")
img = cv2.imread("fruits.jpg")
rows, cols = img.shape[:2]
# 変換元の3点と変換先の3点
pts1 = np.float32([[50, 50], [200, 50], [50, 200]])
pts2 = np.float32([[10, 100], [200, 50], [100, 250]])
# アフィン変換行列を計算して変換
M = cv2.getAffineTransform(pts1, pts2)
result = cv2.warpAffine(img, M, (cols, rows))
cv2.imshow('Affine Transform', result)
cv2.waitKey(0)
cv2.destroyAllWindows()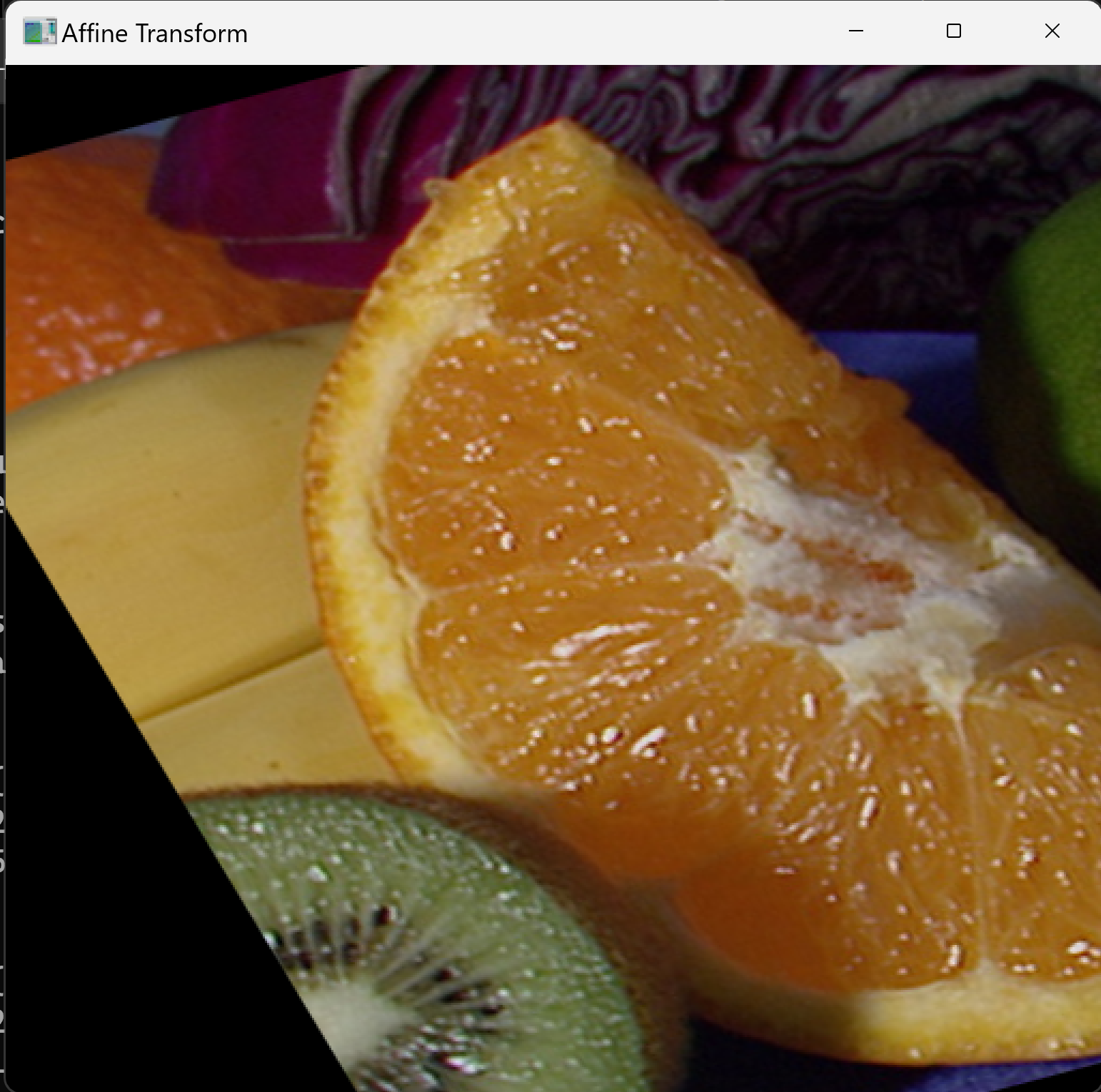
演習4.対応点の変更
手順
- プログラムを実行し、変換結果を表示する。
pts2の各点の座標を変更し、再度実行する。
ヒント
pts1が変換前、pts2が変換後の対応点である。
考察ポイント
pts2の座標変更が、画像の回転・拡大縮小・せん断にどう対応するか。
モルフォロジー演算
概要
モルフォロジー演算は、画像の形状に基づく処理を行う演算である。主に二値画像に対して適用され、ノイズ除去や形状の整形に用いられる。基本演算として膨張(dilation)と収縮(erosion)がある。
使用されている技術
- 収縮(erosion):構造要素内の最小値を出力する演算。物体を縮小させ、小さなノイズを除去できる。
- 膨張(dilation):構造要素内の最大値を出力する演算。物体を拡大させ、穴を埋められる。
- 構造要素(kernel):演算の処理範囲を定義する行列。3×3や5×5の正方行列を用いることが多い。
ソースコード
収縮処理を行う。
import cv2
import numpy as np
import urllib.request
# 画像のダウンロード
url = "https://raw.githubusercontent.com/opencv/opencv/master/samples/data/fruits.jpg"
urllib.request.urlretrieve(url, "fruits.jpg")
img = cv2.imread("fruits.jpg", 0)
# 5×5の構造要素で収縮
kernel = np.ones((5, 5), np.uint8)
result = cv2.erode(img, kernel, iterations=1)
cv2.imshow('Erosion', result)
cv2.waitKey(0)
cv2.destroyAllWindows()
演習5.収縮と膨張
手順
- プログラムを実行し、収縮の結果を表示する。
cv2.erodeをcv2.dilateに変更し、膨張の結果を表示する。
ヒント
cv2.dilateの引数はcv2.erodeと同じである。
考察ポイント
- 収縮と膨張で、明るい領域の面積がそれぞれどのように変化するか。
画像ピラミッド(多重解像度表現)
概要
画像ピラミッドは、同一画像を異なる解像度で階層的に表現する手法である。物体検出やテンプレートマッチングにおいて、異なるスケールの対象を探索するために用いられる。
使用されている技術
- cv2.pyrDown:画像の解像度を半分に縮小する関数。
- cv2.pyrUp:画像の解像度を2倍に拡大する関数。pyrDownで失われた情報は復元されない。
ソースコード
画像の解像度を縮小し、続いて拡大する。
import cv2
import urllib.request
# 画像のダウンロード
url = "https://raw.githubusercontent.com/opencv/opencv/master/samples/data/fruits.jpg"
urllib.request.urlretrieve(url, "fruits.jpg")
img = cv2.imread("fruits.jpg")
lower = cv2.pyrDown(img)
higher = cv2.pyrUp(lower)
cv2.imshow('Lower Resolution', lower)
cv2.imshow('Higher Resolution', higher)
cv2.waitKey(0)
cv2.destroyAllWindows()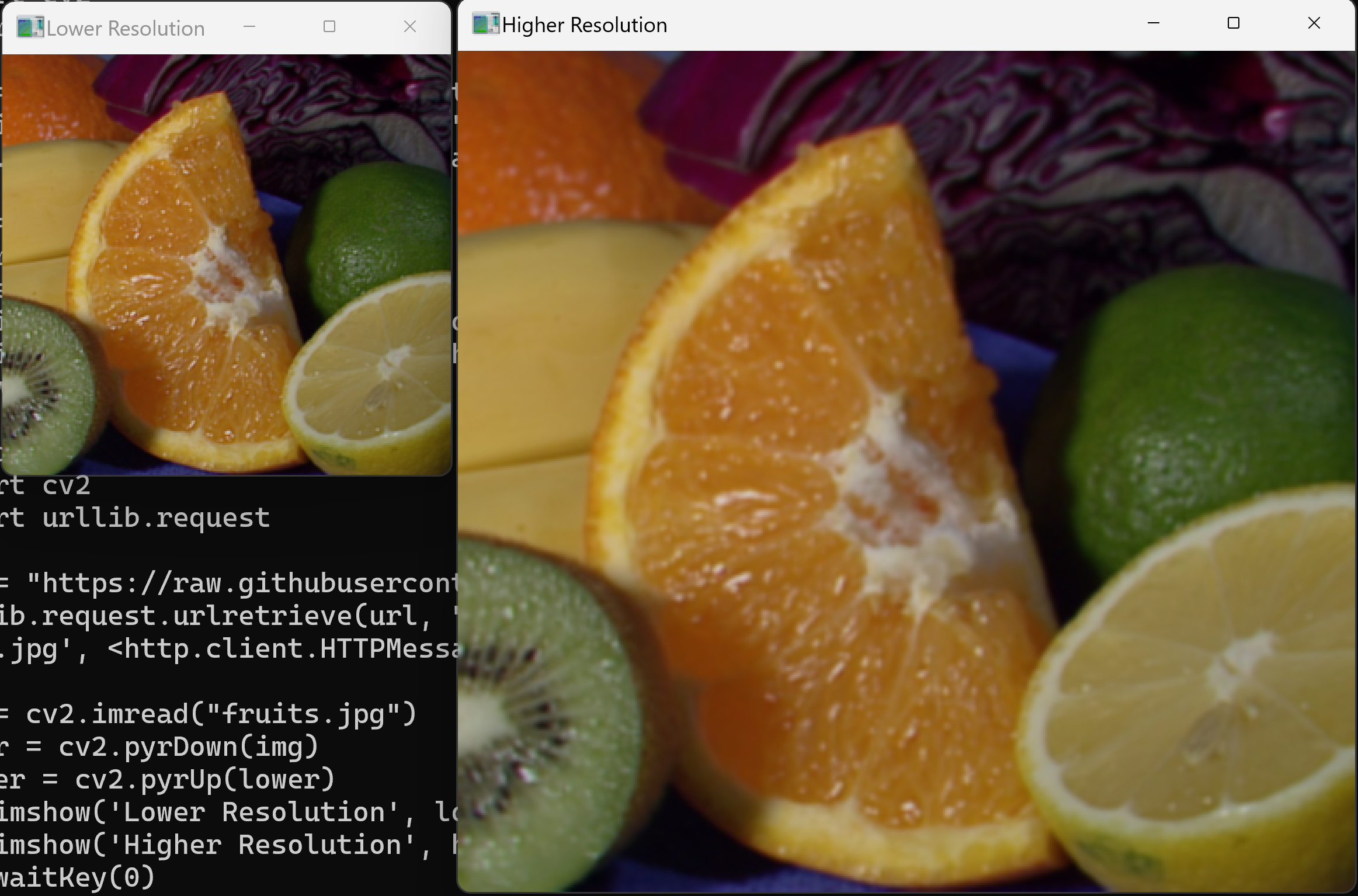
演習6.縮小と拡大による画質変化
手順
- プログラムを実行し、縮小画像(lower)と再拡大画像(higher)を表示する。
- 再拡大画像と、元画像(
img)を表示して見比べる。
ヒント
- 元画像を表示するには、
cv2.imshow('Original', img)を追加する。
考察ポイント
- 縮小してから拡大した画像が、元画像と比べてどの程度劣化するか。
テンプレートマッチング
概要
テンプレートマッチングは、画像内から指定したテンプレート画像と類似する領域を検出する手法である。部品検査や文字認識などに用いられる。下記プログラムは、同一画像の一部をテンプレートとして用いる。切り出し元の位置では最高スコア(1.0)となり、加えて類似度0.8以上の領域が検出される。検出される領域の数は、画像内に類似した模様がどれだけ存在するかに依存する。
使用されている技術
- cv2.matchTemplate:テンプレートマッチングを実行する関数。
- TM_CCOEFF_NORMED:正規化相互相関係数による類似度計算手法。値の範囲は-1から1で、1に近いほど類似度が高い。
ソースコード
画像の一部をテンプレートとして切り出し、類似領域を検出する。類似度0.8以上の領域を緑色矩形、元のテンプレート位置を赤色矩形で表示する(矩形を色付きで描画するため、画像はカラーで読み込む)。
import cv2
import numpy as np
import urllib.request
# 画像のダウンロード
url = "https://raw.githubusercontent.com/opencv/opencv/master/samples/data/smarties.png"
urllib.request.urlretrieve(url, "smarties.png")
img = cv2.imread("smarties.png")
# 画像の一部をテンプレートとして切り出す
template_x, template_y = 50, 50
template_w, template_h = 60, 60
template = img[template_y:template_y+template_h, template_x:template_x+template_w]
# テンプレートマッチング
result = cv2.matchTemplate(img, template, cv2.TM_CCOEFF_NORMED)
# スコア0.8以上の位置を緑色矩形で表示
locations = np.where(result >= 0.8)
for y, x in zip(*locations):
cv2.rectangle(img, (x, y), (x+template_w, y+template_h), (0, 255, 0), 2)
# 元のテンプレート位置を赤色矩形で表示
cv2.rectangle(img, (template_x, template_y), (template_x+template_w, template_y+template_h), (0, 0, 255), 2)
cv2.imshow('Template Matching', img)
cv2.waitKey(0)
cv2.destroyAllWindows()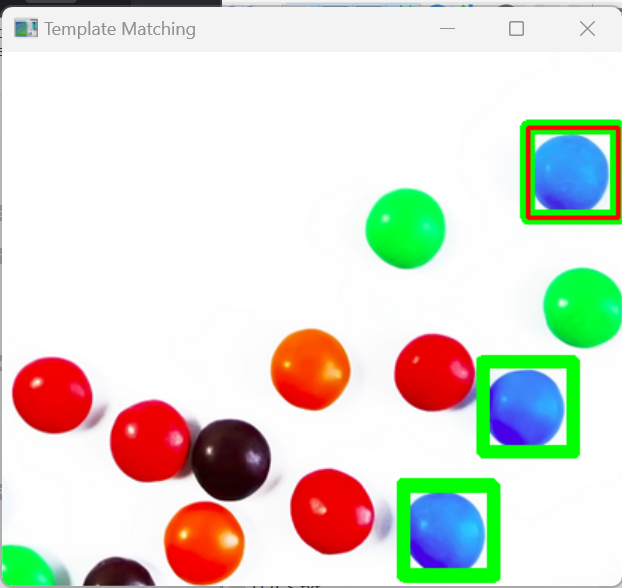
演習7.閾値の変更
手順
- プログラムを実行し、検出結果を表示する。
- 類似度の閾値 0.8 を 0.9、0.7 へ変更し、それぞれ実行する。
ヒント
- 閾値は
np.where(result >= 0.8)の数値で指定する。
考察ポイント
- 閾値を上げる・下げると、緑色矩形で検出される領域の数がどのように変化するか。
適応的閾値処理
概要
適応的閾値処理は、画像の局所領域ごとに閾値を計算して二値化を行う手法である。照明が不均一な画像に対しても適切な二値化が可能である。文書スキャンやOCRの前処理に用いられる。
使用されている技術
- cv2.adaptiveThreshold:適応的閾値処理を実行する関数。
- ADAPTIVE_THRESH_GAUSSIAN_C:ガウシアン重み付けにより局所領域の閾値を計算する手法。
- blockSize:閾値計算に用いる局所領域のサイズ。奇数を指定する。
ソースコード
適応的閾値処理により二値化を行う。第5引数の 11 がblockSize、第6引数の 2 が閾値から引く定数である。
import cv2
import urllib.request
# 画像のダウンロード
url = "https://raw.githubusercontent.com/opencv/opencv/master/samples/data/sudoku.png"
urllib.request.urlretrieve(url, "sudoku.png")
img = cv2.imread("sudoku.png", 0)
# 適応的閾値処理(blockSizeは奇数を指定する)
result = cv2.adaptiveThreshold(img, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C,
cv2.THRESH_BINARY, 11, 2)
cv2.imshow('Adaptive Threshold', result)
cv2.waitKey(0)
cv2.destroyAllWindows()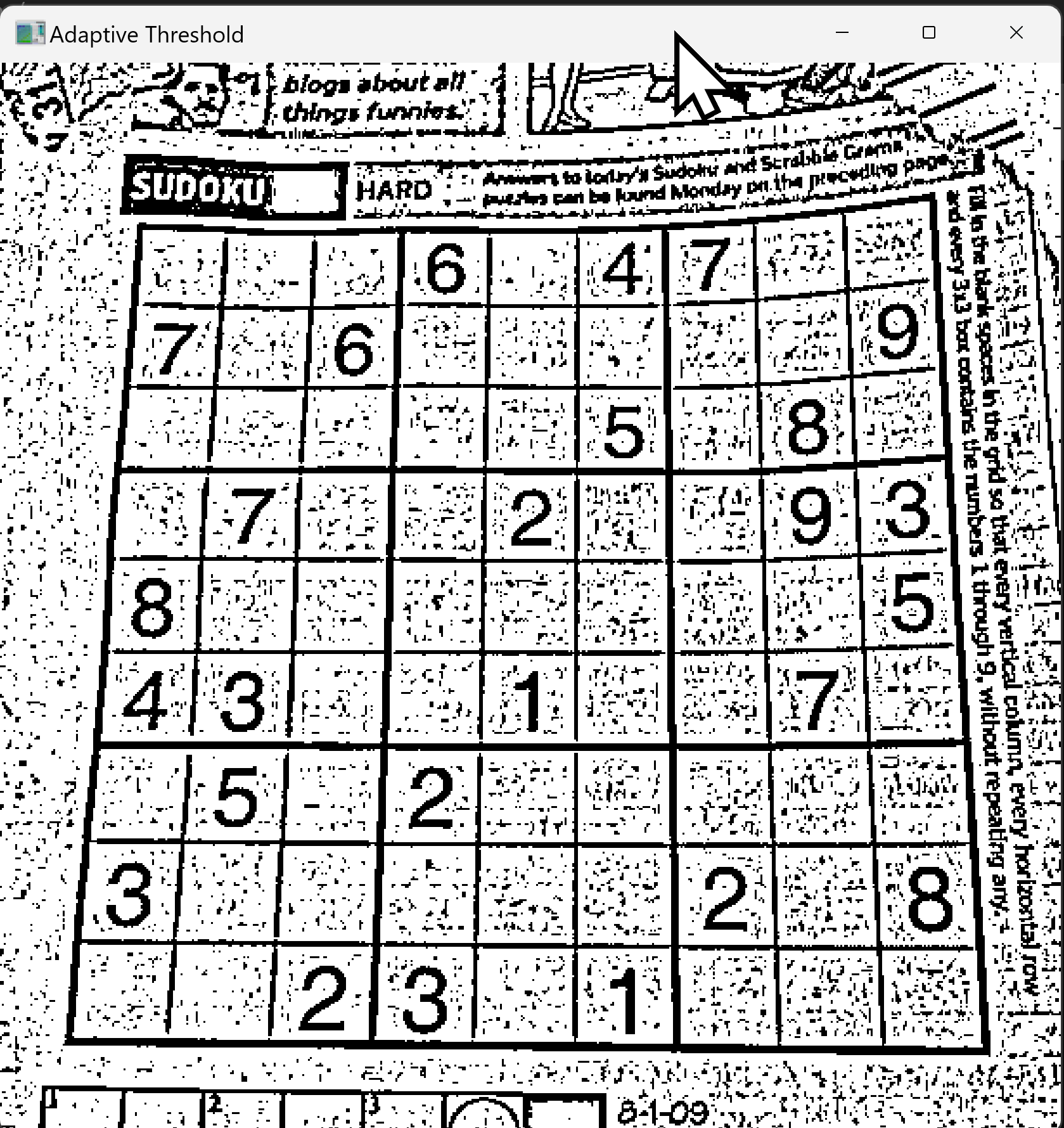
演習8.blockSizeの変更
手順
- プログラムを実行し、二値化結果を表示する。
- blockSize(第5引数)を 11 から 21、51 へ変更し、それぞれ実行する。
ヒント
- blockSizeには奇数を指定する。
考察ポイント
- blockSizeを大きくすると、二値化結果の細部がどのように変化するか。
GrabCutによる画像セグメンテーション
概要
GrabCutは、画像の前景と背景を分離するセグメンテーションアルゴリズムである。ユーザが指定した矩形領域を基に、グラフカット(画像をグラフ構造として扱い、最適な分割を求める手法)による最適化で前景を抽出する。背景除去や画像合成の前処理に用いられる。下記の rect は対象画像(messi5.jpg)に合わせた値であり、別の画像に適用する場合は、前景を囲むように矩形を調整する。
使用されている技術
- cv2.grabCut:GrabCutアルゴリズムを実行する関数。反復回数を増やすと精度が向上するが、処理時間も増加する。
- GC_INIT_WITH_RECT:矩形領域を初期値として前景抽出を行うモード。
ソースコード
矩形領域を指定して前景を抽出する。rect は (x, y, 幅, 高さ) で前景を囲む矩形を表す。
import cv2
import numpy as np
import urllib.request
# 画像のダウンロード
url = "https://raw.githubusercontent.com/opencv/opencv/master/samples/data/messi5.jpg"
urllib.request.urlretrieve(url, "messi5.jpg")
img = cv2.imread("messi5.jpg")
# GrabCutに必要な配列を準備
mask = np.zeros(img.shape[:2], np.uint8)
bgdModel = np.zeros((1, 65), np.float64)
fgdModel = np.zeros((1, 65), np.float64)
# 前景を囲む矩形 (x, y, 幅, 高さ)。別画像では要調整
rect = (50, 50, 450, 290)
# GrabCutを5回反復して実行
cv2.grabCut(img, mask, rect, bgdModel, fgdModel, 5, cv2.GC_INIT_WITH_RECT)
# 前景と判定された画素のみ残す
mask2 = np.where((mask == 2) | (mask == 0), 0, 1).astype('uint8')
result = img * mask2[:, :, np.newaxis]
cv2.imshow('GrabCut', result)
cv2.waitKey(0)
cv2.destroyAllWindows()
演習9.矩形領域の変更
手順
- プログラムを実行し、前景抽出の結果を表示する。
rectの値を変更し、前景の一部が矩形の外に出るようにして実行する。
ヒント
rectは (x, y, 幅, 高さ) の順で指定する。
考察ポイント
- 矩形の外に出た前景部分が、抽出結果でどのように扱われるか。
カラー画像の読み込みと表示
概要
カラー画像を読み込み、表示用に縮小するプログラムである。画像幅が1024ピクセルを超える場合に縮小する。本資料が用いるサンプル画像の範囲では、縮小後の幅は1024ピクセル以下に収まる。
使用されている技術
- cv2.resize:画像のサイズを変更する関数。
- INTER_AREA:縮小に適した補間手法。面積平均により画質劣化を抑える。
ソースコード
import cv2
import urllib.request
# 画像のダウンロード
url = "https://raw.githubusercontent.com/opencv/opencv/master/samples/data/fruits.jpg"
urllib.request.urlretrieve(url, "fruits.jpg")
# 画像の読み込み
img = cv2.imread("fruits.jpg")
height, width = img.shape[:2]
# 幅が1024を超える場合、幅が1024以下になるよう1/2または1/4に縮小
if width > 1024:
scale = 0.5 if width / 2 <= 1024 else 0.25
img = cv2.resize(img, (int(width * scale), int(height * scale)), interpolation=cv2.INTER_AREA)
cv2.imshow('Image', img)
cv2.waitKey(0)
cv2.destroyAllWindows()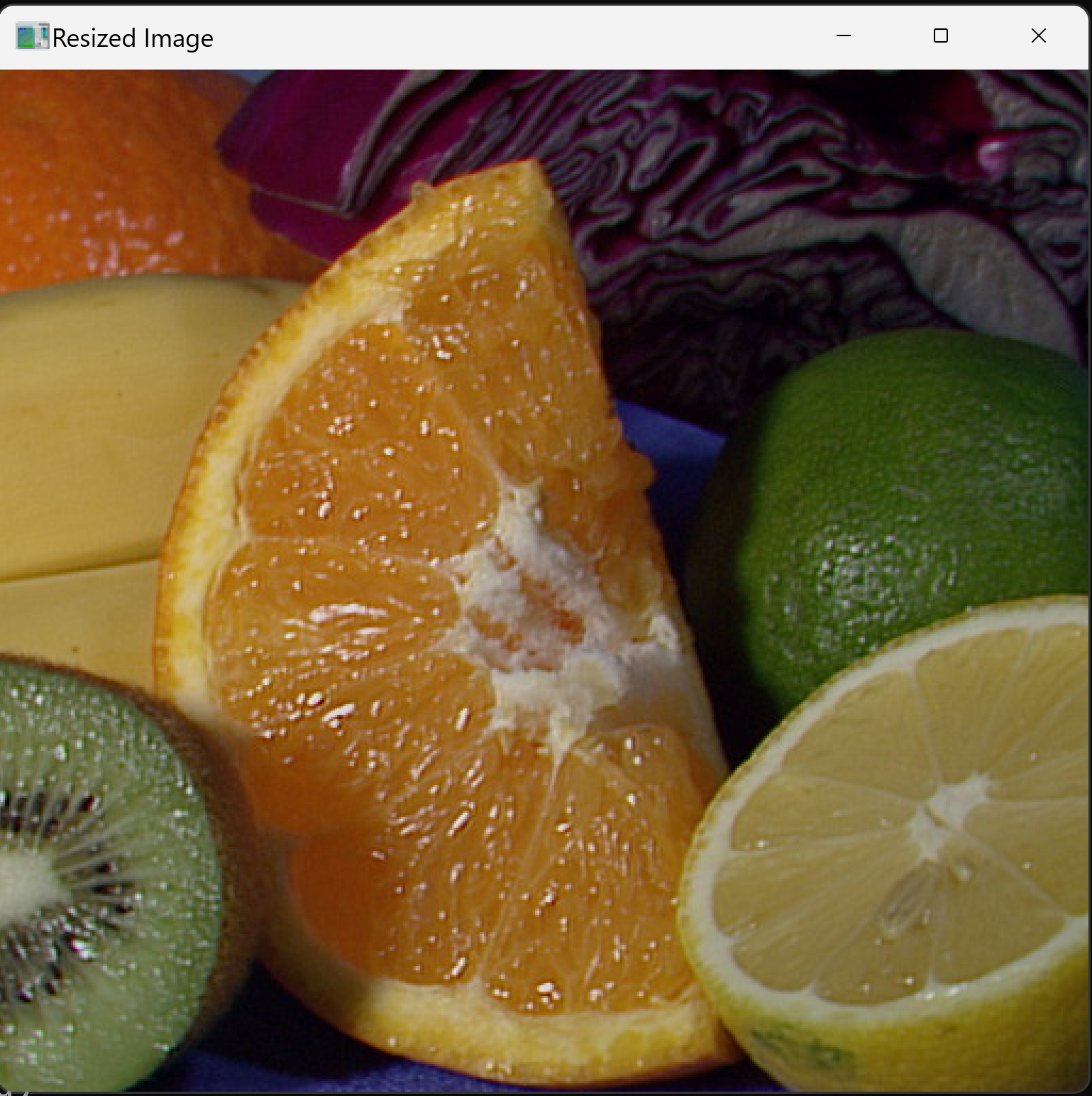
パソコンカメラ映像の表示
概要
パソコンのカメラから映像を取得し、表示用に縮小するプログラムである。カメラが接続されていない場合や使用できない場合は、フレームを取得できずに終了する。
使用されている技術
- cv2.VideoCapture:カメラや動画ファイルから映像を取得するクラス。引数0は既定のカメラを指定する。
- INTER_AREA:縮小に適した補間手法。
ソースコード
カメラ映像を取得し、縮小して表示する。qキーで終了する。縮小条件はS10と同一である。
import cv2
# カメラのキャプチャ
cap = cv2.VideoCapture(0)
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
height, width = frame.shape[:2]
# 幅が1024を超える場合、幅が1024以下になるよう1/2または1/4に縮小
if width > 1024:
scale = 0.5 if width / 2 <= 1024 else 0.25
frame = cv2.resize(frame, (int(width * scale), int(height * scale)), interpolation=cv2.INTER_AREA)
cv2.imshow('Webcam', frame)
# 'q'キーで終了
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()演習10.解像度の確認
手順
- S10のプログラムを実行し、画像を表示する。
- S11のプログラムを実行し、カメラ映像を表示する。
qキーで終了する。
ヒント
- カメラが使用できない場合、S11は何も表示せずに終了する。
考察ポイント
- 表示された画像・映像の幅が1024ピクセル以下に収まっているか。