Ruby で,文字列を空白文字類や「.」などを区切りとして切り出す
- 文字列を,空白文字類を区切りとして,文字列の配列に変換 (split を使用)
- 文字列を,空白文字類と半角のカンマ「,」と「\v」を区切りとして,文字列の配列に変換 (gsub と split を使用)
- 文字列を,空白文字類とと半角のカンマ「,」と「\v」と全角の空白文字を区切りとして,文字列の配列に変換
- 文字列を,連続する [a-zA-Z0-9_] を切り出して,文字列の配列に変換
- 半角数字の並びを切り出す
- IP アドレスを数字に変換半角のピリオドを区切りとする)
文字列を,空白文字類を区切りとして,文字列の配列に変換 (split を使用)
文字列を,空白文字類を区切りとして,文字列の配列に変換してみる. ここでいう「空白文字類」とは Ruby でいう「\s」のこと(つまり「 |\t|\r|\n|\f」)です.
String#split(nil) を使って簡単にできる. split の引数として nil を与えたとき, 先頭と末尾の空白文字類を取り除いたのち,空白文字類を区切りとして,文字列の配列に変換します.つまり,次の 3つは同じ働きをします.
- str.split(nil)
- str.strip.split(/\s+/)
- str.strip.split(/[ |\t|\r|\n|\f]+/)
【実行結果の例】

文字列を,空白文字類と半角のカンマ「,」と「\v」を区切りとして,文字列の配列に変換 (gsub と split を使用)
今度は,区切りとして空白文字類だけでなく,半角のカンマ「,」と「\v」も使う.
gsub を使って,半角のカンマ「,」と「\v」を,半角の空白文字「 」に置き換えた後に,String#split(nil) を使う.
gsub(/,/," ").gsub(/\v/," ").split(nil)
【実行結果の例】
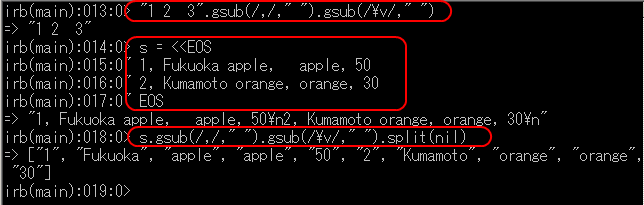
文字列を,空白文字類とと半角のカンマ「,」と「\v」と全角の空白文字を区切りとして,文字列の配列に変換
今度は,全角の空白文字も区切りにしたい場合です. そのために、
全角の空白文字を半角の空白文字に置き換えます.
プログラムは次のようになる.
Ruby スクリプトの文字コードの設定に注意してください.
* Ruby 1.8 では先頭行に shebang を使って指定する(のがおすすめ)
- 「#! ruby -Ks」 : 起動時のオプション指定を「-Ks」にしたのと同じ効果. Shift_JIS に設定
- 「#! ruby -Ke」 : 起動時のオプション指定を「-Ke」にしたのと同じ効果.EUC-JP に設定
- 「#! ruby -Ku」 : 起動時のオプション指定を「-Ku」にしたのと同じ効果.UTF-8 に設定
- 「#! ruby -Kn」 : 日本語を認識しない
* Ruby 1.9 では先頭行に magic comment を書く(のがおすすめ)
magic comment の例は次の通り.
- 「# -*- coding: shift_jis -*-」 : Shift_JIS に設定
- 「# -*- coding: shift_jis -*-」 : Windows-31J に設定
- 「# -*- coding: euc-jp -*-」 : EUC-JP に設定
- 「# -*- coding: utf-8 -*-」 : UTF-8 に設定
shbang と magic comment の両方を指定したい場合には,1行目を shebang, 2行目を magic comment.Ruby 1.8 では magic comment は読み飛ばされる.
【ソースコード】
#! ruby -Ks
# -*- coding: shift_jis -*-
require 'pp'
require 'nkf'
def tokenize(s)
# 文字列を,空白文字類と半角のカンマ「,」と「\v」と全角の空白文字を区切りとして,文字列の配列に変換
# 全角の空白文字を gsub を使って半角の空白文字に置き換える.
# その後,半角のカンマ「,」と「\v」を半角の空白文字に置き換える
# その後 split を使って区切る
return s.gsub(/ /," ").gsub(/,/," ").gsub(/\v/," ").split(nil)
end
if __FILE__ == $0
p tokenize("1 2 3")
s = <<EOS
1, Fukuoka apple, apple, 50
2, Kumamoto orange, orange, 30
EOS
p tokenize( s )
# 「"① ② I Ⅱ ㍉ ㌢ ㈱"」は Shift_JIS にはなく,Shift_JIS を拡張した文字コードセットにある
p tokenize( "① ② I Ⅱ ㍉ ㌢ ㈱" )
# 「"‖ 〜 − ¢ £ ¬ " 」は Shift_JIS, EUC-JP, ISO-2022-JP では同じ文字コードなのに Windows-31J では違う文字コード
p tokenize( "‖ 〜 − ¢ £ ¬ " )
# その他
p tokenize( "表 〒" )
end
* 下記の実行結果は Linux 上の Ruby バージョン 1.9.1 での実行結果です.

【実行結果の例 (Shift_JISj の場合)】
- Ruby スクリプトの文字コードがShift_JISであることの確認

- shebang と magic comment (先頭の 2 行) の確認

- プログラムの実行と実行結果の確認

【実行結果の例 (UTF-8 の場合)】
- ターミナルの文字コードが UTF-8 であることの確認
- Ruby スクリプトの文字コードが UTF-8 であることの確認

- shebang と magic comment (先頭の 2 行) の確認
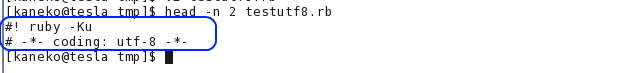
- プログラムの実行と実行結果の確認
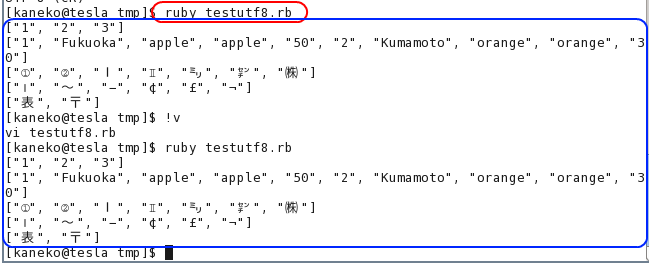
【実行結果の例 (EUC-JP の場合)】
- ターミナルの文字コードが EUC-JP であることの確認
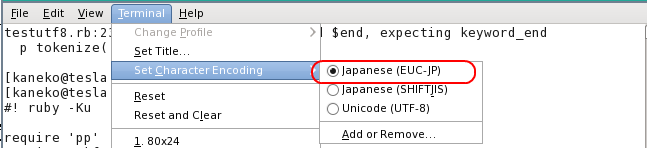
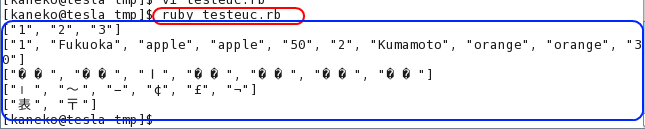
- Ruby スクリプトの文字コードが EUC-JP であることの確認

- shebang と magic comment (先頭の 2 行) の確認

- プログラムの実行と実行結果の確認
「① ② I Ⅱ ㍉ ㌢ ㈱」が化けるが,私の力が足りず,力尽きる.
文字列を,連続する [a-zA-Z0-9_] を切り出して,文字列の配列に変換
今度は,連続する [a-zA-Z0-9_] を切り出して,文字列の配列に変換します. String#scan を使って簡単にできる.scan(/\w+/n)
【実行結果の例】
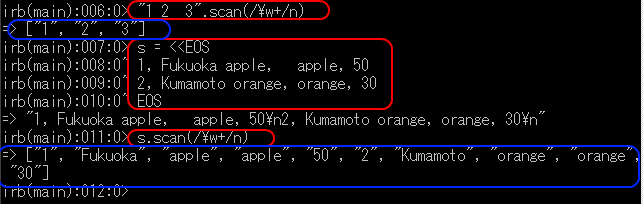
半角数字の並びを切り出す
半角数字の並びを切り出すのは簡単です.
scan(/[0-9]+/n)
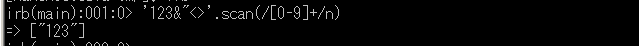
0から9(つまり半角数字)以外を消すのも簡単です.
gsub(/[^0-9]/,"")

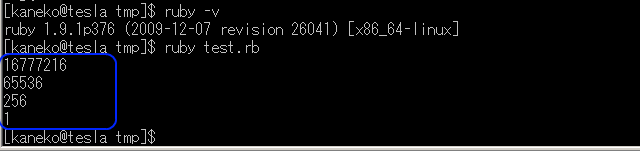
IP アドレスを数字に変換半角のピリオドを区切りとする)
入力の例: "1.2.3.4", 出力の例: 16909060 ( = ( 1 * 256 * 256 * 256 ) + ( 2 * 256 * 256 ) + ( 3 * 256 ) + 4 )
#! ruby -Ks # -*- coding: shift_jis -*- require 'pp' require 'nkf' def ipaddrval(ip) # . で区切られた IP アドレスを数値に変える a = ip.strip.split(/[.]/) return ( a[0].to_i * 256 * 256 * 256 ) + ( a[1].to_i * 256 * 256 ) + ( a[2].to_i * 256 ) + a[3].to_i end if __FILE__ == $0 p ipaddrval "1.0.0.0" p ipaddrval "0.1.0.0" p ipaddrval "0.0.1.0" p ipaddrval "0.0.0.1" end