Whisper のインストール,Whisper を使う Python プログラム(音声からの文字起こし,翻訳)(Python,PyTorch を使用)(Windows 上)
【要約】 Whisperは,音声からの文字起こしや翻訳に使用されるモデルである.このページで説明するWhisperのインストール(Windows)および動作確認手順に従い,Pythonプログラムを使用して実行することができる.FFmpegをインストールすることで,音声ファイルからの文字起こしを実行し,結果をテキストファイルに保存することも可能である.
【目次】
Whisper
Whisperは,音声からの文字起こし,翻訳 訓練されたモデルが既存のデータセットにゼロショットで適用可能であり、データセット固有のファインチューニングを必要とせずに高品質な結果を達成することを特徴とする.
【文献】
Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, Ilya Sutskever, Robust Speech Recognition via Large-Scale Weak Supervision, arXiv:2212.04356, 2022.
https://cdn.openai.com/papers/whisper.pdf
【サイト内の関連ページ】
- マイクに話しかけた言葉を,リアルタイムにAIが認識(whisper, whisper_mic, Python を使用)(Windows 上)別ページ »で説明
【関連する外部ページ】
- Paper with Code のページ: https://paperswithcode.com/paper/robust-speech-recognition-via-large-scale-1
- Introducing Whisper のページ: https://openai.com/index/whisper/
- GitHub のページ: https://github.com/openai/whisper
【関連項目】 mallorbc の whisper_mic
前準備
Build Tools for Visual Studio 2022 (ビルドツール for Visual Studio 2022)または Visual Studio 2022 のインストール(Windows 上)
【インストールの判断】 Build Tools for Visual Studio は,C++コンパイラなどを含む開発ツールセットです. Visual Studio は統合開発環境であり,いくつかのエディションがあり,Build Tools for Visual Studioの機能を含むか連携して使用します.インストールは以下の基準で判断してください:
- コマンドラインからのビルドなど、C++コンパイラ機能のみが必要な場合:
- Visual Studioのエディタやデバッガなどの統合開発環境機能が必要な場合、あるいは、どちらをインストールすべきかよく分からない場合:
Visual Studio Community (または他のエディション) をインストール します.
Visual Studio 2022 をインストールする際に,「C++ によるデスクトップ開発」ワークロードを選択することで,必要なBuild Toolsの機能も一緒にインストールされます.
不明な点がある場合は,Visual Studio 全体をインストール する方が、後で機能を追加する手間が省ける場合があります.
Build Tools for Visual Studio 2022 のインストール(Windows 上)
- Windows で,コマンドプロンプトを管理者権限で起動します(例:Windowsキーを押し,「cmd」と入力し,「管理者として実行」を選択)。
以下の
wingetコマンドを実行します。wingetはWindows標準のパッケージマネージャーです。--scope machineオプションはシステム全体にインストールすることを意味します。次のコマンドは,Build Tools for Visual Studio 2022と、多くのプログラムで必要とされるVC++ 2015以降の再頒布可能パッケージをインストールします.
- Build Tools for Visual Studio 2022 で C++ によるデスクトップ開発関連コンポーネントのインストール
CUDA開発には、標準のC++開発ツールに加えて、特定のコンポーネントが必要になる場合があります。
- Visual Studio Installer を起動します。
起動方法: スタートメニューから「Visual Studio Installer」を探して実行します.
- Visual Studio Build Tools 2022 の項目で「変更」ボタンをクリックします.
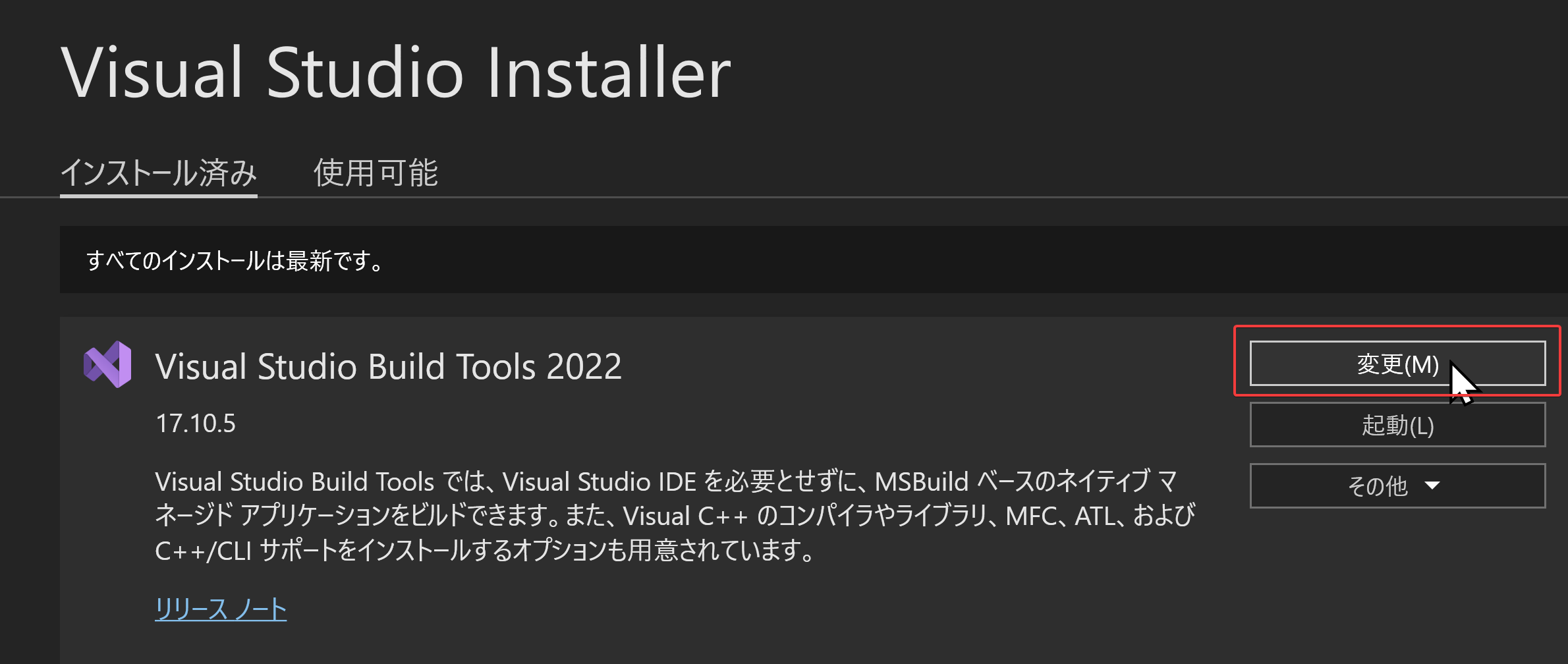
- 「ワークロード」タブで「C++ によるデスクトップ開発」をクリックして選択します。画面右側の「インストールの詳細」で、必要に応じて「v143 ビルドツール用 C++/CLI サポート(最新)」、「ATL」、「MFC」などをチェックします(これらは一般的なC++開発や特定のプロジェクトタイプで必要になる場合があります)。その後、「変更」をクリックしてインストールまたは変更を適用します.
- Visual Studio Installer を起動します。
Visual Studio Community 2022 のインストール(Windows 上)
- Windows で,コマンドプロンプトを管理者権限で起動します。
- インストールコマンドの実行
以下の
wingetコマンドを実行します。--override "--add ..."部分で、インストールするワークロードやコンポーネントを指定しています。winget install Microsoft.VisualStudio.2022.Community --scope machine --override "--add Microsoft.VisualStudio.Workload.NativeDesktop Microsoft.VisualStudio.ComponentGroup.NativeDesktop.Core Microsoft.VisualStudio.Component.VC.CLI.Support Microsoft.VisualStudio.Component.CoreEditor Microsoft.VisualStudio.Component.NuGet Microsoft.VisualStudio.Component.Roslyn.Compiler Microsoft.VisualStudio.Component.TextTemplating Microsoft.VisualStudio.Component.Windows.SDK.Latest Microsoft.VisualStudio.Component.VC.Tools.x86.x64 Microsoft.VisualStudio.Component.VC.ATL Microsoft.VisualStudio.Component.VC.ATLMFC" winget install Microsoft.VisualStudio.2022.Community --scope machine Microsoft.VCRedist.2015+.x64
インストールされる主要なコンポーネントの説明:
NativeDesktop(C++によるデスクトップ開発): CUDA開発に必要なC++コンパイラ(VC.Tools.x86.x64)やWindows SDK (Windows.SDK.Latest)など、基本的な開発ツール一式を含みます。CoreEditor: Visual Studioの基本的なコードエディタ機能を提供します。VC.CLI.Support: C++/CLIを用いた開発サポート(通常、純粋なCUDA C++開発では不要な場合もあります)。NuGet: .NETライブラリ管理用(C++プロジェクトでも利用されることがあります)。VC.ATL/VC.ATLMFC: 特定のWindowsアプリケーション開発フレームワーク(通常、CUDA開発自体には直接必要ありません)。
システム要件と注意事項:
- 管理者権限でのインストールが必須です。
- 必要ディスク容量:10GB以上(選択するコンポーネントにより変動)。
- 推奨メモリ:8GB以上のRAM。
- インストール過程でシステムの再起動が要求される可能性があります。
- 安定したインターネット接続環境が必要です。
後から追加のコンポーネントが必要になった場合は,Visual Studio Installerを使用して個別にインストールすることが可能です.
- インストール完了の確認
インストールが成功したか確認するには、管理者権限のコマンドプロンプトで以下のコマンドを実行します。
winget list Microsoft.VisualStudio.2022.Community
リストに表示されればインストールされています。
トラブルシューティング:
インストール失敗時は,以下のログファイルを確認すると原因究明の手がかりになります:
%TEMP%\dd_setup_
.log %TEMP%\dd_bootstrapper_ .log (
- (オプション) Visual Studio Installer での確認と変更
wingetでのインストール後も、Visual Studio Installerを使ってインストール内容を確認・変更できます。- Visual Studio Installer を起動します。
- Visual Studio Community 2022 の項目で「変更」をクリックします。
- 「ワークロード」タブで「C++ によるデスクトップ開発」がチェックされていることを確認します。必要であれば、「個別のコンポーネント」タブで特定のツール(例: 特定バージョンのMSVCコンパイラ、CMakeツールなど)を追加・削除できます。「インストールの詳細」で「v143 ビルドツール用 C++/CLI サポート(最新)」などが選択されているかも確認できます。変更後、「変更」または「インストール」をクリックします。
Python 3.12 のインストール
インストール済みの場合は実行不要。
管理者権限でコマンドプロンプトを起動(手順:Windowsキーまたはスタートメニュー > cmd と入力 > 右クリック > 「管理者として実行」)し、以下を実行する。管理者権限は、wingetの--scope machineオプションでシステム全体にソフトウェアをインストールするために必要である。
REM Python をシステム領域にインストール
winget install --scope machine --id Python.Python.3.12 -e --silent
REM Python のパス設定
set "PYTHON_PATH=C:\Program Files\Python312"
set "PYTHON_SCRIPTS_PATH=C:\Program Files\Python312\Scripts"
echo "%PATH%" | find /i "%PYTHON_PATH%" >nul
if errorlevel 1 setx PATH "%PATH%;%PYTHON_PATH%" /M >nul
echo "%PATH%" | find /i "%PYTHON_SCRIPTS_PATH%" >nul
if errorlevel 1 setx PATH "%PATH%;%PYTHON_SCRIPTS_PATH%" /M >nul【関連する外部ページ】
Python の公式ページ: https://www.python.org/
AI エディタ Windsurf のインストール
Pythonプログラムの編集・実行には、AI エディタの利用を推奨する。ここでは,Windsurfのインストールを説明する。
管理者権限でコマンドプロンプトを起動(手順:Windowsキーまたはスタートメニュー > cmd と入力 > 右クリック > 「管理者として実行」)し、以下を実行して、Windsurfをシステム全体にインストールする。管理者権限は、wingetの--scope machineオプションでシステム全体にソフトウェアをインストールするために必要となる。
winget install --scope machine Codeium.Windsurf -e --silent【関連する外部ページ】
Windsurf の公式ページ: https://windsurf.com/
Gitのインストール
管理者権限でコマンドプロンプトを起動(手順:Windowsキーまたはスタートメニュー > cmd と入力 > 右クリック > 「管理者として実行」)し、以下を実行する。管理者権限は、wingetの--scope machineオプションでシステム全体にソフトウェアをインストールするために必要となる。
REM Git をシステム領域にインストール
winget install --scope machine --id Git.Git -e --silent
REM Git のパス設定
set "GIT_PATH=C:\Program Files\Git\cmd"
if exist "%GIT_PATH%" (
echo "%PATH%" | find /i "%GIT_PATH%" >nul
if errorlevel 1 setx PATH "%PATH%;%GIT_PATH%" /M >nul
)
Build Tools for Visual Studio 2022,NVIDIA ドライバ,NVIDIA CUDA ツールキット 11.8,NVIDIA cuDNN 8.9.7 のインストール(Windows 上)
【サイト内の関連ページ】 NVIDIA グラフィックスボードを搭載しているパソコンの場合には, NVIDIA ドライバ, NVIDIA CUDA ツールキット, NVIDIA cuDNN のインストールを行う.
- Windows での Build Tools for Visual Studio 2022 のインストール: 別ページ »で説明
- Windows での NVIDIA ドライバ,NVIDIA CUDA ツールキット 11.8,NVIDIA cuDNN v8.9.7 のインストール手順: 別ページ »で説明
【関連する外部ページ】
- Build Tools for Visual Studio 2022 (ビルドツール for Visual Studio 2022)の公式ダウンロードページ: https://visualstudio.microsoft.com/ja/visual-cpp-build-tools/
- NVIDIA ドライバのダウンロードの公式ページ: https://www.nvidia.co.jp/Download/index.aspx?lang=jp
- NVIDIA CUDA ツールキットのアーカイブの公式ページ: https://developer.nvidia.com/cuda-toolkit-archive
- NVIDIA cuDNN のダウンロードの公式ページ: https://developer.nvidia.com/cudnn
PyTorch のインストール(Windows 上)
Windows 環境に PyTorch をインストールする手順を解説します.主に pip を使用する方法と Miniconda (conda) を使用する方法を紹介します.
1. 実行前の準備
インストール作業を行う前に,以下の準備と確認を行ってください.
- 管理者権限でのコマンドプロンプト/Miniconda Prompt 起動:
インストールコマンドは管理者権限で実行することを推奨します.Windows キーを押し「cmd」または「Miniconda Prompt」と入力し,「管理者として実行」を選択して起動してください. - Python 環境:
システムに Python がインストールされ,pip または Miniconda (conda) が利用可能な状態であることを確認してください. - NVIDIA CUDA Toolkit (GPU版を利用する場合):
PyTorch で NVIDIA GPU を利用する場合は,対応する GPU と,適切なバージョンの NVIDIA CUDA Toolkit が事前にインストールされている必要があります.- CUDA バージョンの確認: コマンドプロンプト等で
nvcc --versionを実行し,バージョンを確認します.この例では CUDA 11.8 がインストール済みであると仮定します. - 互換性の確認: インストールする PyTorch と互換性のある CUDA バージョンを PyTorch 公式サイトで確認してください.
- CUDA バージョンの確認: コマンドプロンプト等で
2. PyTorch 公式サイトでのコマンド確認
【重要】 PyTorch のインストールコマンドは,OS,パッケージ管理ツール (pip/conda),Python バージョン,CUDA バージョンによって異なります.必ず以下の PyTorch 公式サイトで,ご自身の環境に合った最新のインストールコマンドを確認・実行してください.
- PyTorch 公式サイト (インストールページ): https://pytorch.org/get-started/locally/
以下の手順で示すコマンドは,特定の環境(例: CUDA 11.8)における一例です.
3. pip を使用したインストール
Python 標準のパッケージ管理ツール pip を使用する方法です.
(1) pip の更新 (任意)
python -m pip install --upgrade pip
(2) 既存の PyTorch 関連パッケージのアンインストール (推奨)
古いバージョン等がインストールされている場合に実行します.
python -m pip uninstall torch torchvision torchaudio
# 必要に応じて torchtext, xformers などもアンインストール
# python -m pip uninstall torchtext xformers
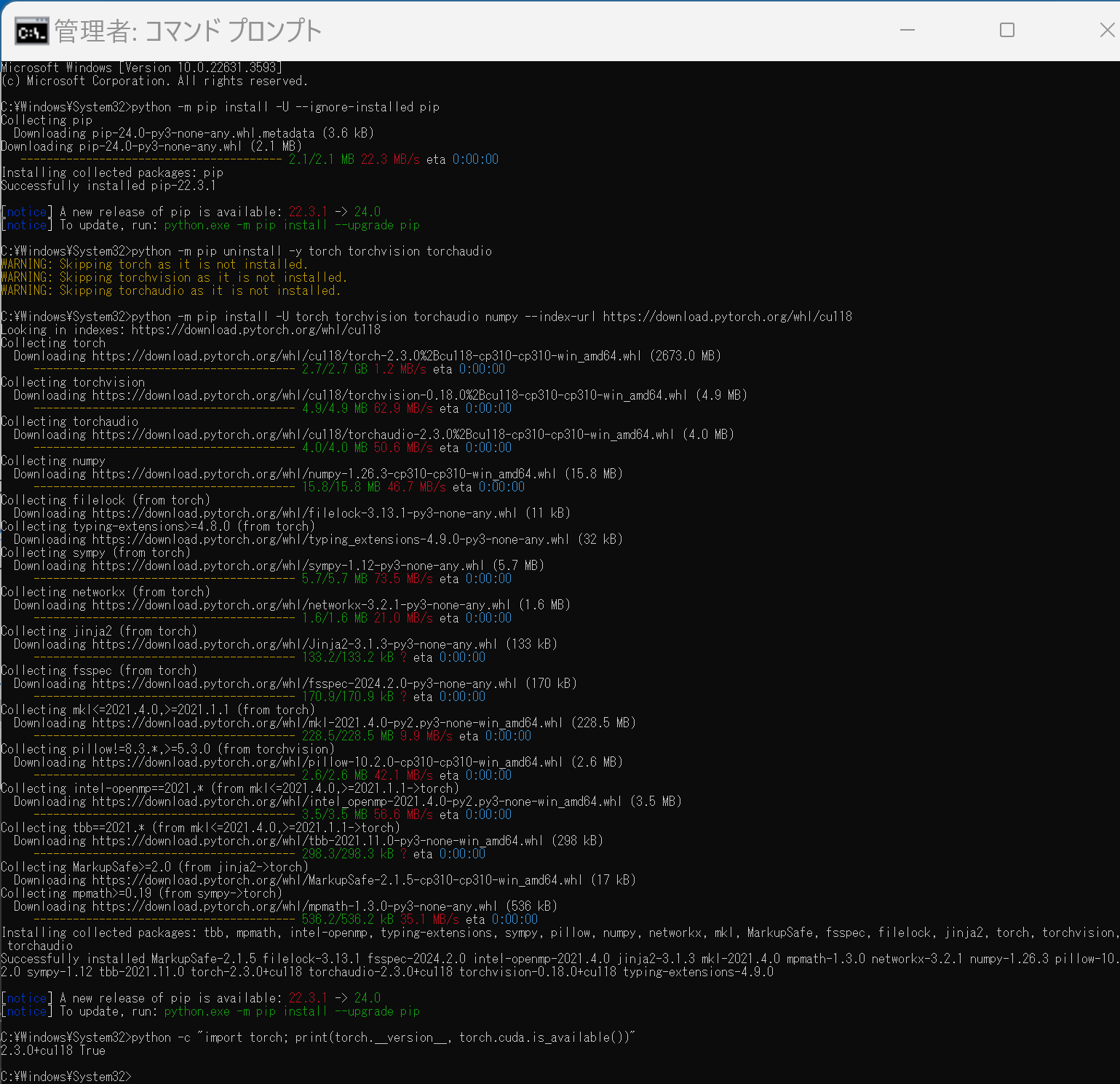
(3) PyTorch のインストール
【注意】 必ず公式サイトで生成したコマンドを使用してください.以下は CUDA 11.8 環境向けの 一例 です.
# 公式サイトで取得した pip install コマンドを実行
# 例 (CUDA 11.8):
python -m pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
(4) インストールの確認
python -c "import torch; print(f'PyTorch Version: {torch.__version__}'); print(f'CUDA Available: {torch.cuda.is_available()}')"
CUDA Available: True と表示されれば,GPU が正しく認識されています (GPU 環境の場合).
4. Miniconda (conda) を使用したインストール
データサイエンス環境構築によく使われる Miniconda (または Anaconda) を使用している場合は,conda コマンドでもインストールできます.
注意点:
conda 環境では,PyTorch のような複雑な依存関係を持つライブラリの場合,pip よりも依存関係の問題が発生することがあります.問題が発生した場合は,pip を使用したインストール(セクション3)を試すことを検討してください.
(1) Miniconda Prompt (または Anaconda Prompt) の起動
管理者として実行で Miniconda Prompt を起動します.
(2) PyTorch のインストール
【注意】 必ず公式サイトで Package に Conda を選択し,生成されたコマンドを使用してください.以下は CUDA 11.8 環境向けの 一例 です.
# 公式サイトで取得した conda install コマンドを実行
# 例 (CUDA 11.8):
conda install pytorch torchvision torchaudio pytorch-cuda=11.8 -c pytorch -c nvidia
-c pytorch -c nvidia は,PyTorch と NVIDIA の公式 conda チャネルを指定しています.
(3) インストールの確認
python -c "import torch; print(f'PyTorch Version: {torch.__version__}'); print(f'CUDA Available: {torch.cuda.is_available()}')"
関連情報
【サイト内の関連ページ】
【関連する外部ページ】
- PyTorch 公式サイト (インストール): https://pytorch.org/get-started/locally/
- PyTorch 公式サイト (トップ): https://pytorch.org/
Whisper のインストール(Windows 上)
FFmpeg のインストール(Windows 上)
Windows での FFmpeg のインストール(Windows 上): 別ページ »で説明
Whisperのインストール(Windows上)
- Windows で,管理者権限でコマンドプロンプトを起動(手順:Windowsキーまたはスタートメニュー >
cmdと入力 > 右クリック > 「管理者として実行」)。。 - Whisper本体をダウンロードしてインストールします。以下のコマンドを実行してください。
(注意:環境によっては依存関係のあるFFmpegのインストールも別途必要になる場合があります。)
python -m pip install -U openai-whisper

- (オプション)動作確認用ファイルの準備
ここでは例として、ホームディレクトリに必要なファイルをダウンロードします。Whisperの公式リポジトリをクローン(複製)することで、テスト用の音声ファイルなどを取得できます。
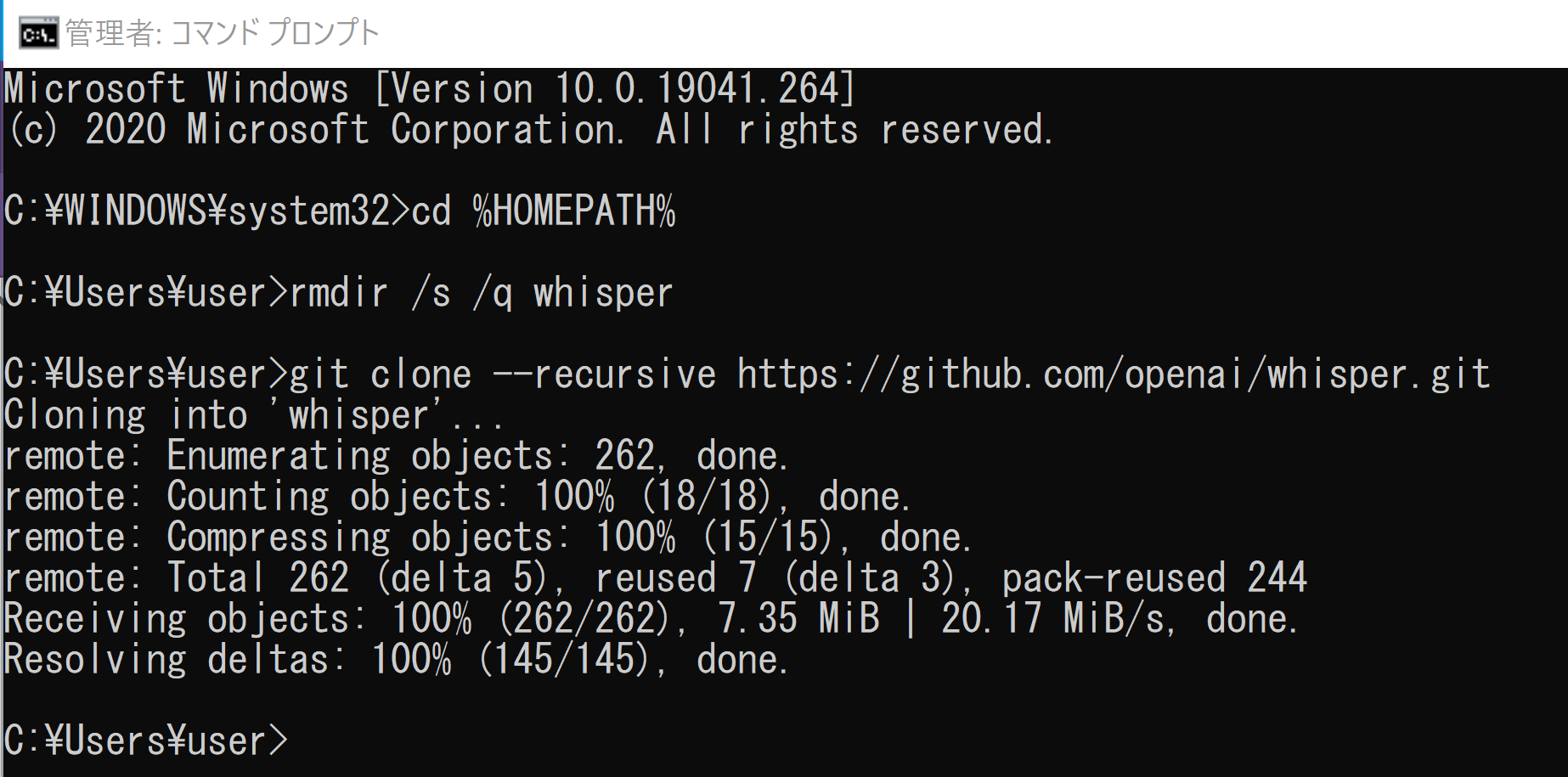
まず、ホームディレクトリに移動します。
cd /d c:%HOMEPATH%
もし以前に同じ名前の 'whisper' ディレクトリが存在する場合は、以下のコマンドで削除します。(注意:このコマンドは 'whisper' フォルダとその中身を完全に削除します。必要なファイルが含まれていないか確認してください。)
rmdir /s /q whisper
公式リポジトリをクローンします。
git clone --recursive https://github.com/openai/whisper.git
コマンドラインでのWhisperの基本的な使い方
インストールが完了したら、コマンドラインからWhisperを使ってみましょう。先ほど(オプションで)ダウンロードしたテスト用音声ファイル (`jfk.flac`) を使って、基本的な文字起こしを試してみます。
基本的なコマンドの書式は以下の通りです。
whisper <音声ファイルパス> --model <モデルサイズ> --language <言語>
- <音声ファイルパス>:文字起こししたい音声ファイルのパスを指定します。(例: `%HOMEPATH%\whisper\tests\jfk.flac`)。MP3, WAV, M4A, MP4など様々な形式に対応しています。
- --model <モデルサイズ>:使用するモデルのサイズを指定します。
tiny,base,small,medium,large(または `large-v2`, `large-v3` など最新版) があります。モデルが大きいほど精度は高くなりますが、計算リソース(メモリ、時間)も多く必要になります。tiny.en,base.en,small.en,medium.enといった英語専用モデルもあります。 - --language <言語>:音声の言語を指定します(例:
English,Japanese)。指定しない場合、Whisperが自動検出を試みますが、明示的に指定する方が確実です。対応言語は多数あります(例:Chinese,German,Spanish,Russian,Korean,Frenchなど)。
- 次のコマンドを実行して文字起こしを行います。
実行すると、文字起こし結果がコンソールに表示され、同時に音声ファイルと同じディレクトリにテキストファイル(`.txt`, `.vtt`, `.srt`など)としても保存されます。
smallモデル, English で実行する場合:
whisper %HOMEPATH%/whisper/tests/jfk.flac --model small --language English

largeモデル, Japanese で実行する場合(もし日本語音声ファイルがあれば):
(注意:jfk.flacは英語の音声ファイルのため、Japaneseを指定しても英語として認識される可能性が高いです。日本語の音声ファイルでお試しください。)whisper <日本語音声ファイルのパス> --model large --language Japanese
(例:`%HOMEPATH%/whisper/tests/jfk.flac` を large, Japanese で実行した場合の表示例)
whisper %HOMEPATH%/whisper/tests/jfk.flac --model large --language Japanese
- (補足)音声ファイルの再生
Windowsでは、コマンドプロンプトから以下のようにパスを指定して実行すると、関連付けられたアプリケーションで音声ファイルが再生される場合があります。(環境によります)
あるいは、エクスプローラーでファイルを直接ダブルクリックして再生することもできます。
%HOMEPATH%\whisper\tests\jfk.flac

4. PythonプログラムからのWhisper利用
コマンドラインだけでなく、PythonスクリプトからWhisperライブラリを直接利用することも可能です。これにより、他のプログラムと連携させたり、より複雑な処理を行ったりすることができます。ここでは、ファイル選択ダイアログで選んだ複数の音声ファイルを順番に文字起こしする簡単な例を示します。
- Pythonスクリプトの作成
まず、作業用のディレクトリに移動し、テキストエディタでPythonスクリプトファイルを作成します。ここでは例として、先ほど `git clone` した `whisper` ディレクトリ内に `small.py` という名前で作成します。(別の場所、別のファイル名でも構いません)
Windows で コマンドプロンプト を起動し、以下を実行します。
cd /d c:%HOMEPATH%\whisper notepad small.py
- プログラムコードの入力
開いたエディタ(メモ帳)に、以下のPythonコードをコピー&ペーストして保存します。
このプログラムは、公式の GitHub のページ: https://github.com/openai/whisperで公開されているサンプルコードを参考に、ファイル選択機能などを追加したものです。
import whisper # 使用するモデルをロード(初回はダウンロードが実行される) # "tiny", "base", "small", "medium", "large"などを指定可能 model = whisper.load_model("small") # ファイル選択ダイアログ表示のためのライブラリをインポート import tkinter as tk from tkinter import filedialog # ファイル選択ダイアログの準備 root = tk.Tk() root.withdraw() # 空のTkinterウィンドウを非表示にする # ファイル選択ダイアログを開き、複数選択を可能にする fpaths = filedialog.askopenfilenames() # 選択された各ファイルに対して処理を実行 for fpath in root.tk.splitlist(fpaths): print("Processing file: ", fpath) # 文字起こしを実行(言語を日本語に指定) # 必要に応じて language="english" などに変更 result = model.transcribe(fpath, language="japanese") # 結果のテキスト部分を表示 print("Transcription:") print(result["text"]) print("-" * 20) # ファイルごとの区切り線コードの簡単な説明:
import whisper: Whisperライブラリを使えるようにします。model = whisper.load_model("small"): 使用するWhisperモデル(ここでは "small")をメモリに読み込みます。指定したモデルがローカルにない場合、自動的にダウンロードされます。import tkinter ...: ファイル選択ダイアログを表示するための準備です。Pythonの標準ライブラリを使用しています。fpaths = filedialog.askopenfilenames(): ファイル選択ダイアログを表示し、ユーザーが選択したファイル(複数可)のパスを取得します。for fpath in ...: 選択されたファイルパスのリストを一つずつ取り出し、ループ処理を行います。result = model.transcribe(fpath, language="japanese"): 各ファイルパス (`fpath`) をWhisperの `transcribe` メソッドに渡し、文字起こしを実行します。ここでは言語を日本語 (`language="japanese"`) に指定していますが、英語の場合は `language="english"` などと指定します。言語を指定しない場合は自動検出されます。print(result["text"]): 文字起こし結果(辞書形式)の中から、テキスト部分 (`"text"`) を取り出してコンソールに出力します。
- Python プログラムの実行
作成したPythonスクリプトを実行するには、コマンドプロンプトでスクリプトを保存したディレクトリ(この例では `c:%HOMEPATH%\whisper`)にいることを確認し、以下のコマンドを実行します。
python small.py
コマンドを実行するとファイル選択ダイアログが表示されるので、文字起こししたい音声ファイルを選択してください(Ctrlキーを押しながらクリックすると複数選択できます)。
Python実行環境について:
- Windows では通常 python コマンドを使用します。(環境によっては Python ランチャーの py コマンドも利用可能です)
- Ubuntu などのLinux環境やmacOSでは python3 コマンドを使用するのが一般的です。
Python 開発環境(Jupyter Qt Console, Jupyter ノートブック (Jupyter Notebook), Jupyter Lab, Nteract, Spyder, PyCharm, PyScripterなど)を利用すると、コードの編集や実行、デバッグがより効率的に行えます。
Python のより詳しい情報: 別ページ »
- 実行結果の確認
ファイル選択後、選択されたファイルの処理が順番に行われ、完了すると各ファイルの文字起こし結果がコマンドプロンプトの画面に出力されます。
