くずし字 MNIST データセット(Kuzushiji-MNIST データセット)のダウンロード,画像分類の学習,画像分類の実行
【概要】
くずし字 MNIST データセット(Kuzushiji-MNIST データセット)は,手書きのくずし字を 28×28 画素のグレースケール画像として収めた,機械学習用の公開データセット(オープンデータ)である.Kuzushiji-MNIST は 10 クラス,Kuzushiji-49 は 49 クラスの文字からなる.本資料では,このデータセットのダウンロード,画像分類の学習,画像分類の実行までを説明する.利用条件は利用者自身で確認すること.
* くずし字 MNIST データセット(Kuzushiji-MNIST データセット)
くずし字 MNIST データセットは,公開されているデータセット(オープンデータ)である.
【文献】 CODH(Center for Open Data in the Humanities), KMNIST データセット(機械学習用くずし字データセット), arXiv:1812.01718 [cs.CV], 2018.
【目次】
【関連する外部ページ】
- くずし字 MNIST データセットの公式ページ:
https://github.com/rois-codh/kmnist
Kuzushiji-MNIST, Kuzushiji-49, Kuzushiji-Kanji の 3 種類が公開されている(オープンデータ).
【サイト内の関連情報】
第1章 前準備
Git のインストール
Git の URL: https://git-scm.com/
第2章 Python 3.12 のインストール
Pythonのインストールを行い、Pythonのプログラムを実行する環境を整える。扱う環境は、Windows搭載パソコンである。金子研究室では、Python 3.12.10を推奨する。
[Windows での Python 3.12 のインストール手順を見るには、ここをクリック]
Windows での Python 3.12 のインストール
以下のいずれかの方法でPython 3.12をインストールする。Pythonがインストール済みの場合、この手順は不要である。
方法 1:winget によるインストール
【インストールコマンドの実行方法】
管理者権限でコマンドプロンプトを起動する(手順:Windowsキーまたはスタートメニュー → cmd と入力 → 右クリック → 「管理者として実行」)。そして、コマンド全体をコマンドプロンプトにコピー&ペーストする。
--scope machine を指定することで、システム全体(全ユーザー向け)にインストールされる。このオプションの実行には管理者権限が必要である。インストール完了後、コマンドプロンプトを再起動するとPATHが反映される。
REM Python 3.12 をシステム領域にインストール
winget install --id Python.Python.3.12 -e --scope machine --silent --accept-source-agreements --accept-package-agreements --override "/quiet InstallAllUsers=1 PrependPath=1 Include_test=0 Include_pip=1 Include_launcher=1 InstallLauncherAllUsers=1 TargetDir=\"C:\Program Files\Python312\""
REM Python と Scripts を PATH 先頭に追加
powershell -NoProfile -Command "$p='C:\Program Files\Python312'; $s=\"$p\Scripts\"; $c=[Environment]::GetEnvironmentVariable('Path','Machine'); if((Test-Path $p) -and (';'+$c+';' -notlike \"*;$p;*\") -and (';'+$c+';' -notlike \"*;$s;*\")){[Environment]::SetEnvironmentVariable('Path',\"$p;$s;$c\",'Machine')}"
方法 2:インストーラーによるインストール
- Python公式サイト(https://www.python.org/downloads/)にアクセスし、「Download Python 3.x.x」ボタンからWindows用インストーラーをダウンロードする。
- ダウンロードしたインストーラーを実行する。
- 初期画面の下部に表示される「Add python.exe to PATH」にチェックを入れてから「Customize installation」を選択する。このチェックを入れ忘れると、コマンドプロンプトから
pythonコマンドを実行できない。 - 「Install Python 3.xx for all users」にチェックを入れ、「Install」をクリックする。
インストールの確認
コマンドプロンプトで以下を実行する。
python --versionバージョン番号(例:Python 3.12.x)が表示されればインストール成功である。「'python' は、内部コマンドまたは外部コマンドとして認識されていません。」と表示される場合は、インストールが正常に完了していない。
第3章 Python の開発環境 Visual Studio Code のインストールと Python 用の設定
Python の開発環境Visual Studio Code(プログラムを編集するソフトウェア。以下、VS Code)を整える。
[Windows での Visual Studio Code のインストールと Python 用の設定手順を見るには、ここをクリック]
Windows での Visual Studio Code のインストールと Python 用の設定手順
1. VS Code と拡張機能のインストール
以下のコマンドにより,既存の VS Code を削除し,全ユーザー共有の設定で再インストールしたうえで,拡張機能(VS Code に機能を追加するソフトウェア)をまとめて導入する.
【インストールコマンドの実行方法】
管理者権限でコマンドプロンプトを起動する(手順:Windows キーまたはスタートメニュー → cmd と入力 → 右クリック → 「管理者として実行」)。そして,コマンド全体をコマンドプロンプトにコピー&ペーストする。
インストールコマンド
REM ============================================================
REM Microsoft Visual Studio Code
REM ============================================================
winget uninstall -e --id Microsoft.VisualStudioCode --silent --disable-interactivity --accept-source-agreements
rmdir /s /q C:\ProgramData\vscode-extensions 2>nul
rmdir /s /q "%APPDATA%\Code" 2>nul
rmdir /s /q "%USERPROFILE%\.vscode" 2>nul
rmdir /s /q "%LOCALAPPDATA%\Microsoft\vscode-update" 2>nul
REM VS Code をシステム領域に新規インストール
winget install --scope machine --id Microsoft.VisualStudioCode -e --silent --accept-source-agreements --accept-package-agreements
REM 全ユーザー共有の拡張機能フォルダ
mkdir C:\ProgramData\vscode-extensions 2>nul
icacls "C:\ProgramData\vscode-extensions" /grant "Everyone:(OI)(CI)M" /T
REM スタートメニューのショートカットを --extensions-dir 付きで再作成
rmdir /s /q "C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code" 2>nul
del "C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code.lnk" 2>nul
powershell -NoProfile -Command "$s=New-Object -ComObject WScript.Shell; $lnk=$s.CreateShortcut('C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code.lnk'); $lnk.TargetPath='C:\Program Files\Microsoft VS Code\Code.exe'; $lnk.Arguments='--extensions-dir \"C:\ProgramData\vscode-extensions\"'; $lnk.Save()"
REM ショートカットの検証
powershell -NoProfile -Command "$s=New-Object -ComObject WScript.Shell; $lnk=$s.CreateShortcut('C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code.lnk'); Write-Host 'TargetPath:' $lnk.TargetPath; Write-Host 'Arguments:' $lnk.Arguments"
REM ファイル / フォルダ右クリックの「Code で開く」を登録
reg add "HKLM\SOFTWARE\Classes\*\shell\VSCode\command" /ve /d "\"C:\Program Files\Microsoft VS Code\Code.exe\" --extensions-dir \"C:\ProgramData\vscode-extensions\" \"%1\"" /f
reg add "HKLM\SOFTWARE\Classes\Directory\shell\VSCode\command" /ve /d "\"C:\Program Files\Microsoft VS Code\Code.exe\" --extensions-dir \"C:\ProgramData\vscode-extensions\" \"%1\"" /f
reg add "HKLM\SOFTWARE\Classes\Directory\Background\shell\VSCode\command" /ve /d "\"C:\Program Files\Microsoft VS Code\Code.exe\" --extensions-dir \"C:\ProgramData\vscode-extensions\" \"%V\"" /f
REM --extensions-dir 付きで起動する code.cmd ラッパを作成
REM (%* を echo で書くと対話的 cmd で失われるため、PowerShell で [char]37+'*' を書き出す)
powershell -NoProfile -Command "$pct=[char]37; $q=[char]34; $c='@echo off'+[char]13+[char]10+$q+'C:\Program Files\Microsoft VS Code\bin\code.cmd'+$q+' --extensions-dir '+$q+'C:\ProgramData\vscode-extensions'+$q+' '+$pct+'*'+[char]13+[char]10; [IO.File]::WriteAllText('C:\ProgramData\vscode-extensions\vscode.cmd',$c,[Text.Encoding]::ASCII)"
REM 拡張機能のインストール
set "CODE=C:\Program Files\Microsoft VS Code\bin\code.cmd"
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --uninstall-extension GitHub.copilot
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --uninstall-extension GitHub.copilot-chat
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension ms-python.python
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension ms-python.vscode-pylance
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension ms-python.debugpy
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension MS-CEINTL.vscode-language-pack-ja
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension saoudrizwan.claude-dev
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension rust-lang.rust-analyzer
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension tamasfe.even-better-toml
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension anthropic.claude-code
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension almenon.arepl
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --list-extensions --show-versions
echo === セットアップ完了 ===
2. Python インタプリタの選択
同一マシンに複数の Python がインストールされている場合,VS Code で使用する Python 本体(インタプリタ:Python プログラムを解釈・実行するソフトウェア)を選択する必要がある.
- コマンドパレット(コマンド名で機能を呼び出す VS Code の入力欄)を開く(
Ctrl+Shift+P) Python: Select Interpreterと入力する
- 表示される一覧から,使用する Python(例:
C:\Program Files\Python312\python.exe)を選択する.
Python 用 numpy,pandas,seaborn,matplotlib のインストール
- 管理者権限のコマンドプロンプトで以下を実行する.
管理者権限でコマンドプロンプトを起動する (手順:Windowsキーまたはスタートメニュー →
cmdと入力 → 右クリック → 「管理者として実行」)。python -m pip install -U --no-user numpy pandas seaborn matplotlib - Ubuntu の場合
端末で,次のコマンドを実行する.
# パッケージリストの情報を更新 sudo apt update sudo apt -y install python3-numpy python3-pandas python3-seaborn python3-matplotlib
第4章 kmnist のダウンロード
Windows での手順を示す.Ubuntu でも同様の手順である.
- 以下の手順を管理者権限のコマンドプロンプトで実行する.
管理者権限でコマンドプロンプトを起動する (手順:Windowsキーまたはスタートメニュー →
cmdと入力 → 右クリック → 「管理者として実行」)。 - ダウンロード用ディレクトリの準備
cd /d c:\ rmdir /s /q kmnist
- Kuzushiji-49 のダウンロード
download_data.pyを実行すると,Kuzushiji-MNIST, Kuzushiji-49, Kuzushiji-Kanji の 3 種類から,どれをダウンロードするかを選べる.下の実行例では,Kuzushiji-49 を選んでダウンロードしている.
cd C:\ git clone https://github.com/rois-codh/kmnist cd kmnist python download_data.py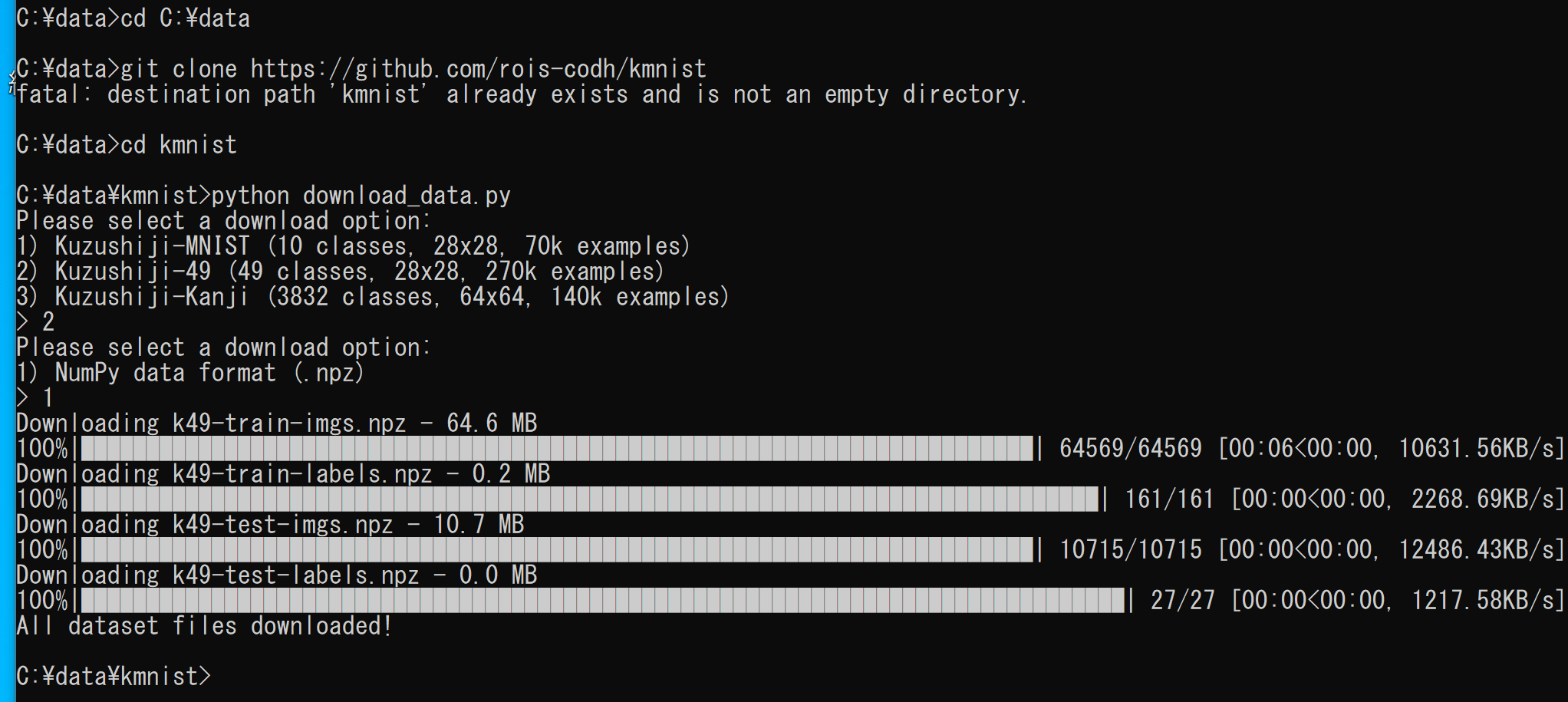
- Kuzushiji-MNIST のダウンロード
download_data.pyを実行すると,Kuzushiji-MNIST, Kuzushiji-49, Kuzushiji-Kanji の 3 種類から,どれをダウンロードするかを選べる.下の実行例では,Kuzushiji-MNIST を選んでダウンロードしている.
cd C:\kmnist python download_data.py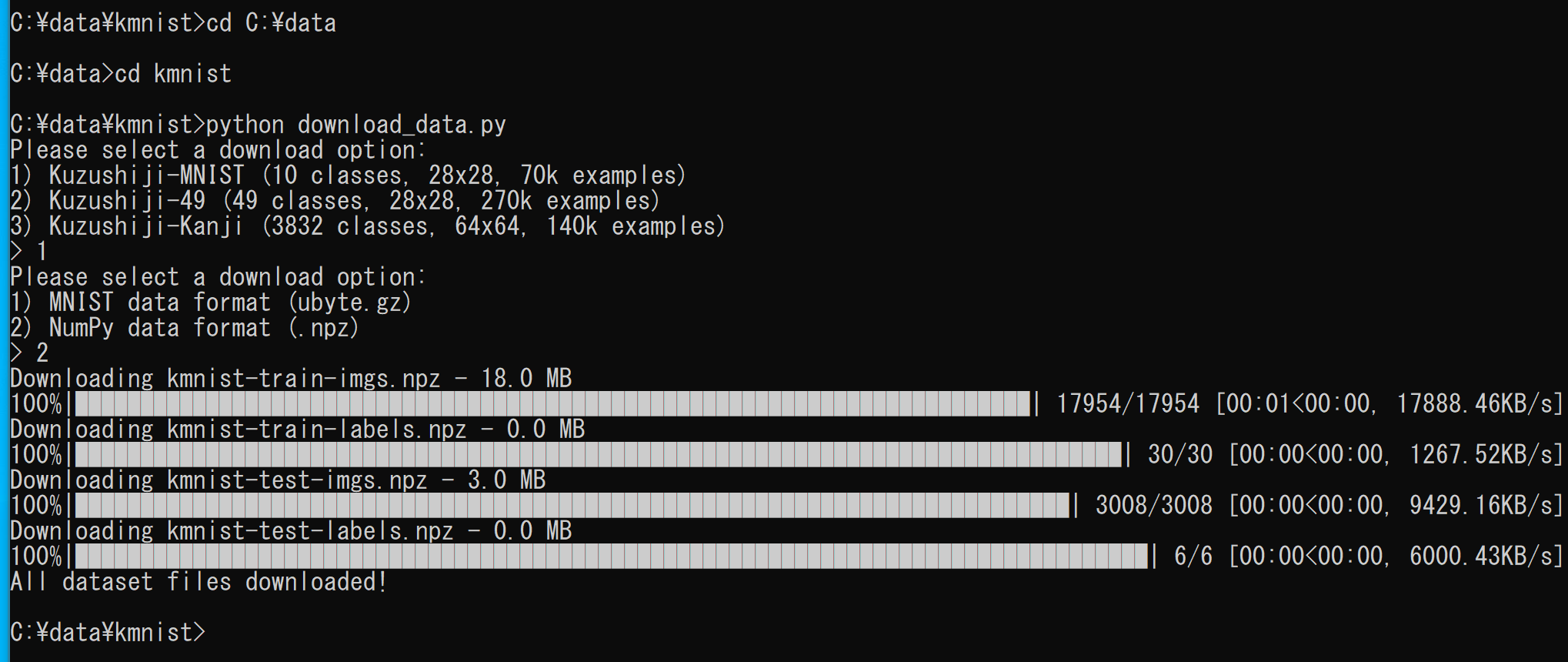
第5章 データセットの読み込みと確認表示
Kuzushiji-49 の読み込み
- 読み込み
import numpy as np x_train = np.load("C:/data/kmnist/k49-train-imgs.npz")['arr_0'] y_train = np.load("C:/data/kmnist/k49-train-labels.npz")['arr_0'] x_test = np.load("C:/data/kmnist/k49-test-imgs.npz")['arr_0'] y_test = np.load("C:/data/kmnist/k49-test-labels.npz")['arr_0'] print(type(x_train), x_train.shape, np.max(x_train), np.min(x_train)) print(type(x_test), x_test.shape, np.max(x_test), np.min(x_test)) print(type(y_train), y_train.shape, np.max(y_train), np.min(y_train)) print(type(y_test), y_test.shape, np.max(y_test), np.min(y_test))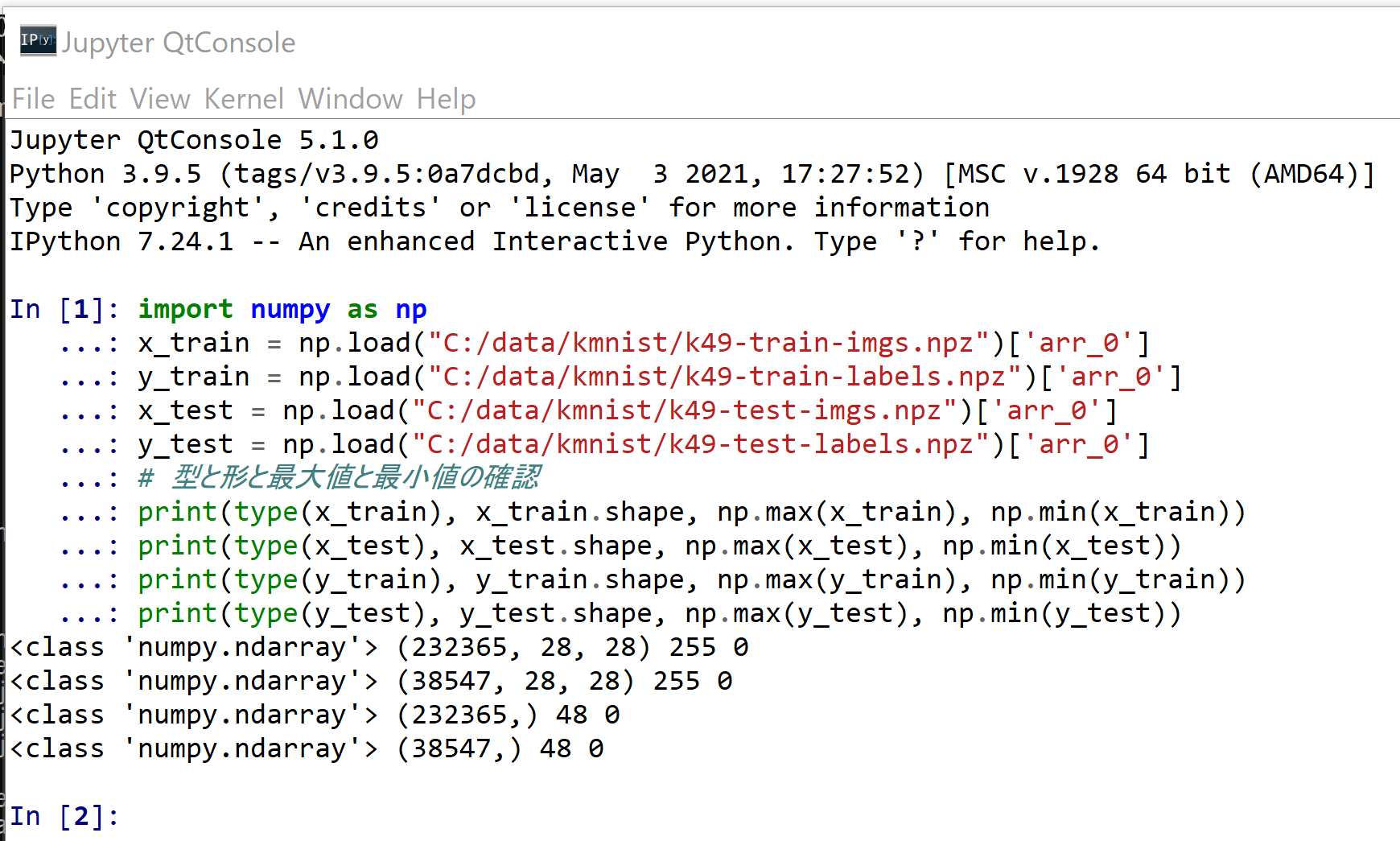
- 確認表示
%matplotlib inline import matplotlib.pyplot as plt import warnings warnings.filterwarnings('ignore') # Suppress Matplotlib warnings plt.imshow(x_train[0], cmap='gray') plt.imshow(x_test[0], cmap='gray')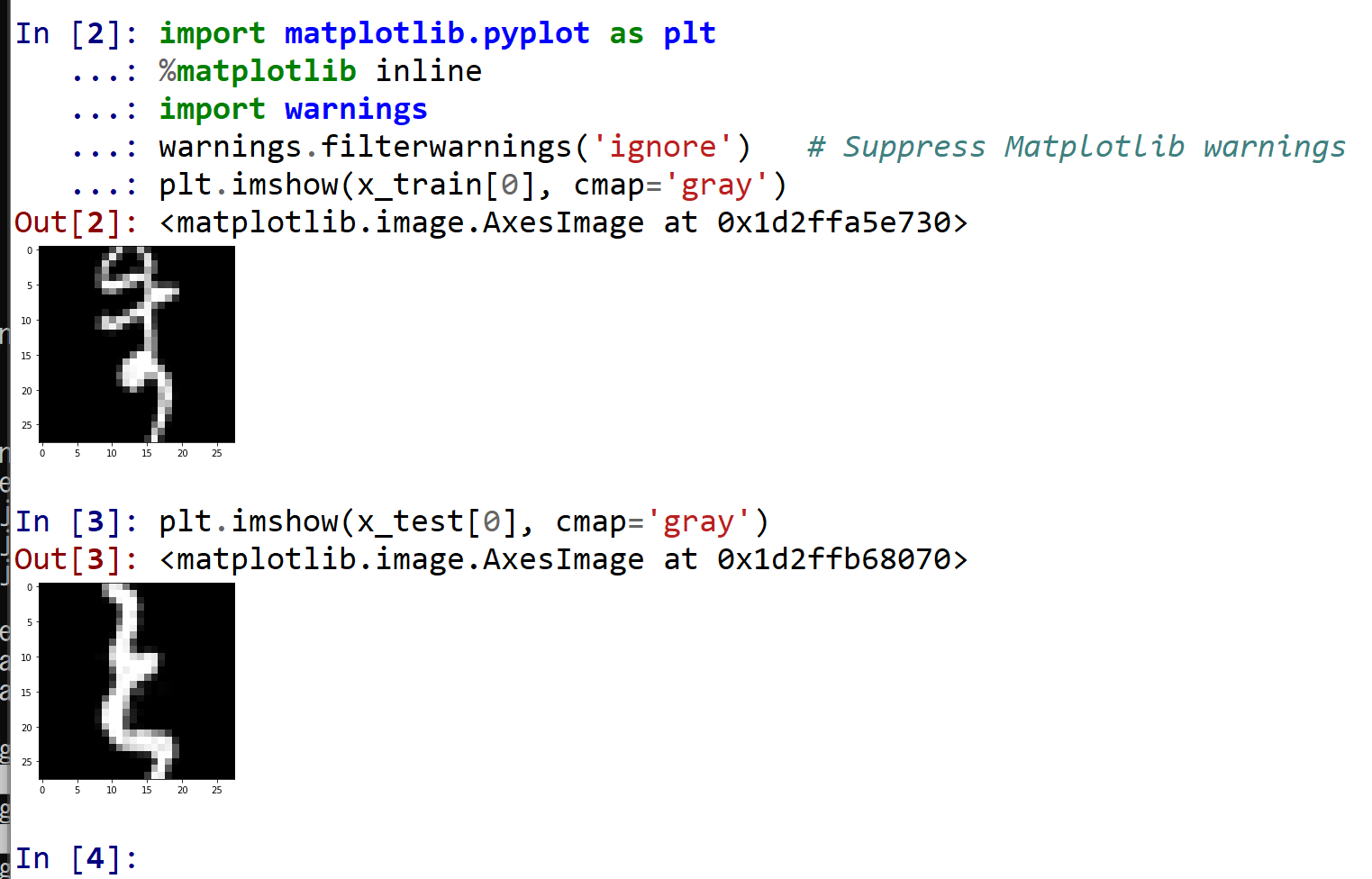
Kuzushiji-MNIST の読み込み
- 読み込み
import numpy as np x_train = np.load("C:/data/kmnist/kmnist-train-imgs.npz")['arr_0'] y_train = np.load("C:/data/kmnist/kmnist-train-labels.npz")['arr_0'] x_test = np.load("C:/data/kmnist/kmnist-test-imgs.npz")['arr_0'] y_test = np.load("C:/data/kmnist/kmnist-test-labels.npz")['arr_0'] print(type(x_train), x_train.shape, np.max(x_train), np.min(x_train)) print(type(x_test), x_test.shape, np.max(x_test), np.min(x_test)) print(type(y_train), y_train.shape, np.max(y_train), np.min(y_train)) print(type(y_test), y_test.shape, np.max(y_test), np.min(y_test))
- 確認表示
%matplotlib inline import matplotlib.pyplot as plt import warnings warnings.filterwarnings('ignore') # Suppress Matplotlib warnings plt.imshow(x_train[0], cmap='gray') plt.imshow(x_test[0], cmap='gray')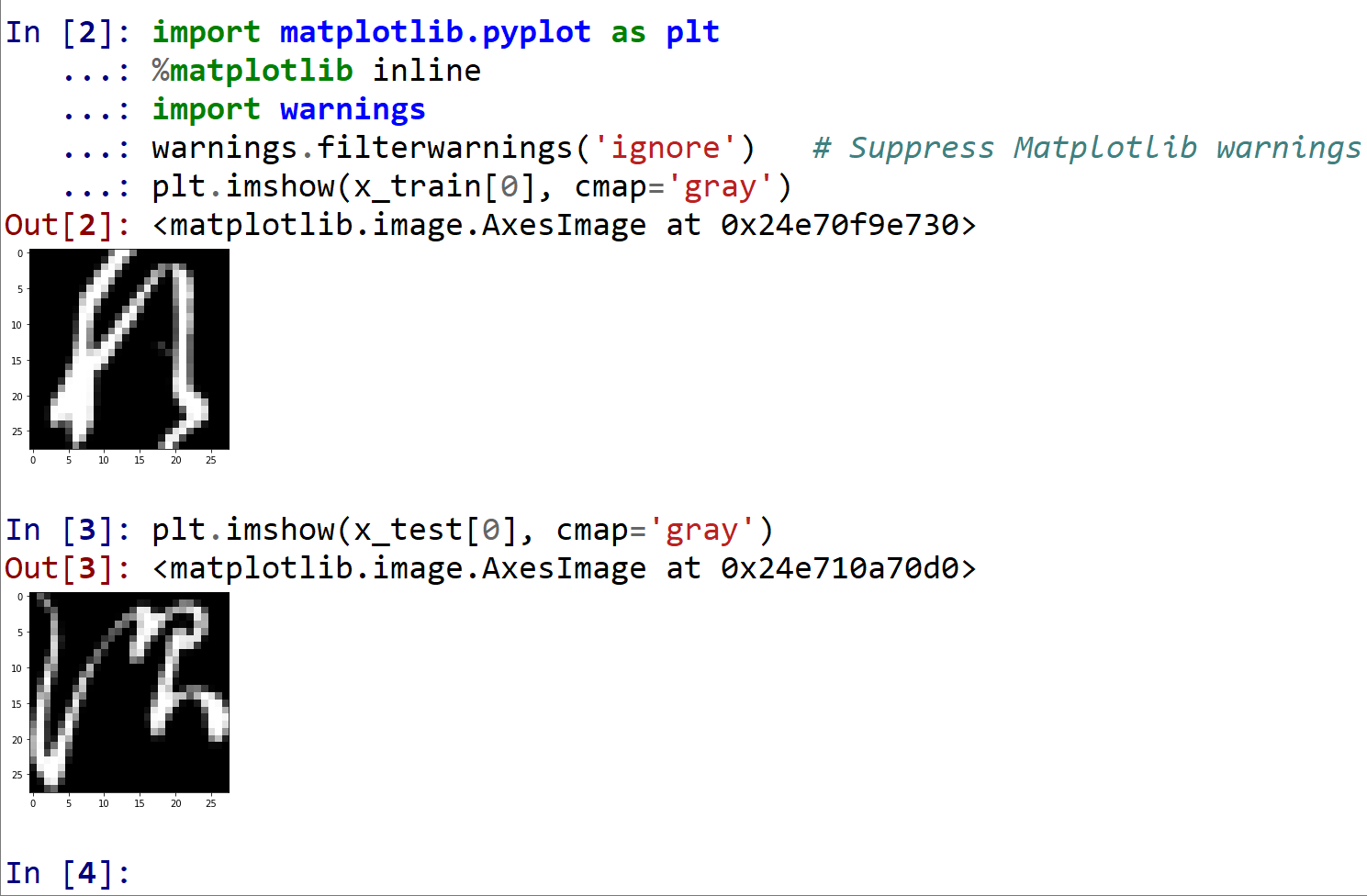
第6章 ディープラーニングの実行
Kuzushiji-MNIST(10 クラス)を用いる.直前の「Kuzushiji-MNIST の読み込み」で読み込んだ x_train,y_train,x_test,y_test を使う.
- パッケージのインポート,TensorFlow のバージョン確認など
import tensorflow as tf from tensorflow.keras import backend as K K.clear_session() import numpy as np %matplotlib inline import matplotlib.pyplot as plt import warnings warnings.filterwarnings('ignore') # Suppress Matplotlib warnings
- x_train, x_test, y_train, y_test の numpy ndarray への変換と,値の範囲の調整(値の範囲が 0 〜 255 であるのを,0 〜 1 に調整)
x_train = x_train.astype("float32") / 255.0 x_test = x_test.astype("float32") / 255.0 print(type(x_train), x_train.shape, np.max(x_train), np.min(x_train)) print(type(x_test), x_test.shape, np.max(x_test), np.min(x_test)) print(type(y_train), y_train.shape, np.max(y_train), np.min(y_train)) print(type(y_test), y_test.shape, np.max(y_test), np.min(y_test))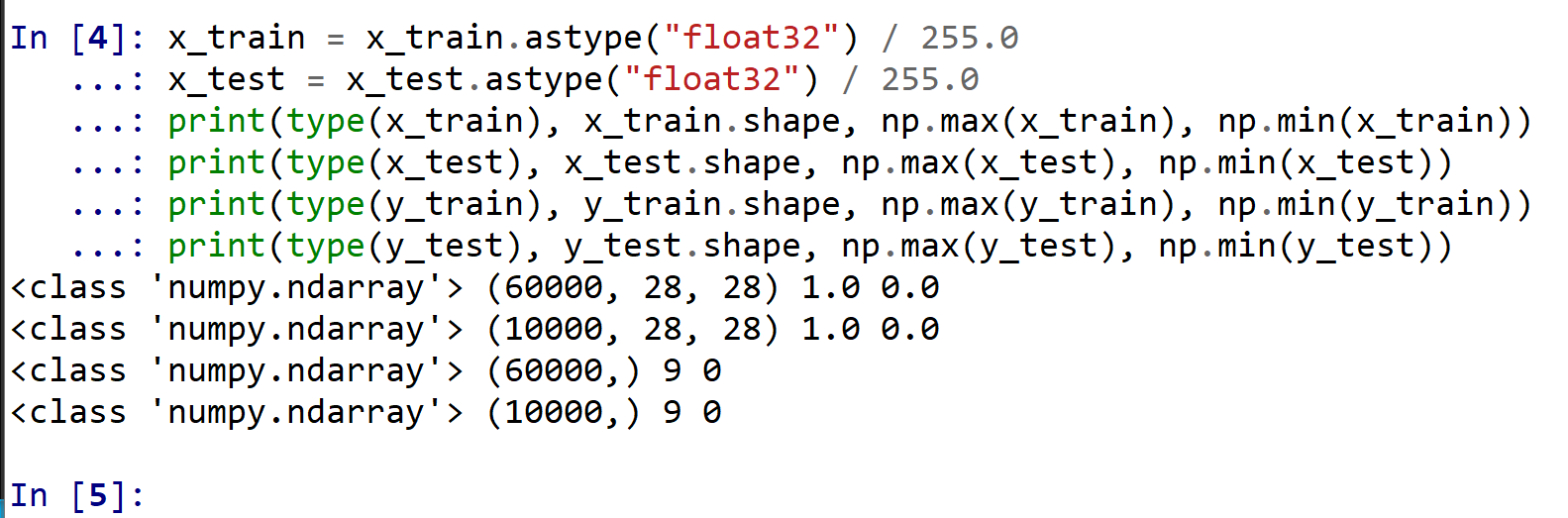
- データの確認表示
class_names = ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9'] plt.style.use('default') plt.figure(figsize=(10,10)) for i in range(25): plt.subplot(5,5,i+1) plt.xticks([]) plt.yticks([]) plt.grid(False) plt.imshow(x_train[i], cmap=plt.cm.binary) plt.xlabel(class_names[y_train[i]]) plt.show()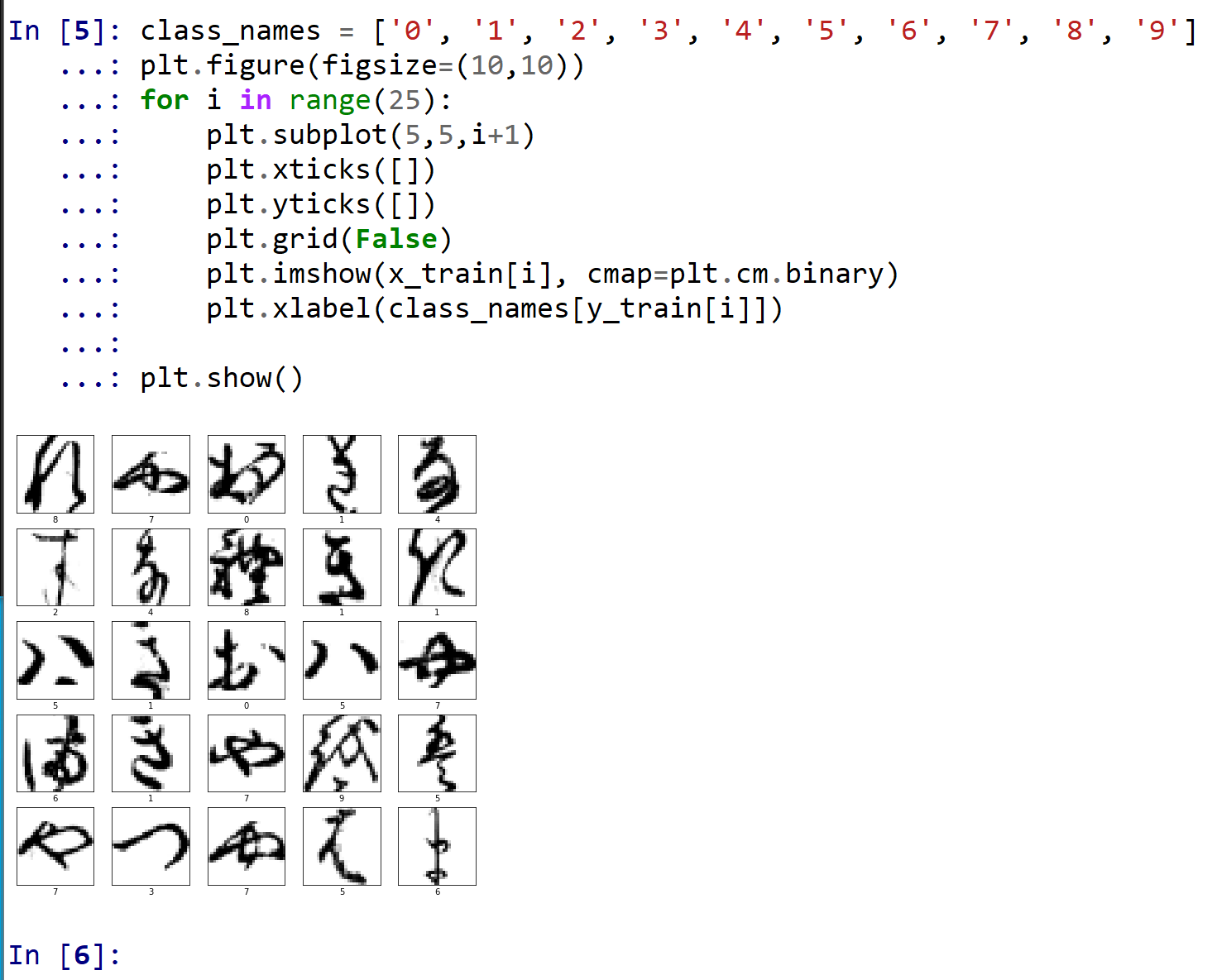
- ニューラルネットワークの作成と確認とコンパイル
最適化器(オプティマイザ)と損失関数とメトリクスを設定する.
2 層のニューラルネットワークを作成する.
1 層目:ユニット数は 128
2 層目:ユニット数は 10
ADAM を使う場合のプログラム例
NUM_CLASSES = 10 m = tf.keras.Sequential() m.add(tf.keras.layers.Flatten(input_shape=(28, 28))) m.add(tf.keras.layers.Dense(units=128, activation='relu')) m.add(tf.keras.layers.Dropout(rate=0.5)) m.add(tf.keras.layers.Dense(units=NUM_CLASSES, activation='softmax')) m.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.001), loss='sparse_categorical_crossentropy', metrics=['accuracy'])
SGD を使う場合のプログラム例
NUM_CLASSES = 10 m = tf.keras.Sequential() m.add(tf.keras.layers.Flatten(input_shape=(28, 28))) m.add(tf.keras.layers.Dense(units=128, activation='relu')) m.add(tf.keras.layers.BatchNormalization()) m.add(tf.keras.layers.Dropout(rate=0.5)) m.add(tf.keras.layers.Dense(units=NUM_CLASSES, activation='softmax')) m.compile(optimizer=tf.keras.optimizers.SGD(learning_rate=0.01, momentum=0.9, nesterov=True), loss='sparse_categorical_crossentropy', metrics=['accuracy']) - ニューラルネットワークの確認表示
print(m.summary())
- ニューラルネットワークの学習を行う
EPOCHS = 50 history = m.fit(x_train, y_train, validation_data=(x_test, y_test), verbose=2, epochs=EPOCHS)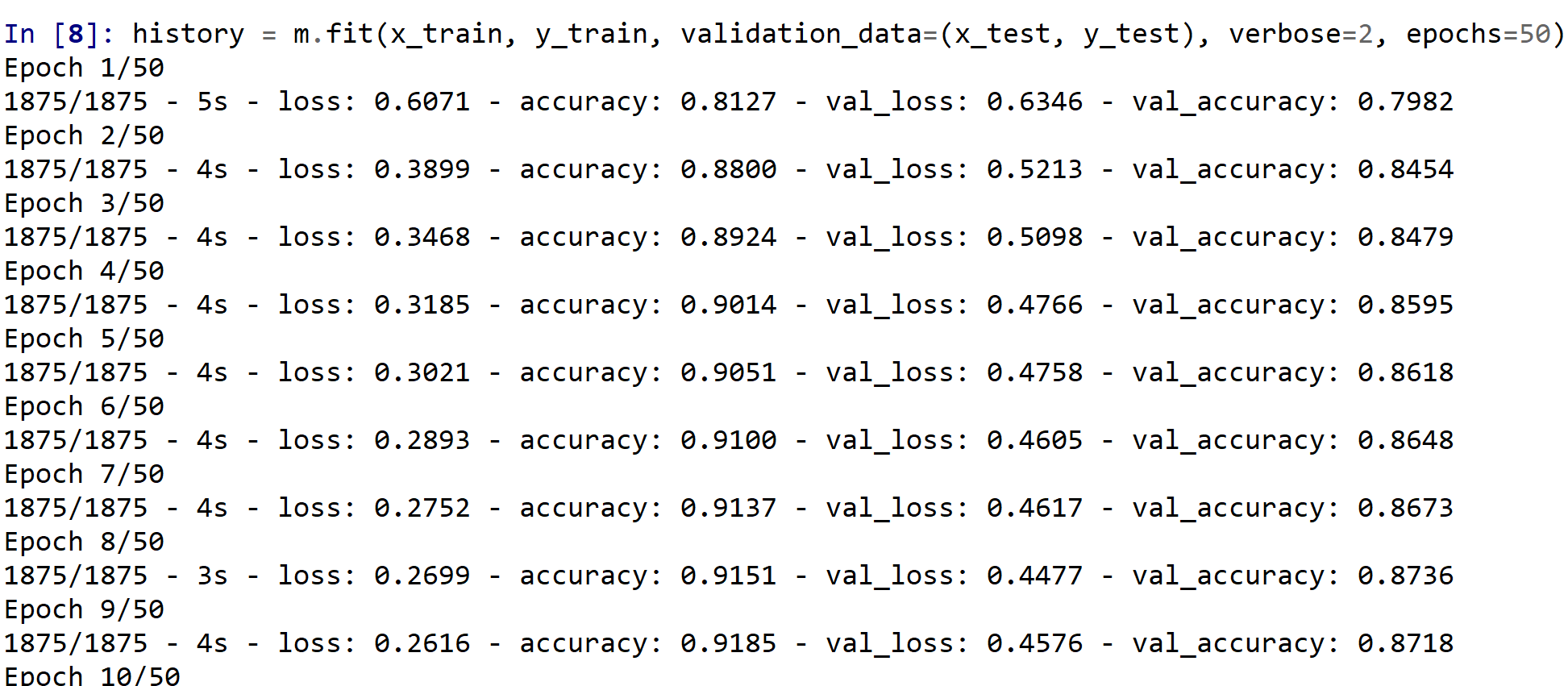
- ニューラルネットワークを使い,分類を行う.
* 訓練(学習)などで乱数が使われるので,下図と違う値になる.
predictions = m.predict(x_test) print(predictions[0])
- 正解表示
テスト画像 0 番の正解を表示する.
print(y_test[0])
- 訓練の履歴の可視化
【関連する外部ページ】 訓練の履歴の可視化については,https://keras.io/api/utils/model_plotting_utils/
- 学習時と検証時の,損失の違い
acc = history.history['accuracy'] val_acc = history.history['val_accuracy'] loss = history.history['loss'] val_loss = history.history['val_loss'] epochs = range(1, len(acc) + 1) # "bo" は青いドット plt.plot(epochs, loss, 'bo', label='Training loss') # "b" は青い実線 plt.plot(epochs, val_loss, 'b', label='Validation loss') plt.title('Training and validation loss') plt.xlabel('Epochs') plt.ylabel('Loss') plt.legend() plt.show()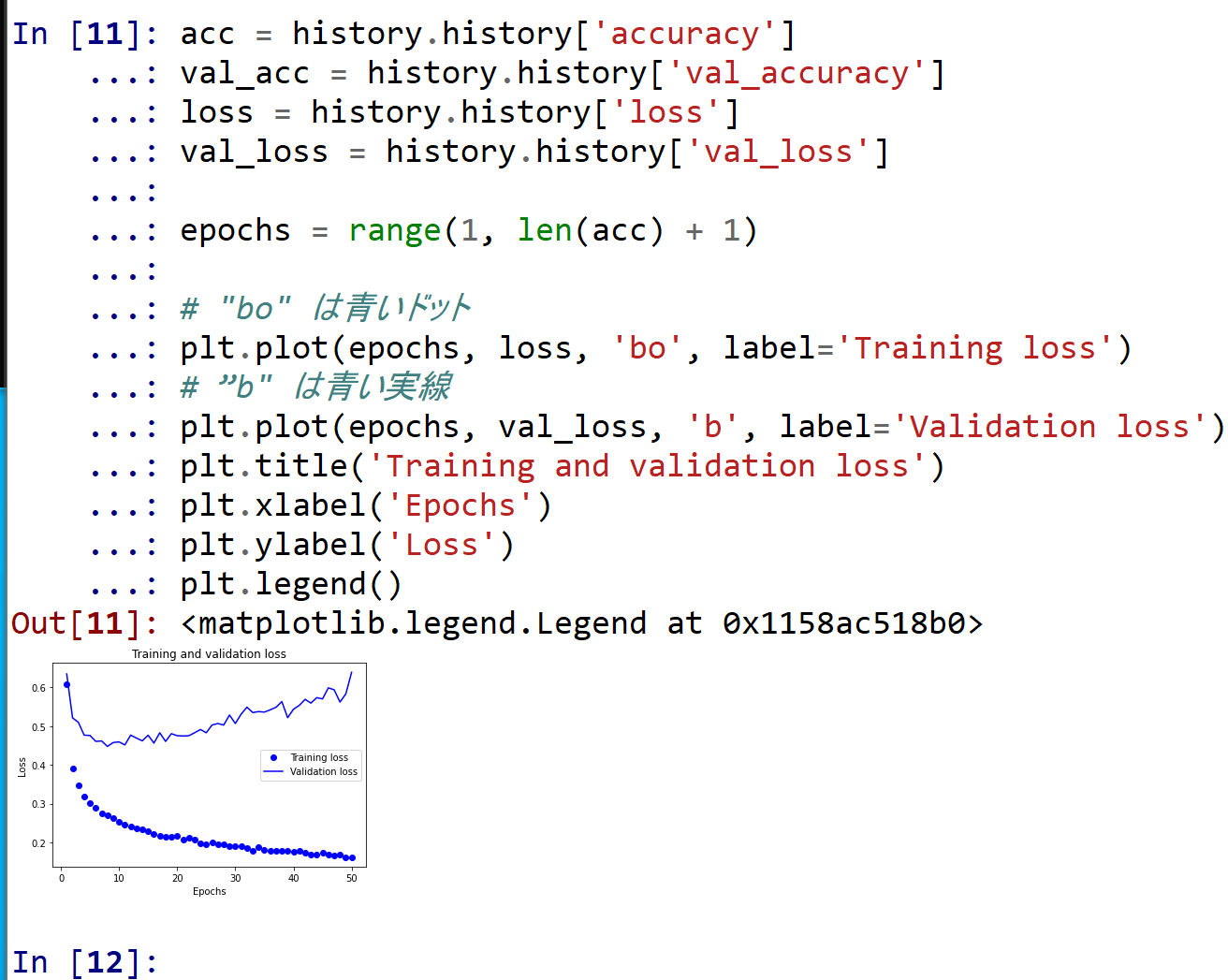
- 学習時と検証時の,精度の違い
acc = history.history['accuracy'] val_acc = history.history['val_accuracy'] loss = history.history['loss'] val_loss = history.history['val_loss'] epochs = range(1, len(acc) + 1) plt.clf() # 図のクリア plt.plot(epochs, acc, 'bo', label='Training acc') plt.plot(epochs, val_acc, 'b', label='Validation acc') plt.title('Training and validation accuracy') plt.xlabel('Epochs') plt.ylabel('Accuracy') plt.legend() plt.show()
- 学習時と検証時の,損失の違い