二次索引 (secondary index)
URL:
https://www.kkaneko.jp/tools/sqlitedb/7.html

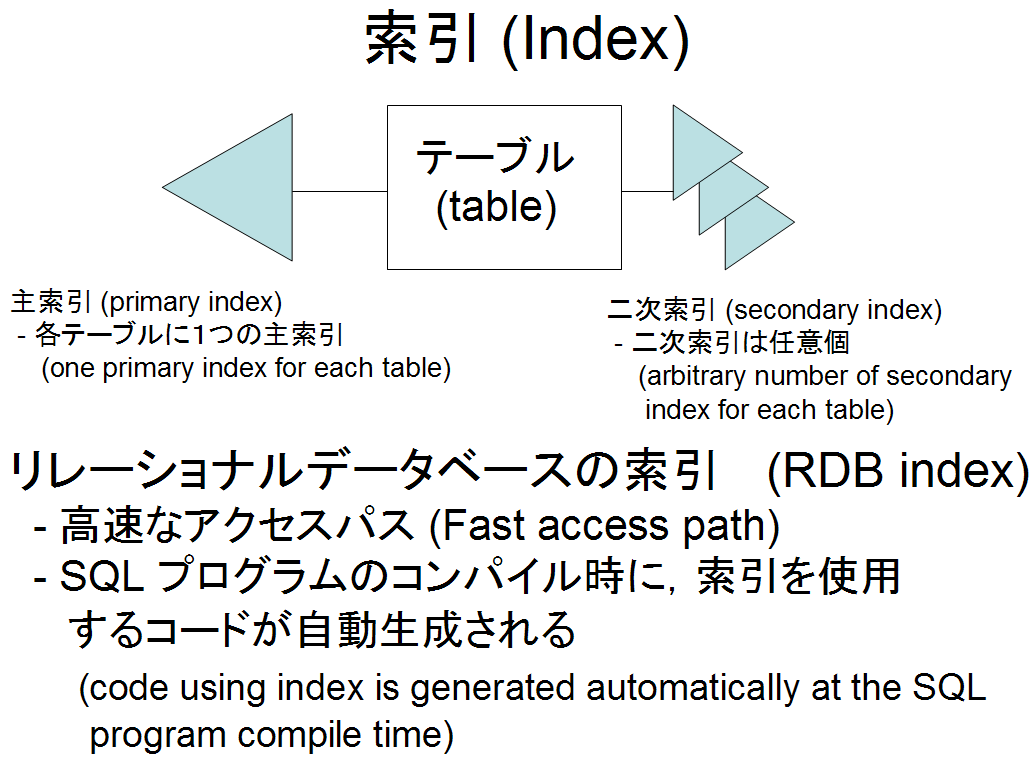


- 索引 (index)
索引を用いることで,レコードを効率よく検索することができる.
但し,レコードデータの更新時には,索引の維持 (maintenance) を行わなければならないので,索引を増やしすぎるのは良くない.
- 主索引 (primary index)
主キー (Key Primary) の値とレコードとを直接結びつけているような索引構造のことを,この資料では「主索引」と呼ぶことにする.
各テーブルに,1つの主索引がある(1つのテーブルに2個以上の主索引はありえない).
テーブル定義において「primary key」と指定した属性が,主キーになるのが普通である.
「primary key」を指定しなかったときは, テーブル定義が「primary key」を含まないなどの場合には,データベース管理システムが,テーブルの各行を識別する識別番号を自動生成し,それを主索引のキーとして使うのが普通である.
- 二次索引 (secondary index)
主索引のキー以外の属性による索引構造.
二次索引は,1つのテーブルに対して任意個作ることができる.二次索引は自由に追加,削除できるのが普通である.
【SQLite 3 の主要なオペコード (Opcode) の要点】
- OpenRead: ルート・ページが P2 であるようなテーブルのカーソルを作る. P1 にはカーソル番号を設定する. P4 には、テーブルの列数を設定するか, KeyInfo 構造体 (KeyInfo 構造体)と呼ばれる構造体へのポインタを設定する.
- Rewind: 将来の Column, Rowid, Next 命令の実行に備えて,カーソル P1 をテーブルの先頭を指し示すようにする.テーブルが空の場合には,アドレス P2 にジャンプする.o
- Column: カーソル P1 (cursor P1) が指し示すレコードの P2 番目の桁 (P2-th column) からデータを取り出して,レジスタ P3 に格納する.(列番号は 0 から始まる)
- Rowid: カーソル P1 (cursor P1) が指し示すレコードの主キーの値を,レジスタ P2 に格納する.
- MakeRecord:
レジスタP1 から レジスタ(P1+P2-1) までの値を,テーブルの1行、あるいは索引のキー (key) として使うことを示す.
P4には column affinity を文字列として指定できる.column affinity の各文字は,SQLite バージョン 3.7.9 では次のように定義されている.
#define SQLITE_AFF_text 'a' #define SQLITE_AFF_NONE 'b' #define SQLITE_AFF_NUMERIC 'c' #define SQLITE_AFF_integer 'd' #define SQLITE_AFF_REAL 'e'
- IdxInsert: IdxInsert命令を実行すると,索引P1にデータを挿入する.
- ResultRow: レジスタP1 から レジスタ(P1+P2-1) までの値を1行として出力する
- SeekGe カーソルP1がテーブルを指し示しているときは,レジスタP3の値を検索キーとして使う。 カーソルP1が索引を指し示すときは,レジスタP3からレジスタ(P3+P4-1)までを使う. カーソルP1の位置を,検索キーに等しいか検索キーよりも大きいという条件を満足するなかで最小の要素を指し示すように動かす.そのような要素がない場合にはP2にジャンプする.
- IdxGE レジスタP3からレジスタ(P3+P4-1)までを検索キーとして使う.検索キーの値を,現在P1が指し示している索引を使って比較する. もし,P1が指し示す索引エントリ (index entry) が,検索キーの値1と等しいか大きければ P2 にジャンプする.さもなければ次に進む.
- Eq: レジスタP1 の値とレジスタ P3 の値が等しいときに限り,アドレス P2 (address P2) にジャンプする.
- Ne: レジスタP1 の値とレジスタ P3 の値が等しくないときに限り,アドレス P2 (address P2) にジャンプする.
- Next: もし,カーソル P1 (cursor P1) が指し示すレコードが末端レコードならば、次の命令に進む. もし,カーソル P1 (cursor P1) が指し示すレコードが末端レコードでなければ、カーソル P1 (cursor P1) を1つ進めて、アドレス P2 (address P2) にジャンプする.
- Goto: アドレス P2 (address P2) にジャンプする.
* SQLite 3 のオペコードの説明は http://www.hwaci.com/sw/sqlite/opcode.html にある.
* SQLite 3の SQL の説明は http://www.hwaci.com/sw/sqlite/lang.html (English Web Page) にある.
演習で行うこと
- 二次索引の生成
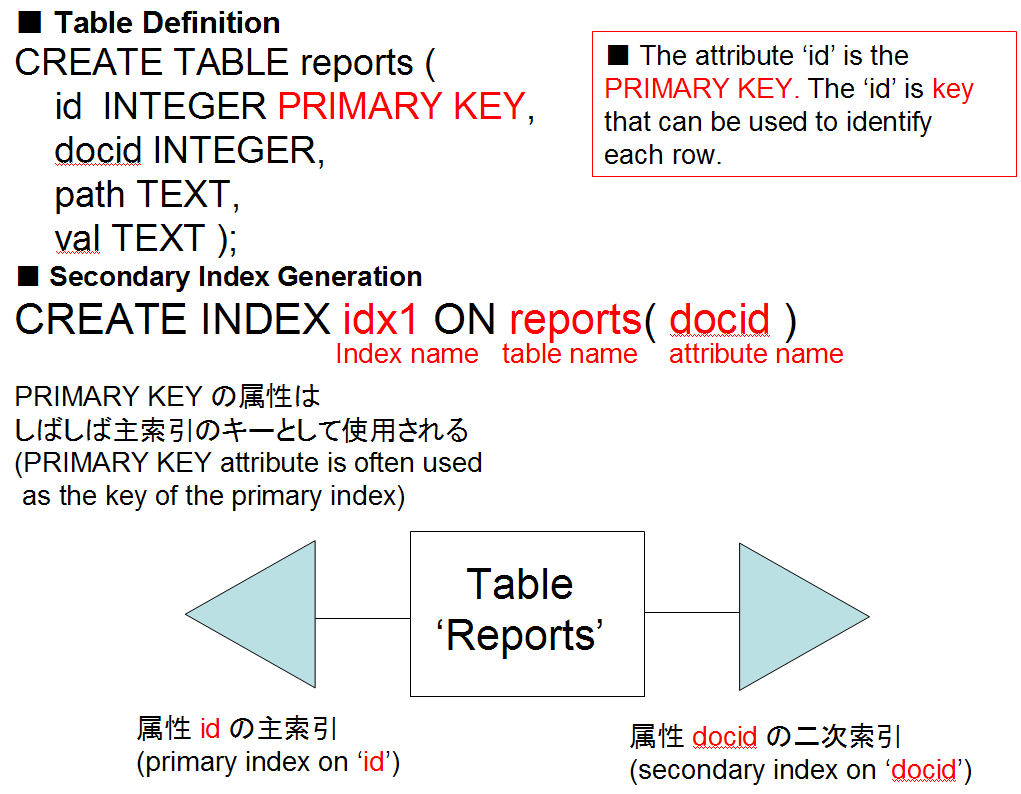
CREATE INDEX <index-name> ON <table-name> ( <column-name の並び> )
テーブル名と属性名を指定して,二次索引を生成する.「index-name」とあるのは二次索引の名前のことで,後で二次索引を削除したいときなどに使う.
SQLite 3 の SQL 演習に関連する部分
SQLite 3の SQL の説明は http://www.hwaci.com/sw/sqlite/lang.html (English Web Page) にある.
- CREATE INDEX <index-name> ON <table-name> ( <column-name の並び> )
テーブル名と属性名を指定して,二次索引を生成する.「index-name」とあるのは二次索引の名前のことで,後で二次索引を削除したいときなどに使う.
- DROP INDEX <index-name>;
索引名を指定して二次索引を削除する.
郵便番号データベース (Japanese ZIP code database)
郵便番号データベースは zips, kens, shichosons の 3 つのテーブルから構成される.
郵便番号データベースの作成手順については別の Web ページで説明している.
Sqliteman で既存のデータベースを開く
すでに作成済みのデータベースを,下記の手順で開くことができる.
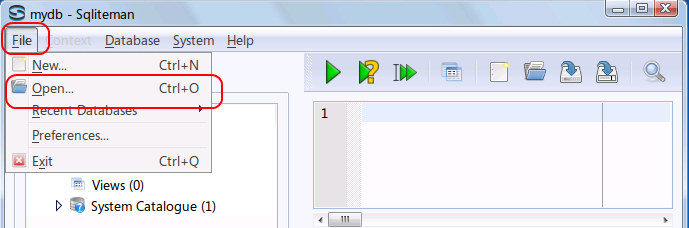
以下の手順で,既存のデータベースファイルを開く. (Open an existing database file)
- Sqliteman を起動する
- 「File」→
「Open」
- データベースファイルを開く
* Ubuntu での実行例(「SQLite/mydb」を開く場合)
データベースファイル SQLite/mydb を選び, 「開く」をクリック (Click '開く' after choosing the database file "SQLite/mydb")
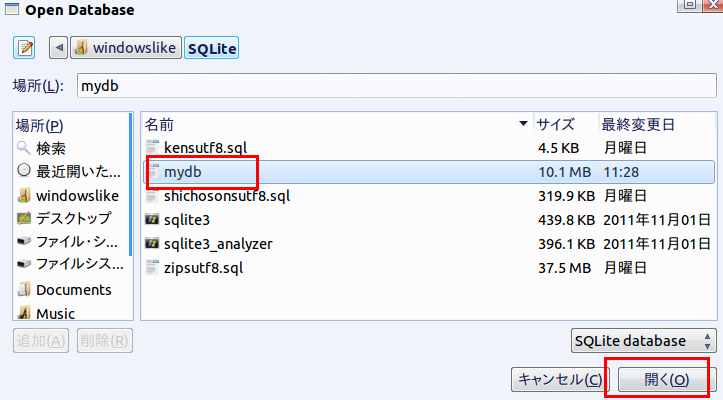
* Windows での実行例(「C:\SQLite\mydb」を開く場合)
データベースファイル C:\SQLite\mydb を選び, 「開く」をクリック (Click '開く' after choosing the database file "C:\SQLite\mydb")
要するに,/home/<ユーザ名>/SQLite 3の下の mydb を選ぶ.
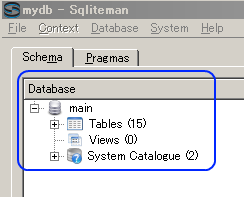
- データベースの中身が表示されるので確認する (Database appears)
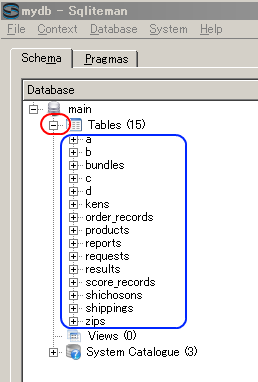
- 「Tables」を展開すると,テーブルの一覧 (List of Tables) が表示されるので確認する (List of tables appears by clicking 'Tables')
Sqliteman を用いたデータのブラウズ
zips, kens, shichosons テーブルの中身を表示してみる. 表示ができないというときは, zips, kens, shichosons テーブルを作る作業(前回の資料)を行っていないのかも知れない
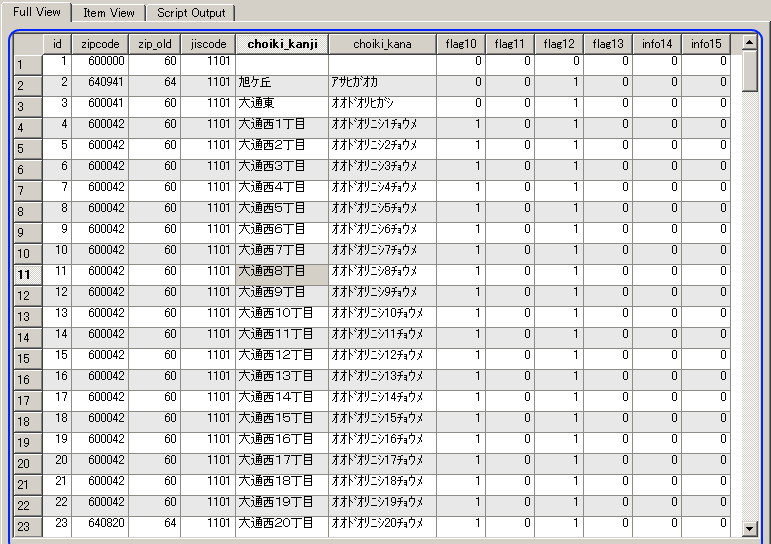
- zips テーブル
オブジェクト・ブラウザ (Object Browser) の中のzips テーブルを選ぶ (Select table 'zips')
テーブル zipsが表示される (table 'zips' appears)
データベースの構造の確認 (Database Structure)
- sqlite_master をクリック (Click 'sqlite_master)
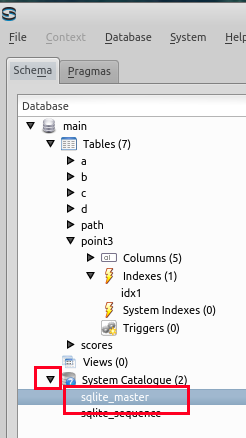
- テーブルと二次索引のルート・ページ番号が分かる
(Root page number of each table and secondary index)
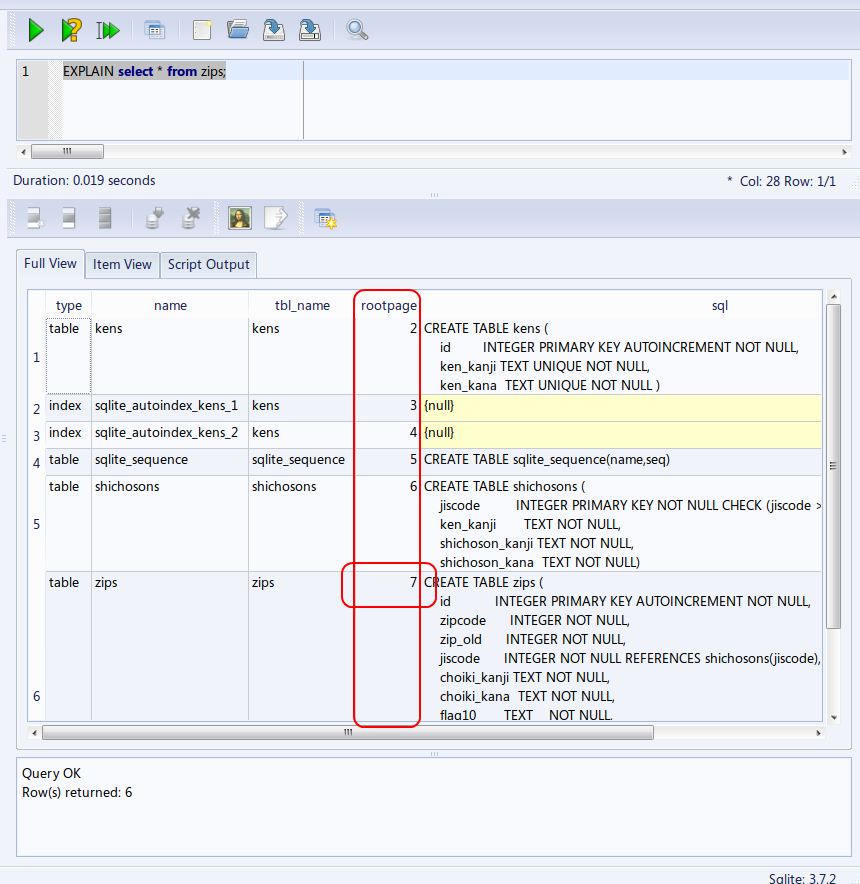
zips, kens, shichosons の 3 つのテーブルのルートページ (root page) は,この資料では,次の値になっているものとして説明を続ける.
- kens のルートページ: 2
- shichosons のルートページ: 6
- zips のルートページ: 7
* ルート・ページ番号は,SQLite 3 システムが決める値なので, 実際には,上とは違う値になっていることが多い,
(The number is automatically decided by the database management system)
Sqliteman を用いた SQL 問い合わせ計画の表示
単一テーブルに対する問い合わせの SQL 問い合わせ計画の表示例 (SQL query plan)
条件を満足する行のみの表示 (List the rows which satisfy a given condition)
- SQL の問い合わせの発行と評価結果の確認
SELECT zipcode, choiki_kanji FROM zips WHERE zipcode = 8190012;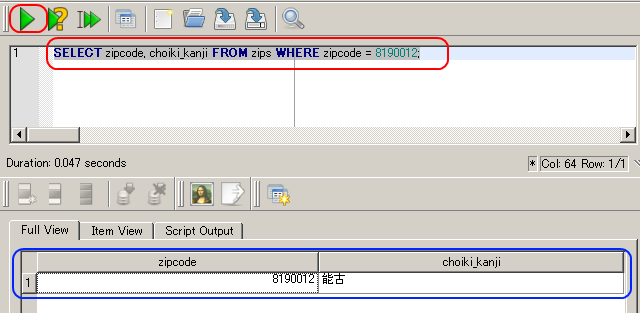
- SQL 問い合わせ計画の表示 (SQL query plan)
SQL 文の前に「EXPLAIN」を付ける.(Add 'EXPLAIN' before a SQL statement)
EXPLAIN SELECT zipcode, choiki_kanji FROM zips WHERE zipcode = 8190012;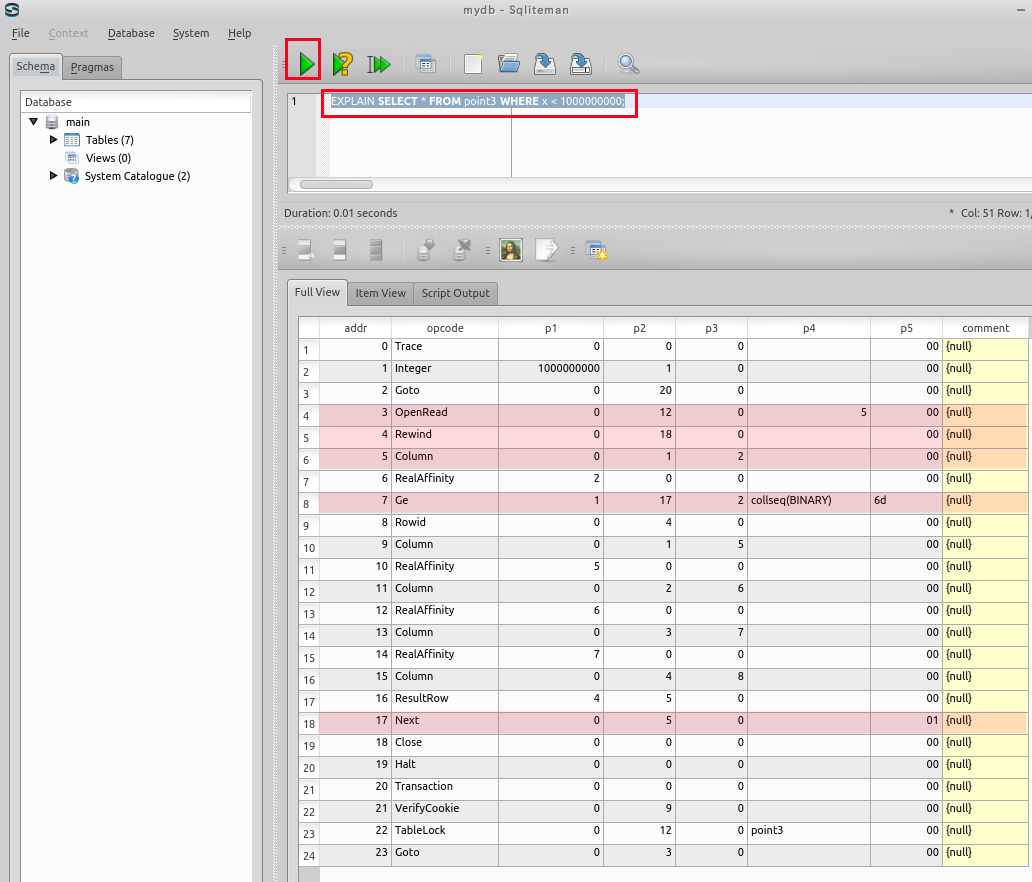
【表示された問い合わせ計画の要点】
アドレス (addr) オペコード 主なオペランド 1 Integer P1 = 8190012, P2 = 1 レジスタ1に,値8190012をセットする (store 8190012 into register #1) 3 OpenRead P2 = 7 ルート・ページが 7 であるようなテーブル (この場合は,テーブル zips) のカーソルを作る (Open table 'zips' for read, and make a cursor) 3 Rewind P2 = 11 カーソルを,テーブルの先頭を指し示すようにする.テーブルが空の場合には,アドレス 11 (Close)にジャンプする (Use the first row. If the first row is empty then jump to '11') 5 Column P2 = 1, P2 = 2 列番号1の値を,レジスタ 2 に格納する.(Save #1 column value into the register #2) 8 Ne P1 = 1, P2 = 10, P3 = 2 条件付きジャンプ. レジスタ 1 の値とレジスタ 2 の値が等しくないときに限り,アドレス 10 にジャンプする. (jump 10 if and only if register #1 is not equal to register #2) 7, 8 Column P2 = 1, 4, P2 = 4, 5 列番号1と4の値を,レジスタ 4 と 5 に格納する. 9 ResultRow P1 = 4, P2 = 2 レジスタ 4 からレジスタ 5 までの値 (出力されるレジスタは2個) を1行として出力する (Generate output using registers) 12 Next P2 = 5 もし,カーソルが指し示すレコードが末端レコードならば、次の命令に進む. もし,カーソルが指し示すレコードが末端レコードでなければ、カーソルを1つ進めて、アドレス5 (「Column 0 1 2」のところ) にジャンプする. (Advance cursor to the next tow. If there are more rows, then jump to the address '5') 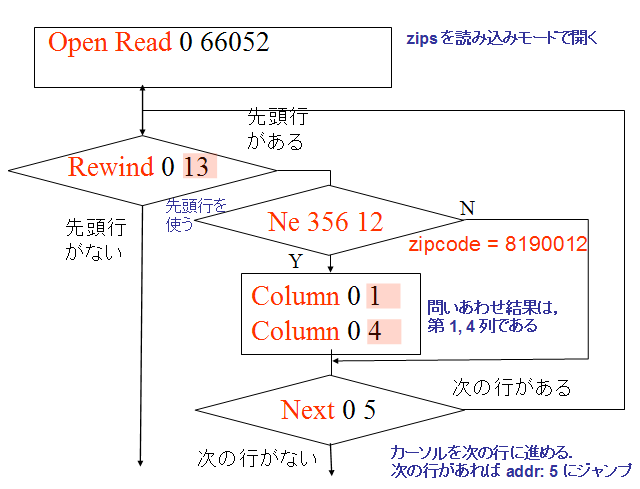
結合問い合わせの SQL 問い合わせ計画の表示例 (SQL query plan)
今度は結合問い合わせである (join query)
- SQL の問い合わせの発行と評価結果の確認
10秒以上はかかる.結果が出るまで待つ.
select distinct R.choiki_kanji FROM zips as R, zips as S WHERE R.choiki_kanji = S.choiki_kanji AND R.jiscode <> S.jiscode;
- SQL 問い合わせ計画の表示 (SQL query plan)
EXPLAIN select distinct R.choiki_kanji FROM zips as R, zips as S WHERE R.choiki_kanji = S.choiki_kanji AND R.jiscode <> S.jiscode;SQL 文の前に「EXPLAIN」を付ける.(Add 'EXPLAIN' before a SQL statement)
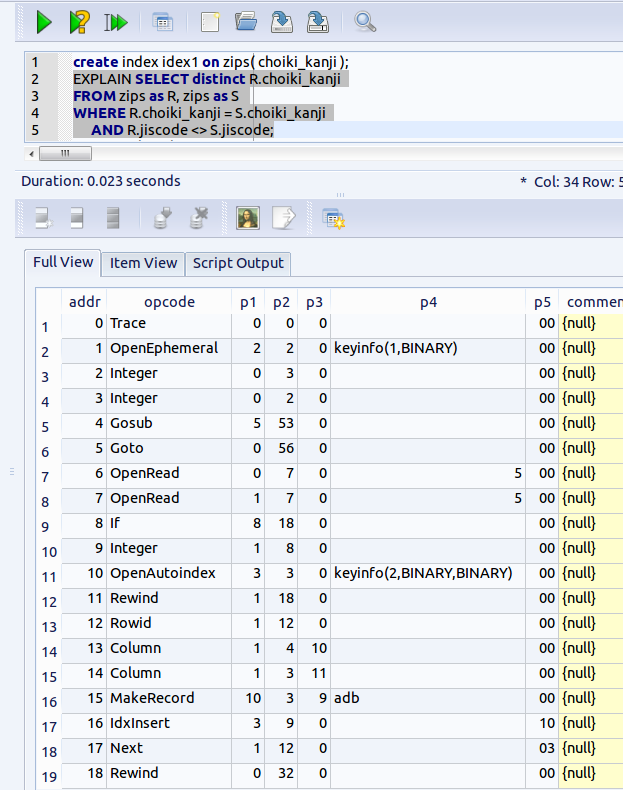
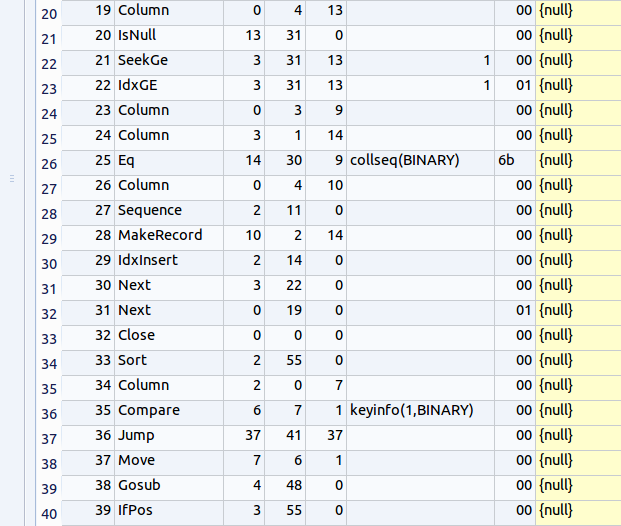
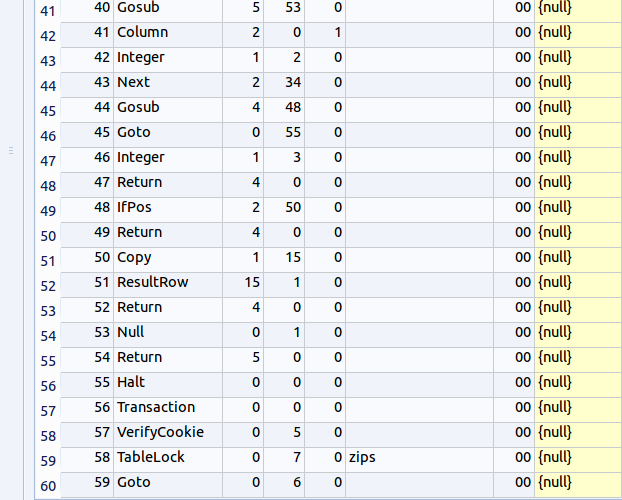
【表示された問い合わせ計画の要点】
要点のみを示す
アドレス (addr) オペコード 主なオペランド 6 OpenRead P1 = 0, P2 = 7 ルート・ページが 7 であるようなテーブル (この場合は,テーブル zips) のカーソルを作る. カーソル番号は 0 (Open table 'zips' for read, and make a cursor) 7 OpenRead P1 = 1, P2 = 7 ルート・ページが 7 であるようなテーブル (この場合は,テーブル zips) のカーソルを作る. カーソル番号は 1 (Open table 'zips' for read, and make a cursor) 11 Rewind P1 = 1, P2 = 18 カーソル 1 を,テーブルの先頭を指し示すようにする.テーブルが空の場合には,アドレス 18 にジャンプする (Use the first row. If the first row is empty then jump to '18') 12 Rowid P1 = 1, P2 = 12 カーソル 1 が指し示すレコードの主キーの値を、レジスタ12に格納する 13 Column P1 = 1, P2 = 4, P3 = 10 カーソル 1 が指し示すレコードの列番号4の値を,レジスタ 10 に格納する.(Save #4 column value into the register #10) 14 Column P1 = 1, P2 = 3, P3 = 11 カーソル 1 が指し示すレコードの列番号3の値を,レジスタ 11 に格納する.(Save #3 column value into the register #11) 15 MakeRecord P1 = 10, P2 = 3 レジスタ 10 からレジスタ 12 までの値からレコードをつくる(次の IdxInsert で使う) 16 IdxInsert P1 = 3, P2 = 9 索引 3 に,前の MakeRecord 命令で作ったレコードを挿入する. * 「索引 3」といっているのは、アドレス10の「OpenAutoindex」で生成された索引のことである。この索引は、今回の SQL 問い合わせの評価のために一時的に生成された索引である。MakeRecord 命令で作ったレコードの挿入が繰り返されるが、この「索引 3」を使って、整列(ソート)が行われる。 17 Next P1 = 1, P2 = 12 もし,カーソル 1 が指し示すレコードが末端レコードならば、次の命令に進む. もし,カーソル 1 が指し示すレコードが末端レコードでなければ、カーソルを1つ進めて、アドレス12 にジャンプする. (Advance cursor to the next tow. If there are more rows, then jump to the address '12') 18 Rewind P1 = 0, P2 = 32 カーソル 0 を,テーブルの先頭を指し示すようにする.テーブルが空の場合には,アドレス 32 にジャンプする (Use the first row. If the first row is empty then jump to '32') 19 Column P1 = 0, P2 = 4, P3 = 13 カーソル 0 が指し示すレコードの列番号4の値を,レジスタ 13 に格納する.(Save #4 column value into the register #13) 21 SeekGe P1 = 3, P2 = 31, P3 = 13, P4 = 1 いま,カーソル 3 は,「索引 3」を指し示している. カーソル 3の位置を,レジスタ13に入っている検索キーに等しいか検索キーよりも大きいという条件を満足するなかで最小の要素を指し示すように動かす.そのような要素がない場合には31にジャンプする. 22 IdxGe P1 = 3, P2 = 31, P3 = 13, P4 = 1 レジスタ13を検索キーとして使う. 検索キーの値を,現在,カーソル3が指し示している索引(正確にはカーソル3が指し示している索引エントリ)を使って比較する. もし,カーソル3が指し示す索引エントリが,検索キーの値と等しいか大きければ31にジャンプするさもなければ次に進む. 23 Column P1 = 0, P2 = 3, P3 = 9 カーソル 0 が指し示すレコードの列番号3の値を,レジスタ 9 に格納する.(Save #3 column value into the register #11) 24 Column P1 = 3, P2 = 1, P3 = 14 カーソル 3 が指し示すレコードの列番号1の値を,レジスタ 14 に格納する.(Save #1 column value into the register #14) 25 Eq P1 = 14, P2 = 30, P3 = 9 条件付きジャンプ. レジスタ 14 の値とレジスタ 9 の値が等しくないときに限り,アドレス 30 にジャンプする. 26 Column P1 = 0, P2 = 4, P3 = 10 カーソル 0 が指し示すレコードの列番号4の値を,レジスタ 10 に格納する. 28 MakeRecord P1 = 10, P2 = 2 レジスタ 10 からレジスタ 11 までの値からレコードをつくる(次の IdxInsert で使う) 29 IdxInsert P1 = 2, P2 = 14 カーソル 2 のために,新しい通し番号 (sequence number) を見つける。これを行っている理由は「DISCINCT」指定による重複除去を行いたいから. * 「カーソル 2」といっているのは,最終結果として出力されるテーブルのために作られたカーソルのことである。このカーソルは、アドレス1の「OpenEmphemeral」命令で生成されている。 30 Next P1 = 3, P2 = 22 もし,カーソル 3 が指し示すレコードが末端レコードならば、次の命令に進む. もし,カーソル 22 が指し示すレコードが末端レコードでなければ、カーソルを1つ進めて、アドレス22 にジャンプする. 31 Next P1 = 0, P2 = 19 もし,カーソル 0 が指し示すレコードが末端レコードならば、次の命令に進む. もし,カーソル 0 が指し示すレコードが末端レコードでなければ、カーソルを1つ進めて、アドレス19 にジャンプする.
Sqliteman を用いた二次索引の追加 (generate a secondary index using Sqliteman)
ここでは,テーブル zips の属性 choiki_kanjiの二次索引を作る. (Generate a secondary index of the table 'zips')- CREATE INDEX を用いた二次索引の生成 (Generate a secondary index using 'CREATE INDEX')
CREATE INDEX idx1 ON zips( choiki_kanji );
「idx1は索引名である.索引の管理(索引の削除など)に使用される. ('idx1' is index name).
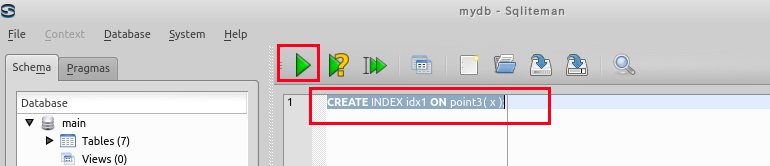
索引は数秒以内で生成される.(The secondary index will be generated in a several seconds)
- Sqliteman での二次索引の確認
idx1 が出来ている
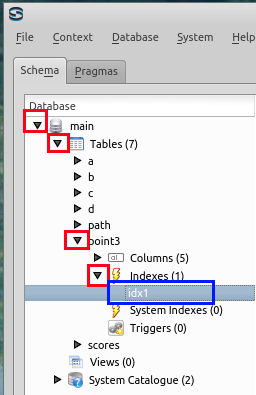
二次索引による問い合わせ計画の変化 (secondary index and query plan)
* データベースの構造の確認 (Database Structure)
sqlite_master をクリック (Click 'sqlite_master)

テーブルと二次索引のルート・ページ番号が分かる (Root page number of each table and secondary index)
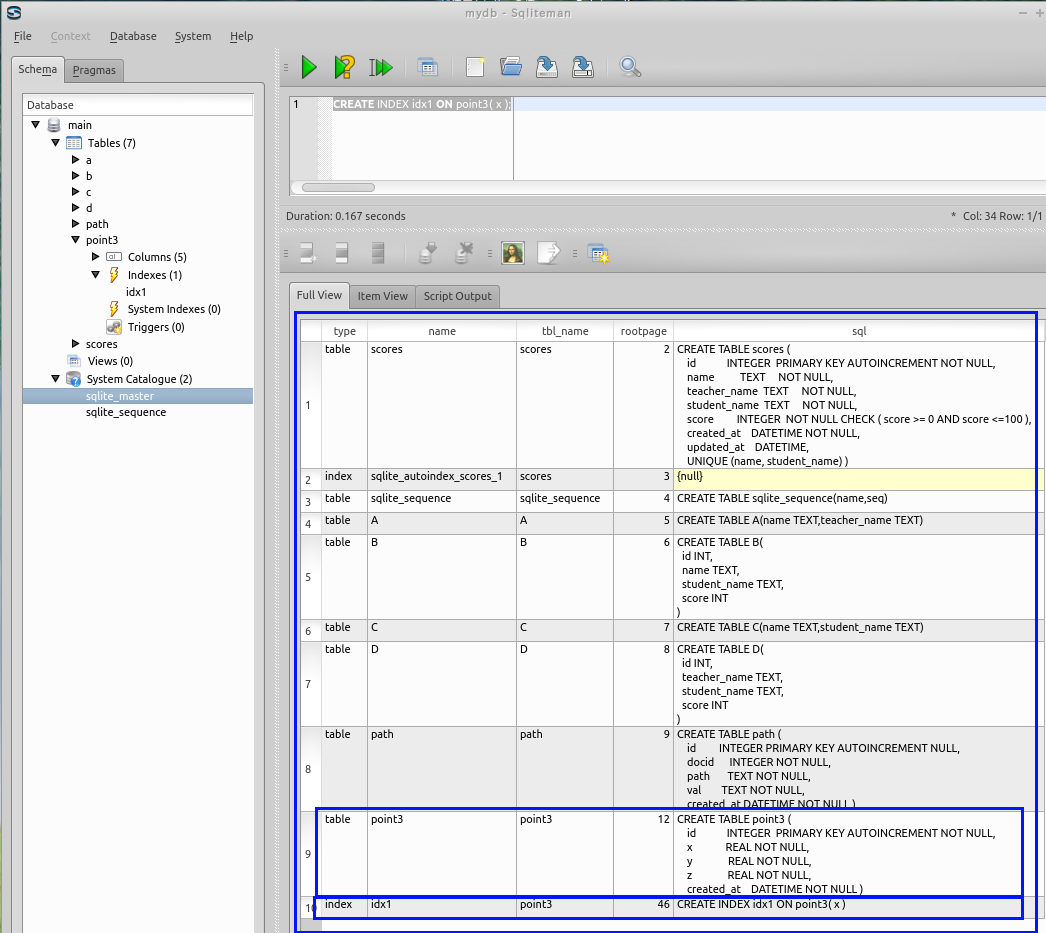
(Inspect the root page number of the secondary index 'idx1'. The number is automatically decided by the database management system)
問い合わせ計画の表示 (query plan)
今度は,先ほどと同じ SQL 問い合わせを評価させる. 評価結果は同じになる. 評価にかかる時間は速くなる.
select distinct R.choiki_kanji
FROM zips as R, zips as S
WHERE R.choiki_kanji = S.choiki_kanji
AND R.jiscode <> S.jiscode;

SQL 文の前に「EXPLAIN」を付ける.(Add 'EXPLAIN' before a SQL statement)
EXPLAIN select distinct R.choiki_kanji
FROM zips as R, zips as S
WHERE R.choiki_kanji = S.choiki_kanji
AND R.jiscode <> S.jiscode;
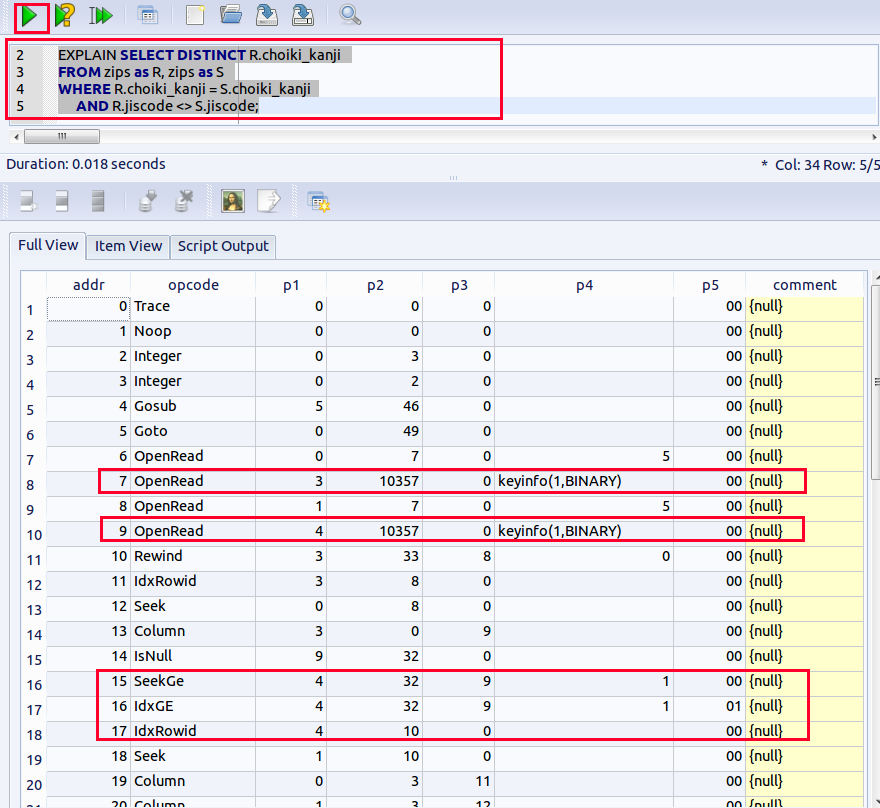

【問い合わせ計画の要点】
二次索引が働くとき,処理は二次索引上で行われる.
最初,カーソルは二次索引の先頭ページにセットされる. 二次索引の中から,「jiscode = 40135」という条件式を満たす索引エントリを見つけ, そのエントリを使って,データが取り出される. カーソルは,二次索引の中だけを動く.
- 二次索引のサイズは,テーブル本体のサイズよりずっと小さい (The size of secondary index is much smaller than the table)
- 二次索引は,高速処理に向いたデータ構造になっている (Secondary index is fast access path)
演習問題
次の問いに答えよ. Answer the following questions.
問い (Questions)
- 次の PTABLE テーブルに関する問題 (About the following 'PTABLE' table)
name | type | color ------------------------------ apple | fruit | red apple | fruit | blue rose | flower | white rose | flower | red rose | flower | yellow
このテーブルの行数は 1,000,000 行以上に増える予定である.(The number of row of the table will be more than 1,000,000).
次の SQL を高速に処理するための二次索引を生成しなさい.二次索引の索引名は「idx3」にしなさい. (Write a SQL to generate a secondary index named 'idx3' that is used for the following SQL)
SELECT * FROM PTABLE WHERE name = 'apple'
- 次の PLACE テーブルに関する問題 (About the following 'PLACE' table)
name | x | y ------------------------------ tenji | 101 | 104 hakata | 180 | 125 nishijin| 45 | 108
このテーブルの行数は 1,000,000 行以上に増える予定である.(The number of row of the table will be more than 1,000,000).
次の SQL を高速に処理するための二次索引を下記の中から選びなさい.二次索引の索引名は「idx4」にしなさい. (Write a SQL to generate a secondary index named 'idx4' that is used for the following SQL)
SELECT * FROM PLACE WHERE x > 80 AND x < 120 AND y > 90 AND y < 110
- CREATE INDEX idx4 ON PLACE( x, y );
- CREATE INDEX idx4 ON PLACE( name, x );
- CREATE INDEX idx4 ON PLACE( name, y );
- 次のテーブルに関する問題 (About the following table)
create table R ( id integer primary key, val integer, note text );
テーブル R の属性 val に対する二次索引を生成した場合,どのような処理が遅くなるか? (What kinds of database processing become slower when a secondary index on 'val' of the table 'R').
- 下記を行いなさい (Do the followings)
- SQLite を使い,下記のテーブルを定義しなさい (Define tables below using SQL)
FF (id, name, price) - FF の属性 name に二次索引を作りなさい (Generate a secondary index on 'name' of 'FF')
- SQLite を使い,下記のテーブルを定義しなさい (Define tables below using SQL)
解答例 (Answers)
- CREATE INDEX idx3 ON PTABLE( name );
- CREATE INDEX idx4 ON PLACE( x, y );
- テーブル R への行の挿入や削除が遅くなる (Insertion of rows into R. Deletion of rows from R).
-
create table FF ( id integer primary key, name text, price integer ); CREATE INDEX idx5 ON FF( name );