CSV ファイルに対して SQL 問い合わせを実行
CSV ファイルに対する SQL 問い合わせの実行を行う方法は種々ある.
手軽にできるもの複数紹介する.
使用する CSV ファイルの先頭行には,各列の属性名が書かれているものとする.
【目次】
1. 前準備
前準備として CSV ファイルを準備
ここでは,csvkit に同封されているデータファイルである ks_1033_data.csv
次の URL からダウンロードして使用.
https://github.com/wireservice/csvkit/tree/master/examples/realdata
他の CSV ファイルを使うときの注意点としては,用する CSV ファイルの先頭行には,各列の属性名が書かれていること.
2. SQLite 3 を用いる
SQLite 3 のインストール
SQL 問い合わせの例
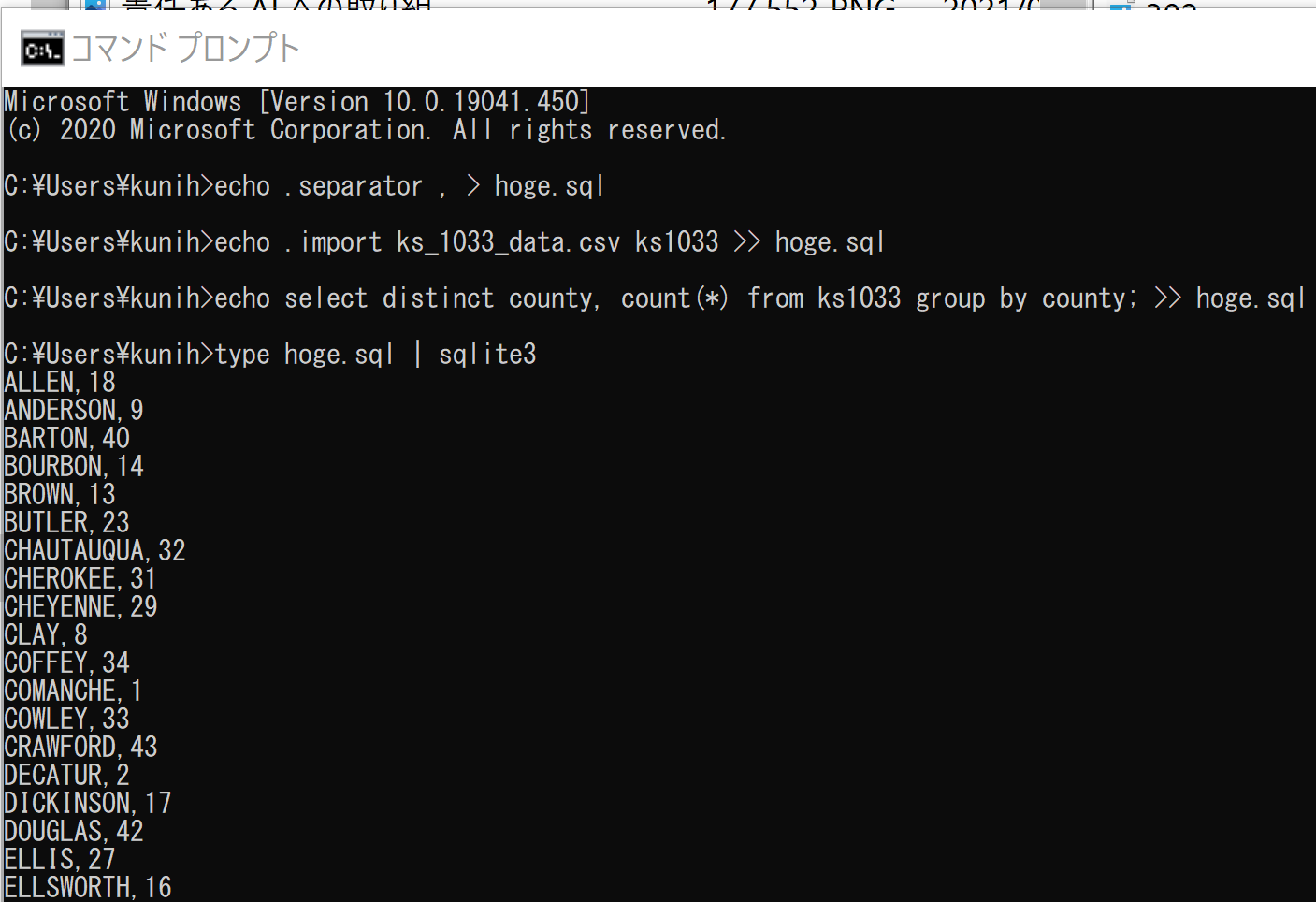
Windows の場合は次のようなコマンドを実行.
echo .separator , > hoge.sql
echo .import ks_1033_data.csv ks1033 >> hoge.sql
echo select distinct county, count(*) from ks1033 group by county; >> hoge.sql
type hoge.sql | sqlite3
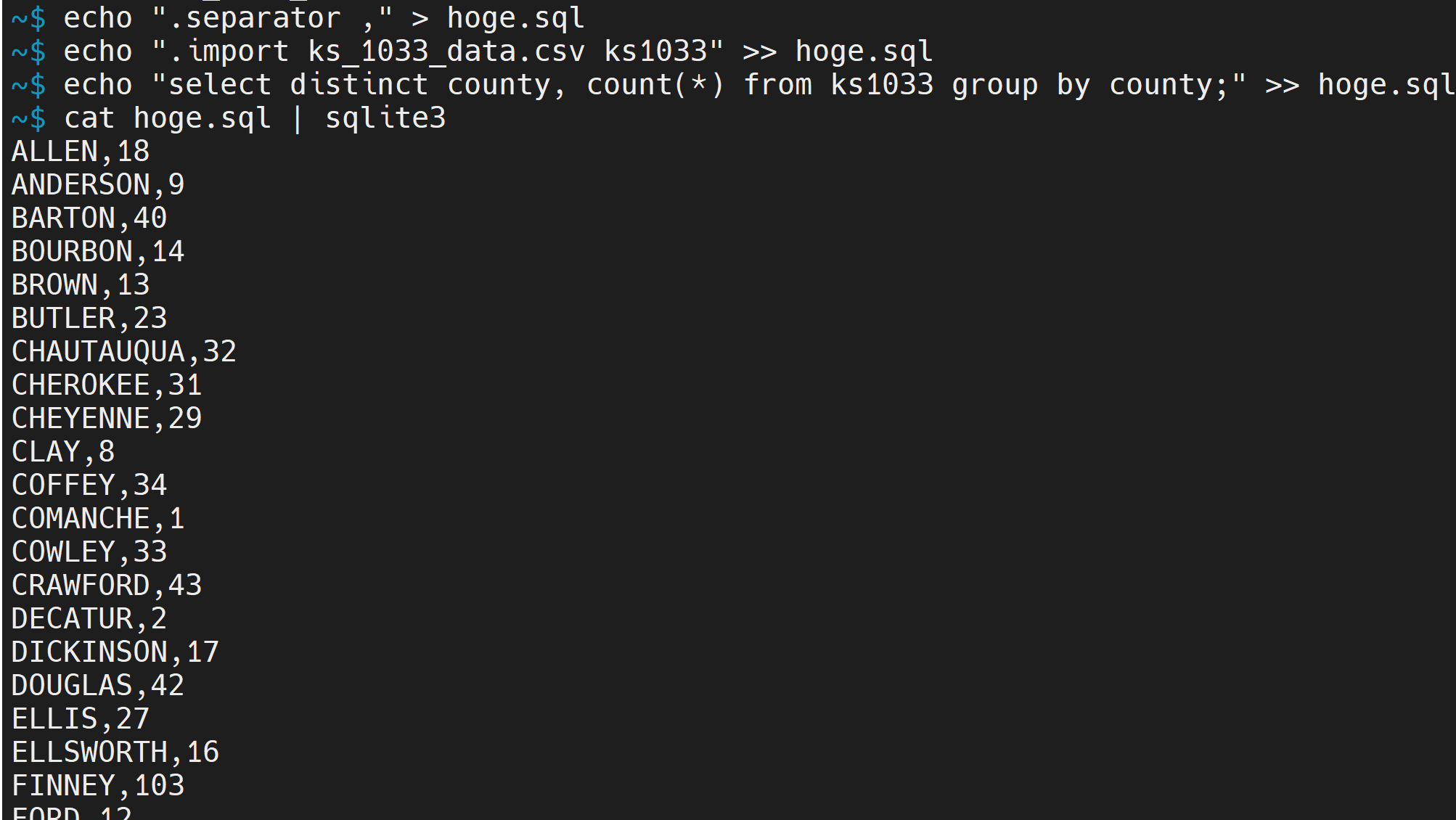
Ubuntu の場合は次のようなコマンドを実行.「type」 の代わりに cat.
echo ".separator ," > hoge.sql
echo ".import ks_1033_data.csv ks1033" >> hoge.sql
echo "select distinct county, count(*) from ks1033 group by county;" >> hoge.sql
cat hoge.sql | sqlite3
3. pandasql を用いる
Pandas データフレームの詳細は 別ページ »にまとめ
前準備
Windows の場合
- Python のインストール: 別ページ »で説明
Python の公式ページ: https://www.python.org/
- pandas と pandasql のインストール
Windows では,コマンドプロンプトを管理者として実行し, 次のコマンドを実行する.
python -m pip install pandas pandasql
Ubuntu の場合
pandas と pandasql のインストール
次のコマンドを実行する.
# パッケージリストの情報を更新
sudo apt update
sudo apt -y install python3-pandas
sudo pip3 install pandasql
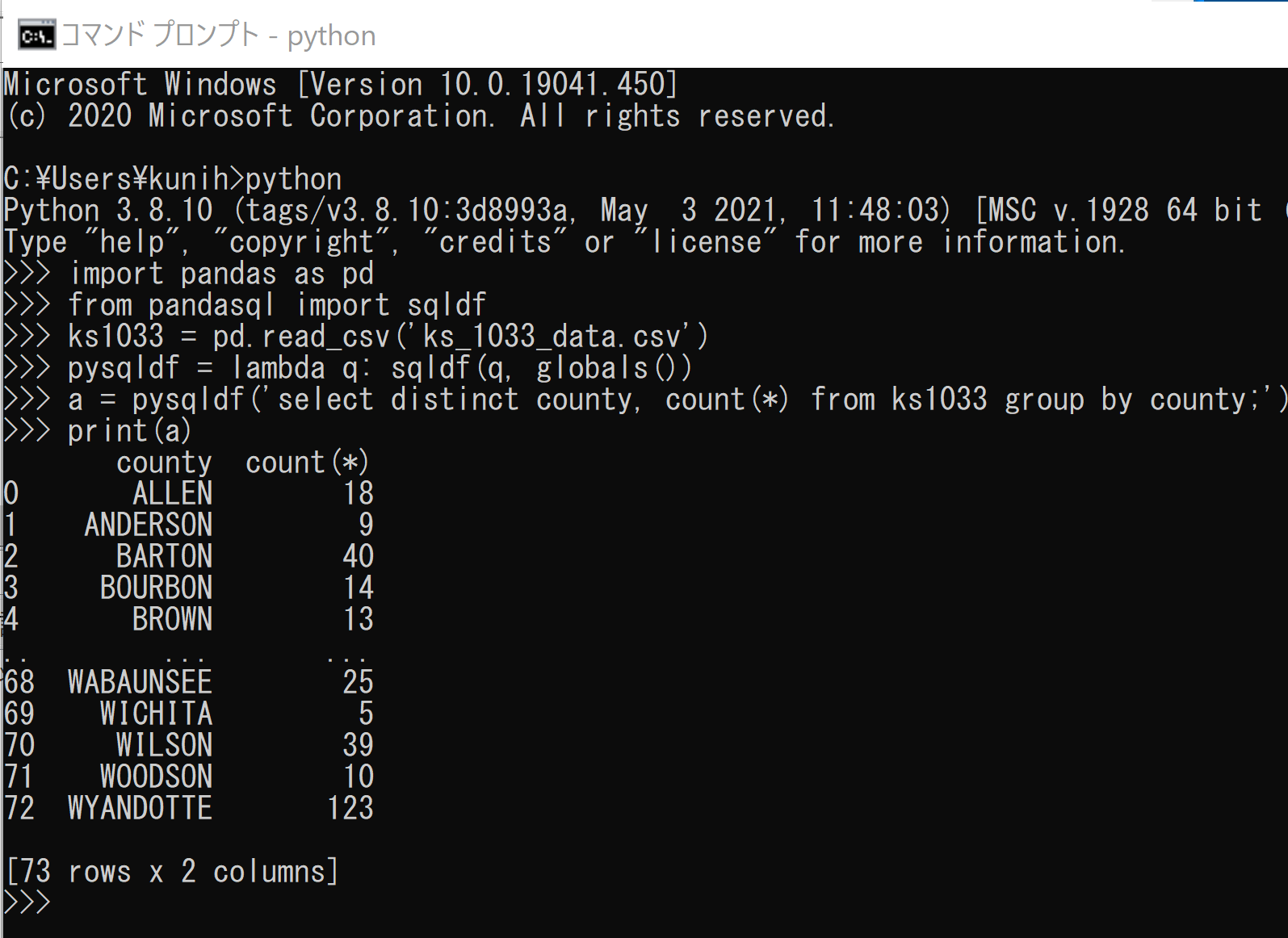
pandasql を用いた SQL 問い合わせの例
Python プログラム
import pandas as pd
from pandasql import sqldf
ks1033 = pd.read_csv('ks_1033_data.csv')
pysqldf = lambda q: sqldf(q, globals())
a = pysqldf('select distinct county, count(*) from ks1033 group by county;')
print(a)
4. csvkit を用いる
csvkit のインストール
csvkit のインストール
- Windows の場合
Windows で,管理者権限でコマンドプロンプトを起動(手順:Windowsキーまたはスタートメニュー >
cmdと入力 > 右クリック > 「管理者として実行」)。.次のように操作する.
python -m pip install csvkit - Ubuntu の場合
端末で,次のコマンドを実行する.
sudo apt -y install csvkit python3-csvkit
csvkit を用いた SQL 問い合わせの例
コマンド
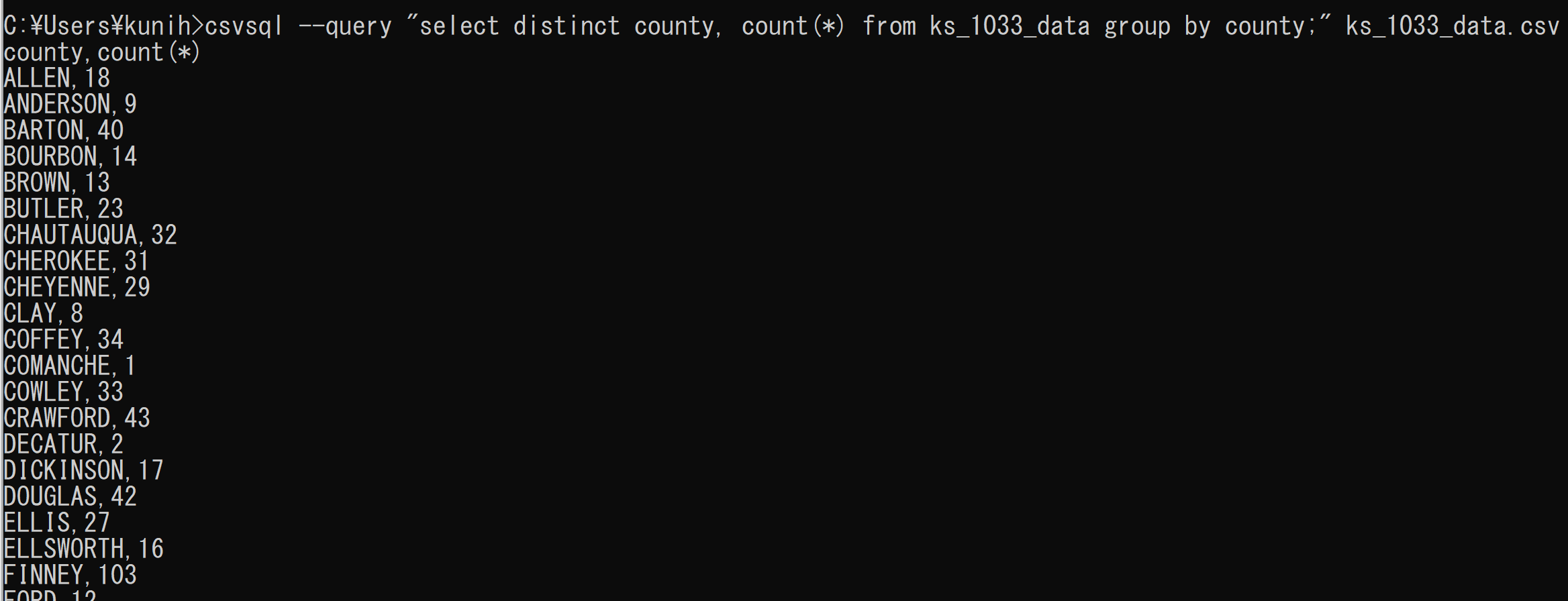
csvsql --query "select distinct county, count(*) from ks_1033_data group by county;" ks_1033_data.csv
5. TicklishHoneyBee/csvdb を用いる(Ubuntu 上)
TicklishHoneyBee/csvdb のインストール(Ubuntu 上)
Ubuntu の場合次のコマンドを実行.
cd /var/tmp
rm -rf csvdb
git clone https://github.com/TicklishHoneyBee/csvdb
cd csvdb
autoreconf -i
./configure
make
sudo make install
TicklishHoneyBee/csvdb を用いた SQL 問い合わせの例
コマンド
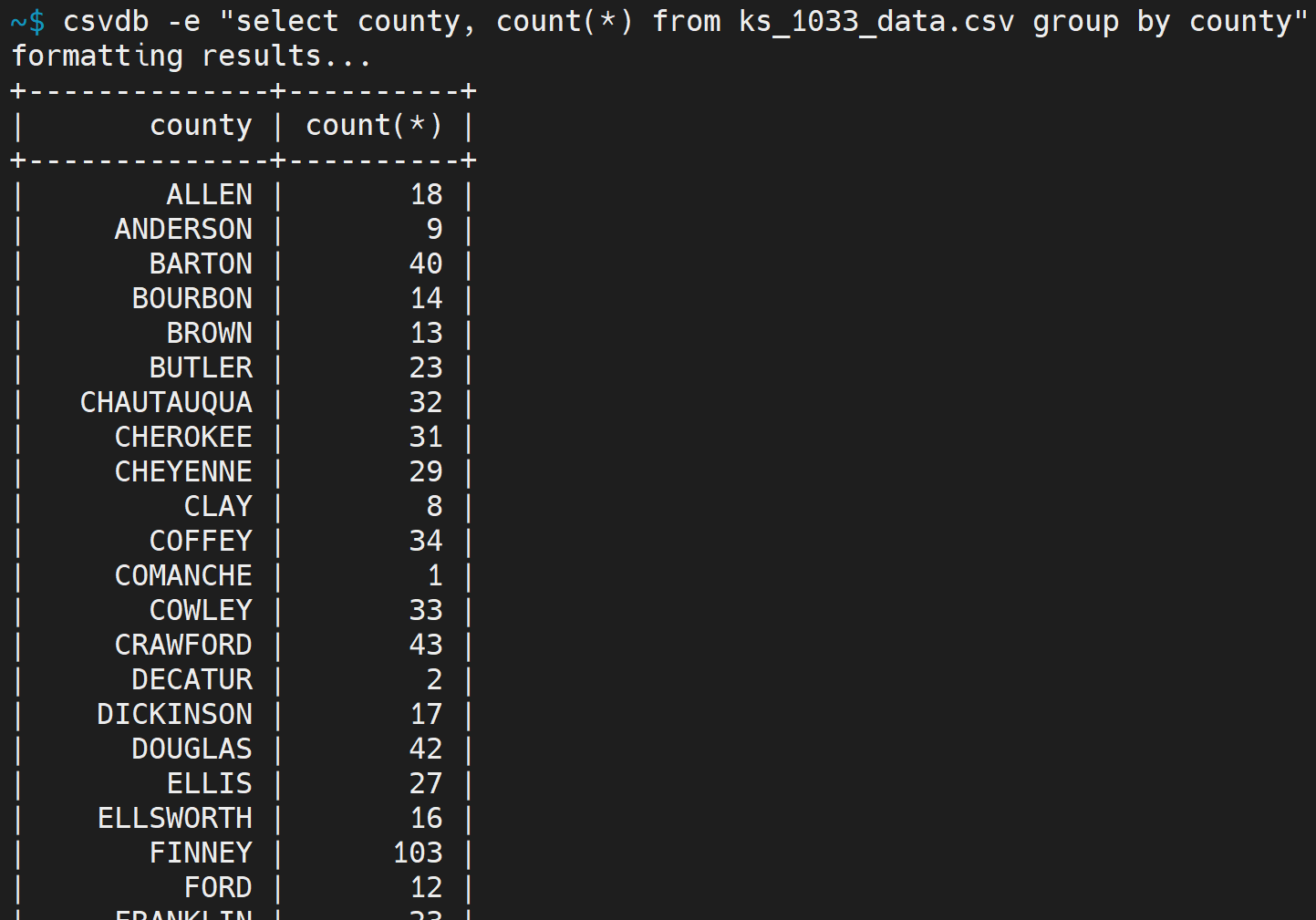
csvdb -e "select county, count(*) from ks_1033_data.csv group by county"
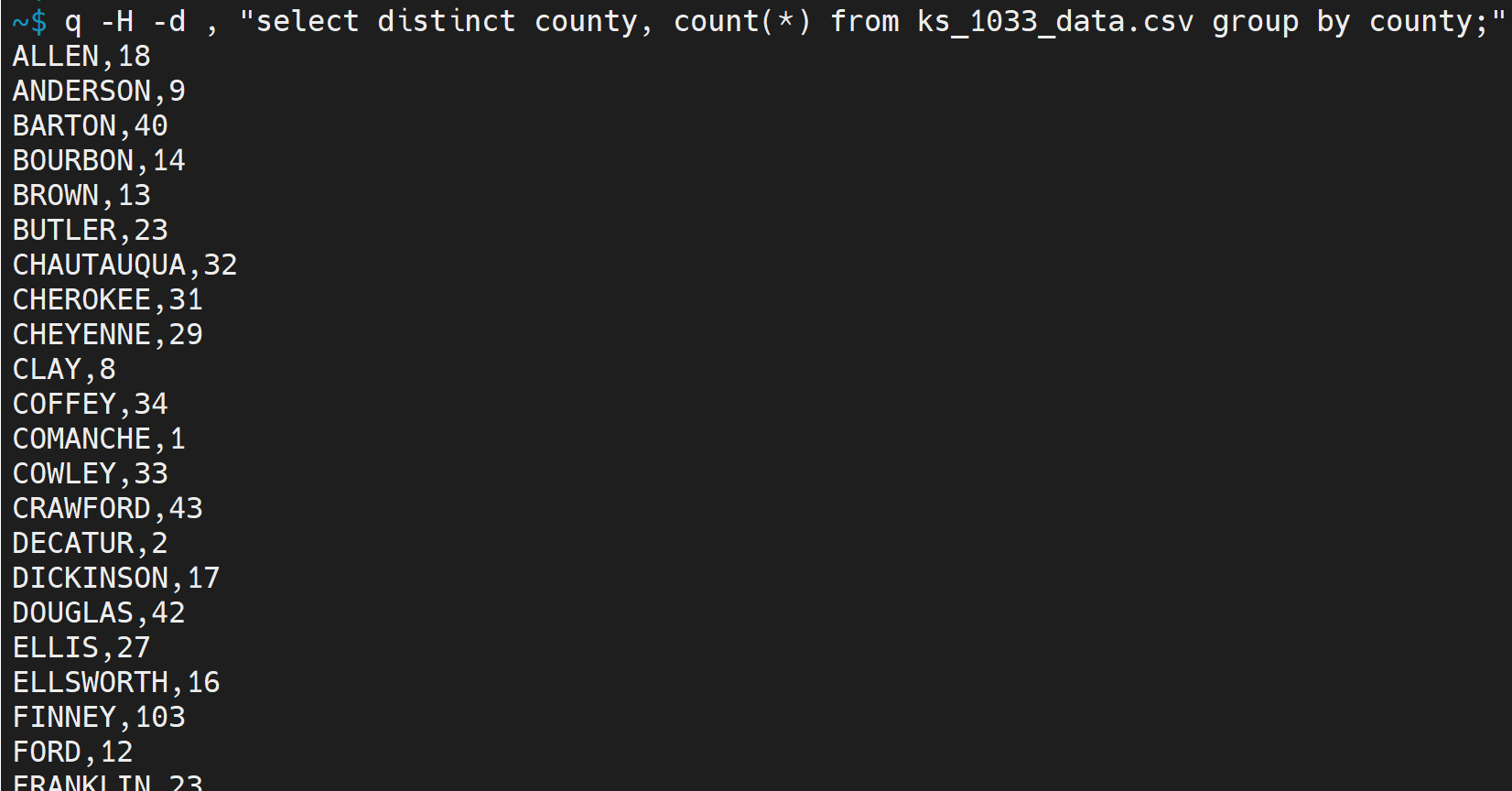
6. q を用いる
Ubuntu の場合の前準備
次のコマンドを実行.
sudo apt install python3-q-text-as-data
q を用いた SQL 問い合わせの例
コマンド
q -H -d , "select distinct county, count(*) from ks_1033_data.csv group by county;"