動作認識,動作認識を行う Python プログラム(MMAction,Python,PyTorch を使用)(Windows 上)
前準備
Build Tools for Visual Studio 2022 のインストール(Windows 上)
Build Tools for Visual Studio は,Visual Studio の IDE を含まない C/C++ コンパイラ,ライブラリ,ビルドツール等のコマンドライン向け開発ツールセットである。
以下のコマンドを管理者権限のコマンドプロンプトで実行する
(手順:Windowsキーまたはスタートメニュー → cmd と入力 → 右クリック → 「管理者として実行」)。
REM VC++ ランタイム
winget install --scope machine --id Microsoft.VCRedist.2015+.x64 -e --silent --disable-interactivity --force --accept-source-agreements --accept-package-agreements --override "/quiet /norestart"
REM Build Tools + Desktop development with C++(VCTools)+ 追加コンポーネント(一括)
winget install --id Microsoft.VisualStudio.2022.BuildTools --accept-source-agreements --accept-package-agreements ^
--override "--passive --wait --norestart --add Microsoft.VisualStudio.Workload.VCTools --includeRecommended --add Microsoft.VisualStudio.Component.VC.Llvm.Clang --add Microsoft.VisualStudio.ComponentGroup.ClangCL --add Microsoft.VisualStudio.Component.VC.CMake.Project --add Microsoft.VisualStudio.Component.Windows11SDK.26100"--add で追加されるコンポーネント
上記のコマンドでは,まず Build Tools 本体と Visual C++ 再頒布可能パッケージをインストールし,次に setup.exe を用いて以下のコンポーネントを追加している。
VCTools:C++ デスクトップ開発ワークロード(--includeRecommendedにより、MSVC コンパイラ、C++ AddressSanitizer、vcpkg、CMake ツール、Windows 11 SDK 等の推奨コンポーネントが含まれる)VC.Llvm.Clang:Windows 向け C++ Clang コンパイラClangCL:clang-cl ツールセットを含むコンポーネントグループ(MSBuild から Clang を使用するために必要)VC.CMake.Project:Windows 向け C++ CMake ツールWindows11SDK.26100:Windows 11 SDK(ビルド 10.0.26100)
インストール完了の確認
winget list Microsoft.VisualStudio.2022.BuildTools上記以外の追加のコンポーネントが必要になった場合は Visual Studio Installer で個別にインストールできる。
Visual Studio の機能を必要とする場合は、追加インストールできる。
Python 3.12 のインストール(Windows 上) [クリックして展開]
以下のいずれかの方法で Python 3.12 をインストールする。Python がインストール済みの場合、この手順は不要である。
方法1:winget によるインストール
管理者権限のコマンドプロンプトで以下を実行する。管理者権限のコマンドプロンプトを起動するには、Windows キーまたはスタートメニューから「cmd」と入力し、表示された「コマンドプロンプト」を右クリックして「管理者として実行」を選択する。
winget install --id Python.Python.3.12 -e --scope machine --silent --accept-source-agreements --accept-package-agreements --override "/quiet InstallAllUsers=1 PrependPath=1 Include_test=0 Include_pip=1 Include_launcher=1 InstallLauncherAllUsers=1 TargetDir=\"C:\Program Files\Python312\""
powershell -Command "$p='C:\Program Files\Python312'; $s=\"$p\Scripts\"; $m=[Environment]::GetEnvironmentVariable('Path','Machine'); if($m -notlike \"*$s*\") { [Environment]::SetEnvironmentVariable('Path', \"$p;$s;$m\", 'Machine') }"--scope machine を指定することで、システム全体(全ユーザー向け)にインストールされる。このオプションの実行には管理者権限が必要である。インストール完了後、コマンドプロンプトを再起動すると PATH が自動的に設定される。
方法2:インストーラーによるインストール
- Python 公式サイト(https://www.python.org/downloads/)にアクセスし、「Download Python 3.x.x」ボタンから Windows 用インストーラーをダウンロードする。
- ダウンロードしたインストーラーを実行する。
- 初期画面の下部に表示される「Add python.exe to PATH」に必ずチェックを入れてから「Customize installation」を選択する。このチェックを入れ忘れると、コマンドプロンプトから
pythonコマンドを実行できない。 - 「Install Python 3.xx for all users」にチェックを入れ、「Install」をクリックする。
インストールの確認
コマンドプロンプトで以下を実行する。
python --versionバージョン番号(例:Python 3.12.x)が表示されればインストール成功である。「'python' は、内部コマンドまたは外部コマンドとして認識されていません。」と表示される場合は、インストールが正常に完了していない。
Git のインストール
管理者権限のコマンドプロンプトで以下を実行する。管理者権限のコマンドプロンプトを起動するには、Windows キーまたはスタートメニューから「cmd」と入力し、表示された「コマンドプロンプト」を右クリックして「管理者として実行」を選択する。
REM Git をシステム領域にインストール
winget install --scope machine --id Git.Git -e --silent --disable-interactivity --force --accept-source-agreements --accept-package-agreements --override "/VERYSILENT /NORESTART /NOCANCEL /SP- /CLOSEAPPLICATIONS /RESTARTAPPLICATIONS /COMPONENTS=""icons,ext\reg\shellhere,assoc,assoc_sh"" /o:PathOption=Cmd /o:CRLFOption=CRLFCommitAsIs /o:BashTerminalOption=MinTTY /o:DefaultBranchOption=main /o:EditorOption=VIM /o:SSHOption=OpenSSH /o:UseCredentialManager=Enabled /o:PerformanceTweaksFSCache=Enabled /o:EnableSymlinks=Disabled /o:EnableFSMonitor=Disabled"
【関連する外部ページ】
- Git の公式ページ: https://git-scm.com/
Build Tools for Visual Studio 2022,NVIDIA ドライバ,NVIDIA CUDA ツールキット 11.8,NVIDIA cuDNN 8.9.7 のインストール(Windows 上)
【サイト内の関連ページ】 NVIDIA グラフィックスボードを搭載しているパソコンの場合には, NVIDIA ドライバ, NVIDIA CUDA ツールキット, NVIDIA cuDNN のインストールを行う.
- Windows での Build Tools for Visual Studio 2022 のインストール: 別ページ »で説明
- Windows での NVIDIA ドライバ,NVIDIA CUDA ツールキット 11.8,NVIDIA cuDNN v8.9.7 のインストール手順: 別ページ »で説明
【関連する外部ページ】
- Build Tools for Visual Studio 2022 (ビルドツール for Visual Studio 2022)の公式ダウンロードページ: https://visualstudio.microsoft.com/ja/visual-cpp-build-tools/
- NVIDIA ドライバのダウンロードの公式ページ: https://www.nvidia.co.jp/Download/index.aspx?lang=jp
- NVIDIA CUDA ツールキットのアーカイブの公式ページ: https://developer.nvidia.com/cuda-toolkit-archive
- NVIDIA cuDNN のダウンロードの公式ページ: https://developer.nvidia.com/cudnn
PyTorch のインストール(Windows 上)
- 以下の手順を管理者権限のコマンドプロンプトで実行する
(手順:Windowsキーまたはスタートメニュー →
cmdと入力 → 右クリック → 「管理者として実行」)。 - PyTorch のページを確認
- 次のようなコマンドを実行(実行するコマンドは,PyTorch のページの表示されるコマンドを使う).
次のコマンドを実行することにより, PyTorch 2.3 (NVIDIA CUDA 11.8 用)がインストールされる. 但し,Anaconda3を使いたい場合には別手順になる.
事前に NVIDIA CUDA のバージョンを確認しておくこと(ここでは,NVIDIA CUDA ツールキット 11.8 が前もってインストール済みであるとする).
PyTorch で,GPU が動作している場合には,「torch.cuda.is_available()」により,True が表示される.
python -m pip install -U --ignore-installed pip python -m pip uninstall -y torch torchvision torchaudio torchtext xformers python -m pip install -U torch torchvision torchaudio numpy --index-url https://download.pytorch.org/whl/cu118 python -c "import torch; print(torch.__version__, torch.cuda.is_available())"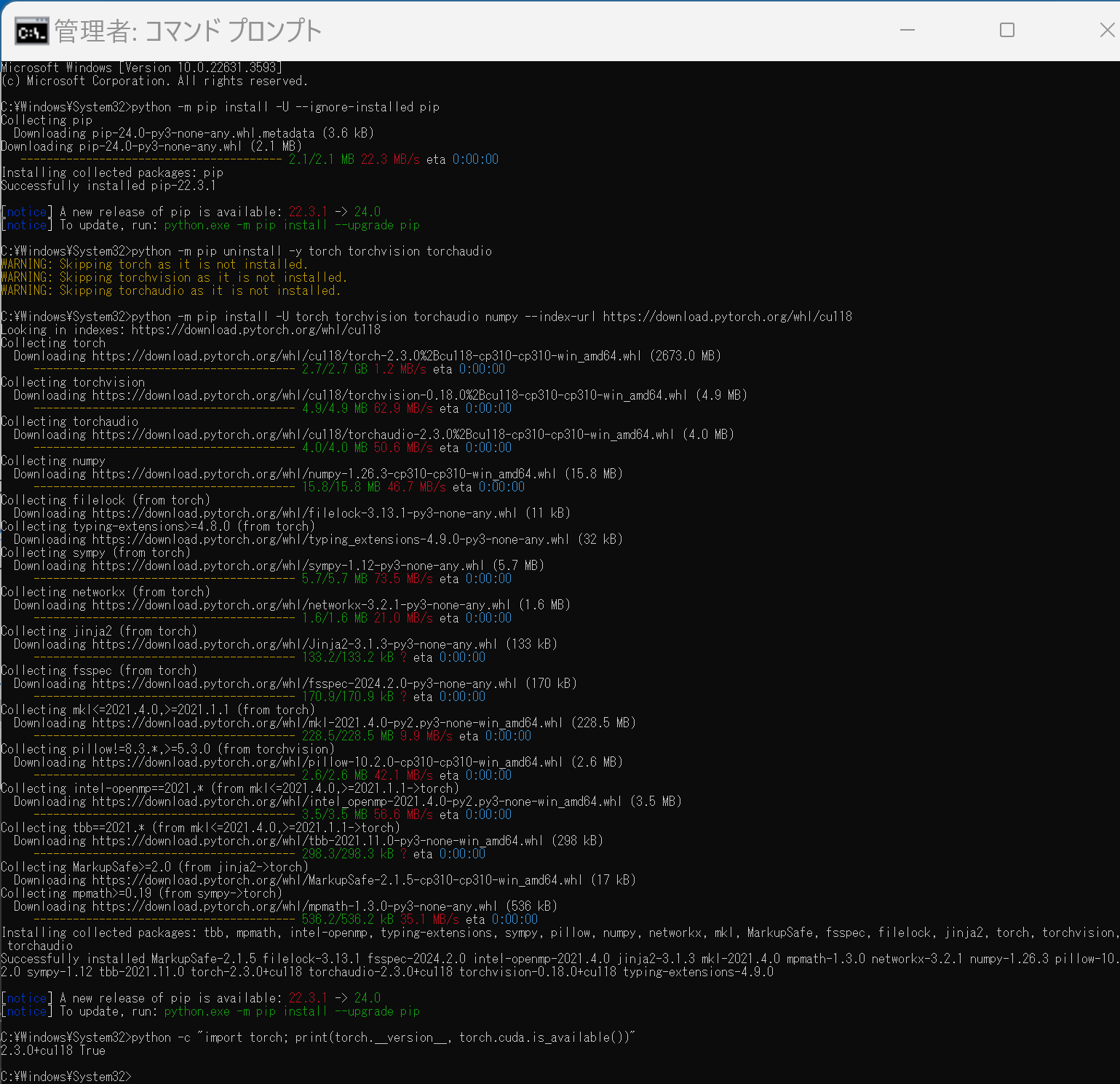 Anaconda3を使いたい場合には, Anaconda プロンプト (Anaconda Prompt) を管理者として実行し, 次のコマンドを実行する. (PyTorch と NVIDIA CUDA との連携がうまくいかない可能性があるため,Anaconda3を使わないことも検討して欲しい).
Anaconda3を使いたい場合には, Anaconda プロンプト (Anaconda Prompt) を管理者として実行し, 次のコマンドを実行する. (PyTorch と NVIDIA CUDA との連携がうまくいかない可能性があるため,Anaconda3を使わないことも検討して欲しい).conda install -y pytorch torchvision torchaudio pytorch-cuda=11.8 cudnn -c pytorch -c nvidia py -c "import torch; print(torch.__version__, torch.cuda.is_available())"【サイト内の関連ページ】
【関連する外部ページ】
MMAction のインストール(Windows 上)
- 以下の手順を管理者権限のコマンドプロンプトで実行する
(手順:Windowsキーまたはスタートメニュー →
cmdと入力 → 右クリック → 「管理者として実行」)。 - ダウンロードとインストール
python -m pip install -U openmim mim install mmengine mim install mmcv mim install mmdet mim install mmpose cd /d c:%HOMEPATH% rmdir /s /q mmaction2 git clone https://github.com/open-mmlab/mmaction2.git cd mmaction2 pip install -v -e . mim download mmaction2 --config tsn_imagenet-pretrained-r50_8xb32-1x1x8-100e_kinetics400-rgb --dest . - 終了の確認
エラーメッセージが出ていないこと.

MMAction の動作確認(Windows 上)
- Windows で,コマンドプロンプトを実行
- エディタを起動
cd /d c:%HOMEPATH%\mmaction2 notepad actreg.py
- エディタで,次のプログラムを保存
このプログラムは, 公式の GitHub のページで公開されていたものを変更して使用している.
このプログラムは,動作認識のためにMMActionを使用する.事前学習済みモデルを読み込んで指定されたビデオファイルで実行し,動作認識結果の上位5位の動作ラベルとそれに対応するスコアを表示する.
- ラベルファイルの読み込み:load_labels関数は,指定されたラベルファイルを読み込み,各行の末尾の空白を取り除いたリストを返す.
- モデルの初期化:init_recognizer関数は,指定された設定ファイルとチェックポイントファイルを使用して,動作認識のモデルを初期化する.
- 動作認識の実行:get_top5_action_labels関数は,モデルとビデオファイルを引数として受け取り,モデルを使用してビデオから動作を認識する.その後,スコアに基づいて上位5位の動作ラベルを選択し,これらのラベルとスコアのリストを返す.
- エラーハンドリング:モデルの初期化とラベルの読み込みに失敗した場合,または動作認識中に例外が発生した場合にエラーメッセージを表示する.
- 結果の表示:動作認識結果の上位5位の動作ラベルとそれに対応するスコアを表示する.
from operator import itemgetter from mmaction.apis import init_recognizer, inference_recognizer def load_labels(label_file): with open(label_file, 'r') as file: labels = [line.strip() for line in file.readlines()] return labels def get_top5_action_labels(model, video_file, labels): try: pred_result = inference_recognizer(model, video_file) except Exception as e: print(f"Error during model inference: {e}") return [] pred_scores = pred_result.pred_score.tolist() score_tuples = tuple(zip(range(len(pred_scores)), pred_scores)) score_sorted = sorted(score_tuples, key=itemgetter(1), reverse=True) top5_label = score_sorted[:5] return [(labels[k[0]], k[1]) for k in top5_label] # モデルとラベルの読み込み config_file = 'tsn_imagenet-pretrained-r50_8xb32-1x1x8-100e_kinetics400-rgb.py' checkpoint_file = 'tsn_imagenet-pretrained-r50_8xb32-1x1x8-100e_kinetics400-rgb_20220906-2692d16c.pth' video_file = 'demo/demo_skeleton.mp4' label_file = 'tools/data/kinetics/label_map_k400.txt' try: model = init_recognizer(config_file, checkpoint_file, device='cpu') # or device='cuda:0' labels = load_labels(label_file) except Exception as e: print(f"Error initializing model or loading labels: {e}") else: results = get_top5_action_labels(model, video_file, labels) print('The top-5 labels with corresponding scores are:') for result in results: print(f'{result[0]}: {result[1]}')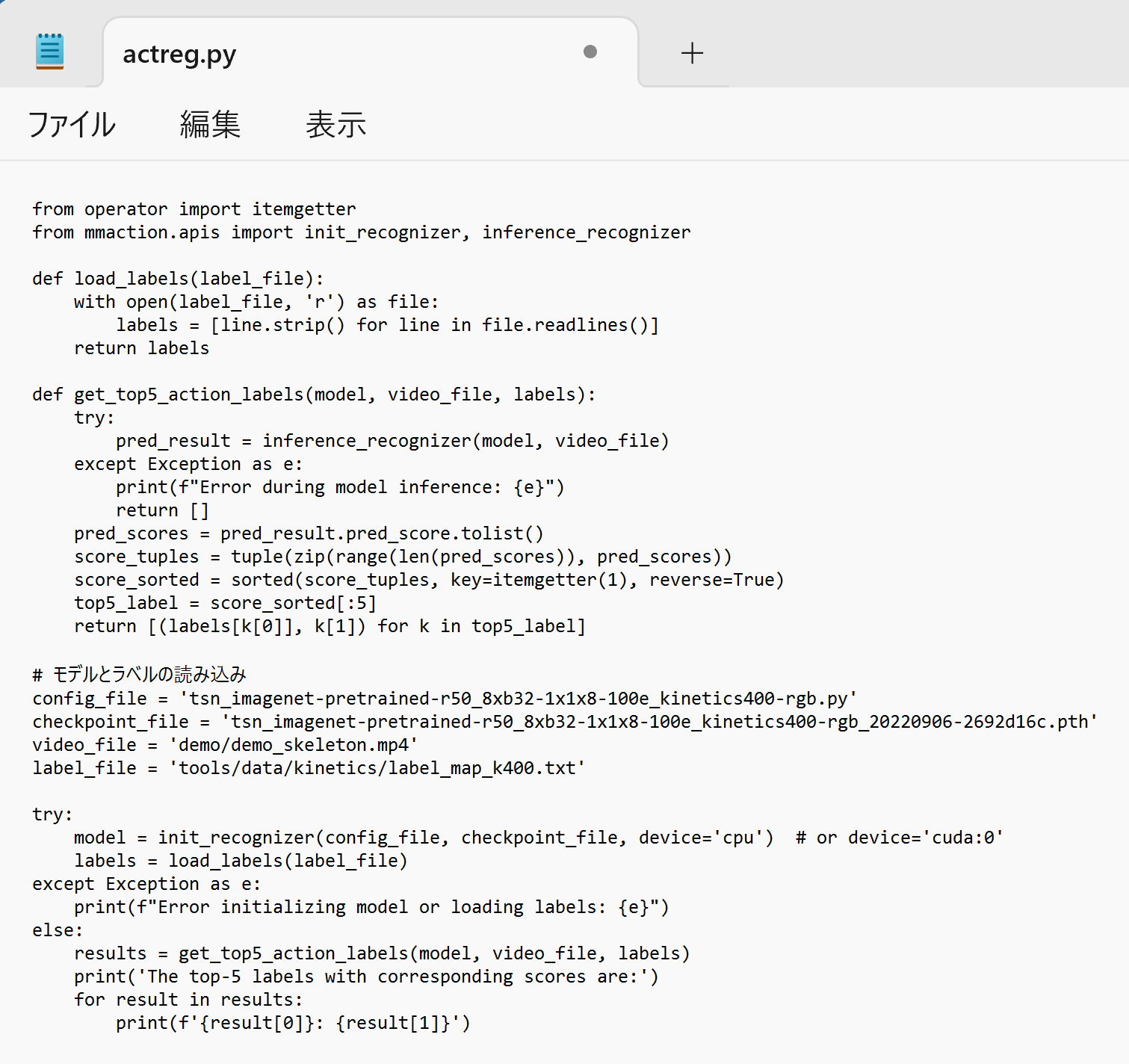
- Python プログラムの実行
Python プログラムの実行
- Windows では python (Python ランチャーは py)
- Ubuntu では python3
Python 開発環境(Jupyter Qt Console, Jupyter ノートブック (Jupyter Notebook), Jupyter Lab, Nteract, Spyder, PyCharm, PyScripterなど)も便利である.
Python のまとめ: 別ページ »にまとめ
プログラムを actreg.pyのようなファイル名で保存したので, 「python actreg.py」のようなコマンドで行う.
cd /d c:%HOMEPATH%\mmaction2 python actreg.py
- 結果の確認
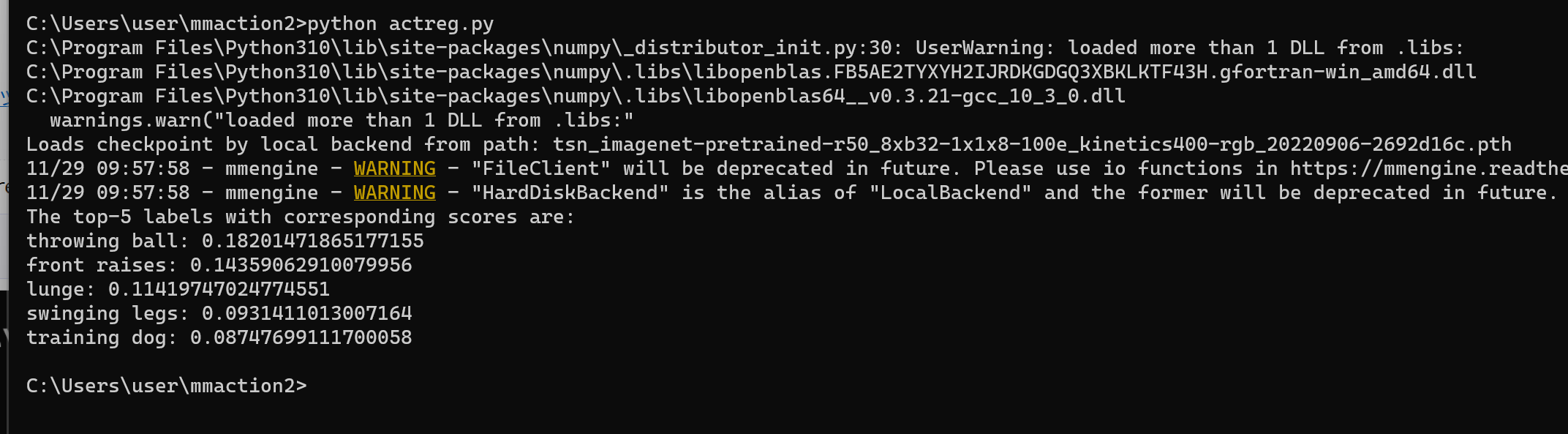
他の動画を試したいときは, cd /d c:%HOMEPATH%\mmaction2\demo に動画ファイルを置き, actreg.py の「video_file = 'demo/demo_skeleton.mp4'」のところを変更して実行する.
MMAction を使う Python プログラムの実行(Windows 上)
ビデオカメラの動作認識を行うプログラム
- Windows で,コマンドプロンプトを実行
- エディタを起動
cd /d c:%HOMEPATH%\mmaction2 notepad vidactreg.py - エディタで,次のプログラムを保存
ビデオカメラから読み込み,一定数(ここでは30)のフレームが集まるたびに,最新の120フレームを使用して動作認識を実行する.これを行うために,フレームを一時的に保存するバッファ(リスト)を使用する.このプログラムでは,ビデオからフレームを読み込み,frame_buffer(Pythonのdequeを使用)に保存する.このバッファは最大120フレームを保持し,古いフレームは自動的に削除される.30フレームごとにrecognize_action関数を呼び出し,その時点での最新の120フレームで動作認識を実行する.
import cv2 from mmaction.apis import init_recognizer, inference_recognizer from collections import deque from operator import itemgetter # モデルとラベルの初期化 def initialize_model(config_file, checkpoint_file): try: model = init_recognizer(config_file, checkpoint_file, device='cpu') # or 'cuda:0' return model except Exception as e: print(f"Error initializing model: {e}") return None # ラベルの読み込み def load_labels(label_file): with open(label_file, 'r') as file: labels = [line.strip() for line in file.readlines()] return labels # アクション認識と結果の表示 def recognize_action(model, frames, labels): try: pred_result = inference_recognizer(model, frames) pred_scores = pred_result.pred_score.tolist() score_tuples = tuple(zip(range(len(pred_scores)), pred_scores)) score_sorted = sorted(score_tuples, key=itemgetter(1), reverse=True) top5_label = score_sorted[:5] results = [(labels[k[0]], k[1]) for k in top5_label] for result in results: print(f'{result[0]}: {result[1]}') except Exception as e: print(f"Error during model inference: {e}") def process_video(config_file, checkpoint_file, label_file): model = initialize_model(config_file, checkpoint_file) labels = load_labels(label_file) if not model: return cap = cv2.VideoCapture(0) frame_buffer = deque(maxlen=120) # フレームサイズを取得(動画ファイルの初期化用) frame_width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)) frame_height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)) while True: ret, frame = cap.read() if not ret: break frame_buffer.append(frame) vidfile = 'a.mp4' if len(frame_buffer) % 30 == 0: # 30フレームごとに # ビデオファイルへの書き込みの初期化 out = cv2.VideoWriter(vidfile, cv2.VideoWriter_fourcc(*'mp4v'), 30, (frame_width, frame_height)) # バッファ内のフレームをビデオファイルに書き込み for f in frame_buffer: out.write(f) out.release() # ビデオライターを解放 recognize_action(model, vidfile, labels) cv2.imshow('Video Frame', frame) if cv2.waitKey(1) & 0xFF == ord('q'): break cap.release() cv2.destroyAllWindows() # モデルとラベルの読み込み config_file = 'tsn_imagenet-pretrained-r50_8xb32-1x1x8-100e_kinetics400-rgb.py' checkpoint_file = 'tsn_imagenet-pretrained-r50_8xb32-1x1x8-100e_kinetics400-rgb_20220906-2692d16c.pth' label_file = 'tools/data/kinetics/label_map_k400.txt' # ビデオ処理の実行 process_video(config_file, checkpoint_file, label_file) - Python プログラムの実行
Python プログラムの実行
- Windows では python (Python ランチャーは py)
- Ubuntu では python3
Python 開発環境(Jupyter Qt Console, Jupyter ノートブック (Jupyter Notebook), Jupyter Lab, Nteract, Spyder, PyCharm, PyScripterなど)も便利である.
Python のまとめ: 別ページ »にまとめ
プログラムを vidactreg.pyのようなファイル名で保存したので, 「python vidactreg.py」のようなコマンドで行う.
cd /d c:%HOMEPATH%\mmaction2 python vidactreg.py - 結果の確認
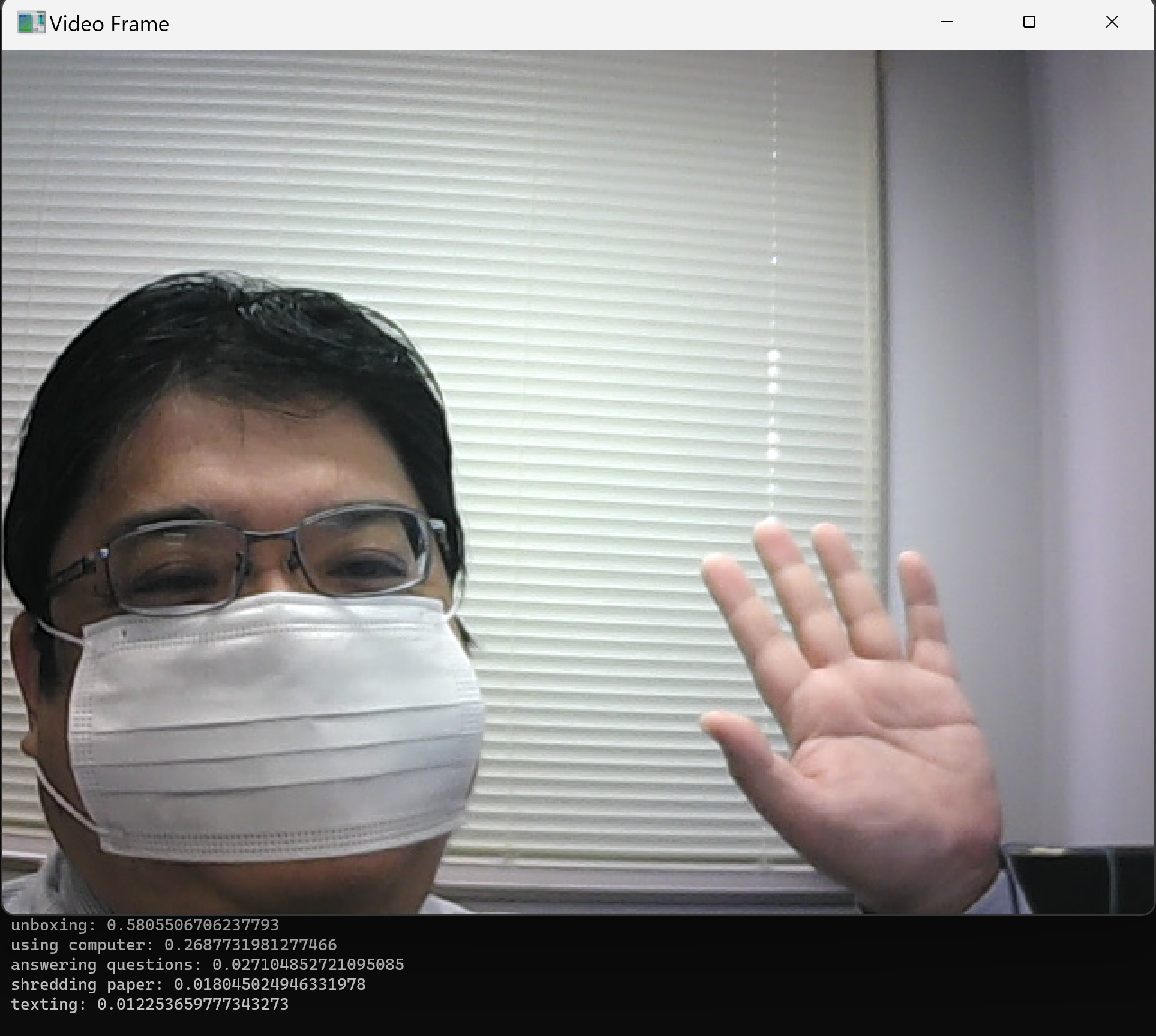
- 以下の手順を管理者権限のコマンドプロンプトで実行する
(手順:Windowsキーまたはスタートメニュー →