PostgreSQL への CSV ファイルインポートと性能確認手順
【概要】
CSVファイルのインポートとは、CSVファイルをリレーショナルデータベースのテーブルに取り込むことである。ここで扱うCSVファイルは、先頭行に各列の属性名が記述されているものとする。1つのCSVファイルを1つのテーブルにインポートし、レコード内の値の順序はそのまま維持する。あわせて、インポートの処理性能を dstat で計測する手順と、ファイルサイズと処理時間の関係を調べる手順を示す。
本ページで扱うソフトウェアの利用条件は、利用者自身で確認すること。
【目次】
【サイト内の関連ページ】
前準備
CSVファイルの準備
- テスト用CSVデータの合成: 別ページ »で説明
PostgreSQL のインストール
PostgreSQL の利用: 別ページ »にまとめている。
CSVファイルインポートのテスト実行
以下の設定を行って実行する。PostgreSQL 18 を用いる。
- 「T1000M_1.csv」の部分には、インポートするCSVファイル名を指定する
- 「T1000M_1.sql」の部分には、作成するテーブル定義のSQLを指定する
- 「T1000M_1」の部分には、作成するテーブル名を指定する
- 「testdb」の部分には、PostgreSQL のデータベース名を指定する
サーバ側の COPY コマンドは、PostgreSQL サーバのプロセスがファイルを直接読むため、ファイルのパスはサーバから見た絶対パスで指定し、サーバの実行ユーザ(postgres)がそのファイルを読める必要がある。
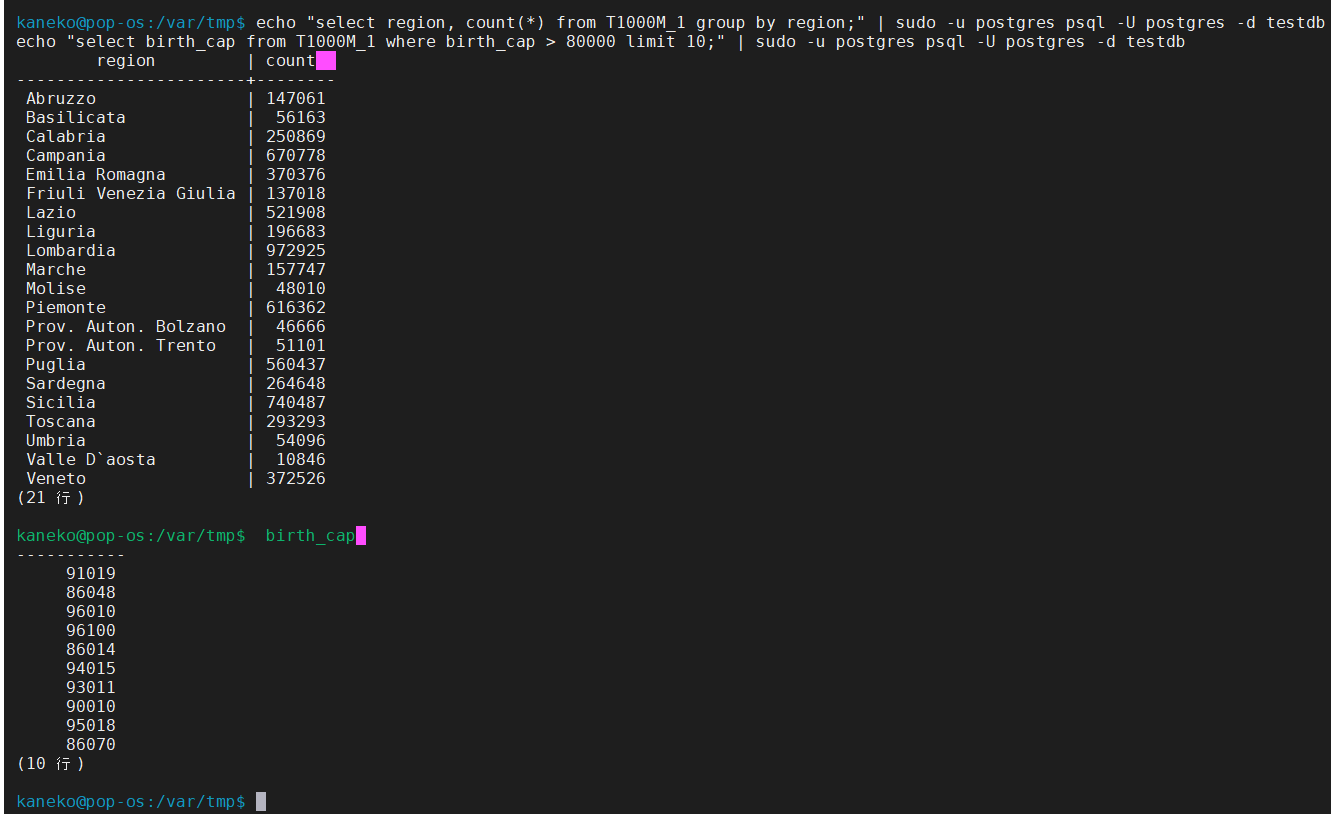
# インポートのプログラム
cat >import.sql<<EOF
truncate T1000M_1;
copy T1000M_1 from '`pwd`/T1000M_1.csv' with (format csv, header);
\q
EOF
# クリーンアップ(clean up)
echo "drop database if exists testdb" | sudo -u postgres psql -U postgres
sudo systemctl stop postgresql
sudo rm -rf /var/lib/postgresql/data
sudo mkdir /var/lib/postgresql/data
sudo chown -R postgres:postgres /var/lib/postgresql/data
sudo -u postgres /usr/lib/postgresql/18/bin/initdb --encoding=UTF-8 --locale=ja_JP.UTF8 -D /var/lib/postgresql/data > /dev/null
sudo systemctl start postgresql
echo "create database testdb owner postgres encoding 'UTF8';" | sudo -u postgres psql -U postgres
# インポート(import)
cat T1000M_1.sql | sudo -u postgres psql -U postgres -d testdb
cat import.sql | sudo -u postgres time psql -U postgres -d testdb --single-transaction
rm -f import.sql
# 問い合わせ(query)
echo "select * from T1000M_1 limit 10;" | sudo -u postgres psql -U postgres -d testdb
echo "select region, count(*) from T1000M_1 group by region;" | sudo -u postgres psql -U postgres -d testdb
echo "select birth_cap from T1000M_1 where birth_cap > 80000 limit 10;" | sudo -u postgres psql -U postgres -d testdb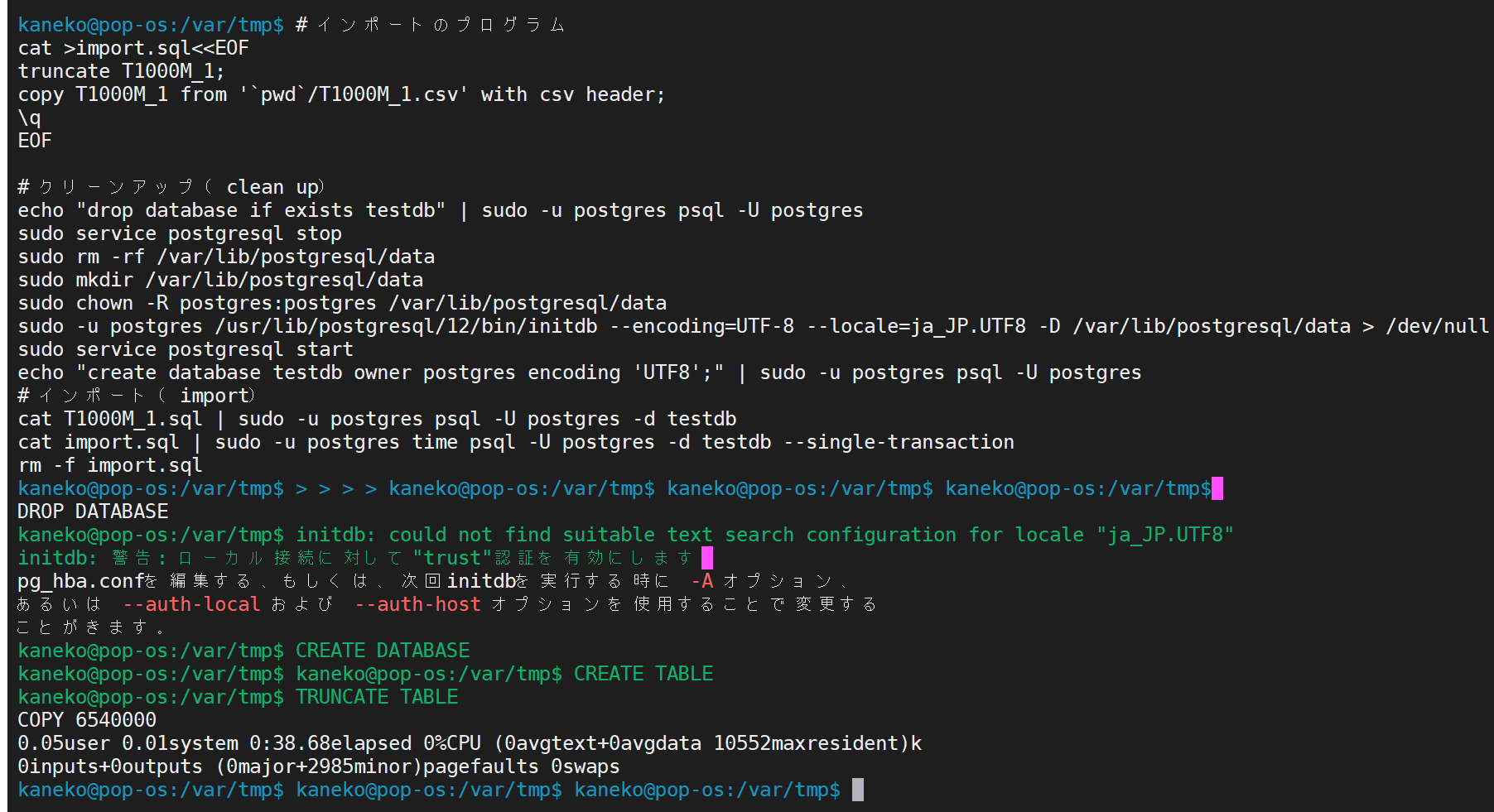

性能の計測
次のプログラムを実行し、dstat を用いて性能を測定する。
# キャッシュのクリア(PageCache, dentries and inodes)
function cache_clear() {
/usr/bin/sync
sleep 3
sudo sysctl -w vm.drop_caches=3 > /dev/null
echo 3 | sudo tee -a /proc/sys/vm/drop_caches > /dev/null
return
}
# 性能を測定するプログラム
cat >import.sql<<EOF
truncate T1000M_1;
copy T1000M_1 from '`pwd`/T1000M_1.csv' with (format csv, header);
\q
EOF
# クリーンアップ(clean up)
echo "drop database if exists testdb" | sudo -u postgres psql -U postgres
sudo systemctl stop postgresql
sudo rm -rf /var/lib/postgresql/data
sudo mkdir /var/lib/postgresql/data
sudo chown -R postgres:postgres /var/lib/postgresql/data
sudo -u postgres /usr/lib/postgresql/18/bin/initdb --encoding=UTF-8 --locale=ja_JP.UTF8 -D /var/lib/postgresql/data
sudo systemctl start postgresql
echo "create database testdb owner postgres encoding 'UTF8';" | sudo -u postgres psql -U postgres
# dstat データをプロットするプログラムの準備
WIDTH=48
HEIGHT=20
sudo apt -y install dstat
rm -f dstatplot.py
wget https://www.kkaneko.jp/data/rdb/dstatplot.py
# キャッシュのクリア
cache_clear
# 48 は表示の横幅を指定
# 20 は表示の縦幅を指定
# 表示が開始されるまで「表示の横幅」秒待機する
dstat -tcdylm -C 0,1,2,3,4,5,6,7 | python3 dstatplot.py $WIDTH $HEIGHT &
sleep $WIDTH
# インポート(import)
cat T1000M_1.sql | sudo -u postgres psql -U postgres -d testdb --single-transaction
cat import.sql | sudo -u postgres time psql -U postgres -d testdb
rm -f import.sql数字 0 から 7 はプロセッサのコアを表す。R、W はストレージの読み書きを、m はメモリ使用量を表す。
読み込みと書き込みの処理はすぐに開始される。読み込まれたデータはメモリ上に保持され、メモリはすぐには解放されない。また、トランザクションの終了後にデータの書き込みが実行される。

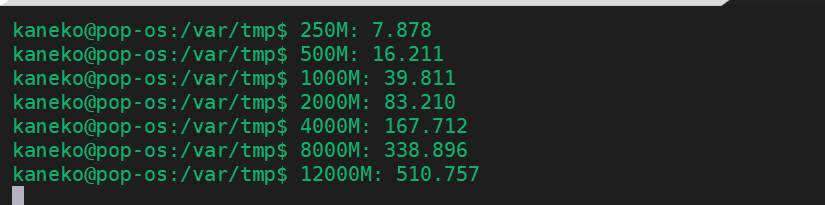
CSVファイルインポートでのファイルサイズと処理時間の関係
#!/bin/bash
function elapsed() {
echo `python3 -c "import sys; print( float(sys.argv[2]) - float(sys.argv[1]) )" $1 $2`
return
}
function avg() {
echo `python3 -c 'import sys; print("%.3f" % ((float(sys.argv[1]) + float(sys.argv[2]) + float(sys.argv[3])) / 3.0) )' $1 $2 $3`
return
}
# キャッシュのクリア(PageCache, dentries and inodes)
function cache_clear() {
/usr/bin/sync
sleep 3
sudo sysctl -w vm.drop_caches=3 > /dev/null
echo 3 | sudo tee -a /proc/sys/vm/drop_caches > /dev/null
return
}
F=/etc/postgresql/18/main/postgresql.conf
function wal_level_minimal() {
sudo sed -i 's/#wal_level = replica/wal_level = minimal/g' $F
sudo sed -i 's/wal_level = replica/wal_level = minimal/g' $F
sudo sed -i 's/#wal_level = logical/wal_level = minimal/g' $F
sudo sed -i 's/wal_level = logical/wal_level = minimal/g' $F
}
function wal_level_replica() {
sudo sed -i 's/wal_level = minimal/wal_level = replica/g' $F
sudo sed -i 's/#wal_level = logical/wal_level = replica/g' $F
sudo sed -i 's/wal_level = logical/wal_level = replica/g' $F
}
# $1: CSV file name, $2: Table name, $3: PostgreSQL Database name, $4: Table definition SQL
function psql_import() {
# クリーンアップ(clean up)
echo "drop database if exists $3" | sudo -u postgres psql -U postgres > /dev/null
cache_clear
sudo systemctl stop postgresql
cache_clear
sudo rm -rf /var/lib/postgresql/data
sudo mkdir /var/lib/postgresql/data
sudo chown -R postgres:postgres /var/lib/postgresql/data
sudo -u postgres /usr/lib/postgresql/18/bin/initdb --encoding=UTF-8 --locale=ja_JP.UTF8 -D /var/lib/postgresql/data > /dev/null
sudo systemctl start postgresql
echo "create database $3 owner postgres encoding 'UTF8';" | sudo -u postgres psql -U postgres > /dev/null
cat $4 | sudo -u postgres psql -U postgres -d $3 > /dev/null
rm -f psql_import.sql
# インポートのプログラム
cat >psql_import.sql<<EOF
truncate $2;
copy $2 from '`pwd`/$1' with (format csv, header);
\q
EOF
start=`date +%s.%N`
cat psql_import.sql | sudo -u postgres time psql -U postgres -d $3 --single-transaction --quiet > /dev/null
current=`date +%s.%N`
echo `elapsed $start $current`
return
}
wal_level_replica
# 250M
cache_clear
elapsed1=`psql_import T250M_1.csv T250M_1 t250m_1_db T250M_1.sql`
cache_clear
elapsed2=`psql_import T250M_1.csv T250M_1 t250m_1_db T250M_1.sql`
cache_clear
elapsed3=`psql_import T250M_1.csv T250M_1 t250m_1_db T250M_1.sql`
echo 250M: `avg $elapsed1 $elapsed2 $elapsed3`
# 500M
cache_clear
elapsed1=`psql_import T500M_1.csv T500M_1 t500m_1_db T500M_1.sql`
cache_clear
elapsed2=`psql_import T500M_1.csv T500M_1 t500m_1_db T500M_1.sql`
cache_clear
elapsed3=`psql_import T500M_1.csv T500M_1 t500m_1_db T500M_1.sql`
echo 500M: `avg $elapsed1 $elapsed2 $elapsed3`
# 1000M
cache_clear
elapsed1=`psql_import T1000M_1.csv T1000M_1 t1000m_1_db T1000M_1.sql`
cache_clear
elapsed2=`psql_import T1000M_1.csv T1000M_1 t1000m_1_db T1000M_1.sql`
cache_clear
elapsed3=`psql_import T1000M_1.csv T1000M_1 t1000m_1_db T1000M_1.sql`
echo 1000M: `avg $elapsed1 $elapsed2 $elapsed3`
# 2000M
cache_clear
elapsed1=`psql_import T2000M_1.csv T2000M_1 t2000m_1_db T2000M_1.sql`
cache_clear
elapsed2=`psql_import T2000M_1.csv T2000M_1 t2000m_1_db T2000M_1.sql`
cache_clear
elapsed3=`psql_import T2000M_1.csv T2000M_1 t2000m_1_db T2000M_1.sql`
echo 2000M: `avg $elapsed1 $elapsed2 $elapsed3`
# 4000M
cache_clear
elapsed1=`psql_import T4000M_1.csv T4000M_1 t4000m_1_db T4000M_1.sql`
cache_clear
elapsed2=`psql_import T4000M_1.csv T4000M_1 t4000m_1_db T4000M_1.sql`
cache_clear
elapsed3=`psql_import T4000M_1.csv T4000M_1 t4000m_1_db T4000M_1.sql`
echo 4000M: `avg $elapsed1 $elapsed2 $elapsed3`
# 8000M
cache_clear
elapsed1=`psql_import T8000M_1.csv T8000M_1 t8000m_1_db T8000M_1.sql`
cache_clear
elapsed2=`psql_import T8000M_1.csv T8000M_1 t8000m_1_db T8000M_1.sql`
cache_clear
elapsed3=`psql_import T8000M_1.csv T8000M_1 t8000m_1_db T8000M_1.sql`
echo 8000M: `avg $elapsed1 $elapsed2 $elapsed3`
# 12000M
cache_clear
elapsed1=`psql_import T12000M_1.csv T12000M_1 t12000m_1_db T12000M_1.sql`
cache_clear
elapsed2=`psql_import T12000M_1.csv T12000M_1 t12000m_1_db T12000M_1.sql`
cache_clear
elapsed3=`psql_import T12000M_1.csv T12000M_1 t12000m_1_db T12000M_1.sql`
echo 12000M: `avg $elapsed1 $elapsed2 $elapsed3`wal_level = minimal で実行したとき
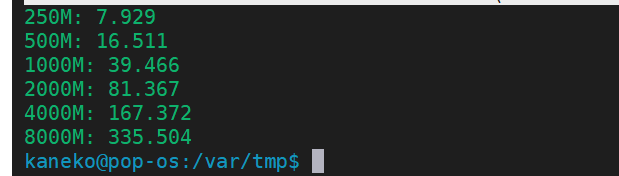
wal_level = replica で実行したとき