Tesseract OCR 4.1 の学習(Windows 上)(書きかけ)
Tesseract OCR 4.1 の学習を行う。 ここでの学習は、次の通り.
- 学習に使うための日本語テキストファイルを作成する.
- それを用いて、Tesseract OCR 4.1 で Fine Tuning を行い、認識精度の向上を試す.
手順は、次のページの記載による
https://tesseract-ocr.github.io/tessdoc/#training-for-tesseract-4
新しいフォント、新しい文字を学習させたいときの基礎として説明している. 精度の向上のみが目的の場合は、より高い解像度の画像を使う、 バージョン 5 でなく、安定版を使うことを検討する価値がある。
前準備
Gitのインストール
管理者権限でコマンドプロンプトを起動(手順:Windowsキーまたはスタートメニュー > cmd と入力 > 右クリック > 「管理者として実行」)し、以下を実行する。管理者権限は、wingetの--scope machineオプションでシステム全体にソフトウェアをインストールするために必要となる。
REM Git をシステム領域にインストール
winget install --scope machine --id Git.Git -e --silent --accept-source-agreements --accept-package-agreements
REM Git のパス設定
set "GIT_PATH=C:\Program Files\Git\cmd"
for /f "tokens=2*" %a in ('reg query "HKLM\SYSTEM\CurrentControlSet\Control\Session Manager\Environment" /v Path') do set "SYSTEM_PATH=%b"
if exist "%GIT_PATH%" (
echo "%SYSTEM_PATH%" | find /i "%GIT_PATH%" >nul
if errorlevel 1 setx PATH "%GIT_PATH%;%SYSTEM_PATH%" /M >nul
)
Tesseract OCR 4.1 のインストール
Tesseract OCR のバージョンは、 https://github.com/livezingy/tesstrainsh-win にあわせて、4.1.0 をインストール.
Tesseract OCR は、次の手順でダウンロード
- 「Tesseract OCR のバイナリ」の Web ページを開く
- Windows のところの「Tesseract at UB Mannheim」をクリック
- 下の「older versions」をクリック
- 32 ビット版を選ぶ
- Additional script data (download) で 「Japanese script」と「Japanese vertical script」を選ぶ
- Additional language data (download) で「Japanese」と「Japanese (vertical)」を選ぶ
- インストールディレクトリは C:\Tesseract-OCR とする(空白文字を含まないこと)
Windows での Tesseract OCR のインストール手順: 別ページで説明
Tesseract OCR のテスト実行
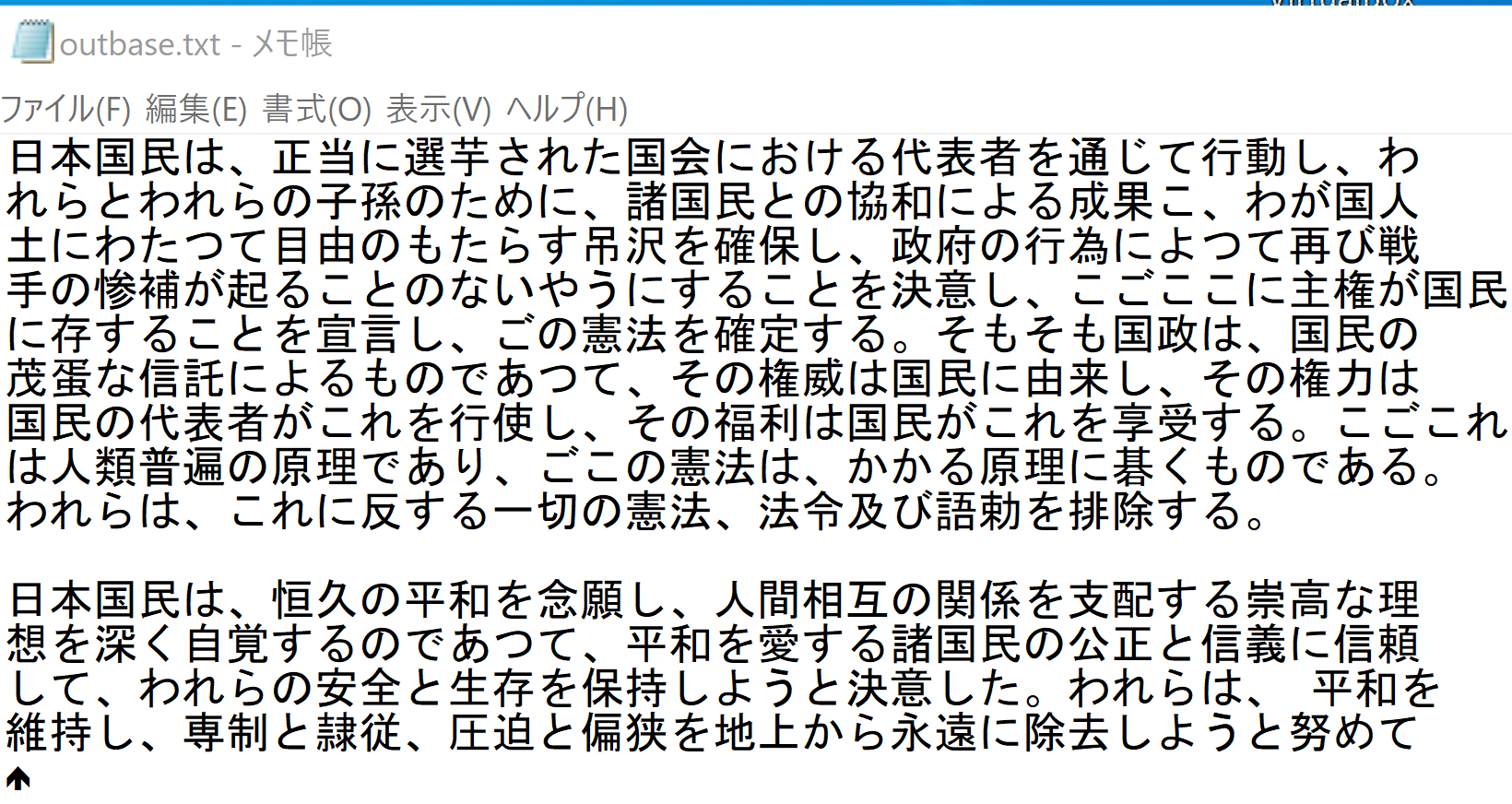
最初に、画像ファイルを用意し、テスト実行してみる
"C:\Tesseract-OCR\tesseract.exe" 2255.png outbase -l jpn
notepad outbase.txt

Tesseract OCR の学習手順(Windows 上)
【関連する外部ページ】 https://github.com/livezingy/tesstrainsh-win
-
Windows で,コマンドプロンプトを管理者として実行する.
- tesstrainsh-win とフォントファイル(langdata_lstm) のダウンロード
tesstrainsh-win の利用条件などは利用者で確認すること.
C: cd "C:\Tesseract-OCR rmdir /s /q tesstrainsh-win git clone --recursive https://github.com/livezingy/tesstrainsh-win copy /y "C:\Tesseract-OCR\tesstrainsh-win\tessdata\configs\lstm.train" "C:\Tesseract-OCR\tesstrainsh-win\tessdata\configs\lstm.train.DIST" xcopy /e /c /h /y "C:\Tesseract-OCR\tessdata" "C:\Tesseract-OCR\tesstrainsh-win\tessdata" cd "C:\Tesseract-OCR\tesstrainsh-win rmdir /s /q langdata_lstm rmdir /s /q langdata git clone --recursive https://github.com/tesseract-ocr/langdata_lstm - Windows パソコンでインストールされている Tesseract OCR のバージョンの確認
"C:\Tesseract-OCR\tesseract" --version
- C:\Tesseract-OCR にパスを通す.
Tesseract OCR の学習手順(Ubuntu 上)
- 学習に用いる日本語ファイル C:\Tesseract-OCR\tesstrainsh-win\jpn.training_text の準備
copy "C:\Tesseract-OCR\tesstrainsh-win\langdata_lstm\jpn\jpn.training_text" "C:\Tesseract-OCR\tesstrainsh-win\jpn.training_text" - "C:\Tesseract-OCR\tesstrainsh-win\jpn.training_text" の編集
ここでは、次のように編集したとして説明を続ける。
00 01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 -00 -01 -02 -03 -04 -05 -06 -07 -08 -09 -10 -11 -12 -13 -14 -15 -16 -17 -18 -19 -20 -21 -22 -23 -24 -25 -26 -27 -28 -29 -30 -31 -32 -33 -34 -35 -36 -37 -38 -39 -40 -41 -42 -43 -44 -45 -46 -47 -48 -49 -50 -51 -52 -53 -54 -55 -56 -57 -58 -59 -60 -61 -62 -63 -64 -65 -66 -67 -68 -69 -70 -71 -72 -73 -74 -75 -76 -77 -78 -79 -80 -81 -82 -83 -84 -85 -86 -87 -88 -89 -90 -91 -92 -93 -94 -95 -96 -97 -98 -99 00- 01- 02- 03- 04- 05- 06- 07- 08- 09- 10- 11- 12- 13- 14- 15- 16- 17- 18- 19- 20- 21- 22- 23- 24- 25- 26- 27- 28- 29- 30- 31- 32- 33- 34- 35- 36- 37- 38- 39- 40- 41- 42- 43- 44- 45- 46- 47- 48- 49- 50- 51- 52- 53- 54- 55- 56- 57- 58- 59- 60- 61- 62- 63- 64- 65- 66- 67- 68- 69- 70- 71- 72- 73- 74- 75- 76- 77- 78- 79- 80- 81- 82- 83- 84- 85- 86- 87- 88- 89- 90- 91- 92- 93- 94- 95- 96- 97- 98- 99 a b c d e f g h i j k l m n o p q r s t u v w x y z A B C D E F G H I J K L M N O P Q R S T U V W X Y Z ・ さ す せ そ た ち つ て と な に ぬ ね の は ひ ふ ほ ま み む め も や ゆ よ ら り る ろ れ わ あ い う え か き く け こ を いわき つくば とちぎ なにわ 愛媛 旭川 伊豆 一宮 宇都宮 越谷 奄美 横浜 岡崎 岡山 沖縄 下関 会津 岩手 岐阜 久留米 宮崎 宮城 京都 金沢 釧路 熊谷 熊本 群馬 郡山 広島 香川 高崎 高知 佐賀 佐世保 堺 札幌 三河 三重 山形 山口 山梨 滋賀 鹿児島 室蘭 秋田 習志野 春日井 春日部 所沢 庄内 松本 沼津 湘南 新潟 神戸 諏訪 水戸 杉並 世田谷 成田 盛岡 青森 静岡 石川 仙台 千葉 川越 川口 川崎 前橋 倉敷 相模 足立 袖ヶ浦 多摩 帯広 大宮 大阪 大分 筑豊 長岡 長崎 長野 鳥取 土浦 島根 徳島 奈良 那須 柏 函館 八王子 八戸 飛騨 尾張小牧 姫路 品川 浜松 富山 富士山 富士山 福井 福岡 福山 福島 平泉 豊橋 豊田 北九州 北見 名古屋 野田 鈴鹿 練馬 和歌山 和泉 - 教師データの生成、訓練データの生成(tesstrain.sh を使用)
tesstrainDone.sh を書き換えて使用している.
終了までしばらく待つ.(学習に用いる日本語ファイルが長いなどの場合は、時間がかかる)
「--fontlist 」のところに、使用する日本語フォント名を書く。
cd "C:\Tesseract-OCR\tesstrainsh-win rmdir /s /q train mkdir train # フォント名と --lang の設定 "C:\Program Files\Git\bin\sh.exe" tesstrain.sh --linedata_only --fonts_dir C:\Windows\Fonts --lang jpn --linedata_only --langdata_dir langdata_lstm --tessdata_dir tessdata --output_dir train --training_text jpn.training_text --fontlist 'Meiryo' -
cd "C:\Tesseract-OCR\tesstrainsh-win rmdir /s /q output mkdir output # jpn.traineddata とjpn.lstm の更新.lang.traineddata とlang.lstm を使用. combine_tessdata -e tessdata/jpn.traineddata train/jpn.lstm # jpn.lstm/jpn.traineddata/jpn.training_files.txt の更新 # フォント名を設定すること lstmtraining \ --continue_from train/jpn.lstm \ --model_output output/Meiryo \ --traineddata tessdata/jpn.traineddata \ --train_listfile train/jpn.training_files.txt \ --debug_interval -1\ --max_iterations 500 # jpn.traineddata の更新 # Update impact_checkpoint and Impact.traineddata の更新 lstmtraining --stop_training \ --continue_from output/impact_checkpoint \ --traineddata tessdata/jpn.traineddata \ --model_output output/Impact.traineddata - 学習に用いる日本語ファイルの仮設定
C:\Tesseract-OCR\langdata_lstm\jpn\jpn.training_text を編集する。
このとき、このファイルの文字コードが変わらないようにすること(ファイルの上書きコピーを行うと、文字コードが変わってしまっても気づきにくい。必ず確認すること)。
エディタを管理者の権限で実行して編集する。
ここでは、次のように編集したとして説明を続ける。
0123456789- abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ ・ さすせそたちつてとなにぬねのはひふほまみむめもやゆよらりるろれわ あいうえかきくけこを いわき,つくば,とちぎ,なにわ,愛媛,旭川,伊豆,一宮,宇都宮,越谷,奄美,横浜,岡崎,岡山,沖縄,下関,会津,岩手,岐阜,久留米,宮崎,宮城,京都,金沢,釧路,熊谷,熊本,群馬,郡山,広島,香川,高崎,高知,佐賀,佐世保,堺,札幌,三河,三重,山形,山口,山梨,滋賀,鹿児島,室蘭,秋田,習志野,春日井,春日部,所沢,庄内,松本,沼津,湘南,新潟,神戸,諏訪,水戸,杉並,世田谷,成田,盛岡,青森,静岡,石川,仙台,千葉,川越,川口,川崎,前橋,倉敷,相模,足立,袖ヶ浦,多摩,帯広,大宮,大阪,大分,筑豊,長岡,長崎,長野,鳥取,土浦,島根,徳島,奈良,那須,柏,函館,八王子,八戸,飛騨,尾張小牧,姫路,品川,浜松,富山,富士山,富士山,福井,福岡,福山,福島,平泉,豊橋,豊田,北九州,北見,名古屋,野田,鈴鹿,練馬,和歌山,和泉 - 教師データの生成(tesstrain.sh の実行)
終了までしばらく待つ.(学習に用いる日本語ファイルが長い場合は、かなりの時間がかかる)
「--linedata_only 」は、LSTM での学習のための設定
「--fontlist 」のところには、日本語フォント名を書く。ここでは、Windows 20.04 を想定して、Window 20.04 の一般的な日本語フォント名を書いている。日本語フォント名は、「"C:\Tesseract-OCR\text2image.exe" --list_available_fonts --fonts_dir C:\Windows\Fonts」で調べることができる。
Windows 10 の日本語フォント: MS ゴシック,MS 明朝,MS UI Gothic,メイリオ,Meiryo UI,游ゴシック・游明朝,Yu Gothic UI,UDデジタル教科書体,BIZ UDゴシック・BIZ UD明朝
rm -rf /tmp/jpntrain tesstrain.sh --fonts_dir C:\Windows\Fonts --lang jpn --linedata_only \ --noextract_font_properties --langdata dir /usr/local/share/langdata_lstm \ --tessdata_dir /usr/local/share/tessdata --output_dir /tmp/jpntrain \ --fontlist 'Noto Sans CJK JP' 'Noto Serif CJK JP Bold' 'Noto Serif CJK JP Heavy' 'Noto Serif CJK JP Light' 'Noto Serif CJK JP Medium' 'Noto Serif CJK JP Semi-Bold' 'Noto Serif CJK JP Ultra-Light' - 終了の確認
エラーメッセージが出ていないこと
- ファイルができるので確認
ls -al /tmp/jpntrain ls -al /tmp/jpntrain/jpn - Fine Tuning の実行
まず、コマンドで、配布・公開されている jpn.traineddata のファイルから、モデルのファイルを生成
combine_tessdata -e /usr/local/share/tessdata/jpn.traineddata /tmp/jpntrain/jpn.lstmいま生成したモデルのファイルを、先ほど生成した教師データを使って FineTuning する.
終了までしばらく待つ.
cd rm lstmtrain* lstmtraining -D /tmp/jpnoutput --model_output lstmtrain \ --continue_from /tmp/jpntrain/jpn.lstm \ --traineddata /usr/local/share/tessdata/jpn.traineddata \ --train_listfile /tmp/jpntrain/jpn.training_files.txt - 終了の確認
エラーメッセージが出ていないこと.
- モデルのファイルを生成、所定の場所にコピー
cd lstmtraining --stop_training \ --continue_from lstmtrain_checkpoint \ --traineddata /usr/local/share/tessdata/jpn.traineddata \ --train_listfile /tmp/jpntrain/jpn.training_files.txt \ --model_output jpn.traineddata sudo cp /usr/local/share/tessdata/jpn.traineddata /usr/local/share/tessdata/jpn.traineddata.$$ sudo cp jpn.traineddata /usr/local/share/tessdata/jpn.traineddata - テスト実行し、動作確認
tesseract 2255.png outbase -l jpn type outbase.txt
{kind=link}