テーブルの分解 (table decomposition)
【概要】 リレーショナルデータベースでのテーブルの分解は,あるテーブルを属性集合の部分集合による射影で置き換えるプロセスであり,X₁∪X₂∪…∪Xₘ = {A₁, A₂,…, Aₙ}を満たす.情報無損失分解は,分解されたテーブルから元のテーブルが復元可能な分解である.関数従属性はリレーションスキーマの属性間の依存関係を表すものであり,ある属性の値が決まれば別の属性の値が一意に決まる関係である.ボイス・コッド正規形は,任意の関数従属性X→Yについて,Xがスキーマのキーになっていると定義される.ボイス・コッド正規形は更新時異常を解消可能だが,正規化前のテーブルにおける関数従属性を維持できない場合がある.

- テーブル(table)
リレーショナルデータベース での「テーブル」は,多重集合 (muti set)を基礎とする体系になっている ということに注意して欲しい. 「テーブル」は,同じ値をもった行が複数回現れることが許される.
- SQL におけるDISTINCT 指定
SQL では,SELECT と選択リスト内の間に「DISTINCT」と書く場合がある.これを DISTINCT 指定という.
DISTINCT 指定を行うと,問い合わせの結果に重複行があるとき1つを残して他を除去する. 重複行というときは,行全体が同じ値だという意味である. 下記の例では,同じ注文者名が別の商品番号の注文を行った場合には重複行ではない.
select distinct 商品番号, 注文者名 FROM 注文DISTINCT 指定があるとき,重複行があるとき1つを残して他を除去するから,SQL の評価結果は多重集合にはなることは無い(必ず集合になる) . 一方で,DISTINCT 指定がないときは,SQL の評価結果が多重集合になる場合がある.
補足説明しておく. 下記のテーブル scores を例に説明する.
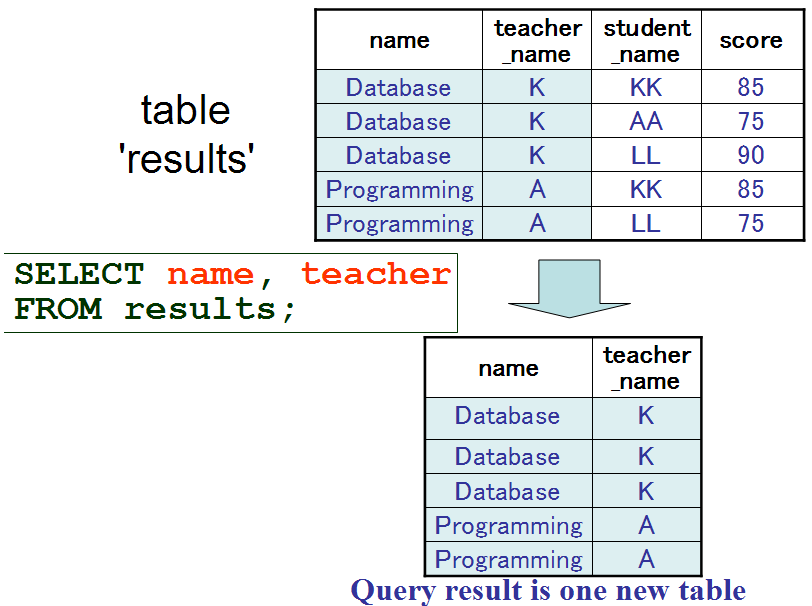
id | name | teacher_name | student_name | score ---------------------------------------------------- 1 | Database | K | KK | 85 2 | Database | K | AA | 75 3 | Database | K | LL | 90 4 | Programming | A | KK | 85 5 | Programming | A | LL | 75このテーブル scores から,属性 name と teacher_name だけを抜き出して新しいテーブルを作ったとする.下記のように重複行が現れる.つまり新しく出来たテーブルは多重集合である.
name | teacher_name --------------------------- Database | K Database | K Database | K Programming | A Programming | A上記のテーブルを作るための SQL は次の通りである.
SELECT name, teacher_name FROM scores;
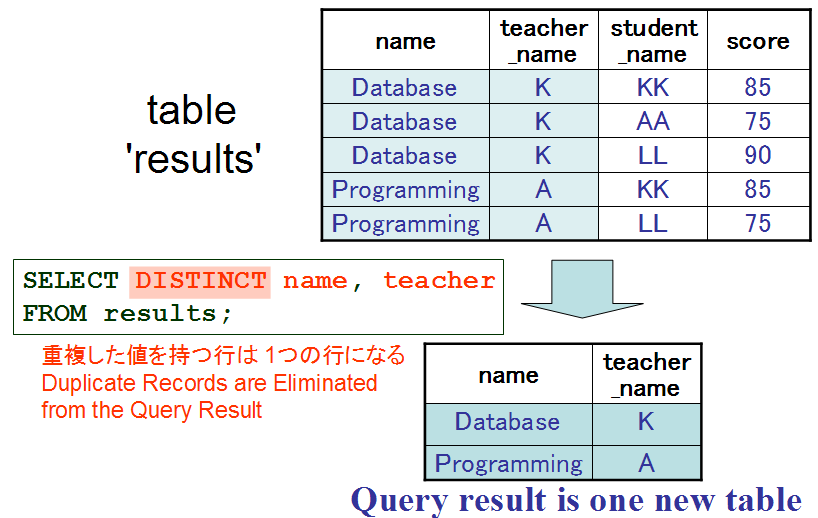
一方で,射影 scores[name, student_name] といったときは,属性 name と teacher_name だけを抜き出した上で, 重複行があるとき1つを残して他を除去する.結果は次の通りである.
name | teacher_name --------------------------- Database | K Programming | A上記のテーブルを得るための SQL には, 次のように DISTINCT 指定が付く.
SELECT DISTINCT name, teacher_name FROM scores; - 結合属性
R(A1, A2, …, An) とS(B1, B2, …, Bm)をリレーションとする.この2つのリレーションの共通属性C1, C2, …, Ck は次の性質を満たす.
- {A1, A2, …, An}∩{B1, B2, …, Bm} = {C1, C2, …, Ck}
- 各Ci(1≦i≦k)について,元のリレーションRとSにおけるドメインが等しい.つまり dom(R.Ci) = dom(S.Ci)
共通属性のことを結合属性ともいう.
- 自然結合演算
R(A1, A2, …, An) とS(B1, B2, …, Bm)をリレーションとする.RとSの自然結合演算を「R * S」と書く.自然結合演算は,結合演算と,射影演算を使って,次のように表すことができる.
R * S = (R[C1 = C1, C2 = C2, …, Ck = Ck]S) [A1, A2, …, An, D1, D2, …, Dm-k], 但し,C1, C2, …, Ck は,AとB の結合属性. また,{B1, B2, …, Bm}−{C1, C2, …, Ck} = {D1, D2, …, Dm-k}とする.*「R * S」の代わりに「R S」のように書くこともある.
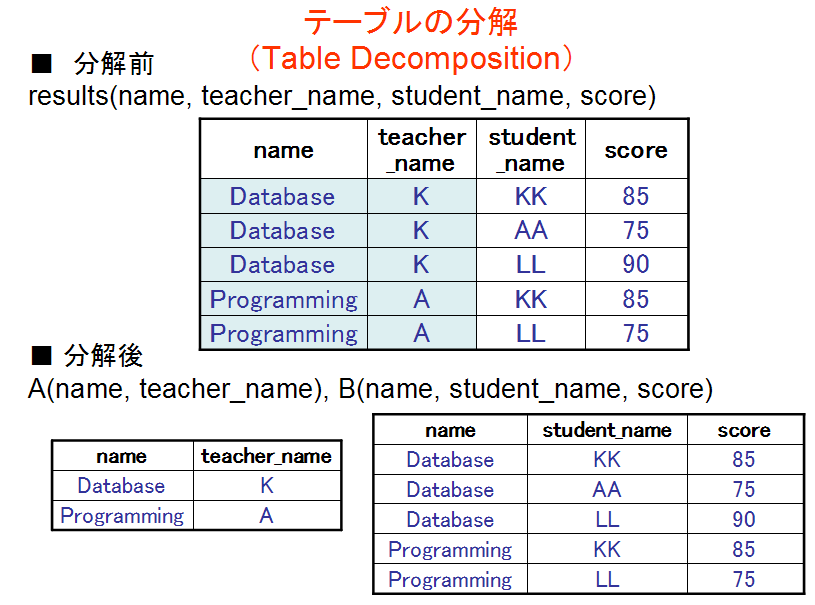
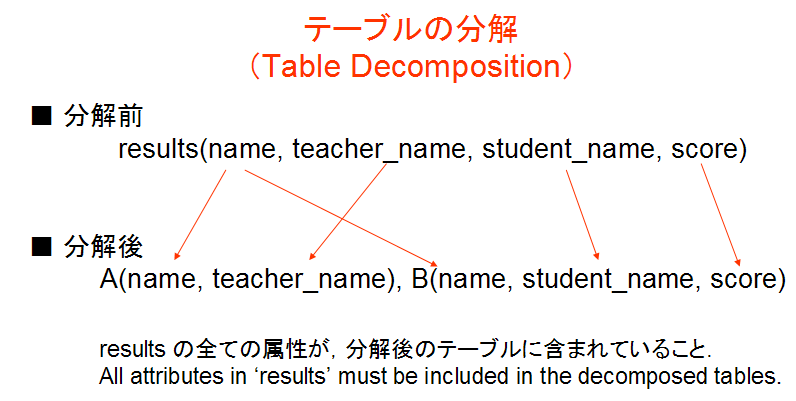
- テーブルの分解
あるテーブルの テーブル名が R,属性名が A1, A2, …, An であるとする.また,このテーブルには 重複行が無いものと仮定する. このテーブルの,m 個のテーブル X1, X2, ..., Xm への分解は次のように定義される.
X1, X2, …, Xm をR の全属性集合{A1, A2,…, An}の部分集合で, X1∪X2∪…∪Xm = {A1, A2,…, An}なる条件を満たすとき(XiとXjは共通集合をもってよい),テーブルを m 個の射影 R[X1], R[X2], …, R[Xm] で置き換えることを,このテーブルの分解という.* 重複行を持つようなテーブルについては,分解を考えないことにする(重複行を持つテーブルについては,無損失分解であることの定義が「難しい」から).
- リレーションの情報無損失分解
あるリレーションが,その分解成分の自然結合をとると元の復元できるとき,その分解は情報無損失分解(information lossless decomposition) であるという.
- 更新時異状
更新時異状は,修正時異状,挿入時異状,削除時異状の3種類がある.データベース設計時の配慮によって,更新時異状のかなりの部分を防ぐことができる.
- 修正時異状
修正時異状は,リレーションのタップルの属性値の修正において発生する異状のことである.
実世界におけるある変化を,あるリレーションのタップルの属性値の修正において反映させたいというときに,リレーションの設計によっては,リレーションの中の複数のタップルを同時に更新せねばならないことがある.これは,つい,複数のタップルを同時に更新することを忘れてしまい,データベースを壊してしまう可能性を生む.
- 挿入時異状
挿入時異状は,リレーションへのタップルの挿入において発生する異状のことである.
非空制約あるいはキー制約があると,その制約が付与されている属性の属性値が空値であるようなタップルは挿入できない.そのことが原因で,実世界におけるある変化を,あるリレーションへのタップルの挿入によってデータベースに反映させたいと思っても,それが出来ないことがある.
- 削除時異状
削除時異状は,リレーションからのタップルの削除において発生する異状のことである.
実世界におけるある変化を,あるリレーションからのタップルの削除によってデータベースに反映させようとしたとき,そのタップルの削除によって,他の有用な情報が失われることがある.
- 関数従属性
リレーションスキーマR(A1, A2, …, Al, B1, B2, …, Bm, C1, C2, …, Cn) に関数従属性A1, A2, …, Al → B1, B2, …, Bm が存在するとは,次の場合をいう.
・リレーションスキーマRの任意のインスタンスの任意の2タップルt と t' について,それらのA1, A2, …, Al値が等しければ,B1, B2, …, Bm 値が等しいということが必ず成り立つ
(補足) リレーションスキーマR(A1, A2, …, Al, B1, B2, …, Bm, C1, C2, …, Cn) に関数従属性A1, A2, …, Al → B1, B2, …, Bm が存在することは,リレーションスキーマRの任意のインスタンスRが,2つの射影R[A1, A2, …, Al, B1, B2, …, Bm] とR[A1, A2, …, Al, C1, C2, …, Cn] に情報無損失分解されるための十分条件になるという性質がある.
- ボイスコッド正規形 (Boyce-Codd normal form)
リレーションスキーマRがボイスコッド正規形であるとは,次の条件が成立することである.
・Rが持つ任意の関数従属性X→Yについて(複数の関数従属性があるときは,その全てについて),XがR のキーになっている
大胆にまとめると,ボイズコッド正規形について,次のことが言える.
- 任意のリレーションスキーマを情報無損失分解して,ボイズコッド正規形にできる
- ボイスコッド正規形になるように情報無損失分解することで,更新時異状を解消することができる
- しかし,分解前のリレーションが保持していた関数従属性を,ボイスコッド正規形に分解後のリレーションが維持できなくなる可能性がある.つまり,ボイスコッド正規形に分解後のリレーションでは,元のリレーションが保持していた関数従属性に抵触するような更新操作を防ぐことができなくなる可能性がある.
- 単純値 atomic value
分解不可能な値のことである. 直積集合の要素や,べき集合の要素は単純値ではないと考えるのが普通である.
- 直積集合の例: 属性名「family name」のドメインと,属性名「given name」のドメインの直積集合
- べき集合の例: ドメイン {みかん,りんご,バナナ}から構成されるべき集合は,{φ, {みかん}, {りんご}, {バナナ}, {みかん, りんご}, {りんご, バナナ}, {バナナ, みかん}, {みかん, りんご, バナナ}}
演習で行うこと
- Sqliteman の起動と終了
- Sqliteman で既存のデータベースを開く
- SQL を用いたテーブル定義と一貫性制約の記述
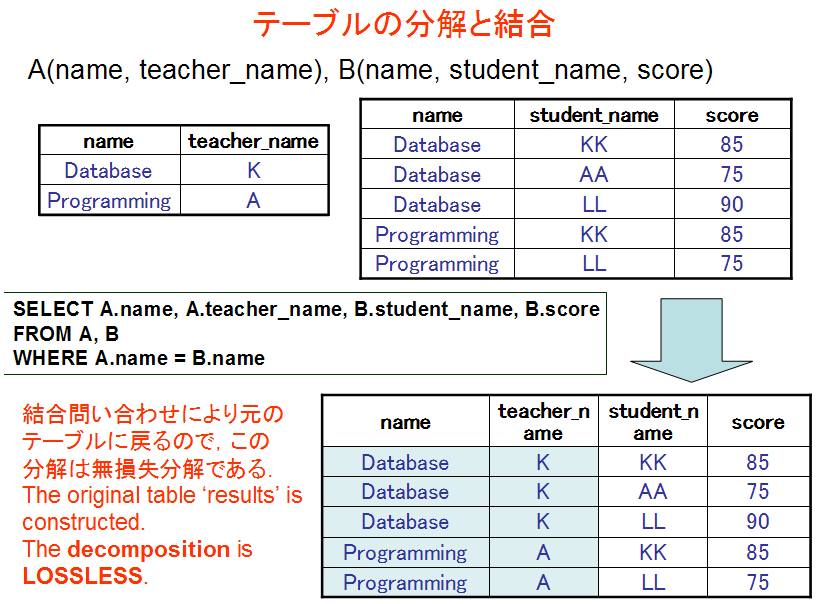
リレーショナル・スキーマ (relational schema): scores(id, name, teacher_name, student_name, score, created_at, updated_at)
SQL プログラム:
create table scores ( id integer primary key autoincrement not null, name text not null, teacher_name text not null, student_name text not null, score integer not null check ( score >= 0 AND score <=100 ), created_at datetime not null, updated_at datetime, UNIQUE (name, student_name) ); - SQL を用いたテーブルへの行の挿入
begin transaction; insert into scores values( 1, 'Database', 'K', 'KK', 85, datetime('now', 'localtime'), NULL ); insert into scores values( 2, 'Database', 'K', 'AA', 75, datetime('now', 'localtime'), NULL ); insert into scores values( 3, 'Database', 'K', 'LL', 90, datetime('now', 'localtime'), NULL ); insert into scores values( 4, 'Programming', 'A', 'KK', 85, datetime('now', 'localtime'), NULL ); insert into scores values( 5, 'Programming', 'A', 'LL', 75, datetime('now', 'localtime'), NULL ); commit;datetime('now', 'localtime') は現在日時の取得である.datetime型は,YYYY-MM-DD HH:MM:SS形式である.
- Sqliteman を用いたデータのブラウズ
- DISTINCT を含む SQL の例
SELECT DISTINCT name, teacher_name FROM scores; SELECT name, teacher_name FROM scores; SELECT DISTINCT score FROM scores; SELECT score FROM scores; - SQL を用いたテーブルの分解
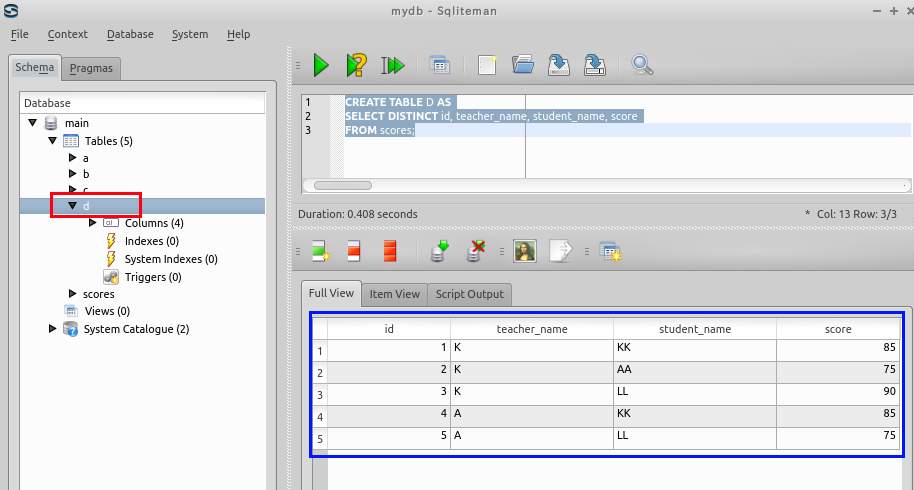
create table A AS select distinct name, teacher_name FROM scores; create table B AS select distinct id, name, student_name, score FROM scores; - 結合問い合わせ (join query)
SELECT B.id, A.name, A.teacher_name, B.student_name, B.score FROM A, B WHERE A.name = B.name;
- 情報無損失分解にならない分解
create table C AS select distinct name, student_name FROM scores; create table D AS select distinct id, teacher_name, student_name, score FROM scores; SELECT D.id, C.name, D.teacher_name, C.student_name, D.score FROM C, D WHERE C.student_name = D.student_name;
SQLite 3 の SQL 演習に関連する部分
SQLite 3の SQL の説明は http://www.hwaci.com/sw/sqlite/lang.html (English Web Page) にある.
- select distinct ...
同一の値を持つ行が複数あるとき,1つを残して除去する
- create table AS <table-name> SELECT ...
SQL 問い合わせ結果から新しいテーブルを作る
Sqliteman の起動と終了
- Sqliteman の起動
* Ubuntu での SQLiteman の起動例
「プログラミング」→「Sqliteman」と操作する.
SQLiteman の新しいウインドウが開く.
* Lubuntu での SQLiteman の起動例
「プログラミング」→「Sqliteman」と操作する
SQLiteman の新しいウインドウが開く.
* Windows での SQLiteman の起動例
「Sqliteman」 のアイコンをダブルクリック

Sqliteman のウインドウが開く.
SQLiteman で新しいデータベースを作成する
前回の授業で作成したデータベースを使うときは,ここの手順は行わなくて良い.
以下の手順で,新しいデータベースを作成する.その結果,データベースファイルができる.
- 「File」→ 「New」
- データベースの新規作成を開始する
データベースファイル名 を指定
Sqliteman で既存のデータベースを開く
すでに作成済みのデータベースを,下記の手順で開くことができる.
以下の手順で,既存のデータベースファイルを開く.
- 「File」→
「Open」
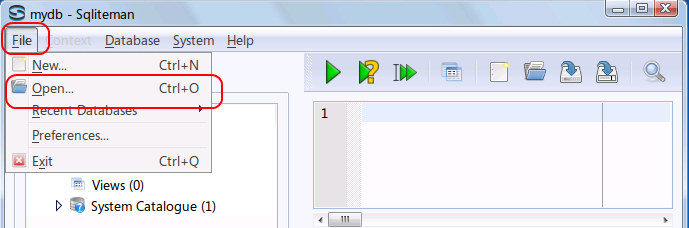
- データベースファイルを開く
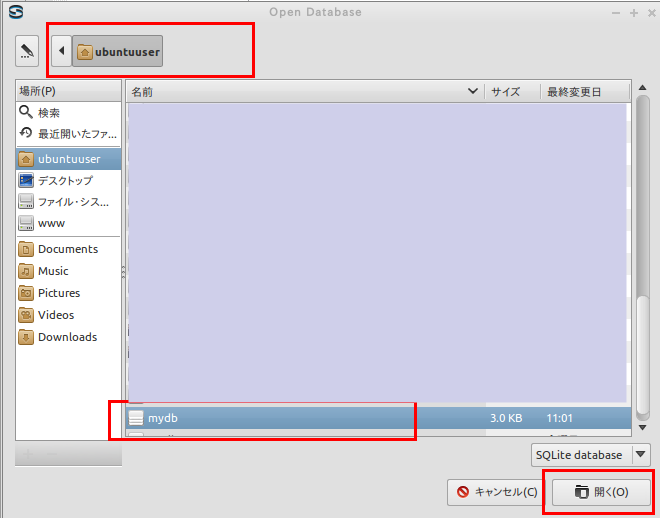
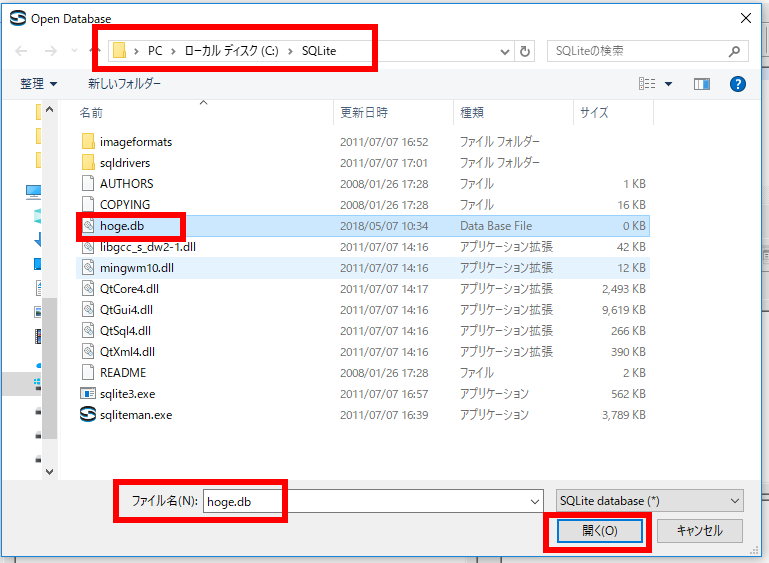
* Ubuntu での実行例(「mydb」を開く場合)
データベースファイル mydb を選び, 「開く」をクリック
* Windows での実行例(「C:\SQLite\mydb」を開く場合)
データベースファイル C:\SQLite\mydb を選び, 「開く」をクリック
要するに,/home/<ユーザ名>/SQLite 3の下の mydb を選ぶ.
SQL を用いたテーブル定義と一貫性制約の記述
SQL を用いて,scores テーブルを定義し,一貫性制約を記述する.
リレーショナル・スキーマ (relational schema): scores(id, name, teacher_name, student_name, score, created_at, updated_at)
- scores テーブルの定義
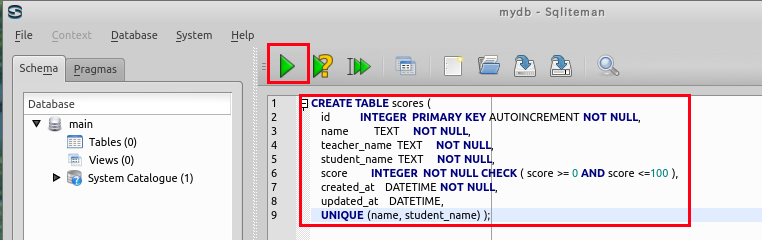
次の SQL を入力し,「Run SQL」のアイコンをクリック
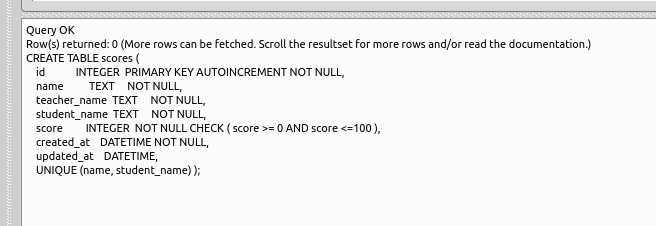
create table scores ( id integer primary key autoincrement not null, name text not null, teacher_name text not null, student_name text not null, score integer not null check ( score >= 0 AND score <=100 ), created_at datetime not null, updated_at datetime, UNIQUE (name, student_name) );* 「SQL Editor」のウインドウには,SQL プログラムを記述することができる.
- コンソールの確認
エラーメッセージが出ていないことを確認する.
SQL を用いたテーブルへの行の挿入
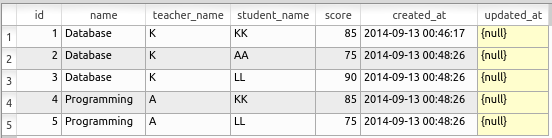
次のような scores テーブルを作成する.
以下の手順で,SQL を用いて scores テーブルへの行の挿入を行う.
- SQL プログラムの記述
「insert into ...」は行の挿入を意味する.ここには 5つの SQL 文を書き, 「begin transaction」と「commit」で囲む.
begin transaction; insert into scores values( 1, 'Database', 'K', 'KK', 85, datetime('now', 'localtime'), NULL ); insert into scores values( 2, 'Database', 'K', 'AA', 75, datetime('now', 'localtime'), NULL ); insert into scores values( 3, 'Database', 'K', 'LL', 90, datetime('now', 'localtime'), NULL ); insert into scores values( 4, 'Programming', 'A', 'KK', 85, datetime('now', 'localtime'), NULL ); insert into scores values( 5, 'Programming', 'A', 'LL', 75, datetime('now', 'localtime'), NULL ); commit;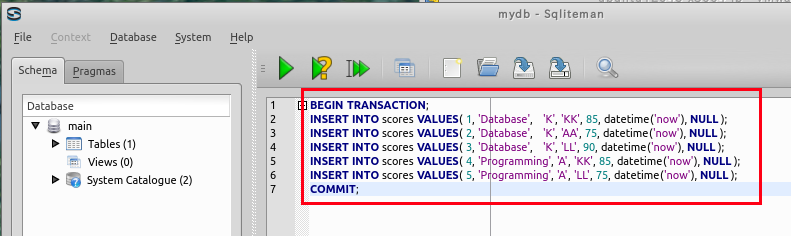
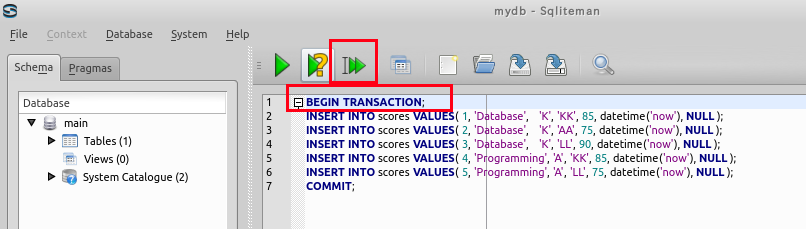
- 複数の SQL 文の一括実行
複数の SQL 文を一括実行したいので,カーソルを先頭行に移動した後に,「Run multiple SQL statements ...」のボタンをクリックする. 「Move the cursor to the top statement. Click "Run multiple SQL statements from current cursor position in one batch" icon)
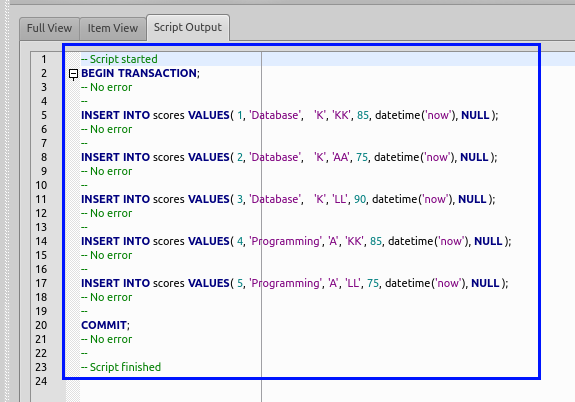
- 「Script Output」ウインドウの確認
エラーメッセージが出ていないことを確認する.
Sqliteman を用いたデータのブラウズ
- scores テーブル
まず,オブジェクト・ブラウザ (Object Browser) の中の「Tables」を展開する.
次に,テーブル scoresを選択する. テーブル scoresが表示される.
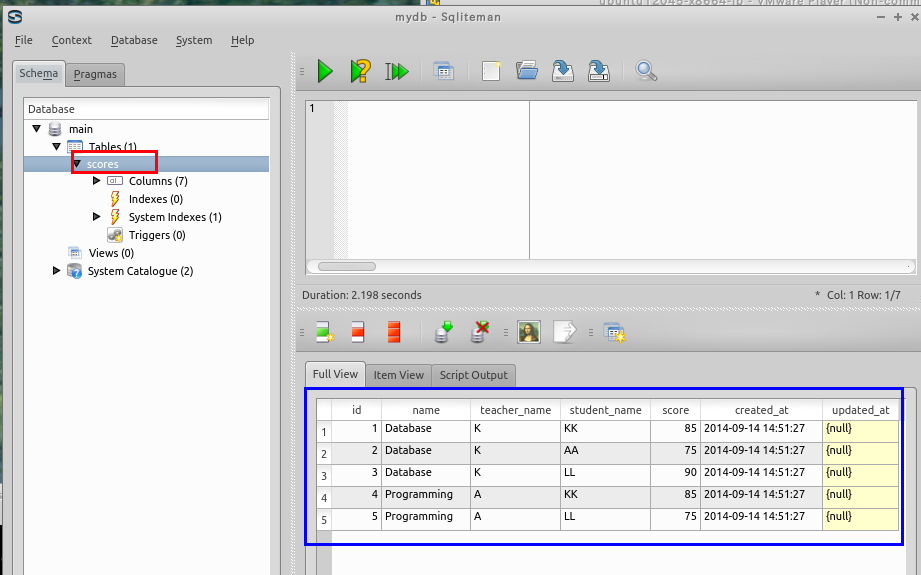
* もし,データに間違いがあれば,このウインドウで修正することができる.
DISTINCT を含む SQL の例
DISTINCT を付ける場合
SELECT DISTINCT name, teacher_name
FROM scores;
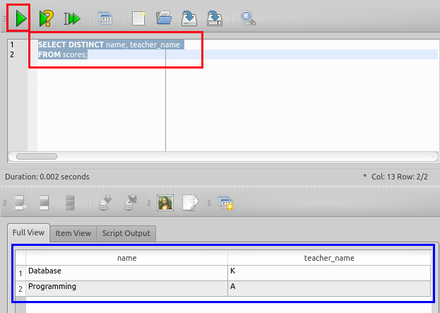
DISTINCT を付けない場合
SELECT name, teacher_name
FROM scores;
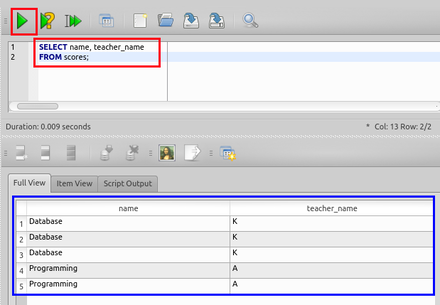
DISTINCT を付ける場合
SELECT DISTINCT score
FROM scores;
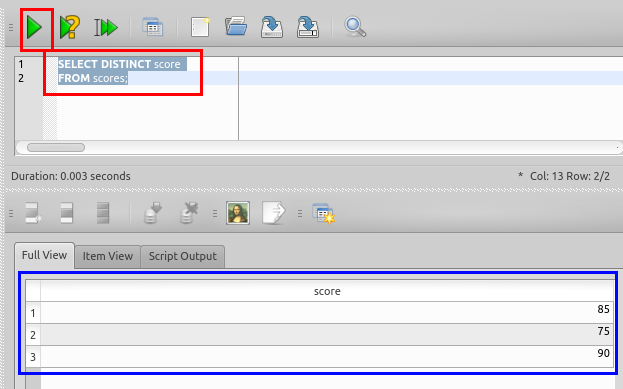
DISTINCT を付けない場合
SELECT score
FROM scores;
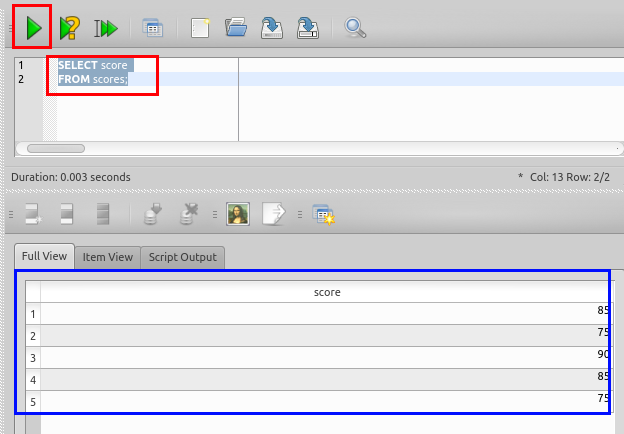
SQL を用いたテーブルの分解
scores( name, teacher_name, student_name, score )を 2つのテーブルに分解する:
- A(name, teacher_name)
- B(name, student_score, score)
テーブルを分解する際には,重複行を除去するという規則があることに注意する.DISTINCTを使用する.
SQL の実行
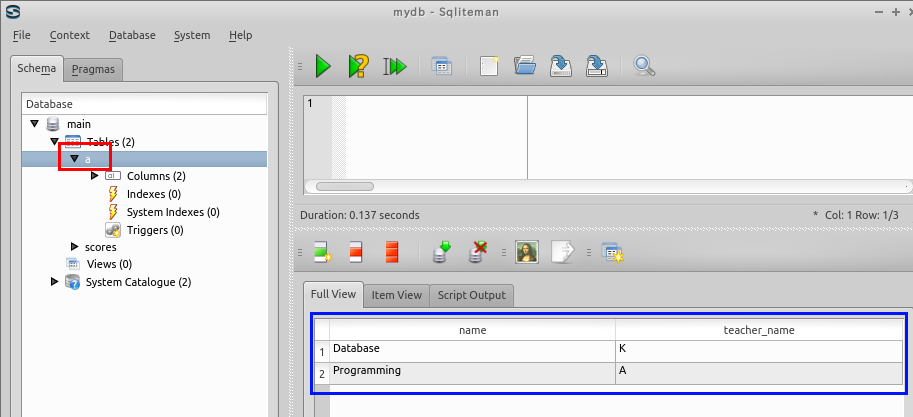
create table A AS
select distinct name, teacher_name
FROM scores;
データのブラウズ機能を使いテーブル A を確認する.
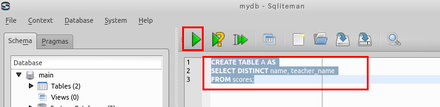
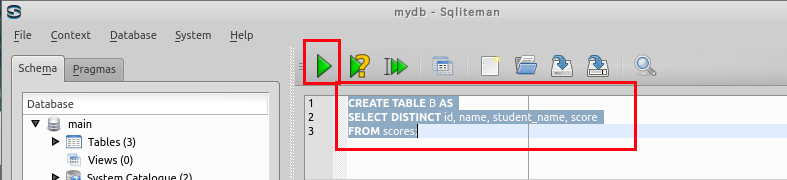
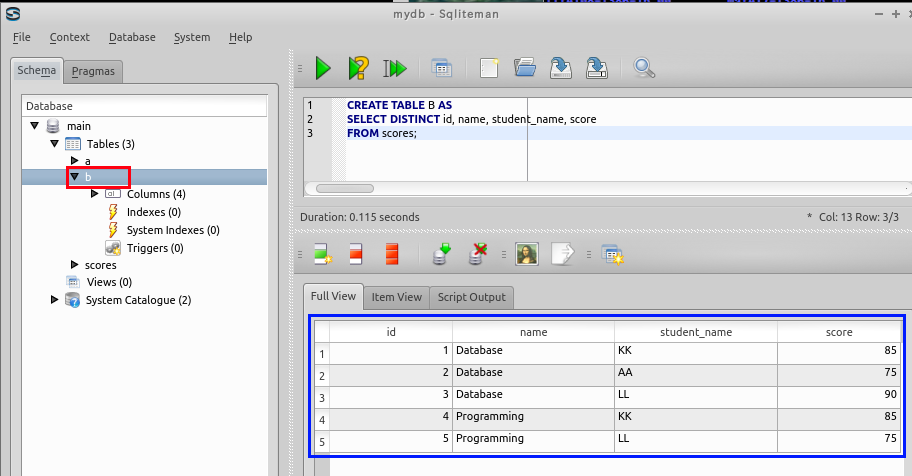
SQL の実行
create table B AS
select distinct id, name, student_name, score
FROM scores;
データのブラウズ機能を使いテーブル B を確認する.
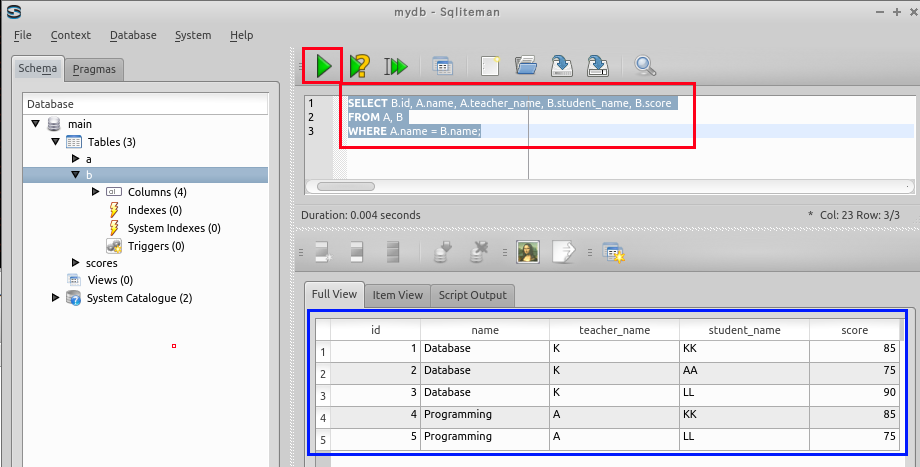
結合問い合わせ (join query)
元のテーブル scores が,分解後の2つのテーブル A, B から復元できることを確認する. テーブル scores は,テーブル A と B から復元できるため,データベース設計として:
- テーブル scores をデータベースに格納する方法
- テーブル scores ではなく,テーブル A と B をデータベースに格納する方法
という 2つの選択肢が考えられる.(では,どちらが良いのか? 今度の授業で明らかにしていく)
Examine that the original table 'scores' can be constructed from the two tables A and B. It means that there are two alternatives in database design.
- Store 'scores' into database, or
- Store 'A' and 'B' instead of 'scores' in database.
SELECT B.id, A.name, A.teacher_name, B.student_name, B.score
FROM A, B
WHERE A.name = B.name;
情報無損失分解にならない分解
今度は,テーブルの分解の仕方を変える. 分解後のテーブルから,もとのテーブルに復元できない場合があることを確認する.
Table decompositions are not always LOSSLESS.
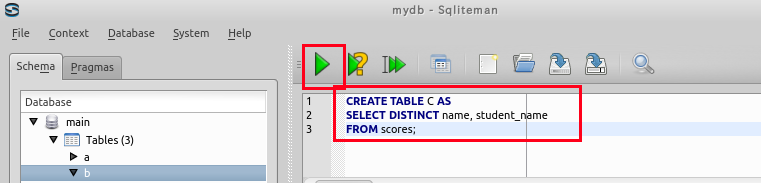
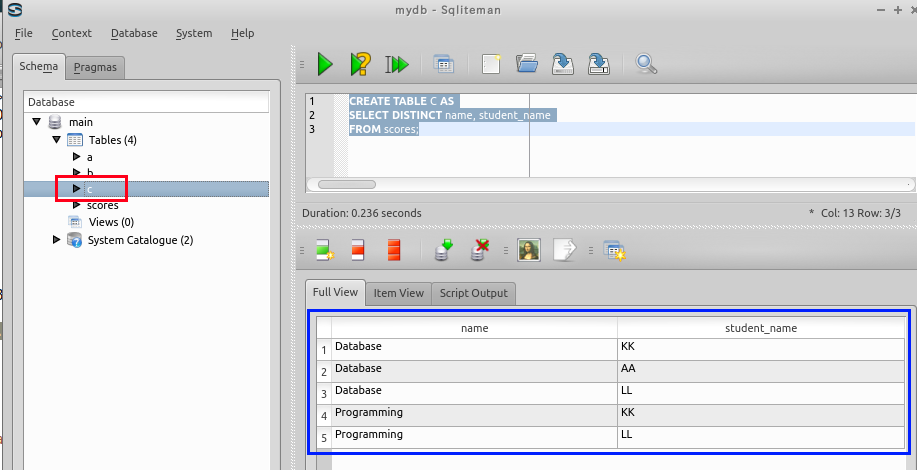
SQL の実行
create table C AS
select distinct name, student_name
FROM scores;
データのブラウズ
SQL の実行
create table D AS
select distinct id, teacher_name, student_name, score
FROM scores;
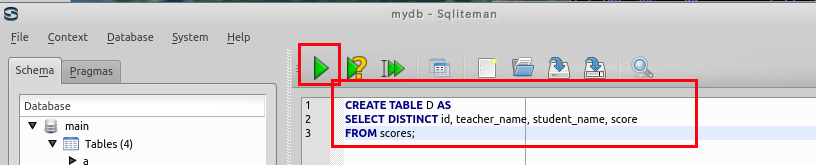
データのブラウズ
テーブル C, D からは,テーブル scores を構築できない.
次の問いに答えよ.その後,下記の解答例を確認せよ.
問い
次のようなテーブル R(id, price, type) を作成したい.
そこで,SQLite 3 で 次の SQL を実行した.
そのために,次のSQLを評価する.
そこで,次のSQLを評価する.「SELECT * FROM RR;」の評価結果は何か?
解答例 (Answers)
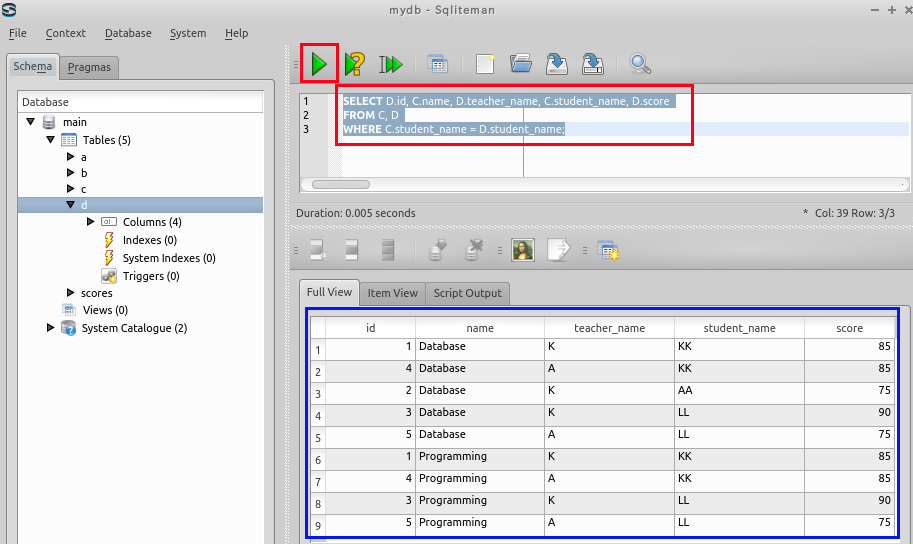
* 問い合わせ結果は1つのテーブルになる.その属性名には,元のテーブル名と属性名をドットでつなげたドット記法を用いている.
SELECT D.id, C.name, D.teacher_name, C.student_name, D.score
FROM C, D
WHERE C.student_name = D.student_name;
演習問題と解答例
name | type | color
------------------------------
apple | fruit | red
apple | fruit | blue
rose | flower | white
rose | flower | red
rose | flower | yellow
SELECT DISTINCT name, type FROM PTABLE;
SELECT DISTINCT name FROM PTABLE;
id|price|type
------------------------------
1 |10 |author
2 |21 |name
3 |30 |author
4 |45 |name
5 |50 |author
create table R (
id integer primary key autoincrement not null,
price integer not null,
type text );
insert into R(price, type) values(10, 'author');
insert into R(price, type) values(21, 'name');
insert into R(price, type) values(30, 'author');
insert into R(price, type) values(45, 'name');
insert into R(price, type) values(50, 'author');
SELECT DISTINCT type FROM R;
tid | type
-----------
1 |author
2 |name
create table S (
tid integer primary key autoincrement not null,
type text);
insert into S(tid, type) values(1, 'author');
insert into S(tid, type) values(2, 'name');
SELECT R.id, R.price, R.type, S.tid FROM R, S where R.type = S.type;
CREATE TEMPORARY TABLE T1 AS select distinct type FROM R where type IS not null;
create table T2 AS SELECT OID AS typeid, * FROM T1;
SELECT * FROM T2;
create table RR AS SELECT R.id AS id, R.price AS price, S.tid AS tid
FROM R NATURAL JOIN S;
SELECT * FROM RR;
select distinct name, type FROM PTABLE;
name | type
------------------
apple | fruit
rose | flower
select distinct name FROM PTABLE;
name
--------
apple
rose
select distinct type FROM R;
type
--------
author
name
SELECT R.id, R.price, R.type, S.tid FROM R, S where R.type = S.type;
id | price | type | tid
-----------------------------
1 | 10 | author | 1
2 | 21 | name | 2
3 | 30 | author | 1
4 | 45 | name | 2
5 | 50 | author | 1
SELECT * FROM T2;
1|author
2|name
SELECT * FROM RR;
id|price|tid
1|10|1
2|21|2
3|30|1
4|45|2
5|50|1