日本語対応のLLM,チャットボット(ELYZA-japanese-Llama-2-7b,transformer,Python,PyTorch を使用)(Windows 上)
前準備
Build Tools for Visual Studio 2026(ビルドツール)のインストール
Build Tools for Visual Studio 2026(ビルドツール)のインストールを行い、C/C++ コードのビルド環境を整える。
Build Tools for Visual Studio は,Visual Studio の IDE を含まない C/C++ コンパイラ,ライブラリ,ビルドツール等のコマンドライン向け開発ツールセットである。インストール済みの場合,この手順は不要である。 以下のコマンドは、Build Tools が未インストールの場合は winget で新規インストールし、インストール済みの場合は 【インストールコマンドの実行方法】 管理者権限でコマンドプロンプトを起動する(手順:Windows キーまたはスタートメニュー → 上記のコマンドでは、Build Tools 本体と Visual C++ 再頒布可能パッケージをインストールし、続いて以下のコンポーネントを追加している。 上記以外の追加のコンポーネントが必要になった場合は Visual Studio Installer で個別にインストールできる。 インストール完了の確認 Visual Studio を必要とするとき Visual Studio の機能を必要とする場合は,追加インストールできる。 以下のいずれかの方法で Python 3.7 をインストールする。Python がインストール済みの場合、この手順は不要である。 方法1:winget によるインストール 管理者権限のコマンドプロンプトで以下を実行する。管理者権限のコマンドプロンプトを起動するには、Windows キーまたはスタートメニューから「 方法2:インストーラーによるインストール インストールの確認 コマンドプロンプトで以下を実行する。 バージョン番号(例:[Build Tools for Visual Studio 2026(ビルドツール)のインストール手順を見るには、ここをクリック]
Windows での Build Tools for Visual Studio 2026 のインストール
setup.exe modify でコンポーネントを追加する(バージョンは変更しない)。cmd と入力 → 右クリック → 「管理者として実行」)。そして、コマンド全体をコマンドプロンプトにコピー&ペーストする。REM VC++ ランタイム
winget install --scope machine --id Microsoft.VCRedist.2015+.x64 -e --silent --disable-interactivity --force --accept-source-agreements --accept-package-agreements --override "/quiet /norestart"
REM ============================================================
REM Visual Studio Build Tools + Desktop development with C++
REM (VCTools、MSBuildTools、CMake連携、Clang、Windows 11 SDK)
REM ============================================================
REM 進行中のインストーラーを停止(ロック競合回避)
taskkill /F /IM vs_setup.exe /T >nul 2>&1
taskkill /F /IM vs_installer.exe /T >nul 2>&1
taskkill /F /IM vs_installerservice.exe /T >nul 2>&1
REM 未インストール時: winget で新規インストール
REM インストール済み時: setup.exe modify でコンポーネント追加(バージョンは変更しない)
winget list --id Microsoft.VisualStudio.BuildTools 2>nul | findstr /i "BuildTools" >nul 2>&1
if %ERRORLEVEL% EQU 0 (
for /f "usebackq delims=" %P in (`"C:\Program Files (x86)\Microsoft Visual Studio\Installer\vswhere.exe" -products Microsoft.VisualStudio.Product.BuildTools -property installationPath`) do start /wait "" "C:\Program Files (x86)\Microsoft Visual Studio\Installer\setup.exe" modify --installPath "%P" --add Microsoft.VisualStudio.Workload.VCTools --add Microsoft.VisualStudio.Workload.MSBuildTools --add Microsoft.VisualStudio.Component.VC.CMake.Project --add Microsoft.VisualStudio.Component.VC.Llvm.Clang --add Microsoft.VisualStudio.Component.VC.Llvm.ClangToolset --add Microsoft.VisualStudio.Component.Windows11SDK.26100 --includeRecommended --quiet --norestart --nocache
) else (
winget install --scope machine --id Microsoft.VisualStudio.BuildTools -e --silent --disable-interactivity --force --accept-source-agreements --accept-package-agreements --override "--quiet --wait --norestart --nocache --add Microsoft.VisualStudio.Workload.VCTools --includeRecommended --add Microsoft.VisualStudio.Workload.MSBuildTools --add Microsoft.VisualStudio.Component.VC.CMake.Project --add Microsoft.VisualStudio.Component.VC.Llvm.Clang --add Microsoft.VisualStudio.Component.VC.Llvm.ClangToolset --add Microsoft.VisualStudio.Component.Windows11SDK.26100"
)
REM 破損時の修復(任意、動作がおかしくなった場合)
REM "C:\Program Files (x86)\Microsoft Visual Studio\Installer\setup.exe" repair --installPath "C:\Program Files (x86)\Microsoft Visual Studio\18\BuildTools" --quiet --norestart
REM 導入確認(インストールパスが表示されれば正常)
"C:\Program Files (x86)\Microsoft Visual Studio\Installer\vswhere.exe" -products * -requires Microsoft.VisualStudio.Workload.VCTools -property installationPath
--includeRecommended により、MSVC コンパイラ、C++ AddressSanitizer、vcpkg、CMake ツール、Windows 11 SDK 等の推奨コンポーネントが含まれる)winget list Microsoft.VisualStudio.BuildToolsPython 3.7 のインストール(Windows 上) [クリックして展開]
cmd」と入力し、表示された「コマンドプロンプト」を右クリックして「管理者として実行」を選択する。winget install -e --id Python.Python.3.7 --scope machine --silent --accept-source-agreements --accept-package-agreements --override "/quiet InstallAllUsers=1 PrependPath=1 AssociateFiles=1 InstallLauncherAllUsers=1"--scope machine を指定することで、システム全体(全ユーザー向け)にインストールされる。このオプションの実行には管理者権限が必要である。インストール完了後、コマンドプロンプトを再起動すると PATH が自動的に設定される。
python コマンドを実行できない。python --versionPython 3.7.x)が表示されればインストール成功である。「'python' は、内部コマンドまたは外部コマンドとして認識されていません。」と表示される場合は、インストールが正常に完了していない。
Build Tools for Visual Studio 2026(ビルドツール)のインストール
Build Tools for Visual Studio 2026(ビルドツール)のインストールを行い、C/C++ コードのビルド環境を整える。
Build Tools for Visual Studio は,Visual Studio の IDE を含まない C/C++ コンパイラ,ライブラリ,ビルドツール等のコマンドライン向け開発ツールセットである。インストール済みの場合,この手順は不要である。 以下のコマンドは、Build Tools が未インストールの場合は winget で新規インストールし、インストール済みの場合は 【インストールコマンドの実行方法】 管理者権限でコマンドプロンプトを起動する(手順:Windows キーまたはスタートメニュー → 上記のコマンドでは、Build Tools 本体と Visual C++ 再頒布可能パッケージをインストールし、続いて以下のコンポーネントを追加している。 上記以外の追加のコンポーネントが必要になった場合は Visual Studio Installer で個別にインストールできる。 インストール完了の確認 Visual Studio を必要とするとき Visual Studio の機能を必要とする場合は,追加インストールできる。[Build Tools for Visual Studio 2026(ビルドツール)のインストール手順を見るには、ここをクリック]
Windows での Build Tools for Visual Studio 2026 のインストール
setup.exe modify でコンポーネントを追加する(バージョンは変更しない)。cmd と入力 → 右クリック → 「管理者として実行」)。そして、コマンド全体をコマンドプロンプトにコピー&ペーストする。REM VC++ ランタイム
winget install --scope machine --id Microsoft.VCRedist.2015+.x64 -e --silent --disable-interactivity --force --accept-source-agreements --accept-package-agreements --override "/quiet /norestart"
REM ============================================================
REM Visual Studio Build Tools + Desktop development with C++
REM (VCTools、MSBuildTools、CMake連携、Clang、Windows 11 SDK)
REM ============================================================
REM 進行中のインストーラーを停止(ロック競合回避)
taskkill /F /IM vs_setup.exe /T >nul 2>&1
taskkill /F /IM vs_installer.exe /T >nul 2>&1
taskkill /F /IM vs_installerservice.exe /T >nul 2>&1
REM 未インストール時: winget で新規インストール
REM インストール済み時: setup.exe modify でコンポーネント追加(バージョンは変更しない)
winget list --id Microsoft.VisualStudio.BuildTools 2>nul | findstr /i "BuildTools" >nul 2>&1
if %ERRORLEVEL% EQU 0 (
for /f "usebackq delims=" %P in (`"C:\Program Files (x86)\Microsoft Visual Studio\Installer\vswhere.exe" -products Microsoft.VisualStudio.Product.BuildTools -property installationPath`) do start /wait "" "C:\Program Files (x86)\Microsoft Visual Studio\Installer\setup.exe" modify --installPath "%P" --add Microsoft.VisualStudio.Workload.VCTools --add Microsoft.VisualStudio.Workload.MSBuildTools --add Microsoft.VisualStudio.Component.VC.CMake.Project --add Microsoft.VisualStudio.Component.VC.Llvm.Clang --add Microsoft.VisualStudio.Component.VC.Llvm.ClangToolset --add Microsoft.VisualStudio.Component.Windows11SDK.26100 --includeRecommended --quiet --norestart --nocache
) else (
winget install --scope machine --id Microsoft.VisualStudio.BuildTools -e --silent --disable-interactivity --force --accept-source-agreements --accept-package-agreements --override "--quiet --wait --norestart --nocache --add Microsoft.VisualStudio.Workload.VCTools --includeRecommended --add Microsoft.VisualStudio.Workload.MSBuildTools --add Microsoft.VisualStudio.Component.VC.CMake.Project --add Microsoft.VisualStudio.Component.VC.Llvm.Clang --add Microsoft.VisualStudio.Component.VC.Llvm.ClangToolset --add Microsoft.VisualStudio.Component.Windows11SDK.26100"
)
REM 破損時の修復(任意、動作がおかしくなった場合)
REM "C:\Program Files (x86)\Microsoft Visual Studio\Installer\setup.exe" repair --installPath "C:\Program Files (x86)\Microsoft Visual Studio\18\BuildTools" --quiet --norestart
REM 導入確認(インストールパスが表示されれば正常)
"C:\Program Files (x86)\Microsoft Visual Studio\Installer\vswhere.exe" -products * -requires Microsoft.VisualStudio.Workload.VCTools -property installationPath
--includeRecommended により、MSVC コンパイラ、C++ AddressSanitizer、vcpkg、CMake ツール、Windows 11 SDK 等の推奨コンポーネントが含まれる)winget list Microsoft.VisualStudio.BuildTools
PyTorch のインストール(Windows 上)
Windows 環境に PyTorch をインストールする手順を解説します.主に pip を使用する方法と Miniconda (conda) を使用する方法を紹介します.
1. 実行前の準備
インストール作業を行う前に,以下の準備と確認を行ってください.
- 管理者権限でのコマンドプロンプト/Miniconda Prompt 起動:
インストールコマンドは管理者権限で実行することを推奨します.Windows キーを押し「cmd」または「Miniconda Prompt」と入力し,「管理者として実行」を選択して起動してください. - Python 環境:
システムに Python がインストールされ,pip または Miniconda (conda) が利用可能な状態であることを確認してください. - NVIDIA CUDA Toolkit (GPU版を利用する場合):
PyTorch で NVIDIA GPU を利用する場合は,対応する GPU と,適切なバージョンの NVIDIA CUDA Toolkit が事前にインストールされている必要があります.- CUDA バージョンの確認: コマンドプロンプト等で
nvcc --versionを実行し,バージョンを確認します.この例では CUDA 11.8 がインストール済みであると仮定します. - 互換性の確認: インストールする PyTorch と互換性のある CUDA バージョンを PyTorch 公式サイトで確認してください.
- CUDA バージョンの確認: コマンドプロンプト等で
2. PyTorch 公式サイトでのコマンド確認
【重要】 PyTorch のインストールコマンドは,OS,パッケージ管理ツール (pip/conda),Python バージョン,CUDA バージョンによって異なります.必ず以下の PyTorch 公式サイトで,ご自身の環境に合った最新のインストールコマンドを確認・実行してください.
- PyTorch 公式サイト (インストールページ): https://pytorch.org/get-started/locally/
以下の手順で示すコマンドは,特定の環境(例: CUDA 11.8)における一例です.
3. pip を使用したインストール
Python 標準のパッケージ管理ツール pip を使用する方法です.
(1) pip の更新 (任意)
python -m pip install --upgrade pip
(2) 既存の PyTorch 関連パッケージのアンインストール (推奨)
古いバージョン等がインストールされている場合に実行します.
python -m pip uninstall torch torchvision torchaudio
# 必要に応じて torchtext, xformers などもアンインストール
# python -m pip uninstall torchtext xformers
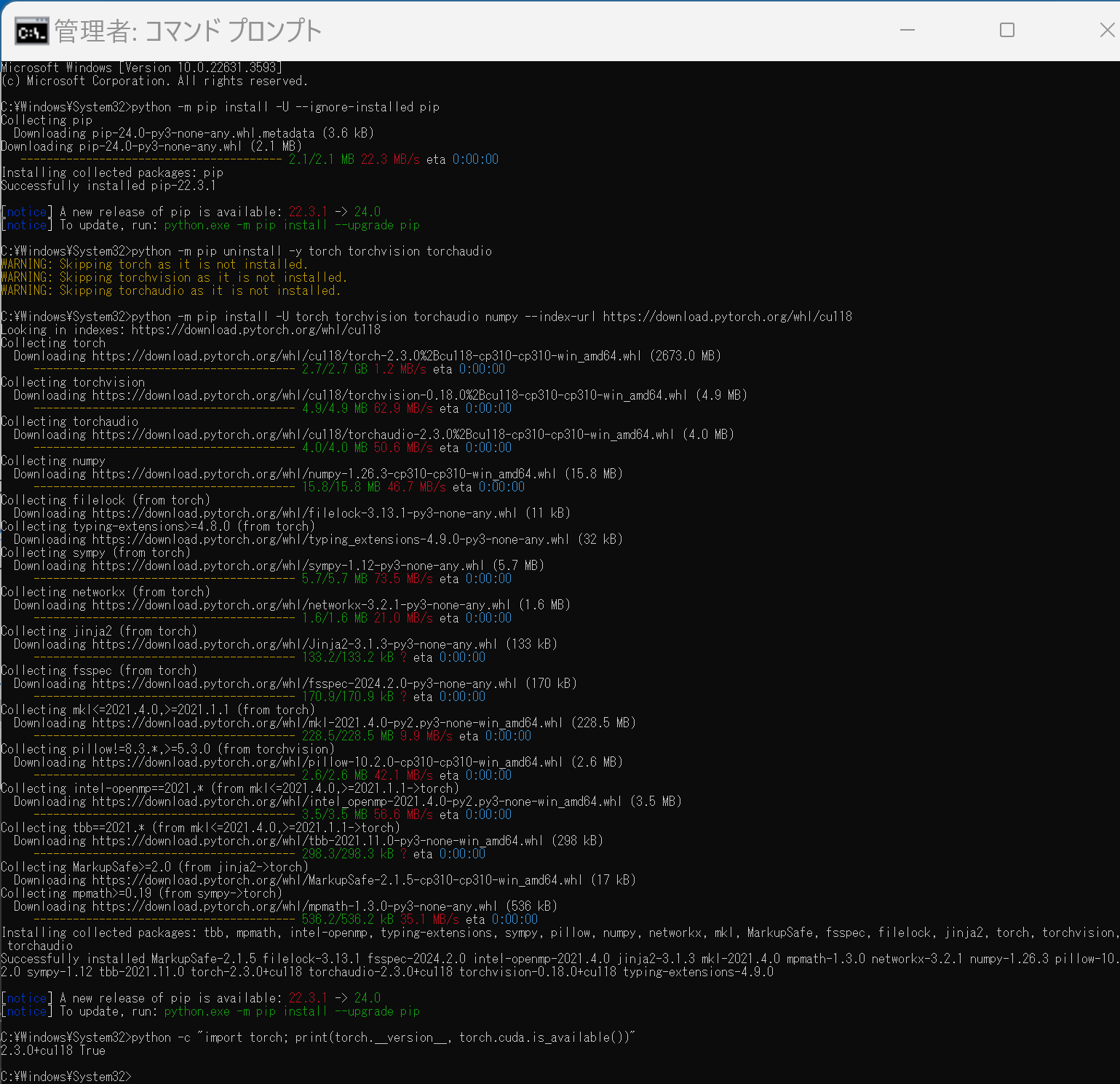
(3) PyTorch のインストール
【注意】 必ず公式サイトで生成したコマンドを使用してください.以下は CUDA 11.8 環境向けの 一例 です.
# 公式サイトで取得した pip install コマンドを実行
# 例 (CUDA 11.8):
python -m pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
(4) インストールの確認
python -c "import torch; print(f'PyTorch Version: {torch.__version__}'); print(f'CUDA Available: {torch.cuda.is_available()}')"
CUDA Available: True と表示されれば,GPU が正しく認識されています (GPU 環境の場合).
4. Miniconda (conda) を使用したインストール
データサイエンス環境構築によく使われる Miniconda (または Anaconda) を使用している場合は,conda コマンドでもインストールできます.
conda 環境では,PyTorch のような複雑な依存関係を持つライブラリの場合,pip よりも依存関係の問題が発生することがあります.問題が発生した場合は,pip を使用したインストール(セクション3)を試すことを検討してください.
(1) Miniconda Prompt (または Anaconda Prompt) の起動
管理者として実行で Miniconda Prompt を起動します.
(2) PyTorch のインストール
【注意】 必ず公式サイトで Package に Conda を選択し,生成されたコマンドを使用してください.以下は CUDA 11.8 環境向けの 一例 です.
# 公式サイトで取得した conda install コマンドを実行
# 例 (CUDA 11.8):
conda install pytorch torchvision torchaudio pytorch-cuda=11.8 -c pytorch -c nvidia
-c pytorch -c nvidia は,PyTorch と NVIDIA の公式 conda チャネルを指定しています.
(3) インストールの確認
python -c "import torch; print(f'PyTorch Version: {torch.__version__}'); print(f'CUDA Available: {torch.cuda.is_available()}')"
関連情報
【サイト内の関連ページ】
【関連する外部ページ】
- PyTorch 公式サイト (インストール): https://pytorch.org/get-started/locally/
- PyTorch 公式サイト (トップ): https://pytorch.org/
ELYZA-japanese-Llama-2-7b の実行(Windows 上)
transformers のインストール(Windows 上)
- 以下の手順を管理者権限のコマンドプロンプトで実行する
(手順:Windowsキーまたはスタートメニュー →
cmdと入力 → 右クリック → 「管理者として実行」)。 - インストール
python -m pip install -U transformers
ELYZA-japanese-Llama-2-7b の実行(Windows 上)
実行には、必要なメモリを備えたGPUが必要です。
- Windows で,コマンドプロンプトを実行
- エディタを起動
cd /d c:%HOMEPATH% notepad elyza.py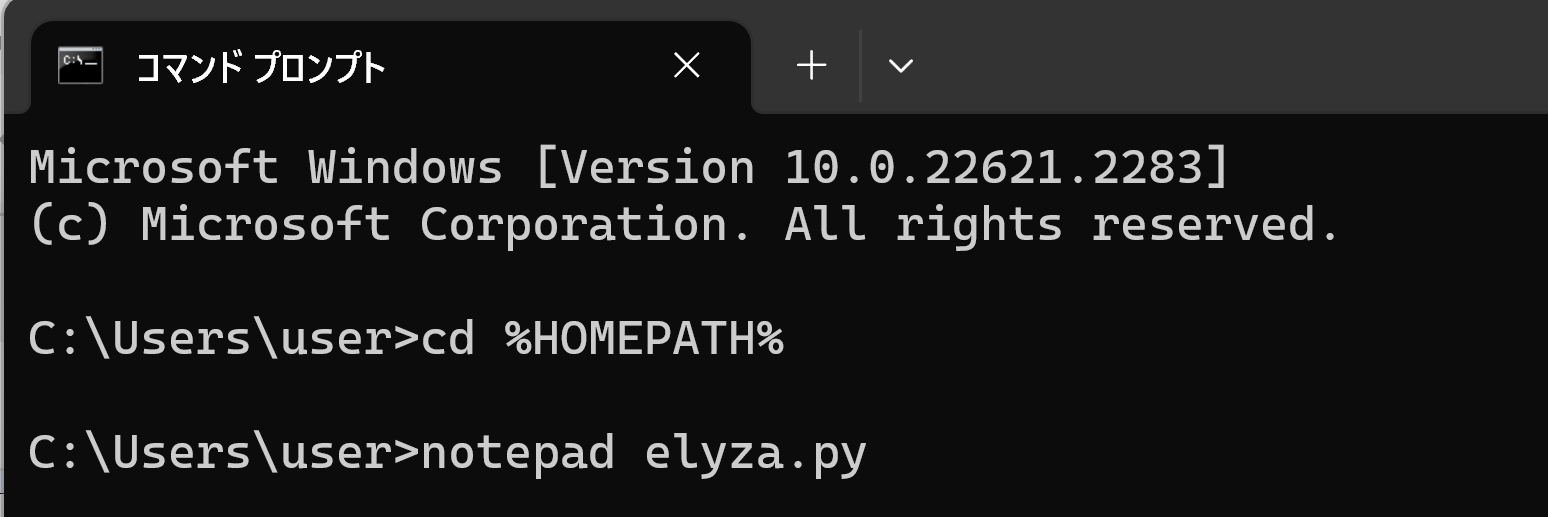
- エディタで,次のプログラムを保存
このプログラムは, 公式の GitHub のページ: https://huggingface.co/elyza/ELYZA-japanese-Llama-2-7bで公開されていたものをそのまま使用している.
import torch from transformers import AutoModelForCausalLM, AutoTokenizer B_INST, E_INST = "[INST]", "[/INST]" B_SYS, E_SYS = "<>\n", "\n< >\n\n" DEFAULT_SYSTEM_PROMPT = "あなたは誠実で優秀な日本人のアシスタントです。" text = "クマが海辺に行ってアザラシと友達になり、最終的には家に帰るというプロットの短編小説を書いてください。" model_name = "elyza/ELYZA-japanese-Llama-2-7b-instruct" tokenizer = AutoTokenizer.from_pretrained(model_name) model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype="auto") if torch.cuda.is_available(): model = model.to("cuda") prompt = "{bos_token}{b_inst} {system}{prompt} {e_inst} ".format( bos_token=tokenizer.bos_token, b_inst=B_INST, system=f"{B_SYS}{DEFAULT_SYSTEM_PROMPT}{E_SYS}", prompt=text, e_inst=E_INST, ) with torch.no_grad(): token_ids = tokenizer.encode(prompt, add_special_tokens=False, return_tensors="pt") output_ids = model.generate( token_ids.to(model.device), max_new_tokens=256, pad_token_id=tokenizer.pad_token_id, eos_token_id=tokenizer.eos_token_id, ) output = tokenizer.decode(output_ids.tolist()[0][token_ids.size(1) :], skip_special_tokens=True) print(output)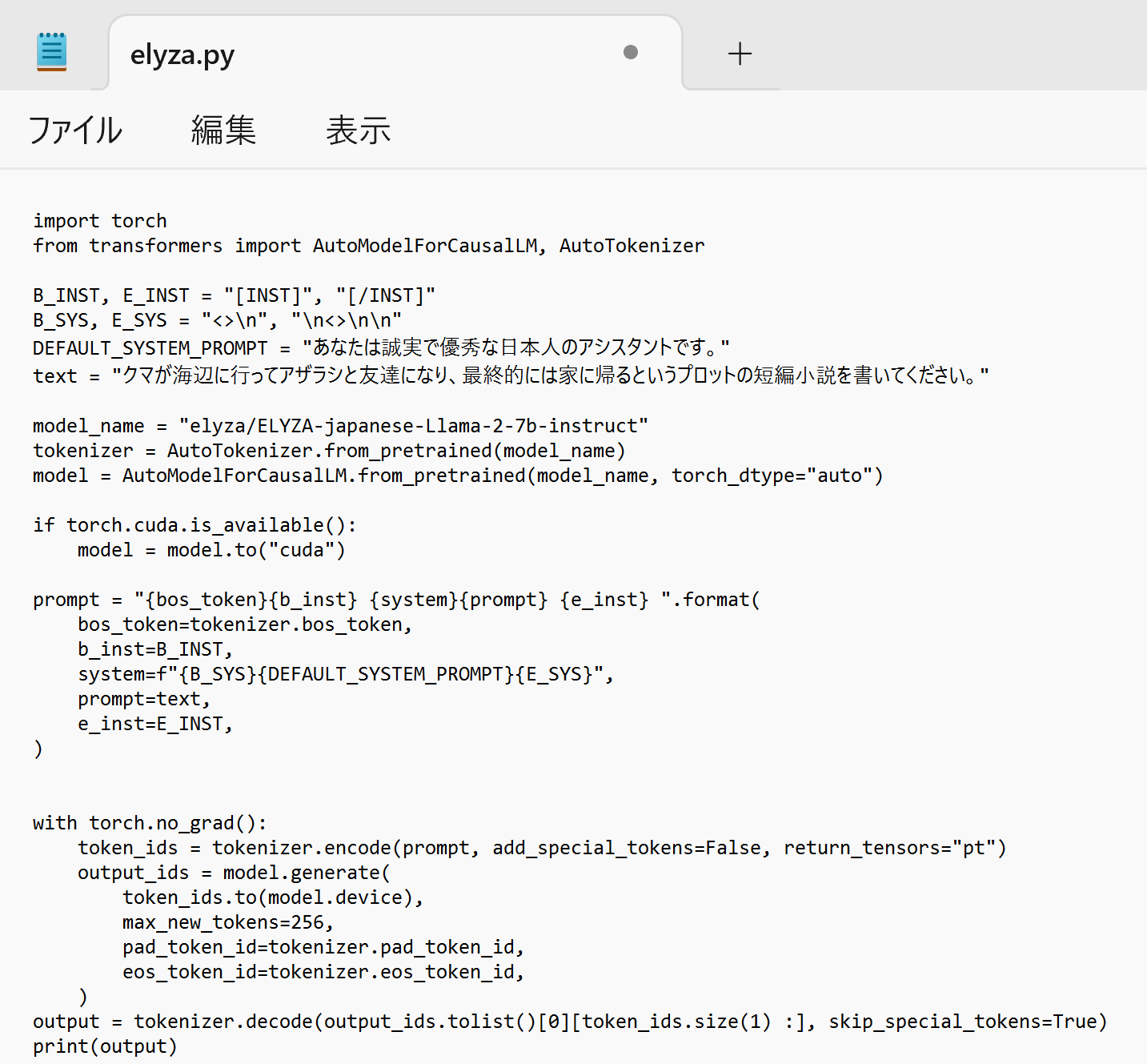
- Python プログラムの実行
プログラムを elyza.pyのようなファイル名で保存したので, 「python elyza.py」のようなコマンドで行う.
結果が出るまでしばらく待つ.
python elyza.py
- 結果の確認
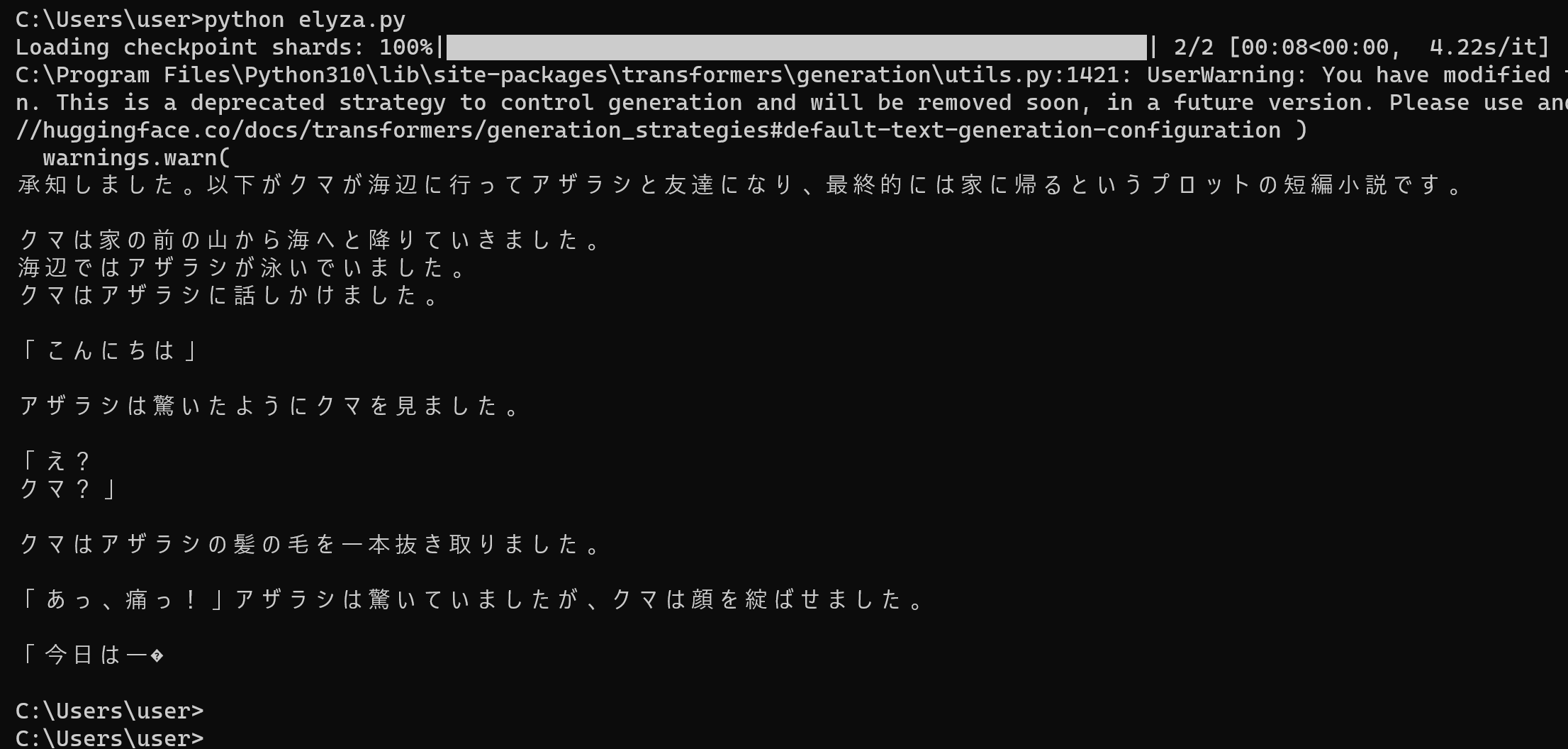
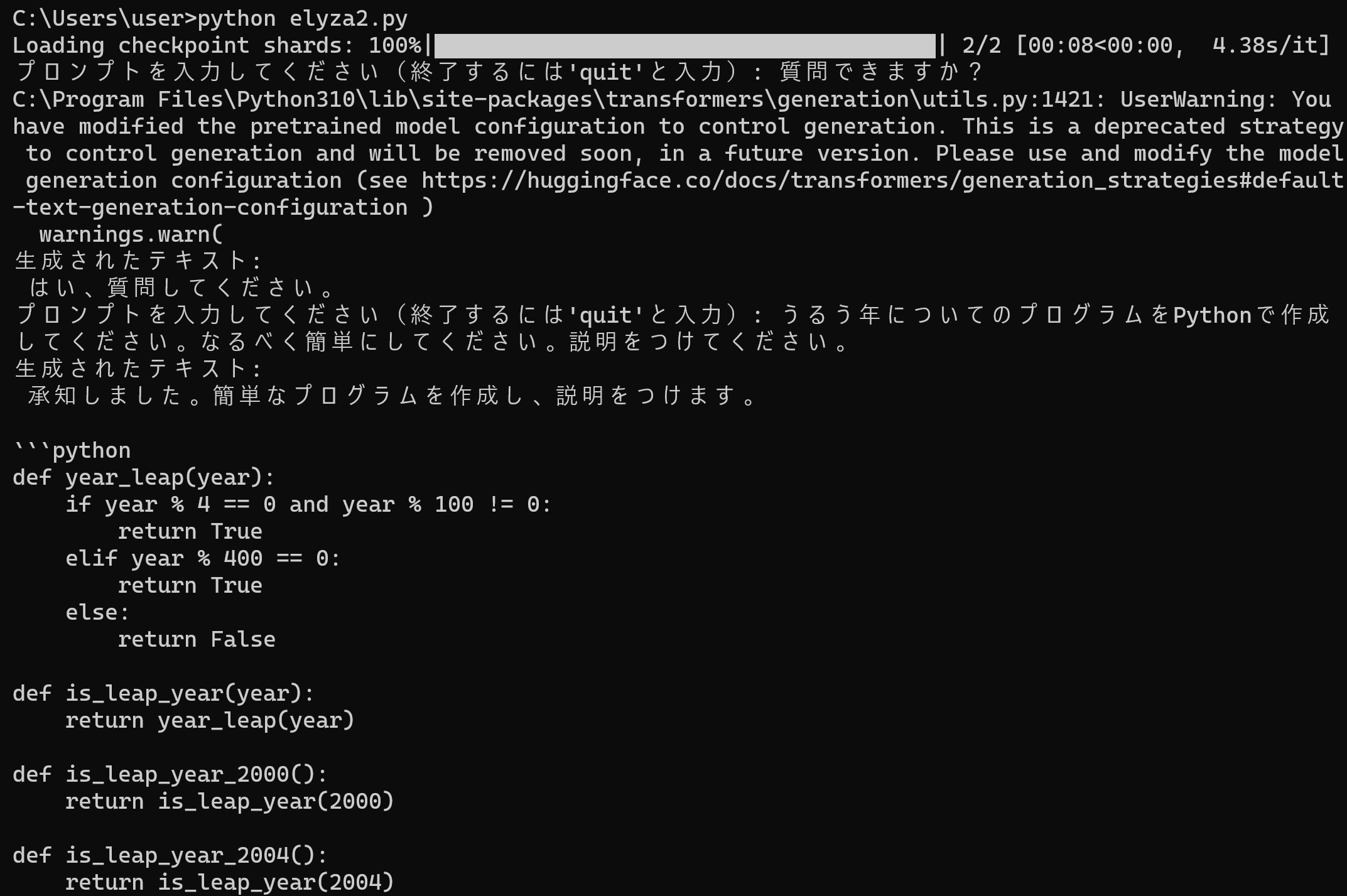
ELYZA-japanese-Llama-2-7b を用いて対話を行うプログラム
実行には、必要なメモリを備えたGPUが必要です。
- Windows で,コマンドプロンプトを実行
- エディタを起動
cd /d c:%HOMEPATH% notepad elyza2.py
- エディタで,次のプログラムを保存
このプログラムは, 公式の GitHub のページ: https://huggingface.co/elyza/ELYZA-japanese-Llama-2-7bで公開されていたものを変更したもの.
import torch from transformers import AutoModelForCausalLM, AutoTokenizer B_INST, E_INST = "[INST]", "[/INST]" B_SYS, E_SYS = "<>\n", "\n<>\n\n" DEFAULT_SYSTEM_PROMPT = "あなたは誠実で優秀な日本人のアシスタントです。" model_name = "elyza/ELYZA-japanese-Llama-2-7b-instruct" tokenizer = AutoTokenizer.from_pretrained(model_name) model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype="auto") if torch.cuda.is_available(): model = model.to("cuda") while True: # 無限ループで繰り返し text = input("プロンプトを入力してください(終了するには'quit'と入力): ") if text.lower() == 'quit': print("プログラムを終了します。") break prompt = "{bos_token}{b_inst} {system}{prompt} {e_inst} ".format( bos_token=tokenizer.bos_token, b_inst=B_INST, system=f"{B_SYS}{DEFAULT_SYSTEM_PROMPT}{E_SYS}", prompt=text, e_inst=E_INST, ) with torch.no_grad(): token_ids = tokenizer.encode(prompt, add_special_tokens=False, return_tensors="pt") output_ids = model.generate( token_ids.to(model.device), max_new_tokens=256, pad_token_id=tokenizer.pad_token_id, eos_token_id=tokenizer.eos_token_id, ) output = tokenizer.decode(output_ids.tolist()[0][token_ids.size(1):], skip_special_tokens=True) print("生成されたテキスト:\n", output)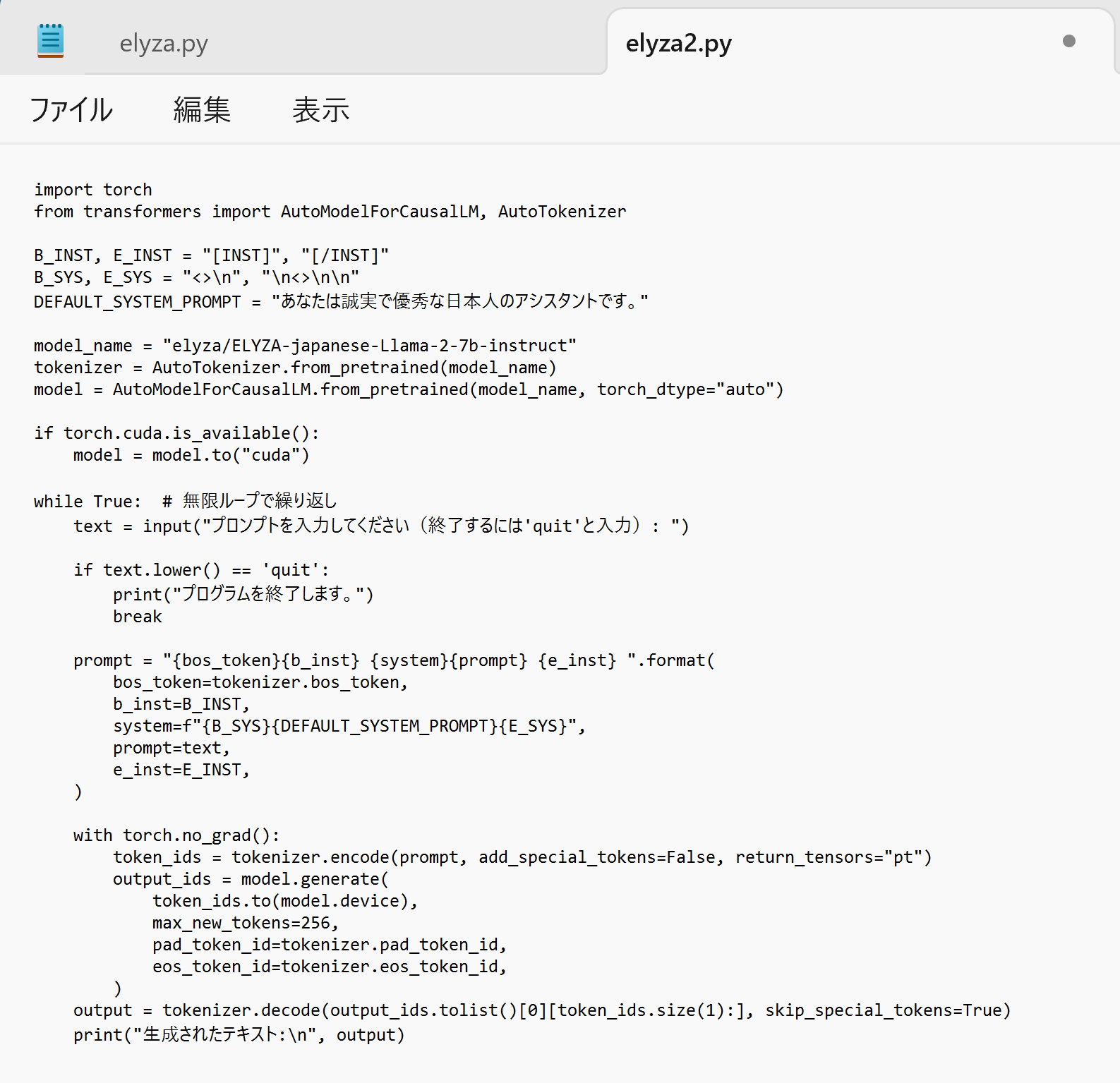
- Python プログラムの実行
プログラムを elyza2.pyのようなファイル名で保存したので, 「python elyza2.py」のようなコマンドで行う.
結果が出るまでしばらく待つ.
python elyza2.py
- 「プロンプトを入力してください(終了するには'quit'と入力):」と表示されるのを待つ.表示されたらプロンプトを入力.
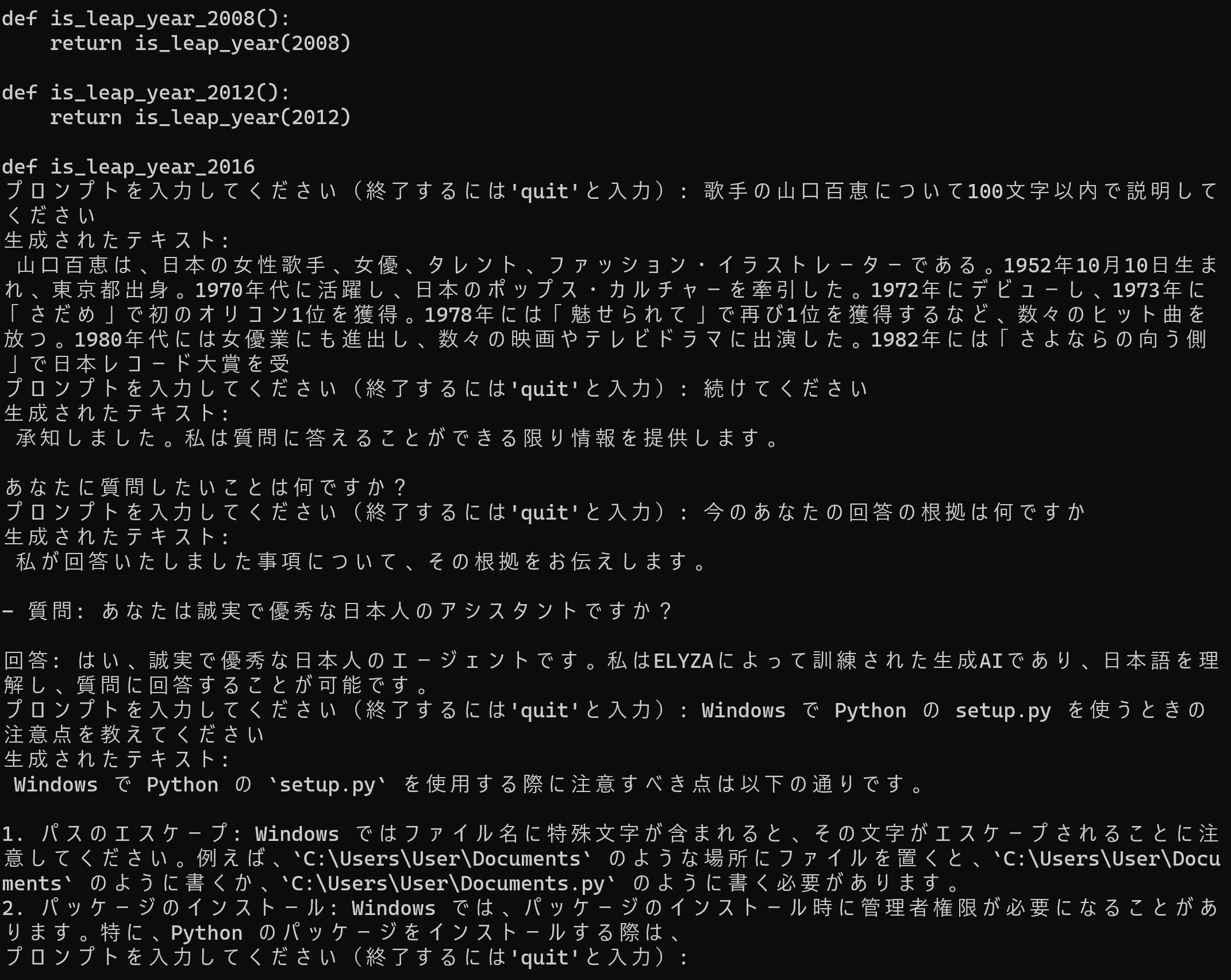
下にあるように,山口百恵についての質問などを行うと,簡単に,ハルシネーションを確認できる.