gensim を使ってみる
gensim の URL : https://radimrehurek.com/gensim/
先人に感謝.
前準備
Python 3.12 のインストール
インストール済みの場合は実行不要。
管理者権限でコマンドプロンプトを起動(手順:Windowsキーまたはスタートメニュー > cmd と入力 > 右クリック > 「管理者として実行」)し、以下を実行する。管理者権限は、wingetの--scope machineオプションでシステム全体にソフトウェアをインストールするために必要である。
REM Python をシステム領域にインストール
winget install --scope machine --id Python.Python.3.12 -e --silent --accept-source-agreements --accept-package-agreements
REM Python のパス設定
set "PYTHON_PATH=C:\Program Files\Python312"
set "PYTHON_SCRIPTS_PATH=C:\Program Files\Python312\Scripts"
echo "%PATH%" | find /i "%PYTHON_PATH%" >nul
if errorlevel 1 setx PATH "%PATH%;%PYTHON_PATH%" /M >nul
echo "%PATH%" | find /i "%PYTHON_SCRIPTS_PATH%" >nul
if errorlevel 1 setx PATH "%PATH%;%PYTHON_SCRIPTS_PATH%" /M >nul【関連する外部ページ】
Python の公式ページ: https://www.python.org/
AI エディタ Windsurf のインストール
Pythonプログラムの編集・実行には、AI エディタの利用を推奨する。ここでは,Windsurfのインストールを説明する。
管理者権限でコマンドプロンプトを起動(手順:Windowsキーまたはスタートメニュー > cmd と入力 > 右クリック > 「管理者として実行」)し、以下を実行して、Windsurfをシステム全体にインストールする。管理者権限は、wingetの--scope machineオプションでシステム全体にソフトウェアをインストールするために必要となる。
winget install --scope machine --id Codeium.Windsurf -e --silent --accept-source-agreements --accept-package-agreements【関連する外部ページ】
Windsurf の公式ページ: https://windsurf.com/
gensim パッケージのインストール
- Windows で,管理者権限でコマンドプロンプトを起動(手順:Windowsキーまたはスタートメニュー >
cmdと入力 > 右クリック > 「管理者として実行」)。 - gensim をインストール
python -m pip install -U gensim

- インストール終了の確認
Word2Vec に関するサンプルプログラムを動かしてみる
次のページで公開されているプログラムを使用する.
上のページの注意書きにもある通り,2G バイトのファイルがダウンロードされます.
- データのダウンロードと語彙の確認
import gensim.downloader as api wv = api.load('word2vec-google-news-300') for i, word in enumerate(wv.vocab): if i == 10: break print(word)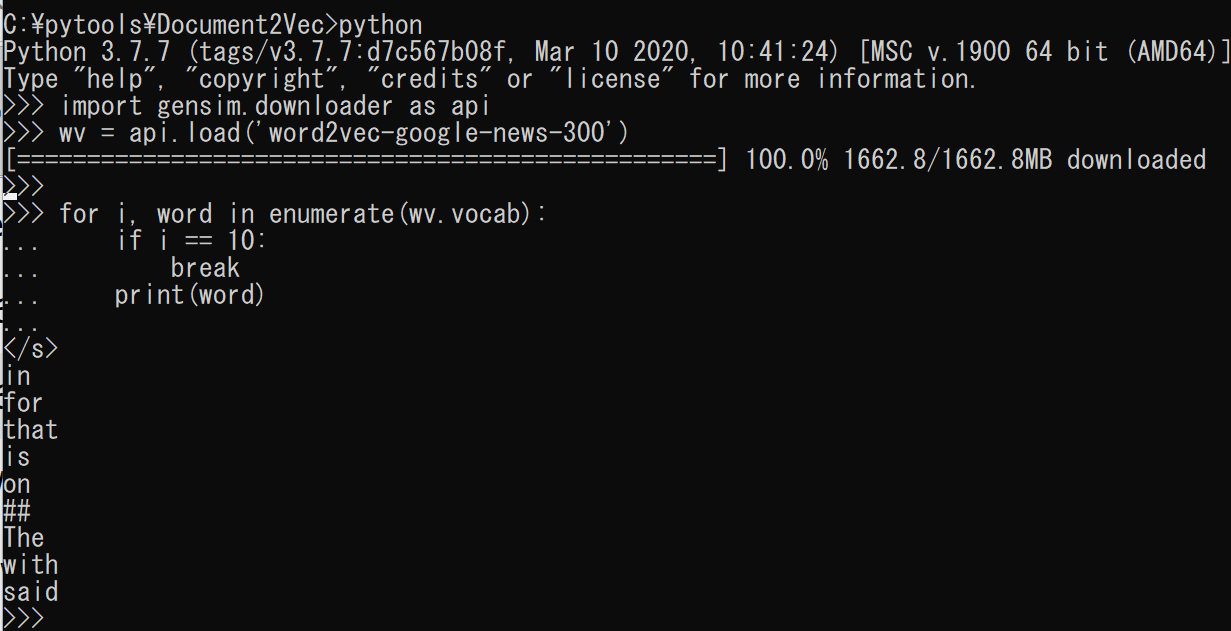
- 単語ベクトルの表示
words = ['car', 'minivan', 'bicycle', 'airplane', 'cereal', 'communism'] for w in words: print(wv[w])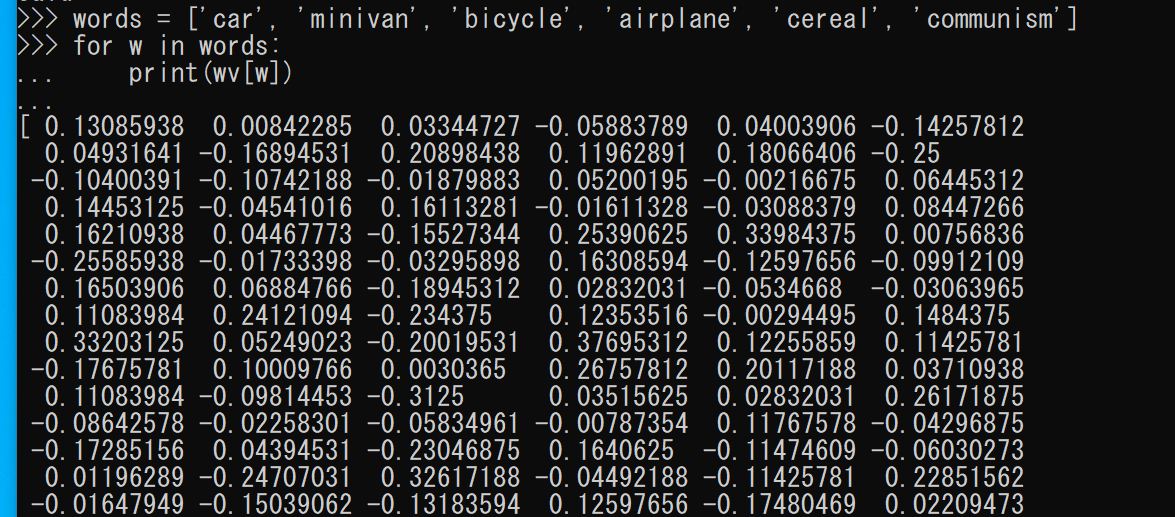
- 2単語間の類似度
pairs = [ ('car', 'minivan'), # a minivan is a kind of car ('car', 'bicycle'), # still a wheeled vehicle ('car', 'airplane'), # ok, no wheels, but still a vehicle ('car', 'cereal'), # ... and so on ('car', 'communism'), ] for w1, w2 in pairs: print('%r\t%r\t%.2f' % (w1, w2, wv.similarity(w1, w2)))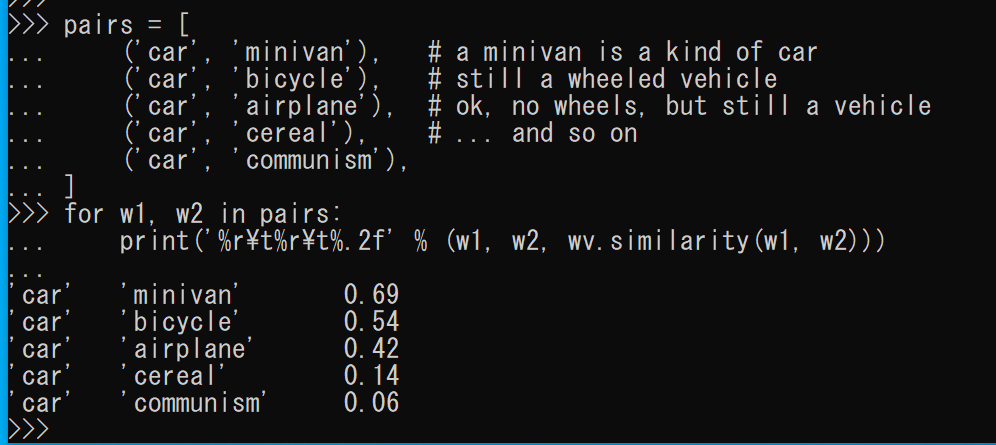
- 単語の類似検索
print(wv.most_similar(positive=['car', 'minivan'], topn=5))
