セマンティック・セグメンテーション(MMSegmentation のインストールと動作確認)(PyTorch,Python を使用)(Windows 上)
【目次】
MMSegmentation
MMSegmentation は, OpenMMLab の構成物で,セグメンテーションの機能を提供する.
【文献】
MMSegmentation Contributors, MMSegmentation: OpenMMLab Semantic Segmentation Toolbox and Benchmark, https://github.com/open-mmlab/mmsegmentation, 2020.
【関連する外部ページ】
- MMSegmentation の公式ドキュメント: https://mmsegmentation.readthedocs.io
- MMSegmentation の訓練,検証,推論の公式チュートリアル: https://github.com/open-mmlab/mmsegmentation/blob/master/demo/MMSegmentation_Tutorial.ipynb
- MMSegmentation の公式の学習済みモデル: https://mmsegmentation.readthedocs.io/en/latest/model_zoo.html
前準備
Build Tools for Visual Studio 2022 のインストール(Windows 上)
Build Tools for Visual Studio は,Visual Studio の IDE を含まない C/C++ コンパイラ,ライブラリ,ビルドツール等のコマンドライン向け開発ツールセットである。
以下のコマンドを管理者権限のコマンドプロンプトで実行する
(手順:Windowsキーまたはスタートメニュー → cmd と入力 → 右クリック → 「管理者として実行」)。
REM VC++ ランタイム
winget install --scope machine --id Microsoft.VCRedist.2015+.x64 -e --silent --disable-interactivity --force --accept-source-agreements --accept-package-agreements --override "/quiet /norestart"
REM Build Tools + Desktop development with C++(VCTools)+ 追加コンポーネント(一括)
winget install --id Microsoft.VisualStudio.2022.BuildTools --accept-source-agreements --accept-package-agreements ^
--override "--passive --wait --norestart --add Microsoft.VisualStudio.Workload.VCTools --includeRecommended --add Microsoft.VisualStudio.Component.VC.Llvm.Clang --add Microsoft.VisualStudio.ComponentGroup.ClangCL --add Microsoft.VisualStudio.Component.VC.CMake.Project --add Microsoft.VisualStudio.Component.Windows11SDK.26100"--add で追加されるコンポーネント
上記のコマンドでは,まず Build Tools 本体と Visual C++ 再頒布可能パッケージをインストールし,次に setup.exe を用いて以下のコンポーネントを追加している。
VCTools:C++ デスクトップ開発ワークロード(--includeRecommendedにより、MSVC コンパイラ、C++ AddressSanitizer、vcpkg、CMake ツール、Windows 11 SDK 等の推奨コンポーネントが含まれる)VC.Llvm.Clang:Windows 向け C++ Clang コンパイラClangCL:clang-cl ツールセットを含むコンポーネントグループ(MSBuild から Clang を使用するために必要)VC.CMake.Project:Windows 向け C++ CMake ツールWindows11SDK.26100:Windows 11 SDK(ビルド 10.0.26100)
インストール完了の確認
winget list Microsoft.VisualStudio.2022.BuildTools上記以外の追加のコンポーネントが必要になった場合は Visual Studio Installer で個別にインストールできる。
Visual Studio の機能を必要とする場合は、追加インストールできる。
Python 3.12 のインストール(Windows 上) [クリックして展開]
以下のいずれかの方法で Python 3.12 をインストールする。Python がインストール済みの場合、この手順は不要である。
方法1:winget によるインストール
管理者権限のコマンドプロンプトで以下を実行する。管理者権限のコマンドプロンプトを起動するには、Windows キーまたはスタートメニューから「cmd」と入力し、表示された「コマンドプロンプト」を右クリックして「管理者として実行」を選択する。
winget install --id Python.Python.3.12 -e --scope machine --silent --accept-source-agreements --accept-package-agreements --override "/quiet InstallAllUsers=1 PrependPath=1 Include_test=0 Include_pip=1 Include_launcher=1 InstallLauncherAllUsers=1 TargetDir=\"C:\Program Files\Python312\""
powershell -Command "$p='C:\Program Files\Python312'; $s=\"$p\Scripts\"; $m=[Environment]::GetEnvironmentVariable('Path','Machine'); if($m -notlike \"*$s*\") { [Environment]::SetEnvironmentVariable('Path', \"$p;$s;$m\", 'Machine') }"--scope machine を指定することで、システム全体(全ユーザー向け)にインストールされる。このオプションの実行には管理者権限が必要である。インストール完了後、コマンドプロンプトを再起動すると PATH が自動的に設定される。
方法2:インストーラーによるインストール
- Python 公式サイト(https://www.python.org/downloads/)にアクセスし、「Download Python 3.x.x」ボタンから Windows 用インストーラーをダウンロードする。
- ダウンロードしたインストーラーを実行する。
- 初期画面の下部に表示される「Add python.exe to PATH」に必ずチェックを入れてから「Customize installation」を選択する。このチェックを入れ忘れると、コマンドプロンプトから
pythonコマンドを実行できない。 - 「Install Python 3.xx for all users」にチェックを入れ、「Install」をクリックする。
インストールの確認
コマンドプロンプトで以下を実行する。
python --versionバージョン番号(例:Python 3.12.x)が表示されればインストール成功である。「'python' は、内部コマンドまたは外部コマンドとして認識されていません。」と表示される場合は、インストールが正常に完了していない。
Git のインストール
管理者権限のコマンドプロンプトで以下を実行する。管理者権限のコマンドプロンプトを起動するには、Windows キーまたはスタートメニューから「cmd」と入力し、表示された「コマンドプロンプト」を右クリックして「管理者として実行」を選択する。
REM Git をシステム領域にインストール
winget install --scope machine --id Git.Git -e --silent --disable-interactivity --force --accept-source-agreements --accept-package-agreements --override "/VERYSILENT /NORESTART /NOCANCEL /SP- /CLOSEAPPLICATIONS /RESTARTAPPLICATIONS /COMPONENTS=""icons,ext\reg\shellhere,assoc,assoc_sh"" /o:PathOption=Cmd /o:CRLFOption=CRLFCommitAsIs /o:BashTerminalOption=MinTTY /o:DefaultBranchOption=main /o:EditorOption=VIM /o:SSHOption=OpenSSH /o:UseCredentialManager=Enabled /o:PerformanceTweaksFSCache=Enabled /o:EnableSymlinks=Disabled /o:EnableFSMonitor=Disabled"
【関連する外部ページ】
- Git の公式ページ: https://git-scm.com/
Build Tools for Visual Studio 2022,NVIDIA ドライバ,NVIDIA CUDA ツールキット 11.8,NVIDIA cuDNN 8.9.7 のインストール(Windows 上)
【サイト内の関連ページ】 NVIDIA グラフィックスボードを搭載しているパソコンの場合には, NVIDIA ドライバ, NVIDIA CUDA ツールキット, NVIDIA cuDNN のインストールを行う.
- Windows での Build Tools for Visual Studio 2022 のインストール: 別ページ »で説明
- Windows での NVIDIA ドライバ,NVIDIA CUDA ツールキット 11.8,NVIDIA cuDNN v8.9.7 のインストール手順: 別ページ »で説明
【関連する外部ページ】
- Build Tools for Visual Studio 2022 (ビルドツール for Visual Studio 2022)の公式ダウンロードページ: https://visualstudio.microsoft.com/ja/visual-cpp-build-tools/
- NVIDIA ドライバのダウンロードの公式ページ: https://www.nvidia.co.jp/Download/index.aspx?lang=jp
- NVIDIA CUDA ツールキットのアーカイブの公式ページ: https://developer.nvidia.com/cuda-toolkit-archive
- NVIDIA cuDNN のダウンロードの公式ページ: https://developer.nvidia.com/cudnn
PyTorch のインストール(Windows 上)
- 以下の手順を管理者権限のコマンドプロンプトで実行する
(手順:Windowsキーまたはスタートメニュー →
cmdと入力 → 右クリック → 「管理者として実行」)。 - PyTorch のページを確認
- 次のようなコマンドを実行(実行するコマンドは,PyTorch のページの表示されるコマンドを使う).
次のコマンドを実行することにより, PyTorch 2.3 (NVIDIA CUDA 11.8 用)がインストールされる. 但し,Anaconda3を使いたい場合には別手順になる.
事前に NVIDIA CUDA のバージョンを確認しておくこと(ここでは,NVIDIA CUDA ツールキット 11.8 が前もってインストール済みであるとする).
PyTorch で,GPU が動作している場合には,「torch.cuda.is_available()」により,True が表示される.
python -m pip install -U --ignore-installed pip python -m pip uninstall -y torch torchvision torchaudio torchtext xformers python -m pip install -U torch torchvision torchaudio numpy --index-url https://download.pytorch.org/whl/cu118 python -c "import torch; print(torch.__version__, torch.cuda.is_available())"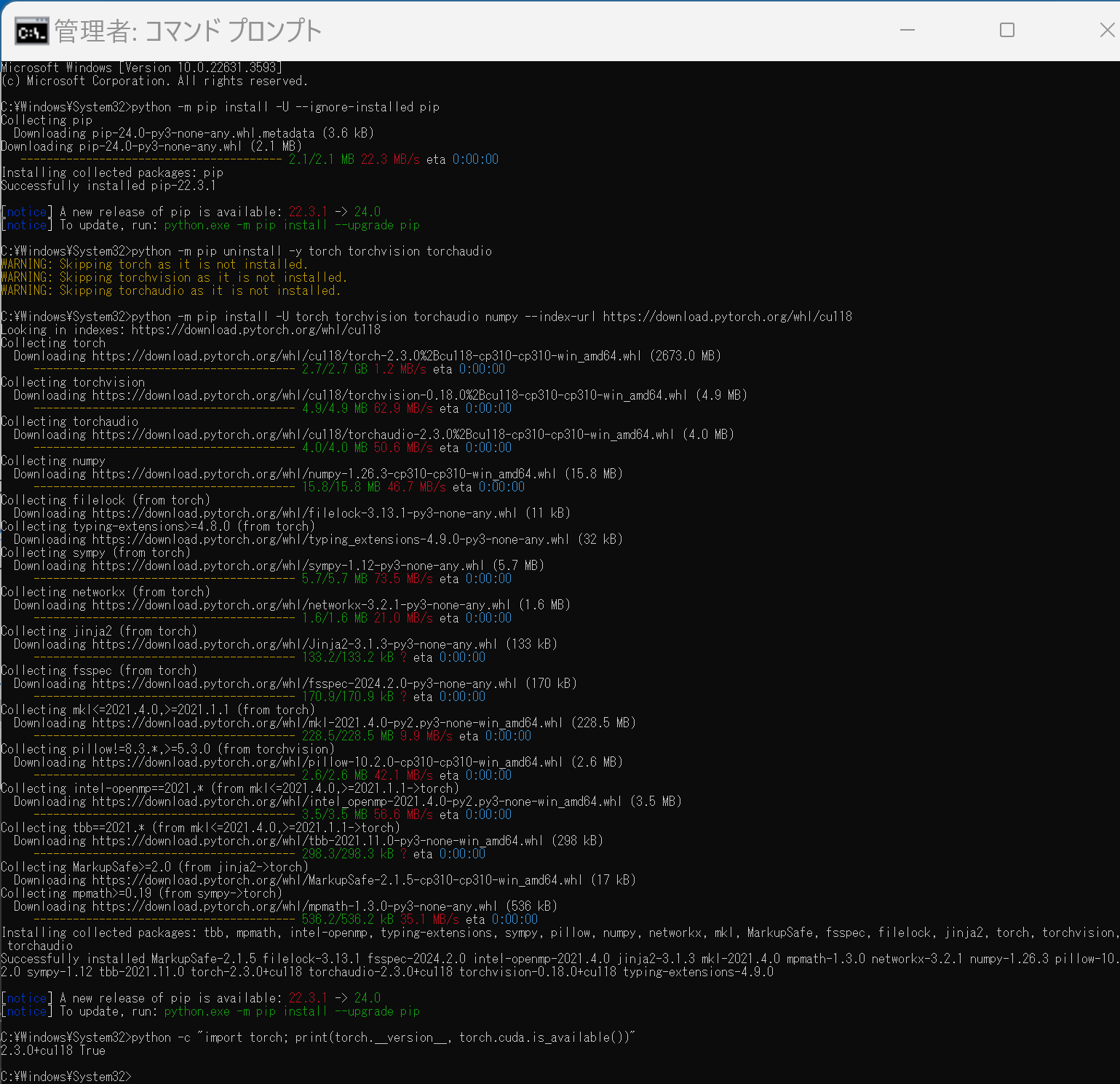 Anaconda3を使いたい場合には, Anaconda プロンプト (Anaconda Prompt) を管理者として実行し, 次のコマンドを実行する. (PyTorch と NVIDIA CUDA との連携がうまくいかない可能性があるため,Anaconda3を使わないことも検討して欲しい).
Anaconda3を使いたい場合には, Anaconda プロンプト (Anaconda Prompt) を管理者として実行し, 次のコマンドを実行する. (PyTorch と NVIDIA CUDA との連携がうまくいかない可能性があるため,Anaconda3を使わないことも検討して欲しい).conda install -y pytorch torchvision torchaudio pytorch-cuda=11.8 cudnn -c pytorch -c nvidia py -c "import torch; print(torch.__version__, torch.cuda.is_available())"【サイト内の関連ページ】
【関連する外部ページ】
MMDetection,MMSegmentation のインストール(Windows 上)
インストールの方法は複数ある. ここでは, NVIDIA CUDA ツールキットを使うことも考え, インストールしやすい方法として,ソースコードからビルドしてインストールする方法を案内している.
- 以下の手順を管理者権限のコマンドプロンプトで実行する
(手順:Windowsキーまたはスタートメニュー →
cmdと入力 → 右クリック → 「管理者として実行」)。 - PyTorch がインストールできていることを確認するために,PyTorch のバージョンを表示
python -c "import torch; TORCH_VERSION = '.'.join(torch.__version__.split('.')[:2]); print(TORCH_VERSION)"
- PyTorch が NVIDIA CUDA ツールキットを認識できていることを確認するために,
PyTorch が認識しているNVIDIA CUDA ツールキット のバージョンを表示
このとき,実際には 11.8 をインストールしているのに,「cu117」のように古いバージョンが表示されることがある.このような場合は,気にせずに続行する.
python -c "import torch; CUDA_VERSION = torch.__version__.split('+')[-1]; print(CUDA_VERSION)"
- 環境変数 PROTOCOL_BUFFERS_PYTHON_IMPLEMENTATION の設定
システム環境変数 PROTOCOL_BUFFERS_PYTHON_IMPLEMENTATION に「python」を設定するために, コマンドプロンプトで,次のコマンドを実行する.
この設定は,MMSegmentation 利用のときのエラーの回避のためである.関連する外部ページ: https://developers.google.com/protocol-buffers/docs/news/2022-05-06#python-updates
powershell -command "[System.Environment]::SetEnvironmentVariable(\"PROTOCOL_BUFFERS_PYTHON_IMPLEMENTATION\", \"python\", \"Machine\")"
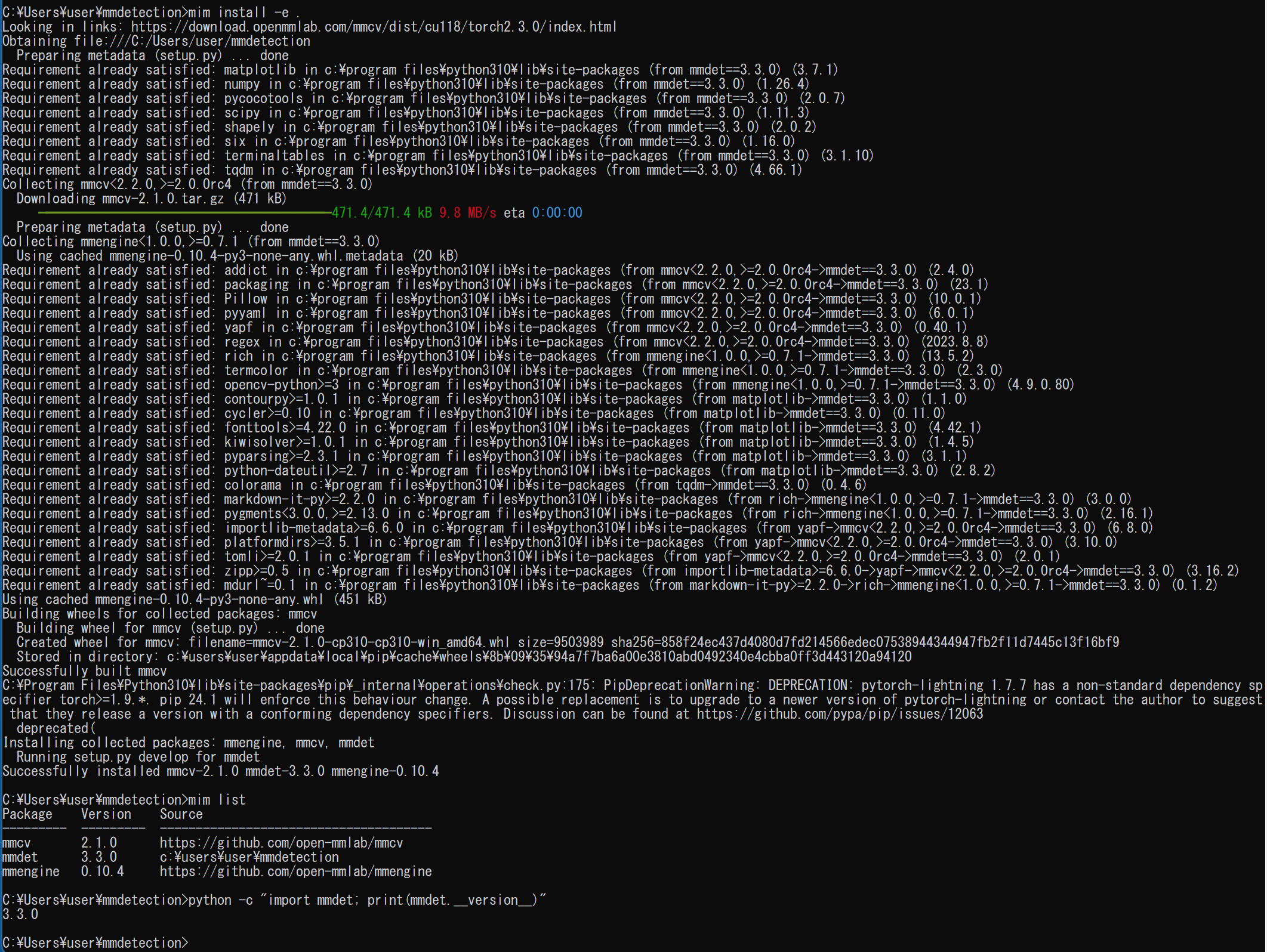
- MIM,MMDetection, MMSegmentation のインストール
インストール手順は, https://mmdetection.readthedocs.io/en/latest/get_started.html による.
python -m pip install -U --ignore-installed pip python -m pip uninstall -y openmim mmdet mmseg mmsegmentation mmcv mmcv-full opencv-python opencv-python-headless python -m pip install -U openmim opencv-python cd /d c:%HOMEPATH% rmdir /s /q mmdetection git clone https://github.com/open-mmlab/mmdetection.git cd mmdetection mim uninstall -y mmdet pip install -r requirements.txt mim install -e . mim list python -c "import mmdet; print(mmdet.__version__)"(途中省略)
- MMSegmentation のインストール
https://mmdetection.readthedocs.io/en/latest/get_started.html による.
cd /d c:%HOMEPATH% rmdir /s /q mmsegmentation git clone https://github.com/open-mmlab/mmsegmentation.git cd mmsegmentation mim uninstall -y mmsegmentation pip install -r requirements.txt mim install -e . mim list python -c "import mmseg; print(mmseg.__version__)"(途中省略)
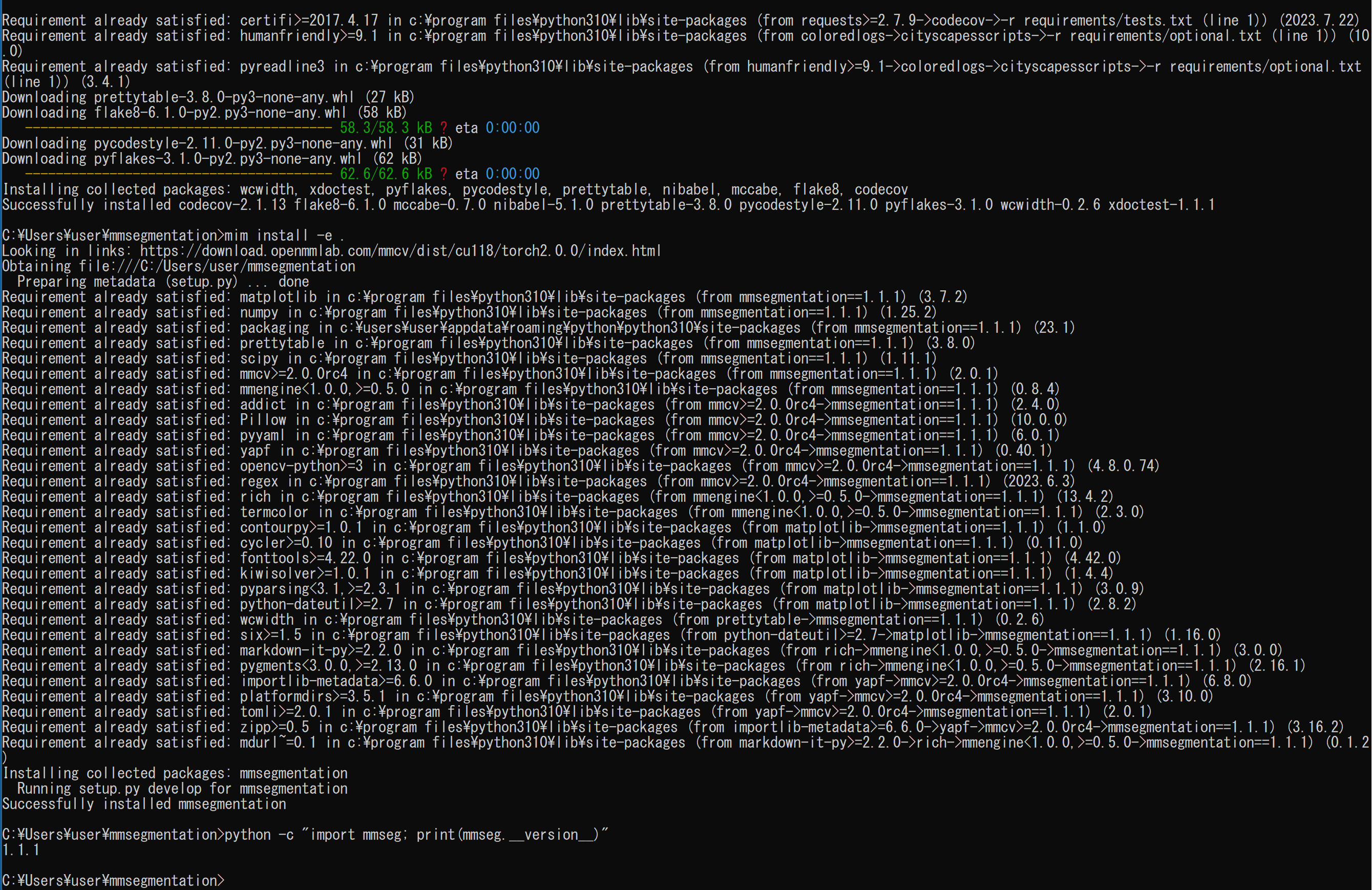
- mim list の実行により確認
mim list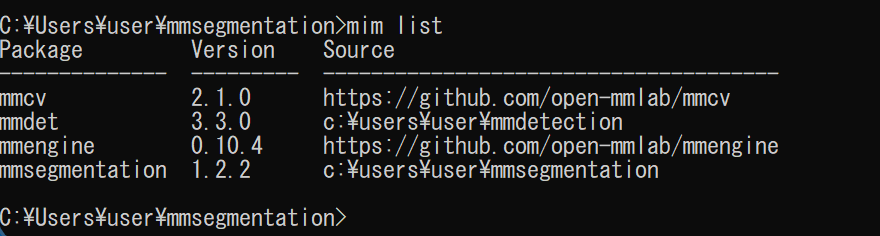
- MMDetection, MMSegmentation をインストールできたことの確認
エラーメッセージが出ないこと.
python -c "import mmdet; print(mmdet.__version__)" python -c "import mmseg; print(mmseg.__version__)"
MMSegmentation を用いた画像のセグメンテーションの実行(Windows 上)
画像のセマンティック・セグメンテーション(CityScapes, DeepLabV3plus, R-101-D8 を使用)
- Windows のコマンドプロンプトを開く
- 事前学習済みモデルのダウンロード
Cityscapes データセットを用いての事前学習済みモデルを使用している.
MMSegmentation の model zoo のページ: https://github.com/open-mmlab/mmsegmentation/blob/master/docs/en/model_zoo.mdここではCityScapes, DeepLabV3plus, R-101-D8 を選ぶことにする. Cityscapes データセットで学習済みのモデルである.
- deeplabv3plus_r101-d8_4xb2-80k_cityscapes-512x1024.py
- deeplabv3plus_r101-d8_512x1024_80k_cityscapes_20200606_114143-068fcfe9.pth
次のコマンドを実行する.dir /w の実行により,ファイル名「deeplabv3plus_r101-d8_512x1024_80k_cityscapes_20200606_114143-068fcfe9.pth」を確認する.
cd /d c:%HOMEPATH%\mmsegmentation mkdir checkpoints cd checkpoints mim download mmsegmentation --config deeplabv3plus_r101-d8_4xb2-80k_cityscapes-512x1024 --dest . dir /w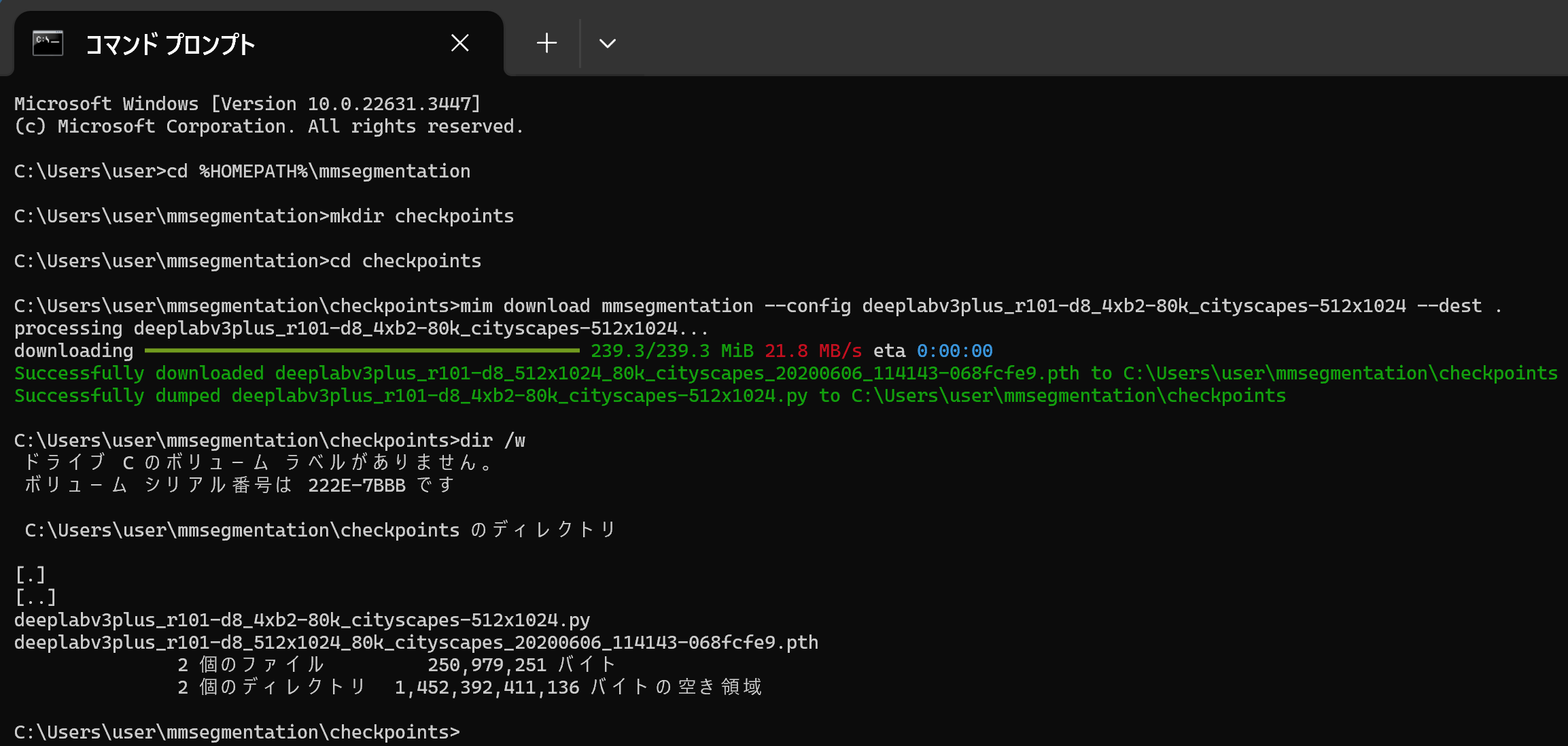
- Python プログラムの実行
Python プログラムの実行
- Windows では python (Python ランチャーは py)
- Ubuntu では python3
Python 開発環境(Jupyter Qt Console, Jupyter ノートブック (Jupyter Notebook), Jupyter Lab, Nteract, Spyder, PyCharm, PyScripterなど)も便利である.
Python のまとめ: 別ページ »にまとめ
python - 次の Python プログラムを実行する.
セマンティック・セグメンテーションを行う.
プログラムは,公式ページ https://mmsegmentation.readthedocs.io/en/latest/get_started.html のものを書き換えて使用.
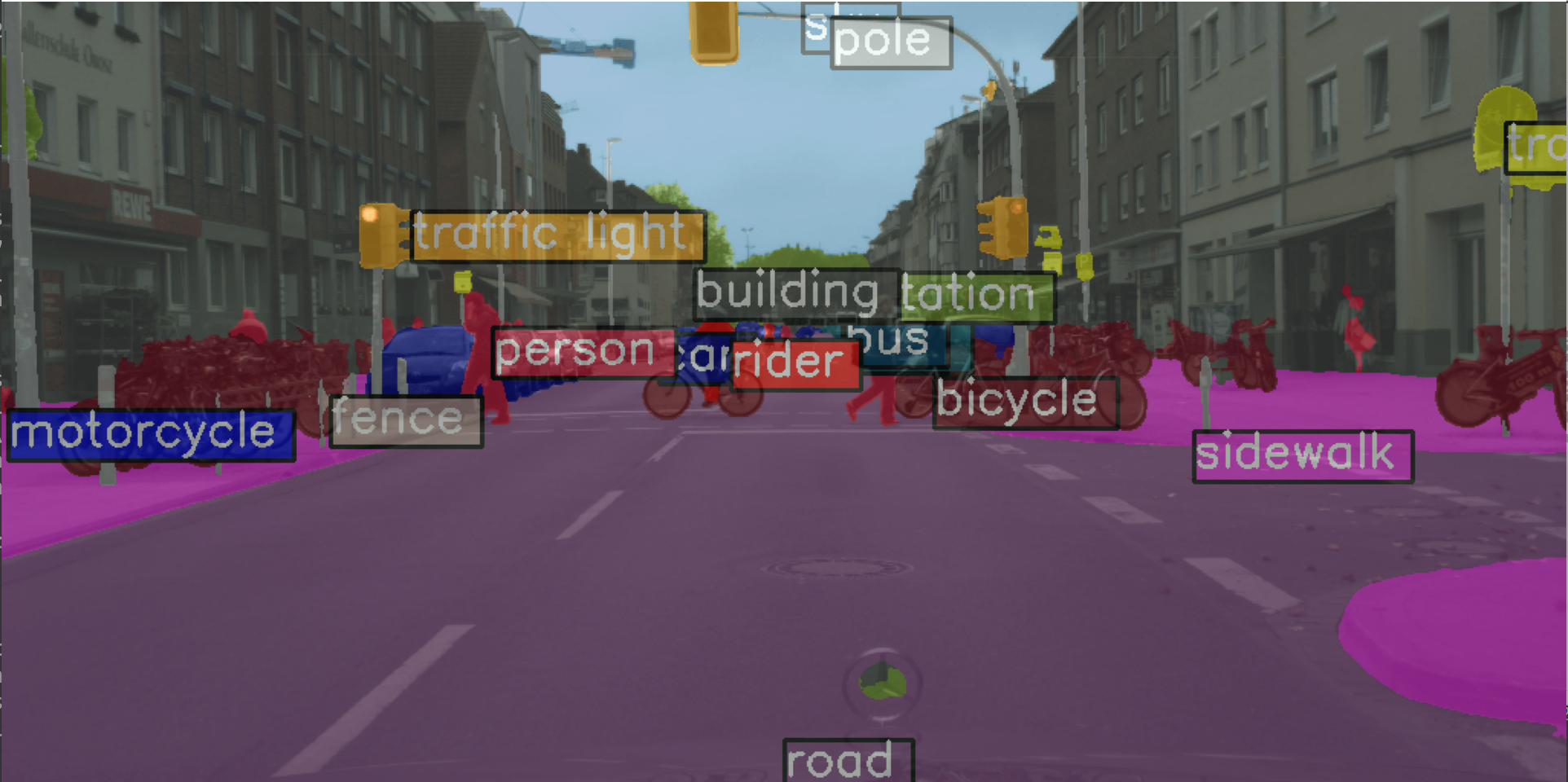
このプログラムは、MMSegmentationライブラリを使用して、事前学習済みのDeepLabV3+モデルを初期化し、指定された画像に対してセグメンテーションを実行します。推論結果は、元の画像に重ねて表示されます。import os import torch from mmseg.apis import init_model, inference_model, show_result_pyplot import mmcv def initialize_model(config_file, checkpoint_file, device): model = init_model(config_file, checkpoint_file, device=device) return model def load_image(img_path): if img_path.startswith('http'): img = mmcv.imread(img_path) else: img = img_path return img def perform_inference(model, img): result = inference_model(model, img) return result def main(): os.chdir((os.getenv('HOMEPATH') + '\\' + 'mmsegmentation')) device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') config_file = 'configs/deeplabv3plus/deeplabv3plus_r101-d8_4xb2-80k_cityscapes-512x1024.py' checkpoint_file = 'checkpoints/deeplabv3plus_r101-d8_512x1024_80k_cityscapes_20200606_114143-068fcfe9.pth' model = initialize_model(config_file, checkpoint_file, device) img_path = 'https://raw.githubusercontent.com/open-mmlab/mmsegmentation/main/demo/demo.png' img = load_image(img_path) result = perform_inference(model, img) show_result_pyplot(model, img, result, opacity=0.5) if __name__ == '__main__': main()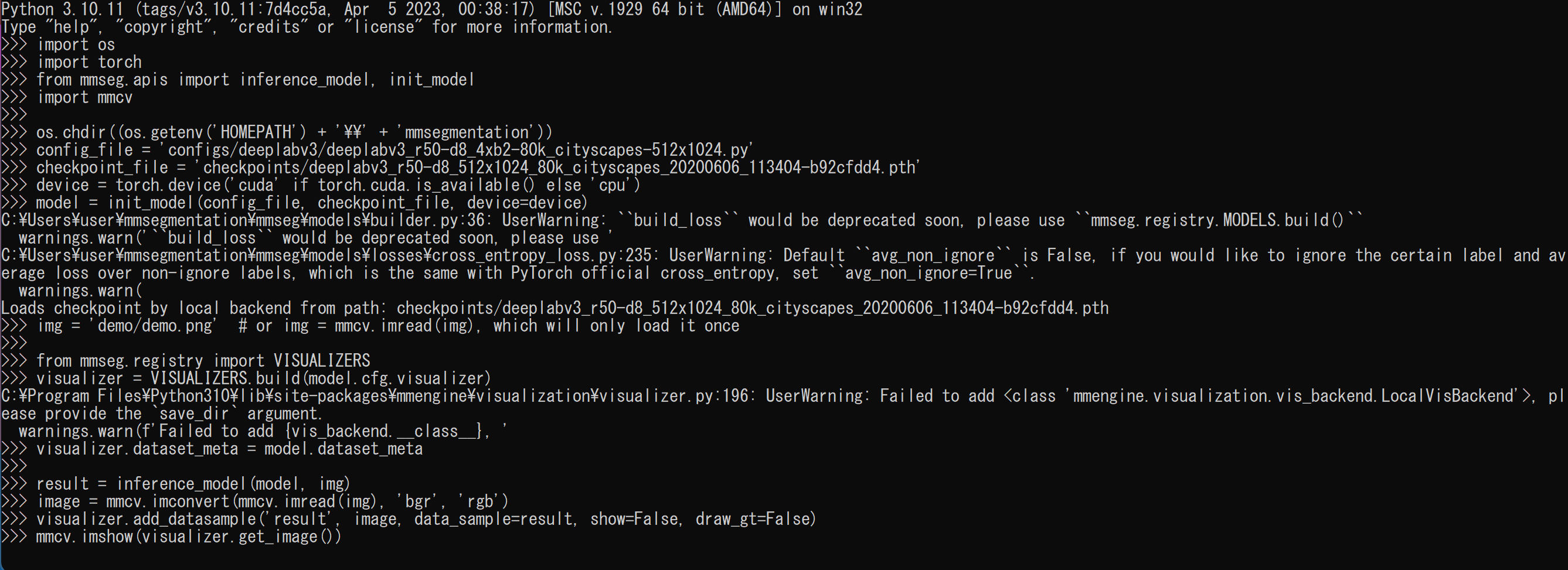
- 結果が表示される
エラーメッセージが出ないことを確認.
動画ファイルのセマンティック・セグメンテーション
- 動画ファイル video.mp4 を %HOMEPATH%\mmsegmentation に置く
- 動画ファイルのセグメンテーションを行う Python プログラム
次の Python プログラムを実行する.mmcv を用いた表示を行うので,Jupyter QtConsole や Jupyter ノートブック (Jupyter Notebook) の利用が便利である.
import os import torch from mmseg.apis import inference_model, init_model, show_result_pyplot import mmcv os.chdir((os.getenv('HOMEPATH') + '\\' + 'mmsegmentation')) config_file = 'configs/deeplabv3/deeplabv3_r50-d8_4xb2-80k_cityscapes-512x1024.py' checkpoint_file = 'checkpoints/deeplabv3_r50-d8_512x1024_80k_cityscapes_20200606_113404-b92cfdd4.pth' device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') model = init_model(config_file, checkpoint_file, device=device) video = mmcv.VideoReader(os.getenv('HOMEPATH') + '\\' + 'mmdetection' + '\\' + 'demo' + '\\' + 'demo.mp4') from mmseg.registry import VISUALIZERS visualizer = VISUALIZERS.build(model.cfg.visualizer) visualizer.dataset_meta = model.dataset_meta for frame in video: result = inference_model(model, frame) image = mmcv.imconvert(frame, 'bgr', 'rgb') visualizer.add_datasample('result', image, data_sample=result, show=False, draw_gt=False) mmcv.imshow(visualizer.get_image(), wait_time=100)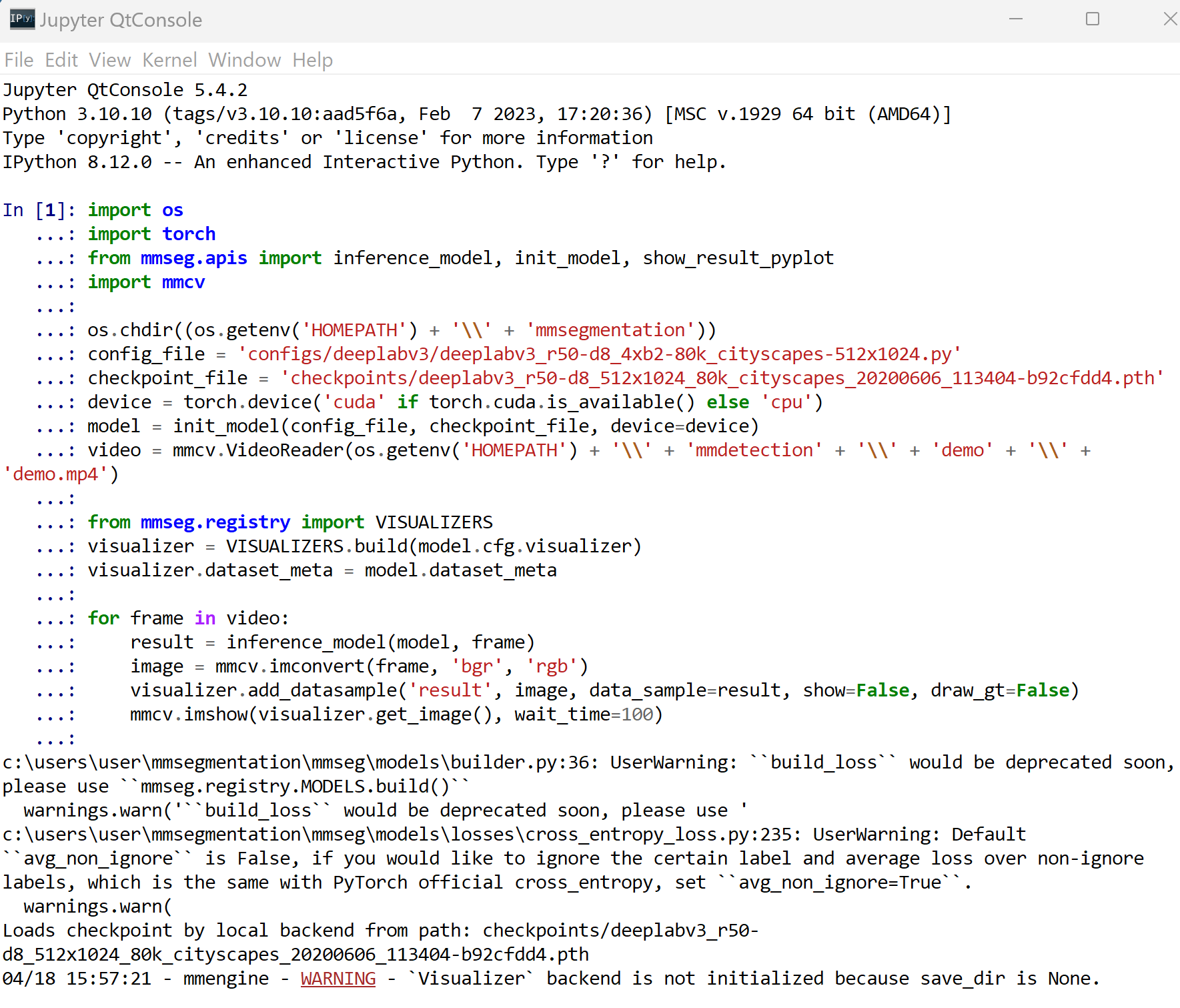
- 結果が表示される
エラーメッセージが出ないことを確認.

パソコンのカメラのセマンティック・セグメンテーション
- 事前学習済みモデルのダウンロード
Cityscapes データセットを用いての事前学習済みモデルを使用している.
MMSegmentation の model zoo のページ: https://github.com/open-mmlab/mmsegmentation/blob/master/docs/en/model_zoo.mdここではCityScapes, DeepLabV3, R-50-D8 を選ぶことにする. Cityscapes データセットで学習済みのモデルである.
- configs/deeplabv3/deeplabv3_r50-d8_512x1024_80k_cityscapes.py
- https://download.openmmlab.com/mmsegmentation/v0.5/deeplabv3/deeplabv3_r50-d8_512x1024_80k_cityscapes/deeplabv3_r50-d8_512x1024_80k_cityscapes_20200606_113404-b92cfdd4.pth
次のコマンドを実行する.
cd /d c:%HOMEPATH%\mmsegmentation mkdir checkpoints cd checkpoints curl -O https://download.openmmlab.com/mmsegmentation/v0.5/deeplabv3/deeplabv3_r50-d8_512x1024_80k_cityscapes/deeplabv3_r50-d8_512x1024_80k_cityscapes_20200606_113404-b92cfdd4.pth dir /w
- 動画ファイルのセグメンテーションを行う Python プログラム
次の Python プログラムを実行する.mmcv を用いた表示を行うので,Jupyter QtConsole や Jupyter ノートブック (Jupyter Notebook) の利用が便利である.
import os import torch import cv2 from mmseg.apis import inference_model, init_model, show_result_pyplot import mmcv os.chdir((os.getenv('HOMEPATH') + '\\' + 'mmsegmentation')) config_file = 'configs/deeplabv3/deeplabv3_r50-d8_4xb2-80k_cityscapes-512x1024.py' checkpoint_file = 'checkpoints/deeplabv3_r50-d8_512x1024_80k_cityscapes_20200606_113404-b92cfdd4.pth' device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') model = init_model(config_file, checkpoint_file, device=device) video = mmcv.VideoReader(os.getenv('HOMEPATH') + '\\' + 'mmdetection' + '\\' + 'demo' + '\\' + 'demo.mp4') from mmseg.registry import VISUALIZERS visualizer = VISUALIZERS.build(model.cfg.visualizer) visualizer.dataset_meta = model.dataset_meta v = cv2.VideoCapture(0) while(v.isOpened()): r, f = v.read() if ( r == False ): break result = inference_model(model, f) image = mmcv.imconvert(f, 'bgr', 'rgb') visualizer.add_datasample('result', image, data_sample=result, show=False, draw_gt=False) mmcv.imshow(visualizer.get_image(), wait_time=100)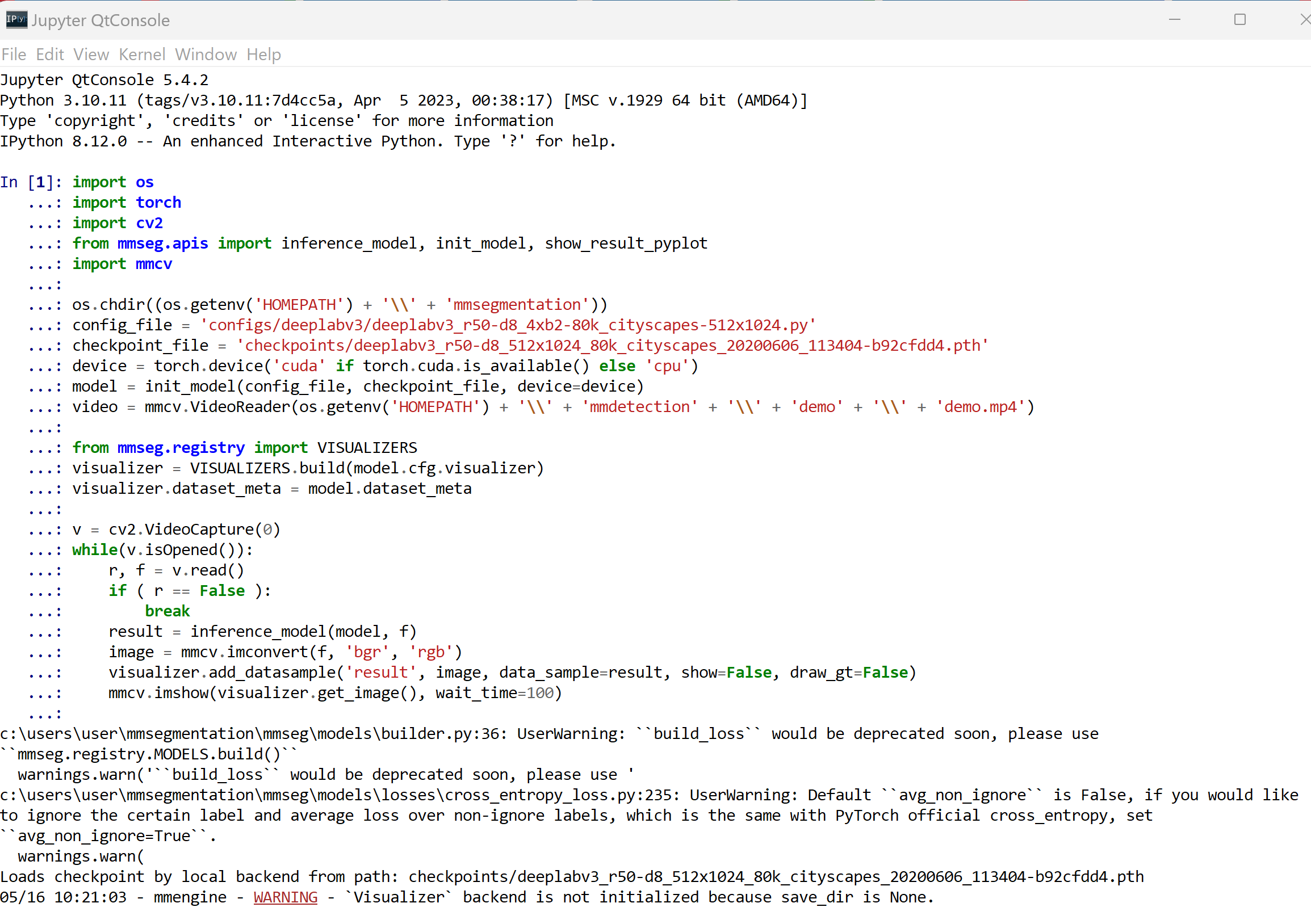
- 結果が表示される
エラーメッセージが出ないことを確認.
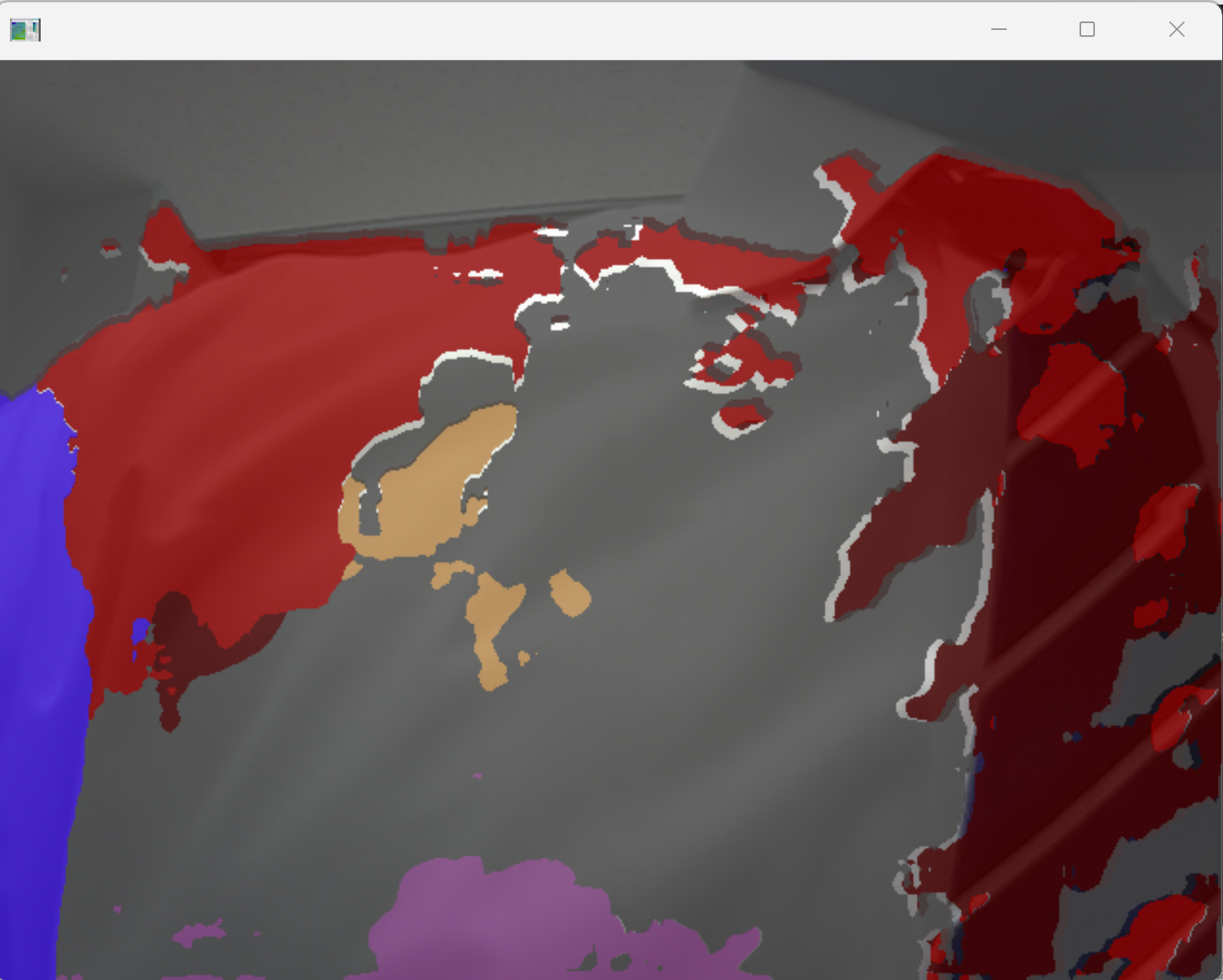
- 事前学習済みモデルのダウンロード
Pascal VOC データセットを用いての事前学習済みモデルを使用している.
MMSegmentation の model zoo のページ: https://github.com/open-mmlab/mmsegmentation/blob/master/docs/en/model_zoo.mdここではPascal VOC, DeepLabV3, R-50-D8 を選ぶことにする. Cityscapes データセットで学習済みのモデルである.
- configs/deeplabv3plus/deeplabv3plus_r50-d8_4xb4-80k_ade20k-512x512.py
- https://download.openmmlab.com/mmsegmentation/v0.5/deeplabv3plus/deeplabv3plus_r50-d8_512x512_80k_ade20k/deeplabv3plus_r50-d8_512x512_80k_ade20k_20200614_185028-bf1400d8.pth
次のコマンドを実行する.
cd /d c:%HOMEPATH%\mmsegmentation mkdir checkpoints cd checkpoints curl -O https://download.openmmlab.com/mmsegmentation/v0.5/deeplabv3plus/deeplabv3plus_r50-d8_512x512_80k_ade20k/deeplabv3plus_r50-d8_512x512_80k_ade20k_20200614_185028-bf1400d8.pth dir /w
- 動画ファイルのセグメンテーションを行う Python プログラム
次の Python プログラムを実行する.mmcv を用いた表示を行うので,Jupyter QtConsole や Jupyter ノートブック (Jupyter Notebook) の利用が便利である.
import os import torch import cv2 from mmseg.apis import inference_model, init_model, show_result_pyplot import mmcv os.chdir((os.getenv('HOMEPATH') + '\\' + 'mmsegmentation')) config_file = 'configs/deeplabv3plus/deeplabv3plus_r50-d8_4xb4-80k_ade20k-512x512.py' checkpoint_file = 'checkpoints/deeplabv3plus_r50-d8_512x512_80k_ade20k_20200614_185028-bf1400d8.pth' device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') model = init_model(config_file, checkpoint_file, device=device) video = mmcv.VideoReader(os.getenv('HOMEPATH') + '\\' + 'mmdetection' + '\\' + 'demo' + '\\' + 'demo.mp4') from mmseg.registry import VISUALIZERS visualizer = VISUALIZERS.build(model.cfg.visualizer) visualizer.dataset_meta = model.dataset_meta v = cv2.VideoCapture(0) while(v.isOpened()): r, f = v.read() if ( r == False ): break result = inference_model(model, f) image = mmcv.imconvert(f, 'bgr', 'rgb') visualizer.add_datasample('result', image, data_sample=result, show=False, draw_gt=False) mmcv.imshow(visualizer.get_image(), wait_time=100)
- 結果が表示される
エラーメッセージが出ないことを確認.

- 以下の手順を管理者権限のコマンドプロンプトで実行する
(手順:Windowsキーまたはスタートメニュー →