MambaOut による画像分類(入力:動画像)(ImageNet 1000クラス)(ソースコードと説明と利用ガイド)
プログラム利用ガイド
1. このプログラムの利用シーン
動画ファイルやリアルタイムカメラ映像から、ImageNet 1000クラスの物体分類をリアルタイムで実行するためのソフトウェアである。研究用途でのMambaOutモデルの性能評価や、画像認識システムのプロトタイプ開発に活用される。
2. 主な機能
- MambaOutモデル選択: 4種類のモデル(Tiny/Small/Base/Kobe)から用途に応じて選択できる。
- リアルタイム分類: 動画フレームごとにTop-5分類結果を表示し、確信度に応じて色分け表示する。
- 複数入力対応: 動画ファイル、ウェブカメラ、サンプル動画の3つの入力ソースに対応する。
- 結果保存: 分類結果をリアルタイム表示するとともに、終了時にresult.txtファイルに保存する。
- 分類統計: 検出されたクラスごとの出現回数を自動集計する。
3. 基本的な使い方
- 起動とモデル選択: プログラム実行後、使用するMambaOutモデル(1-4)を選択する。
- 入力選択: キーボードで0(動画ファイル)、1(ウェブカメラ)、2(サンプル動画)のいずれかを入力する。
- 分類実行: 映像が表示され、リアルタイムで分類結果が画面に描画される。
- 終了: 映像表示画面でqキーを押してプログラムを終了する。
4. 便利な機能
- モデル比較: 異なるMambaOutモデルを選択して性能差を確認できる。
- 確信度表示: 分類結果の確信度が色で視覚化される(緑: 高確信、赤: 低確信)。
- フレーム情報: 処理フレーム数とクラス数がリアルタイムで表示される。
- 結果ログ: 全フレームの分類結果がコンソールに出力され、ファイルに保存される。
Python開発環境,ライブラリ類
ここでは、最低限の事前準備について説明する。機械学習や深層学習を行う場合は、NVIDIA CUDA、Visual Studio、Cursorなどを追加でインストールすると便利である。これらについては別ページ https://www.kkaneko.jp/cc/dev/aiassist.htmlで詳しく解説しているので、必要に応じて参照してください。
Python 3.12 のインストール
Pythonのインストールを行い、Pythonのプログラムを実行する環境を整える。扱う環境は、Windows搭載パソコンである。金子研究室では、Python 3.12.10を推奨する。
[Windows での Python 3.12 のインストール手順を見るには、ここをクリック]
Windows での Python 3.12 のインストール
以下のいずれかの方法でPython 3.12をインストールする。Pythonがインストール済みの場合、この手順は不要である。
方法 1:winget によるインストール
【インストールコマンドの実行方法】
管理者権限でコマンドプロンプトを起動する(手順:Windowsキーまたはスタートメニュー → cmd と入力 → 右クリック → 「管理者として実行」)。そして、コマンド全体をコマンドプロンプトにコピー&ペーストする。
--scope machine を指定することで、システム全体(全ユーザー向け)にインストールされる。このオプションの実行には管理者権限が必要である。インストール完了後、コマンドプロンプトを再起動するとPATHが反映される。
REM Python 3.12 をシステム領域にインストール
winget install --id Python.Python.3.12 -e --scope machine --silent --accept-source-agreements --accept-package-agreements --override "/quiet InstallAllUsers=1 PrependPath=1 Include_test=0 Include_pip=1 Include_launcher=1 InstallLauncherAllUsers=1 TargetDir=\"C:\Program Files\Python312\""
REM Python と Scripts を PATH 先頭に追加
powershell -NoProfile -Command "$p='C:\Program Files\Python312'; $s=\"$p\Scripts\"; $c=[Environment]::GetEnvironmentVariable('Path','Machine'); if((Test-Path $p) -and (';'+$c+';' -notlike \"*;$p;*\") -and (';'+$c+';' -notlike \"*;$s;*\")){[Environment]::SetEnvironmentVariable('Path',\"$p;$s;$c\",'Machine')}"
方法 2:インストーラーによるインストール
- Python公式サイト(https://www.python.org/downloads/)にアクセスし、「Download Python 3.x.x」ボタンからWindows用インストーラーをダウンロードする。
- ダウンロードしたインストーラーを実行する。
- 初期画面の下部に表示される「Add python.exe to PATH」にチェックを入れてから「Customize installation」を選択する。このチェックを入れ忘れると、コマンドプロンプトから
pythonコマンドを実行できない。 - 「Install Python 3.xx for all users」にチェックを入れ、「Install」をクリックする。
インストールの確認
コマンドプロンプトで以下を実行する。
python --versionバージョン番号(例:Python 3.12.x)が表示されればインストール成功である。「'python' は、内部コマンドまたは外部コマンドとして認識されていません。」と表示される場合は、インストールが正常に完了していない。
Python の開発環境 Visual Studio Code のインストールと Python 用の設定
Python の開発環境Visual Studio Code(プログラムを編集するソフトウェア。以下、VS Code)を整える。
[Windows での Visual Studio Code のインストールと Python 用の設定手順を見るには、ここをクリック]
Windows での Visual Studio Code のインストールと Python 用の設定手順
1. VS Code と拡張機能のインストール
以下のコマンドにより,既存の VS Code を削除し,全ユーザー共有の設定で再インストールしたうえで,拡張機能(VS Code に機能を追加するソフトウェア)をまとめて導入する.
【インストールコマンドの実行方法】
管理者権限でコマンドプロンプトを起動する(手順:Windows キーまたはスタートメニュー → cmd と入力 → 右クリック → 「管理者として実行」)。そして,コマンド全体をコマンドプロンプトにコピー&ペーストする。
インストールコマンド
REM ============================================================
REM Microsoft Visual Studio Code
REM ============================================================
winget uninstall -e --id Microsoft.VisualStudioCode --silent --disable-interactivity --accept-source-agreements
rmdir /s /q C:\ProgramData\vscode-extensions 2>nul
rmdir /s /q "%APPDATA%\Code" 2>nul
rmdir /s /q "%USERPROFILE%\.vscode" 2>nul
rmdir /s /q "%LOCALAPPDATA%\Microsoft\vscode-update" 2>nul
REM VS Code をシステム領域に新規インストール
winget install --scope machine --id Microsoft.VisualStudioCode -e --silent --accept-source-agreements --accept-package-agreements
REM 全ユーザー共有の拡張機能フォルダ
mkdir C:\ProgramData\vscode-extensions 2>nul
icacls "C:\ProgramData\vscode-extensions" /grant "Everyone:(OI)(CI)M" /T
REM スタートメニューのショートカットを --extensions-dir 付きで再作成
rmdir /s /q "C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code" 2>nul
del "C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code.lnk" 2>nul
powershell -NoProfile -Command "$s=New-Object -ComObject WScript.Shell; $lnk=$s.CreateShortcut('C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code.lnk'); $lnk.TargetPath='C:\Program Files\Microsoft VS Code\Code.exe'; $lnk.Arguments='--extensions-dir \"C:\ProgramData\vscode-extensions\"'; $lnk.Save()"
REM ショートカットの検証
powershell -NoProfile -Command "$s=New-Object -ComObject WScript.Shell; $lnk=$s.CreateShortcut('C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code.lnk'); Write-Host 'TargetPath:' $lnk.TargetPath; Write-Host 'Arguments:' $lnk.Arguments"
REM ファイル / フォルダ右クリックの「Code で開く」を登録
reg add "HKLM\SOFTWARE\Classes\*\shell\VSCode\command" /ve /d "\"C:\Program Files\Microsoft VS Code\Code.exe\" --extensions-dir \"C:\ProgramData\vscode-extensions\" \"%1\"" /f
reg add "HKLM\SOFTWARE\Classes\Directory\shell\VSCode\command" /ve /d "\"C:\Program Files\Microsoft VS Code\Code.exe\" --extensions-dir \"C:\ProgramData\vscode-extensions\" \"%1\"" /f
reg add "HKLM\SOFTWARE\Classes\Directory\Background\shell\VSCode\command" /ve /d "\"C:\Program Files\Microsoft VS Code\Code.exe\" --extensions-dir \"C:\ProgramData\vscode-extensions\" \"%V\"" /f
REM --extensions-dir 付きで起動する code.cmd ラッパを作成
REM (%* を echo で書くと対話的 cmd で失われるため、PowerShell で [char]37+'*' を書き出す)
powershell -NoProfile -Command "$pct=[char]37; $q=[char]34; $c='@echo off'+[char]13+[char]10+$q+'C:\Program Files\Microsoft VS Code\bin\code.cmd'+$q+' --extensions-dir '+$q+'C:\ProgramData\vscode-extensions'+$q+' '+$pct+'*'+[char]13+[char]10; [IO.File]::WriteAllText('C:\ProgramData\vscode-extensions\vscode.cmd',$c,[Text.Encoding]::ASCII)"
REM 拡張機能のインストール
set "CODE=C:\Program Files\Microsoft VS Code\bin\code.cmd"
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --uninstall-extension GitHub.copilot
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --uninstall-extension GitHub.copilot-chat
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension ms-python.python
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension ms-python.vscode-pylance
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension ms-python.debugpy
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension MS-CEINTL.vscode-language-pack-ja
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension saoudrizwan.claude-dev
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension rust-lang.rust-analyzer
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension tamasfe.even-better-toml
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension anthropic.claude-code
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension almenon.arepl
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --list-extensions --show-versions
echo === セットアップ完了 ===
2. Python インタプリタの選択
同一マシンに複数の Python がインストールされている場合,VS Code で使用する Python 本体(インタプリタ:Python プログラムを解釈・実行するソフトウェア)を選択する必要がある.
- コマンドパレット(コマンド名で機能を呼び出す VS Code の入力欄)を開く(
Ctrl+Shift+P) Python: Select Interpreterと入力する
- 表示される一覧から,使用する Python(例:
C:\Program Files\Python312\python.exe)を選択する.
ライブラリのインストール:
コマンドプロンプトを管理者として実行(手順:Windowsキーまたはスタートメニュー > cmd と入力 > 右クリック > 「管理者として実行」)し、以下を実行する。
REM PyTorch をインストール(GPU対応版)
set "CUDA_TAG=cu128"
set "PYTHON_PATH=C:\Program Files\Python312"
"%PYTHON_PATH%\Scripts\pip" install --no-user -U numpy torch torchvision torchaudio --index-url https://download.pytorch.org/whl/%CUDA_TAG%
pip install opencv-python pillow timm
MambaOut による画像分類プログラム
概要
このプログラムは、動画の各フレームからMambaOutアーキテクチャを用いてImageNet 1000クラス分類を実行する。SSM(state space model)を除去したGated CNNブロックによる階層的アーキテクチャで画像認識を行い、リアルタイム表示と結果保存を実現する。
主要技術
MambaOut
Yu & Wangが2025年のCVPRで発表したアーキテクチャ[1]。MambaブロックからSSM(state space model)を除去し、Gated CNNブロックのみで構成される。ImageNet画像分類において既存のvisual Mambaモデルを上回る性能を示す。
timm(PyTorch Image Models)
Ross Wightmanが開発したPyTorchベースの画像モデルライブラリ[2]。300以上の事前学習済みモデルと標準的なデータ変換機能を提供する。
技術的特徴
- SSMレス設計
従来のMambaブロックからSSMコンポーネントを除去し、Gated CNNブロックのみで構成する。これによりImageNet分類タスクにおいて不要な複雑性を排除する。
- 深さ方向畳み込みによるトークンミキシング
7x7カーネルの深さ方向畳み込みを用いて空間的特徴の混合を行う。
- 階層的アーキテクチャ
Gated CNNブロックを積み重ねた階層構造により、マルチスケール特徴抽出を実現する。
- timm標準データ変換
ImageNet互換の正規化とリサイズ処理により、事前学習モデルとの整合性を保つ。
実装の特色
- 4種類のMambaOutモデル選択(Tiny/Small/Base/Kobe)
- 複数入力ソース対応(動画ファイル、カメラ、サンプル動画)
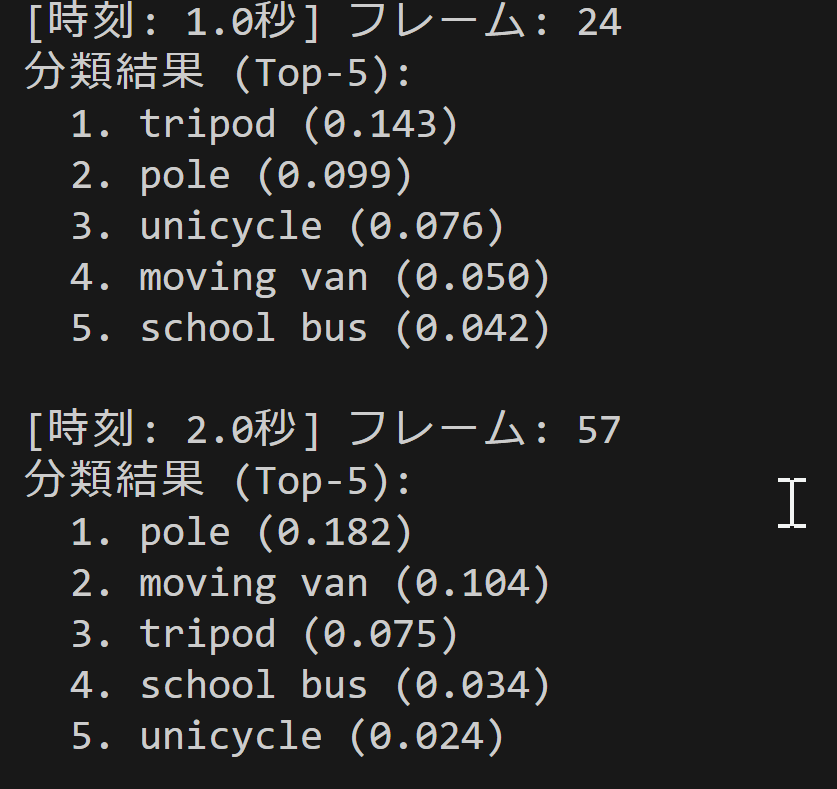
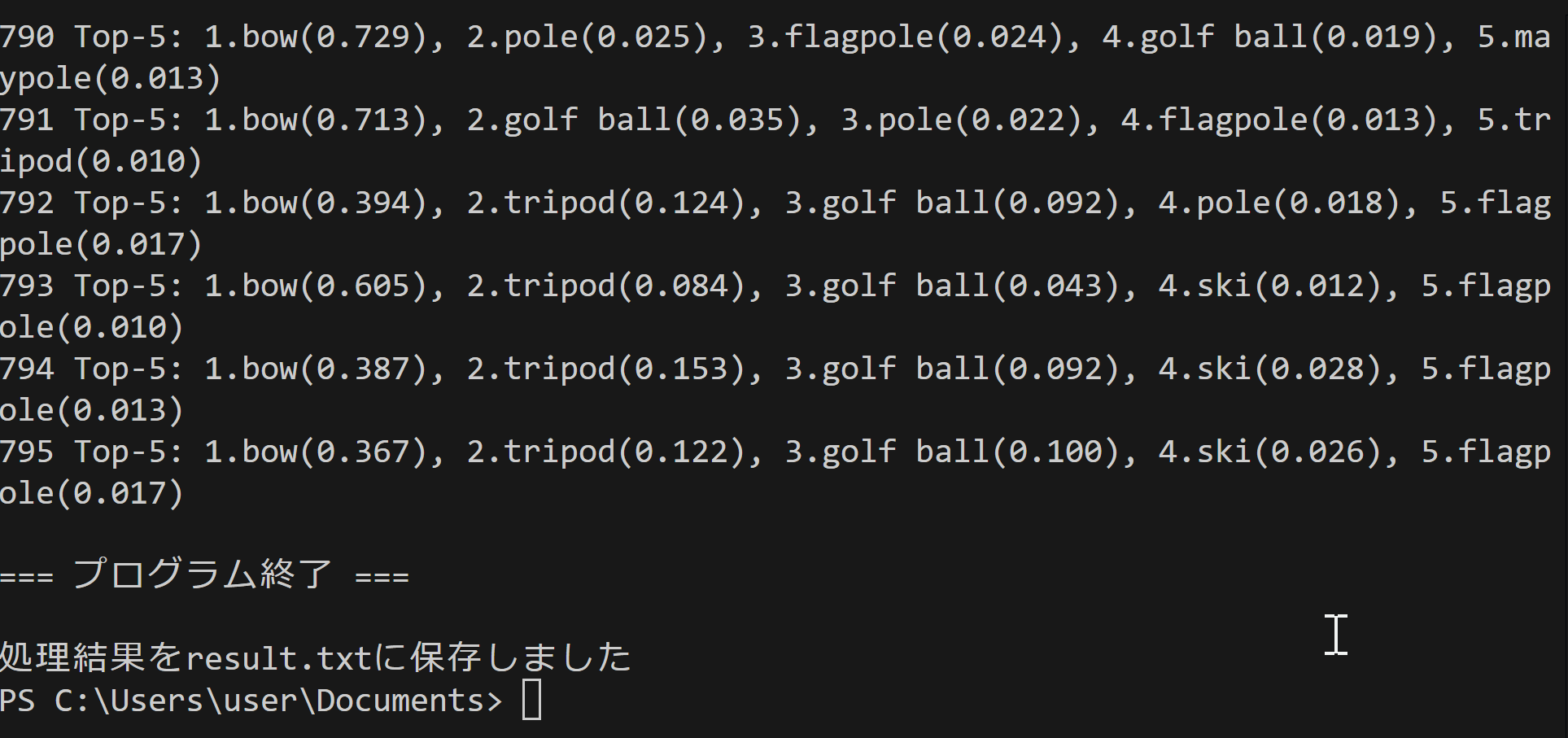
- Top-K分類結果のリアルタイム表示(デフォルトK=5)
- PIL/Pillowによる日本語フォント描画システム
- 分類統計情報の自動集計とファイル保存
参考文献
[1] Yu, W., & Wang, X. (2025). MambaOut: Do We Really Need Mamba for Vision? Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025, pp. 4484-4496. https://openaccess.thecvf.com/content/CVPR2025/papers/Yu_MambaOut_Do_We_Really_Need_Mamba_for_Vision_CVPR_2025_paper.pdf
[2] Wightman, R. (2019). PyTorch Image Models. https://github.com/huggingface/pytorch-image-models
[3] Yu, W., & Wang, X. (2024). MambaOut GitHub Repository. https://github.com/yuweihao/MambaOut
ソースコード
"""
プログラム名: MambaOut 画像分類プログラム(ImageNet 1000クラス)
特徴技術名: MambaOut
出典: Yu, W., & Wang, X. (2025). MambaOut: Do We Really Need Mamba for Vision? In CVPR.
特徴機能: Gated CNNブロックを積み重ねた階層的アーキテクチャによる画像分類。7x7カーネルの深さ方向畳み込みでトークンミキシングを行う。ImageNet画像分類に関する性能が報告されている。
学習済みモデル: MambaOut-Tiny(26.5M parameters)、MambaOut-Small(48.5M)、MambaOut-Base(84.8M)、MambaOut-Kobe(9.1M)が利用可能。timmライブラリから事前学習済みモデルをダウンロード可能。
特徴技術および学習済モデルの利用制限: Apache 2.0ライセンス(オープンソース)。商用利用可能。
方式設計:
関連利用技術:
- timm(PyTorch Image Models): 学習済みモデル提供
- OpenCV: 動画・カメラ入力とリアルタイム表示
- PIL/Pillow: 画像前処理と日本語フォント描画
- tkinter: ファイル選択UI
入力と出力: 入力: 動画(ユーザは「0:動画ファイル,1:カメラ,2:サンプル動画」のメニューで選択.0:動画ファイルの場合はtkinterでファイル選択.1の場合はOpenCVでカメラが開く.2の場合はhttps://raw.githubusercontent.com/opencv/opencv/master/samples/data/vtest.aviを使用)、出力: OpenCV画面でリアルタイム表示、各フレームごとにprint()による分類結果表示、プログラム終了時result.txtファイル保存
処理手順: 1.動画入力の取得・前処理(RGB変換、timm標準変換)→2.MambaOutモデルによる推論実行→3.Top-5分類結果の算出・日本語表示→4.リアルタイム画面描画・結果保存
前処理、後処理: 前処理:timm標準データ変換(正規化、リサイズ)によるImageNet互換形式変換、後処理:ソフトマックス確率変換、Top-k選択、日本語フォント描画
調整を必要とする設定値: MODEL_NAME(学習済みモデル選択)、TOP_K(表示する上位分類結果数、デフォルト5)、FONT_SIZE(表示サイズ)
将来方策: プログラム内でのモデル性能比較機能(複数MambaOutモデルの精度・速度測定)
その他の重要事項: Windows環境対応、DirectShowバックエンド使用(Windows環境時)、ImageNet-1000クラス全て分類可能
前準備:
pip install timm opencv-python pillow
"""
import cv2
import numpy as np
import torch
import timm
import torch.nn.functional as F
import tkinter as tk
from tkinter import filedialog
from PIL import Image, ImageDraw, ImageFont
import urllib.request
import time
import sys
import io
from datetime import datetime
import threading
# Windows文字エンコーディング設定
sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='utf-8', line_buffering=True)
# GPU/CPU自動選択
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f'デバイス: {str(device)}')
# GPU使用時の最適化
if device.type == 'cuda':
torch.backends.cudnn.benchmark = True
# モデル情報の構造化
MODEL_INFO = {
'mambaout_tiny.in1k': {
'name': 'MambaOut Tiny',
'params': '26.5M',
'top1_acc': '82.7%',
'desc': '軽量・高速'
},
'mambaout_small.in1k': {
'name': 'MambaOut Small',
'params': '48.5M',
'top1_acc': '84.1%',
'desc': 'バランス型'
},
'mambaout_base.in1k': {
'name': 'MambaOut Base',
'params': '84.8M',
'top1_acc': '85.0%',
'desc': 'デフォルト推奨モデル'
},
'mambaout_kobe.in1k': {
'name': 'MambaOut Kobe',
'params': '9.1M',
'top1_acc': '80.0%',
'desc': '軽量高性能'
}
}
# 調整可能な設定値
MODEL_NAME = 'mambaout_base.in1k' # MambaOutモデル選択
TOP_K = 5 # 表示する上位分類結果数
FONT_PATH = 'C:/Windows/Fonts/meiryo.ttc' # 日本語フォントパス
FONT_SIZE = 18 # フォントサイズ
WINDOW_NAME = "ImageNet 1000-Class Classification" # OpenCVウィンドウ名
# ImageNet クラス名リスト
IMAGENET_CLASSES = [
'tench', 'goldfish', 'great white shark', 'tiger shark', 'hammerhead', 'electric ray', 'stingray', 'cock', 'hen', 'ostrich',
'brambling', 'goldfinch', 'house finch', 'junco', 'indigo bunting', 'robin', 'bulbul', 'jay', 'magpie', 'chickadee',
'water ouzel', 'kite', 'bald eagle', 'vulture', 'great grey owl', 'European fire salamander', 'common newt', 'eft', 'spotted salamander', 'axolotl',
'bullfrog', 'tree frog', 'tailed frog', 'loggerhead', 'leatherback turtle', 'mud turtle', 'terrapin', 'box turtle', 'banded gecko', 'common iguana',
'American chameleon', 'whiptail', 'agama', 'frilled lizard', 'alligator lizard', 'Gila monster', 'green lizard', 'African chameleon', 'Komodo dragon', 'African crocodile',
'American alligator', 'triceratops', 'thunder snake', 'ringneck snake', 'hognose snake', 'green snake', 'king snake', 'garter snake', 'water snake', 'vine snake',
'night snake', 'boa constrictor', 'rock python', 'Indian cobra', 'green mamba', 'sea snake', 'horned viper', 'diamondback', 'sidewinder', 'trilobite',
'harvestman', 'scorpion', 'black and gold garden spider', 'barn spider', 'garden spider', 'black widow', 'tarantula', 'wolf spider', 'tick', 'centipede',
'black grouse', 'ptarmigan', 'ruffed grouse', 'prairie chicken', 'peacock', 'quail', 'partridge', 'African grey', 'macaw', 'sulphur-crested cockatoo',
'lorikeet', 'coucal', 'bee eater', 'hornbill', 'hummingbird', 'jacamar', 'toucan', 'drake', 'red-breasted merganser', 'goose',
'black swan', 'tusker', 'echidna', 'platypus', 'wallaby', 'koala', 'wombat', 'jellyfish', 'sea anemone', 'brain coral',
'flatworm', 'nematode', 'conch', 'snail', 'slug', 'sea slug', 'chiton', 'chambered nautilus', 'Dungeness crab', 'rock crab',
'fiddler crab', 'king crab', 'American lobster', 'spiny lobster', 'crayfish', 'hermit crab', 'isopod', 'white stork', 'black stork', 'spoonbill',
'flamingo', 'little blue heron', 'American egret', 'bittern', 'crane', 'limpkin', 'European gallinule', 'American coot', 'bustard', 'ruddy turnstone',
'red-backed sandpiper', 'redshank', 'dowitcher', 'oystercatcher', 'pelican', 'king penguin', 'albatross', 'grey whale', 'killer whale', 'dugong',
'sea lion', 'Chihuahua', 'Japanese spaniel', 'Maltese dog', 'Pekinese', 'Shih-Tzu', 'Blenheim spaniel', 'papillon', 'toy terrier', 'Rhodesian ridgeback',
'Afghan hound', 'basset', 'beagle', 'bloodhound', 'bluetick', 'black-and-tan coonhound', 'Walker hound', 'English foxhound', 'redbone', 'borzoi',
'Irish wolfhound', 'Italian greyhound', 'whippet', 'Ibizan hound', 'Norwegian elkhound', 'otterhound', 'Saluki', 'Scottish deerhound', 'Weimaraner', 'Staffordshire bullterrier',
'American Staffordshire terrier', 'Bedlington terrier', 'Border terrier', 'Kerry blue terrier', 'Irish terrier', 'Norfolk terrier', 'Norwich terrier', 'Yorkshire terrier', 'wire-haired fox terrier', 'Lakeland terrier',
'Sealyham terrier', 'Airedale', 'cairn', 'Australian terrier', 'Dandie Dinmont', 'Boston bull', 'miniature schnauzer', 'giant schnauzer', 'standard schnauzer', 'Scotch terrier',
'Tibetan terrier', 'silky terrier', 'soft-coated wheaten terrier', 'West Highland white terrier', 'Lhasa', 'flat-coated retriever', 'curly-coated retriever', 'golden retriever', 'Labrador retriever', 'Chesapeake Bay retriever',
'German short-haired pointer', 'vizsla', 'English setter', 'Irish setter', 'Gordon setter', 'Brittany spaniel', 'clumber', 'English springer', 'Welsh springer spaniel', 'cocker spaniel',
'Sussex spaniel', 'Irish water spaniel', 'kuvasz', 'schipperke', 'groenendael', 'malinois', 'briard', 'kelpie', 'komondor', 'Old English sheepdog',
'Shetland sheepdog', 'collie', 'Border collie', 'Bouvier des Flandres', 'Rottweiler', 'German shepherd', 'Doberman', 'miniature pinscher', 'Greater Swiss Mountain dog', 'Bernese mountain dog',
'Appenzeller', 'EntleBucher', 'boxer', 'bull mastiff', 'Tibetan mastiff', 'French bulldog', 'Great Dane', 'Saint Bernard', 'Eskimo dog', 'malamute',
'Siberian husky', 'dalmatian', 'affenpinscher', 'basenji', 'pug', 'Leonberg', 'Newfoundland', 'Great Pyrenees', 'Samoyed', 'Pomeranian',
'chow', 'keeshond', 'Brabancon griffon', 'Pembroke', 'Cardigan', 'toy poodle', 'miniature poodle', 'standard poodle', 'Mexican hairless', 'timber wolf',
'white wolf', 'red wolf', 'coyote', 'dingo', 'dhole', 'African hunting dog', 'hyena', 'red fox', 'kit fox', 'Arctic fox',
'grey fox', 'tabby', 'tiger cat', 'Persian cat', 'Siamese cat', 'Egyptian cat', 'cougar', 'lynx', 'leopard', 'snow leopard',
'jaguar', 'lion', 'tiger', 'cheetah', 'brown bear', 'American black bear', 'ice bear', 'sloth bear', 'mongoose', 'meerkat',
'tiger beetle', 'ladybug', 'ground beetle', 'long-horned beetle', 'leaf beetle', 'dung beetle', 'rhinoceros beetle', 'weevil', 'fly', 'bee',
'ant', 'grasshopper', 'cricket', 'walking stick', 'cockroach', 'mantis', 'cicada', 'leafhopper', 'lacewing', 'dragonfly',
'damselfly', 'admiral', 'ringlet', 'monarch', 'cabbage butterfly', 'sulphur butterfly', 'lycaenid', 'starfish', 'sea urchin', 'sea cucumber',
'wood rabbit', 'hare', 'Angora', 'hamster', 'porcupine', 'fox squirrel', 'marmot', 'beaver', 'guinea pig', 'sorrel',
'zebra', 'hog', 'wild boar', 'warthog', 'hippopotamus', 'ox', 'water buffalo', 'bison', 'ram', 'bighorn',
'ibex', 'hartebeest', 'impala', 'gazelle', 'Arabian camel', 'llama', 'weasel', 'mink', 'polecat', 'black-footed ferret',
'otter', 'skunk', 'badger', 'armadillo', 'three-toed sloth', 'orangutan', 'gorilla', 'chimpanzee', 'gibbon', 'siamang',
'guenon', 'patas', 'baboon', 'macaque', 'langur', 'colobus', 'proboscis monkey', 'marmoset', 'capuchin', 'howler monkey',
'titi', 'spider monkey', 'squirrel monkey', 'Madagascar cat', 'indri', 'Indian elephant', 'African elephant', 'lesser panda', 'giant panda', 'barracouta',
'eel', 'coho', 'rock beauty', 'anemone fish', 'sturgeon', 'gar', 'lionfish', 'puffer', 'abacus', 'abaya',
'academic gown', 'accordion', 'acoustic guitar', 'aircraft carrier', 'airliner', 'airship', 'altar', 'ambulance', 'amphibian', 'analog clock',
'apiary', 'apron', 'ashcan', 'assault rifle', 'backpack', 'bakery', 'balance beam', 'balloon', 'ballpoint', 'Band Aid',
'banjo', 'bannister', 'barbell', 'barber chair', 'barbershop', 'barn', 'barometer', 'barrel', 'barrow', 'baseball',
'basketball', 'bassinet', 'bassoon', 'bathing cap', 'bath towel', 'bathtub', 'beach wagon', 'beacon', 'beaker', 'bearskin',
'beer bottle', 'beer glass', 'bell cote', 'bib', 'bicycle-built-for-two', 'bikini', 'binder', 'binoculars', 'birdhouse', 'boathouse',
'bobsled', 'bolo tie', 'bonnet', 'bookcase', 'bookshop', 'bottlecap', 'bow', 'bow tie', 'brass', 'brassiere',
'breakwater', 'breastplate', 'broom', 'bucket', 'buckle', 'bulletproof vest', 'bullet train', 'butcher shop', 'cab', 'caldron',
'candle', 'cannon', 'canoe', 'can opener', 'cardigan', 'car mirror', 'carousel', 'carpenter\'s kit', 'carton', 'car wheel',
'cash machine', 'cassette', 'cassette player', 'castle', 'catamaran', 'CD player', 'cello', 'cellular telephone', 'chain', 'chainlink fence',
'chain mail', 'chain saw', 'chest', 'chiffonier', 'chime', 'china cabinet', 'Christmas stocking', 'church', 'cinema', 'cleaver',
'cliff dwelling', 'cloak', 'clog', 'cocktail shaker', 'coffee mug', 'coffeepot', 'coil', 'combination lock', 'computer keyboard', 'confectionery',
'container ship', 'convertible', 'corkscrew', 'cornet', 'cowboy boot', 'cowboy hat', 'cradle', 'crane', 'crash helmet', 'crate',
'crib', 'Crock Pot', 'croquet ball', 'crutch', 'cuirass', 'dam', 'desk', 'desktop computer', 'dial telephone', 'diaper',
'digital clock', 'digital watch', 'dining table', 'dishrag', 'dishwasher', 'disk brake', 'dock', 'dogsled', 'dome', 'doormat',
'drilling platform', 'drum', 'drumstick', 'dumbbell', 'Dutch oven', 'electric fan', 'electric guitar', 'electric locomotive', 'entertainment center', 'envelope',
'espresso maker', 'face powder', 'feather boa', 'file', 'fireboat', 'fire engine', 'fire screen', 'flagpole', 'flute', 'folding chair',
'football helmet', 'forklift', 'fountain', 'fountain pen', 'four-poster', 'freight car', 'French horn', 'frying pan', 'fur coat', 'garbage truck',
'gasmask', 'gas pump', 'goblet', 'go-kart', 'golf ball', 'golfcart', 'gondola', 'gong', 'gown', 'grand piano',
'greenhouse', 'grille', 'grocery store', 'guillotine', 'hair slide', 'hair spray', 'half track', 'hammer', 'hamper', 'hand blower',
'hand-held computer', 'handkerchief', 'hard disc', 'harmonica', 'harp', 'harvester', 'hatchet', 'holster', 'home theater', 'honeycomb',
'hook', 'hoopskirt', 'horizontal bar', 'horse cart', 'hourglass', 'iPod', 'iron', 'jack-o\'-lantern', 'jean', 'jeep',
'jersey', 'jigsaw puzzle', 'jinrikisha', 'joystick', 'kimono', 'knee pad', 'knot', 'lab coat', 'ladle', 'lampshade',
'laptop', 'lawn mower', 'lens cap', 'letter opener', 'library', 'lifeboat', 'lighter', 'limousine', 'liner', 'lipstick',
'Loafer', 'lotion', 'loudspeaker', 'loupe', 'lumbermill', 'magnetic compass', 'mailbag', 'mailbox', 'maillot', 'maillot (tank suit)',
'manhole cover', 'maraca', 'marimba', 'mask', 'matchstick', 'maypole', 'maze', 'measuring cup', 'medicine chest', 'megalith',
'microphone', 'microwave', 'military uniform', 'milk can', 'minibus', 'miniskirt', 'minivan', 'missile', 'mitten', 'mixing bowl',
'mobile home', 'Model T', 'modem', 'monastery', 'monitor', 'moped', 'mortar', 'mortarboard', 'mosque', 'mosquito net',
'motor scooter', 'mountain bike', 'mountain tent', 'mouse', 'mousetrap', 'moving van', 'muzzle', 'nail', 'neck brace', 'necklace',
'nipple', 'notebook', 'obelisk', 'oboe', 'ocarina', 'odometer', 'oil filter', 'organ', 'oscilloscope', 'overskirt',
'oxcart', 'oxygen mask', 'packet', 'paddle', 'paddlewheel', 'padlock', 'paintbrush', 'pajama', 'palace', 'panpipe',
'paper towel', 'parachute', 'parallel bars', 'park bench', 'parking meter', 'passenger car', 'patio', 'pay-phone', 'pedestal', 'pencil box',
'pencil sharpener', 'perfume', 'Petri dish', 'photocopier', 'pick', 'pickelhaube', 'picket fence', 'pickup', 'pier', 'piggy bank',
'pill bottle', 'pillow', 'ping-pong ball', 'pinwheel', 'pirate', 'pitcher', 'plane', 'planetarium', 'plastic bag', 'plate rack',
'plow', 'plunger', 'Polaroid camera', 'pole', 'police van', 'poncho', 'pool table', 'pop bottle', 'pot', 'potter\'s wheel',
'power drill', 'prayer rug', 'printer', 'prison', 'projectile', 'projector', 'puck', 'punching bag', 'purse', 'quill',
'quilt', 'racer', 'racket', 'radiator', 'radio', 'radio telescope', 'rain barrel', 'recreational vehicle', 'reel', 'reflex camera',
'refrigerator', 'remote control', 'restaurant', 'revolver', 'rifle', 'rocking chair', 'rotisserie', 'rubber eraser', 'rugby ball', 'rule',
'running shoe', 'safe', 'safety pin', 'saltshaker', 'sandal', 'sarong', 'sax', 'scabbard', 'scale', 'school bus',
'schooner', 'scoreboard', 'screen', 'screw', 'screwdriver', 'seat belt', 'sewing machine', 'shield', 'shoe shop', 'shoji',
'shopping basket', 'shopping cart', 'shovel', 'shower cap', 'shower curtain', 'ski', 'ski mask', 'sleeping bag', 'slide rule', 'sliding door',
'slot', 'snorkel', 'snowmobile', 'snowplow', 'soap dispenser', 'soccer ball', 'sock', 'solar dish', 'sombrero', 'soup bowl',
'space bar', 'space heater', 'space shuttle', 'spatula', 'speedboat', 'spider web', 'spindle', 'sports car', 'spotlight', 'stage',
'steam locomotive', 'steel arch bridge', 'steel drum', 'stethoscope', 'stole', 'stone wall', 'stopwatch', 'stove', 'strainer', 'streetcar',
'stretcher', 'studio couch', 'stupa', 'submarine', 'suit', 'sundial', 'sunglass', 'sunglasses', 'sunscreen', 'suspension bridge',
'swab', 'sweatshirt', 'swimming trunks', 'swing', 'switch', 'syringe', 'table lamp', 'tank', 'tape player', 'teapot',
'teddy', 'television', 'tennis ball', 'thatch', 'theater curtain', 'thimble', 'thresher', 'throne', 'tile roof', 'toaster',
'tobacco shop', 'toilet seat', 'torch', 'totem pole', 'tow truck', 'toyshop', 'tractor', 'trailer truck', 'tray', 'trench coat',
'tricycle', 'trimaran', 'tripod', 'triumphal arch', 'trolleybus', 'trombone', 'tub', 'turnstile', 'typewriter keyboard', 'umbrella',
'unicycle', 'upright', 'vacuum', 'vase', 'vault', 'velvet', 'vending machine', 'vestment', 'viaduct', 'violin',
'volleyball', 'waffle iron', 'wall clock', 'wallet', 'wardrobe', 'warplane', 'washbasin', 'washer', 'water bottle', 'water jug',
'water tower', 'whiskey jug', 'whistle', 'wig', 'window screen', 'window shade', 'Windsor tie', 'wine bottle', 'wing', 'wok',
'wooden spoon', 'wool', 'worm fence', 'wreck', 'yawl', 'yurt', 'web site', 'comic book', 'crossword puzzle', 'street sign',
'traffic light', 'book jacket', 'menu', 'plate', 'guacamole', 'consomme', 'hot pot', 'trifle', 'ice cream', 'ice lolly',
'French loaf', 'bagel', 'pretzel', 'cheeseburger', 'hotdog', 'mashed potato', 'head cabbage', 'broccoli', 'cauliflower', 'zucchini',
'spaghetti squash', 'acorn squash', 'butternut squash', 'cucumber', 'artichoke', 'bell pepper', 'cardoon', 'mushroom', 'Granny Smith', 'strawberry',
'orange', 'lemon', 'fig', 'pineapple', 'banana', 'jackfruit', 'custard apple', 'pomegranate', 'hay', 'carbonara',
'chocolate sauce', 'dough', 'meat loaf', 'pizza', 'potpie', 'burrito', 'red wine', 'espresso', 'cup', 'eggnog',
'alp', 'bubble', 'cliff', 'coral reef', 'geyser', 'lakeside', 'promontory', 'sandbar', 'seashore', 'valley',
'volcano', 'ballplayer', 'groom', 'scuba diver', 'rapeseed', 'daisy', 'yellow lady\'s slipper', 'corn', 'acorn', 'hip',
'buckeye', 'coral fungus', 'agaric', 'gyromitra', 'stinkhorn', 'earthstar', 'hen-of-the-woods', 'bolete', 'ear', 'toilet tissue'
]
# BGR→RGB色変換のヘルパー関数
def bgr_to_rgb(color_bgr):
"""BGRカラーをRGBカラーに変換"""
return (color_bgr[2], color_bgr[1], color_bgr[0])
# クラスごとの色生成(HSVからBGRに変換)
def generate_class_colors(num_classes):
colors = []
for i in range(num_classes):
hue = int(180.0 * i / num_classes)
hsv = np.uint8([[[hue, 255, 255]]])
bgr = cv2.cvtColor(hsv, cv2.COLOR_HSV2BGR)[0][0]
colors.append((int(bgr[0]), int(bgr[1]), int(bgr[2])))
return colors
# 1000クラス分の色を生成
CLASS_COLORS = generate_class_colors(1000)
# 日本語フォント設定
font_main = ImageFont.truetype(FONT_PATH, FONT_SIZE)
# グローバル変数
frame_count = 0
results_log = []
class_counts = {}
model = None
transforms = None
class ThreadedVideoCapture:
"""スレッド化されたVideoCapture(常に最新フレームを取得)"""
def __init__(self, src, is_camera=False):
if is_camera:
self.cap = cv2.VideoCapture(src, cv2.CAP_DSHOW)
fourcc = cv2.VideoWriter_fourcc('M', 'J', 'P', 'G')
self.cap.set(cv2.CAP_PROP_FOURCC, fourcc)
self.cap.set(cv2.CAP_PROP_FPS, 60)
else:
self.cap = cv2.VideoCapture(src)
self.grabbed, self.frame = self.cap.read()
self.stopped = False
self.lock = threading.Lock()
self.thread = threading.Thread(target=self.update, args=())
self.thread.daemon = True
self.thread.start()
def update(self):
"""バックグラウンドでフレームを取得し続ける"""
while not self.stopped:
grabbed, frame = self.cap.read()
with self.lock:
self.grabbed = grabbed
if grabbed:
self.frame = frame
def read(self):
"""最新フレームを返す"""
with self.lock:
return self.grabbed, self.frame.copy() if self.grabbed else None
def isOpened(self):
return self.cap.isOpened()
def get(self, prop):
return self.cap.get(prop)
def release(self):
self.stopped = True
self.thread.join()
self.cap.release()
def display_program_header():
print('=' * 60)
print('=== MambaOut画像分類プログラム ===')
print('=' * 60)
print('概要: ImageNet 1000クラス分類をリアルタイムで実行')
print('機能: MambaOutによる画像分類(ImageNet 1000クラス)')
print('技術: Gated CNNブロック、深さ方向畳み込み、トークンミキシング')
print('操作: qキーで終了')
print('出力: 各フレームごとに処理結果を表示し、終了時にresult.txtへ保存')
print()
def get_confidence_color(prob):
"""確信度に応じた色を返す"""
if prob >= 0.7:
return (0, 255, 0) # 緑
elif prob >= 0.5:
return (0, 255, 255) # 黄
elif prob >= 0.3:
return (0, 165, 255) # オレンジ
else:
return (0, 0, 255) # 赤
def draw_classification_results(frame, classifications):
"""画像分類の描画処理"""
texts_to_draw = []
# ヘッダー表示
texts_to_draw.append({
'text': f'画像分類結果 (上位{TOP_K}位):',
'org': (10, 30),
'color': (255, 255, 255),
'font_type': 'main'
})
# 分類結果表示
for i, cls in enumerate(classifications):
color = get_confidence_color(cls['conf'])
result_text = f'{i+1}位: {cls["name"]} ({cls["conf"]:.3f})'
texts_to_draw.append({
'text': result_text,
'org': (10, 60 + i * 25),
'color': bgr_to_rgb(color),
'font_type': 'main'
})
frame = draw_texts_with_pillow(frame, texts_to_draw)
# 統計情報を描画
info_text = f"Classes: {len(classifications)} | Frame: {frame_count}"
cv2.putText(frame, info_text, (10, frame.shape[0] - 20),
cv2.FONT_HERSHEY_SIMPLEX, 0.6, (255, 255, 255), 2)
return frame
def format_classification_output(classifications):
"""画像分類の出力フォーマット"""
if len(classifications) == 0:
return 'count=0'
else:
parts = []
for cls in classifications:
class_name = cls['name']
conf = cls['conf']
parts.append(f'class={class_name},conf={conf:.3f}')
return f'count={len(classifications)}; ' + ' | '.join(parts)
def draw_texts_with_pillow(bgr_frame, texts):
"""テキスト描画, texts: list of dict with keys {text, org, color, font_type}"""
img_pil = Image.fromarray(cv2.cvtColor(bgr_frame, cv2.COLOR_BGR2RGB))
draw = ImageDraw.Draw(img_pil)
for item in texts:
text = item['text']
x, y = item['org']
color = item['color'] # RGB
draw.text((x, y), text, font=font_main, fill=color)
return cv2.cvtColor(np.array(img_pil), cv2.COLOR_RGB2BGR)
def classify_image(frame):
"""共通の分類処理(前処理、推論、分類を実行)"""
global model, transforms
# 推論実行
pil_image = Image.fromarray(cv2.cvtColor(frame, cv2.COLOR_BGR2RGB))
input_tensor = transforms(pil_image).unsqueeze(0).to(device)
with torch.no_grad():
outputs = model(input_tensor)
probabilities = F.softmax(outputs, dim=1)
topk_prob, topk_indices = torch.topk(probabilities, TOP_K)
topk_prob = topk_prob.cpu().numpy()[0]
topk_indices = topk_indices.cpu().numpy()[0]
curr_classifications = []
for i, (class_index, confidence) in enumerate(zip(topk_indices, topk_prob)):
if class_index < len(IMAGENET_CLASSES):
name = IMAGENET_CLASSES[class_index]
curr_classifications.append({
'conf': confidence,
'class': class_index,
'name': name
})
return curr_classifications
def process_video_frame(frame, timestamp_ms, is_camera):
"""動画用ラッパー"""
# 共通の分類処理
classifications = classify_image(frame)
# クラスごとの分類数を更新
global class_counts
for cls in classifications:
name = cls['name']
if name not in class_counts:
class_counts[name] = 0
class_counts[name] += 1
# 画像分類固有の描画処理
frame = draw_classification_results(frame, classifications)
# 画像分類固有の出力フォーマット
result = format_classification_output(classifications)
return frame, result
def video_frame_processing(frame, timestamp_ms, is_camera):
"""動画フレーム処理(標準形式)"""
global frame_count
current_time = time.time()
frame_count += 1
processed_frame, result = process_video_frame(frame, timestamp_ms, is_camera)
return processed_frame, result, current_time
# プログラムヘッダー表示
display_program_header()
# モデル選択(対話的実装)
print("\n=== MambaOutモデル選択 ===")
print('使用するMambaOutモデルを選択してください:')
model_list = list(MODEL_INFO.keys())
for i, key in enumerate(model_list, 1):
info = MODEL_INFO[key]
print(f'{i}: {info["name"]} ({info["params"]} params, Top-1 {info["top1_acc"]}) - {info["desc"]}')
print()
model_choice = ''
while model_choice not in ['1', '2', '3', '4']:
model_choice = input("選択 (1/2/3/4) [デフォルト: 3]: ").strip()
if model_choice == '':
model_choice = '3'
break
if model_choice not in ['1', '2', '3', '4']:
print("無効な選択です。もう一度入力してください。")
# モデル名の決定
selected_model = model_list[int(model_choice) - 1]
# モデルの初期化
print(f"\nMambaOutモデルをロード中...")
try:
model = timm.create_model(selected_model, pretrained=True)
model = model.to(device)
model.eval()
# timm標準のデータ変換設定
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
# 分類可能な1000クラスを表示
print(f"\n分類可能なクラス数: {len(IMAGENET_CLASSES)}")
print(f"モデル情報: {MODEL_INFO[selected_model]['name']} ({MODEL_INFO[selected_model]['params']} params, Top-1 {MODEL_INFO[selected_model]['top1_acc']})")
print("モデルのロード完了")
except Exception as e:
print(f"モデルのロードに失敗しました: {e}")
raise SystemExit(1)
# 入力選択
print("\n=== MambaOutリアルタイム画像分類(ImageNet 1000クラス) ===")
print("0: 動画ファイル")
print("1: カメラ")
print("2: サンプル動画")
choice = input("選択: ")
is_camera = (choice == '1')
if choice == '0':
root = tk.Tk()
root.withdraw()
path = filedialog.askopenfilename()
if not path:
raise SystemExit(1)
cap = cv2.VideoCapture(path)
elif choice == '1':
cap = ThreadedVideoCapture(0, is_camera=True)
else:
print("サンプル動画をダウンロード中...")
SAMPLE_URL = 'https://raw.githubusercontent.com/opencv/opencv/master/samples/data/vtest.avi'
SAMPLE_FILE = 'vtest.avi'
urllib.request.urlretrieve(SAMPLE_URL, SAMPLE_FILE)
cap = cv2.VideoCapture(SAMPLE_FILE)
if not cap.isOpened():
print('動画ファイル・カメラを開けませんでした')
raise SystemExit(1)
# フレームレートの取得とタイムスタンプ増分の計算
if is_camera:
actual_fps = cap.get(cv2.CAP_PROP_FPS)
print(f'カメラのfps: {actual_fps}')
timestamp_increment = int(1000 / actual_fps) if actual_fps > 0 else 33
else:
video_fps = cap.get(cv2.CAP_PROP_FPS)
timestamp_increment = int(1000 / video_fps) if video_fps > 0 else 33
# メイン処理
print('\n=== 動画処理開始 ===')
print('操作方法:')
print(' q キー: プログラム終了')
frame_count = 0
results_log = []
start_time = time.time()
last_info_time = start_time
info_interval = 10.0
timestamp_ms = 0
total_processing_time = 0.0
try:
while True:
ret, frame = cap.read()
if not ret:
break
timestamp_ms += timestamp_increment
processing_start = time.time()
processed_frame, result, current_time = video_frame_processing(frame, timestamp_ms, is_camera)
processing_time = time.time() - processing_start
total_processing_time += processing_time
cv2.imshow(WINDOW_NAME, processed_frame)
if result:
if is_camera:
timestamp = datetime.fromtimestamp(current_time).strftime("%Y-%m-%d %H:%M:%S.%f")[:-3]
print(f'{timestamp}, {result}')
else:
print(f'Frame {frame_count}: {result}')
results_log.append(result)
# 情報提供(カメラモードのみ、info_interval秒ごと)
if is_camera:
elapsed = current_time - last_info_time
if elapsed >= info_interval:
total_elapsed = current_time - start_time
actual_fps = frame_count / total_elapsed if total_elapsed > 0 else 0
avg_processing_time = (total_processing_time / frame_count * 1000) if frame_count > 0 else 0
print(f'[情報] 経過時間: {total_elapsed:.1f}秒, 処理フレーム数: {frame_count}, 実測fps: {actual_fps:.1f}, 平均処理時間: {avg_processing_time:.1f}ms')
last_info_time = current_time
if cv2.waitKey(1) & 0xFF == ord('q'):
break
finally:
print('\n=== プログラム終了 ===')
cap.release()
cv2.destroyAllWindows()
if results_log:
with open('result.txt', 'w', encoding='utf-8') as f:
f.write('=== MambaOut画像分類結果 ===\n')
f.write(f'処理フレーム数: {frame_count}\n')
f.write(f'使用モデル: {selected_model}\n')
f.write(f'モデル情報: {MODEL_INFO[selected_model]["name"]} ({MODEL_INFO[selected_model]["params"]} params, Top-1 {MODEL_INFO[selected_model]["top1_acc"]})\n')
f.write(f'使用デバイス: {str(device).upper()}\n')
if device.type == 'cuda':
f.write(f'GPU: {torch.cuda.get_device_name(0)}\n')
if is_camera:
f.write('形式: タイムスタンプ, 分類結果\n')
else:
f.write('形式: フレーム番号, 分類結果\n')
f.write(f'\n分類されたクラス一覧:\n')
for class_name, count in sorted(class_counts.items()):
f.write(f' {class_name}: {count}回\n')
f.write('\n')
f.write('\n'.join(results_log))
print(f'\n処理結果をresult.txtに保存しました')
print(f'分類されたクラス数: {len(class_counts)}')
実験・探求のアイデア
AIモデル選択の実験:
convnext_tiny(28.6M)からconvnext_small(50.2M)への変更による分類精度比較
実験要素:
- 異なるモデルサイズでの分類精度比較
体験・実験・探求のアイデア:
- 同じ物体を異なる角度から撮影し、分類結果の安定性を確認
- 複数の物体を同時に画面に映し、どの物体が認識されるかを観察
- 照明条件を変更して分類精度への影響を検証
- MambaOutアーキテクチャの階層構造が、どのような物体認識に効果的かを探求