テクニカルレポート: 人工知能を用いた渋滞予測技術(国外での先行事例)の再現
時系列向き人工知能LSTM 法での渋滞予測、2016年10月公開技術、を再現
(URL: https://github.com/corenel/traffic-prediction)
先行研究で実施されたこと
学習(訓練)に使用するデータ
- 定点で観測した車両速度データ173日分(5分間隔での計測)
- カリフォルニア州 Pasadena市
米国政府機関が公開するオープンデータの1つ
名称: AMS Pasadena Main Data
ライセンス: クリエイティブコモンズ
URL: https://catalog.data.gov/dataset/ams-pasadena-main-data
学習(訓練)に使用するデータの項目
- 曜日番号: {0, 1, 2, 3, 4, 5, 6}
- 平日か休日か: {0, 1}
- 時: 0から23
- 分:{0, 5, 10, 15, 20, 25, 30, 35, 40, 45, 50, 55}
* 5分間隔の計測なので
- 車両速度:数値
何を予測するのか
未来の曜日番号、平日か休日か、時、分から、車両速度を予測
学習に使用するデータの分量
図1に示したデータ49824件
5分間隔の連続データであり、全部で173日分
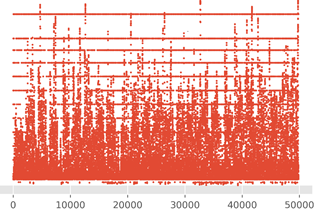
図1.学習に使用するデータのうち車両速度のプロット(横軸はデータ番号,縦軸は車両速度)
AIシステムを構築する基盤
- OS: Windows
- 言語: Python
- 数値演算ライブラリ: TensorFlow 1.5, CuDNN, NVidia CUDA
- NVIDIA ドライバのインストール
「別のページ」で説明している.
- NVIDIA CUDA ツールキットのインストール
- NVIDIA cuDNN のインストール(CUDA のバージョンに適合するもの)
- NVIDIA ドライバのインストール
- AI構築環境: Keras 2
* いずれもAIシステム構築のオープンな基盤で、事実上の標準(デファクトスタンダード)
渋滞予測実験(時系列向きニューラルネットワークを用いた先行技術による)
実験内容
過去173日分のデータを使い,直後約6日間の速度を予測する
4層のディープニューラルネットワーク(うち3層はLSTM,うち1層は総結合層).
学習に要する時間
パソコンで数時間から数十分

図2.学習中の様子(パソコン画面の一部)
予測に要する時間
1秒以内程度(手元のパソコンを使用)
予測結果
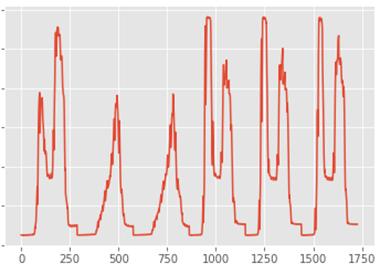
図3.予測結果(横軸はデータ番号,縦軸は予測された車両速度)
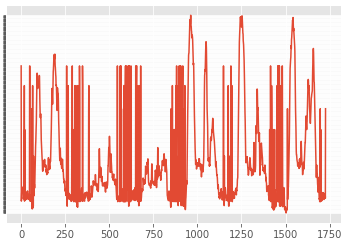
図4.実際の計測結果(横軸はデータ番号,縦軸は予測された車両速度)
図4には、図3の予測結果と同一期間の、実際の計測結果を示している。詳細分析は今後を待つが、
- 平日と休日の違い
- 曜日ごとの違い
が予測できているように判断している
実習手順
学習(訓練)の開始
- 学習(訓練)のデータのダウンロードのため、次のWebページを開く
- 「Clone or download」を展開し,
「Download ZIP」をクリック
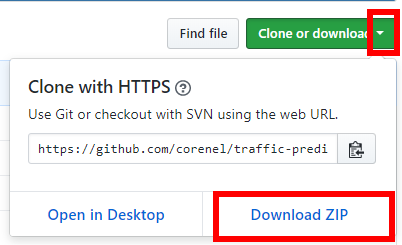
- .zip ファイルのダウンロードが始まるので確認する.

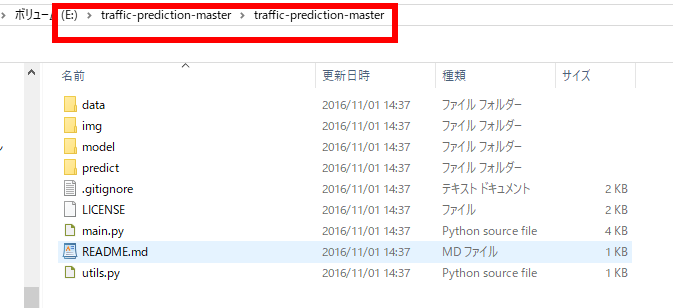
- ダウンロードした .zip ファイルを展開(解凍)する.分かりやすいディレクトリに置く.
- 展開(解凍)したディレクトリを確認しておく
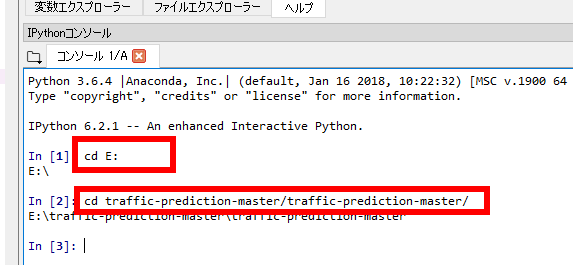
- cd コマンドで、先ほど<展開(解凍)したディレクトリ>に移動
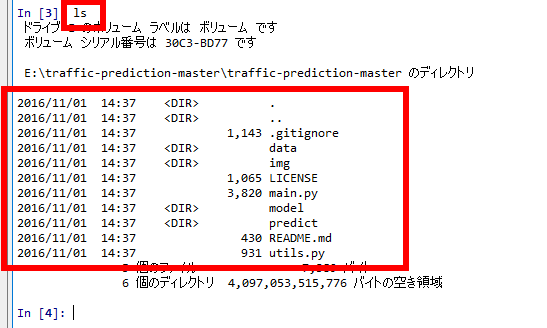
- 確認のため ls コマンドを実行.次のように表示されれば OK.
- Python プログラムの実行
- 次を実行
- いまダウンロードしたデータを Python で読み込む
以下、https://github.com/corenel/traffic-prediction で公開されているオープンソースを一部改変して使用
- データを読み込んでみる
あわせて、いくつかのパッケージも読み込む
from __future__ import print_function import numpy as np import pandas as pd %matplotlib inline import matplotlib.pyplot as plt import warnings warnings.filterwarnings('ignore') # Suppress Matplotlib warnings from keras.models import Sequential, model_from_json from keras.layers import Dense, LSTM, Activation, Dropout from keras.utils.vis_utils import plot_model from random import uniform from datetime import datetime from utils import data_loader, train_test_split import json # Fix AttributeError: 'module' object has no attribute 'control_flow_ops' import tensorflow from tensorflow.python.ops import control_flow_ops # tensorflow.python.control_flow_ops = control_flow_ops import keras.utils.vis_utils print('-- Loading Data --') test_size = 1728 X, y = data_loader('data/data_pems_16664.csv') x_train, y_train, x_test, y_test = train_test_split(X, y, test_size) print('Input shape:', X.shape) print('Output shape:', y.shape)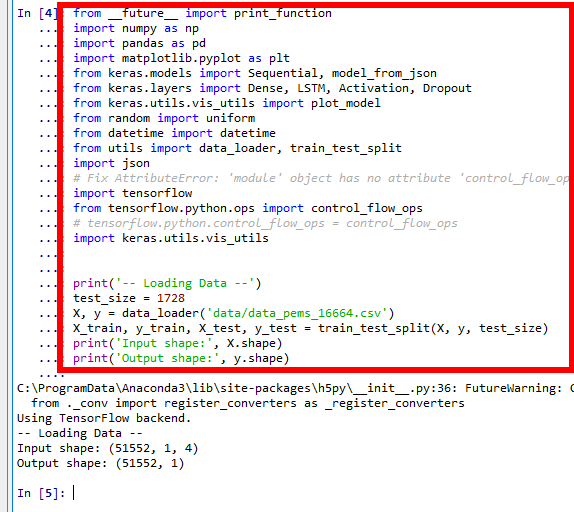
- モデルの中のニューロンの結合の強さ(重み)のデータファイルを読み込み、
その後、モデルのコンパイルを行う
print('-- Reading pre-trained model and weights --') with open('model/model_3_layer.json') as f: json_string = json.load(f) model = model_from_json(json_string) model.load_weights('model/weights_3_layer.h5') # print('-- Creating Model--') batch_size = 96 epochs = 100 out_neurons = 1 hidden_neurons = 500 hidden_inner_factor = uniform(0.1, 1.1) hidden_neurons_inner = int(hidden_inner_factor * hidden_neurons) dropout = uniform(0, 0.5) dropout_inner = uniform(0, 1) # model = Sequential() model.add(LSTM(output_dim=hidden_neurons, input_dim=x_train.shape[2], init='uniform', return_sequences=True, consume_less='mem')) model.add(Dropout(dropout)) model.add(LSTM(output_dim=hidden_neurons_inner, input_dim=hidden_neurons, return_sequences=True, consume_less='mem')) model.add(Dropout(dropout_inner)) model.add(LSTM(output_dim=hidden_neurons_inner, input_dim=hidden_neurons_inner, return_sequences=False, consume_less='mem')) model.add(Dropout(dropout_inner)) model.add(Activation('relu')) model.add(Dense(output_dim=out_neurons, input_dim=hidden_neurons_inner)) model.add(Activation('relu')) m.compile(loss="mse", optimizer="adam", metrics=['accuracy'])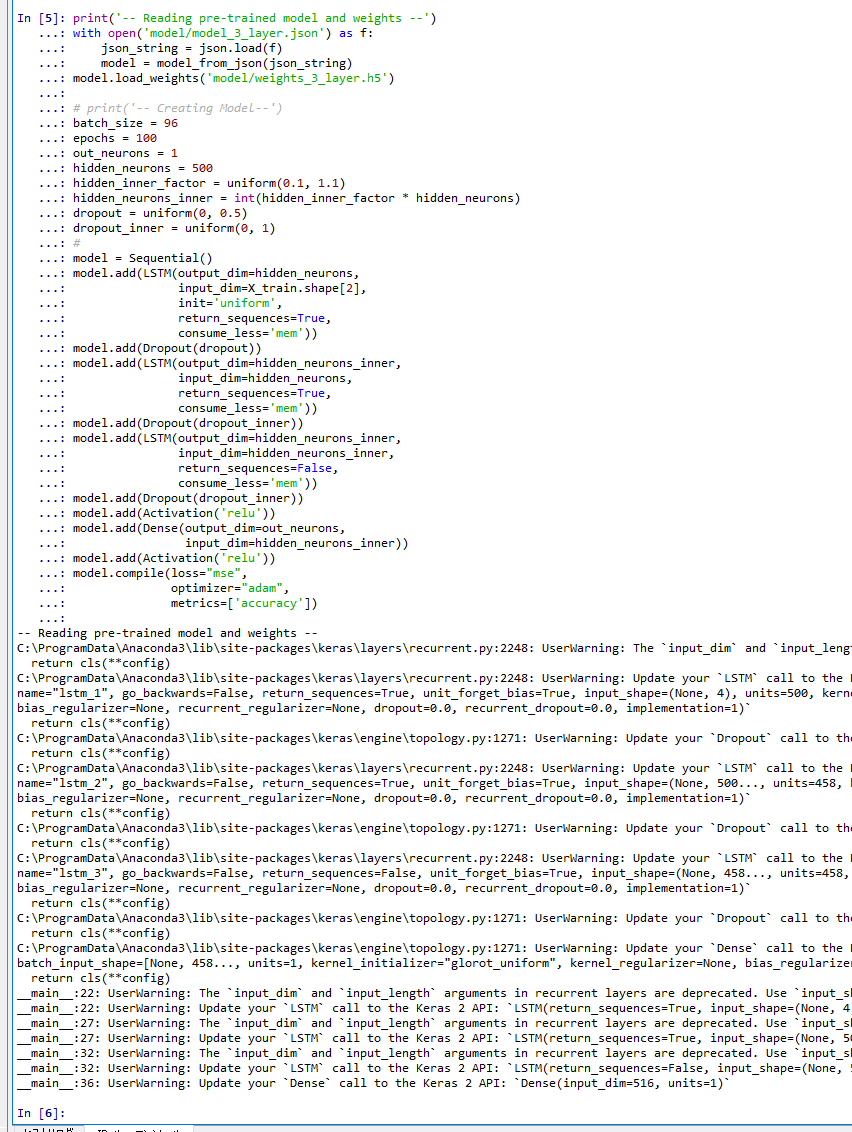
- 学習(訓練)
終わるのを待っていると数時間待ちになる可能性があるので、今日は、ここまで到達したら解散
Epoch 1/100 から始まって Epoch 100/100 までかかります
print('-- Training --') history = m.fit(x_train, y_train, verbose=1, batch_size=batch_size, nb_epoch=epochs, validation_split=0.1, shuffle=False)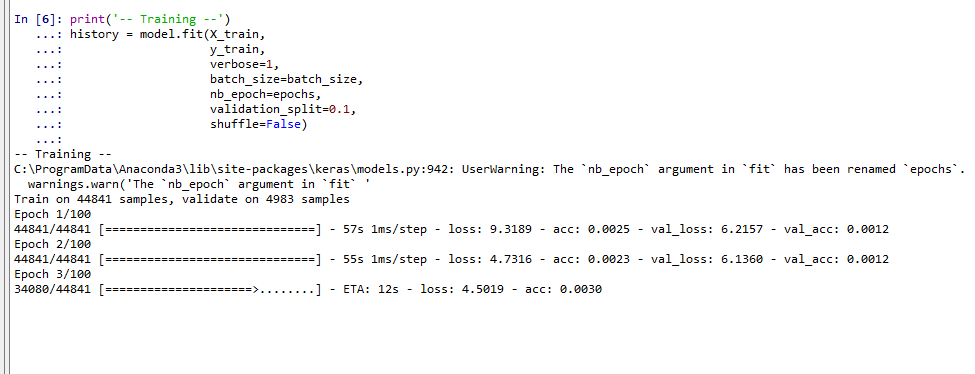
- 予測し、予測精度を見る
print('-- Evaluating --') eval_loss = model.evaluate(x_test, y_test, batch_size=batch_size, verbose=0) print('Evaluate loss: ', eval_loss[0]) print('Evaluate accuracy: ', eval_loss[1])
- 予測結果を y_pred に格納.表示.
print('-- Predicting --') y_pred = model.predict(x_test, batch_size=batch_size)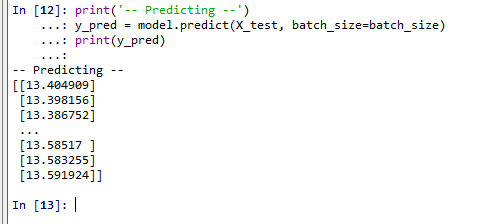
- 予測結果である y_pred のプロット
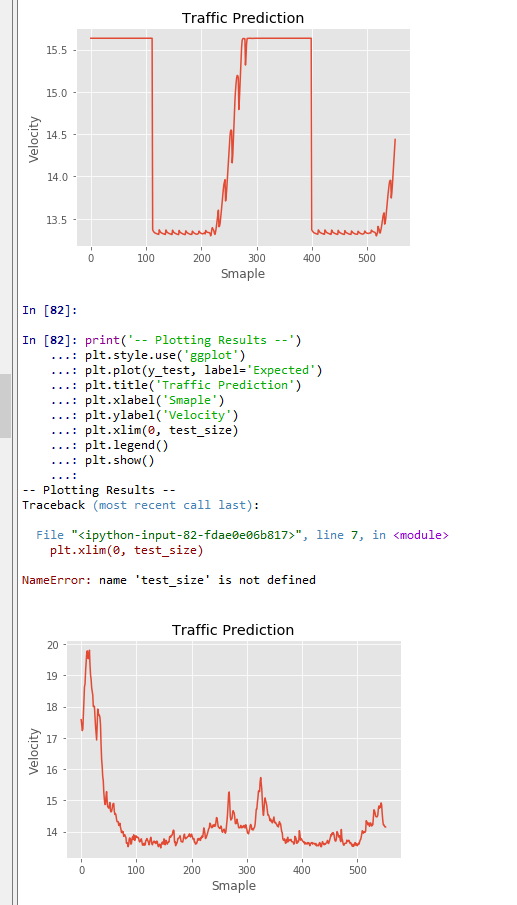
print('-- Plotting Results --') plt.style.use('ggplot') plt.plot(y_pred, label='Predicted') plt.title('Traffic Prediction') plt.xlabel('Smaple') plt.ylabel('Velocity') plt.xlim(0, test_size) plt.legend() plt.show()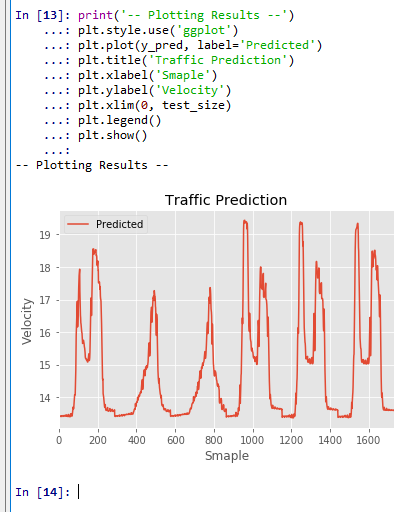
- 正解データのプロット
print('-- Plotting Results --') plt.style.use('ggplot') plt.plot(y_test, label='Expected') plt.title('Traffic Prediction') plt.xlabel('Smaple') plt.ylabel('Velocity') plt.xlim(0, test_size) plt.legend() plt.show()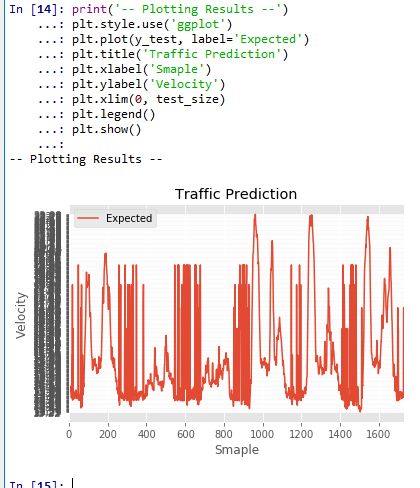
応用してみる
- データの準備
演習:
(1)各自データを準備しなさい
(2)各自、自分が良いしたデータについて、X.csv, y.csv の2つのファイルを作りなさい
X.csv は要因データ。y.csv は予測したいデータ
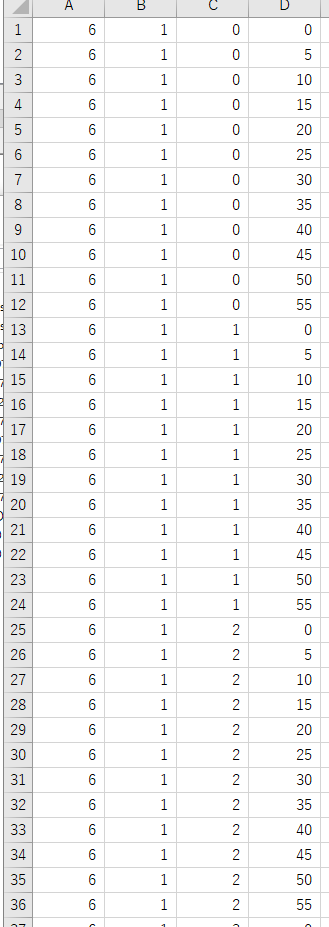
(3)下のように, 1列目XX,2列めXX,行数YYのような資料を作る
ファイル名 X.csv
- 1列目: 曜日番号 {0, 1, 2, 3, 4, 5, 6}
- 2列目: 平日か休日か
- 3列目: 時 0から23
- 4列目: 分 {0, 5, 10, 15, 20, 25, 30, 35, 40, 45, 50, 55}
- 全体の行数: 51552行
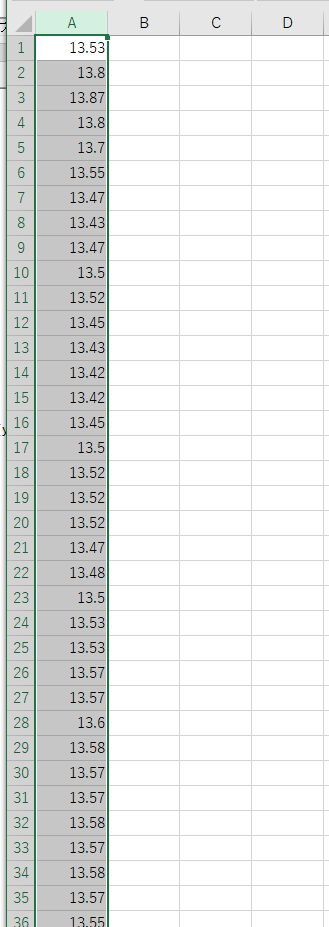
ファイル名 y.csv
- 1列目: 速度
- 全体の行数: 51552行
- いくつかのパッケージを読み込む
from __future__ import print_function import numpy as np import pandas as pd %matplotlib inline import matplotlib.pyplot as plt import warnings warnings.filterwarnings('ignore') # Suppress Matplotlib warnings from keras.models import Sequential, model_from_json from keras.layers import Dense, LSTM, Activation, Dropout from keras.utils.vis_utils import plot_model from random import uniform from datetime import datetime import json # Fix AttributeError: 'module' object has no attribute 'control_flow_ops' import tensorflow from tensorflow.python.ops import control_flow_ops # tensorflow.python.control_flow_ops = control_flow_ops import keras.utils.vis_utils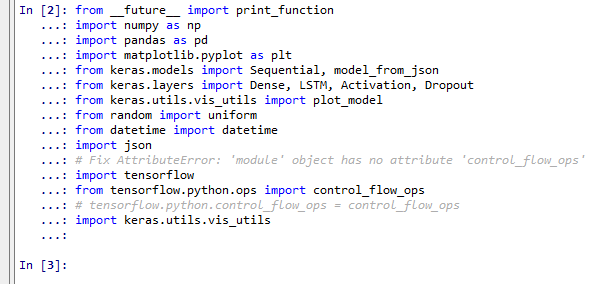
- pwd で、カレントディレクトリを確認

- cd で、X.csv, y.csv が置いてあるディレクトリに移動
- ls で、X.csv, y.csv があることを確認
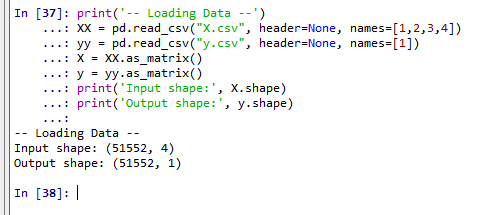
- データ読みこみ
print('-- Loading Data --') XX = pd.read_csv("X.csv", header=None, names=[1,2,3,4]) yy = pd.read_csv("y.csv", header=None, names=[1]) X = XX.as_matrix() y = yy.as_matrix() print('Input shape:', X.shape) print('Output shape:', y.shape)表示される列数と行数を確認
- 個数を確認したら、訓練用データの個数と、検査用データの個数を決める
ここでは、
- 全部で 51552 個
- 訓練用: 51000 個
- 検査用: 552 個
- 訓練用データと、検査用データに分ける
x_train = X[0: 51000,:] y_train = y[0: 51000] x_test = X[51000: 51000 + 552,:] y_test = y[51000: 51000 + 552] x_train = x_train[:,np.newaxis,:] x_test = x_test[:,np.newaxis,:] - モデルの中のニューロンの結合の強さ(重み)のデータファイルを読み込み、
その後、モデルのコンパイルを行う
# print('-- Creating Model--') batch_size = 96 epochs = 100 out_neurons = 1 hidden_neurons = 500 hidden_inner_factor = uniform(0.1, 1.1) hidden_neurons_inner = int(hidden_inner_factor * hidden_neurons) dropout = uniform(0, 0.5) dropout_inner = uniform(0, 1) # model = Sequential() model.add(LSTM(output_dim=hidden_neurons, input_dim=x_train.shape[2], init='uniform', return_sequences=True, consume_less='mem')) model.add(Dropout(dropout)) model.add(LSTM(output_dim=hidden_neurons_inner, input_dim=hidden_neurons, return_sequences=True, consume_less='mem')) model.add(Dropout(dropout_inner)) model.add(LSTM(output_dim=hidden_neurons_inner, input_dim=hidden_neurons_inner, return_sequences=False, consume_less='mem')) model.add(Dropout(dropout_inner)) model.add(Activation('relu')) model.add(Dense(output_dim=out_neurons, input_dim=hidden_neurons_inner)) model.add(Activation('relu')) m.compile(loss="mse", optimizer="adam", metrics=['accuracy']) - 学習(訓練)
終わるのを待っていると数時間待ちになる可能性があるので、今日は、ここまで到達したら解散
Epoch 1/100 から始まって Epoch 100/100 までかかります
print('-- Training --') history = m.fit(x_train, y_train, verbose=1, batch_size=batch_size, nb_epoch=epochs, validation_split=0.1, shuffle=False)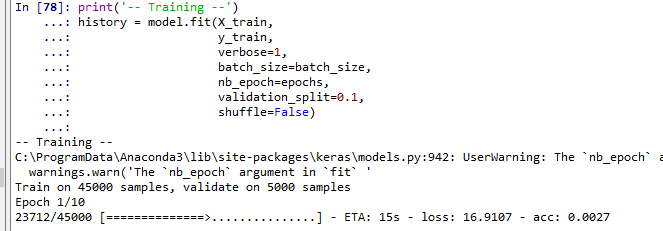
- 予測し、予測精度を見る
print('-- Evaluating --') eval_loss = model.evaluate(x_test, y_test, batch_size=batch_size, verbose=0) print('Evaluate loss: ', eval_loss[0]) print('Evaluate accuracy: ', eval_loss[1]) - 予測結果を y_pred に格納.表示.
print('-- Predicting --') y_pred = model.predict(x_test, batch_size=batch_size) - 予測結果である y_pred のプロット
print('-- Plotting Results --') plt.style.use('ggplot') plt.plot(y_pred, label='Predicted') plt.title('Traffic Prediction') plt.xlabel('Smaple') plt.ylabel('Velocity') plt.legend() plt.show() - 正解データのプロット
print('-- Plotting Results --') plt.style.use('ggplot') plt.plot(y_test, label='Expected') plt.title('Traffic Prediction') plt.xlabel('Smaple') plt.ylabel('Velocity') plt.legend() plt.show()精度が良くなくても気にしないでください (プログラムのデバッグを将来行う可能性がある)