R システムを用いた不偏分散共分散行列(高次元の場合)
このページでは,R システムを用いた不偏分散共分散行列の求め方と図解で説明する. このページでは,高次元の不偏分散共分散行列に焦点をあてます. 不偏分散共分散行列の意味については, 「R システムを用いた不偏分散共分散行列」の Web ページを見てください.
「R システムを用いた不偏分散共分散行列」の Web ページでは,3次元のベクトルデータを扱っていました.この意味は,次の通りです.
- テーブルなので,
各時点(それぞれの瞬間)でのUSDとEURとAUDの観測値(つまり値3つ)が,1行になる.
言い換えると,CSV ファイル Book1.csv では,「1行」が1回の観測値ということです.
- 「R システムを用いた不偏分散共分散行列」の Web ページでは,
3列目,4列目,5列目を抜き出して,1個の3次元のベクトルと見立てていました.
(値が3個なので、3次元のベクトル)です.
3列目,4列目,5列目に並んだデータを1つのベクトルとして扱ってきました.「[,3:5]」という書き方を使ってきました. つまり,3列目,4列目,5列目の部分は、3次元空間中の点の集まり,とみなされる.
一方で,この Web ページの手順では,CSV ファイルを読み込んだあと,R の t() 関数を使って,転置させます.
- すると,各行には,USDやEURやAUDの値の経時変化が並ぶ. これをベクトルと見立てると,2834次元のベクトルができる. これは,USDとEURとAUDの経時変化の波形をベクトルと見立てるもの.
不偏分散共分散行列と不偏相関係数行列
3 つの変数を n 回観測して得られる n 個の標本から構成される長さ n のベクトル に対する不偏分散共分散行列と不偏相関係数行列の定義は次の通り。
- 分散は、標本分散と不偏分散の2種類あり,同様に, 共分散は,標本分散の拡張と不偏分散の拡張の 2 種類ある. R や octave では,不偏分散の方になっている(標本分散ではない).
- ここでは、3 つの変数としているが,一般の m 個の変数が与えられた場合も同様の定義になる.


前準備
R システムのインストール
【関連する外部ページ】
R システムの CRAN の URL: https://cran.r-project.org/
CSVファイルを読み込み,データフレームに格納
- (前準備) 使用する CSV ファイルの作成
Book1.csv をダウンロード (参考: 「外国為替データ(時系列データ)の情報源の紹介」の Web ページ)
以下の説明では、
- Windows の場合: データファイル名: C:\R\Book1.csv
- Linuxの場合: データファイル名: /tmp/Book1.csv
として説明を続ける.
* 自前の CSV ファイルを使うときの注意: read.table() 関数を使うので, 属性名は英語になっていること.属性名は,CSV ファイルの第一行目に書いていること.
- 使用する CSV ファイルの確認
属性名が CSV ファイルの1行目に書かれていることを確認する.
- R の起動
- 「read.table」を用いて,CSV ファイルを R のデータフレームに読み込み
次のコマンドを実行.
◆ Windows での動作手順例
X <- read.table("C:/R/Book1.csv", header=TRUE, sep=",", na.strings="NA", dec=".", strip.white=TRUE);◆ Linux での動作手順例
X <- read.table("/tmp/Book1.csv", header=TRUE, sep=",", na.strings="NA", dec=".", strip.white=TRUE);R の read.table のオプション
- X <- ・・・ 変数 X に読み込むという意味
- C:/R/Book1.csv, "/tmp/Book1.csv" ・・・ 読み込む CSV ファイル名.Windows では区切りには「/」を使うことに注意.
- header="TRUE" または header="FALSE" ・・・ 列ラベルが設定されているか
- seq="," や seq="\" や seq=" " や ・・・ 列を区切る記号(CSV ファイルのときは「seq=","」)
- na.string="NA" ・・・ Not a Number には "NA" を使うという意味
- dec="." ・・・ ファイルで使われている小数点記号(既定値は,ピリオド)
- strip.white=TRUE ・・・ 個々のデータの先頭や末尾にある「空白文字」を取り除いて読み込む
- skip=<行数> ・・・ 読み飛ばし行数
- nrow=<行数> ・・・ 読み込み行数
- (その他のオプション) dec: ファイルで使われている小数点記号を指定できる
- オブジェクト X の確認
次のコマンドを実行.
edit(X);
次のコマンドを実行.
str(X)
cov() 関数を使って不偏分散共分散行列を求める
cov() 関数を使って不偏分散共分散行列を求める
次のコマンドを実行.
covTX <- cov( t( X[,3:5] ) )

* 実は,covTX は,2834行2834列になっています.
長すぎるので,「covTX」+ Enter ではうまく表示できません.
str(covTX)
edit(covTX);

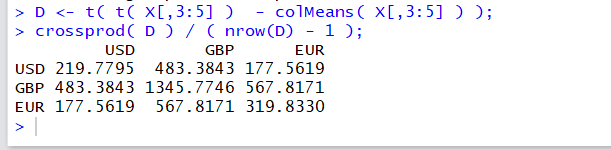
- cov() 関数を使って,分散共分散行列を求める R の式
cov( t( X[,3:5] ) )
- colMeans() 関数, t() 関数などを使って,分散共分散行列を求める R の式
crossprod( D ) / ( nrow(D) - 1 ); * この式は「t( D ) %*% t( D ) / ( nrow(D) - 1 )」と同じ意味
但し、D は次の手順で作る. D は,行列 X の各列の平均値を X の各要素から引き,転置した行列になっている. ここで「転置」になっているのは R のリサイクル規則を使って簡単に作れるから。
D <- t( t( X[,3:5] ) - colMeans( X[,3:5] ) );