CSV ファイルのApache SparkへのインポートとSQL問い合わせ(Ubuntu環境)
本ページで紹介するソフトウェアの利用条件については,利用者自身で確認する必要があります.
CSVファイルを Apache Spark の一時テーブル(temporary table)にインポートする方法を解説します.
前準備
前準備として JDK のインストール
OpenJDK 18 のインストールと設定(Ubuntu環境): 別ページ »に詳細を記載
* 利用条件については,必ず利用者自身で確認してください.
Apache Spark のインストール
Ubuntu における Apache Spark のインストール手順は,別ページ »で詳しく解説しています.
CSV ファイルの準備
本解説で使用するCSVファイルは, 先頭行に各列の属性名が記載されているものを想定しています. 具体例として, 以下のファイルを使用します.
- https://github.com/simongeek/PandasDA/blob/master/weather.csv
本手順を実際に試す場合は,以下のコマンドでCSVファイルをダウンロードしてください.
cd /tmp
rm -f /tmp/weather.csv
git clone https://github.com/simongeek/PandasDA
cp ./PandasDA/weather.csv /tmp/weather.csv
Apache Spark への CSV ファイルのインポート
- pyspark の起動手順
- インポート処理の実行
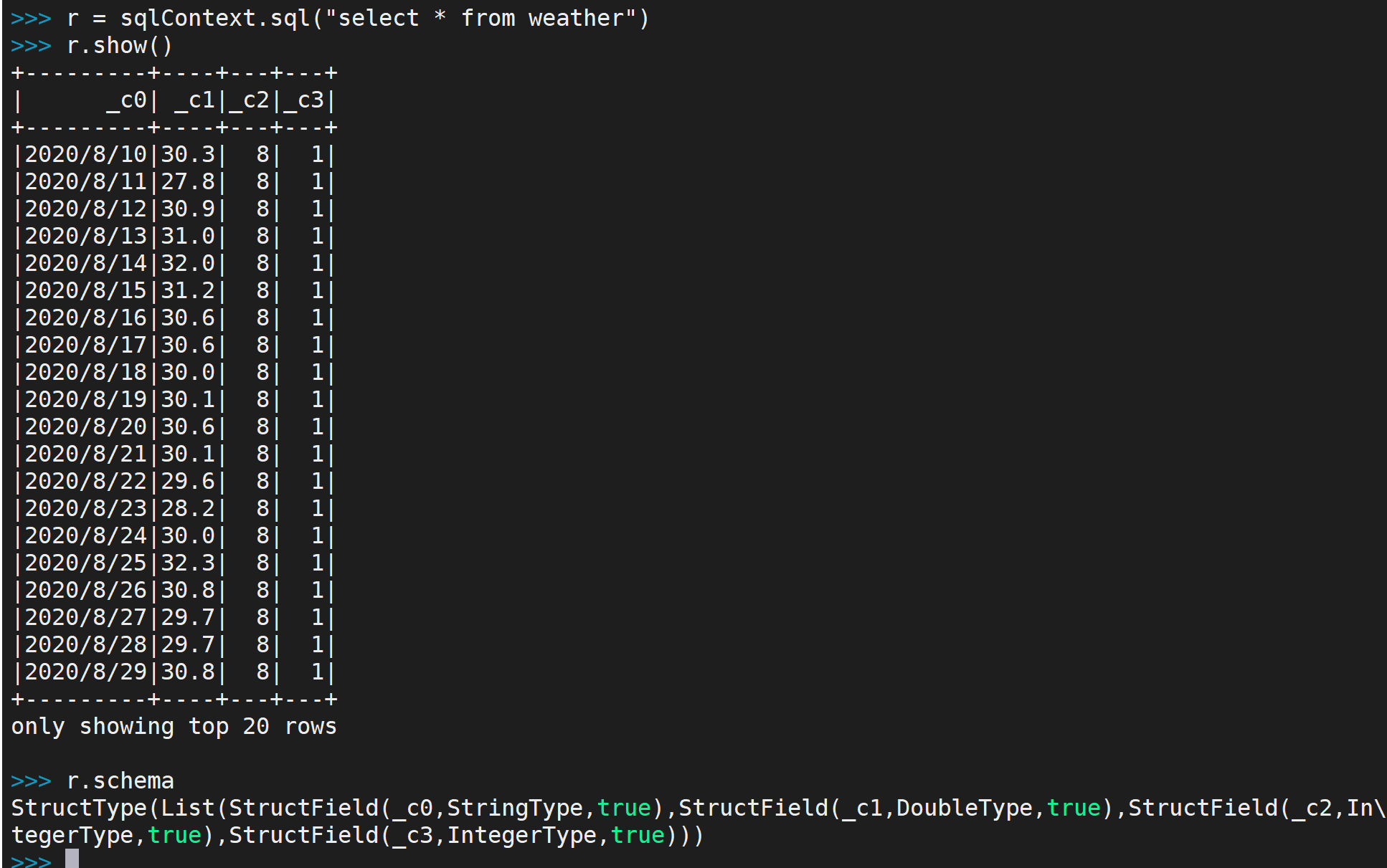
sqlContext.read.format("com.databricks.spark.csv").option("header", "false").option("inferSchema", "true").load("/tmp/w.csv").registerTempTable("weather")
- SQL クエリの実行方法
r = sqlContext.sql("select * from weather") r.show() r.schema