Ruby で rsruby を用いた散布図の作成
このページでは,rsruby を用いた散布図の作成について,
散布図内での平均と分散の図示,散布図行列,スケールの信頼性
の作成手順を図解で説明する
前準備
Ubuntu の場合
Ubuntu を使用する場合は,次のように操作する.
- Ubuntu で Ruby 処理系のインストール
- Ubuntu で R 処理系のインストール
- Rでのパッケージのインストールの Web ページの記述に従って,Rcmdr のインストールが済んでいること.
- Ubuntu で rsruby のインストール
Windows の場合
Windows を使用する場合は,次のように操作する.
- Ruby と DevKit のインストール(Ruby インストーラ 3.1.2 を使用)(Windows 上): 別ページ »で説明
- Windows で R 処理系のインストール
- (オプション) Rでのパッケージのインストールの Web ページの記述に従って,Rcmdr のインストールが済んでいること.
- Windows の環境変数 PATH に「C:\R\R-2.14.1\bin\i386」を追加
- Windows で rsruby のインストール
CSVファイルを読み込み,Ruby の連想配列に格納 (Read CSV file, and store into an HashTable of Ruby)
- (前準備) 使用する CSV ファイルの作成
ここでは,テスト用の CSV ファイル Book1.csv をダウンロードし, ディレクトリ C:\R\の下におくことにします.
* Ubuntu の場合は /tmp の下などに置く(要するにどこでも良い)
- 使用する CSV ファイルの確認
この Web ページのプログラムでは,1行目がヘッダー.2行目以降がデータ本体になっている必要がある. CSV ファイルの1行目に,各列の属性名が書かれていることを確認する.
テスト用の CSV ファイル Book1.csv では, 属性名として seq, date, USD, EUR, AUD の5つが 書かれている.
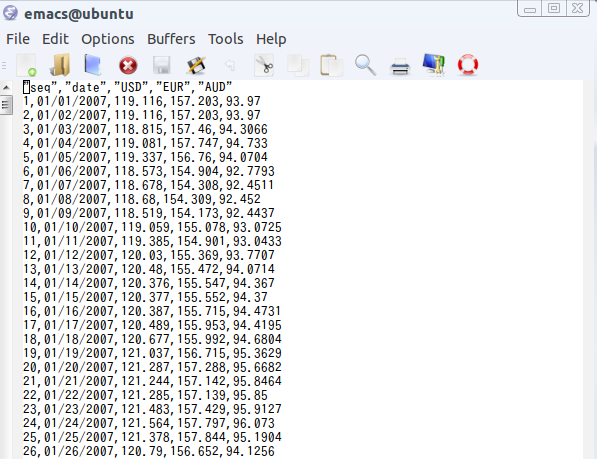
- CSVファイルを読み込み,Ruby の連想配列に格納するプログラム (Read CSV file, and store into an HashTable of Ruby)
まだ rsruby は使っていません.このプログラムを書き換えて,いろいろなグラフ作成に使うことします.
require 'rubygems' require "csv" reader = CSV.open("/tmp/Book1.csv", "r") header = reader.take(1)[0] T = Hash::new header.each do |attr| T[attr.strip] = [] end reader.each do |row| i = 0 row.each do |item| T[header[i].strip].push(item.strip) i = i + 1 end end
散布図の作成
- 数値による要約
最小値,中央値,平均値,最大値などを取得
◆ Ubuntu の場合の実行手順例
export R_HOME=/usr/lib/Rirb require 'rubygems' require "csv" require 'rsruby' reader = CSV.open("/tmp/Book1.csv", "r") header = reader.take(1)[0] T = Hash::new header.each do |attr| T[attr.strip] = [] end reader.each do |row| i = 0 row.each do |item| T[header[i].strip].push(item.strip) i = i + 1 end end # r = RSRuby::instance r.eval_R(<<-RCOMMAND) # create a data frame D seq <- c( #{T["seq"].join(",")} ) date <- c( #{T["date"].join(",")} ) USD <- c( #{T["USD"].join(",")} ) EUR <- c( #{T["EUR"].join(",")} ) AUD <- c( #{T["AUD"].join(",")} ) D = data.frame( cbind( seq = seq, date = date, USD = USD, EUR = EUR, AUD = AUD ) ) a = summary(D) RCOMMAND r.a 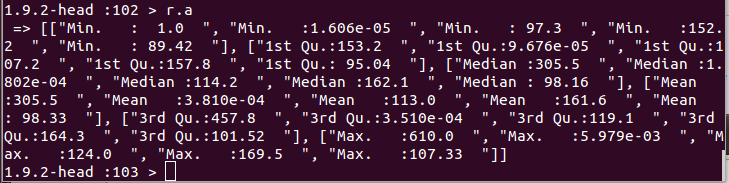
- 数値による要約
平均値,標準偏差などを取得
◆ Ubuntu の場合の実行手順例
export R_HOME=/usr/lib/Rirb require 'rubygems' require "csv" require 'rsruby' reader = CSV.open("/tmp/Book1.csv", "r") header = reader.take(1)[0] T = Hash::new header.each do |attr| T[attr.strip] = [] end reader.each do |row| i = 0 row.each do |item| T[header[i].strip].push(item.strip) i = i + 1 end end # r = RSRuby::instance r.eval_R(<<-RCOMMAND) library(Rcmdr) # create a data frame D seq <- c( #{T["seq"].join(",")} ) date <- c( #{T["date"].join(",")} ) USD <- c( #{T["USD"].join(",")} ) EUR <- c( #{T["EUR"].join(",")} ) AUD <- c( #{T["AUD"].join(",")} ) D = data.frame( cbind( seq = seq, date = date, USD = USD, EUR = EUR, AUD = AUD ) ) a = numSummary( D[,c("USD", "EUR", "AUD")], statistics=c("mean", "sd", "quantiles"), quantiles=c( 0,.25,.5,.75,1 )) RCOMMAND r.a 
- 「scatterplot」を用いた散布図の描画
要点: 横軸が seq, 縦軸が USD
◆ Ubuntu の場合の実行手順例
export R_HOME=/usr/lib/Rirb require 'rubygems' require "csv" require 'rsruby' reader = CSV.open("/tmp/Book1.csv", "r") header = reader.take(1)[0] T = Hash::new header.each do |attr| T[attr.strip] = [] end reader.each do |row| i = 0 row.each do |item| T[header[i].strip].push(item.strip) i = i + 1 end end # r = RSRuby::instance r.eval_R(<<-RCOMMAND) # create a data frame D seq <- c( #{T["seq"].join(",")} ) date <- c( #{T["date"].join(",")} ) USD <- c( #{T["USD"].join(",")} ) EUR <- c( #{T["EUR"].join(",")} ) AUD <- c( #{T["AUD"].join(",")} ) D = data.frame( cbind( seq = seq, date = date, USD = USD, EUR = EUR, AUD = AUD ) ) scatterplot( USD~seq, reg.line=lm, smooth=TRUE, boxplots=FALSE, span=0.5, data=D ) RCOMMAND 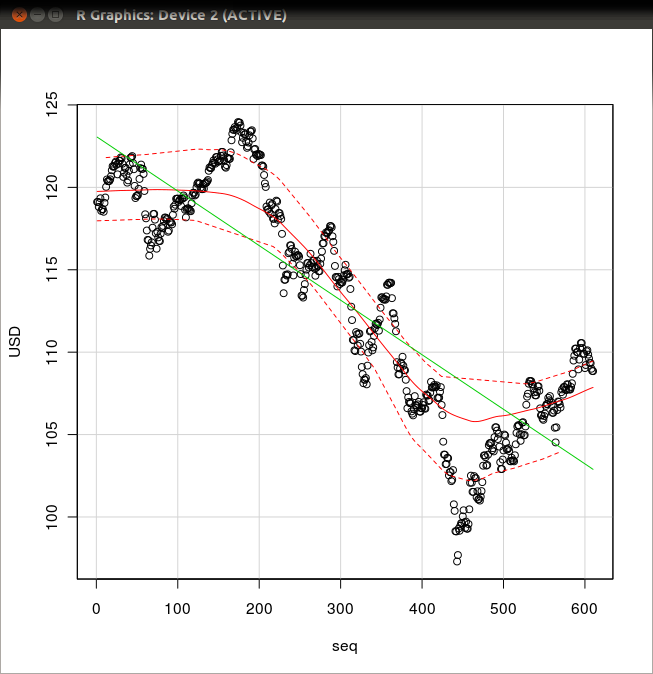
- 「scatterplot」を用いた散布図の描画(分布の平均と分散も図示)
要点: 横軸が seq, 縦軸が USD.分布の平均と分散も図示
◆ Ubuntu の場合の実行手順例
export R_HOME=/usr/lib/Rirb require 'rubygems' require "csv" require 'rsruby' reader = CSV.open("/tmp/Book1.csv", "r") header = reader.take(1)[0] T = Hash::new header.each do |attr| T[attr.strip] = [] end reader.each do |row| i = 0 row.each do |item| T[header[i].strip].push(item.strip) i = i + 1 end end # r = RSRuby::instance r.eval_R(<<-RCOMMAND) # create a data frame D seq <- c( #{T["seq"].join(",")} ) date <- c( #{T["date"].join(",")} ) USD <- c( #{T["USD"].join(",")} ) EUR <- c( #{T["EUR"].join(",")} ) AUD <- c( #{T["AUD"].join(",")} ) D = data.frame( cbind( seq = seq, date = date, USD = USD, EUR = EUR, AUD = AUD ) ) scatterplot( USD~seq, reg.line=lm, smooth=TRUE, boxplots='xy', span=0.5, data=D ) RCOMMAND 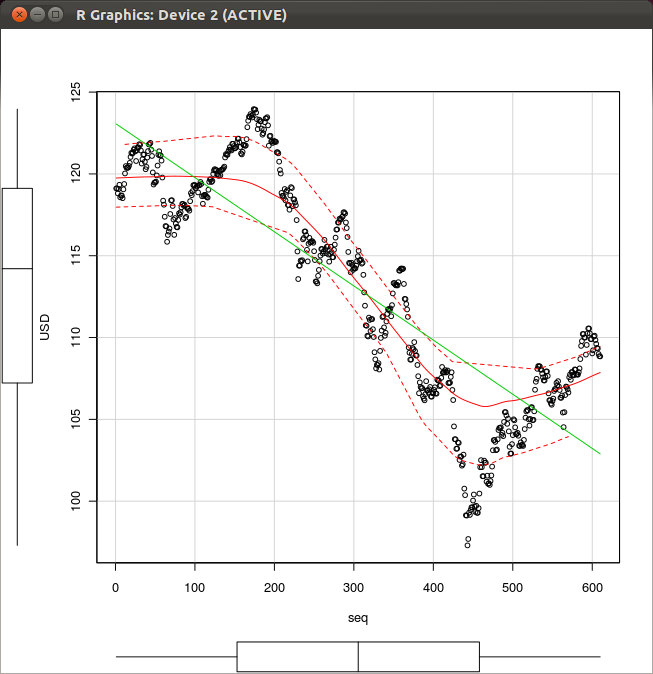
- 散布図行列
◆ Ubuntu の場合の実行手順例
export R_HOME=/usr/lib/Rirb require 'rubygems' require "csv" require 'rsruby' reader = CSV.open("/tmp/Book1.csv", "r") header = reader.take(1)[0] T = Hash::new header.each do |attr| T[attr.strip] = [] end reader.each do |row| i = 0 row.each do |item| T[header[i].strip].push(item.strip) i = i + 1 end end # r = RSRuby::instance r.eval_R(<<-RCOMMAND) # create a data frame D seq <- c( #{T["seq"].join(",")} ) date <- c( #{T["date"].join(",")} ) USD <- c( #{T["USD"].join(",")} ) EUR <- c( #{T["EUR"].join(",")} ) AUD <- c( #{T["AUD"].join(",")} ) D = data.frame( cbind( seq = seq, date = date, USD = USD, EUR = EUR, AUD = AUD ) ) scatterplot.matrix( ~seq+USD+EUR+AUD, reg.line=lm, smooth=TRUE, diagonal='density', span=0.5, data=D ) RCOMMAND 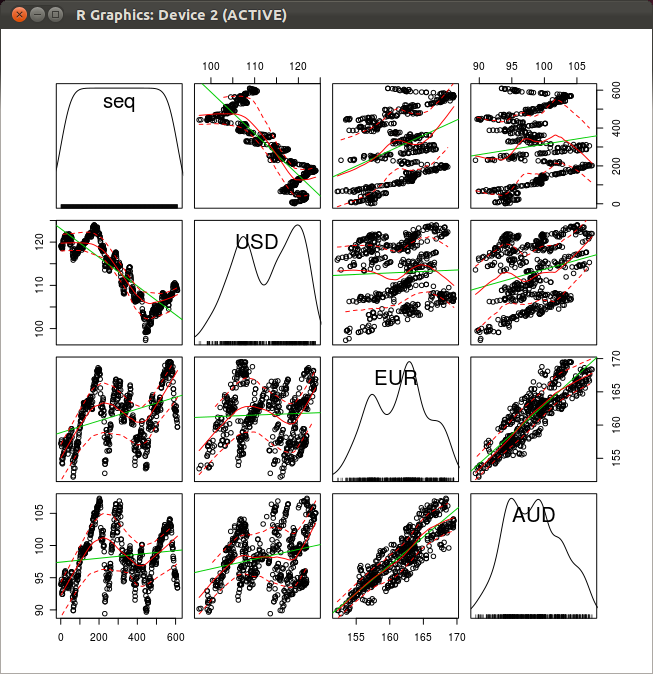
- スケールの信頼性
export R_HOME=/usr/lib/Rirb require 'rubygems' require "csv" require 'rsruby' reader = CSV.open("/tmp/Book1.csv", "r") header = reader.take(1)[0] T = Hash::new header.each do |attr| T[attr.strip] = [] end reader.each do |row| i = 0 row.each do |item| T[header[i].strip].push(item.strip) i = i + 1 end end # r = RSRuby::instance r.eval_R(<<-RCOMMAND) # create a data frame D seq <- c( #{T["seq"].join(",")} ) date <- c( #{T["date"].join(",")} ) USD <- c( #{T["USD"].join(",")} ) EUR <- c( #{T["EUR"].join(",")} ) AUD <- c( #{T["AUD"].join(",")} ) D = data.frame( cbind( seq = seq, date = date, USD = USD, EUR = EUR, AUD = AUD ) ) reliability( cov(D[,c("USD","EUR","AUD")], use="complete.obs") ) RCOMMAND 