AIエディタ Windsurf の活用
【概要】WindsurfはVS CodeをベースとしたAIエディタである。無料でも利用できる。Ctrl + LでCascade機能(AIとの対話パネル)を起動し,日本語で各種依頼ができる。Windsurf標準のAIモデルを使う場合,外部サービスのAPI Keyは不要であり,Windsurfアカウントの登録のみで使用できる。
【料金・モデルに関する注意】 Windsurfの料金体系と利用可能なAIモデル,およびその無料・有料の区分は頻繁に更新される。本資料に記載した数値(利用枠やクレジット数,各モデルの消費量,無料・無制限の条件など)は執筆時点のものである。その後(2026年3月)に料金体系は大きく改定され,従来の月単位のクレジット制から,日次・週次の利用枠(クォータ)制へ移行した。あわせてプラン料金の改定や,無料で利用できるモデルの変更・縮小も行われている。本資料の記述(クレジット数や特定モデル名など)は旧制度を前提とした箇所があるため,最新の情報は,公式の料金ページ(https://windsurf.com/pricing)とドキュメント(https://docs.windsurf.com)で必ず確認すること。本資料で言う「クレジット(利用枠)」とは,AIモデルへの問い合わせで消費される単位であり,モデルによって消費量が異なる(詳細は第3章で説明する)。現行のクォータ制では,この単位は日次・週次で更新される利用枠に置き換わっている。
【目次】
- メリットと機能
- 基本機能とショートカットキー
- 無料プランの機能
- API Key 要件
- Cursor と Windsurf の比較
- 事前準備
- Windsurf の起動と初回設定
- Windsurf の推奨モデル
- 無料枠で使えるモデルの選択手順
- Windsurf をエディタとして活用する
- Windsurf の AI 機能の活用
- Windsurf の重要機能一覧
【資料】旧版のWord windsurf.docx,PDF windsurf.pdf(このページの記事が最新版である)
【サイト内のPython関連主要ページ】
- Windows AI支援Python開発環境構築ガイド: 別ページ »で説明
- AIエディタ Windsurf の活用: 別ページ »で説明
- AIエディタCursorガイド: 別ページ »で説明
- Google Colaboratory: 別ページ »で説明
- Python のまとめ: 別ページ »で説明
- 機械学習の Python 実現ガイド: 別ページ »で説明
- 行列計算の Python 実現ガイド: 別ページ »で説明
- 統計分析のPythonでの実現ガイド: 別ページ »で説明
- 音声信号処理の Python 実現ガイド: 別ページ »で説明
- カラー画像処理の Python 実現ガイド: 別ページ »で説明
- Pythonによる簡単なアドベンチャーゲーム(変数,式,if,while,関数,print,time.sleep,def,globalを使用): 別ページ »で説明
- Pythonプログラミング講座:基礎から応用まで(授業資料,全15回): 別ページ »で説明
- Pythonプログラミングの例と実践ガイド: 別ページ »で説明
【外部リソース】
- Pythonの公式サイト: https://www.python.org
- 東京大学の「Pythonプログラミング入門」: https://utokyo-ipp.github.io/IPP_textbook.pdf
- ITmedia社の「Pythonチートシート」の記事: https://atmarkit.itmedia.co.jp/ait/articles/2004/20/news015.html
1. メリットと機能
WindsurfはVS Codeをベースとした統合開発環境(IDE: Integrated Development Environment)であり,AI機能を標準搭載している。無料プランがあり,学生や個人開発者が利用しやすい。VS Codeと操作方法が類似しているため,VS Code利用者は移行が容易である。VS Codeの多くの拡張機能をそのまま利用できる。
Windsurf Tabは,Tabキーを用いたコード補完機能である。Cascade機能は,コード生成や実行を支援するAI機能である。
個人情報を含む画像やデータを使用する場合は,匿名化処理を行い,データ保護法に従って取り扱う。
2. 基本機能とショートカットキー
Cascade 機能
Cascadeは,コード生成や実行を支援するAI機能である。Ctrl + Lキーを押すとCascadeパネルが開く。日本語の指示に対応しており,例えば「Pythonで折れ線グラフのサンプルコードを作成して」のように自然言語で依頼できる。
主要ショートカットキー
主要なショートカットキーを以下に示す。Ctrl + L と Ctrl + I はいずれもAIを呼び出すが,用途が異なる。Ctrl + L はパネルでAIと対話する用途,Ctrl + I はエディタ内のカーソル位置で直接コードを生成・編集する用途である。
Ctrl + L:Cascade(AI対話)パネルを開くCtrl + I:エディタ内のカーソル位置でコードを生成・編集するCtrl + `:統合ターミナルを開くF5:デバッグを開始するTab:コード補完候補を選択する
3. 無料プランの機能
Windsurfの無料プランでは,一定量の利用枠(プロンプトクレジット)が提供される。クレジット(利用枠)とは,AIモデルへの問い合わせで消費される単位であり,モデルによって消費量が異なる。執筆時点では月25クレジットが提供され,これはGPT-4.1プロンプト約100回分(GPT-4.1は0.25クレジット/プロンプトのため,25 ÷ 0.25 = 約100回)に相当した。利用可能なモデルには,GPT-4.1(0.25クレジット/プロンプト),Claude 3.7 Sonnet(1クレジット/プロンプト),DeepSeek-V3-0324(執筆時点では無料枠で利用可)などがあった。
クレジットを消費するモデル(GPT-4.1,Claude 3.7 Sonnetなど)には月間上限がある一方,無料枠のモデル(DeepSeek-V3-0324など)はクレジットを消費せずに利用できた。すなわち,クレジット上限は主にクレジットを消費するモデルの利用回数に対する制約であった。執筆時点では,無制限のFast TabやSWE-1 Liteも無料プランに含まれていた。
上記のクレジット数・消費量・無料・無制限の条件は変動する。2026年3月には月単位のクレジット制から日次・週次の利用枠(クォータ)制へ移行し,その後,無料プランで利用できるモデルも変更・縮小されている(執筆時点で無料枠にあった DeepSeek-V3-0324 や SWE-1 系は,現在は無料プランの対象から外れている場合がある)。Tabによるコード補完は引き続き全プランで利用枠を消費せずに使える。最新の条件は,公式の料金ページとドキュメントで確認すること。
4. API Key 要件
Windsurf標準のAIモデルを利用する場合,外部サービスのAPIキー(外部のAIサービスにアクセスするための認証キー)は不要である。Windsurfアカウントの作成のみで利用を開始できる。アカウント登録は無料であり,登録後すぐに利用できる。
特定の高性能モデルを自分で契約して使う場合は,自前のAPIキーを登録して利用するBYOK(Bring Your Own Key)という仕組みがある。これは任意の選択肢であり,標準モデルのみを使う通常の利用では不要である。BYOKで利用できるモデルや設定方法は変更されるため,必要な場合は公式ドキュメントで確認すること。
5. Cursor と Windsurf の比較
執筆時点での比較を示す。Claude 3.7 Sonnetの利用回数は,Cursor無料版が月50回,Windsurf無料版が月約25回であった。一方,Windsurfでは無料枠のモデル(DeepSeek-V3-0324など)を,その時点の条件の範囲で多く利用できた。
両者の無料枠の内容・回数・対象モデルは変動する。上記の比較値は執筆時点(クレジット制・回数制)の目安であり,現在は両サービスとも料金・利用枠の方式が変わっている(Windsurfは日次・週次のクォータ制へ移行済み)。最新の条件は各サービスの公式情報で確認すること。
6. 事前準備
本資料の手順とスクリーンショットは,Windows環境を前提とする。
Python 3.12 のインストール(Windows 上) [クリックして展開]
以下のいずれかの方法で Python 3.12 をインストールする。Python がインストール済みの場合,この手順は不要である。なお,Windows版のPyTorchが対応するPythonのバージョンには範囲があるため,新しすぎるバージョンではなく Python 3.12 を用いる。
方法1:winget によるインストール
winget は Windows 標準のパッケージ管理ツールである。Windows 10(1809以降)・Windows 11 では「アプリインストーラー(App Installer)」として利用できる。winget コマンドが認識されない場合は,Microsoft Store から「アプリインストーラー」を導入する。
管理者権限のコマンドプロンプトで以下を実行する。管理者権限のコマンドプロンプトを起動するには,Windows キーまたはスタートメニューから「cmd」と入力し,表示された「コマンドプロンプト」を右クリックして「管理者として実行」を選択する。
winget install --id Python.Python.3.12 -e --scope machine --silent --accept-source-agreements --accept-package-agreements --override "/quiet InstallAllUsers=1 PrependPath=1 Include_test=0 Include_pip=1 Include_launcher=1 InstallLauncherAllUsers=1 TargetDir=\"C:\Program Files\Python312\""
powershell -Command "$p='C:\Program Files\Python312'; $s=\"$p\Scripts\"; $m=[Environment]::GetEnvironmentVariable('Path','Machine'); if($m -notlike \"*$s*\") { [Environment]::SetEnvironmentVariable('Path', \"$p;$s;$m\", 'Machine') }"--scope machine を指定すると,システム全体(全ユーザー向け)にインストールされる。このオプションの実行には管理者権限が必要である。インストール完了後,コマンドプロンプトを再起動すると PATH が設定される。
方法2:インストーラーによるインストール
- Python 公式サイト(https://www.python.org/downloads/)にアクセスし,Python 3.12 系の Windows 用インストーラーをダウンロードする。
- ダウンロードしたインストーラーを実行する。
- 初期画面の下部に表示される「Add python.exe to PATH」にチェックを入れてから「Customize installation」を選択する。このチェックを入れないと,コマンドプロンプトから
pythonコマンドを実行できない。 - 「Install Python 3.xx for all users」にチェックを入れ,「Install」をクリックする。
インストールの確認
コマンドプロンプトで以下を実行する。
python --versionバージョン番号(例:Python 3.12.x)が表示されればインストール成功である。「'python' は,内部コマンドまたは外部コマンドとして認識されていません。」と表示される場合は,インストールが正常に完了していない。
AIエディタ Windsurf のインストール(Windows 上) [クリックして展開]
ここでは,Windsurf のインストールを説明する。Windsurf がインストール済みの場合,この手順は不要である。
なお,Windsurf(旧 Codeium)は2025年7月に Cognition(AIコーディングエージェント Devin の開発元)に買収された。これに伴い,下記の winget パッケージID(Codeium.Windsurf)や提供元の表記が変更されている場合がある。コマンドが認識されない場合は,「winget search windsurf」で現在のIDを確認すること。
管理者権限のコマンドプロンプトで以下を実行する。管理者権限のコマンドプロンプトを起動するには,Windows キーまたはスタートメニューから「cmd」と入力し,表示された「コマンドプロンプト」を右クリックして「管理者として実行」を選択する。
winget install --scope machine --id Codeium.Windsurf -e --silent --disable-interactivity --force --accept-source-agreements --accept-package-agreements --custom "/SP- /SUPPRESSMSGBOXES /NORESTART /CLOSEAPPLICATIONS /DIR=""C:\Program Files\Windsurf"" /MERGETASKS=!runcode,addtopath,associatewithfiles,!desktopicon"
powershell -Command "$env:Path=[System.Environment]::GetEnvironmentVariable('Path','Machine')+';'+[System.Environment]::GetEnvironmentVariable('Path','User'); windsurf --install-extension MS-CEINTL.vscode-language-pack-ja --force; windsurf --install-extension ms-python.python --force; windsurf --install-extension Codeium.windsurfPyright --force"--scope machine を指定すると,システム全体(全ユーザー向け)にインストールされる。このオプションの実行には管理者権限が必要である。インストール完了後,コマンドプロンプトを再起動すると PATH が設定される。
【関連する外部ページ】
Windsurf の公式ページ: https://windsurf.com/
7. Windsurf の起動と初回設定
Windsurfの初回起動時には,アカウント登録と基本設定を行う。これにより,AI機能を含むすべての機能が利用可能になる。以下の画面表示やメッセージは,Windsurfのバージョンによって異なる場合がある。
- Windsurfを起動する。スタートメニューから起動するか,コマンドラインで「windsurf」コマンドを実行する。
- 「Get Started」をクリックする。
- VS Codeから設定を引き継ぐ場合は「Import from VS Code」を,引き継がない場合は「Start fresh」を選択する。
- 設定を続行する。
- 「Log in to Windsurf」の画面で,「Sign up」をクリックしてアカウントを新規作成する。登録情報を記録しておき,次回からは「Log in」でログインする。Googleアカウントを使ったアカウント登録もできる。これでインストールと初期設定は完了である。
- Getting Started(始めよう)の画面を確認する。
- 動作確認を行う。利用枠(クォータ)を節約するため,あらかじめ第9章の手順で無料枠のモデルを選択しておく。Ctrl + LキーでCascadeを開き,「折れ線グラフを描くコードを出して」と入力し,Enterキーを押す。
コードが出力される。
このとき,左下に「Do you want to install the recommended 'Python' extension...」というメッセージが表示される場合がある。「Install」をクリックし,インストール終了を待つ。
AIパネルには「コードを実行します」のように表示される。実行する場合は「Accept」をクリックする。
実行結果を確認する。
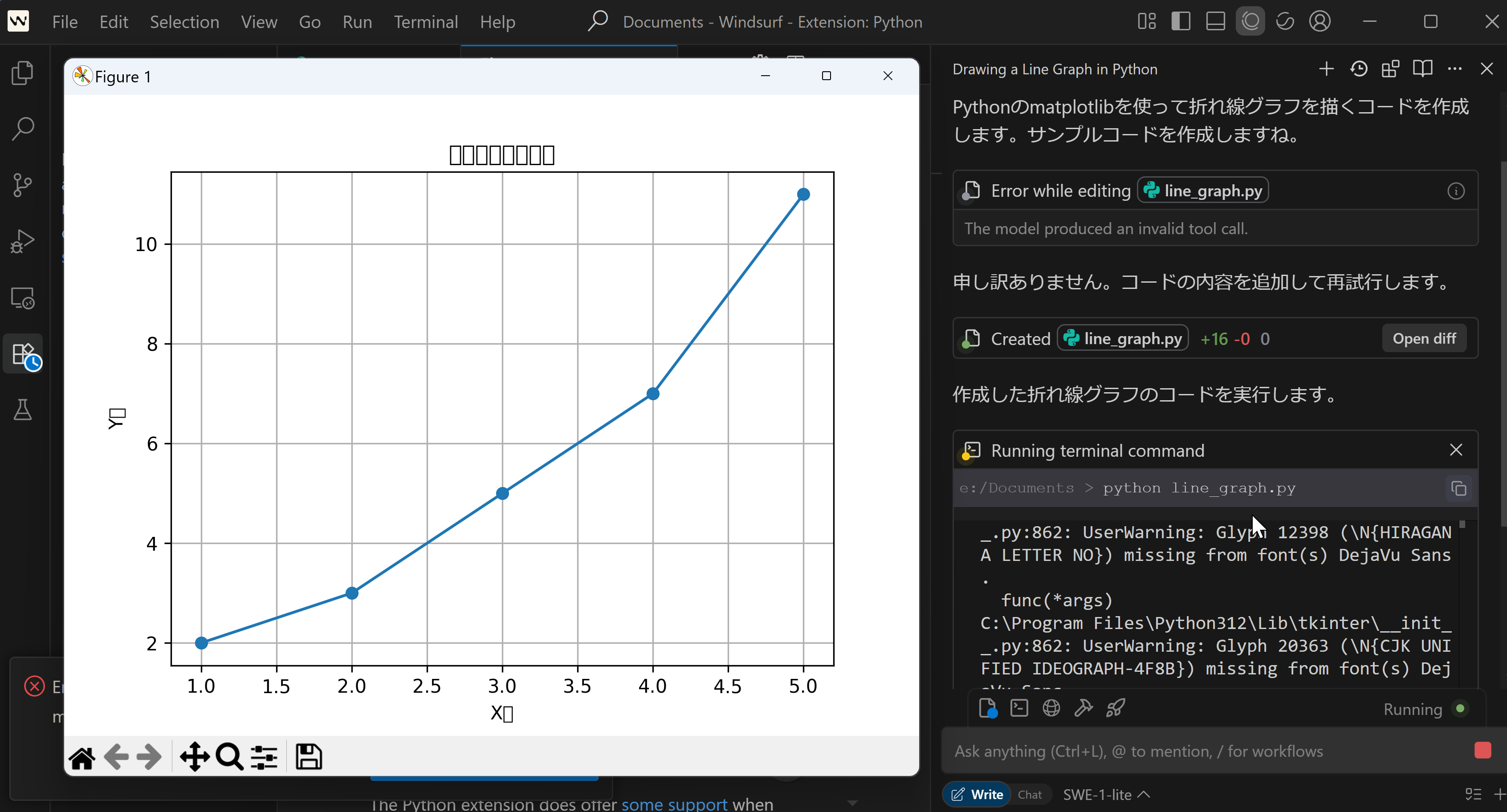
8. Windsurf の推奨モデル
利用枠(クォータ)を節約するため,消費の少ないモデルの利用を推奨する。どのモデルが無料枠(利用枠を消費しないモデル,または無料プランで選択可能なモデル)に該当するかは頻繁に変更されるため,利用時に画面の表示を確認すること。執筆時点では,以下のモデルが消費の少ない選択肢であった。
- DeepSeek-V3-0324(執筆時点では0クレジットで利用可。提供条件は変更される)
- SWE-1(執筆時点では0クレジットだが,期間限定の提供であった)
- SWE-1-lite(執筆時点では0クレジットの軽量版)
これらの具体的なモデル名や無料提供の条件は変動が大きく,上記のモデルはいずれも現在は無料プランの対象から外れている場合がある(無料プランで選べるモデルは,より新しいモデルへ随時入れ替わっている)。長期的にどのモデルが無料で使えるかは,モデル選択時の画面表示と公式ドキュメントで確認すること。
9. 無料枠で使えるモデルの選択手順
無料枠で利用できるモデルを選択する手順を示す。第7章・第10章・第11章の演習に入る前にこの手順でモデルを選んでおくと,利用枠(クォータ)の消費を抑えられる。
- Cascadeパネル(Ctrl + Lキー)を開く。
- 入力欄上部のモデル選択ドロップダウンをクリックする。
- その時点で無料枠(利用枠を消費しないモデル,または無料プランで選択可能なモデル)に表示されているモデルを選択する。執筆時点では DeepSeek-V3-0324 や SWE-1 系が該当したが,提供条件は変更されるため,現在表示されている無料枠のモデルを選ぶこと。
10. Windsurf をエディタとして活用する
ここでは,Windsurfでファイル作成,コード編集,実行を行う手順を説明する。AI機能を使う場合は,第9章の手順で無料枠のモデルを選択した状態で進める。
演習1.Pythonファイルの作成と実行
手順
- Windsurfを起動する。スタートメニューから起動する。起動直後にログインを求められた場合はログインする。初回起動時には,サインアップ(IDとパスワードの登録)が必要である。サインアップの際は,Googleアカウントの利用を推奨する。
- 新規ファイルを作成する。メニューで「File」>「New File」を選択する。
- ファイル名を設定する。例えば
a.pyとする。このとき,拡張子を「.py」に設定する。これはPythonファイルとして認識させるためである。
- Enterキーを押し,「Create File」をクリックしてファイル作成を確定する。
a.pyに以下のプログラムを入力する。print(100 + 200)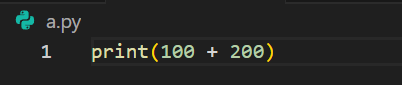
- プログラムを実行する。画面上部の三角形の実行ボタンをクリックする。実行ボタンがない場合は,Python拡張機能をインストールする。
- 実行結果として「300」が表示されることを確認する。ターミナルがない場合は,「View」メニュー >「Terminal」を選択する。
ヒント
print()は,括弧内の値や計算結果を画面に表示するPythonの関数である。この例では,100 + 200 の計算結果である300が出力される。
考察ポイント
- ターミナルに表示された値が,計算式
100 + 200の結果と一致するかを確認する。
11. Windsurf の AI 機能の活用
ここでは,AIによる画像分類プログラムを実行し,AIとの対話を行う。画像分類プログラムを通じて,深層学習の流れ(データ準備,モデル構築,学習,評価)を体験する。
【GPUの有無について】 以下のプログラムは,GPUがあればGPUで,なければCPUで動作する。NVIDIA GPUを搭載していない環境では,本章の「NVIDIA CUDA Toolkit 12.8 のインストール」とGPU版PyTorchのインストールは不要であり,CPU版のPyTorchをインストールする。GPUがない環境では学習に時間がかかる。
NVIDIA CUDA Toolkit 12.8 のインストール(NVIDIA GPU搭載環境のみ)
- 前提条件:NVIDIA GPU,NVIDIAドライバ,および Build Tools for Visual Studio もしくは Visual Studio が必要である。GPUがない環境ではこの手順は不要である。
- 注意:他のウィンドウは事前に閉じておく。
GPU版PyTorchを使う場合は,CUDA Toolkit 12.8 をインストールする。以下のコマンドを管理者権限のコマンドプロンプトで実行する。管理者権限のコマンドプロンプトを起動するには,Windows キーまたはスタートメニューから「cmd」と入力し,表示された「コマンドプロンプト」を右クリックして「管理者として実行」を選択する。
以下のコマンドのうち setx ... /M は,一時ファイルの保存先(環境変数 TEMP・TMP)を C:\TEMP にシステム全体で恒久的に変更する操作である(システム設定の変更であり,他のアプリの動作に影響する場合がある)。元に戻す場合は,システムの環境変数設定から TEMP・TMP を既定値(%USERPROFILE%\AppData\Local\Temp など)に戻す。変更を望まない場合は,TEMP・TMP の設定行を実行せず,CUDAのインストール行のみを実行する。
REM NVIDIA CUDA Toolkit 12.8 をシステム領域にインストール
winget install --scope machine --id Nvidia.CUDA --version 12.8 -e --silent --disable-interactivity --force --uninstall-previous --accept-source-agreements --accept-package-agreements --override "-s -n"
REM 環境変数TEMP, TMPの設定(一時ファイルの保存先を短いパスに変更。システム全体に影響する)
mkdir C:\TEMP
set "TEMP_PATH=C:\TEMP"
setx TEMP "%TEMP_PATH%" /M >nul
setx TMP "%TEMP_PATH%" /M >nulPyTorch のインストール
PyTorchがインストール済みの場合,この手順は不要である。管理者権限のコマンドプロンプトで以下を実行する。管理者権限のコマンドプロンプトを起動するには,Windows キーまたはスタートメニューから「cmd」と入力し,表示された「コマンドプロンプト」を右クリックして「管理者として実行」を選択する。
NVIDIA GPU搭載環境では,CUDA 12.8 対応のGPU版PyTorchをインストールする。インデックスURLの cu128 は CUDA 12.8 向けを表す。
REM PyTorch をインストール(GPU版。CUDA 12.8 対応)
set "CUDA_TAG=cu128"
set "PYTHON_PATH=C:\Program Files\Python312"
"%PYTHON_PATH%\Scripts\pip" install --no-user -U numpy torch torchvision torchaudio --index-url https://download.pytorch.org/whl/%CUDA_TAG%GPUがない環境では,CUDA Toolkitのインストールは行わず,CPU版のPyTorchをインストールする。
REM PyTorch をインストール(CPU版。GPUがない環境向け)
set "PYTHON_PATH=C:\Program Files\Python312"
"%PYTHON_PATH%\Scripts\pip" install --no-user -U numpy torch torchvision torchaudio必要なライブラリのインストール
管理者権限のコマンドプロンプトで以下を実行する。管理者権限のコマンドプロンプトを起動するには,Windows キーまたはスタートメニューから「cmd」と入力し,表示された「コマンドプロンプト」を右クリックして「管理者として実行」を選択する。
pip install matplotlib numpy pillowpip は,Pythonのパッケージ管理システムである。インターネット上のライブラリをダウンロードし,インストールする。ライブラリとは,再利用可能なプログラムの集合体である。機械学習や画像処理などの処理を簡潔に実装できる。
各ライブラリの役割を以下に示す。
- PyTorch (torch):Metaが開発した機械学習フレームワーク(プログラム開発を支援する基盤ソフトウェア)である。深層学習の実装に使用する。
- torchvision:PyTorchの画像処理用ライブラリである。画像データの前処理やデータセットの読み込みに使用する。
- Matplotlib:グラフや図表を作成するライブラリである。データの可視化に使用する。
- NumPy:数値計算ライブラリである。多次元配列の操作や数学関数を提供する。
- Pillow:画像処理ライブラリである。画像の読み込み,編集,保存に使用する。
グラフ中の日本語表示には,Windowsに標準で含まれる日本語フォント(MS Gothic)をMatplotlibに指定する。これは後述のプログラム内で設定するため,追加のライブラリは不要である。
演習2.CIFAR-10画像分類とAI対話
手順
- Windsurfエディタ画面に,以下のプログラムをコピーして貼り付ける。
# CIFAR-10画像分類プログラム # CNNによる10クラス画像分類と学習過程の可視化 # 参考: PyTorch公式チュートリアル "Training a Classifier" # URL: https://pytorch.org/tutorials/beginner/blitz/cifar10_tutorial.html # 到達精度は設定(エポック数,ネットワーク規模など)により変動する # 前準備: GPU搭載環境(CUDA 12.8) # pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu128 # GPUなし環境 # pip install torch torchvision torchaudio # 共通 # pip install matplotlib numpy pillow # (管理者権限のコマンドプロンプトで実行) import torch import torch.nn as nn import torch.optim as optim import torchvision import torchvision.transforms as transforms import matplotlib.pyplot as plt import matplotlib import numpy as np # グラフの日本語表示(Windows標準フォント MS Gothic を指定) matplotlib.rcParams['font.family'] = 'MS Gothic' # 定数定義 BATCH_SIZE = 32 EPOCHS = 5 LEARNING_RATE = 0.001 RANDOM_SEED = 42 # 再現性確保のためのシード設定 torch.manual_seed(RANDOM_SEED) np.random.seed(RANDOM_SEED) # データセットのクラス名 CLASSES = ['飛行機', '自動車', '鳥', '猫', '鹿', '犬', 'カエル', '馬', '船', 'トラック'] # デバイス設定 device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') print(f'使用デバイス: {device}') if torch.cuda.is_available(): print('GPUを使用して学習を実行します') else: print('CPUを使用して学習を実行します') # データの前処理 transform = transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) ]) # CIFAR-10データセットの読み込み print("データセットを読み込み中...") trainset = torchvision.datasets.CIFAR10( root='./data', train=True, download=True, transform=transform ) trainloader = torch.utils.data.DataLoader( trainset, batch_size=BATCH_SIZE, shuffle=True ) testset = torchvision.datasets.CIFAR10( root='./data', train=False, download=True, transform=transform ) testloader = torch.utils.data.DataLoader( testset, batch_size=BATCH_SIZE, shuffle=False ) # CNNモデルの定義 class CNN(nn.Module): def __init__(self): super(CNN, self).__init__() self.conv1 = nn.Conv2d(3, 32, 3, padding=1) self.conv2 = nn.Conv2d(32, 64, 3, padding=1) self.conv3 = nn.Conv2d(64, 64, 3, padding=1) self.pool = nn.MaxPool2d(2, 2) self.fc1 = nn.Linear(64 * 8 * 8, 64) self.fc2 = nn.Linear(64, 10) self.relu = nn.ReLU() def forward(self, x): x = self.pool(self.relu(self.conv1(x))) x = self.pool(self.relu(self.conv2(x))) x = self.relu(self.conv3(x)) x = x.view(-1, 64 * 8 * 8) x = self.relu(self.fc1(x)) x = self.fc2(x) return x model = CNN().to(device) criterion = nn.CrossEntropyLoss() optimizer = optim.Adam(model.parameters(), lr=LEARNING_RATE) # 学習 print("学習を開始します...") train_losses = [] val_losses = [] for epoch in range(EPOCHS): # 訓練フェーズ model.train() running_train_loss = 0.0 for inputs, labels in trainloader: inputs, labels = inputs.to(device), labels.to(device) optimizer.zero_grad() outputs = model(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() running_train_loss += loss.item() # 検証フェーズ model.eval() running_val_loss = 0.0 with torch.no_grad(): for inputs, labels in testloader: inputs, labels = inputs.to(device), labels.to(device) outputs = model(inputs) loss = criterion(outputs, labels) running_val_loss += loss.item() epoch_train_loss = running_train_loss / len(trainloader) epoch_val_loss = running_val_loss / len(testloader) train_losses.append(epoch_train_loss) val_losses.append(epoch_val_loss) print(f'エポック {epoch+1}/{EPOCHS}: 訓練損失 = {epoch_train_loss:.4f}, 検証損失 = {epoch_val_loss:.4f}') # 評価 print("評価を実行中...") model.eval() correct = 0 total = 0 test_images = [] test_labels = [] predictions = [] with torch.no_grad(): for images, labels in testloader: images, labels = images.to(device), labels.to(device) outputs = model(images) _, predicted = torch.max(outputs, 1) total += labels.size(0) correct += (predicted == labels).sum().item() if len(test_images) < 5: for j in range(min(5 - len(test_images), images.size(0))): test_images.append(images[j].cpu()) test_labels.append(labels[j].cpu()) predictions.append(predicted[j].cpu()) accuracy = 100 * correct / total # 分類結果の表示 plt.figure(figsize=(15, 3)) for i in range(5): plt.subplot(1, 5, i+1) img = test_images[i].permute(1, 2, 0) img = img * 0.5 + 0.5 plt.imshow(img) plt.title(f'予測: {CLASSES[predictions[i]]}\n実際: {CLASSES[test_labels[i]]}') plt.axis('off') plt.tight_layout() plt.show() # 学習曲線の表示 plt.figure(figsize=(8, 4)) plt.plot(range(1, EPOCHS + 1), train_losses, 'b-', label='訓練損失') plt.plot(range(1, EPOCHS + 1), val_losses, 'r-', label='検証損失') plt.title('学習過程') plt.xlabel('エポック') plt.ylabel('損失') plt.legend() plt.grid(True) plt.show() print(f"テスト精度: {accuracy:.2f}%")
- プログラムを実行する。画面上部の三角形の実行ボタンをクリックする。
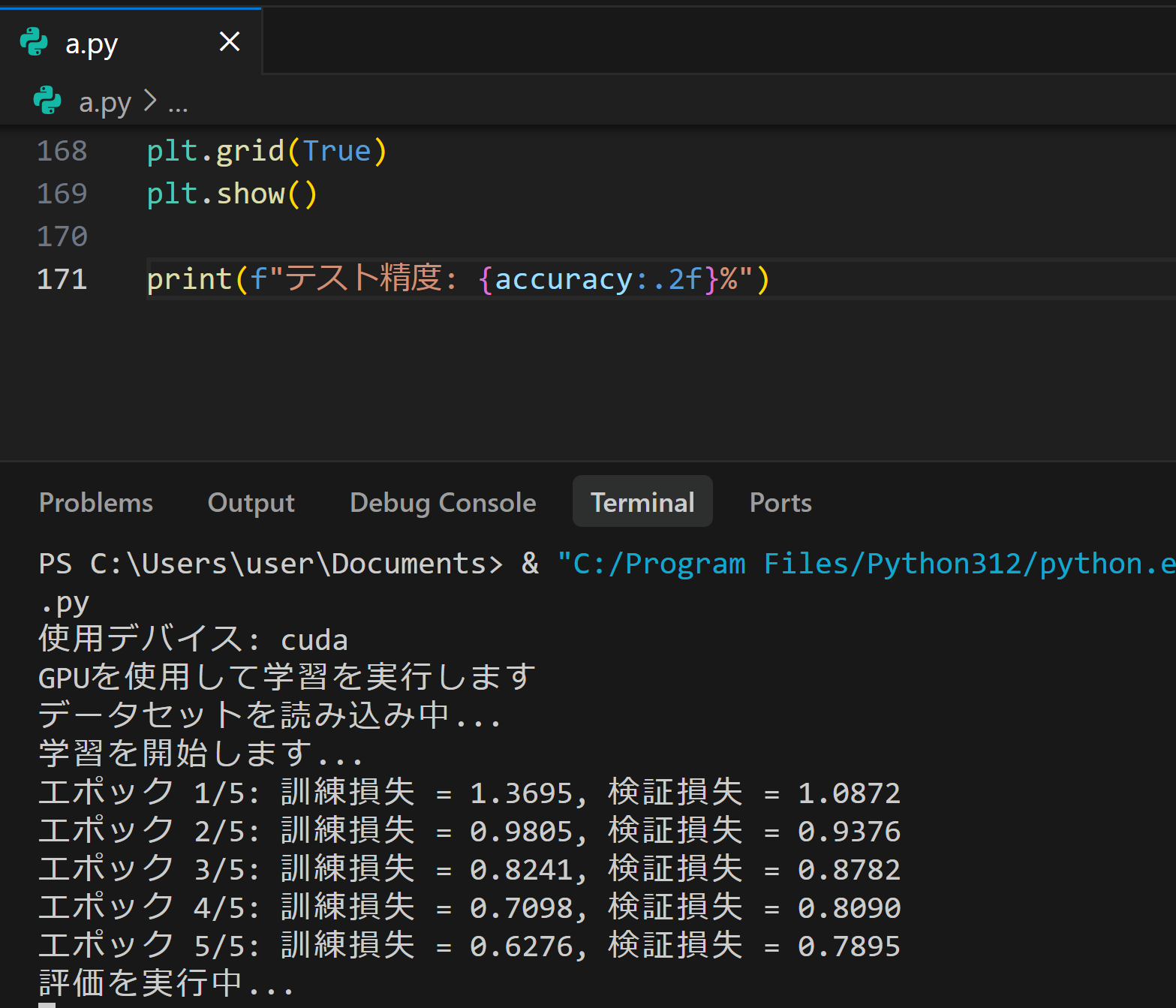
- 実行完了まで数分待機する。深層学習モデルの訓練は計算量が多いため,通常のプログラムより時間を要する。GPUがない環境ではさらに時間がかかる。
- 最初に,5枚のテスト画像に対する予測結果と正解の比較が表示される。

- 確認後,右上の「x」ボタンをクリックして次へ進む。
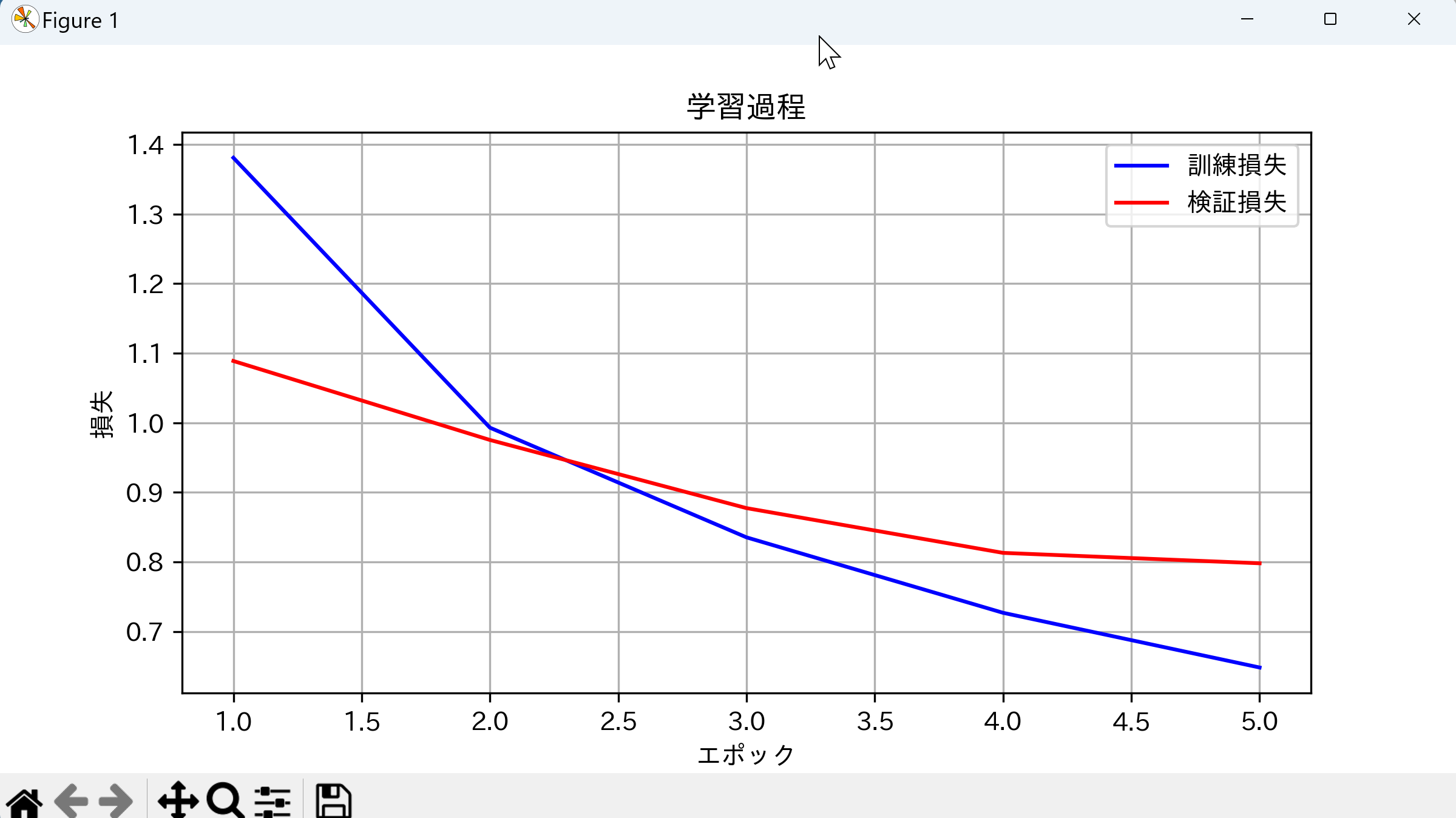
- 学習曲線(損失の変化)が表示される。これはモデルの学習過程を可視化したグラフである。
- 確認後,右上の「x」ボタンをクリックする。
- AI対話パネルを起動する。Ctrl + Lキーを押す。右側にAI対話用パネルが開く。
- 右側の対話画面で,以下の質問を順に入力する(各質問の後にEnterキーを押す)。
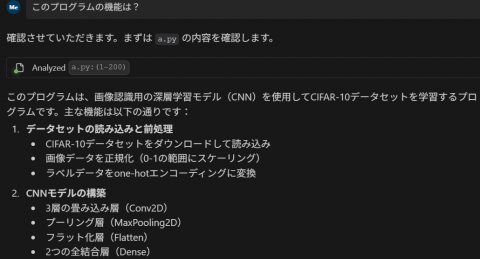
- 「このプログラムの機能は」
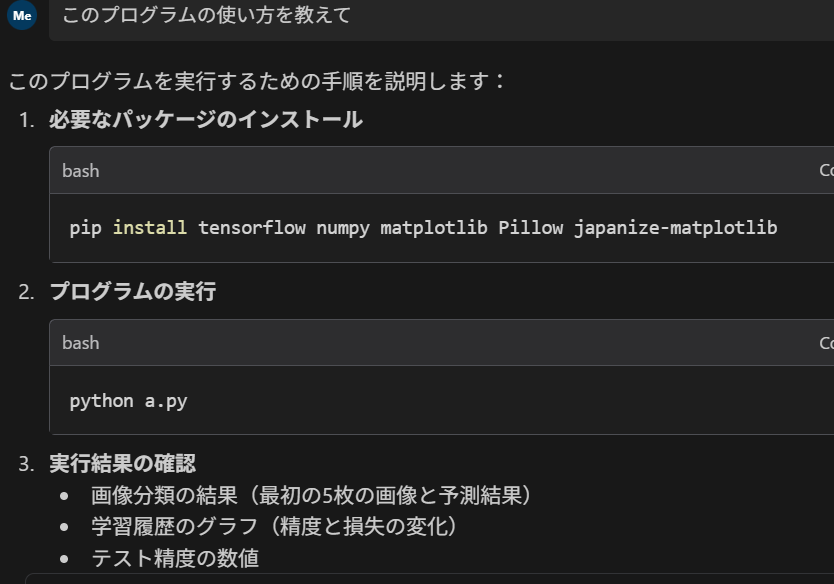
- 「このプログラムの使い方を具体的に教えて」
- 「このプログラムを使って何が研究できるの。研究中間発表(研究目標,研究課題,取り組み,期待される成果,独自の工夫予定)のサンプルを簡潔に教えて。そのとき,社会課題の解決を考えて。」

- 「このプログラムの機能は」
ヒント
- CIFAR-10は,10種類の物体(飛行機,自動車,鳥,猫,鹿,犬,カエル,馬,船,トラック)が写った32×32ピクセルのカラー画像60,000枚で構成される画像認識用データセットである。
- データの前処理は,元のデータをモデルが学習しやすい形に変換する処理である。ここでは画像の画素値を-1から1の範囲に正規化(データの値を一定の範囲に変換する処理)している。
- CNN(畳み込みニューラルネットワーク)は,画像認識に用いるモデルである。畳み込み層(Conv2d)で画像の特徴を抽出し,プーリング層(MaxPool2d)で情報を集約する。
- エポックは,全訓練データを1回学習する単位である。本プログラムでは5エポック,すなわち全データを5回繰り返し学習する。
- バッチサイズは,一度に処理するデータの個数である。本プログラムでは32個ずつまとめて処理する。
- デバイス設定では,GPUが利用可能な場合は自動的にGPUを使用し,利用できない場合はCPUを使用する。
- 損失関数(CrossEntropyLoss,交差エントロピー損失)で予測と正解の差を計算し,最適化手法(Adam)でモデルのパラメータを更新する。
- AI対話パネルが「Loading...」と表示されて使用できない場合は,Windsurfを再起動(一度終了し,再度起動)する。これはAIサービスへの接続に時間がかかる場合に発生する。
- AIへの質問は,具体的で明確にする。専門用語が分からない場合は「初心者向けに説明して」と付け加える。複数の質問がある場合は一つずつ順に聞く。回答をさらに詳しく聞きたい場合は「もっと詳しく教えて」と追加質問する。
考察ポイント
- 5枚のテスト画像について,予測ラベルと正解ラベルが一致した画像と一致しなかった画像を数える。
- 学習曲線で,訓練損失と検証損失がエポックごとにどう変化したかを読み取る。両方の損失が減少する傾向が望ましい。
- 本プログラムは学習エポック数が少ないため,到達するテスト精度は限定的である。エポック数と精度の関係を考える。
- AIの回答が,実際のプログラムの動作(読み込むデータ,学習の流れ,出力)と対応しているかを確認する。
12. Windsurf の重要機能一覧
AI機能
- AIコード生成機能:Ctrl + Iキー(エディタ内のカーソル位置で生成・編集),またはCtrl + LのAIパネルで「○○○のコードを生成して」と依頼する。コードの自動生成に使用する。
- AIコード解説機能:コードを選択して右クリック >「Explain」,またはAIパネルで質問する。コードの解説に使用する。
- AIバグ修正支援機能:エラー箇所を選択し,AIパネルで「このエラーを修正して」と依頼する。デバッグに使用する。
開発支援機能
- インテリセンス(自動補完)機能:コード入力中に候補が表示され,Tabキーで選択する。関数名や変数名の入力に使用する。
- 統合ターミナル機能:「View」メニュー >「Terminal」,または Ctrl + ` キーで起動する。コマンド実行やライブラリのインストールに使用する。
- ファイルエクスプローラー機能:左側のサイドバーに表示され,フォルダやファイルをクリックで選択する。複数ファイルの管理に使用する。
- デバッガー機能:ライン番号をクリックしてブレークポイントを設定し,F5キーでデバッグを開始する。実行時の変数値確認やステップ実行に使用する。
- 問題検出機能:Problemsパネルに警告やエラーが表示される。実行前のエラー検出に使用する。