Pandas データフレームの集計・集約(グループごとの数え上げ,最大,最小,平均,中央値,和)(Python, pandas, matplotlib, seaborn, Iris データセット, titanic データセットを使用)(Google Colaboratory へのリンクあり)
1. エグゼクティブサマリー
Python の pandas データフレームを用いたグループごとの集計・集約(数え上げ,最大,最小,平均,中央値,和)について,プログラム例で説明する.
特定の列でグループを作り,各グループの要素数,最大,最小,平均,中央値,和を求める.集計には pandas の groupby を使用し,データセットとして Iris および titanic を用いる.
この資料の URL: https://www.kkaneko.jp/cc/od/group.html
【目次】
Google Colaboratory のページ:
https://colab.research.google.com/drive/1UxKjDODi08fFwuJu9MC9wiykD4zbmxHh?usp=sharing
2. 前準備(必要ソフトウェアの入手)
ここでは、最低限の事前準備について説明する。機械学習や深層学習を行う場合は、NVIDIA CUDA、Visual Studio、Cursorなどを追加でインストールすると便利である。これらについては別ページ https://www.kkaneko.jp/cc/dev/aiassist.htmlで詳しく解説しているので、必要に応じて参照してください。
Python 3.12 のインストール(Windows 上) [クリックして展開]
以下のいずれかの方法で Python 3.12 をインストールする。Python がインストール済みの場合、この手順は不要である。
方法1:winget によるインストール
管理者権限のコマンドプロンプトで以下を実行する。管理者権限のコマンドプロンプトを起動するには、Windows キーまたはスタートメニューから「cmd」と入力し、表示された「コマンドプロンプト」を右クリックして「管理者として実行」を選択する。
winget install --id Python.Python.3.12 -e --scope machine --silent --accept-source-agreements --accept-package-agreements --override "/quiet InstallAllUsers=1 PrependPath=1 Include_test=0 Include_pip=1 Include_launcher=1 InstallLauncherAllUsers=1 TargetDir=\"C:\Program Files\Python312\""
powershell -Command "$p='C:\Program Files\Python312'; $s=\"$p\Scripts\"; $m=[Environment]::GetEnvironmentVariable('Path','Machine'); if($m -notlike \"*$s*\") { [Environment]::SetEnvironmentVariable('Path', \"$p;$s;$m\", 'Machine') }"--scope machine を指定することで、システム全体(全ユーザー向け)にインストールされる。このオプションの実行には管理者権限が必要である。インストール完了後、コマンドプロンプトを再起動すると PATH が自動的に設定される。
方法2:インストーラーによるインストール
- Python 公式サイト(https://www.python.org/downloads/)にアクセスし、「Download Python 3.x.x」ボタンから Windows 用インストーラーをダウンロードする。
- ダウンロードしたインストーラーを実行する。
- 初期画面の下部に表示される「Add python.exe to PATH」に必ずチェックを入れてから「Customize installation」を選択する。このチェックを入れ忘れると、コマンドプロンプトから
pythonコマンドを実行できない。 - 「Install Python 3.xx for all users」にチェックを入れ、「Install」をクリックする。
インストールの確認
コマンドプロンプトで以下を実行する。
python --versionバージョン番号(例:Python 3.12.x)が表示されればインストール成功である。「'python' は、内部コマンドまたは外部コマンドとして認識されていません。」と表示される場合は、インストールが正常に完了していない。
AIエディタ Windsurf のインストール(Windows 上) [クリックして展開]
Pythonプログラムの編集・実行には、AIエディタの利用を推奨する。ここでは、Windsurfのインストールを説明する。Windsurf がインストール済みの場合、この手順は不要である。
管理者権限のコマンドプロンプトで以下を実行する。管理者権限のコマンドプロンプトを起動するには、Windows キーまたはスタートメニューから「cmd」と入力し、表示された「コマンドプロンプト」を右クリックして「管理者として実行」を選択する。
winget install --scope machine --id Codeium.Windsurf -e --silent --disable-interactivity --force --accept-source-agreements --accept-package-agreements --custom "/SP- /SUPPRESSMSGBOXES /NORESTART /CLOSEAPPLICATIONS /DIR=""C:\Program Files\Windsurf"" /MERGETASKS=!runcode,addtopath,associatewithfiles,!desktopicon"
powershell -Command "$env:Path=[System.Environment]::GetEnvironmentVariable('Path','Machine')+';'+[System.Environment]::GetEnvironmentVariable('Path','User'); windsurf --install-extension MS-CEINTL.vscode-language-pack-ja --force; windsurf --install-extension ms-python.python --force; windsurf --install-extension Codeium.windsurfPyright --force"--scope machine を指定することで、システム全体(全ユーザー向け)にインストールされる。このオプションの実行には管理者権限が必要である。インストール完了後、コマンドプロンプトを再起動すると PATH が自動的に設定される。
【関連する外部ページ】
Windsurf の公式ページ: https://windsurf.com/
必要なライブラリのインストール [クリックして展開]
管理者権限のコマンドプロンプトで以下を実行する.起動するには,Windows キーまたはスタートメニューから「cmd」と入力し,表示された「コマンドプロンプト」を右クリックして「管理者として実行」を選択する.
python -m pip install -U pip setuptools numpy pandas matplotlib seaborn scikit-learn scikit-learn-intelex
3. 実行のための準備とその確認手順(Windows 前提)
3.1 プログラムファイルの準備
第5章のソースコードをテキストエディタ(メモ帳,Windsurf 等)に貼り付け,group.py として保存する(文字コード:UTF-8).
3.2 実行コマンド
コマンドプロンプトでファイルの保存先ディレクトリに移動し,以下を実行する.
python group.py3.3 動作確認チェックリスト
| 確認項目 | 期待される結果 |
|---|---|
| iris データセットの読み込み | iris.head() で sepal_length,sepal_width,petal_length,petal_width,species の5列が表示される |
| titanic データセットの読み込み | titanic.head() で survived,pclass,sex,age 等の列が表示される |
| iris のグループごとの数え上げ | iris.groupby('species').size() で setosa,versicolor,virginica の要素数が表示される |
| titanic のグループごとの数え上げ | titanic.groupby('embark_town').size() で Cherbourg,Queenstown,Southampton の要素数が表示される |
| iris のグループごとの集計 | iris.groupby('species') に対し max,min,mean,median,sum の各結果が表示される |
| titanic のグループごとの集計 | titanic.groupby('embark_town') に対し max,min,mean,median,sum の各結果が表示される |
4. 概要・使い方・実行上の注意
4.1 Iris データセット,titanic データセットの準備
seaborn の load_dataset 関数で iris および titanic を読み込む.読み込んだデータは pandas のデータフレームとなる.head() で先頭行を表示し,内容を確認する.
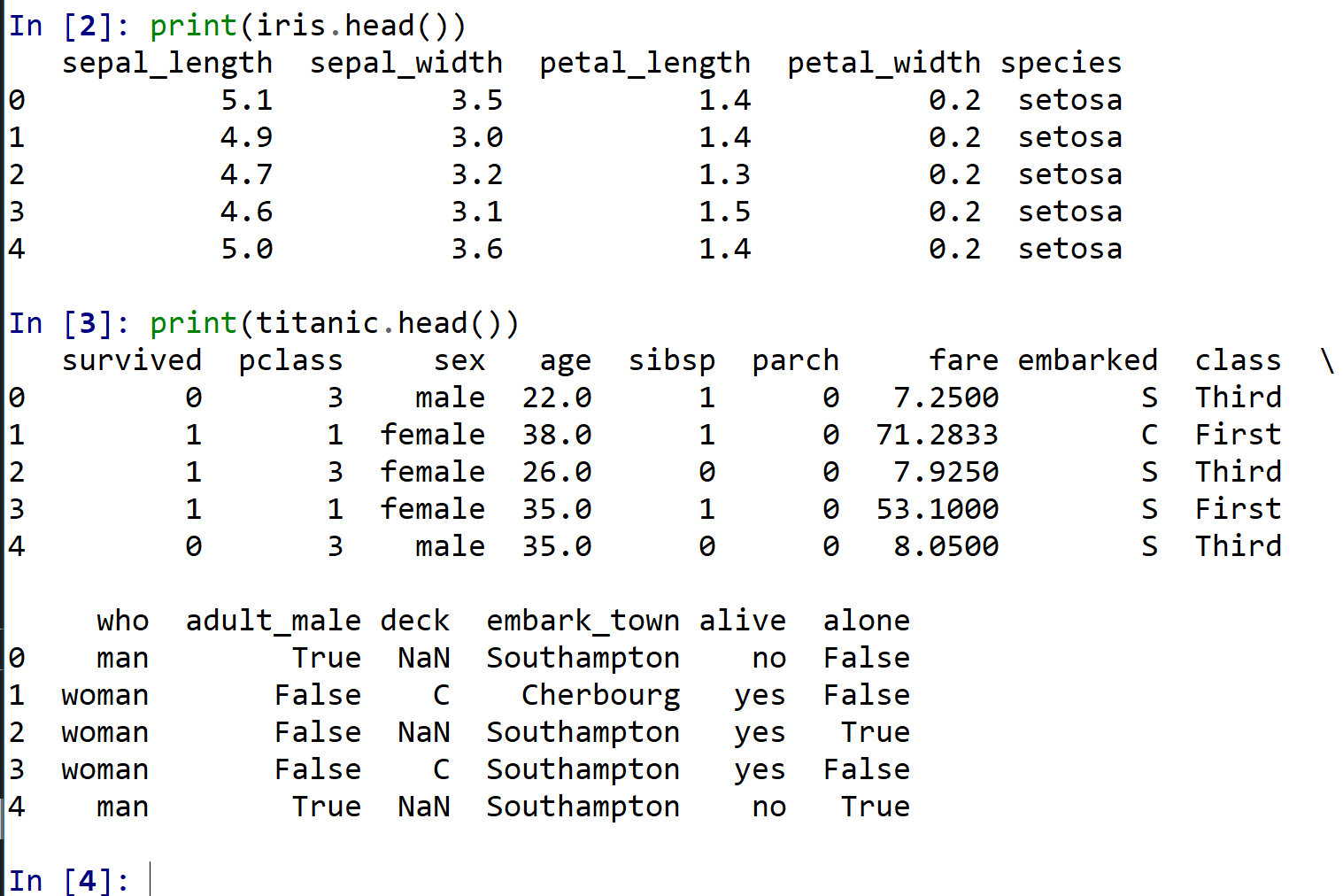
4.2 グループごとの数え上げ
特定の列でグループを作り,各グループの要素数を求める.
groupby でグループ化し,size() で各グループの要素数を取得する.iris では 'species' 列,titanic では 'embark_town' 列でグループ化する.
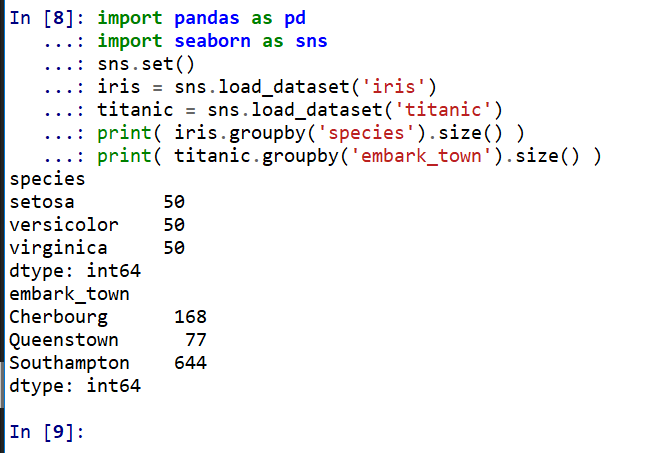
value_counts でも同等の結果が得られるが,デフォルトで降順にソートされる点が異なる.
4.3 グループごとの最大,最小,平均,中央値,和
特定の列でグループを作り,各グループの最大,最小,平均,中央値,和を求める.
groupby でグループ化し,max(),min(),mean(),median(),sum() で集計する.numeric_only=True を指定すると,数値列のみが対象となる.pandas 2.0 以降では,この引数を省略すると FutureWarning が発生するため,指定を推奨する.
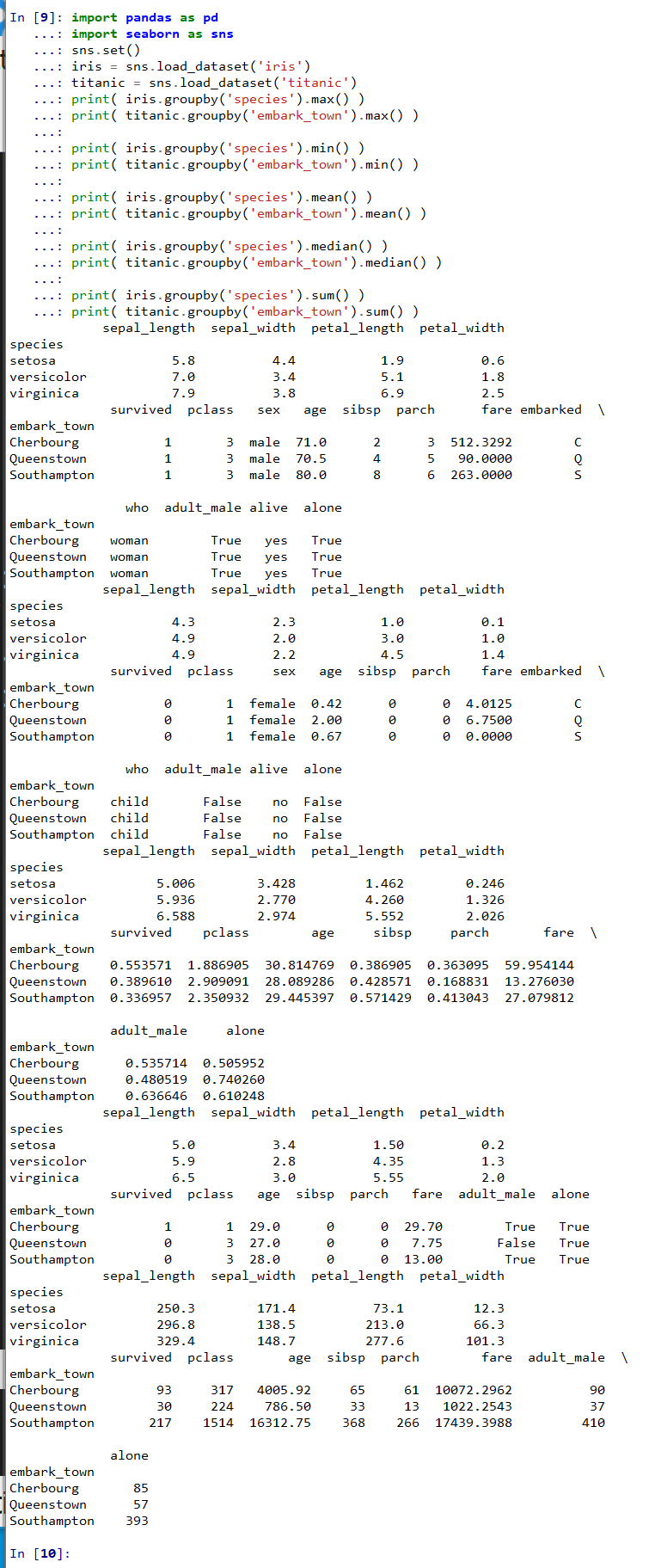
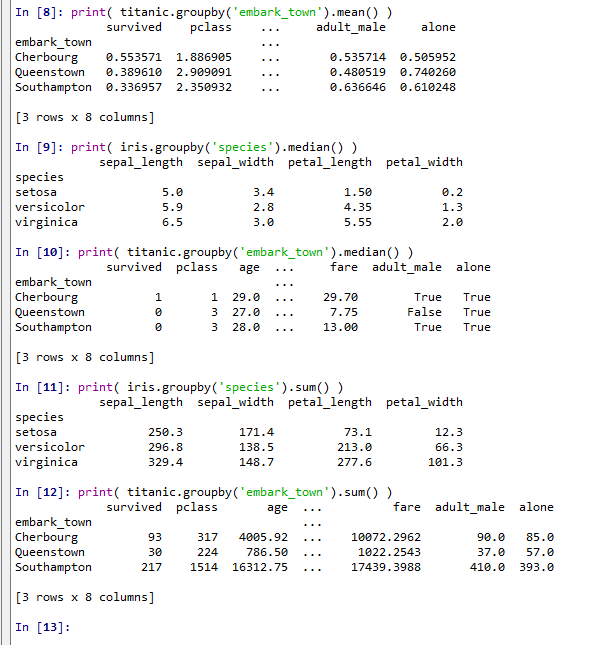
agg メソッドを使うと,複数の集計関数を一度に適用できる.集計関数をリストで指定することで,1回の呼び出しで結果を得られる.
5. ソースコード
5.1 iris,titanic データセットの読み込み
import pandas as pd
import seaborn as sns
sns.set()
iris = sns.load_dataset('iris')
titanic = sns.load_dataset('titanic')
5.2 データの確認
print(iris.head())
print(titanic.head())
5.3 グループごとの数え上げ(groupby と size を使用)
import pandas as pd
import seaborn as sns
sns.set()
iris = sns.load_dataset('iris')
titanic = sns.load_dataset('titanic')
print( iris.groupby('species').size() )
print( titanic.groupby('embark_town').size() )
5.4 グループごとの数え上げ(value_counts を使用)
import pandas as pd
import seaborn as sns
iris = sns.load_dataset('iris')
titanic = sns.load_dataset('titanic')
print(iris['species'].value_counts())
print(titanic['embark_town'].value_counts())
5.5 グループごとの最大,最小,平均,中央値,和
import pandas as pd
import seaborn as sns
sns.set()
iris = sns.load_dataset('iris')
titanic = sns.load_dataset('titanic')
print( iris.groupby('species').max(numeric_only=True) )
print( titanic.groupby('embark_town').max(numeric_only=True) )
print( iris.groupby('species').min(numeric_only=True) )
print( titanic.groupby('embark_town').min(numeric_only=True) )
print( iris.groupby('species').mean(numeric_only=True) )
print( titanic.groupby('embark_town').mean(numeric_only=True) )
print( iris.groupby('species').median(numeric_only=True) )
print( titanic.groupby('embark_town').median(numeric_only=True) )
print( iris.groupby('species').sum(numeric_only=True) )
print( titanic.groupby('embark_town').sum(numeric_only=True) )
5.6 複数の集計を一括で行う(agg を使用)
import pandas as pd
import seaborn as sns
iris = sns.load_dataset('iris')
titanic = sns.load_dataset('titanic')
print(iris.groupby('species').agg(['max', 'min', 'mean', 'median', 'sum']))
print(titanic.groupby('embark_town')[['age', 'fare']].agg(['max', 'min', 'mean', 'median', 'sum']))
6. まとめ
6.1 pandas の groupby によるグループ化
groupby を使うと,データフレームの特定の列を基準にグループを作れる.iris では 'species' 列,titanic では 'embark_town' 列でグループ化を行った.
6.2 グループごとの数え上げ
groupby と size() の組み合わせで各グループの要素数を求められる.value_counts でも同等の結果が得られるが,デフォルトで降順ソートされる点が異なる.
6.3 グループごとの集計(最大,最小,平均,中央値,和)
groupby の後に max(),min(),mean(),median(),sum() を呼び出すことで集計できる.numeric_only=True を指定すると,数値列のみが対象となる.
6.4 agg による一括集計
agg を使うと,複数の集計関数を一度に適用できる.集計関数をリストで指定することで,1回の呼び出しで結果を得られる.
6.5 seaborn によるデータセットの読み込み
seaborn の load_dataset で iris および titanic を pandas のデータフレームとして読み込める.head() で先頭行を表示し,内容を確認できる.