PostgreSQL への CSV ファイルインポートと性能確認手順
CSV ファイルインポートとは:CSVファイルをリレーショナルデータベースのテーブルにインポートする.
- ここで扱う CSV ファイルは, 先頭行には,各列の属性名が書かれているものとする.
- 1つのCSVファイルを1つのテーブルにインポートする.
- CSVファイルのレコードの中の値の順序は維持する.
このページで紹介しているソフトウェア類の利用条件等は,利用者で確認すること.
前準備
- テスト用に使うCSV データの合成: 別ページ »で説明
SQLite 3 について: 別ページ »にまとめ
PostgreSQL のインストール
PostgreSQL の利用: 別ページ »にまとめ
- Windows での PostgreSQL のインストール: 別ページ »で説明
- Ubuntu での PostgreSQL のインストール: 別ページ »で説明
SQLite 3 での CSV ファイルインポート性能
CSV ファイルインポートのテスト実行(SQLite 3 を使用)
次のように設定して実行すること.
- 「T1000M_1.csv」のところは CSV ファイル名
- 「T1000M_1」のところはテーブル名
- 「T1000M_1.db」のところは SQLite 3 データベース名
エラーメッセージが出ないことを確認.
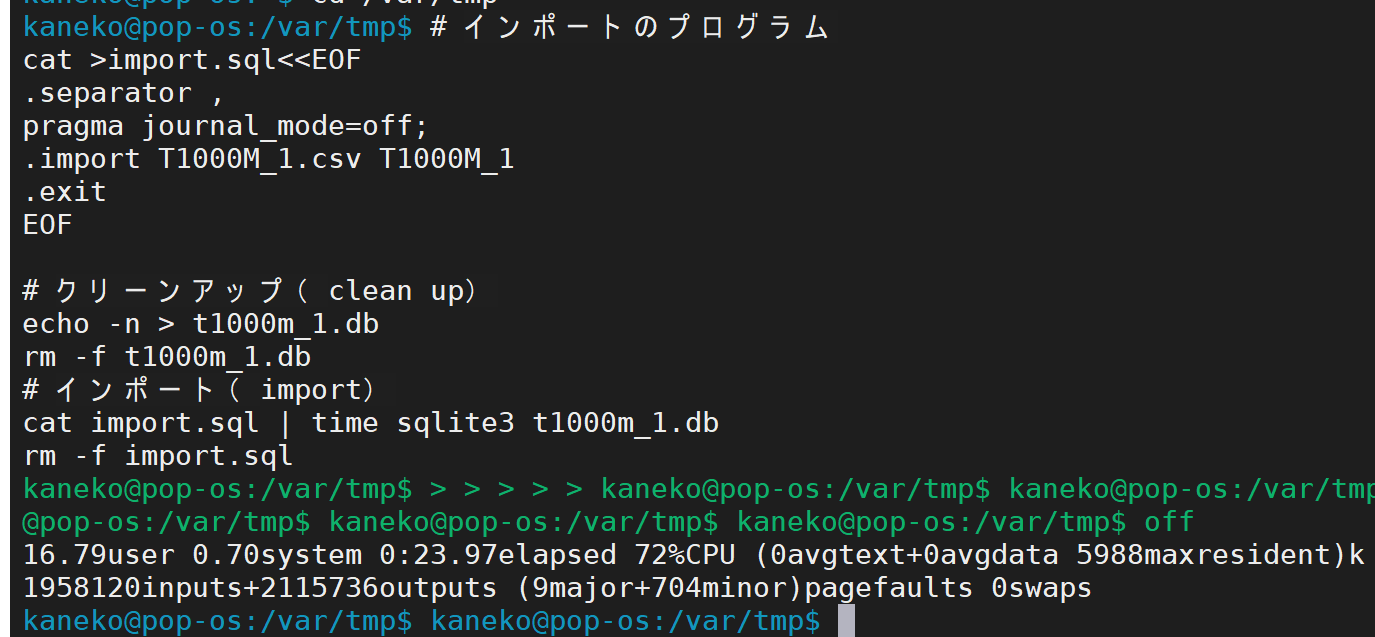
cat >import.sql<<EOF
.separator ,
pragma journal_mode=off;
.import T1000M_1.csv T1000M_1
.exit
EOF
echo -n > T1000M_1.db
rm -f T1000M_1.db
cat import.sql | time sqlite3 T1000M_1.db
rm -rf import.sql
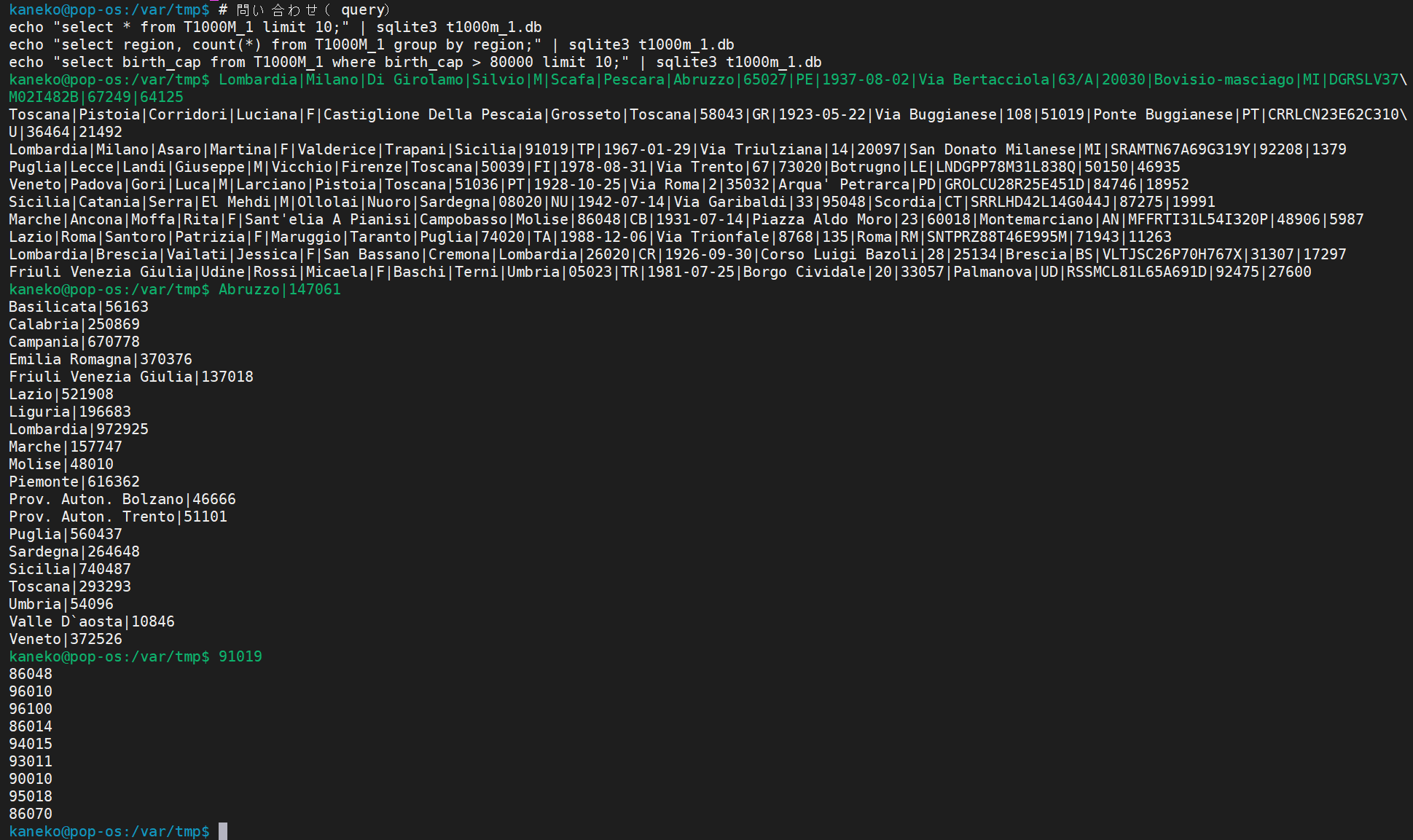
echo "select * from T1000M_1 limit 10;" | sqlite3 T1000M_1.db
echo "select region, count(*) from T1000M_1 group by region;" | sqlite3 T1000M_1.db
echo "select birth_cap from T1000M_1 where birth_cap > 80000 limit 10;" | sqlite3 T1000M_1.db
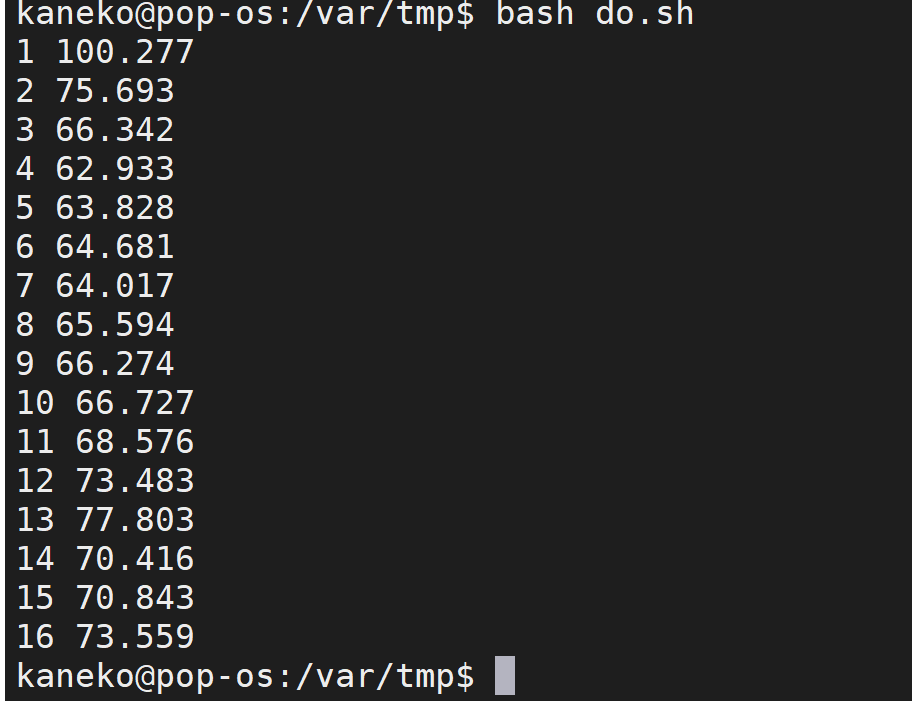
性能計測
数字 0 から 7 はプロセッサのコア.R, W はストレージの読み書き.
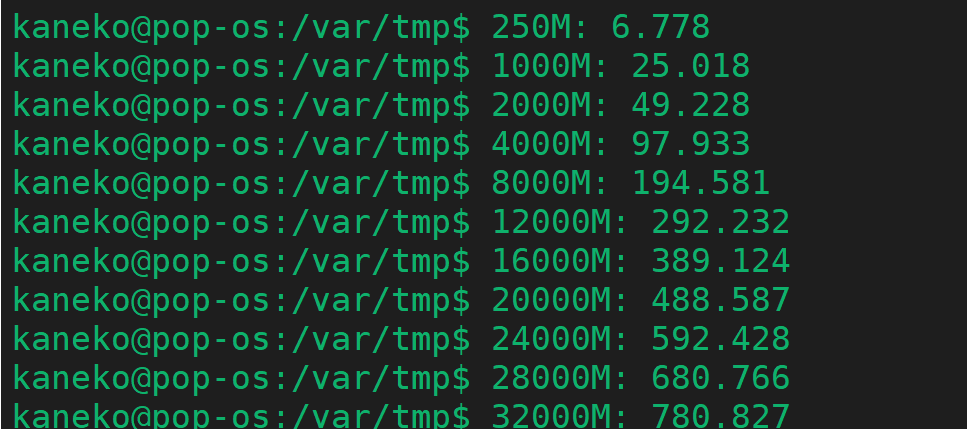
CSV ファイルインポートでのファイルサイズと処理時間の関係(SQLite 3 を使用)
#/bin/bash
function elapsed() {
echo `python3 -c "import sys; print( float(sys.argv[2]) - float(sys.argv[1]) )" $1 $2`
return
}
function avg() {
echo `python3 -c 'import sys; print("%.3f" % ((float(sys.argv[1]) + float(sys.argv[2]) + float(sys.argv[3])) / 3.0) )' $1 $2 $3`
return
}
# キャッシュのクリア(PageCache, dentries and inodes)
function cache_clear() {
/usr/bin/sync
/usr/bin/sync
/usr/bin/sync
/usr/bin/sync
/usr/bin/sync
sleep 3
sudo sysctl -w vm.drop_caches=3 > /dev/null
echo 3 | sudo tee -a /proc/sys/vm/drop_caches > /dev/null
return
}
# $1: CSV file name, $2: Table name, $3: SQLite 3 Database name
function sqlite3_import() {
echo -n > $3
rm -f $3
rm -f sqlite3_import.sql
cat >sqlite3_import.sql<<EOF
.separator ,
pragma journal_mode=off;
.import $1 $2
.exit
EOF
echo ".import $1 $2"
start=`date +%s.%N`
cat sqlite3_import.sql | sqlite3 $3 > /dev/null
current=`date +%s.%N`
echo `elapsed $start $current`
return
}
# 250M
cache_clear
elapsed1=`sqlite3_import T250M_1.csv T250M_1 T250M_1.db`
cache_clear
elapsed2=`sqlite3_import T250M_1.csv T250M_1 T250M_1.db`
cache_clear
elapsed3=`sqlite3_import T250M_1.csv T250M_1 T250M_1.db`
echo 250M: `avg $elapsed1 $elapsed2 $elapsed3`
# 500M
cache_clear
elapsed1=`sqlite3_import T500M_1.csv T500M_1 T500M_1.db`
cache_clear
elapsed2=`sqlite3_import T500M_1.csv T500M_1 T500M_1.db`
cache_clear
elapsed3=`sqlite3_import T500M_1.csv T500M_1 T500M_1.db`
echo 500M: `avg $elapsed1 $elapsed2 $elapsed3`
# 1000M
cache_clear
elapsed1=`sqlite3_import T1000M_1.csv T1000M_1 T1000M_1.db`
cache_clear
elapsed2=`sqlite3_import T1000M_1.csv T1000M_1 T1000M_1.db`
cache_clear
elapsed3=`sqlite3_import T1000M_1.csv T1000M_1 T1000M_1.db`
echo 1000M: `avg $elapsed1 $elapsed2 $elapsed3`
# 2000M
cache_clear
elapsed1=`sqlite3_import T2000M_1.csv T2000M_1 T2000M_1.db`
cache_clear
elapsed2=`sqlite3_import T2000M_1.csv T2000M_1 T2000M_1.db`
cache_clear
elapsed3=`sqlite3_import T2000M_1.csv T2000M_1 T2000M_1.db`
echo 2000M: `avg $elapsed1 $elapsed2 $elapsed3`
# 4000M
cache_clear
elapsed1=`sqlite3_import T4000M_1.csv T4000M_1 T4000M_1.db`
cache_clear
elapsed2=`sqlite3_import T4000M_1.csv T4000M_1 T4000M_1.db`
cache_clear
elapsed3=`sqlite3_import T4000M_1.csv T4000M_1 T4000M_1.db`
echo 4000M: `avg $elapsed1 $elapsed2 $elapsed3`
# 8000M
cache_clear
elapsed1=`sqlite3_import T8000M_1.csv T8000M_1 T8000M_1.db`
cache_clear
elapsed2=`sqlite3_import T8000M_1.csv T8000M_1 T8000M_1.db`
cache_clear
elapsed3=`sqlite3_import T8000M_1.csv T8000M_1 T8000M_1.db`
echo 8000M: `avg $elapsed1 $elapsed2 $elapsed3`
# 12000M
cache_clear
elapsed1=`sqlite3_import T12000M_1.csv T12000M_1 T12000M_1.db`
cache_clear
elapsed2=`sqlite3_import T12000M_1.csv T12000M_1 T12000M_1.db`
cache_clear
elapsed3=`sqlite3_import T12000M_1.csv T12000M_1 T12000M_1.db`
echo 12000M: `avg $elapsed1 $elapsed2 $elapsed3`
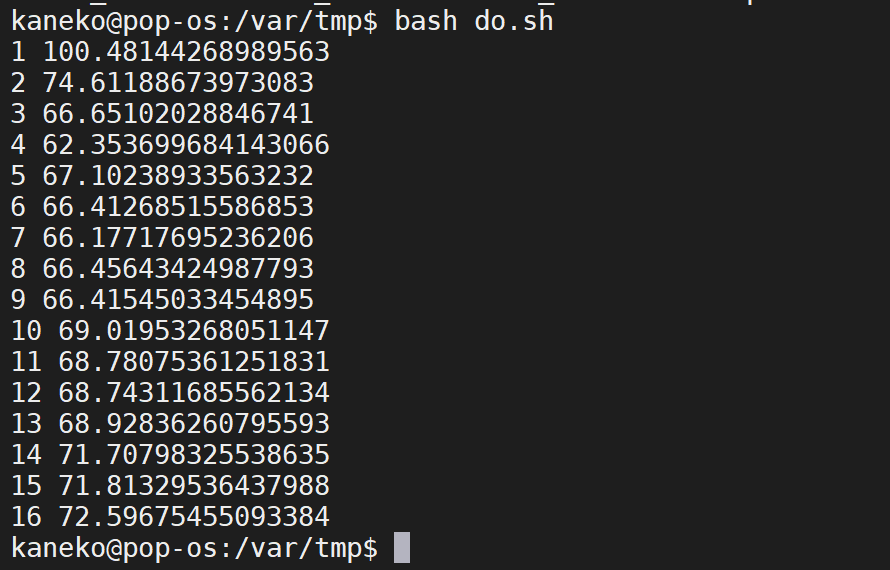
CSV ファイルインポートの並行処理
並行度を 1, 2, 4, 8 のように変える.インポートするデータの総量は同じとし,性能の違いを見る.
#/bin/bash
function elapsed() {
echo `python3 -c "import sys; print( float(sys.argv[2]) - float(sys.argv[1]) )" $1 $2`
return
}
function avg() {
echo `python3 -c 'import sys; print("%.3f" % ((float(sys.argv[1]) + float(sys.argv[2]) + float(sys.argv[3])) / 3.0) )' $1 $2 $3`
return
}
# キャッシュのクリア(PageCache, dentries and inodes)
function cache_clear() {
/usr/bin/sync
/usr/bin/sync
/usr/bin/sync
/usr/bin/sync
/usr/bin/sync
sleep 3
sudo sysctl -w vm.drop_caches=3 > /dev/null
echo 3 | sudo tee -a /proc/sys/vm/drop_caches > /dev/null
return
}
# $1: CSV file name, $2: Table name, $3: SQLite 3 Database name
function sqlite3_import() {
echo -n > $3
rm -f $3
rm -f sqlite3_import.$$.sql
cat >sqlite3_import.$$.sql<<EOF
.separator ,
pragma journal_mode=off;
.import $1 $2
.exit
EOF
echo ".import $1 $2"
start=`date +%s.%N`
cat sqlite3_import.$$.sql | sqlite3 $3 > /dev/null
current=`date +%s.%N`
rm -f sqlite3_import.$$.sql
echo `elapsed $start $current`
return
}
#########################################################################
# TODOLIST は,実行させたいコマンド,あるいは「taskほにゃらら <引数>」
TODOLIST=$(cat <<EOD
sqlite3_import T250M_1.csv T250M_1 T250M_1.db
sqlite3_import T250M_2.csv T250M_2 T250M_2.db
sqlite3_import T250M_3.csv T250M_3 T250M_3.db
sqlite3_import T250M_4.csv T250M_4 T250M_4.db
sqlite3_import T250M_5.csv T250M_5 T250M_5.db
sqlite3_import T250M_6.csv T250M_6 T250M_6.db
sqlite3_import T250M_7.csv T250M_7 T250M_7.db
sqlite3_import T250M_8.csv T250M_8 T250M_8.db
sqlite3_import T250M_9.csv T250M_9 T250M_9.db
sqlite3_import T250M_10.csv T250M_10 T250M_10.db
sqlite3_import T250M_11.csv T250M_11 T250M_11.db
sqlite3_import T250M_12.csv T250M_12 T250M_12.db
sqlite3_import T250M_13.csv T250M_13 T250M_13.db
sqlite3_import T250M_14.csv T250M_14 T250M_14.db
sqlite3_import T250M_15.csv T250M_15 T250M_15.db
sqlite3_import T250M_16.csv T250M_16 T250M_16.db
EOD
)
#########################################################################
# TODOLIST の記載を,指定された並列度で実行.
# この先は決まり文句
# さて,このプログラムは,引数の数が1のときは,行番号の指定である.TODOLIST のその行番号の1行を実行する.使い方 concurrent.sh <行番号>
if [ $# == 1 ]; then
# echo "$a" のように「"」を付けると改行が保たてる
eval $(echo "$TODOLIST" | sed -n ${1}P)
exit
fi
# 引数なしで実行するとき,
# seq 1 $(echo "$TODOLIST" | wc -l) は,TODOLIST の行数以下の整数を1から順に生成.
# 使うときは chmod 755 で実行可能にしておくこと.
for i in `seq 1 16`; do
# 並列度
NUM_CONCURRENT=$i
#
cache_clear
start=`date +%s.%N`
seq 1 $(echo "$TODOLIST" | wc -l) | xargs -L 1 -P ${NUM_CONCURRENT} bash ./$0 > /dev/null
current=`date +%s.%N`
elapsed1=`elapsed $start $current`
#
cache_clear
start=`date +%s.%N`
seq 1 $(echo "$TODOLIST" | wc -l) | xargs -L 1 -P ${NUM_CONCURRENT} bash ./$0 > /dev/null
current=`date +%s.%N`
elapsed2=`elapsed $start $current`
#
cache_clear
start=`date +%s.%N`
seq 1 $(echo "$TODOLIST" | wc -l) | xargs -L 1 -P ${NUM_CONCURRENT} bash ./$0 > /dev/null
current=`date +%s.%N`
elapsed3=`elapsed $start $current`
#
echo ${NUM_CONCURRENT} `avg $elapsed1 $elapsed2 $elapsed3`
done
PostgreSQL
sudo -u postgres service postgresql start
# clean up
echo "drop database testdb" | sudo -u postgres psql -U postgres
sudo service postgresql stop
sudo rm -rf /var/lib/postgresql/data
sudo mkdir /var/lib/postgresql/data
sudo chown -R postgres:postgres /var/lib/postgresql/data
sudo -u postgres /usr/lib/postgresql/12/bin/initdb --encoding='UTF-8' -D /var/lib/postgresql/data
#
sudo service postgresql start
echo "create database testdb owner postgres encoding 'UTF8';" | sudo -u postgres psql -U postgres
cat T1000M_1.sql | sudo -u postgres psql -U postgres -d testdb
echo "\copy T1000M_1 from 'T1000M_1.csv' with csv header;" | sudo -u postgres psql -U postgres -d testdb
echo "select region, count(*) from T1000M_1 group by region;" | sudo -u postgres psql -U postgres -d testdb
echo "select birth_cap from T1000M_1 where birth_cap > 80000 limit 10;" | sudo -u postgres psql -U postgres -d testdb