Iris データセットの次元削減(t-SNE, Isomap, Spectral Embedding, LLE 法)(Python, scikit-learn を使用)
1. サマリー
本記事では、Iris データセットの4つの数値特徴量を2次元に変換し、散布図で可視化する。使用する次元削減手法は、t-SNE、Isomap、Spectral Embedding、Locally Linear Embedding (LLE)、PCA の5種類であり、いずれも Python の scikit-learn で実装する。
t-SNE、Isomap、Spectral Embedding、LLE は非線形手法であり、scikit-learn の manifold モジュールに含まれる。PCA は線形手法であり、非線形手法との比較に用いる。scikit-learn の cheat sheet によれば、Isomap や Spectral Embedding で十分な結果が得られないときは LLE が候補になる。
2. 本資料の前提と注意
「次元」という語について: 本資料で次元削減の対象とする「次元」は、特徴量の数(Iris では sepal_length, sepal_width, petal_length, petal_width の4つ)を指す。これを2次元に圧縮して可視化する。一方、後出の iris.ndim が返す 2 は、pandas DataFrame が「行と列からなる表(2軸)」であることを表す DataFrame の軸数であり、特徴量の次元数(4)とは別の概念である。
対象とする手法: 本資料が扱う次元削減手法は t-SNE、Isomap、Spectral Embedding、LLE、PCA の5種類である。カーネル近似(RBFSampler 等の kernel approximation)は、RBF カーネルを近似する特徴写像であり、線形分類器の前処理として次元を増やす手法である(削減ではない)。2次元可視化に用いてもクラス構造を保持しないため、次元削減手法としては扱わない。
結果の再現性と読み方: t-SNE は乱数で初期化されるため、実行のたびに図が変わる。再現性を確保するには random_state を指定する。また t-SNE、Isomap、Spectral Embedding、LLE の軸には、PCA の主成分のような解釈可能な意味はない。軸の数値や点間の距離ではなく、同じ種類の花がまとまっているか(クラスタの分離)を見る。
動作環境: 本資料の手法とパッケージはすべて、Windows のパソコンで動作する(GPU の有無は問わない)。
3. 前準備(必要ソフトウェアの入手)
ここでは、最低限の事前準備について説明する。機械学習や深層学習を行う場合は、NVIDIA CUDA、Visual Studio、Cursor などを追加でインストールすると便利である。これらについては別ページ https://www.kkaneko.jp/cc/dev/aiassist.html で解説しているので、必要に応じて参照してください。
Python 3.12 のインストール
Pythonのインストールを行い、Pythonのプログラムを実行する環境を整える。扱う環境は、Windows搭載パソコンである。金子研究室では、Python 3.12.10を推奨する。
[Windows での Python 3.12 のインストール手順を見るには、ここをクリック]
Windows での Python 3.12 のインストール
以下のいずれかの方法でPython 3.12をインストールする。Pythonがインストール済みの場合、この手順は不要である。
方法 1:winget によるインストール
【インストールコマンドの実行方法】
管理者権限でコマンドプロンプトを起動する(手順:Windowsキーまたはスタートメニュー → cmd と入力 → 右クリック → 「管理者として実行」)。そして、コマンド全体をコマンドプロンプトにコピー&ペーストする。
--scope machine を指定することで、システム全体(全ユーザー向け)にインストールされる。このオプションの実行には管理者権限が必要である。インストール完了後、コマンドプロンプトを再起動するとPATHが反映される。
REM Python 3.12 をシステム領域にインストール
winget install --id Python.Python.3.12 -e --scope machine --silent --accept-source-agreements --accept-package-agreements --override "/quiet InstallAllUsers=1 PrependPath=1 Include_test=0 Include_pip=1 Include_launcher=1 InstallLauncherAllUsers=1 TargetDir=\"C:\Program Files\Python312\""
REM Python と Scripts を PATH 先頭に追加
powershell -NoProfile -Command "$p='C:\Program Files\Python312'; $s=\"$p\Scripts\"; $c=[Environment]::GetEnvironmentVariable('Path','Machine'); if((Test-Path $p) -and (';'+$c+';' -notlike \"*;$p;*\") -and (';'+$c+';' -notlike \"*;$s;*\")){[Environment]::SetEnvironmentVariable('Path',\"$p;$s;$c\",'Machine')}"
方法 2:インストーラーによるインストール
- Python公式サイト(https://www.python.org/downloads/)にアクセスし、「Download Python 3.x.x」ボタンからWindows用インストーラーをダウンロードする。
- ダウンロードしたインストーラーを実行する。
- 初期画面の下部に表示される「Add python.exe to PATH」にチェックを入れてから「Customize installation」を選択する。このチェックを入れ忘れると、コマンドプロンプトから
pythonコマンドを実行できない。 - 「Install Python 3.xx for all users」にチェックを入れ、「Install」をクリックする。
インストールの確認
コマンドプロンプトで以下を実行する。
python --versionバージョン番号(例:Python 3.12.x)が表示されればインストール成功である。「'python' は、内部コマンドまたは外部コマンドとして認識されていません。」と表示される場合は、インストールが正常に完了していない。
Python の開発環境 Visual Studio Code のインストールと Python 用の設定
Python の開発環境Visual Studio Code(プログラムを編集するソフトウェア。以下、VS Code)を整える。
[Windows での Visual Studio Code のインストールと Python 用の設定手順を見るには、ここをクリック]
Windows での Visual Studio Code のインストールと Python 用の設定手順
1. VS Code と拡張機能のインストール
以下のコマンドにより,既存の VS Code を削除し,全ユーザー共有の設定で再インストールしたうえで,拡張機能(VS Code に機能を追加するソフトウェア)をまとめて導入する.
【インストールコマンドの実行方法】
管理者権限でコマンドプロンプトを起動する(手順:Windows キーまたはスタートメニュー → cmd と入力 → 右クリック → 「管理者として実行」)。そして,コマンド全体をコマンドプロンプトにコピー&ペーストする。
インストールコマンド
REM ============================================================
REM Microsoft Visual Studio Code
REM ============================================================
winget uninstall -e --id Microsoft.VisualStudioCode --silent --disable-interactivity --accept-source-agreements
rmdir /s /q C:\ProgramData\vscode-extensions 2>nul
rmdir /s /q "%APPDATA%\Code" 2>nul
rmdir /s /q "%USERPROFILE%\.vscode" 2>nul
rmdir /s /q "%LOCALAPPDATA%\Microsoft\vscode-update" 2>nul
REM VS Code をシステム領域に新規インストール
winget install --scope machine --id Microsoft.VisualStudioCode -e --silent --accept-source-agreements --accept-package-agreements
REM 全ユーザー共有の拡張機能フォルダ
mkdir C:\ProgramData\vscode-extensions 2>nul
icacls "C:\ProgramData\vscode-extensions" /grant "Everyone:(OI)(CI)M" /T
REM スタートメニューのショートカットを --extensions-dir 付きで再作成
rmdir /s /q "C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code" 2>nul
del "C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code.lnk" 2>nul
powershell -NoProfile -Command "$s=New-Object -ComObject WScript.Shell; $lnk=$s.CreateShortcut('C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code.lnk'); $lnk.TargetPath='C:\Program Files\Microsoft VS Code\Code.exe'; $lnk.Arguments='--extensions-dir \"C:\ProgramData\vscode-extensions\"'; $lnk.Save()"
REM ショートカットの検証
powershell -NoProfile -Command "$s=New-Object -ComObject WScript.Shell; $lnk=$s.CreateShortcut('C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code.lnk'); Write-Host 'TargetPath:' $lnk.TargetPath; Write-Host 'Arguments:' $lnk.Arguments"
REM ファイル / フォルダ右クリックの「Code で開く」を登録
reg add "HKLM\SOFTWARE\Classes\*\shell\VSCode\command" /ve /d "\"C:\Program Files\Microsoft VS Code\Code.exe\" --extensions-dir \"C:\ProgramData\vscode-extensions\" \"%1\"" /f
reg add "HKLM\SOFTWARE\Classes\Directory\shell\VSCode\command" /ve /d "\"C:\Program Files\Microsoft VS Code\Code.exe\" --extensions-dir \"C:\ProgramData\vscode-extensions\" \"%1\"" /f
reg add "HKLM\SOFTWARE\Classes\Directory\Background\shell\VSCode\command" /ve /d "\"C:\Program Files\Microsoft VS Code\Code.exe\" --extensions-dir \"C:\ProgramData\vscode-extensions\" \"%V\"" /f
REM --extensions-dir 付きで起動する code.cmd ラッパを作成
REM (%* を echo で書くと対話的 cmd で失われるため、PowerShell で [char]37+'*' を書き出す)
powershell -NoProfile -Command "$pct=[char]37; $q=[char]34; $c='@echo off'+[char]13+[char]10+$q+'C:\Program Files\Microsoft VS Code\bin\code.cmd'+$q+' --extensions-dir '+$q+'C:\ProgramData\vscode-extensions'+$q+' '+$pct+'*'+[char]13+[char]10; [IO.File]::WriteAllText('C:\ProgramData\vscode-extensions\vscode.cmd',$c,[Text.Encoding]::ASCII)"
REM 拡張機能のインストール
set "CODE=C:\Program Files\Microsoft VS Code\bin\code.cmd"
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --uninstall-extension GitHub.copilot
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --uninstall-extension GitHub.copilot-chat
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension ms-python.python
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension ms-python.vscode-pylance
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension ms-python.debugpy
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension MS-CEINTL.vscode-language-pack-ja
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension saoudrizwan.claude-dev
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension rust-lang.rust-analyzer
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension tamasfe.even-better-toml
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension anthropic.claude-code
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension almenon.arepl
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --list-extensions --show-versions
echo === セットアップ完了 ===
2. Python インタプリタの選択
同一マシンに複数の Python がインストールされている場合,VS Code で使用する Python 本体(インタプリタ:Python プログラムを解釈・実行するソフトウェア)を選択する必要がある.
- コマンドパレット(コマンド名で機能を呼び出す VS Code の入力欄)を開く(
Ctrl+Shift+P) Python: Select Interpreterと入力する
- 表示される一覧から,使用する Python(例:
C:\Program Files\Python312\python.exe)を選択する.
Python プログラム実行手順
[Windows での Python プログラム実行手順を見るには、ここをクリック]
Windows での Python 実行手順(Visual Studio Codeを使用)
プログラムファイルの作成と保存
- 左サイドバーの「エクスプローラー」アイコン(
Ctrl+Shift+E)をクリックする
- 「NO FOLDER OPENED」(作業対象フォルダが未選択の状態)と表示される場合は,「Open Folder」をクリックし,プログラムを保存するフォルダを選択する
続いて「フォルダを信用するか」を確認する画面(フォルダ内のコードを実行してよいか確認する VS Code の仕組み)が表示されるので,チェックして Yes を選択する
- フォルダ名の右側に表示される「新しいファイル」アイコンをクリックする
- ファイル名(例:
aitask.py.ファイル名は何でも良い)を入力しEnterを押す.拡張子は.py(Python ファイルを示す拡張子)とする
- 実行したいコードを選択し,
Ctrl+Cでコピーする.VS Code のエディタ領域にCtrl+Vで貼り付ける Ctrl+Sで保存する
プログラムの実行
- エディタ右上の三角形「▷」アイコン(Run Python File:現在開いている Python ファイルを実行するボタン)をクリックする.または,エディタ上で右クリックし「ターミナルで Python ファイルを実行」を選択する
- VS Code 下部のターミナル(コマンドの入出力を表示する画面)に,実行結果(
print関数の出力等)が表示される
- tkinter(Python 標準の GUI ライブラリ)のファイル選択ダイアログを使うプログラムを実行した場合は,ダイアログが開くので対象画像を選択する
- VS Code 下部のターミナルで実行結果を確認する.OpenCV ウィンドウ(OpenCV が画像を表示するために開く専用ウィンドウ)が開いた場合はそちらも確認する.OpenCV ウィンドウは,マウスクリックでウィンドウをアクティブ(操作対象の状態)にしてからキーを押すと終了する


必要なライブラリのインストール [クリックして展開]
管理者権限のコマンドプロンプトで以下を実行する。管理者権限のコマンドプロンプトは、Windows キーまたはスタートメニューから「cmd」と入力し、表示された「コマンドプロンプト」を右クリックして「管理者として実行」を選択して起動する。
python -m pip install -U pip setuptools numpy pandas matplotlib seaborn scikit-learn
上記のパッケージはいずれも Windows(x86-64 CPU)で動作し、CPU のみで完結する。scikit-learn-intelex(Intel Extension for Scikit-learn)は scikit-learn の処理を高速化する拡張で、Windows の x86-64 環境(Intel/AMD の64bit CPU。Intel GPU も可)でサポートされている。本記事のデータは 150 件と少なく速度差はほとんど無いため、導入は任意である。高速化を試す場合のみ、次を追加でインストールする。
python -m pip install -U scikit-learn-intelex
4. 実行のための準備とその確認手順(Windows 前提)
4.1 プログラムファイルの準備
本記事のプログラムは Jupyter Notebook 形式でセルごとに逐次実行する。第6章のソースコードを順番にセルへ入力して実行する。Windsurf 等のエディタで Jupyter Notebook を新規作成し、iris_dim_reduction.ipynb として保存する(文字コード:UTF-8)。
4.2 実行コマンド
Windsurf や Jupyter Notebook の GUI からセルを順に実行する。コマンドプロンプトから起動する場合は、ファイルの保存先ディレクトリに移動し、以下を実行する。
jupyter notebook iris_dim_reduction.ipynb4.3 動作確認チェックリスト
| 確認項目 | 期待される結果 |
|---|---|
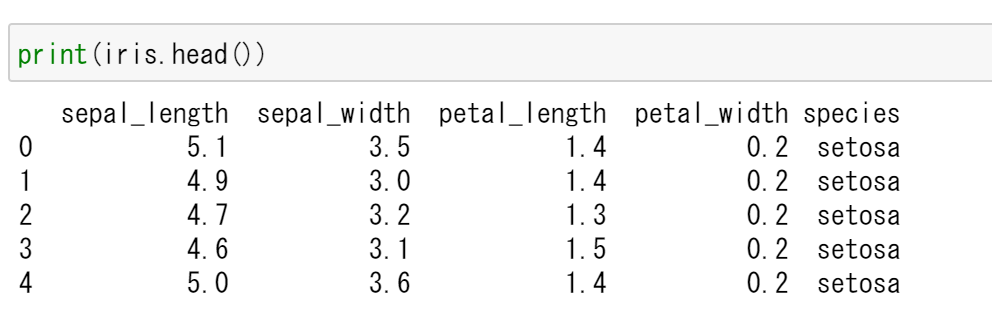
| Iris データセットの読み込み | iris.head() で sepal_length, sepal_width, petal_length, petal_width, species の5列が表示される |
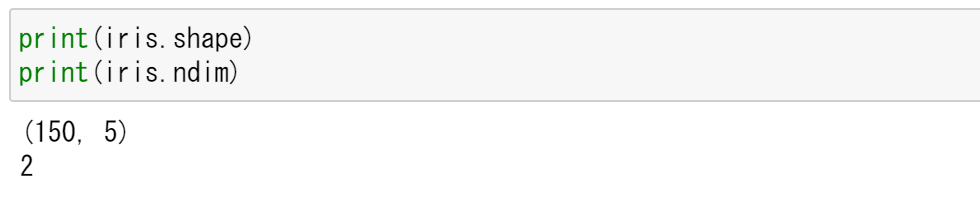
| データの形と軸数の確認 | iris.shape が (150, 5)(150 行・5 列)を返す。iris.ndim が返す 2 は表(行・列の2軸)を意味する DataFrame の軸数であり、特徴量の次元数(4)とは別概念である |
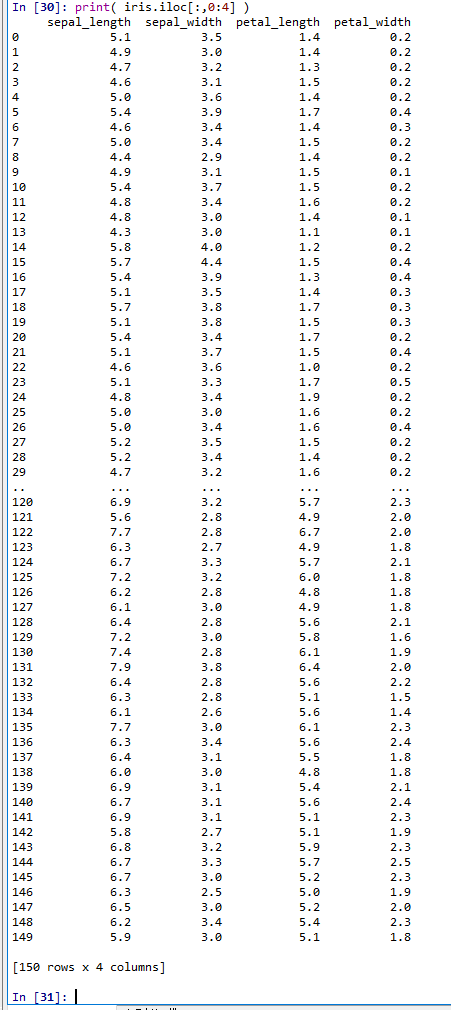
| 0, 1, 2, 3 列目の表示 | iris.iloc[:, 0:4] で 150 行 × 4 列の数値データ(4つの特徴量)が表示される |
| t-SNE による次元削減 | 2次元配列が出力され、3種の花が色分けされた散布図が表示される |
| Isomap による次元削減 | 2次元配列が出力され、3種の花が色分けされた散布図が表示される |
| Spectral Embedding による次元削減 | 2次元配列が出力され、3種の花が色分けされた散布図が表示される |
| LLE による次元削減 | 2次元配列が出力され、3種の花が色分けされた散布図が表示される |
| PCA による次元削減 | 2次元配列が出力され、3種の花が色分けされた散布図が表示される |
5. 概要・使い方・実行上の注意
5.1 Iris データセット
Iris データセットは seaborn の load_dataset 関数で読み込む。形は 150 行 × 5 列である。最後の列 species は花の種類を表すラベルである。次元削減の対象は 0〜3 列目(sepal_length, sepal_width, petal_length, petal_width)の4つの数値特徴量であり、この4次元を2次元に変換して散布図で可視化する。
5.2 散布図プロット関数
各手法の結果を可視化するため、共通の関数 scatter_label_plot を定義する。変換後の行列 M の先頭2列を散布図にプロットし、ラベル b で色分けする。凡例には花の種類の文字列を用いる。
5.3 各次元削減手法
共通の注意:t-SNE、Isomap、Spectral Embedding、LLE は点間の距離や近傍関係に基づく手法であり、特徴量のスケールに影響される。Iris は4特徴量のスケール差が小さいため本記事では標準化を省略するが、スケール差の大きいデータでは StandardScaler で標準化してから適用する。これらの手法の出力の軸には解釈可能な意味はなく、クラスタの分離を見る。
t-SNE:sklearn.manifold.TSNE を使用する。n_components=2 を指定し、fit_transform で変換する。乱数初期化に影響されるため、再現性確保のために random_state を指定する。パラメータ perplexity(既定 30)は標本数より小さくする必要がある(推奨範囲はおよそ 5〜50。標本数は近傍の数の目安)。Iris は 150 件なので既定値のまま動作するが、少数のサブセットで試す場合は perplexity を小さくする。
Isomap:sklearn.manifold.Isomap を使用する。n_components=2, n_neighbors=10(n_neighbors は近傍とみなす点の数)を指定し、fit_transform で変換する。
Spectral Embedding:sklearn.manifold.SpectralEmbedding を使用する。n_components=2, n_neighbors=10 を指定し、fit_transform で変換する。
LLE:sklearn.manifold.LocallyLinearEmbedding を使用する。n_components=2, n_neighbors=10 を指定し、fit_transform で変換する。scikit-learn の cheat sheet によれば、Isomap や Spectral Embedding で十分な結果が得られないときの候補である。
PCA(線形手法との比較):上記はいずれも非線形手法である。比較のため、線形手法である PCA(主成分分析)を用いる。PCA は分散が最大となる方向に射影する手法である。sklearn.decomposition.PCA を使用し、n_components=2 を指定する。
6. ソースコード
6.1 Iris データセットの読み込み
import pandas as pd
import seaborn as sns
sns.set_theme()
iris = sns.load_dataset('iris')

6.2 データの確認
print(iris.head())
6.3 形と軸数の確認
print(iris.shape) # (150, 5) … 150 行 5 列
print(iris.ndim) # 2 … 表(行・列の2軸)。特徴量の次元数(4)ではない
6.4 Iris データセットの 0, 1, 2, 3 列目の表示
print( iris.iloc[:,0:4] ) # 次元削減の対象となる4つの特徴量
6.5 散布図プロット関数の定義
import numpy as np
%matplotlib inline
import matplotlib.pyplot as plt
def scatter_label_plot(M, b, alpha):
a12 = pd.DataFrame(M[:, 0:2], columns=['a1', 'a2'])
a12['target'] = np.asarray(b)
n_classes = a12['target'].nunique()
sns.scatterplot(x='a1', y='a2', hue='target', data=a12,
palette=sns.color_palette("hls", n_classes),
legend="full", alpha=alpha)
plt.show()
6.6 t-SNE 法による次元削減
from sklearn.manifold import TSNE
d = TSNE(n_components=2, random_state=0).fit_transform(iris.iloc[:, 0:4])
print(d)
scatter_label_plot(d, iris.iloc[:, 4], 1)
6.7 Isomap 法による次元削減
from sklearn.manifold import Isomap
d = Isomap(n_components=2, n_neighbors=10).fit_transform(iris.iloc[:, 0:4])
print(d)
scatter_label_plot(d, iris.iloc[:, 4], 1)
6.8 Spectral Embedding 法による次元削減
from sklearn.manifold import SpectralEmbedding
d = SpectralEmbedding(n_components=2, n_neighbors=10).fit_transform(iris.iloc[:, 0:4])
print(d)
scatter_label_plot(d, iris.iloc[:, 4], 1)
6.9 LLE 法による次元削減
from sklearn.manifold import LocallyLinearEmbedding
d = LocallyLinearEmbedding(n_components=2, n_neighbors=10).fit_transform(iris.iloc[:, 0:4])
print(d)
scatter_label_plot(d, iris.iloc[:, 4], 1)
6.10 PCA 法による次元削減(線形手法との比較)
from sklearn.decomposition import PCA
d = PCA(n_components=2).fit_transform(iris.iloc[:, 0:4])
print(d)
scatter_label_plot(d, iris.iloc[:, 4], 1)
7. 演習
演習1.5手法の散布図の比較
手順
- 第6章のコードを 6.1 から 6.10 まで順に実行する。
- t-SNE、Isomap、Spectral Embedding、LLE、PCA の5つの散布図を並べて表示する。
ヒント
各手法のコードは scatter_label_plot(d, iris.iloc[:, 4], 1) で散布図を表示する。表示された図を保存して並べる。
考察ポイント
3種類の花(setosa, versicolor, virginica)が、どの手法で最も分離して表示されるかを読み取る。setosa が他の2種から離れて表示されるか、versicolor と virginica が重なるかを比較する。
演習2.t-SNE の random_state による結果の違い
手順
- 6.6 のコードで
random_state=0をrandom_state=1に変更して実行する。 - 続けて
random_state=2に変更して実行する。 - 3つの散布図を比較する。
ヒント
変更するのは TSNE(n_components=2, random_state=0) の random_state の値のみである。
考察ポイント
散布図の全体の向きや位置が random_state ごとに変わる一方で、3種類の花のまとまり(クラスタ)の分離関係は保たれることを読み取る。軸の数値そのものに意味がないことを確認する。
演習3.Isomap の n_neighbors による結果の違い
手順
- 6.7 のコードで
n_neighbors=10をn_neighbors=5に変更して実行する。 - 続けて
n_neighbors=30に変更して実行する。 - 3つの散布図を比較する。
ヒント
変更するのは Isomap(n_components=2, n_neighbors=10) の n_neighbors の値のみである。
考察ポイント
n_neighbors を小さくすると局所的な構造が、大きくすると全体的な構造が反映される。クラスタの分離の度合いが n_neighbors によってどう変わるかを読み取る。
8. まとめ
t-SNE
TSNE で n_components=2 を指定し、4次元の Iris データを2次元に変換する。局所的な構造を保持する非線形手法である。乱数に影響されるため random_state を指定して再現性を確保する。
Isomap
Isomap で n_components=2, n_neighbors=10 を指定する。測地線距離(データ点を近傍グラフ上でたどったときの最短経路距離)を保持する非線形手法である。
Spectral Embedding と LLE
SpectralEmbedding と LocallyLinearEmbedding をそれぞれ n_components=2, n_neighbors=10 で使用する。scikit-learn の cheat sheet によれば、Isomap や Spectral Embedding で十分な結果が得られないときは LLE が候補になる。
PCA(線形手法との比較)
非線形手法との比較のために PCA を使用する。分散が最大となる方向に射影する線形手法である。