テキストファイル入出力(2)
- Javaのページ
- Javaプログラミング用語集のページ
【関連情報】
Java 25(Temurin 25 JDK) のインストール
Eclipse Temurin(Adoptium)のインストールを行い、Javaのプログラムをコンパイル・実行する環境を整える。扱う環境は、Windows搭載パソコンである。現時点(2026年6月)での最新LTS版である Java 25(Temurin 25 JDK)を推奨する。
[Windows での Java 25(Temurin 25 JDK) のインストール手順を見るには、ここをクリック]
Windows での Java 25(Temurin 25 JDK) のインストール
以下のいずれかの方法で Java 25(Temurin 25 JDK)をインストールする。JDKがインストール済みの場合、この手順は不要である。
方法 1:winget によるインストール
【インストールコマンドの実行方法】
管理者権限でコマンドプロンプトを起動する(手順:Windowsキーまたはスタートメニュー → cmd と入力 → 右クリック → 「管理者として実行」)。そして、コマンド全体をコマンドプロンプトにコピー&ペーストする。
Temurin の Windows インストーラー(.msi)は、ユーザー単位ではなくマシン単位でインストールされる(1台に1つのインストール)。そのため、システム全体(全ユーザー向け)にインストールするには管理者権限が必要である。インストール完了後、コマンドプロンプトを再起動するとPATHが反映される。
REM Java 25(Temurin 25 JDK) をインストール(PATH と JAVA_HOME を更新)
winget install --id EclipseAdoptium.Temurin.25.JDK -e --silent --accept-source-agreements --accept-package-agreements --override "ADDLOCAL=FeatureMain,FeatureEnvironment,FeatureJarFileRunWith,FeatureJavaHome INSTALLDIR=\"C:\Program Files\Eclipse Adoptium\jdk-25\" /quiet"
上記の --override 内の指定の意味は次のとおりである。FeatureEnvironment はPATH環境変数の更新、FeatureJavaHome は JAVA_HOME 環境変数の更新、FeatureJarFileRunWith は .jar ファイルとJavaアプリケーションの関連付けである。INSTALLDIR はインストール先フォルダの指定である。
方法 2:インストーラーによるインストール
- Adoptium公式サイト(https://adoptium.net/temurin/releases/)にアクセスし、Version として「25 - LTS」、Operating System として「Windows」を選び、
.msi形式のWindows用インストーラーをダウンロードする。 - ダウンロードした
.msiファイルを実行し、インストールプログラムを起動する。 - ライセンス条項を確認し、同意できる場合はチェックを入れて次へ進む。
- 「Installation Scope」画面では「Install for all users of this machine」を選ぶ
- 「Custom Setup(カスタムセットアップ)」画面で、インストールする機能を選択する。既定では「Add to PATH(PATH環境変数への追加)」と「Associate .jar」(.jarファイルの関連付け)が有効になっている。さらに、ツリー内でバツ印(×)が付いている「Set JAVA_HOME variable(JAVA_HOME環境変数の更新)」をクリックして有効に変更することを推奨する。これらを有効にしないと、コマンドプロンプトから
javaコマンドを実行できなかったり、開発ツールがJDKを見つけられなかったりする。 - 「次へ (Next)」をクリックし、続いて「インストール (Install)」をクリックしてインストールを開始する。完了後「Finish」で閉じる。
インストールの確認
コマンドプロンプトで以下を実行する。
java --versionバージョン番号(例:openjdk 25.x.x)が表示されればインストール成功である。「'java' は、内部コマンドまたは外部コマンドとして認識されていません。」と表示される場合は、インストールが正常に完了していないか、PATHが反映されていない(コマンドプロンプトを再起動して再度確認する)。
あわせて、コンパイラと JAVA_HOME も確認しておくとよい。
javac --version
echo %JAVA_HOME%Eclipse のインストール
Eclipse をインストールする。扱う環境は、Windows搭載パソコンである。
Windows での Eclipse のインストール 以下のいずれかの方法で Java 25(Temurin 25 JDK)をインストールする。JDKがインストール済みの場合、この手順は不要である。 方法 1:winget によるインストール 【インストールコマンドの実行方法】 管理者権限でコマンドプロンプトを起動する(手順:Windowsキーまたはスタートメニュー → winget が使えない場合や,インストール先・パッケージ種類を画面で選びながら導入したい場合は,次の方法を用いる。 方法 2:インストーラーによるインストール 公式サイトからダウンロードしてインストールできる。詳しくはhttps://www.kkaneko.jp/tools/win/eclipse.htmlで説明している。 Eclipse の初期設定、使用方法の基本 詳しくはhttps://www.kkaneko.jp/tools/win/eclipse.htmlで説明している。[Windows での Eclipse のインストール手順を見るには、ここをクリック]
cmd と入力 → 右クリック → 「管理者として実行」)。そして,コマンド全体をコマンドプロンプトにコピー&ペーストする。REM Temurin 25 JDK をインストール
winget install --id EclipseAdoptium.Temurin.25.JDK -e --accept-source-agreements --accept-package-agreements
FileInputStream, FileOutputStream を利用
StringBufferとappendとStringTokenizerを使ったプログラム
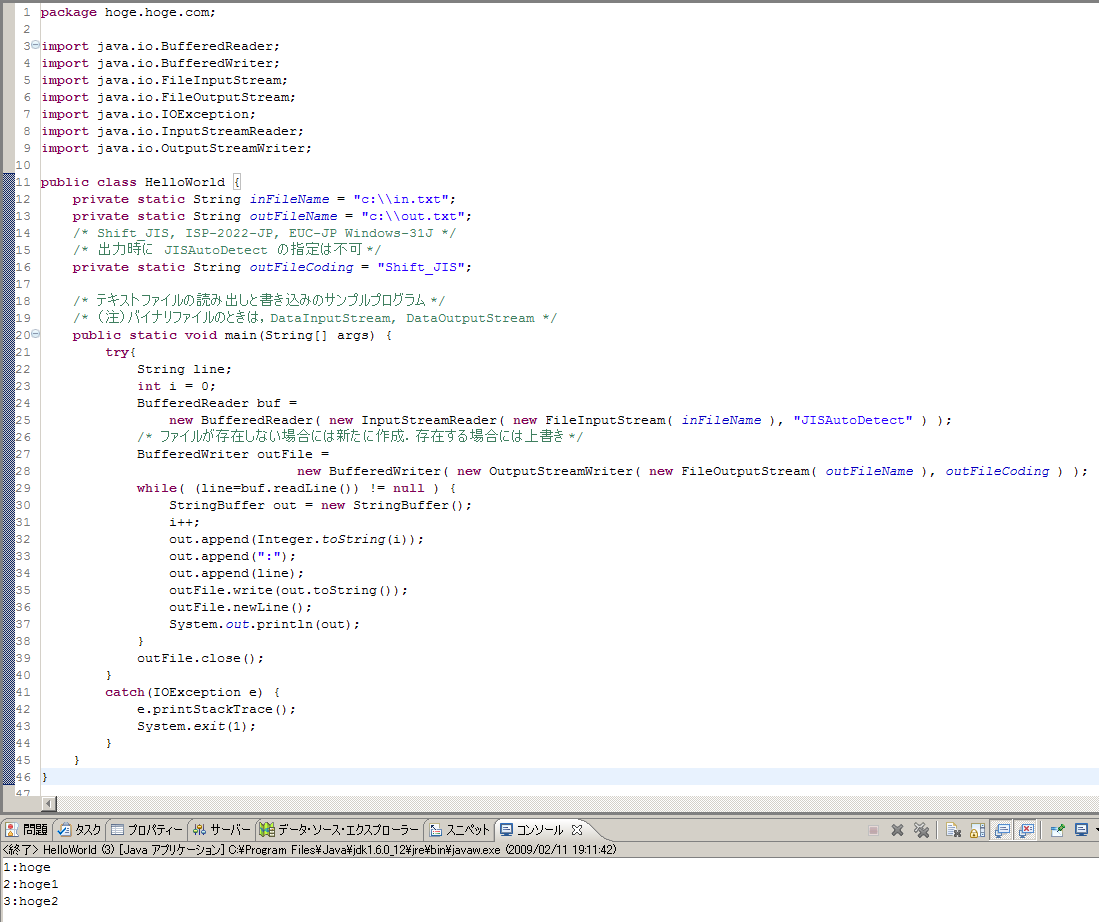
テキストファイルから1行単位で読み込み、行番号を付けて書き出す
要点
- テキストファイルから1行単位での読み込み,書き出し
- 1行読み込んだ結果に,行番号を付けるために,StringBuffer の append メソッドを使用
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
public class HelloWorld {
private static String inFileName = "c:\\in.txt";
private static String outFileName = "c:\\out.txt";
/* Shift_JIS, ISP-2022-JP, EUC-JP Windows-31J */
/* 出力時に JISAutoDetect の指定は不可 */
private static String outFileCoding = "Shift_JIS";
/* テキストファイルの読み出しと書き込みのサンプルプログラム */
/* (注)バイナリファイルのときは,DataInputStream, DataOutputStream */
public static void main(String[] args) {
try{
String line;
int i = 0;
BufferedReader buf =
new BufferedReader( new InputStreamReader( new FileInputStream( inFileName ), "JISAutoDetect" ) );
/* ファイルが存在しない場合には新たに作成.存在する場合には上書き */
BufferedWriter outFile =
new BufferedWriter( new OutputStreamWriter( new FileOutputStream( outFileName ), outFileCoding ) );
while( (line=buf.readLine()) != null ) {
StringBuffer out = new StringBuffer();
i++;
out.append(Integer.toString(i));
out.append(":");
out.append(line);
outFile.write(out.toString());
outFile.newLine();
System.out.println(out);
}
buf.close();
outFile.flush();
outFile.close();
}
catch(IOException e) {
e.printStackTrace();
System.exit(1);
}
}
}
テキストファイルから1行単位で読み込み,トークンの区切り文字を,別の文字列に置き換えてて書き出す
要点
- テキストファイルから1行単位での読み込み,書き出し
- 1行読み込んだ結果からトークンを切り出すために StringTokenizerを利用
- このときのトークンの区切り文字は,複数種類指定できることに注意(プログラム中の変数 seperator)
- 切り取った個々のトークンの末尾に,別の文字列(プログラム中の変数 new_seperator)を付けて出力
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.util.StringTokenizer;
public class HelloWorld {
private static String inFileName = "c:\\in.txt";
private static String outFileName = "c:\\out.txt";
/* Shift_JIS, ISP-2022-JP, EUC-JP Windows-31J */
/* 出力時に JISAutoDetect の指定は不可 */
private static String outFileCoding = "Shift_JIS";
/* トークンの区切り文字を設定 */
private static String seperator = "/ \t";
private static String new_seperator = ", ";
/* テキストファイルの読み出しと書き込みのサンプルプログラム */
/* (注)バイナリファイルのときは,DataInputStream, DataOutputStream */
public static void main(String[] args) {
try{
String line;
int i = 0;
BufferedReader buf =
new BufferedReader( new InputStreamReader( new FileInputStream( inFileName ), "JISAutoDetect" ) );
/* ファイルが存在しない場合には新たに作成.存在する場合には上書き */
BufferedWriter outFile =
new BufferedWriter( new OutputStreamWriter( new FileOutputStream( outFileName ), outFileCoding ) );
while( (line=buf.readLine()) != null ) {
StringTokenizer st = new StringTokenizer(line, seperator);
// トークン数の取得
System.out.print( st.countTokens() + "," );
StringBuffer out = new StringBuffer();
while (st.hasMoreTokens()) {
out.append(st.nextToken());
// 区切られたトークンは new_seperator で区切りなおす
out.append( new_seperator );
}
outFile.write(out.toString());
outFile.newLine();
System.out.println(out);
}
buf.close();
outFile.flush();
outFile.close();
}
catch(IOException e) {
e.printStackTrace();
System.exit(1);
}
}
}
C:\in.txt の中身(トークンが「/」や空白文字やタブで区切られている)

C:\out.txt の中身(個々のトークンの後ろに「, 」が付く)

タブ等で区切られた顧客データ(in.txt)をcsv形式に変換
- CustomerDSO : 顧客 (Customer) の Data Storage Object
- CustomerDAO : 顧客 (Customer) の Data Access Object
- HelloWorld : メイン
- in.txt : 入力ファイル
- out.txt : 出力ファイル
CustomerDSO.java
public class CustomerDSO {
private String ID;
private String name;
private String age;
private String address;
private String phone_num;
public String getID() {
return ID;
}
public void setID(String id) {
ID = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getAge() {
return age;
}
public void setAge(String age) {
this.age = age;
}
public String getAddress() {
return address;
}
public void setAddress(String address) {
this.address = address;
}
public String getPhone_num() {
return phone_num;
}
public void setPhone_num(String phone_num) {
this.phone_num = phone_num;
}
}
CustomerDAO.java
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.util.LinkedList;
import java.util.List;
import java.util.ListIterator;
import java.util.StringTokenizer;
public class CustomerDAO {
private static String inFileName = "c:\\in.txt";
private static String outFileName = "c:\\out.txt";
/* Shift_JIS, ISP-2022-JP, EUC-JP Windows-31J */
/* 出力時に JISAutoDetect の指定は不可 */
private static String outFileCoding = "Shift_JIS";
/* トークンの区切り文字を設定 */
private static String seperator = ",/ \t\r\n";
private static String new_seperator = ", ";
/* テキストファイルからの読み出し */
public static LinkedList<CustomerDSO> readFromTextFile( final String inFileName, final String seperator ) {
// inFileName の例 "c:\\in.txt"
// seperator の例 ",/ \t\r\n"
// inFileName から読み込んで,seperator で区切る
try{
String line;
int i = 0;
BufferedReader buf =
new BufferedReader( new InputStreamReader( new FileInputStream( inFileName ), "JISAutoDetect" ) );
LinkedList<CustomerDSO> list = new LinkedList<CustomerDSO>();
while( (line=buf.readLine()) != null ) {
/* 空行は読み飛ばす */
if ( line.length() == 0 ) {
continue;
}
/* 顧客データの読み込み */
StringTokenizer st = new StringTokenizer(line, seperator);
CustomerDSO k = new CustomerDSO();
k.setID( st.nextToken() );
k.setName( st.nextToken() );
k.setAge( st.nextToken() );
k.setAddress( st.nextToken() );
k.setPhone_num( st.nextToken() );
// 要素数のカウント
i++;
// リストに追加
list.add(k);
// デバック表示
/*
StringBuffer out = new StringBuffer();
out
.append(k.getID()).append(",")
.append(k.getName()).append(",")
.append(k.getAge()).append(",")
.append(k.getAddress()).append(",")
.append(k.getPhone_num());
System.out.println(out);
*/
}
buf.close();
return list;
}
catch(IOException e) {
e.printStackTrace();
System.exit(1);
return null;
}
}
/* テキストファイルからの読み出し */
public static void writeToTextFile( final String おうtFileName, final String outFileCoding, final String seperator, LinkedList<CustomerDSO> list ) {
// outFileName の例 "c:\\out.txt"
// outFileCoding の例 "Shift_JIS" ・・・ Shift_JIS, ISP-2022-JP, EUC-JP, Windows-31J のいずれか
// seperator の例 "," (1文字でなくてもよい)
// outFileName に書き込む.トークンを,seperator で区切る
try{
BufferedWriter outFile =
new BufferedWriter( new OutputStreamWriter( new FileOutputStream( outFileName ), outFileCoding ) );
ListIterator<CustomerDSO> it = list.listIterator();
while( it.hasNext() ) {
// 書き込み
CustomerDSO k = it.next();
StringBuffer out = new StringBuffer();
out
.append(k.getID()).append(seperator)
.append(k.getName()).append(seperator)
.append(k.getAge()).append(seperator)
.append(k.getAddress()).append(seperator)
.append(k.getPhone_num());
outFile.write(out.toString());
outFile.newLine();
}
outFile.flush();
outFile.close();
return;
}
catch(IOException e) {
e.printStackTrace();
System.exit(1);
return;
}
}
}
HelloWorld.java
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.util.LinkedList;
import java.util.StringTokenizer;
public class HelloWorld {
private static String inFileName = "c:\\in.txt";
private static String outFileName = "c:\\out.txt";
/* Shift_JIS, ISP-2022-JP, EUC-JP Windows-31J */
/* 出力時に JISAutoDetect の指定は不可 */
private static String outFileCoding = "Shift_JIS";
/* トークンの区切り文字を設定 */
private static String in_seperator = ",/ \t\r\n";
private static String out_seperator = ",";
/* テキストファイルの読み出しと書き込みのサンプルプログラム */
/* (注)バイナリファイルのときは,DataInputStream, DataOutputStream */
public static void main(String[] args) {
CustomerDAO dao = new CustomerDAO();
LinkedList>CustomerDSO> list = dao.readFromTextFile(inFileName, in_seperator);
dao.writeToTextFile(outFileName, outFileCoding, out_seperator, list);
}
}
in.txt
0001 九大 一郎 18 福岡市西区 000-000-0000 0002 九大 二郎 20 福岡市東区 000-000-0001 0003 九大 三郎 22 福岡市南区 000-000-0002
out.txt
0001,九大 一郎,18,福岡市西区,000-000-0000 0002,九大 二郎,20,福岡市東区,000-000-0001 0003,九大 三郎,22,福岡市南区,000-000-0002
タブ等で区切られたテーブルデータ(in.txt)をcsv形式に変換
- TableDSO : テーブルデータの Data Storage Object
- TableDAO : テーブルデータの Data Access Object
- HelloWorld : メイン
- in.txt : 入力ファイル
- out.txt : 出力ファイル
TableDSO.java
import java.util.LinkedList;
import java.util.ListIterator;
public class TableDSO {
private LinkedList<LinkedList<String>> table;
public TableDSO() {
this.table = new LinkedList<LinkedList<String>>();
}
public LinkedList<LinkedList<String>> getTable() {
return table;
}
public ListIterator<LinkedList<String>> getIterator() {
return table.listIterator();
}
public void setTable(LinkedList<LinkedList<String>> table) {
this.table = table;
}
public void insertIntoTable(LinkedList<String> tuple) {
this.table.add(tuple);
}
}
TableDAO.java
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.util.LinkedList;
import java.util.List;
import java.util.ListIterator;
import java.util.StringTokenizer;
public class TableDAO {
private static String inFileName = "c:\\in.txt";
private static String outFileName = "c:\\out.txt";
/* Shift_JIS, ISP-2022-JP, EUC-JP Windows-31J */
/* 出力時に JISAutoDetect の指定は不可 */
private static String outFileCoding = "Shift_JIS";
/* トークンの区切り文字を設定 */
private static String seperator = ",/ \t\r\n";
private static String new_seperator = ", ";
/* テキストファイルからの読み出し */
public static TableDSO readFromTextFile( final String inFileName, final String seperator ) {
// inFileName の例 "c:\\in.txt"
// seperator の例 ",/ \t\r\n"
// inFileName から読み込んで,seperator で区切る
try{
String line;
int i = 0;
BufferedReader buf =
new BufferedReader( new InputStreamReader( new FileInputStream( inFileName ), "JISAutoDetect" ) );
TableDSO table = new TableDSO();
while( (line=buf.readLine()) != null ) {
/* 空行は読み飛ばす */
if ( line.length() == 0 ) {
continue;
}
/* 顧客データの読み込み */
StringTokenizer st = new StringTokenizer(line, seperator);
LinkedList<String> tuple = new LinkedList<String>();
while( st.hasMoreTokens() ) {
tuple.add( st.nextToken() );
}
i++;
// テーブルに追加
table.insertIntoTable(tuple);
// デバック表示
/*
StringBuffer out = new StringBuffer();
out
.append(k.getID()).append(",")
.append(k.getName()).append(",")
.append(k.getAge()).append(",")
.append(k.getAddress()).append(",")
.append(k.getPhone_num());
System.out.println(out);
*/
}
buf.close();
return table;
}
catch(IOException e) {
e.printStackTrace();
System.exit(1);
return null;
}
}
/* テキストファイルからの読み出し */
public static void writeToTextFile( final String おうtFileName, final String outFileCoding, final String seperator, TableDSO table ) {
// outFileName の例 "c:\\out.txt"
// outFileCoding の例 "Shift_JIS" ・・・ Shift_JIS, ISP-2022-JP, EUC-JP, Windows-31J のいずれか
// seperator の例 "," (1文字でなくてもよい)
// outFileName に書き込む.トークンを,seperator で区切る
try{
BufferedWriter outFile =
new BufferedWriter( new OutputStreamWriter( new FileOutputStream( outFileName ), outFileCoding ) );
ListIterator<LinkedList<String>> it = table.getIterator();
while( it.hasNext() ) {
// 書き込み
LinkedList<String> tuple = it.next();
StringBuffer out = new StringBuffer();
ListIterator<String> it2 = tuple.listIterator();
/* 第一列 */
if ( it2.hasNext() ) {
String s= it2.next();
out.append(s);
}
/* 第二列目以降 */
while( it2.hasNext() ) {
String s = it2.next();
out.append(seperator).append(s);
}
outFile.write(out.toString());
outFile.newLine();
}
outFile.flush();
outFile.close();
return;
}
catch(IOException e) {
e.printStackTrace();
System.exit(1);
return;
}
}
}
HelloWorld.java
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.util.LinkedList;
import java.util.StringTokenizer;
public class HelloWorld {
private static String inFileName = "c:\\in.txt";
private static String outFileName = "c:\\out.txt";
/* Shift_JIS, ISP-2022-JP, EUC-JP Windows-31J */
/* 出力時に JISAutoDetect の指定は不可 */
private static String outFileCoding = "Shift_JIS";
/* トークンの区切り文字を設定 */
private static String in_seperator = ",/ \t\r\n";
private static String out_seperator = ",";
/* テキストファイルの読み出しと書き込みのサンプルプログラム */
/* (注)バイナリファイルのときは,DataInputStream, DataOutputStream */
public static void main(String[] args) {
TableDAO dao = new TableDAO();
TableDSO table = dao.readFromTextFile(inFileName, in_seperator);
dao.writeToTextFile(outFileName, outFileCoding, out_seperator, table);
}
}
C:\in.txt の中身(トークンが「/」や空白文字やタブで区切られている)

C:\out.txt の中身(個々のトークンが「,」で区切られる)

ファイルの入出力に関するプログラム
- readAndWriteTest()
ファイルから読み込んだデータをコンソールに出力し、 同時に出力ファイルにそのままの形で書き込む。
- remakeStringTest(String preString, String postString)
ファイルから読み込んだデータに対して、一行ごとに 接頭語・接尾語を追加する。
- searchAndReplaceTest(String search, String replace)
StringTokenizerを用いて、文字列の置き換えを行う。 但し、文字列の最初又は最後に検索対象が存在する場合や 検索対象が連続して並んでいる場合にエラーが発生する。 これはStringTokenizerの仕様によるもののため修正不可。
- AdjustmentDocumentTest()
読み込んだ英文ファイルに関して、
- 不必要なスペース文字の削除
- 単語の途中における改行の修正
を行い、1センテンスごとに改行を付与してコンソール及び ファイルに出力するプログラム。 但し、単語中に間違って記述されているスペース文字に 対しては修正は行われない。
FileIoTest.java
import java.util.*;
import java.io.*;
public class FileIoTest {
/**
* @param args
*/
private static String inFileName;
private static String outFileName;
/* Shift_JIS, ISP-2022-JP, EUC-JP Windows-31J */
private static String outFileCoding = "Shift_JIS";
public static void readAndWriteTest(){
try{
String line;
BufferedReader inFile = new BufferedReader(
new InputStreamReader( new FileInputStream( inFileName ), "JISAutoDetect" ) );
/* ファイルが存在しない場合には新たに作成.存在する場合には上書き */
BufferedWriter outFile = new BufferedWriter(
new OutputStreamWriter( new FileOutputStream( outFileName ), outFileCoding ) );
while((line=inFile.readLine()) != null){
outFile.write(line);
outFile.newLine();
System.out.println(line);
}
outFile.close();
}
catch(IOException e){
e.printStackTrace();
}
}
public static void remakeStringTest(String preString, String postString){
try{
String line;
StringBuffer SB;
BufferedReader inFile = new BufferedReader(
new InputStreamReader( new FileInputStream( inFileName ), "JISAutoDetect" ) );
/* ファイルが存在しない場合には新たに作成.存在する場合には上書き */
BufferedWriter outFile = new BufferedWriter(
new OutputStreamWriter( new FileOutputStream( outFileName ), outFileCoding ) );
while((line=inFile.readLine()) != null){
SB = new StringBuffer().append(preString).append(line).append(postString);
outFile.write(SB.toString());
outFile.newLine();
System.out.println(SB.toString());
}
outFile.close();
}
catch(IOException e){
e.printStackTrace();
}
}
public static void searchAndReplaceTest(String search, String replace){
try{
String line;
StringBuffer SB;
StringTokenizer ST;
BufferedReader inFile = new BufferedReader(
new InputStreamReader( new FileInputStream( inFileName ), "JISAutoDetect" ) );
/* ファイルが存在しない場合には新たに作成.存在する場合には上書き */
BufferedWriter outFile = new BufferedWriter(
new OutputStreamWriter( new FileOutputStream( outFileName ), outFileCoding ) );
while((line=inFile.readLine()) != null){
ST = new StringTokenizer(line, search);
SB = new StringBuffer(ST.nextToken());
for(int i=0;i < ST.countTokens();i++)
SB.append(replace).append(ST.nextToken());
outFile.write(SB.toString());
outFile.newLine();
System.out.println(SB.toString());
}
outFile.close();
}
catch(IOException e){
e.printStackTrace();
}
}
public static void AdjustmentDocumentTest(){
try{
String line;
StringBuffer SB, SB2;
StringTokenizer ST, ST2;
BufferedReader inFile = new BufferedReader(
new InputStreamReader( new FileInputStream( inFileName ), "JISAutoDetect" ) );
/* ファイルが存在しない場合には新たに作成.存在する場合には上書き */
BufferedWriter outFile = new BufferedWriter(
new OutputStreamWriter( new FileOutputStream( outFileName ), outFileCoding ) );
//SB : ファイル内の全ての文書を格納
SB = new StringBuffer();
while((line=inFile.readLine()) != null) SB.append(line);
//ST : 1センテンス毎に文書を区切る
ST = new StringTokenizer(SB.toString(), ".");
while(ST.hasMoreTokens()){
//ST2 : スペース毎にセンテンスを区切る
ST2 = new StringTokenizer(
new StringBuffer().append(ST.nextToken()).toString(),
" ");
//SB2 : 整形後のセンテンスを格納
SB2 = new StringBuffer(ST2.nextToken());
while(ST2.hasMoreTokens())
SB2.append(" ").append(ST2.nextToken());
line = SB2.append(".").toString();
outFile.write(line);
outFile.newLine();
System.out.println(line);
}
outFile.close();
}
catch(IOException e){
e.printStackTrace();
}
}
public static void main(String[] args) {
// TODO Auto-generated method stub
inFileName = "in.txt";
outFileName = "out1.txt";
System.out.println("readAndWriteTest::");
readAndWriteTest();
//inFileName = "in.txt";
outFileName = "out2.txt";
System.out.println("");
System.out.println("remakeStringTest::");
remakeStringTest("<", ">");
//inFileName = "in.txt";
outFileName = "out3.txt";
System.out.println("");
System.out.println("searchAndReplaceTest::");
searchAndReplaceTest("bcd = ", "XYZ");
inFileName = "inEng.txt";
outFileName = "outEng.txt";
System.out.println("");
System.out.println("AdjustmentDocumentTest::");
AdjustmentDocumentTest();
}
}