リレーショナルデータベースとPythonの連携
【概要】
リレーショナルデータベースとPythonの連携について、コード例とともに説明する。為替データ、時系列データ、地理空間データの分析手法を実装例とともに解説する。これにより、データの取得から分析までを自動化する技術を体験できる。
【前提知識】
Pythonの基本文法(変数、関数、クラス)、SQLの基本操作(SELECT、INSERT、CREATE TABLE)を理解していることを前提とする。
【目次】
【関連する外部ページ】
- Python公式サイト:https://www.python.org/
【サイト内の関連ページ】
- リレーショナルデータベースの読み物・用語集
- Python詳細ガイド:別ページ »
1. 基本概念
リレーショナルデータベース(以下、RDB)は、データを表形式で管理し、表同士の関係を定義することでデータ操作を行うデータベースシステムである。RDBでは、SQL(Structured Query Language)を用いてデータの検索、挿入、更新、削除を行う。本文書では、RDBの基本構造を確認した上で、Pythonと連携した応用例を扱う。
2. データベースの構造と設計
RDBは、行(レコード)と列(フィールド)から構成されるテーブルを基本単位とする。各テーブルは、列ごとにデータ型と制約を定義し、データの整合性を保つ。
テーブル定義の例
テーブル定義SQLの実装例を以下に示す。
CREATE TABLE product (
id INTEGER PRIMARY KEY,
product_name TEXT NOT NULL,
type TEXT,
cost REAL,
created_at DATETIME
);データ型
SQLiteで使用する主要なデータ型は以下のとおりである。
- INTEGER(整数値を格納)
- REAL(浮動小数点数を格納)
- TEXT(文字列を格納)
- DATETIME(日時を格納する宣言。SQLiteでは型アフィニティ(列に推奨される型)はNUMERICとなり、実際の値はTEXTまたは数値として格納される)
制約
データの整合性を保つための制約は以下のとおりである。
- NOT NULL(NULL値を許容しない)
- UNIQUE(重複を許容しない一意性制約)
- PRIMARY KEY(主キー。レコードを一意に識別する)
3. 開発環境の構築
Windows上でPythonと必要なライブラリをインストールする手順を説明する。
Python 3.12 のインストール
Pythonのインストールを行い、Pythonのプログラムを実行する環境を整える。扱う環境は、Windows搭載パソコンである。金子研究室では、Python 3.12.10を推奨する。
[Windows での Python 3.12 のインストール手順を見るには、ここをクリック]
Windows での Python 3.12 のインストール
以下のいずれかの方法でPython 3.12をインストールする。Pythonがインストール済みの場合、この手順は不要である。
方法 1:winget によるインストール
【インストールコマンドの実行方法】
管理者権限でコマンドプロンプトを起動する(手順:Windowsキーまたはスタートメニュー → cmd と入力 → 右クリック → 「管理者として実行」)。そして、コマンド全体をコマンドプロンプトにコピー&ペーストする。
--scope machine を指定することで、システム全体(全ユーザー向け)にインストールされる。このオプションの実行には管理者権限が必要である。インストール完了後、コマンドプロンプトを再起動するとPATHが反映される。
REM Python 3.12 をシステム領域にインストール
winget install --id Python.Python.3.12 -e --scope machine --silent --accept-source-agreements --accept-package-agreements --override "/quiet InstallAllUsers=1 PrependPath=1 Include_test=0 Include_pip=1 Include_launcher=1 InstallLauncherAllUsers=1 TargetDir=\"C:\Program Files\Python312\""
REM Python と Scripts を PATH 先頭に追加
powershell -NoProfile -Command "$p='C:\Program Files\Python312'; $s=\"$p\Scripts\"; $c=[Environment]::GetEnvironmentVariable('Path','Machine'); if((Test-Path $p) -and (';'+$c+';' -notlike \"*;$p;*\") -and (';'+$c+';' -notlike \"*;$s;*\")){[Environment]::SetEnvironmentVariable('Path',\"$p;$s;$c\",'Machine')}"
方法 2:インストーラーによるインストール
- Python公式サイト(https://www.python.org/downloads/)にアクセスし、「Download Python 3.x.x」ボタンからWindows用インストーラーをダウンロードする。
- ダウンロードしたインストーラーを実行する。
- 初期画面の下部に表示される「Add python.exe to PATH」にチェックを入れてから「Customize installation」を選択する。このチェックを入れ忘れると、コマンドプロンプトから
pythonコマンドを実行できない。 - 「Install Python 3.xx for all users」にチェックを入れ、「Install」をクリックする。
インストールの確認
コマンドプロンプトで以下を実行する。
python --versionバージョン番号(例:Python 3.12.x)が表示されればインストール成功である。「'python' は、内部コマンドまたは外部コマンドとして認識されていません。」と表示される場合は、インストールが正常に完了していない。
Python の開発環境 Visual Studio Code のインストールと Python 用の設定
Python の開発環境Visual Studio Code(プログラムを編集するソフトウェア。以下、VS Code)を整える。
[Windows での Visual Studio Code のインストールと Python 用の設定手順を見るには、ここをクリック]
Windows での Visual Studio Code のインストールと Python 用の設定手順
1. VS Code と拡張機能のインストール
以下のコマンドにより,既存の VS Code を削除し,全ユーザー共有の設定で再インストールしたうえで,拡張機能(VS Code に機能を追加するソフトウェア)をまとめて導入する.
【インストールコマンドの実行方法】
管理者権限でコマンドプロンプトを起動する(手順:Windows キーまたはスタートメニュー → cmd と入力 → 右クリック → 「管理者として実行」)。そして,コマンド全体をコマンドプロンプトにコピー&ペーストする。
インストールコマンド
REM ============================================================
REM Microsoft Visual Studio Code
REM ============================================================
winget uninstall -e --id Microsoft.VisualStudioCode --silent --disable-interactivity --accept-source-agreements
rmdir /s /q C:\ProgramData\vscode-extensions 2>nul
rmdir /s /q "%APPDATA%\Code" 2>nul
rmdir /s /q "%USERPROFILE%\.vscode" 2>nul
rmdir /s /q "%LOCALAPPDATA%\Microsoft\vscode-update" 2>nul
REM VS Code をシステム領域に新規インストール
winget install --scope machine --id Microsoft.VisualStudioCode -e --silent --accept-source-agreements --accept-package-agreements
REM 全ユーザー共有の拡張機能フォルダ
mkdir C:\ProgramData\vscode-extensions 2>nul
icacls "C:\ProgramData\vscode-extensions" /grant "Everyone:(OI)(CI)M" /T
REM スタートメニューのショートカットを --extensions-dir 付きで再作成
rmdir /s /q "C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code" 2>nul
del "C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code.lnk" 2>nul
powershell -NoProfile -Command "$s=New-Object -ComObject WScript.Shell; $lnk=$s.CreateShortcut('C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code.lnk'); $lnk.TargetPath='C:\Program Files\Microsoft VS Code\Code.exe'; $lnk.Arguments='--extensions-dir \"C:\ProgramData\vscode-extensions\"'; $lnk.Save()"
REM ショートカットの検証
powershell -NoProfile -Command "$s=New-Object -ComObject WScript.Shell; $lnk=$s.CreateShortcut('C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code.lnk'); Write-Host 'TargetPath:' $lnk.TargetPath; Write-Host 'Arguments:' $lnk.Arguments"
REM ファイル / フォルダ右クリックの「Code で開く」を登録
reg add "HKLM\SOFTWARE\Classes\*\shell\VSCode\command" /ve /d "\"C:\Program Files\Microsoft VS Code\Code.exe\" --extensions-dir \"C:\ProgramData\vscode-extensions\" \"%1\"" /f
reg add "HKLM\SOFTWARE\Classes\Directory\shell\VSCode\command" /ve /d "\"C:\Program Files\Microsoft VS Code\Code.exe\" --extensions-dir \"C:\ProgramData\vscode-extensions\" \"%1\"" /f
reg add "HKLM\SOFTWARE\Classes\Directory\Background\shell\VSCode\command" /ve /d "\"C:\Program Files\Microsoft VS Code\Code.exe\" --extensions-dir \"C:\ProgramData\vscode-extensions\" \"%V\"" /f
REM --extensions-dir 付きで起動する code.cmd ラッパを作成
REM (%* を echo で書くと対話的 cmd で失われるため、PowerShell で [char]37+'*' を書き出す)
powershell -NoProfile -Command "$pct=[char]37; $q=[char]34; $c='@echo off'+[char]13+[char]10+$q+'C:\Program Files\Microsoft VS Code\bin\code.cmd'+$q+' --extensions-dir '+$q+'C:\ProgramData\vscode-extensions'+$q+' '+$pct+'*'+[char]13+[char]10; [IO.File]::WriteAllText('C:\ProgramData\vscode-extensions\vscode.cmd',$c,[Text.Encoding]::ASCII)"
REM 拡張機能のインストール
set "CODE=C:\Program Files\Microsoft VS Code\bin\code.cmd"
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --uninstall-extension GitHub.copilot
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --uninstall-extension GitHub.copilot-chat
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension ms-python.python
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension ms-python.vscode-pylance
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension ms-python.debugpy
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension MS-CEINTL.vscode-language-pack-ja
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension saoudrizwan.claude-dev
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension rust-lang.rust-analyzer
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension tamasfe.even-better-toml
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension anthropic.claude-code
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension almenon.arepl
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --list-extensions --show-versions
echo === セットアップ完了 ===
2. Python インタプリタの選択
同一マシンに複数の Python がインストールされている場合,VS Code で使用する Python 本体(インタプリタ:Python プログラムを解釈・実行するソフトウェア)を選択する必要がある.
- コマンドパレット(コマンド名で機能を呼び出す VS Code の入力欄)を開く(
Ctrl+Shift+P) Python: Select Interpreterと入力する
- 表示される一覧から,使用する Python(例:
C:\Program Files\Python312\python.exe)を選択する.
Python プログラム実行手順
[Windows での Python プログラム実行手順を見るには、ここをクリック]
Windows での Python 実行手順(Visual Studio Codeを使用)
プログラムファイルの作成と保存
- 左サイドバーの「エクスプローラー」アイコン(
Ctrl+Shift+E)をクリックする
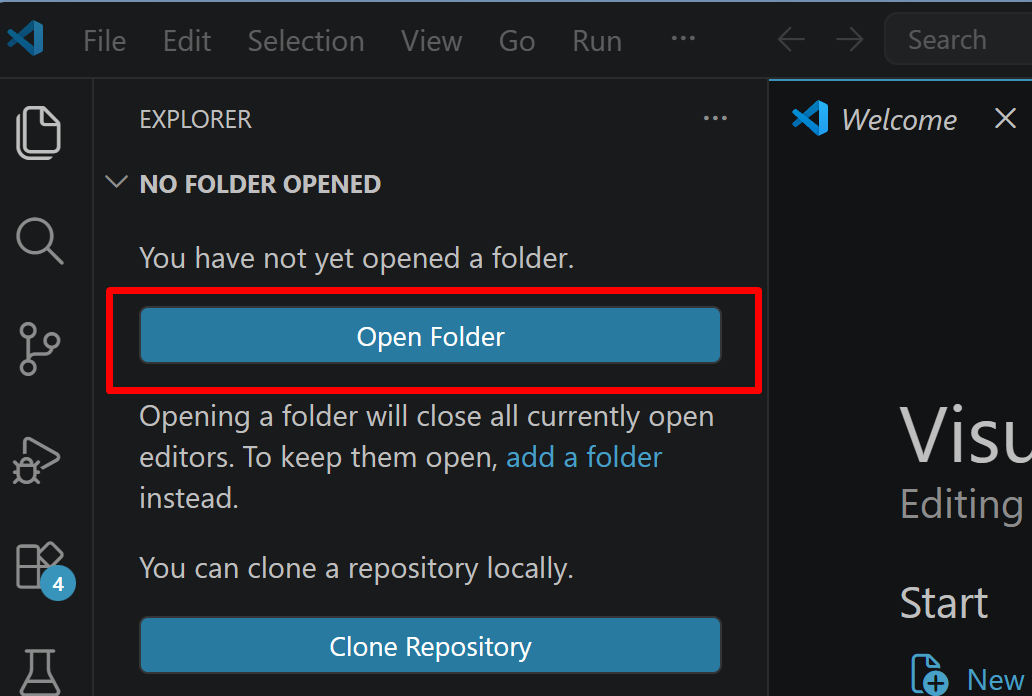
- 「NO FOLDER OPENED」(作業対象フォルダが未選択の状態)と表示される場合は,「Open Folder」をクリックし,プログラムを保存するフォルダを選択する
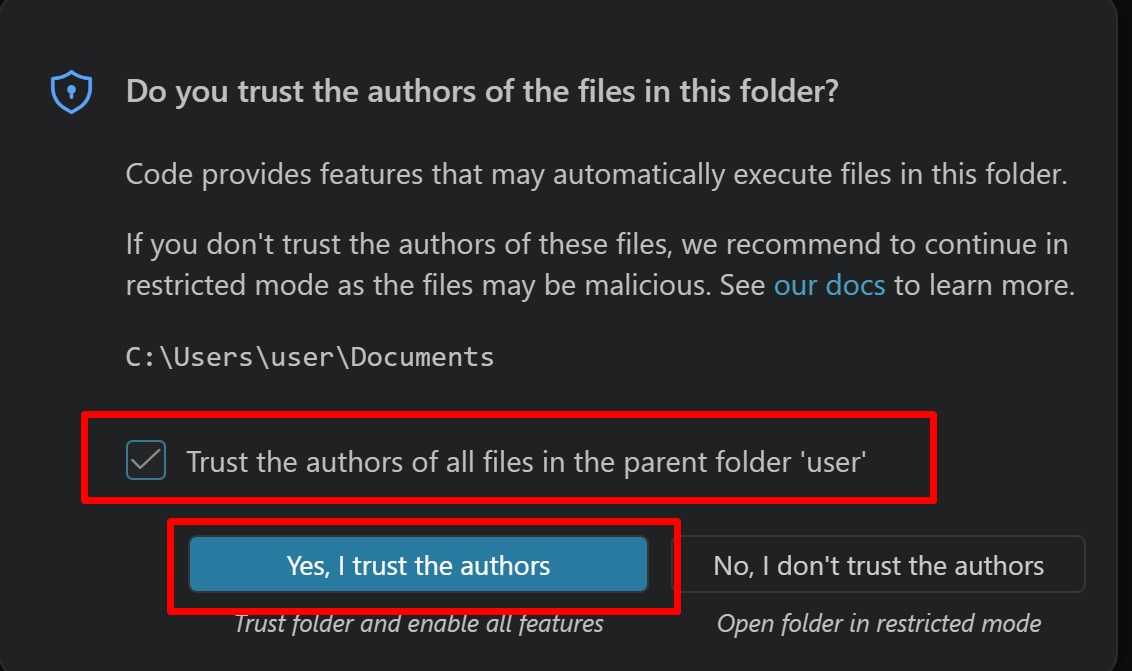
続いて「フォルダを信用するか」を確認する画面(フォルダ内のコードを実行してよいか確認する VS Code の仕組み)が表示されるので,チェックして Yes を選択する
- フォルダ名の右側に表示される「新しいファイル」アイコンをクリックする
- ファイル名(例:
aitask.py.ファイル名は何でも良い)を入力しEnterを押す.拡張子は.py(Python ファイルを示す拡張子)とする
- 実行したいコードを選択し,
Ctrl+Cでコピーする.VS Code のエディタ領域にCtrl+Vで貼り付ける Ctrl+Sで保存する
プログラムの実行
- エディタ右上の三角形「▷」アイコン(Run Python File:現在開いている Python ファイルを実行するボタン)をクリックする.または,エディタ上で右クリックし「ターミナルで Python ファイルを実行」を選択する
- VS Code 下部のターミナル(コマンドの入出力を表示する画面)に,実行結果(
print関数の出力等)が表示される
- tkinter(Python 標準の GUI ライブラリ)のファイル選択ダイアログを使うプログラムを実行した場合は,ダイアログが開くので対象画像を選択する
- VS Code 下部のターミナルで実行結果を確認する.OpenCV ウィンドウ(OpenCV が画像を表示するために開く専用ウィンドウ)が開いた場合はそちらも確認する.OpenCV ウィンドウは,マウスクリックでウィンドウをアクティブ(操作対象の状態)にしてからキーを押すと終了する


必要なライブラリのインストール
管理者権限でコマンドプロンプトを起動する
(手順:Windowsキーまたはスタートメニュー → cmd と入力 → 右クリック → 「管理者として実行」)。
起動したコマンドプロンプトで以下を実行する。
pip install -U --no-user yfinance pandas numpy scikit-learn statsmodels geopandas matplotlib japanize-matplotlib requests4. データベース操作の基本
以下は、データベース操作を管理するクラスの実装例である。このクラスは、データベースの初期化、データの挿入、クエリの実行を処理する。クラス化により、接続管理を一箇所にまとめ、コードの再利用性を高める。
import sqlite3
import pandas as pd
import yfinance as yf
from datetime import datetime, timedelta
class DatabaseManager:
def __init__(self, db_path):
"""データベース接続を初期化する"""
self.conn = sqlite3.connect(db_path)
self.cursor = self.conn.cursor()
self.initialize_database()
def initialize_database(self):
"""テーブルを作成し、サンプルデータを取得して格納する"""
# 株価テーブルの作成
self.cursor.execute("""
CREATE TABLE IF NOT EXISTS stock_prices (
date TEXT,
ticker TEXT,
open REAL,
high REAL,
low REAL,
close REAL,
volume INTEGER,
PRIMARY KEY (date, ticker)
)
""")
# 日経平均とTOPIX連動ETFのデータを取得
tickers = ['^N225', '1306.T']
end_date = datetime.now()
start_date = end_date - timedelta(days=30)
for ticker in tickers:
# multi_level_index=Falseで単一レベルの列名を取得
data = yf.download(ticker, start=start_date, end=end_date, multi_level_index=False)
data['ticker'] = ticker
data.reset_index(inplace=True)
# データの挿入
for _, row in data.iterrows():
self.insert_data('stock_prices', [
row['Date'].strftime('%Y-%m-%d'),
row['ticker'],
row['Open'],
row['High'],
row['Low'],
row['Close'],
row['Volume']
])
def execute_query(self, query, params=None):
"""SQLクエリを実行し、結果をpandasのDataFrameとして返す"""
if params:
return pd.read_sql_query(query, self.conn, params=params)
return pd.read_sql_query(query, self.conn)
def insert_data(self, table, data):
"""指定したテーブルにデータを挿入する"""
placeholders = ','.join(['?' for _ in data])
query = f"INSERT OR REPLACE INTO {table} VALUES ({placeholders})"
self.cursor.execute(query, data)
self.conn.commit()
def get_latest_prices(self):
"""最新の価格データを取得する"""
query = """
SELECT date, ticker, close
FROM stock_prices
WHERE date = (SELECT MAX(date) FROM stock_prices)
"""
return self.execute_query(query)
def close(self):
"""データベース接続を閉じる"""
self.conn.close()実行手順
上記のクラス定義と以下の実行コードを同じPythonファイル(例:db_manager.py)に保存し、実行する。
# データベースの作成と初期化
db = DatabaseManager('stocks.db')
# 最新価格の取得
latest = db.get_latest_prices()
print(latest)
# 接続を閉じる
db.close()実行結果の確認
正常に実行されると、以下のような出力が表示される。日付と価格は実行時点のデータにより異なる。
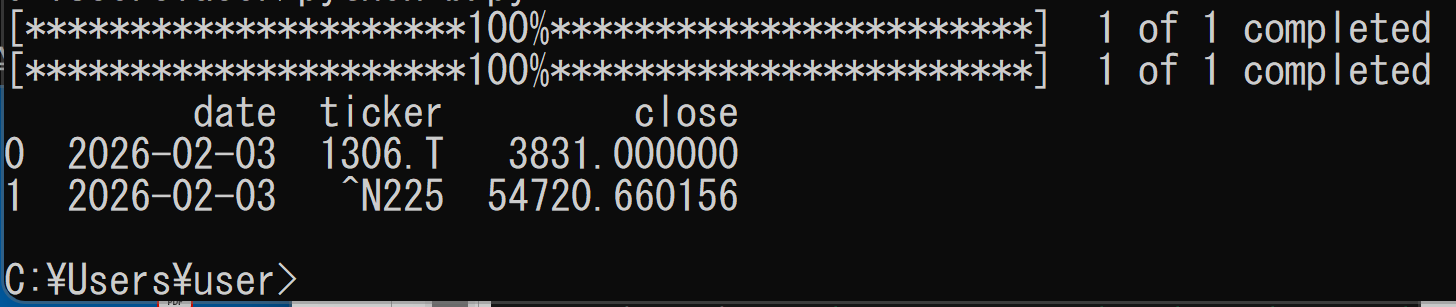
実行後、プログラムと同じディレクトリに stocks.db ファイルが作成される。このファイルがSQLiteデータベースである。
5. 応用例
RDBとPythonを組み合わせた3つの応用例を扱う。為替データの管理、時系列データの分析、地理空間データの活用を順に解説する。
1. 為替データの管理と分析
為替データを管理するためのテーブル定義を以下に示す。このテーブルは、複数の通貨の為替レートを時系列で記録する。
CREATE TABLE quote (
seq INTEGER PRIMARY KEY NOT NULL,
at DATETIME,
USD REAL,
JPY REAL,
EUR REAL
);以下は、Yahoo Finance(yfinanceライブラリ経由)から為替データを取得し、データベースに保存する実装例である。
import pandas as pd
import sqlite3
from datetime import datetime, timedelta
import yfinance as yf
def analyze_exchange_rates():
# 為替データのダウンロード(Yahoo Financeから取得)
currency_pairs = ['USDJPY=X', 'EURJPY=X']
end_date = datetime.now()
start_date = end_date - timedelta(days=30)
# データ取得と整形
dfs = []
for pair in currency_pairs:
# multi_level_index=Falseで単一レベルの列名を取得
df = yf.download(pair, start=start_date, end=end_date, multi_level_index=False)
# 通貨ペア名から通貨コードを抽出(USDJPY=X -> USD, EURJPY=X -> EUR)
currency_code = pair.replace('JPY=X', '')
df = df['Close'].rename(currency_code)
dfs.append(df)
# データフレームの結合
rates_df = pd.concat(dfs, axis=1)
rates_df['JPY'] = 1 # 基準通貨
# データベースへの保存
conn = sqlite3.connect('forex.db')
rates_df.to_sql('quote', conn, if_exists='replace')
# 分析の実行
stats = rates_df.describe()
changes = rates_df.pct_change().mean()
conn.close()
return stats, changesこのプログラムは、Yahoo Financeから為替データを取得し、pandasによる統計分析を実行する。30日間の時系列データを取得し、基本統計量と日次変動率を算出する。データはSQLiteデータベースに保存する。
【注意】Yahoo Financeからのデータ取得にはインターネット接続が必要であり、取得できるデータや頻度に制限がある場合がある。
実行手順
上記の関数定義と以下の実行コードを同じPythonファイル(例:forex_analysis.py)に保存し、実行する。
stats, changes = analyze_exchange_rates()
print("基本統計量:")
print(stats)
print("\n日次変動率:")
print(changes)実行結果の確認
正常に実行されると、以下のような出力が表示される。数値は実行時点のデータにより異なる。
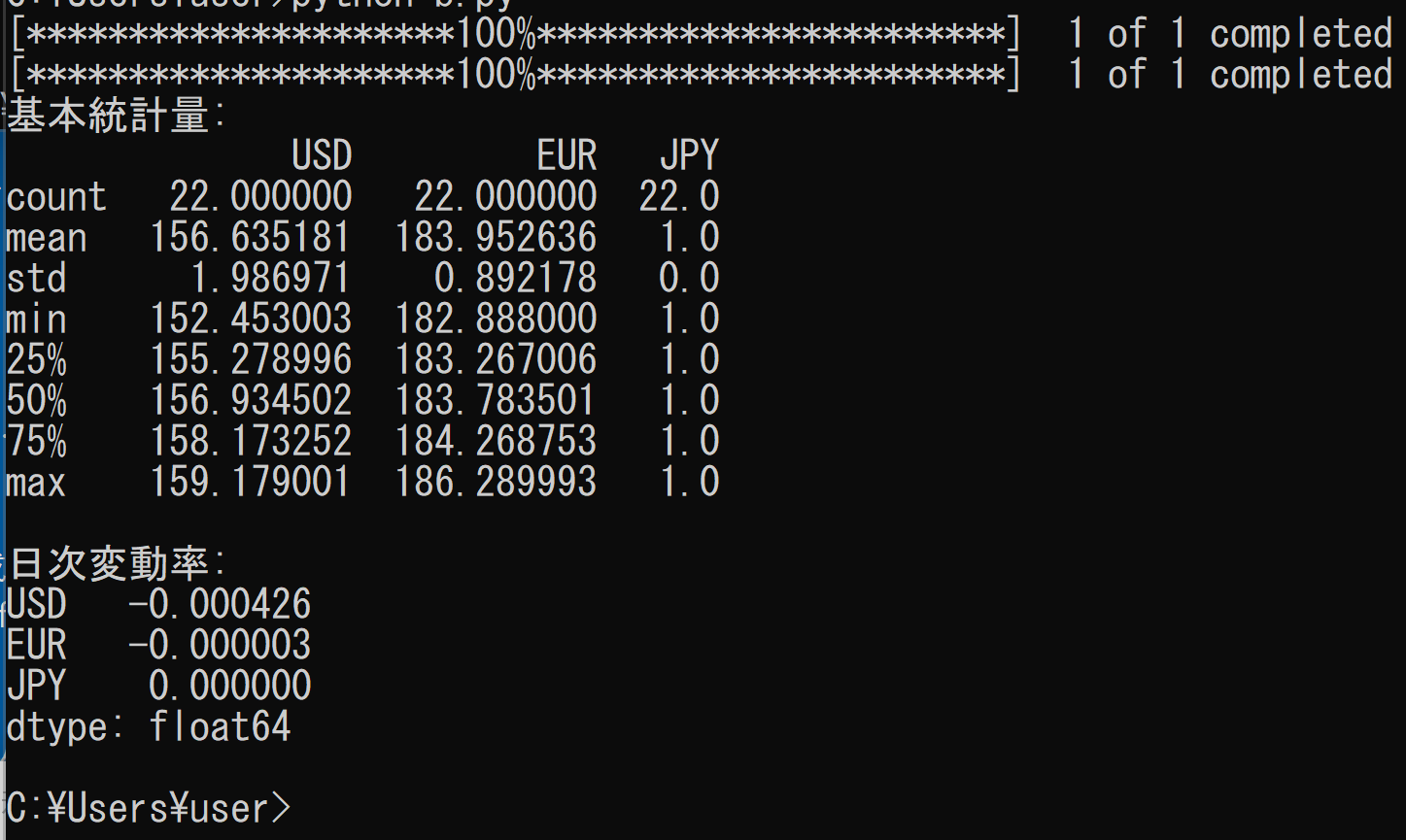
実行後、プログラムと同じディレクトリに forex.db ファイルが作成される。
2. 時系列データの分析と予測
以下は、株価データを使用した時系列分析と異常値検出の実装例である。ARIMA(自己回帰和分移動平均)モデルによる予測と、Isolation Forest(データの分布から外れた点を検出する機械学習手法)による異常値検出を組み合わせる。
import pandas as pd
import numpy as np
from sklearn.ensemble import IsolationForest
from statsmodels.tsa.arima.model import ARIMA
import yfinance as yf
import matplotlib.pyplot as plt
import japanize_matplotlib
def analyze_timeseries(ticker='7203.T', period='1y', forecast_periods=10):
"""
株価データを使用した時系列分析
ticker: 株式コード(デフォルトはトヨタ自動車)
period: 取得期間
forecast_periods: 予測期間
"""
# Yahoo Financeからデータ取得
stock = yf.Ticker(ticker)
data = stock.history(period=period)
# 終値を使用
close_prices = data['Close'].values
# ARIMAモデルによる予測
model = ARIMA(close_prices, order=(1, 1, 1))
model_fit = model.fit()
forecast = model_fit.forecast(steps=forecast_periods)
# 異常値検出(contaminationは異常値とみなすデータの割合)
iso_forest = IsolationForest(contamination=0.1, random_state=42)
anomalies = iso_forest.fit_predict(close_prices.reshape(-1, 1))
# 結果の可視化
plt.figure(figsize=(12, 6))
plt.plot(close_prices, label='実績値')
plt.plot(range(len(close_prices), len(close_prices) + forecast_periods),
forecast, label='予測値', linestyle='--')
plt.scatter(np.where(anomalies == -1)[0],
close_prices[anomalies == -1],
color='red', label='異常値')
plt.title(f'{ticker}の株価分析')
plt.legend()
results = {
'forecast': forecast,
'anomalies': close_prices[anomalies == -1],
'anomaly_dates': data.index[anomalies == -1]
}
return resultsこのプログラムは、Yahoo Financeから取得した株価データに対し、ARIMAモデルによる時系列予測と、Isolation Forestによる異常値検出を実行する。予測結果と異常値を可視化する。
実行手順
上記の関数定義と以下の実行コードを同じPythonファイル(例:timeseries_analysis.py)に保存し、実行する。
results = analyze_timeseries('7203.T', '1y', 10)
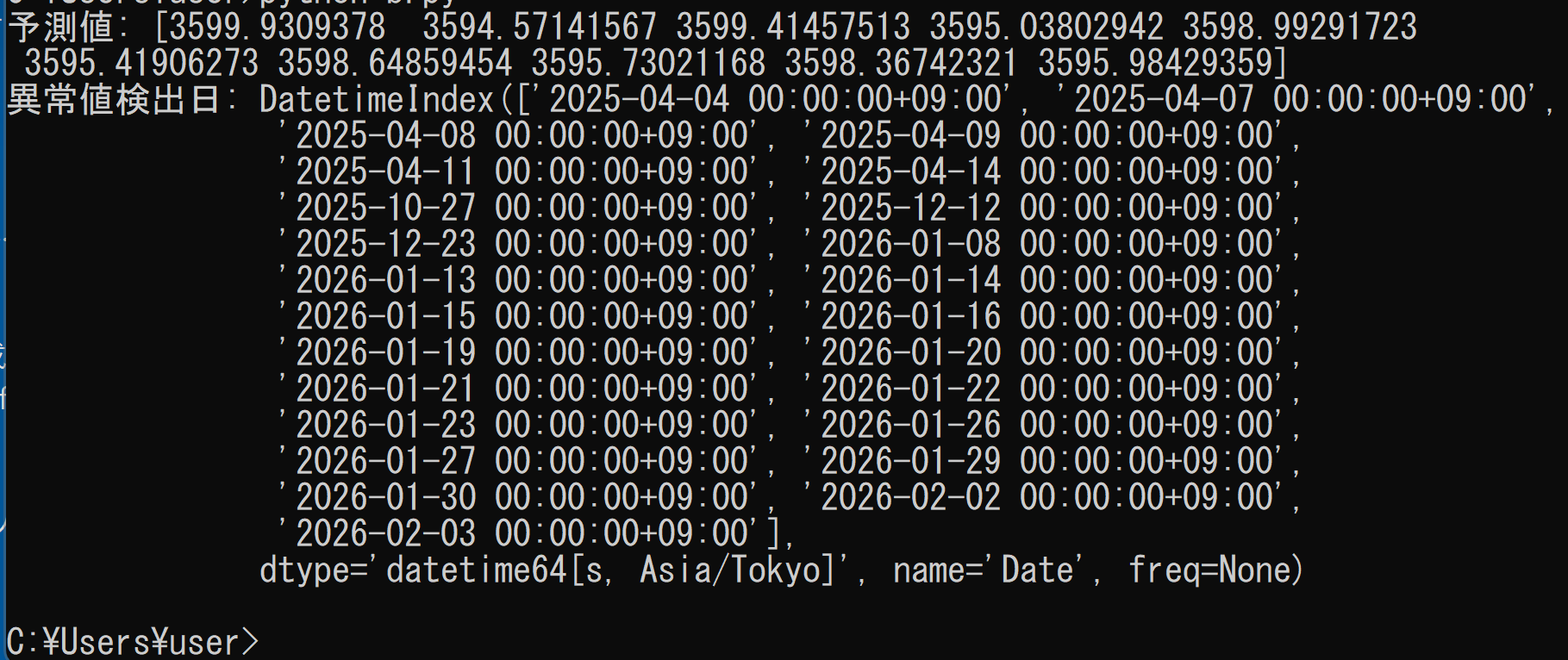
print("予測値:", results['forecast'])
print("異常値検出日:", results['anomaly_dates'])
plt.show()実行結果の確認
正常に実行されると、以下のような出力が表示され、グラフウィンドウが開く。数値と日付は実行時点のデータにより異なる。
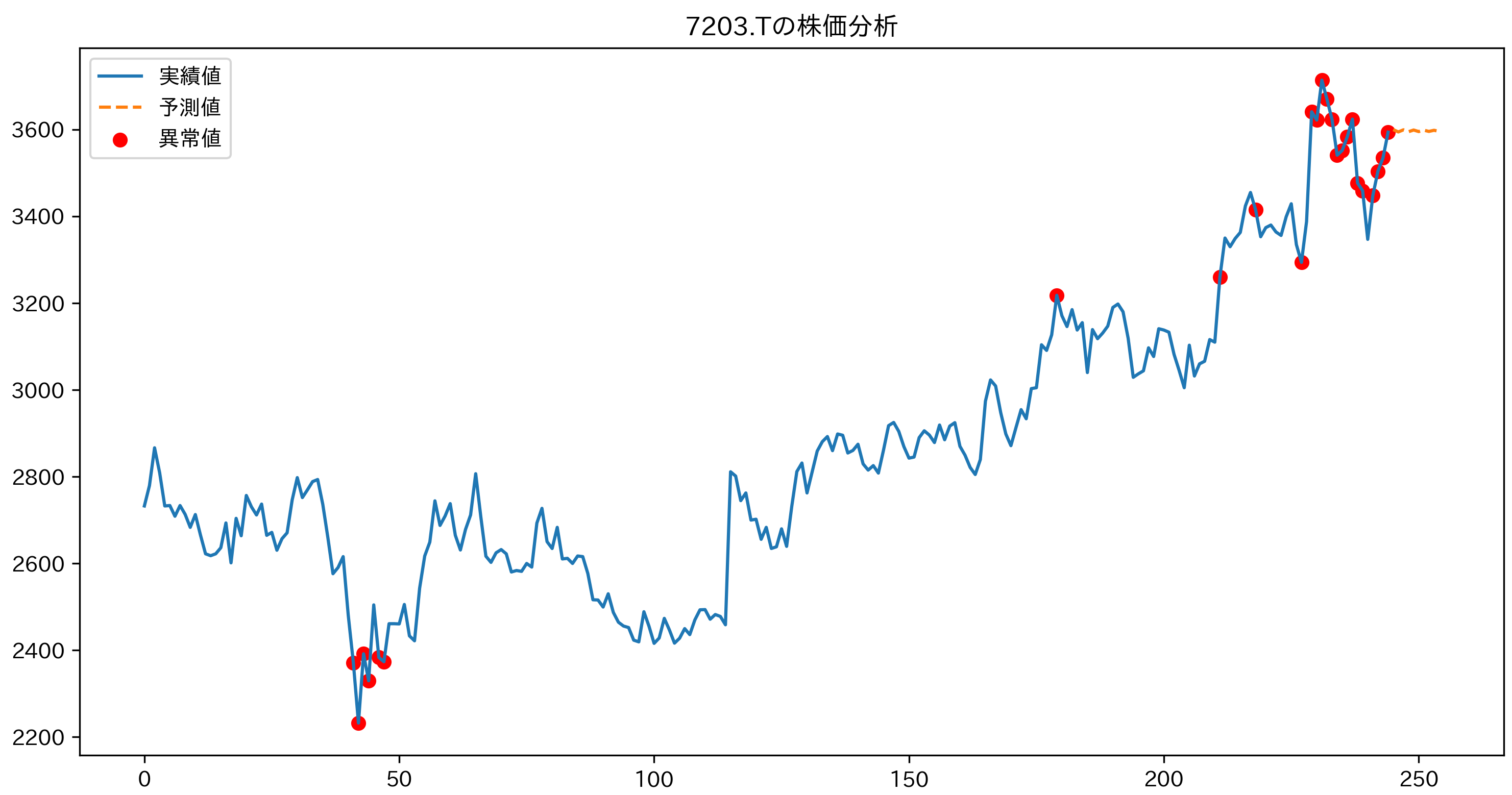

グラフには、実線で実績値、破線で予測値、赤点で異常値として検出された日の株価が表示される。グラフウィンドウを閉じるとプログラムが終了する。
3. 地理空間データの活用
以下は、国土数値情報ダウンロードサービスから取得した地理空間データを読み込み、観測地点との空間結合(複数のレイヤの地理データを位置関係に基づいて結合する処理)を行う実装例である。
データの準備
国土数値情報のデータは、以下の手順で事前にダウンロードする。
- 国土数値情報ダウンロードサービス(https://nlftp.mlit.go.jp/ksj/)にアクセスする。
- 「行政区域」を選択する。
- 対象年度(例:令和7年)と都道府県(例:福岡県)を選択し、シェープファイル(GISで用いられるベクタデータ形式)形式でダウンロードする。
- ダウンロードしたZIPファイルを解凍する。
- 解凍したフォルダをPythonプログラムと同じディレクトリに配置する。
ファイル配置の例を以下に示す。
作業ディレクトリ/
├── spatial_analysis.py (Pythonプログラム)
└── N03-20250101_40_GML/ (解凍したフォルダ)
├── KS-META-N03-20250101_40.xml (メタデータ)
├── N03-20250101_40.xml (XML形式データ)
├── N03-20250101_40.geojson (GeoJSON形式データ)
├── N03-20250101_40.cpg (文字コード情報)
├── N03-20250101_40.shp (シェープファイル本体)
├── N03-20250101_40.dbf (属性データ)
├── N03-20250101_40.shx (インデックス)
└── N03-20250101_40.prj (座標系情報)プログラム
import geopandas as gpd
import pandas as pd
import matplotlib.pyplot as plt
import japanize_matplotlib
from shapely.geometry import Point
def analyze_spatial_data(shp_path):
"""
地理空間データの分析を行う
shp_path: 国土数値情報からダウンロードしたシェープファイルのパス
例: "N03-20250101_40_GML/N03-20250101_40.shp"
"""
points_data = {
'latitude': [33.5902, 33.5895, 33.5932], # サンプル地点(福岡市内)
'longitude': [130.4017, 130.4021, 130.3992],
'name': ['地点A', '地点B', '地点C']
}
# シェープファイルの読み込み
gdf = gpd.read_file(shp_path)
# 福岡市のデータのみを抽出(N03_004は市区町村名の属性)
fukuoka_gdf = gdf[gdf['N03_004'] == '福岡市']
# 点データの作成
points_df = pd.DataFrame(points_data)
points_gdf = gpd.GeoDataFrame(
points_df,
geometry=[Point(xy) for xy in zip(points_df['longitude'], points_df['latitude'])],
crs="EPSG:4326"
)
# 座標参照系を統一
if fukuoka_gdf.crs != points_gdf.crs:
points_gdf = points_gdf.to_crs(fukuoka_gdf.crs)
# 空間結合
joined = gpd.sjoin(points_gdf, fukuoka_gdf, how='left', predicate='within')
# 地図のプロット
fig, ax = plt.subplots(figsize=(10, 10))
fukuoka_gdf.plot(ax=ax, alpha=0.5)
points_gdf.plot(ax=ax, color='red', markersize=50)
plt.title('福岡市地図と観測地点')
return joinedこのプログラムは、国土数値情報ダウンロードサービスから取得した福岡市の地理空間データを読み込み、GeoPandasにより空間分析を実行する。観測地点データとの空間結合および可視化を行う。
実行手順
上記の関数定義と以下の実行コードを同じPythonファイル(例:spatial_analysis.py)に保存し、実行する。shp_pathは実際のファイルパスに合わせて変更する。
result = analyze_spatial_data("N03-20250101_40_GML/N03-20250101_40.shp")
print(result[['name', 'N03_004']])
plt.show()実行結果の確認
正常に実行されると、以下のような出力が表示され、地図ウィンドウが開く。
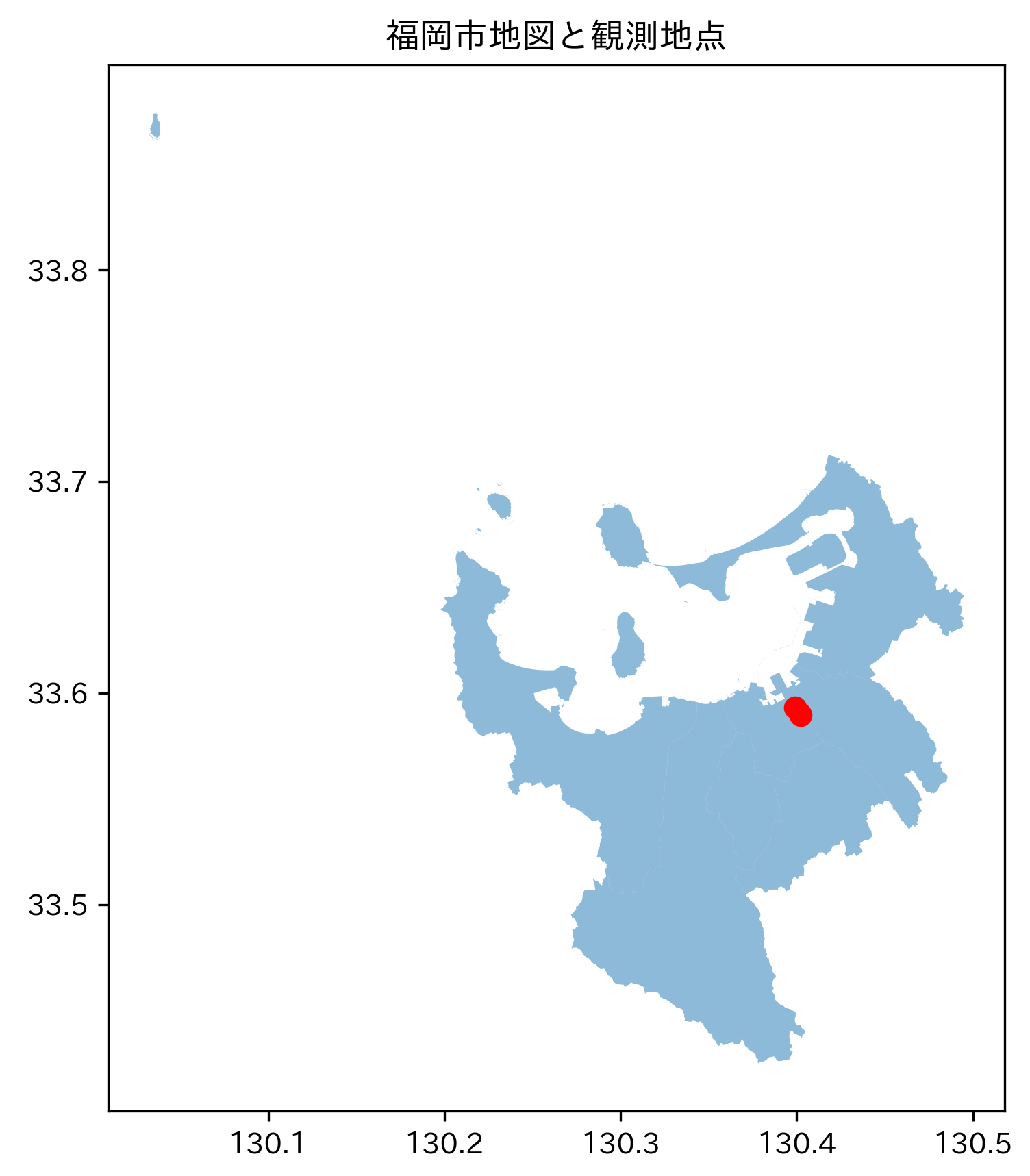
N03_004列に「福岡市」と表示されていれば、各地点が福岡市の行政区域内に位置することが空間結合により判定された結果である。地図ウィンドウには、福岡市の行政区域が薄い色で、観測地点が赤い点で表示される。地図ウィンドウを閉じるとプログラムが終了する。
6. まとめ
本文書では、RDBとPythonを組み合わせた応用例を扱った。RDBを活用することで、以下の点が得られる。
- SQLによるデータ操作が可能であり、検索や集計を実行できる。
- Pythonとの連携により、データの取得から分析までを自動化できる。
- 多様なデータ形式に対応できる。
本文書で扱った主なデータ形式と手法は以下のとおりである。
- 為替・株価などの金融データ(時系列での蓄積と統計分析)
- 時系列データ(ARIMAモデルによる予測、Isolation Forestによる異常値検出)
- 地理空間データ(GeoPandasとの連携、空間結合による分析)