情報工学演習II
【目次】
大学授業用に作成した資料を更新・改良して公開している。これらは クリエイティブコモンズ 表示-非営利-継承 4.0 国際ライセンス(CC BY-NC-SA 4.0) で提供しており、事前の許可なく自由に利用できる。条件は著作者表示(BY)、非営利目的のみ(NC)、同一ライセンスでの再配布(SA)である。
全体内容
キャリアサポート
- オリエンテーションセッション: 学生に情報工学の本質、その学科の学生が持つ強みと魅力、可能なキャリアパスについての理解を深めるための導入セッション。
- 業界エキスパートによるゲストレクチャー: 現場で活躍する専門家を招き、業界の動向や必要なスキルについて説明する。(この行事は情報工学科全体のイベントとして開催予定である)
- 企業説明会とオンライン情報収集: 自主的な情報収集とワークの機会。(これは各自の自習、自発的活動となり、授業外になる)
- カウンセリング: 学生の興味やスキルに応じた自己発見、自立力、自己成長力のカウンセリング。
ITエンジニア、AIエンジニアとして成長する実践的学び
- 授業の特色: 自主性、課題解決能力、正解のない問題への取り組み、失敗からの学び、自己成長力、他者へのポジティブな影響力、広く深い専門知識と実用スキルを養成。
- AIとプログラミングの基礎: Pythonや基礎的な機械学習アルゴリズムの導入。
- プロジェクトワーク:
- プロジェクト1: データ分析(分類、回帰等)とデータマネジメント。
- プロジェクト2: 自然言語処理や画像認識など、より高度な課題に挑戦。
- 個人ワーク
- ミニプロジェクト: 学生自身が問題を設定し、解決策を探求。
- コードレビューと相互刺激: 学生同士で共同して、プログラムの品質を高め合うセッション。ChatGPTも利用。
- 成果の発表: グループワークの成果を発表し、他者にポジティブな影響を与える力を自覚。
自主性、自己分析と自己アピールのスキル、AIやデータベースやプログラミングの実用的な能力、そして自己成長力などの社会的基礎力を身につけることができる。これにより、学生は将来のキャリアに対する具体的な自信とビジョンを形成することが可能となる。大いに成長してほしい。
計画
- セッション1: オリエンテーション
- イントロダクションと期待値の共有
- 情報工学の本質と可能なキャリアパスについての説明
- アクティビティ: 学生が自分の強みや興味について考察
- セッション2: 研究活動サポート
- 研究活動の利点と可能性
- 研究のための心構え
- アクティビティ: 学生が自己の興味のある分野、技術について考察
- セッション3: Pythonとデータ処理の基礎
- Pythonの基本的な文法と操作
- 簡単な機械学習アルゴリズムの導入
- ハンズオン: 簡単なPythonプログラムを作成
- セッション4: AI開発プロジェクト準備:画像分類とGUIアプリケーションの構築
- ディープラーニングによる画像分類
- ディープラーニングでの学習済みモデルの活用
- Tkinterによる GUI の実現
- セッション5: プロジェクト1 - データ分析とデータマネジメント
- データ分析の基礎(分類、回帰等)
- ハンズオン: 実際のデータセットを用いた簡単な分析
- セッション6: ミニプロジェクトと個人ワーク
- 学生が自ら問題を設定し、解決策を模索
- セッション7: プロジェクト2 - 自然言語処理や画像認識
- 自然言語処理と画像認識の基本概念
- ハンズオン: 簡単な自然言語処理または画像認識プロジェクト
- セッション8: コードレビューと相互刺激
- ChatGPTを使ったコードレビュー
- ペアプログラミングやグループでのコードレビュー
- アクティビティ: コードの改善と相互評価
- セッション9: 成果の発表と総括
- 各グループまたは個人がプロジェクトの成果を発表
- コースの振り返りと今後の学びの方向性
- セッション10以降: 高度なテクノロジー
その他、業界エキスパート、OB/OGによるゲストレクチャー
ゲストスピーカーによる業界動向と必要なスキルに関するプレゼンテーション
セッション1: オリエンテーション
各自が、情報工学の本質、情報工学科の学生が持つ強みと魅力、可能なキャリアパスについて理解する。さらに、ITエンジニア、AIエンジニアとして成長するためのビジョンと目標を理解する。
【資料】
セッション2: 研究活動サポート
研究活動は多くの利点と成長の可能性がある。研究を行うには、確固たる心構え、そして、研究に十分に時間をかけることが大切である。研究は楽しく、自分の思い通りに進めていくものである。研究の楽しさを実感しながら進めよう。
【資料】
- PDFファイル: sotu1-intropart202310.pdf
- パワーポイントファイル(PDFファイルと同じ内容): sotu1-intropart202310.pptx
【各自の探求、考察】
- 1: テーマの探索
- 目的: 自分が興味を持つ研究テーマを探索する。
- 課題: インターネットで過去の研究を調査し、選んだ研究テーマを1〜2文で簡潔に説明する。
- 2: 研究計画の理解
- 目的: 研究計画の全体像を把握する。
- 課題: 資料のページ14を参考に、研究を実施するために必要な手順や活動を確認する。具体的な課題設定、実験手法、そして結果の取得方法について考えてみよう。
- 3: スキルセットの確認
- 目的: 研究に必要なスキルセットを特定する。
- 課題: 資料のページ16に、研究で使用する可能性のあるライブラリ、ツール、プログラミング言語をリストアップしている。その中で特に興味を持つスキルについて確認し、自分なりの感想や意欲を持ってほしい。
セッション3: Pythonとデータ処理の基礎
Pythonは多様な用途で広く使われるプログラミング言語であり、特に文法のシンプルさ、拡張性、柔軟性が高く評価されている。この言語は直感的で読みやすく、初心者にも取り組みやすい設計になっている。主要なキーワードには「print」、「type」、「if」、「else」、「for」、「while」などがあり、オブジェクト指向プログラミングもサポートされている。さらに、Pythonは多様な標準ライブラリが提供されているため、データ処理、AI、メディア処理、データ連携、Web開発など幅広い用途で活用できる。オンライン環境であるGoogle Colaboratoryを使えば、Googleアカウントさえあれば手軽にPythonのノートブックを利用できる。特にデータ処理においては、Pandasライブラリのデータフレームが表形式のデータを効率的に扱うツールとして用いられ、多くのデータ形式の読み書きもサポートしている。
【資料】
- PDFファイル: enshu2-3.pdf
- パワーポイントファイル(PDFファイルと同じ内容): enshu2-3.pptx
【関連資料】
Google アカウント
- PDFファイル: googleaccount.pdf
- パワーポイントファイル(PDFファイルと同じ内容): googleaccount.pptx
【演習で使用する Google Colaboratory のページ】
https://colab.research.google.com/drive/1l2pLl72PYG5TFKKu8ha0h_9fFCafxG4j?usp=sharing
セッション4: AI開発プロジェクト準備:画像分類とGUIアプリケーションの構築
画像分類に関連するAI技術は、ディープラーニングという知的なITシステムをベースに、多層のニューラルネットワークを使用して複雑なタスクを実行する能力を持っている。特に、大規模データセットで学習された学習済みモデルは、ニューラルネットワークのパラメータが最適化され、特定のタスクに特化している。これらのモデルは、転移学習やファインチューニングを利用して、異なるタスクにも適用可能である。学習済みモデルの利用はコスト削減や高い性能、迅速な技術検証などのメリットがある。特に、ImageNet-1Kというデータセットで学習されたモデルは、1,000種類のカテゴリを持ち、多様なタスクに適用可能である。このモデルを利用することで、新しい技術の性能を迅速に試すことや、転移学習やファインチューニングの導入などが可能となる。さらに、tkinterというPythonの標準ライブラリを使用すると、GUIを手軽に作成し、ユーザーに視覚的で直感的な操作環境を提供することができる。

【資料】
- PDFファイル: enshu2-5.pdf
- パワーポイントファイル(PDFファイルと同じ内容): enshu2-5.pptx
【演習で使用する Python プログラム】
演習1
import timm
import torch
import requests
from PIL import Image
from io import BytesIO
# ImageNet 1kのラベル情報をダウンロード
IMAGENET_1k_URL = 'https://storage.googleapis.com/bit_models/ilsvrc2012_wordnet_lemmas.txt'
IMAGENET_1k_LABELS = requests.get(IMAGENET_1k_URL).text.strip().split('\n')
def load_image(url, transform):
image = Image.open(requests.get(url, stream=True).raw)
image_tensor = transform(image)
return image_tensor
def classify_image(model, image_tensor, topk=5):
output = model(image_tensor.unsqueeze(0))
probabilities = torch.nn.functional.softmax(output[0], dim=0)
values, indices = torch.topk(probabilities, topk)
return [{'label': IMAGENET_1k_LABELS[idx], 'index': idx, 'value': val.item()} for val, idx in zip(values, indices)]
if __name__ == "__main__":
# モデルを読み込む
model_name = 'eva02_large_patch14_448.mim_in22k_ft_in1k'
model = timm.create_model(model_name, pretrained=True).eval()
transform = timm.data.create_transform(**timm.data.resolve_data_config(model.pretrained_cfg))
# 画像ファイルの指定
url = 'https://datasets-server.huggingface.co/assets/imagenet-1k/--/default/test/12/image/image.jpg'
image_tensor = load_image(url, transform)
# 画像を分類し、結果を表示
top_classes = classify_image(model, image_tensor)
for i in top_classes:
print(i)
# 期待される結果
expected_indices = torch.tensor([162, 166, 161, 164, 167])
print("Expected Indices:", expected_indices)
演習2
import tkinter as tk
from tkinter import filedialog
root = tk.Tk()
file_label = tk.Label(root, text="")
file_label.pack()
filepath = filedialog.askopenfilename()
if filepath:
file_label.config(text=filepath)
root.mainloop()
exit()
演習3
import tkinter as tk
from tkinter import filedialog
import timm
import torch
import requests
from PIL import Image
# ImageNet 1kのラベル情報をダウンロード
IMAGENET_1k_URL = 'https://storage.googleapis.com/bit_models/ilsvrc2012_wordnet_lemmas.txt'
IMAGENET_1k_LABELS = requests.get(IMAGENET_1k_URL).text.strip().split('\n')
def load_image(file_path, transform):
image = Image.open(file_path)
image_tensor = transform(image)
return image_tensor
def classify_image(model, image_tensor, topk=5):
output = model(image_tensor.unsqueeze(0))
probabilities = torch.nn.functional.softmax(output[0], dim=0)
values, indices = torch.topk(probabilities, topk)
return [{'label': IMAGENET_1k_LABELS[idx], 'index': idx, 'value': val.item()} for val, idx in zip(values, indices)]
if __name__ == "__main__":
# モデルを読み込む
model_name = 'eva02_large_patch14_448.mim_in22k_ft_in1k'
model = timm.create_model(model_name, pretrained=True).eval()
transform = timm.data.create_transform(**timm.data.resolve_data_config(model.pretrained_cfg))
# 画像ファイルの指定
root = tk.Tk()
root.withdraw() # GUIウィンドウを表示しないようにする
file_path = filedialog.askopenfilename(title="画像ファイルを選択してください", filetypes=[("JPEG files", "*.jpg"), ("PNG files", "*.png"), ("All files", "*.*")])
if not file_path:
print("ファイルが選択されませんでした")
exit()
image_tensor = load_image(file_path, transform)
# 画像を分類し、結果を表示
top_classes = classify_image(model, image_tensor)
for i in top_classes:
print(i)
セッション5: データ分析とデータマネジメント
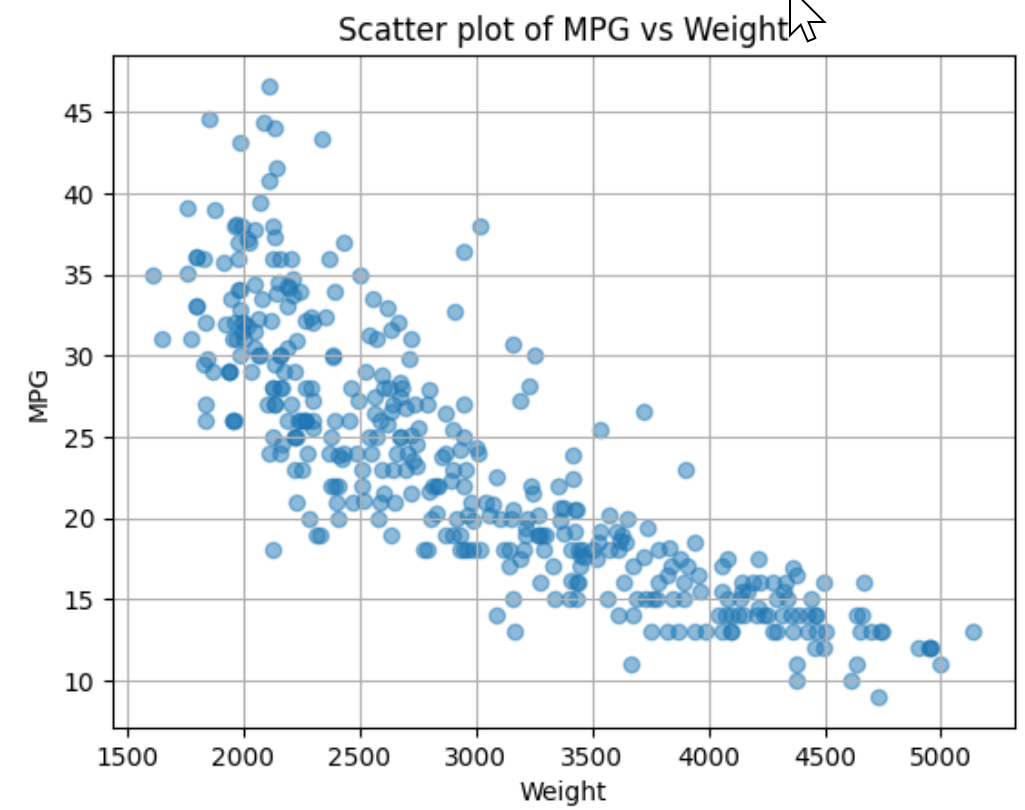
データの管理と処理の基礎について説明する。今回は、PythonのPandasデータフレームを利用する。機械学習は、訓練データを使ってコンピュータに知的能力を獲得させる技術である。機械学習として、主に、回帰や分類がある。線形回帰は、データに最適にフィットする線(もしくは超平面)を見つける技術の一つである。外れ値は、データセット内で、他のデータと顕著に異なるデータのことを言う。外れ値の適切な取り扱いは、分析の精度や機械学習モデルの性能向上に寄与する。外れ値の検出には、zスコアなどの統計的手法などが用いられる。zスコアはデータが平均からどれだけ離れているかを示したものである。欠損値は、データが存在しないか、測定されていないことを示し、PythonではNaNを使って表す。機械学習を行う際、外れ値や欠損値の適切な処理が重要である。データは訓練データとテストデータに分割され、訓練データによる学習で得られた機械学習モデルは、テストデータで評価することが重要である。
【資料】
- PDFファイル: enshu2-6.pdf
- パワーポイントファイル(PDFファイルと同じ内容): enshu2-6.pptx
【演習で使用する Google Colaboratory のページ】
https://colab.research.google.com/drive/1outnxzsm81bwm2dxblrf2a51bhkelfnz?usp=sharing
セッション6: ミニプロジェクト
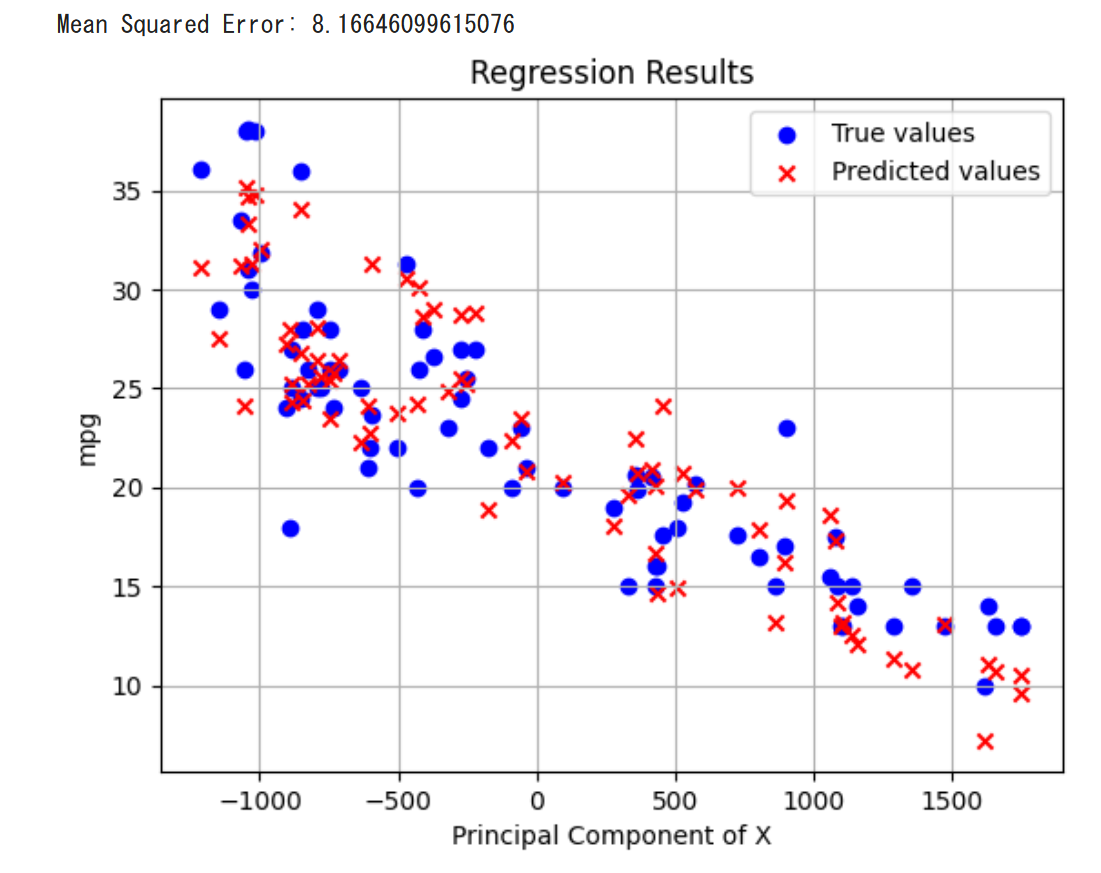
ミニプロジェクトでは、実践的問題解決能力の向上、プログラミング技術の深化、自主性と達成感の促進を目的とし、Pythonでのプログラム作成を通して学ぶ。自らのアイディアをプログラムとして実現し、挑戦とトライアンドエラーを粘り強く重ねながら、そのプロセスで実力を磨く。Trinket、ChatGPT 3.5、TalkAIを使用して、ミニプロジェクトを進める。プログラミングは創造的なプロセスであり、その魅力はアイディアを形にできることにある。演習を通じて、AIのサポートを受けながらプログラムの改善を各自行うことにも挑戦する。
【資料】
- PDFファイル: enshu2-7.pdf
- パワーポイントファイル(PDFファイルと同じ内容): enshu2-7.pptx
【演習で使用する外部ページ】
Trinket
TalkAI
Trinketのプログラム作成のプロンプト例
Trinketで動くProcessingを利用したアクションゲームのPython 2プログラムを作成してください。プログラムの先頭を「from processing import *」で開始してください。
https://trinket.io/python/ab4ac351b3 を使うなどで、ミニプロジェクトを楽しもう。