Pythonとクラウド型データベースでリアルタイムデータ同期を実現:Firebase Cloud Firestoreを活用した差分更新の実装
環境構築と前準備
->Python 3.12 のインストール(Windows 上) [クリックして展開]
以下のいずれかの方法で Python 3.12 をインストールする。Python がインストール済みの場合、この手順は不要である。
方法1:winget によるインストール
管理者権限のコマンドプロンプトで以下を実行する。管理者権限のコマンドプロンプトを起動するには、Windows キーまたはスタートメニューから「cmd」と入力し、表示された「コマンドプロンプト」を右クリックして「管理者として実行」を選択する。
winget install --id Python.Python.3.12 -e --scope machine --silent --accept-source-agreements --accept-package-agreements --override "/quiet InstallAllUsers=1 PrependPath=1 Include_test=0 Include_pip=1 Include_launcher=1 InstallLauncherAllUsers=1 TargetDir=\"C:\Program Files\Python312\""
powershell -Command "$p='C:\Program Files\Python312'; $s=\"$p\Scripts\"; $m=[Environment]::GetEnvironmentVariable('Path','Machine'); if($m -notlike \"*$s*\") { [Environment]::SetEnvironmentVariable('Path', \"$p;$s;$m\", 'Machine') }"--scope machine を指定することで、システム全体(全ユーザー向け)にインストールされる。このオプションの実行には管理者権限が必要である。インストール完了後、コマンドプロンプトを再起動すると PATH が自動的に設定される。
方法2:インストーラーによるインストール
- Python 公式サイト(https://www.python.org/downloads/)にアクセスし、「Download Python 3.x.x」ボタンから Windows 用インストーラーをダウンロードする。
- ダウンロードしたインストーラーを実行する。
- 初期画面の下部に表示される「Add python.exe to PATH」に必ずチェックを入れてから「Customize installation」を選択する。このチェックを入れ忘れると、コマンドプロンプトから
pythonコマンドを実行できない。 - 「Install Python 3.xx for all users」にチェックを入れ、「Install」をクリックする。
インストールの確認
コマンドプロンプトで以下を実行する。
python --versionバージョン番号(例:Python 3.12.x)が表示されればインストール成功である。「'python' は、内部コマンドまたは外部コマンドとして認識されていません。」と表示される場合は、インストールが正常に完了していない。
【関連する外部ページ】
【サイト内の関連ページ】
Cloud Firestoreデータベースの構築と設定
- 初期設定
- Firebase公式サイト: https://firebase.google.com/?hl=ja にアクセスし, プロジェクトを作成して認証用の秘密鍵をダウンロードする.これにより,セキュアな接続とアクセス制御が可能となる.
- Firebase Admin SDKをPythonに導入する.このSDKにより,サーバーサイドからデータベースへの直接アクセスが可能となる.
pip install -U firebase-admin
* 詳細な設定手順は「Cloud Firestoreの実践的な活用ガイド:Pythonによる実装」を参照.
- データモデルの設計と実装
created_atフィールド(datetime型)を含むドキュメント構造を設計する.このフィールドは,分散システムにおけるデータの整合性を保証する重要な役割を果たす.
created_atフィールドはドキュメントの作成タイムスタンプを記録し,時系列での差分更新の基準として機能する.タイムスタンプはミリ秒単位の精度を持ち,一意性が保証される.
新規ドキュメントには必ず既存ドキュメントより新しいタイムスタンプが設定される.これにより,データの順序性が保証され,整合性の高い同期が可能となる.
以下は実装例:
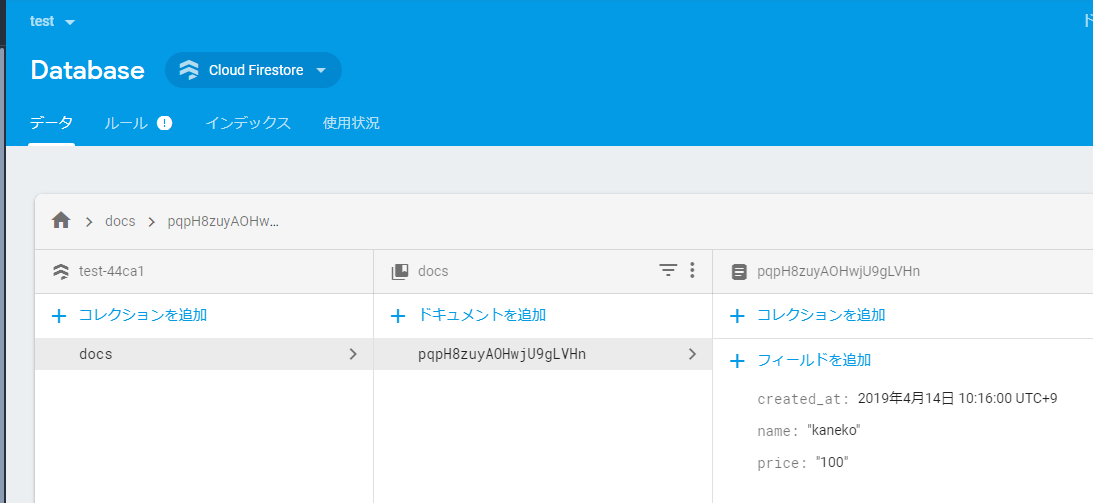
- 動作確認
ダウンロードしたJSONファイル(H:/my-project-abcde-firebase-adminsdk-q53ez-5d420dbcf2.json)のパスを適切に指定する.このファイルには,データベースへのアクセスに必要な認証情報が含まれている.
時刻比較の条件(u'time', u'>', datetime(2019,4,13,3,10,0))で差分データを取得する.この方式により,必要最小限のデータ転送で同期を実現できる.
import datetime import firebase_admin from firebase_admin import credentials from firebase_admin import firestore cred = credentials.Certificate('H:/my-project-abcde-firebase-adminsdk-q53ez-5d420dbcf2.json') app = firebase_admin.initialize_app(cred) db = firestore.client() ref = db.collection(u'docs') a = ref.where(u'created_at', u'>', datetime.datetime(2019,4,8,9,30,0)) docs = a.stream() for doc in docs: print(u'{} => {}'.format(doc.id, doc.to_dict()))
- 最新データの検出と更新処理
キャッシュされたデータから最新のcreated_atを特定し,差分更新の基準として活用する.これにより,効率的なデータ同期が実現できる.
import datetime import firebase_admin from firebase_admin import credentials from firebase_admin import firestore cred = credentials.Certificate('H:/my-project-abcde-firebase-adminsdk-q53ez-5d420dbcf2.json') app = firebase_admin.initialize_app(cred) db = firestore.client() ref = db.collection(u'docs') # 基準時刻の設定 last = datetime.datetime(2019,4,8,0,30,0, 0,datetime.timezone.utc) a = ref.where(u'created_at', u'>', last) docs = a.stream() new_last = last for doc in docs: print(u'{} => {}'.format(doc.id, doc.to_dict())) print(last < doc.to_dict()['created_at']) if ( new_last < doc.to_dict()['created_at'] ): new_last = doc.to_dict()['created_at']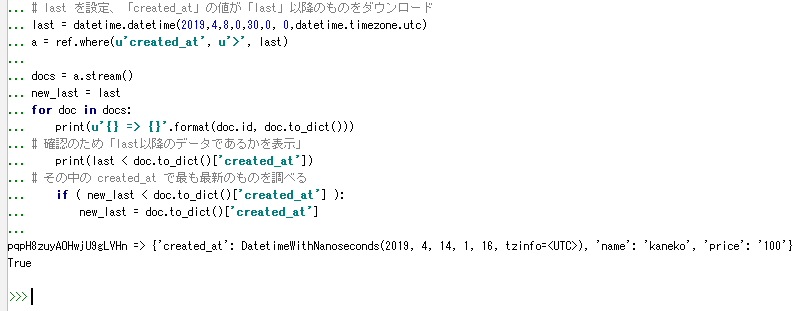
- 定期実行による自動同期の実装
5秒間隔でデータ同期を実行し,効率的な差分更新を実現する.この間隔は,アプリケーションの要件やシステムリソースに応じて調整可能である.
全量同期ではなく,最新タイムスタンプを基準とした差分同期により,通信効率を最大化する.これにより,ネットワーク帯域の効率的な利用が可能となる.
タイムスタンプの比較では10秒のマージンを設定し,データの整合性を確実に確保する.このマージンにより,ネットワーク遅延やクロックずれの影響を吸収できる.
【関連情報】 定期実行処理の実装ガイド
import time import threading import datetime import firebase_admin from firebase_admin import credentials from firebase_admin import firestore cred = credentials.Certificate('H:/my-project-abcde-firebase-adminsdk-q53ez-5d420dbcf2.json') app = firebase_admin.initialize_app(cred) db = firestore.client() ref = db.collection(u'docs') base = datetime.datetime(2019,4,8,0,30,0, 0,datetime.timezone.utc) last = base cache = {} def worker(): global last global cache a = ref.where(u'created_at', u'>', last) docs = a.stream() new_last = last for doc in docs: print(last < doc.to_dict()['created_at']) cache[doc.id] = doc.to_dict() if ( new_last < doc.to_dict()['created_at'] ): new_last = doc.to_dict()['created_at'] print("cache data") print(cache) if ( last < ( new_last - datetime.timedelta(0,10) ) ): last = new_last - datetime.timedelta(0,10) def mainloop(time_interval, f): now = time.time() while True: t = threading.Thread(target=f) t.start() t.join() wait_time = time_interval - ( (time.time() - now) % time_interval ) time.sleep(wait_time) mainloop(5, worker)
差分更新の仕組みの詳細
データベース構造の設計と考慮事項
データベースの各ドキュメントには,以下のフィールドを必須として含める.これらのフィールドにより,効率的なデータ同期と整合性の確保が可能となる.
{
"id": "document_id",
"created_at": timestamp, // ドキュメント作成日時
"updated_at": timestamp, // 最終更新日時
"content": {
// ドキュメントの実データ
}
}
差分更新処理のフロー
- タイムスタンプの管理
created_atフィールドはドキュメントの作成時に自動的に設定され,このフィールドを基準として効率的な差分更新を実現する.タイムスタンプの精度と一意性により,確実なデータ同期が可能となる.
- データの取得と更新
前回の同期時刻以降に作成または更新されたドキュメントのみを効率的に取得する.これにより,不要なデータ転送を最小限に抑えることができる.
def fetch_updates(last_sync_time): updates = ref.where('created_at', '>', last_sync_time) return updates.stream() - ローカルキャッシュの管理
取得したデータをローカルキャッシュに保存し,次回の同期時に効率的に参照する.メモリ使用量とアクセス速度のバランスを考慮した実装となっている.
def update_cache(cache, new_docs): for doc in new_docs: cache[doc.id] = doc.to_dict() return cache
エラーハンドリングと再試行メカニズム
ネットワークエラーやタイムアウトに対する堅牢な処理を実装する.指数バックオフによる再試行により,システムの安定性を確保する.
def safe_fetch(ref, retry_count=3):
for attempt in range(retry_count):
try:
return ref.stream()
except Exception as e:
if attempt == retry_count - 1:
raise e
time.sleep(2 ** attempt)
運用上の注意点
- タイムスタンプは必ずサーバー時刻を使用して正確性を確保する.これにより,分散システム間での時刻の整合性が保証される.
- 同期間隔は適切に設定し,システムリソースを効率的に活用する.過度に頻繁な同期は避け,アプリケーションの要件に応じて調整する.
- データの整合性を確実に保つため,適切なマージン時間を設定する.ネットワーク遅延やシステムの負荷状況を考慮した設定が重要である.
パフォーマンス最適化
- インデックスの活用
created_atフィールドに最適化されたインデックスを設定し,クエリのパフォーマンスを向上させる.時系列データの効率的な検索が可能となる.
- バッチ処理の実装
大量のドキュメントを効率的に処理するためのバッチ処理を実装する.メモリ使用量とレスポンス時間のバランスを考慮した実装が重要である.
def process_in_batches(docs, batch_size=500): batch = [] for doc in docs: batch.append(doc) if len(batch) >= batch_size: process_batch(batch) batch = [] if batch: process_batch(batch) - キャッシュの最適化
メモリ使用量を考慮したキャッシュ管理を実装する.LRU(Least Recently Used)アルゴリズムによる効率的なキャッシュ制御を行う.
def optimize_cache(cache, max_size=1000): if len(cache) > max_size: sorted_items = sorted(cache.items(), key=lambda x: x[1]['created_at']) return dict(sorted_items[-max_size:]) return cache
アプリケーションの監視とログ管理
安定したデータ同期を実現するため,適切な監視体制を整備する.システムの状態を可視化し,問題の早期発見と対応を可能とする.
ログ機能の実装
import logging
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s',
handlers=[
logging.FileHandler('sync.log'),
logging.StreamHandler()
]
)
def sync_with_logging():
try:
logging.info("同期処理を開始")
# 同期処理の実行
logging.info("同期処理が完了")
except Exception as e:
logging.error(f"エラーが発生: {str(e)}")
セキュリティとデータ保護
- 認証情報の適切な管理と定期的な更新による不正アクセスの防止
- 転送時のデータ暗号化によるセキュリティの確保
- 役割ベースのアクセス制御による権限管理の実装
トラブルシューティング
- 同期エラーの診断
エラーが発生した場合の診断手順を定める.ログ分析と原因特定の手順を明確化する.
- データの整合性チェック
定期的にデータの整合性を確認する処理を実装する.チェックサムや比較処理により,データの正確性を検証する.
def verify_data_integrity(local_cache, remote_data): inconsistencies = [] for doc_id, doc_data in local_cache.items(): remote_doc = remote_data.get(doc_id) if remote_doc != doc_data: inconsistencies.append(doc_id) return inconsistencies
まとめと発展的な実装
- 双方向同期の実装による完全な分散システムの構築
- 競合解決メカニズムの導入による整合性の確保
- オフライン対応機能の実装によるシステムの可用性向上