階層的クラスタ分析の例(R, pvclust パッケージを使用)
前準備
R システムのインストール
R のプログラミングについては,別のページにまとめている.
pvclust パッケージのインストール
URL: https://github.com/shimo-lab/pvclust
- R の起動
- install.packages("som") の実行
if (!require("pvclust")) install.packages("pvclust")
初回実行時には,インストールが始まる.
- Windows では,初めて何らかのパッケージをインストールするとき,管理者権限がない場合,ユーザ領域にインストールするという表示が出る.「はい」をクリック.
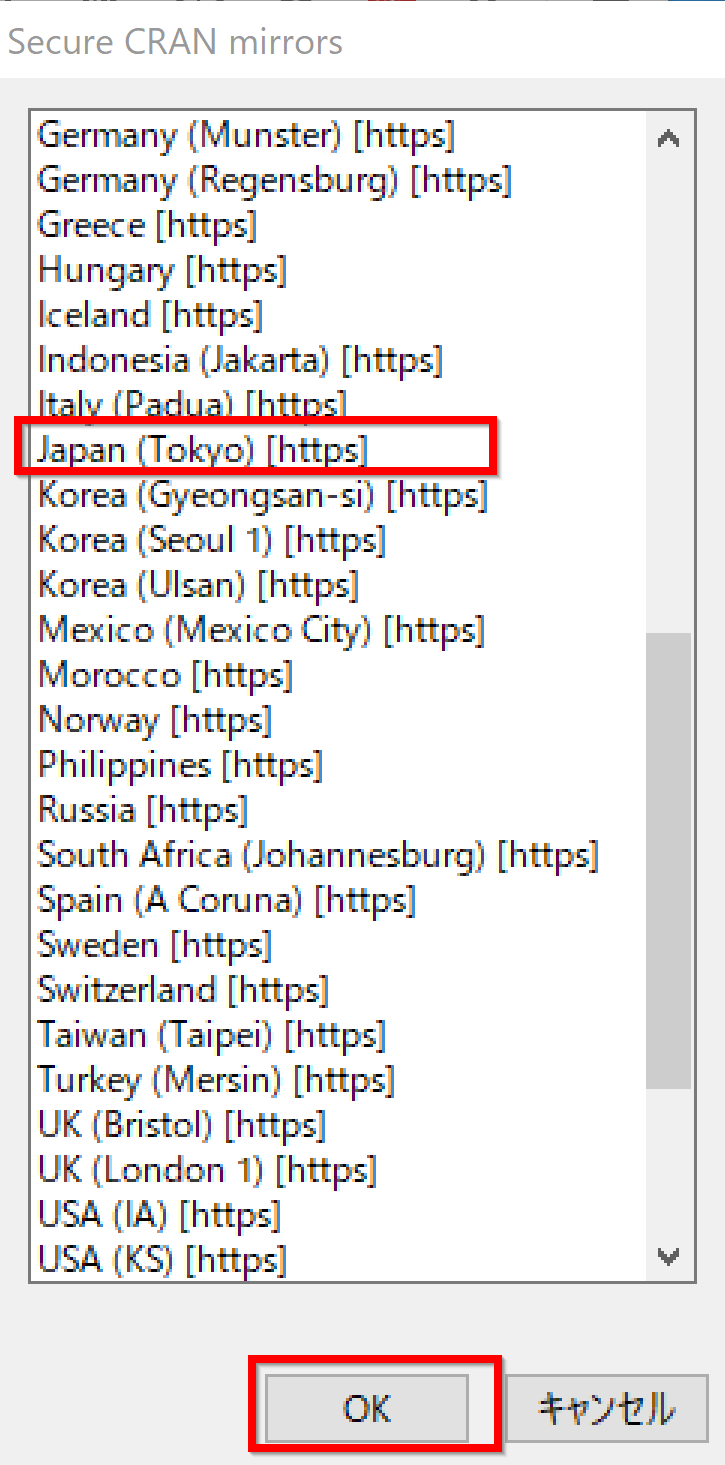
次の表示が出た場合には,「はい」をクリック.
- ミラーサイトは,日本から選ぶ
- Windows では,初めて何らかのパッケージをインストールするとき,管理者権限がない場合,ユーザ領域にインストールするという表示が出る.「はい」をクリック.
- library(pvclust) の実行
library(pvclust)
- サンプルの表示
example(pvclust)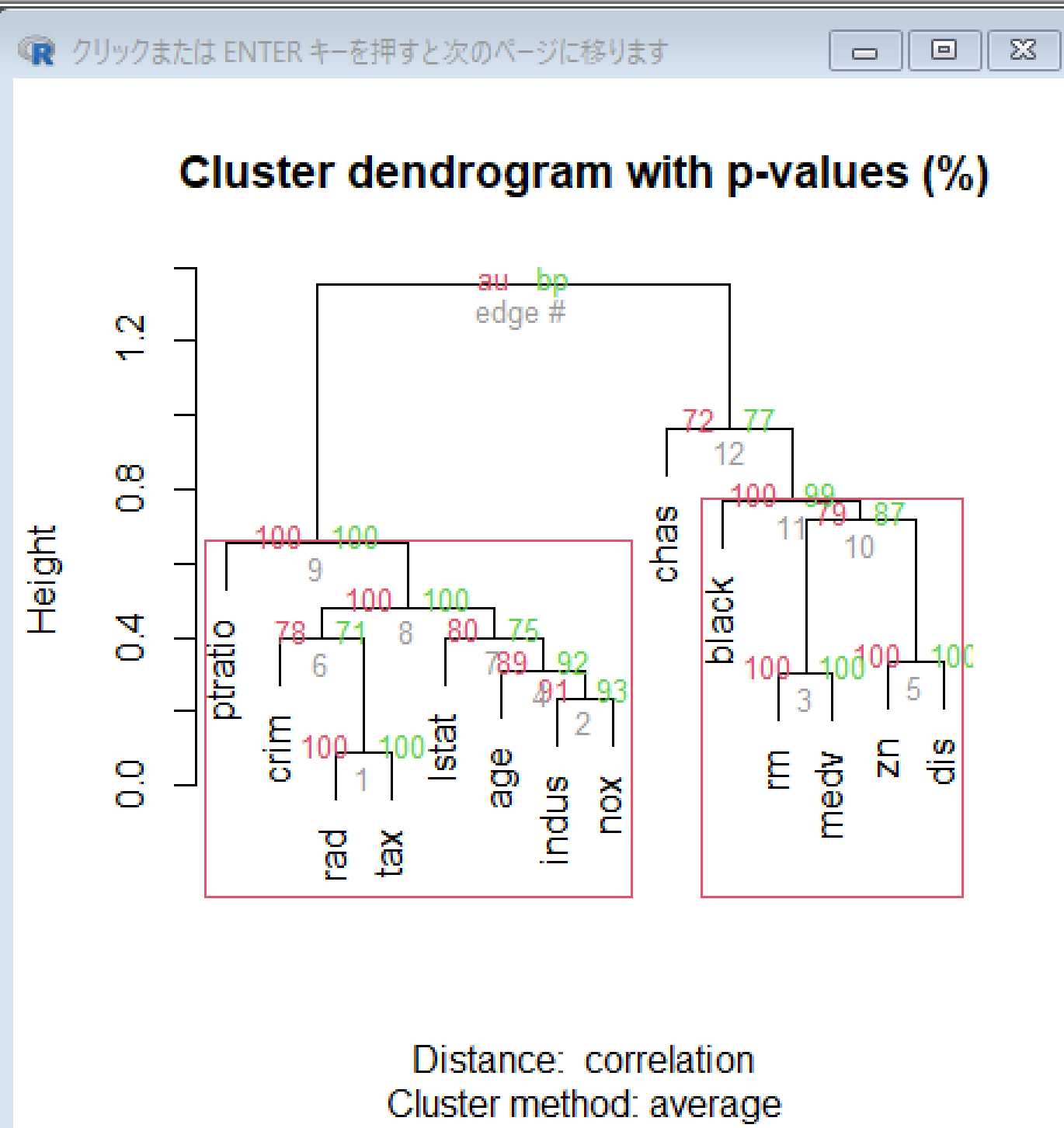
- ヘルプの表示
help(pvclust)
階層的クラスタリングの実行
ここでは,iris をクラスタリングする.iris は,Rシステムに組み込み済みのデータ.
pvclust() を使う.主なオプションは次の通り.
- method.hclust = "averate", "average", "war", "single", "complete", "mcquitty", "median", "centroid"
- method.dist= = "coorrelation", "uncentered", "abscor"
install.packages("pvclust")
data(iris)
c <- pvclust( t( iris[1:4] ) )
plot(c)
hclust を使用した階層的クラスタ分析の例
CSVファイルを読み込み,テーブルに格納
- (前準備) 使用する CSV ファイルの作成
* ここでは Book1.csv をダウンロードし,分かりやすいディレクトリに置く
参考:「外国為替データ(時系列データ)の情報源の紹介」の Web ページ)
以下の説明では、
- Windows の場合: データファイル名: C:\R\Book1.csv
- Linuxの場合: データファイル名: /tmp/Book1.csv
として説明を続ける.
* 自前の CSV ファイルを使うときの注意: read.table() 関数を使うので, 属性名は英語になっていること.属性名は,CSV ファイルの第一行目に書いていること.
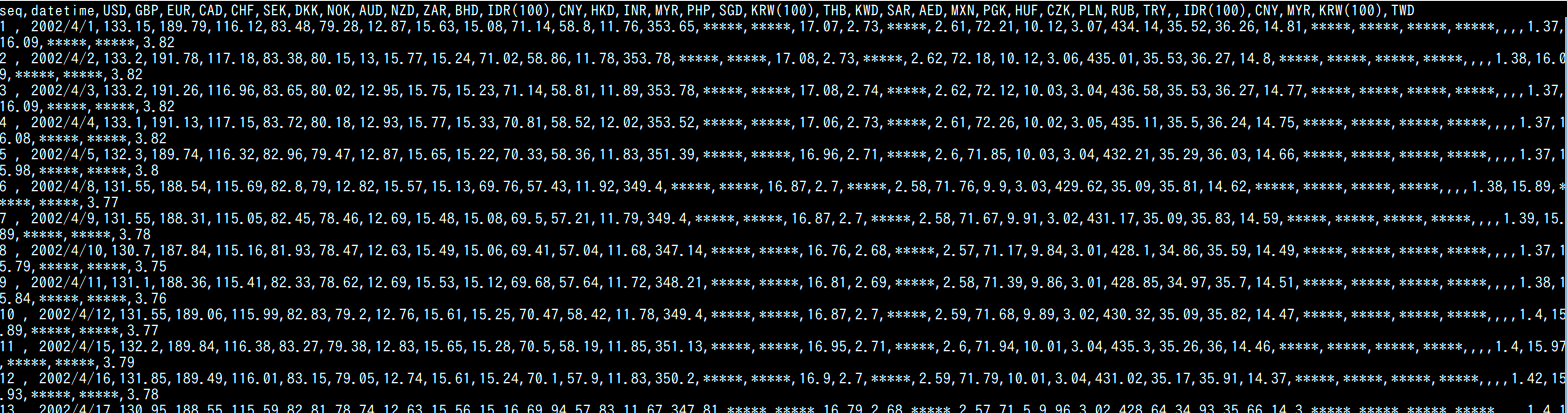
- 使用する CSV ファイルの確認
属性名が CSV ファイルの1行目に書かれていることを確認する.
- R の起動
◆ Windows での動作画面例
◆ Ubuntu での動作画面例
- 「read.table」を用いて,CSV ファイルを R のデータフレームに読み込み
次のコマンドを実行.
◆ Windows での動作手順例
X <- read.table("C:/R/Book1.csv", header=TRUE, sep=",", na.strings="NA", dec=".", strip.white=TRUE);◆ Linux での動作手順例
X <- read.table("/tmp/Book1.csv", header=TRUE, sep=",", na.strings="NA", dec=".", strip.white=TRUE);R の read.table のオプション
- X <- ・・・ 変数 X に読み込むという意味
- C:/R/Book1.csv, "/tmp/Book1.csv" ・・・ 読み込む CSV ファイル名.Windows では区切りには「/」を使うことに注意.
- header="TRUE" または header="FALSE" ・・・ 列ラベルが設定されているか
- seq="," や seq="\" や seq=" " や ・・・ 列を区切る記号(CSV ファイルのときは「seq=","」)
- na.string="NA" ・・・ Not a Number には "NA" を使うという意味
- dec="." ・・・ ファイルで使われている小数点記号(既定値は,ピリオド)
- strip.white=TRUE ・・・ 個々のデータの先頭や末尾にある「空白文字」を取り除いて読み込む
- skip=<行数> ・・・ 読み飛ばし行数
- nrow=<行数> ・・・ 読み込み行数
- (その他のオプション) dec: ファイルで使われている小数点記号を指定できる

- オブジェクト X の確認
次のコマンドを実行.
edit(X);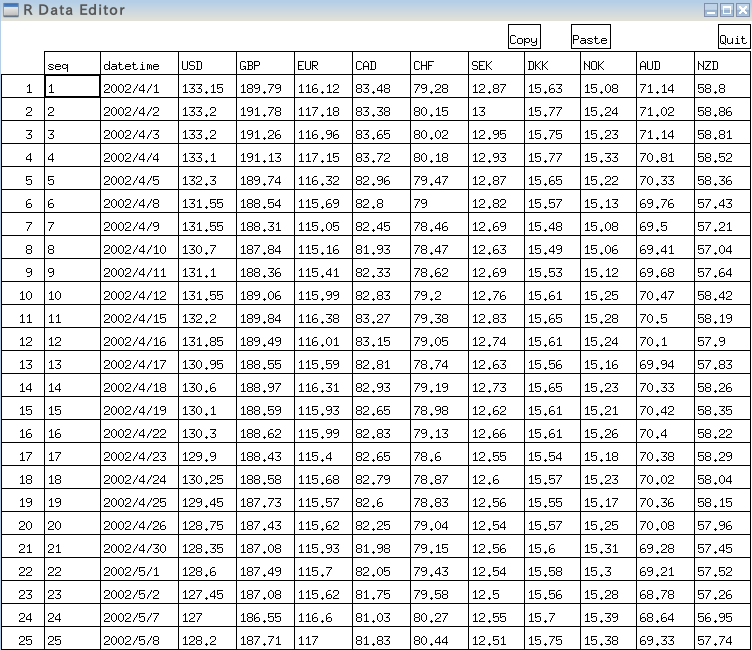
次のコマンドを実行.
str(X)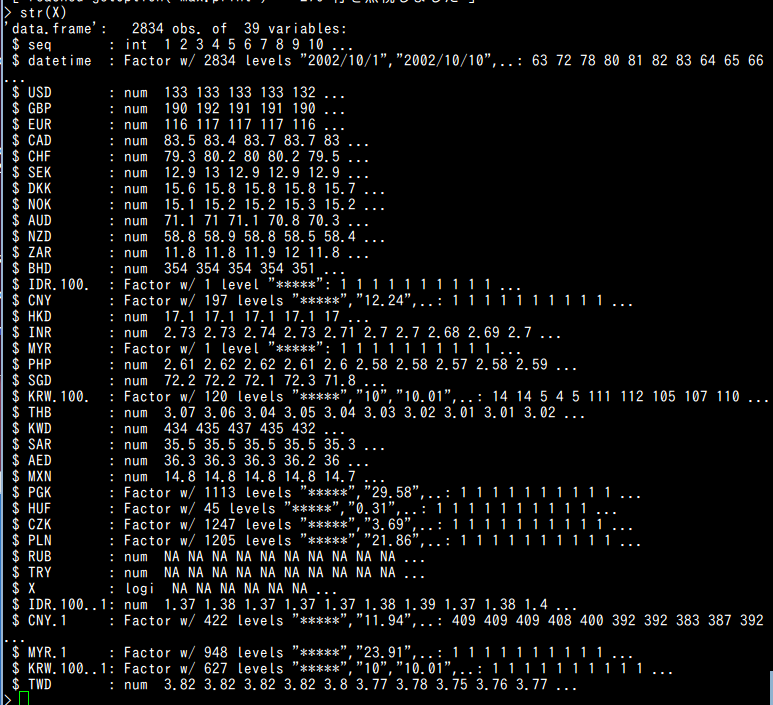
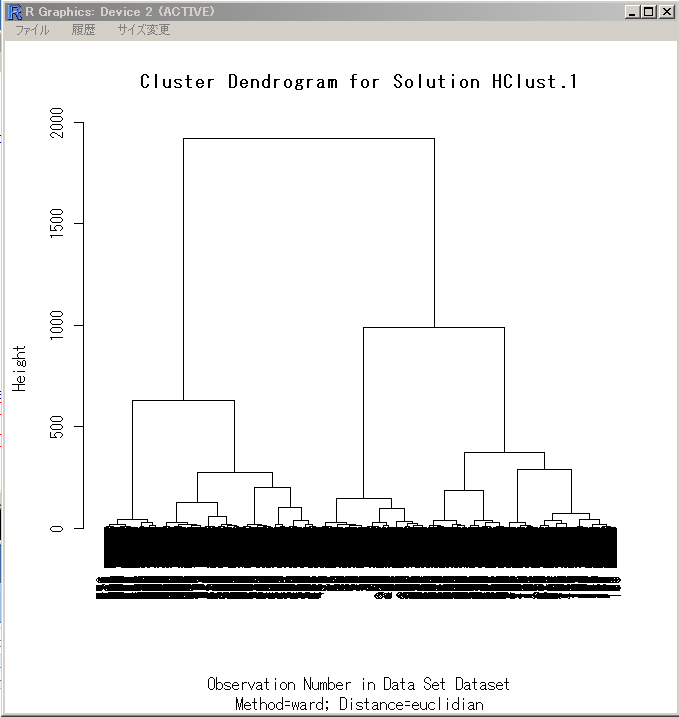
hclust() の実行
HClust.1 <- hclust(dist(model.matrix(~-1 + USD+EUR+AUD, X)) , method= "ward") plot(HClust.1, main= "Cluster Dendrogram for Solution HClust.1", xlab= "Observation Number in Data Set Dataset", sub="Method=ward; Distance=euclidian")