CSV データの合成(Python, random-csv-generator を使用)
【概要】
ランダムなデータが入った CSV ファイルを合成する。リレーショナルデータベースの試験・評価に使うことを想定している。
Python と random-csv-generator を使用し、イタリアの個人情報と金融データを模したランダムな CSV データを生成する。生成した約 250M(メガバイト)の CSV ファイルを結合することで、500M から 40000M までの各種サイズの CSV ファイルを作成する。csvkit を用いて、テーブル定義(CREATE TABLE 文などの SQL)の自動生成も行う。
【目次】
【目次】
- 1. 前準備
- 2. 必要なライブラリのインストール
- 3. 実行手順
- 4. 使い方・実行上の注意
- 5. 演習1 ランダム CSV の生成とカラムの確認
- 6. 演習2 テーブル定義 SQL の生成
- 7. まとめ
【関連する外部ページ】
【サイト内の関連情報】
第1章 前準備
Python 3.12 のインストール
Pythonのインストールを行い、Pythonのプログラムを実行する環境を整える。扱う環境は、Windows搭載パソコンである。金子研究室では、Python 3.12.10を推奨する。
[Windows での Python 3.12 のインストール手順を見るには、ここをクリック]
Windows での Python 3.12 のインストール
以下のいずれかの方法でPython 3.12をインストールする。Pythonがインストール済みの場合、この手順は不要である。
方法 1:winget によるインストール
【インストールコマンドの実行方法】
管理者権限でコマンドプロンプトを起動する(手順:Windowsキーまたはスタートメニュー → cmd と入力 → 右クリック → 「管理者として実行」)。そして、コマンド全体をコマンドプロンプトにコピー&ペーストする。
--scope machine を指定することで、システム全体(全ユーザー向け)にインストールされる。このオプションの実行には管理者権限が必要である。インストール完了後、コマンドプロンプトを再起動するとPATHが反映される。
REM Python 3.12 をシステム領域にインストール
winget install --id Python.Python.3.12 -e --scope machine --silent --accept-source-agreements --accept-package-agreements --override "/quiet InstallAllUsers=1 PrependPath=1 Include_test=0 Include_pip=1 Include_launcher=1 InstallLauncherAllUsers=1 TargetDir=\"C:\Program Files\Python312\""
REM Python と Scripts を PATH 先頭に追加
powershell -NoProfile -Command "$p='C:\Program Files\Python312'; $s=\"$p\Scripts\"; $c=[Environment]::GetEnvironmentVariable('Path','Machine'); if((Test-Path $p) -and (';'+$c+';' -notlike \"*;$p;*\") -and (';'+$c+';' -notlike \"*;$s;*\")){[Environment]::SetEnvironmentVariable('Path',\"$p;$s;$c\",'Machine')}"
方法 2:インストーラーによるインストール
- Python公式サイト(https://www.python.org/downloads/)にアクセスし、「Download Python 3.x.x」ボタンからWindows用インストーラーをダウンロードする。
- ダウンロードしたインストーラーを実行する。
- 初期画面の下部に表示される「Add python.exe to PATH」にチェックを入れてから「Customize installation」を選択する。このチェックを入れ忘れると、コマンドプロンプトから
pythonコマンドを実行できない。 - 「Install Python 3.xx for all users」にチェックを入れ、「Install」をクリックする。
インストールの確認
コマンドプロンプトで以下を実行する。
python --versionバージョン番号(例:Python 3.12.x)が表示されればインストール成功である。「'python' は、内部コマンドまたは外部コマンドとして認識されていません。」と表示される場合は、インストールが正常に完了していない。
Python の開発環境 Visual Studio Code のインストールと Python 用の設定
Python の開発環境Visual Studio Code(プログラムを編集するソフトウェア。以下、VS Code)を整える。
[Windows での Visual Studio Code のインストールと Python 用の設定手順を見るには、ここをクリック]
Windows での Visual Studio Code のインストールと Python 用の設定手順
1. VS Code と拡張機能のインストール
以下のコマンドにより,既存の VS Code を削除し,全ユーザー共有の設定で再インストールしたうえで,拡張機能(VS Code に機能を追加するソフトウェア)をまとめて導入する.
【インストールコマンドの実行方法】
管理者権限でコマンドプロンプトを起動する(手順:Windows キーまたはスタートメニュー → cmd と入力 → 右クリック → 「管理者として実行」)。そして,コマンド全体をコマンドプロンプトにコピー&ペーストする。
インストールコマンド
REM ============================================================
REM Microsoft Visual Studio Code
REM ============================================================
winget uninstall -e --id Microsoft.VisualStudioCode --silent --disable-interactivity --accept-source-agreements
rmdir /s /q C:\ProgramData\vscode-extensions 2>nul
rmdir /s /q "%APPDATA%\Code" 2>nul
rmdir /s /q "%USERPROFILE%\.vscode" 2>nul
rmdir /s /q "%LOCALAPPDATA%\Microsoft\vscode-update" 2>nul
REM VS Code をシステム領域に新規インストール
winget install --scope machine --id Microsoft.VisualStudioCode -e --silent --accept-source-agreements --accept-package-agreements
REM 全ユーザー共有の拡張機能フォルダ
mkdir C:\ProgramData\vscode-extensions 2>nul
icacls "C:\ProgramData\vscode-extensions" /grant "Everyone:(OI)(CI)M" /T
REM スタートメニューのショートカットを --extensions-dir 付きで再作成
rmdir /s /q "C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code" 2>nul
del "C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code.lnk" 2>nul
powershell -NoProfile -Command "$s=New-Object -ComObject WScript.Shell; $lnk=$s.CreateShortcut('C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code.lnk'); $lnk.TargetPath='C:\Program Files\Microsoft VS Code\Code.exe'; $lnk.Arguments='--extensions-dir \"C:\ProgramData\vscode-extensions\"'; $lnk.Save()"
REM ショートカットの検証
powershell -NoProfile -Command "$s=New-Object -ComObject WScript.Shell; $lnk=$s.CreateShortcut('C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code.lnk'); Write-Host 'TargetPath:' $lnk.TargetPath; Write-Host 'Arguments:' $lnk.Arguments"
REM ファイル / フォルダ右クリックの「Code で開く」を登録
reg add "HKLM\SOFTWARE\Classes\*\shell\VSCode\command" /ve /d "\"C:\Program Files\Microsoft VS Code\Code.exe\" --extensions-dir \"C:\ProgramData\vscode-extensions\" \"%1\"" /f
reg add "HKLM\SOFTWARE\Classes\Directory\shell\VSCode\command" /ve /d "\"C:\Program Files\Microsoft VS Code\Code.exe\" --extensions-dir \"C:\ProgramData\vscode-extensions\" \"%1\"" /f
reg add "HKLM\SOFTWARE\Classes\Directory\Background\shell\VSCode\command" /ve /d "\"C:\Program Files\Microsoft VS Code\Code.exe\" --extensions-dir \"C:\ProgramData\vscode-extensions\" \"%V\"" /f
REM --extensions-dir 付きで起動する code.cmd ラッパを作成
REM (%* を echo で書くと対話的 cmd で失われるため、PowerShell で [char]37+'*' を書き出す)
powershell -NoProfile -Command "$pct=[char]37; $q=[char]34; $c='@echo off'+[char]13+[char]10+$q+'C:\Program Files\Microsoft VS Code\bin\code.cmd'+$q+' --extensions-dir '+$q+'C:\ProgramData\vscode-extensions'+$q+' '+$pct+'*'+[char]13+[char]10; [IO.File]::WriteAllText('C:\ProgramData\vscode-extensions\vscode.cmd',$c,[Text.Encoding]::ASCII)"
REM 拡張機能のインストール
set "CODE=C:\Program Files\Microsoft VS Code\bin\code.cmd"
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --uninstall-extension GitHub.copilot
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --uninstall-extension GitHub.copilot-chat
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension ms-python.python
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension ms-python.vscode-pylance
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension ms-python.debugpy
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension MS-CEINTL.vscode-language-pack-ja
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension saoudrizwan.claude-dev
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension rust-lang.rust-analyzer
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension tamasfe.even-better-toml
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension anthropic.claude-code
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension almenon.arepl
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --list-extensions --show-versions
echo === セットアップ完了 ===
2. Python インタプリタの選択
同一マシンに複数の Python がインストールされている場合,VS Code で使用する Python 本体(インタプリタ:Python プログラムを解釈・実行するソフトウェア)を選択する必要がある.
- コマンドパレット(コマンド名で機能を呼び出す VS Code の入力欄)を開く(
Ctrl+Shift+P) Python: Select Interpreterと入力する
- 表示される一覧から,使用する Python(例:
C:\Program Files\Python312\python.exe)を選択する.
Python プログラム実行手順
[Windows での Python プログラム実行手順を見るには、ここをクリック]
Windows での Python 実行手順(Visual Studio Codeを使用)
プログラムファイルの作成と保存
- 左サイドバーの「エクスプローラー」アイコン(
Ctrl+Shift+E)をクリックする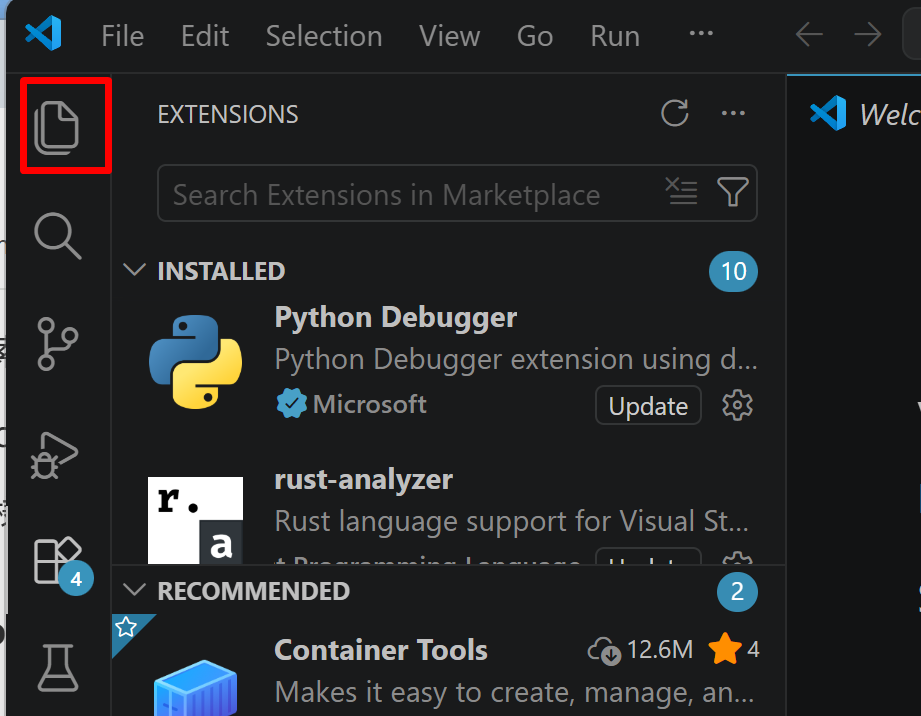
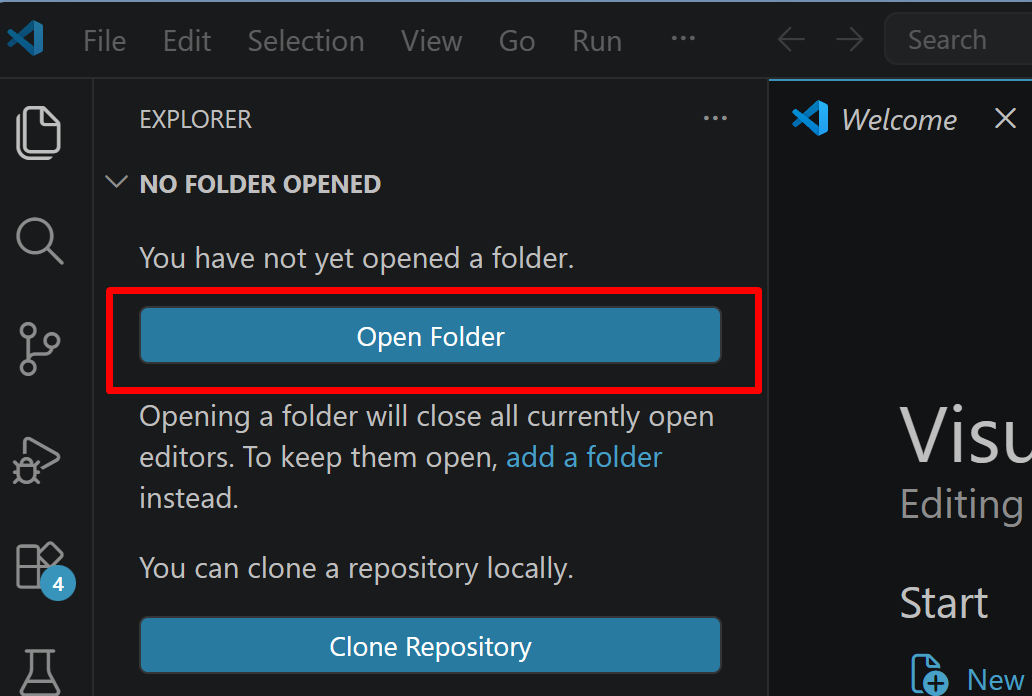
- 「NO FOLDER OPENED」(作業対象フォルダが未選択の状態)と表示される場合は,「Open Folder」をクリックし,プログラムを保存するフォルダを選択する
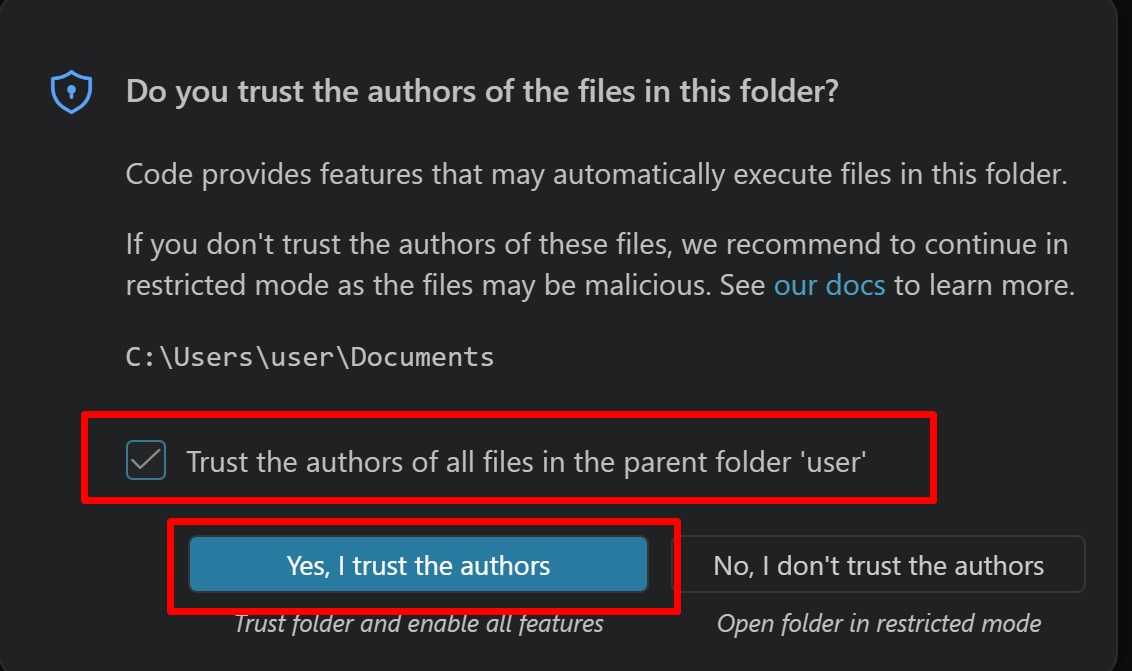
続いて「フォルダを信用するか」を確認する画面(フォルダ内のコードを実行してよいか確認する VS Code の仕組み)が表示されるので,チェックして Yes を選択する
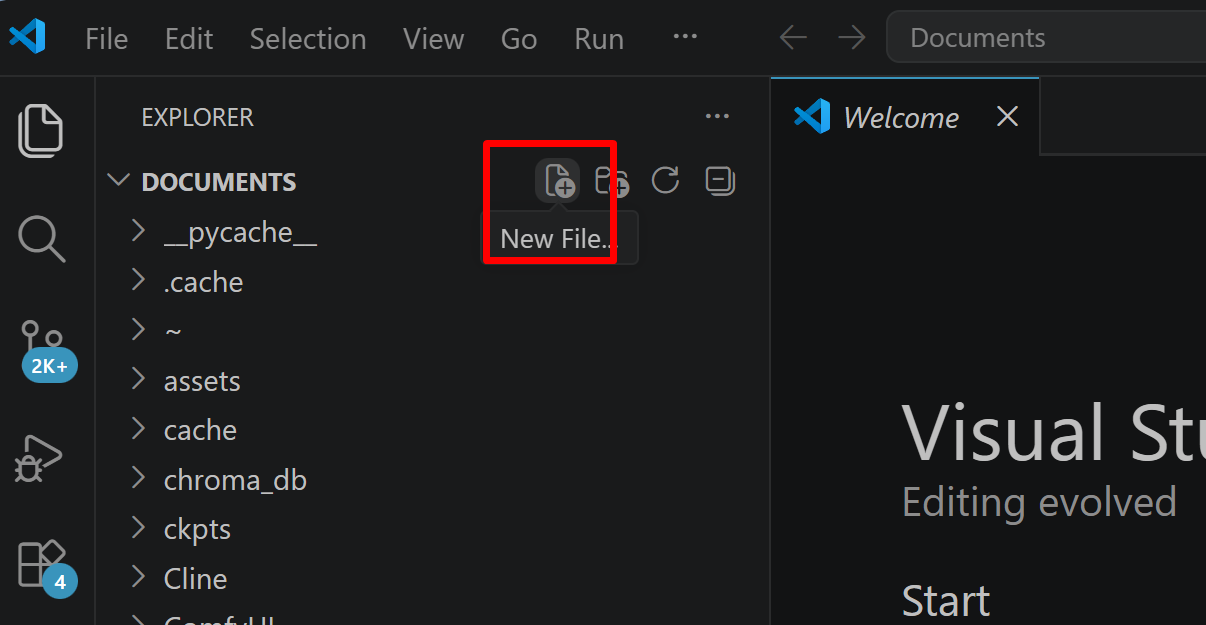
- フォルダ名の右側に表示される「新しいファイル」アイコンをクリックする
- ファイル名(例:
aitask.py.ファイル名は何でも良い)を入力しEnterを押す.拡張子は.py(Python ファイルを示す拡張子)とする
- 実行したいコードを選択し,
Ctrl+Cでコピーする.VS Code のエディタ領域にCtrl+Vで貼り付ける Ctrl+Sで保存する
プログラムの実行
- エディタ右上の三角形「▷」アイコン(Run Python File:現在開いている Python ファイルを実行するボタン)をクリックする.または,エディタ上で右クリックし「ターミナルで Python ファイルを実行」を選択する
- VS Code 下部のターミナル(コマンドの入出力を表示する画面)に,実行結果(
print関数の出力等)が表示される
- tkinter(Python 標準の GUI ライブラリ)のファイル選択ダイアログを使うプログラムを実行した場合は,ダイアログが開くので対象画像を選択する
- VS Code 下部のターミナルで実行結果を確認する.OpenCV ウィンドウ(OpenCV が画像を表示するために開く専用ウィンドウ)が開いた場合はそちらも確認する.OpenCV ウィンドウは,マウスクリックでウィンドウをアクティブ(操作対象の状態)にしてからキーを押すと終了する


第2章 必要なライブラリのインストール
管理者権限でコマンドプロンプトを起動する
(手順:Windowsキーまたはスタートメニュー → cmd と入力 → 右クリック → 「管理者として実行」)。
起動したコマンドプロンプトで以下を実行する。random_csv_generator はランダムな CSV を生成するパッケージ、csvkit は CSV を扱うコマンド群(csvsql を含む)である。
pip install --no-user random_csv_generator csvkit3. 実行手順
手順:コードを実行する(メモ帳を用いる場合は a.py のようなファイル名で保存して実行)。
動作確認チェックリスト
| 確認項目 | 期待される結果 |
|---|---|
| ライブラリのインストール確認 | pip show random_csv_generator でパッケージ情報が表示される |
| プログラムの実行 | 指定ディレクトリに T1M.csv が生成される |
| CSV の内容確認 | region, province, surname, name などのカラムと、ランダムなイタリア個人情報データが含まれている |
| 通貨記号の調整確認 | 調整スクリプトの実行後、CSV 内の「€」や二重引用符が除去されている |
| テーブル定義 SQL の生成確認 | csvsql --tables T1M T1M.csv の実行後、CREATE TABLE 文が出力される |
第4章 使い方・実行上の注意
4.1 生成されるデータの形式
生成されるデータの例を以下に示す。イタリアの個人情報と金融データを模したランダムデータが CSV 形式で出力される。codice_fiscale はイタリアの納税者番号(個人を識別するコード)である。金融カラムの total_debit, paid_debit は、イタリアのロケール書式の通貨(例:13.752,00 € のように、桁区切りがピリオド、小数点がカンマ、末尾に € が付く)として出力される。
region,province,surname,name,sex,birth_municipality,birth_province,birth_region,birth_cap,birth_province_code,birthdate,address,house_number,cap,municipality,province_code,codice_fiscale,total_debit,paid_debit
Lombardia,Pavia,Montanari,Roberto Angelo Giuseppe,M,Marzabotto,Bologna,Emilia Romagna,40043,BO,1942-03-31,Via Roma,69,27050,Ponte Nizza,PV,MNTRRT42C31B689X,"13.752,00 €","8.137,00 €"
Lazio,Latina,Menna,Daniela,F,Fara San Martino,Chieti,Abruzzo,66015,CH,1945-11-15,Via La Nece Snc-condominio De Felice,2,4019,Terracina,LT,MNNDNL45S55D495H,"487,00 €","486,00 €"
4.2 プログラムの使い方
このプログラムはコマンドライン引数を3つ取る。
python hoge.py <レコード数> <ベースファイル名> <出力先ディレクトリ>実行の例を以下に示す。
python hoge.py 6540 T1M C:\temp4.3 データの合成(大量ファイルの生成と結合)
約 250M のファイルを 200 個生成し、結合によって各種サイズのファイルを作成する。以下は Linux のシェル(Bash)で実行する操作例であり、Windows のコマンドプロンプトでは動作しない。tail -n +2 により先頭行(ヘッダ)を除去してから追加する。
#!/bin/bash
DATADIR='/mnt/kaneko'
cd ${DATADIR}
for i in $(seq 1 200); do
python3 hoge.py 1634000 "T250M_${i}" ${DATADIR}
done
# T500M_1(250M x 2 = 500M)
cp T250M_1.csv T500M_1.csv
tail -n +2 T250M_2.csv >> T500M_1.csv
# T1000M_1(250M x 4 = 1000M)
cp T250M_1.csv T1000M_1.csv
for i in $(seq 2 4); do tail -n +2 T250M_${i}.csv >> T1000M_1.csv; done
# T2000M_1(250M x 8 = 2000M)
cp T250M_1.csv T2000M_1.csv
for i in $(seq 2 8); do tail -n +2 T250M_${i}.csv >> T2000M_1.csv; done
# T4000M_1(250M x 16 = 4000M)
cp T250M_1.csv T4000M_1.csv
for i in $(seq 2 16); do tail -n +2 T250M_${i}.csv >> T4000M_1.csv; done
# T8000M_1(250M x 32 = 8000M)
cp T250M_1.csv T8000M_1.csv
for i in $(seq 2 32); do tail -n +2 T250M_${i}.csv >> T8000M_1.csv; done
# T12000M_1(250M x 48 = 12000M)
cp T250M_1.csv T12000M_1.csv
for i in $(seq 2 48); do tail -n +2 T250M_${i}.csv >> T12000M_1.csv; done
# T16000M_1(250M x 64 = 16000M)
cp T250M_1.csv T16000M_1.csv
for i in $(seq 2 64); do tail -n +2 T250M_${i}.csv >> T16000M_1.csv; done
# T20000M_1(250M x 80 = 20000M)
cp T250M_1.csv T20000M_1.csv
for i in $(seq 2 80); do tail -n +2 T250M_${i}.csv >> T20000M_1.csv; done
# T24000M_1(250M x 96 = 24000M)
cp T250M_1.csv T24000M_1.csv
for i in $(seq 2 96); do tail -n +2 T250M_${i}.csv >> T24000M_1.csv; done
# T28000M_1(250M x 112 = 28000M)
cp T250M_1.csv T28000M_1.csv
for i in $(seq 2 112); do tail -n +2 T250M_${i}.csv >> T28000M_1.csv; done
# T32000M_1(250M x 128 = 32000M)
cp T250M_1.csv T32000M_1.csv
for i in $(seq 2 128); do tail -n +2 T250M_${i}.csv >> T32000M_1.csv; done
# T36000M_1(250M x 144 = 36000M)
cp T250M_1.csv T36000M_1.csv
for i in $(seq 2 144); do tail -n +2 T250M_${i}.csv >> T36000M_1.csv; done
# T40000M_1(250M x 160 = 40000M)
cp T250M_1.csv T40000M_1.csv
for i in $(seq 2 160); do tail -n +2 T250M_${i}.csv >> T40000M_1.csv; done
wc T250M_1.csv T500M_1.csv T1000M_1.csv T2000M_1.csv T4000M_1.csv T8000M_1.csv T12000M_1.csv T16000M_1.csv T20000M_1.csv T24000M_1.csv T28000M_1.csv T32000M_1.csv T36000M_1.csv T40000M_1.csv
4.4 テーブル定義 SQL の生成
csvsql を用いて CSV からテーブル定義を生成し、sed でテーブル名を一括置換する。以下も Linux のシェル(Bash)で実行する操作例である。
csvsql --tables T250M_1 T250M_1.csv | sed 's/"//g' > T250M_1.sql
for size in T500 T1000 T2000 T4000 T8000 T12000 T16000 T20000 T24000 T28000 T32000 T36000 T40000; do
sed "s/T250/${size}/g" T250M_1.sql > ${size}M_1.sql
done
4.5 データの調整
生成された CSV 内の通貨記号(€)と二重引用符を除去する。以下も Linux のシェル(Bash)で実行する操作例である。
cd /var/tmp
for i in *.csv; do
echo $i
sed -i 's/€ //g' $i
sed -i 's/€//g' $i
sed -i 's/"//g' $i
done
第5章 演習1 ランダム CSV の生成とカラムの確認
テーマ名:random-csv-generator による CSV 生成
手順:
- 管理者権限でコマンドプロンプトを起動する
(手順:Windowsキーまたはスタートメニュー →
cmdと入力 → 右クリック → 「管理者として実行」)。 - 起動したコマンドプロンプトで
pip install --no-user random_csv_generator csvkitを実行する。 - 次のコードを実行(メモ帳を用いる場合は a.py のようなファイル名で保存して実行)する(文字コード:UTF-8)。
- 保存先ディレクトリに移動し、
python a.py 6540 T1M C:\tempを実行する(メモ帳で保存したファイル名を指定する)。 C:\temp\T1M.csvをテキストエディタで開く。
import sys
from random_csv_generator import random_csv
num_of_records = int(sys.argv[1])
basename = sys.argv[2]
datadir = sys.argv[3]
df = random_csv(num_of_records)
df.to_csv(datadir + '/' + basename + '.csv', index=False, encoding='utf8', chunksize=1000)
ヒント:引数はレコード数、ベースファイル名、出力先ディレクトリの順である。
考察ポイント:出力された CSV の先頭行にどのカラム(region, province, surname など)が並んでいるか、金融カラム(total_debit, paid_debit)にどのような値が入っているかを確認する。
第6章 演習2 テーブル定義 SQL の生成
テーマ名:csvsql によるテーブル定義の自動生成
手順:
- 演習1で生成した
T1M.csvのあるディレクトリに移動する。 csvsql --tables T1M T1M.csvを実行する。
csvsql --tables T1M T1M.csvヒント:--tables は、作成するテーブル名をカンマ区切りで指定するオプションである。省略すると、ファイル名(拡張子を除く)がテーブル名になる。
考察ポイント:出力された CREATE TABLE 文で、各カラムにどのデータ型が割り当てられているかを読み取る。
第7章 まとめ
- random-csv-generator によるランダム CSV の生成:Python の random-csv-generator を使用し、イタリアの個人情報と金融データを模したランダムな CSV ファイルを合成する。リレーショナルデータベースの試験・評価用データを想定している。
- コマンドライン引数によるパラメータ指定:プログラムはレコード数、ベースファイル名、出力先ディレクトリの3つの引数を取り、指定したレコード数の CSV を出力する。
- ファイル結合による大規模データの構築:約 250M のファイルを 200 個生成し、
tail -n +2で先頭行を除去して結合することで、500M から 40000M までの各種サイズの CSV を作成する。 - 通貨記号と書式の調整:CSV に含まれる通貨記号(€)や二重引用符を sed で除去し、データベースへのインポートに適した形式にする。
- csvkit によるテーブル定義の自動生成:csvsql で CSV からテーブル定義(CREATE TABLE 文)を生成し、sed によるテーブル名の一括置換で各サイズの SQL ファイルを作成する。