手元の PC で完結するローカル LLM 活用 ― チャット・図の理解・RAG を体験する(Ollama+Open WebUI/CPU/GPU 対応・Windows)
Windows上でOllama(推論基盤)とOpen WebUI(操作画面)を用い、データを外部送信しないローカルLLM環境を構築する手順書である。 軽量モデルで動作を確認した後、画像入力対応のgemma4系モデルでチャットおよび図・表・数式の読み取りを体験する。 RAG(検索拡張生成)はbge-m3で文書を検索しrerankerで再順位付けし、固有情報や最新情報を要する質問への対応力を高める。 図表・数式を含む文書は標準抽出に限界があるため、Docling連携により表構造や図中テキストを保持し抽出精度を向上できる。
【目次】
- はじめに
- 前提知識(用語の整理)
- 使用するモデル
- 主要 Python パッケージ、埋め込みモデル
- Python 3.12 のインストール
- Build Tools・CUDA Toolkit・PyTorch のインストール
- Ollama・モデル・Open WebUI のインストール
- 演習 1.基本動作確認(CUI)
- 演習 2.RAG なしでチャット(ブラウザ)
- 演習 3.RAG なしで図を理解させてチャット(ブラウザ)
- 演習 4.RAG ありで図を含む文書を扱う(ブラウザ)
- 発展:Docling による図表・数式を含む文書の高精度抽出(Docker + docling-serve)
- 付録:他のモデルを試す
【サイト内の関連ページ】
はじめに
大規模言語モデル(LLM)は、入力された文に続く次のトークン(語や記号の単位)を確率的に予測する仕組みであり、出力に誤りを含む可能性がある。出力の品質は、プロンプト(モデルへの入力指示)の構成と思考モードのオン・オフに依存する。RAG(Retrieval-Augmented Generation、検索拡張生成)は、LLM が既存資料を検索し、その結果を踏まえて応答を生成することで、固有情報や最新情報を要する質問への対応力を高める仕組みである。ローカル運用(外部サーバへ送信せず手元のマシン内で完結させる運用)により、外部に出せない文書を安全に読み込み・精査・点検できる。
本手順は、Windows 上でローカル LLM 環境を構築し、インストール後の基本動作の確認、RAG(検索拡張生成)の体験、および図(画像)を理解させるマルチモーダル利用を行う。基盤は Ollama、フロントエンド(操作・表示を担うソフトウェア)は Open WebUI である。Open WebUI は Python 3.11 と 3.12 で動作する(2026 年 6 月時点では Python 3.13 には未対応)。本手順では Python 3.12 を用いる前提で記述し、コマンド中の Python312 は Python 3.12 を表す。Python 3.11 を用いる場合は、本手順中の Python312 を Python311 に読み替える。
Ollama には、コンテキスト長(一度に処理できるトークン数の上限)262144 トークンおよび KV キャッシュ q8_0 を設定する。KV キャッシュはモデルが過去のトークンの中間表現を保持する領域であり、q8_0 はこの領域を 8 ビット整数に量子化してメモリ使用量を抑える設定である。これらの設定は最初のインストール時に一度だけ行う。
本手順で用いるモデルは、いずれも CPU のみの PC や少 VRAM の GPU でも動作する点が共通する。
- 動作確認用の最軽量モデル LFM2.5-1.2B-Instruct(パラメータ数約 1.2B、GGUF の Q4_K_M 量子化でモデルファイル約 731MB、VRAM 目安 1〜2GB、テキスト専用)。
- 画像入力(図の理解)に対応する gemma4:e2b-it-qat(Gemma 4 シリーズの E2B モデルの QAT 版、ダウンロード容量約 4.3GB、コンテキスト長 128K)と、上位の gemma4:12b-it-qat(同シリーズ 12B モデルの QAT 版、約 7.2GB、コンテキスト長 256K)。いずれも QAT(Quantization-Aware Training、量子化を考慮した学習)によって軽量化され、ライセンスは Apache 2.0(Ollama のモデルページおよび Hugging Face 上のライセンスファイルで最新情報を確認すること)、テキストに加えて画像入力にも対応し、思考モード(応答前に内部で推論過程を生成する機能)を備える。
- RAG の埋め込み(テキストを数値ベクトルに変換する処理)に用いる bge-m3。
LFM2.5-1.2B-Instruct はテキスト専用のため、図(画像)を理解させる演習 3・演習 4 では画像入力に対応する gemma4 系モデルを用いる。
前提知識(用語の整理)
本節では、本手順を読み進めるうえで前提となる基本概念を整理する。
LLM(大規模言語モデル)とは
LLM(Large Language Model、大規模言語モデル)は、大量のテキストを学習したニューラルネットワークであり、対話・要約・翻訳などを行う。入力テキストをトークン(語や記号の単位。文字や単語の断片に相当する)に分割し、入力された文に続く次のトークンを確率的に予測することで文章を生成する。モデルの規模はパラメータ数(例:1.2B=12 億)で表される。この仕組み上、出力は確率に基づく予測であり、事実と異なる内容(ハルシネーション:もっともらしいが事実でない出力)を含む可能性がある。
マルチモーダル(画像入力)とは
マルチモーダルとは、テキストだけでなく画像など複数種類の入力を扱える性質をいう。画像入力に対応したモデル(ビジョンモデル)は、図・グラフ・表の画像や、数式・化学式を撮影した画像を読み取り、その内容を説明したり、内容について質問に答えたりできる。本手順では gemma4 系モデルがこれに対応する。
量子化
量子化は、モデル内部の重みパラメータを低ビット精度(例:32 ビット浮動小数点を 4 ビット整数)に圧縮し、ファイルサイズと必要メモリを削減する技術である。精度はある程度低下するが、CPU や少 VRAM の GPU でも実行可能になる。Q4_K_M は 4 ビット量子化の代表的な品質設定で、4 ビットを基本としつつ重要な層のみ精度を保つ方式であり、サイズと精度のバランスが取れている。QAT(Quantization-Aware Training、量子化を考慮した学習)は、学習の段階から量子化を織り込むことで、4 ビットへ量子化してもメモリ使用量を削減しつつ精度低下を抑える手法である。
GPU の利用(CUDA 等)について
本手順の推論エンジンである Ollama は、GPU があれば自動的に検出して利用する(NVIDIA GPU では CUDA、対応 GPU が無い場合は CPU で実行)。利用者が CUDA を明示的に設定する必要はなく、GPU ドライバが導入されていれば自動で使われる。Ollama は後述の llama.cpp を基盤とする。
ローカル運用とは
ローカル運用とは、外部のサーバへデータを送信せず、手元のマシン内で推論を完結させる運用形態である。入力した文書やプロンプトが外部に送信されないため、情報セキュリティの面で利点がある。機密文書を外部の生成 AI サービスに送れない場面でも、ローカル運用なら安全に扱える。
本手順で用いる 2 つの基盤ソフトウェア
- Ollama:LLM の推論を実行するバックエンド(推論エンジン)である。モデルのダウンロード、メモリへのロード、推論の実行を担う。ローカル API サーバ機能を持ち、API サーバ(HTTP 経由でモデルに問い合わせる仕組みを提供するサーバ)は既定でポート 11434 で待ち受ける。
- Open WebUI:ユーザの操作を受け取り、ブラウザに結果を表示するフロントエンドである。HTTP 経由で Ollama に問い合わせる構造であり、フロントエンド(操作・表示側)とバックエンド(推論側)が分離されている。チャットへの画像添付、Knowledge による RAG、Docling 連携といった機能を一つのブラウザ画面で扱える。
Ollama の基盤について
Ollama は、C++ 実装の推論エンジン llama.cpp を基盤とする。llama.cpp は量子化によりモデルサイズを削減し CPU でも実行できる仕組みで、GPU があれば自動的に利用する。利用者が llama.cpp を直接操作する必要はない。
RAG とは
RAG(Retrieval-Augmented Generation、検索拡張生成)は、ユーザの質問に応じて、事前に登録した資料から関連箇所を検索し、その検索結果を文脈として LLM に渡したうえで応答を生成する仕組みである。これにより、LLM が学習していない固有情報や最新情報を要する質問への対応力が向上する。
コンテキスト長について
コンテキスト長とは、LLM が一度に処理できる入力+出力のトークン数の上限である。本手順では、gemma4:12b-it-qat のコンテキスト長上限である 262144 トークンを基準に設定する。設定値がモデル側の上限を超える場合、Ollama は推論時にモデル側の上限に合わせて動作する。そのため、上限が 128K(131072 トークン)の gemma4:e2b-it-qat でも、上限が 32768 トークンの LFM2.5-1.2B-Instruct でも、同じ設定のまま支障なく動作する。なお、コンテキスト長を大きく設定するほど推論時のメモリ使用量が増えるため、メモリに余裕のない PC では応答が遅くなることがある。この設定は最初のインストールで一度だけ行う。
使用するモデル
LFM2.5-1.2B-Instruct(動作確認・テキスト専用)
Liquid AI 社の軽量モデルである。パラメータ数約 1.2B(正確には 1.17B)と軽量で動作が速く、英語・アラビア語・中国語・フランス語・ドイツ語・日本語・韓国語・スペイン語の 8 言語に対応する。コンテキスト長は 32768 トークンである。本手順では対話用に調整された Instruct 版を用いる。VRAM 目安は Q4_K_M 量子化時で約 1〜2GB(モデルファイル約 731MB)であり、少 VRAM の GPU や CPU のみの PC でも動作する。テキスト専用のため、画像入力には対応しない。開発元は本モデルを RAG・データ抽出・エージェント用途に推奨し、知識集約的な質問への単独利用は推奨していないため、本手順では動作確認用に位置づける。公式情報:https://www.liquid.ai/blog/introducing-lfm2-5-the-next-generation-of-on-device-ai
gemma4:e2b-it-qat(画像入力対応・軽量)
Google DeepMind のオープンモデル Gemma 4 シリーズの E2B モデル(E2B の「E」は有効パラメータ数(effective parameters)を表し、Per-Layer Embeddings(PLE)という、各層に小さな埋め込みを持たせて効率化する仕組みにより、総パラメータ数より少ない約 2.3B 相当の有効パラメータで動作する Dense モデルである)の QAT 版である。ダウンロード容量約 4.3GB、コンテキスト長 128K(131072 トークン)。テキストに加えて画像入力に対応し、思考モードを備える。ライセンスは Apache 2.0 とされる(Hugging Face 上の当該モデルのライセンスファイルで最新情報を確認すること)。
gemma4:12b-it-qat(画像入力対応・上位)
同シリーズの 12B モデルの QAT 版である。ダウンロード容量約 7.2GB、コンテキスト長 256K(262144 トークン)。e2b より規模が大きく、より高い推論能力を要する判定に適する。テキストに加えて画像入力に対応し、思考モードを備える。ライセンスは Apache 2.0 とされる(Hugging Face 上の当該モデルのライセンスファイルで最新情報を確認すること)。QAT による軽量化で 12B 規模でもメモリ 16GB クラスのノート PC で動作しうるが、ディスク空き容量・メモリに余裕のある環境を前提とする。
主要 Python パッケージ、埋め込みモデル
本手順で導入する主要 Python パッケージや埋め込みモデルの役割は次のとおり。
- open-webui:UI 本体である。インストール時に依存パッケージ(FastAPI、ChromaDB、sentence-transformers 等)が一括導入される。
- bge-m3:BAAI(北京智源人工知能研究院)が公開した多言語の埋め込みモデル(テキストを、意味を表す数値ベクトルに変換するモデル)である。日本語・英語を含む 100 以上の言語と最大 8192 トークンの入力に対応する。出力する Dense ベクトル(文全体の意味を 1 本のベクトルで表現したもの)は 1024 次元である。本手順では RAG の埋め込み(Ollama 経由)に用いる。
- bge-reranker-v2-m3:BAAI が公開した多言語の reranker(検索で得た候補を、質問との関連度で再順位付けするモデル)である。bge-m3 と同系統で多言語性能が高く、日本語・英語混在の検索結果の再順位付けに適する。本手順では Open WebUI の Reranking Model として用いる。初回は Hugging Face から約 1 GB のダウンロードが発生する。
- docling(発展節で使用):PDF・Word・PowerPoint 文書を解析するパーサである。Open WebUI と連携させて RAG の抽出エンジンとして使う場合は、別途 docling-serve を起動して接続する(後述の発展節を参照)。日本語 PDF、レイアウト付き文書、表・図・数式を含む文書の抽出精度が、標準抽出エンジンより向上する。
本手順の RAG は、文書解析(標準抽出エンジン、または発展節の Docling)、意味検索の埋め込み(bge-m3)、検索結果の再順位付け(bge-reranker-v2-m3)が担う。数式・図・グラフ・表を含む文書を扱う場合、これらを機械可読なテキストへ変換するのは前段の文書解析の役割であり、埋め込みモデルと reranker はその変換後のテキストを扱う。図表・数式を含む文書を高精度に扱うには、後述の発展節(Docling + docling-serve)の導入が要となる。
Python 3.12 のインストール
Pythonのインストールを行い、Pythonのプログラムを実行する環境を整える。扱う環境は、Windows搭載パソコンである。金子研究室では、Python 3.12.10を推奨する。
[Windows での Python 3.12 のインストール手順を見るには、ここをクリック]
Windows での Python 3.12 のインストール
以下のいずれかの方法でPython 3.12をインストールする。Pythonがインストール済みの場合、この手順は不要である。
方法 1:winget によるインストール
【インストールコマンドの実行方法】
管理者権限でコマンドプロンプトを起動する(手順:Windowsキーまたはスタートメニュー → cmd と入力 → 右クリック → 「管理者として実行」)。そして、コマンド全体をコマンドプロンプトにコピー&ペーストする。
--scope machine を指定することで、システム全体(全ユーザー向け)にインストールされる。このオプションの実行には管理者権限が必要である。インストール完了後、コマンドプロンプトを再起動するとPATHが反映される。
REM Python 3.12 をシステム領域にインストール
winget install --id Python.Python.3.12 -e --scope machine --silent --accept-source-agreements --accept-package-agreements --override "/quiet InstallAllUsers=1 PrependPath=1 Include_test=0 Include_pip=1 Include_launcher=1 InstallLauncherAllUsers=1 TargetDir=\"C:\Program Files\Python312\""
REM Python と Scripts を PATH 先頭に追加
powershell -NoProfile -Command "$p='C:\Program Files\Python312'; $s=\"$p\Scripts\"; $c=[Environment]::GetEnvironmentVariable('Path','Machine'); if((Test-Path $p) -and (';'+$c+';' -notlike \"*;$p;*\") -and (';'+$c+';' -notlike \"*;$s;*\")){[Environment]::SetEnvironmentVariable('Path',\"$p;$s;$c\",'Machine')}"
方法 2:インストーラーによるインストール
- Python公式サイト(https://www.python.org/downloads/)にアクセスし、「Download Python 3.x.x」ボタンからWindows用インストーラーをダウンロードする。
- ダウンロードしたインストーラーを実行する。
- 初期画面の下部に表示される「Add python.exe to PATH」にチェックを入れてから「Customize installation」を選択する。このチェックを入れ忘れると、コマンドプロンプトから
pythonコマンドを実行できない。 - 「Install Python 3.xx for all users」にチェックを入れ、「Install」をクリックする。
インストールの確認
コマンドプロンプトで以下を実行する。
python --versionバージョン番号(例:Python 3.12.x)が表示されればインストール成功である。「'python' は、内部コマンドまたは外部コマンドとして認識されていません。」と表示される場合は、インストールが正常に完了していない。
Build Tools・CUDA Toolkit・PyTorch のインストール
本章では、C++ ビルドツール、NVIDIA CUDA Toolkit、PyTorch のインストールを行い、GPU を活用した機械学習プログラムを実行する環境を整える。扱う環境は、Windows 搭載パソコンである。
[Build Tools・CUDA Toolkit・PyTorch のインストール手順を見るには、ここをクリック]
Windows での Build Tools for Visual Studio 2026 のインストール
Build Tools for Visual Studio 2026 は、C++ ソースコードを Windows 用バイナリにコンパイルするための開発ツール群である。unsloth 等の一部 Python パッケージは、インストール時に C++ コードのビルドを必要とするため、これらのツールが必須となる。
以下のコマンドは、Build Tools が未インストールの場合は winget で新規インストールし、インストール済みの場合は setup.exe modify でコンポーネントを追加する(バージョンは変更しない)。
【インストールコマンドの実行方法】
管理者権限でコマンドプロンプトを起動する(手順:Windows キーまたはスタートメニュー → cmd と入力 → 右クリック → 「管理者として実行」)。そして、コマンド全体をコマンドプロンプトにコピー&ペーストする。
REM VC++ ランタイム
winget install --scope machine --id Microsoft.VCRedist.2015+.x64 -e --silent --disable-interactivity --force --accept-source-agreements --accept-package-agreements --override "/quiet /norestart"
REM ============================================================
REM Visual Studio Build Tools + Desktop development with C++
REM (VCTools、MSBuildTools、CMake連携、Clang、Windows 11 SDK)
REM ============================================================
REM 進行中のインストーラーを停止(ロック競合回避)
taskkill /F /IM vs_setup.exe /T >nul 2>&1
taskkill /F /IM vs_installer.exe /T >nul 2>&1
taskkill /F /IM vs_installerservice.exe /T >nul 2>&1
REM 未インストール時: winget で新規インストール
REM インストール済み時: setup.exe modify でコンポーネント追加(バージョンは変更しない)
winget list --id Microsoft.VisualStudio.BuildTools 2>nul | findstr /i "BuildTools" >nul 2>&1
if %ERRORLEVEL% EQU 0 (
for /f "usebackq delims=" %P in (`"C:\Program Files (x86)\Microsoft Visual Studio\Installer\vswhere.exe" -products Microsoft.VisualStudio.Product.BuildTools -property installationPath`) do start /wait "" "C:\Program Files (x86)\Microsoft Visual Studio\Installer\setup.exe" modify --installPath "%P" --add Microsoft.VisualStudio.Workload.VCTools --add Microsoft.VisualStudio.Workload.MSBuildTools --add Microsoft.VisualStudio.Component.VC.CMake.Project --add Microsoft.VisualStudio.Component.VC.Llvm.Clang --add Microsoft.VisualStudio.Component.VC.Llvm.ClangToolset --add Microsoft.VisualStudio.Component.Windows11SDK.26100 --includeRecommended --quiet --norestart --nocache
) else (
winget install --scope machine --id Microsoft.VisualStudio.BuildTools -e --silent --disable-interactivity --force --accept-source-agreements --accept-package-agreements --override "--quiet --wait --norestart --nocache --add Microsoft.VisualStudio.Workload.VCTools --includeRecommended --add Microsoft.VisualStudio.Workload.MSBuildTools --add Microsoft.VisualStudio.Component.VC.CMake.Project --add Microsoft.VisualStudio.Component.VC.Llvm.Clang --add Microsoft.VisualStudio.Component.VC.Llvm.ClangToolset --add Microsoft.VisualStudio.Component.Windows11SDK.26100"
)
REM 破損時の修復(任意、動作がおかしくなった場合)
REM "C:\Program Files (x86)\Microsoft Visual Studio\Installer\setup.exe" repair --installPath "C:\Program Files (x86)\Microsoft Visual Studio\18\BuildTools" --quiet --norestart
REM 導入確認(インストールパスが表示されれば正常)
"C:\Program Files (x86)\Microsoft Visual Studio\Installer\vswhere.exe" -products * -requires Microsoft.VisualStudio.Workload.VCTools -property installationPath
上記のコマンドでは、Build Tools 本体と Visual C++ 再頒布可能パッケージをインストールし、続いて以下のコンポーネントを追加している。
- VCTools:C++ デスクトップ開発ワークロード(
--includeRecommendedにより、MSVC コンパイラ、C++ AddressSanitizer、vcpkg、CMake ツール、Windows 11 SDK 等の推奨コンポーネントが含まれる) - MSBuildTools:MSBuild によるビルドツールのワークロード
- VC.CMake.Project:Windows 向け C++ CMake ツール
- VC.Llvm.Clang:Windows 向け C++ Clang コンパイラ
- VC.Llvm.ClangToolset:MSBuild から Clang を使用するための clang-cl ツールセット
- Windows11SDK.26100:Windows 11 SDK(ビルド 10.0.26100)
追加のコンポーネントが必要になった場合は Visual Studio Installer で個別にインストールできる。
Windows での NVIDIA CUDA Toolkit のインストール
NVIDIA CUDA Toolkit は、NVIDIA GPU 上で計算を行うためのコンパイラ・ライブラリ群である。PyTorch や vLLM 等が GPU を利用するために必要となる。GPU を使用しない場合、この手順は不要である。
前提条件:NVIDIA GPU、NVIDIA ドライバ、Build Tools for Visual Studio もしくは Visual Studio が必要である。
インストール中の注意:他のウインドウは閉じておくこと。
【インストールコマンドの実行方法】
管理者権限でコマンドプロンプトを起動する(手順:Windows キーまたはスタートメニュー → cmd と入力 → 右クリック → 「管理者として実行」)。そして、コマンド全体をコマンドプロンプトにコピー&ペーストする。
REM NVIDIA CUDA Toolkit 12.8 をシステム領域にインストール
winget install --scope machine --id Nvidia.CUDA --version 12.8 -e --silent --disable-interactivity --force --uninstall-previous --accept-source-agreements --accept-package-agreements --override "-s -n"
REM 環境変数TEMP, TMPの設定(一時ファイルの保存先を短いパスに変更)
mkdir C:\TEMP
setx TEMP "C:\TEMP" /M
setx TMP "C:\TEMP" /M
環境変数 TEMP および TMP を C:\TEMP に変更しているのは、後続のインストール処理で長いパス名や空白を含むパス名がエラーの原因となる場合があるためである。
Windows での PyTorch のインストール
https://pytorch.org のインストールガイドに従い、自環境の CUDA バージョンに対応したコマンドを取得して実行する。CUDA バージョンは以下で確認できる。
nvcc --versionPython 3.12、CUDA 12.6 以上の場合は、管理者権限でコマンドプロンプトを起動し、以下を実行する。cu128 は CUDA 12.8 用のタグである。CUDA バージョンが異なる場合は、上記公式サイトで該当するタグを確認し、URL 末尾の cu128 を置き換えること。
pip install --no-user -U numpy torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu128以降の章では、必要に応じて題材に応じた必要なソフトウェアを追加する。
Ollama・モデル・Open WebUI のインストール
[Windows でのインストール・設定手順を見るには、ここをクリック]
本章では、Ollama、3 つのモデル(LFM2.5-1.2B-Instruct、gemma4:e2b-it-qat、gemma4:12b-it-qat)、埋め込みモデルbge-m3、Open WebUI、Gitのインストール手順を示す。
設定としては、Ollama の動作パラメータを Machine スコープの環境変数として設定しており、その内容は、Flash Attention の有効化(OLLAMA_FLASH_ATTENTION=1)、KV キャッシュの 8bit 量子化(OLLAMA_KV_CACHE_TYPE=q8_0)、コンテキスト長をデフォルトの 4096 から 262144 への拡張(OLLAMA_CONTEXT_LENGTH=262144)、モデル保存先の C:\Ollama\models への変更(OLLAMA_MODELS)である。Flash Attention は KV キャッシュの量子化に必要な高速化機能である。その他、gemma4:e2b-it-qat 起動用のスタートメニュー ショートカット作成を行う。
ハードウェアの前提
- ディスク空き容量 20GB 以上、メモリ搭載量 16GB 以上を推奨(モデル 3 種で合計約 12GB + Open WebUI 等)。少 VRAM の GPU や CPU のみの PC でも動作するが、gemma4:12b-it-qat は時間がかかる場合がある。
- 推論時のメモリ占有は 1 モデル分(モデル切替時に Ollama が自動でアンロードおよびロードを行う)。
ハードウェア要件の事前確定は難しい。新規に PC を準備する前に、現有の機器で本手順を試行し、性能面の問題の有無を確認したうえで、本格運用のハードウェアを決定する。
【インストールコマンドの実行方法】
管理者権限でコマンドプロンプトを起動する(手順:Windows キーまたはスタートメニュー → cmd と入力 → 右クリック → 「管理者として実行」)。winget の --scope machine オプションでシステム全体にインストールするには、管理者権限が必要である。実行時はコマンド全体をコマンドプロンプトにコピー&ペーストする。
REM ============================================================
REM 管理者権限チェック
net session >nul 2>&1
if errorlevel 1 ( echo [エラー] 管理者権限で実行してください & pause & exit /b 1 )
REM winget パッケージ一覧のローカルキャッシュを更新
winget source update
REM === 1. Ollama 環境変数を Machine スコープで事前設定 ===
REM インストール前に設定することで、Ollama 起動時から正しい設定が読み込まれる
powershell -NoProfile -Command "[System.Environment]::SetEnvironmentVariable('OLLAMA_FLASH_ATTENTION', '1', 'Machine')"
powershell -NoProfile -Command "[System.Environment]::SetEnvironmentVariable('OLLAMA_KV_CACHE_TYPE', 'q8_0', 'Machine')"
REM コンテキスト長:Ollama のデフォルトは 4096。
REM ここでは gemma4:12b-it-qat の上限 262144 に設定する
powershell -NoProfile -Command "[System.Environment]::SetEnvironmentVariable('OLLAMA_CONTEXT_LENGTH', '262144', 'Machine')"
powershell -NoProfile -Command "[System.Environment]::SetEnvironmentVariable('OLLAMA_MODELS', 'C:\Ollama\models', 'Machine')"
set "OLLAMA_FLASH_ATTENTION=1"
set "OLLAMA_KV_CACHE_TYPE=q8_0"
set "OLLAMA_CONTEXT_LENGTH=262144"
set "OLLAMA_MODELS=C:\Ollama\models"
REM === 2. 既存の Ollama プロセスを停止(ファイルロック解除のため) ===
taskkill /IM ollama.exe /F >nul 2>&1
taskkill /IM "ollama app.exe" /F >nul 2>&1
REM === 3. モデルフォルダの作成と権限設定 ===
if not exist "C:\Ollama\models" mkdir "C:\Ollama\models"
icacls "C:\Ollama\models" /grant *S-1-5-32-545:(OI)(CI)(M) /T /C
REM === 4. 既存モデルの移動(ユーザープロファイルに残っている場合) ===
REM Ollama 停止状態で実行するためファイルロックが起きない
if exist "%USERPROFILE%\.ollama\models" robocopy "%USERPROFILE%\.ollama\models" "C:\Ollama\models" /E /MOVE
if exist "%USERPROFILE%\.ollama\models" rd /s /q "%USERPROFILE%\.ollama\models"
REM === 5. winget パッケージ一覧のローカルキャッシュを更新 ===
winget source update
REM === 6. Ollama のインストール(Inno Setup) ===
winget uninstall --id Ollama.Ollama -e --silent --disable-interactivity --accept-source-agreements
REM uninstall 後にプロセスが残ることがあるため再度停止
taskkill /IM ollama.exe /F >nul 2>&1
taskkill /IM "ollama app.exe" /F >nul 2>&1
winget install --id Ollama.Ollama -e --silent --disable-interactivity --force --accept-source-agreements --accept-package-agreements --custom "/DIR=C:\Ollama"
winget upgrade --id Ollama.Ollama -e --silent --disable-interactivity --force --accept-source-agreements --accept-package-agreements --custom "/DIR=C:\Ollama"
REM === 7. Ollama のパス設定(システム PATH に未登録の場合のみ追加) ===
powershell -NoProfile -Command "$p='C:\Ollama'; $c=[Environment]::GetEnvironmentVariable('Path','Machine'); if((Test-Path $p) -and (';'+$c+';' -notlike \"*;$p;*\")){[Environment]::SetEnvironmentVariable('Path',\"$c;$p\",'Machine')}"
REM Ollama のパスを現在のセッションに反映
set "PATH=C:\Ollama;%PATH%"
REM === 8. Ollama サービスの起動(モデルダウンロードの前に必要) ===
where ollama >nul 2>&1
if errorlevel 1 echo Ollama のパスが見つかりません。再起動後に再実行してください。 & exit /b 1
tasklist /fi "imagename eq ollama.exe" | find "ollama.exe" 2>&1
if errorlevel 1 start "" "C:\Ollama\ollama.exe" serve & timeout /t 10 /nobreak
REM === 9. モデルのダウンロード ===
REM 動作確認用(テキスト専用、約 731MB)。
echo LFM2.5-1.2B-Instruct モデルをダウンロード中...
ollama pull LiquidAI/lfm2.5-1.2b-instruct
REM 画像入力対応(軽量、約 4.3GB)
echo gemma4:e2b-it-qat モデルをダウンロード中...
ollama pull gemma4:e2b-it-qat
REM 画像入力対応(上位、約 7.2GB)
echo gemma4:12b-it-qat モデルをダウンロード中...
ollama pull gemma4:12b-it-qat
echo モデルダウンロード完了
REM === 10. 埋め込みモデルのダウンロード(RAG 演習で使用) ===
echo bge-m3 埋め込みモデルをダウンロード中...
ollama pull bge-m3
echo 埋め込みモデルダウンロード完了
REM === 11. Open WebUI のインストール ===
REM open-webui パッケージにより、依存パッケージ(FastAPI、ChromaDB、
REM sentence-transformers 等)が一括インストールされる
python -m pip install --no-user --upgrade pip
python -m pip install --no-user --upgrade open-webui
python -m pip uninstall -y open-webui
python -m pip install --user --upgrade open-webui
REM === 12. Git のインストール ===
winget install --scope machine --id Git.Git -e --silent --disable-interactivity --force --accept-source-agreements --accept-package-agreements --override "/VERYSILENT /NORESTART /NOCANCEL /SP- /CLOSEAPPLICATIONS /RESTARTAPPLICATIONS /COMPONENTS=""icons,ext\reg\shellhere,assoc,assoc_sh"" /o:PathOption=Cmd /o:CRLFOption=CRLFCommitAsIs /o:BashTerminalOption=MinTTY /o:DefaultBranchOption=main /o:EditorOption=VIM /o:SSHOption=OpenSSH /o:UseCredentialManager=Enabled /o:PerformanceTweaksFSCache=Enabled /o:EnableSymlinks=Disabled /o:EnableFSMonitor=Disabled"
REM Git のパスを現在のセッションに反映
set "PATH=C:\Program Files\Git\cmd;%PATH%"
REM === 13. スタートメニュー ショートカット作成 ===
REM gemma4:e2b-it-qat 起動ショートカット(CUI で質問・応答を行う)
powershell -NoProfile -Command "$s=New-Object -ComObject WScript.Shell; $l=$s.CreateShortcut([Environment]::GetFolderPath('CommonPrograms')+'\Ollama Gemma4 e2b.lnk'); $l.TargetPath='cmd.exe'; $l.Arguments='/k \"start cmd /k ollama serve ^& timeout /t 3 /nobreak ^>nul ^& ollama run gemma4:e2b-it-qat\"'; $l.Save()"
echo インストール完了
演習 1.基本動作確認(CUI)
Ollama 自体が動作することを確認する。本演習のみコマンドプロンプト(CUI)で行い、LLM のローカル実行(外部サーバへの送信を伴わず、手元のマシン内で完結する推論)を体験する。以降の演習はすべてブラウザ(Open WebUI)で行う。
手順
- Ollama でモデル LFM2.5-1.2B-Instruct を実行する
- コマンドプロンプトを開き、Ollama を起動する(
ollama serve)。次のメッセージが出た場合は、すでに Ollama が起動中なので、問題ない。続行する。

- 別のコマンドプロンプトで、モデル LFM2.5-1.2B-Instruct を選んで実行する(
ollama run LiquidAI/lfm2.5-1.2b-instruct)。
- コマンドプロンプトを開き、Ollama を起動する(
- プロンプト記号
>>>が表示されたら、質問を入力する(例:「日本の首都はどこですか?」)。
- 応答が返ることを確認する。
/byeを入力して終了する。
ヒント
- 初回起動時は、モデルのメモリへのロードに時間を要する(LFM2.5-1.2B-Instruct は軽量のため比較的短時間で完了する)。
- 応答の生成中に中断する場合は Ctrl+C を押す。
ollama serve用ウィンドウは閉じずに残しておく。サーバに接続できない場合は、別のコマンドプロンプトでollama serveを実行してサーバを起動してから、再度モデルを実行する。- 登録済みモデルの一覧は別のコマンドプロンプトで
ollama listで確認できる(LFM2.5-1.2B-Instruct、gemma4:e2b-it-qat、gemma4:12b-it-qat、bge-m3 が表示される)。 - 後述のヒントで触れるスタートメニューの『Ollama LFM2.5 1.2B』は、インストール手順(Ollama・モデル・Open WebUI のインストール)で作成されるショートカットである。
考察ポイント
- モデルが質問に対して応答を返すか(本演習の目的は応答経路の動作確認であり、応答内容の正確性は問わない)。
- 応答が返るまでの時間が、初回ロードと 2 回目以降でどう異なるか。
ollama listに 3 つの LLM と埋め込みモデル bge-m3 が登録されているか。
演習 2.RAG なしでチャット(ブラウザ)
Open WebUI(フロントエンド)から Ollama(バックエンド)の LLM を呼び出す経路が機能することを、RAG を使わない素のチャットで確認する。本構成はフロントエンドとバックエンドが分離されており、Open WebUI は HTTP 経由で Ollama に問い合わせる。
Open WebUI の起動
通常のコマンドプロンプトを開いて以下を実行する。「管理者として実行」しないこと。
%USERPROFILE%\AppData\Roaming\Python\Python312\Scripts\open-webui serve
Python312 は Python 3.12 を表す。Python 3.11 をインストールしている場合は、この部分を Python311 に読み替える。起動には初回 30 秒〜1 分かかる。

コマンドプロンプトに Uvicorn running on http://0.0.0.0:8080 と表示された後、自動でブラウザが http://localhost:8080 を開く(開かない場合は手動で開く)。

初回アクセス時は管理者アカウント作成画面が表示される。氏名・メールアドレス・パスワードを入力してアカウントを作成する(メールアドレスは Open WebUI 内のローカル認証用であり、外部送信は行われない。実在しないメールアドレスでも作成できる)。

手順
- ログイン後、画面左上のモデル選択ドロップダウンを開き、LFM2.5-1.2B-Instruct を選択する。
- 画面下部のチャット入力欄に質問(例:「日本の首都はどこか。」)を入力して送信する。
- 応答が返ることを確認する。
- モデル選択ドロップダウンから gemma4:e2b-it-qat に切り替え、同じ質問を送信して応答を確認する。思考モードを持つ gemma4 系モデルでは、「思考モードを使って、日本語の敬語がなぜ複雑に発達したか説明せよ。」のような質問も試すと、内部の推論過程が観察できる。

- モデル選択ドロップダウンから gemma4:12b-it-qat に切り替え、同じ質問を送信して応答を確認する。
ヒント
- モデルがドロップダウンに表示されない場合、
ollama serveが起動しているか確認する。起動していない場合は、スタートメニューの「Ollama LFM2.5 1.2B」(インストール手順で作成されたショートカット)を一度実行してから再度確認する。 - gemma4 系モデルは思考モード(応答前に内部で推論過程を生成する機能)を備える。設定で、思考モードのオン・オフを切り替えることができる。

考察ポイント
- ブラウザで
http://localhost:8080にアクセスできるか。 - モデル選択ドロップダウンに 3 つの LLM が表示されるか。
- 選択したモデルから応答が返るか。
- 同じモデルを CUI(演習 1)とブラウザ UI(本演習)で呼び出した場合、応答内容に差があるか。同じモデルでも、UI 経由ではシステムプロンプトや既定パラメータ(温度等)が異なる場合があり、応答に差が出ることがある。
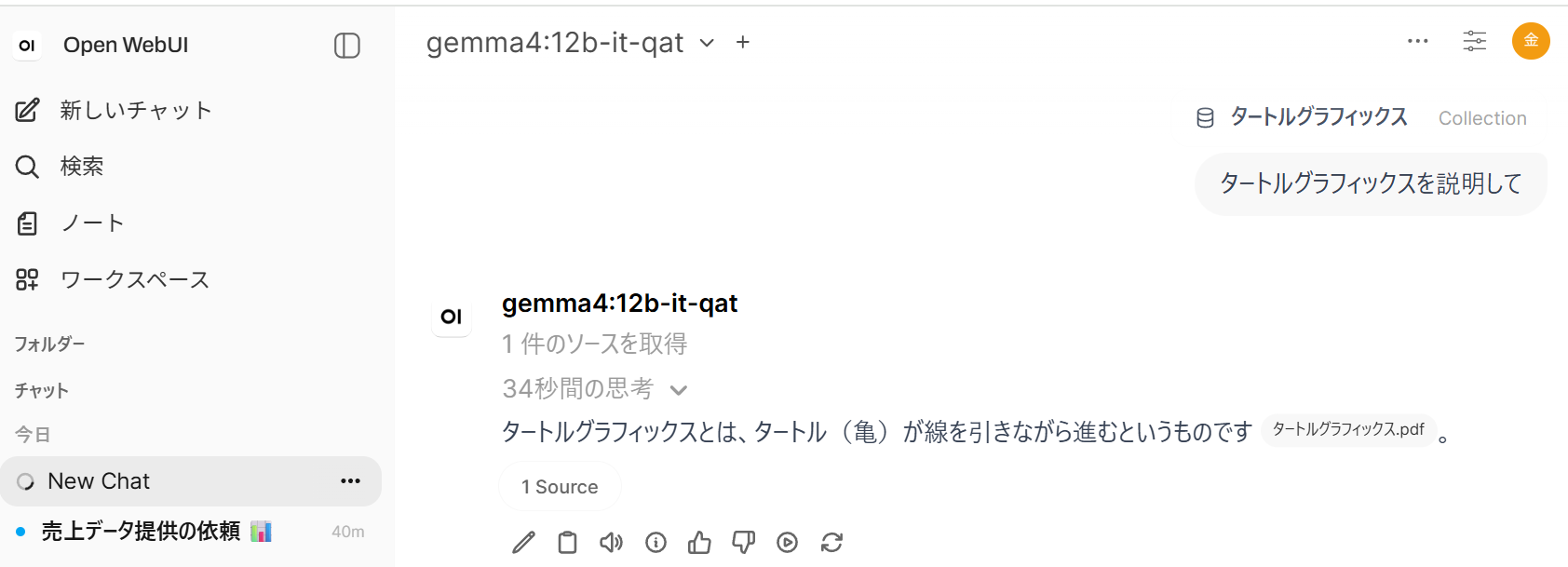
演習 3.RAG なしで図を理解させてチャット(ブラウザ)
画像入力に対応したモデル(gemma4 系)に図(画像)を直接添付し、モデル自身のマルチモーダル能力だけで図の内容を読み取らせる。LFM2.5-1.2B-Instruct はテキスト専用のため本演習には使えない。本演習では gemma4:e2b-it-qat または gemma4:12b-it-qat を用いる。
準備するファイル
- 図・グラフ・表のいずれかを含む画像 1 つ(PNG・JPEG 等)。例:棒グラフや折れ線グラフの画像、数値が入った表の画像、簡単な数式を写した画像。機密情報を含まないものを選ぶ。
- 手元に適当な画像がなければ、表計算ソフトで作ったグラフをスクリーンショットして用いてもよい。
手順
- Open WebUI のチャット画面でモデル
gemma4:12b-it-qat(またはgemma4:e2b-it-qat)を選択する。 - 新しいチャットを開始し、チャット入力欄のクリップ(添付)アイコンから、準備した画像を添付する。
- 同じ入力欄に質問を入力して送信する。図の種類に応じて、たとえば次のように問う:
- グラフの場合:
この画像のグラフは何を表しているか。読み取れる最大値とその項目を答えよ。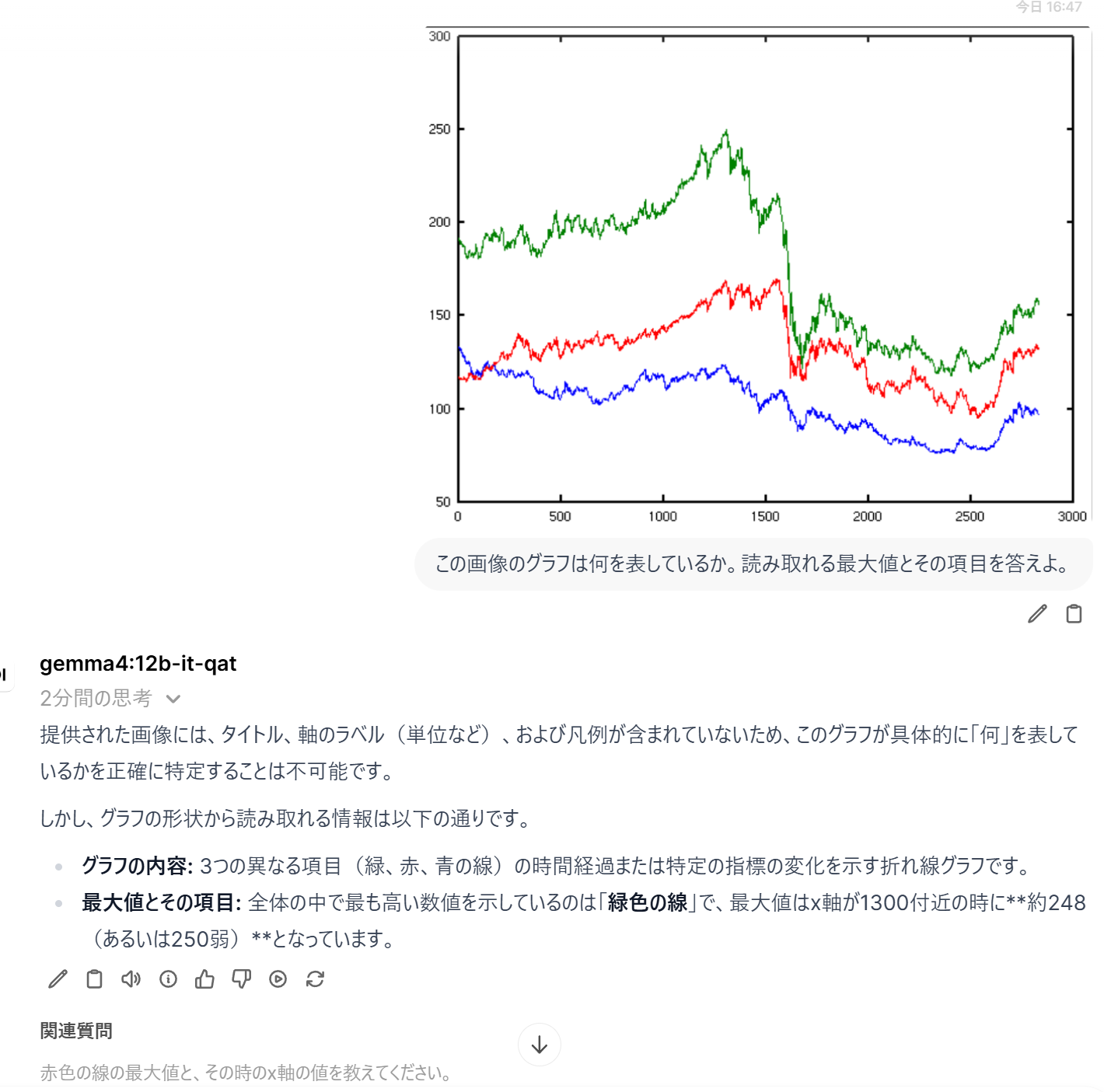
- 表の場合:
この画像の表から、合計値と、最も大きい数値の行を答えよ。
- 数式の場合:
この画像に写っている数式を読み取り、テキストで書き起こせ。
- グラフの場合:
- 応答内容を確認する。
- モデルを別のものに切り替え、同じ画像と質問で応答を比較する。
ヒント
- 画像入力が機能するには、選択中のモデルが画像対応(gemma4 系)である必要がある。テキスト専用の LFM2.5-1.2B-Instruct を選んだ状態では画像を解釈できない。
- 画像は Ollama 経由でモデルに渡される。外部サーバへは送信されない(ローカル完結)。
- 図中テキストや数式が小さい・不鮮明な場合、読み取り精度が下がる。鮮明な画像を用いる。
考察ポイント
- モデルが図の種類(グラフ・表・数式)を正しく認識し、内容を説明できたか。
- 数値の読み取り(最大値、合計、特定セルの値など)は正確か。誤読があればどの箇所か。
- gemma4:12b-it-qat と gemma4:e2b-it-qat で、読み取りの精度や詳しさに差があるか。
- 本演習は「画像そのものをモデルに直接見せる」方式である。次の演習 4(RAG 経由)との違い(RAG では文書から抽出されたテキストを介する)を意識する。
演習 4.RAG ありで図を含む文書を扱う(ブラウザ)
Open WebUI の Knowledge(文書を登録して RAG の検索対象にする機能)を用いて RAG の一連の流れを体験し、あわせて、図・表を含む文書を標準(Default)抽出エンジンで取り込んだ場合の限界を観察する。本演習では、演習 3 の「画像をモデルに直接見せる」方式と、RAG の「文書から抽出したテキストを介する」方式の違いを比較する。
準備 1:RAG の初期設定
- 画面右上のユーザーアイコン(または左下のアカウント名)をクリックし、「管理者パネル(Admin Panel)」を開く。
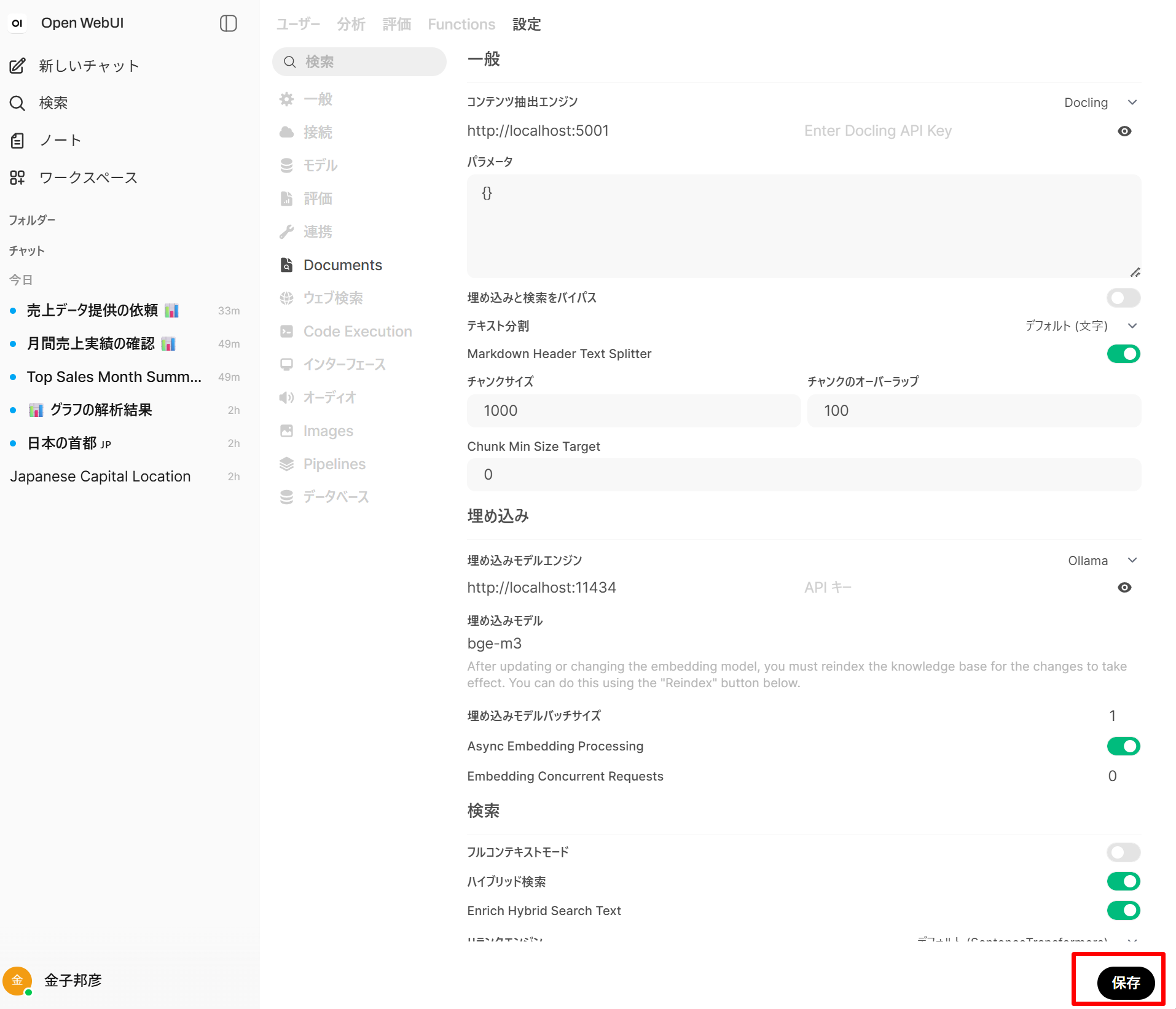
「設定(Settings)」→「ドキュメント(Documents)」を開く。
- 埋め込みモデル:「Embedding Model Engine」を
Ollamaに設定し、「Embedding Model」にbge-m3を入力する。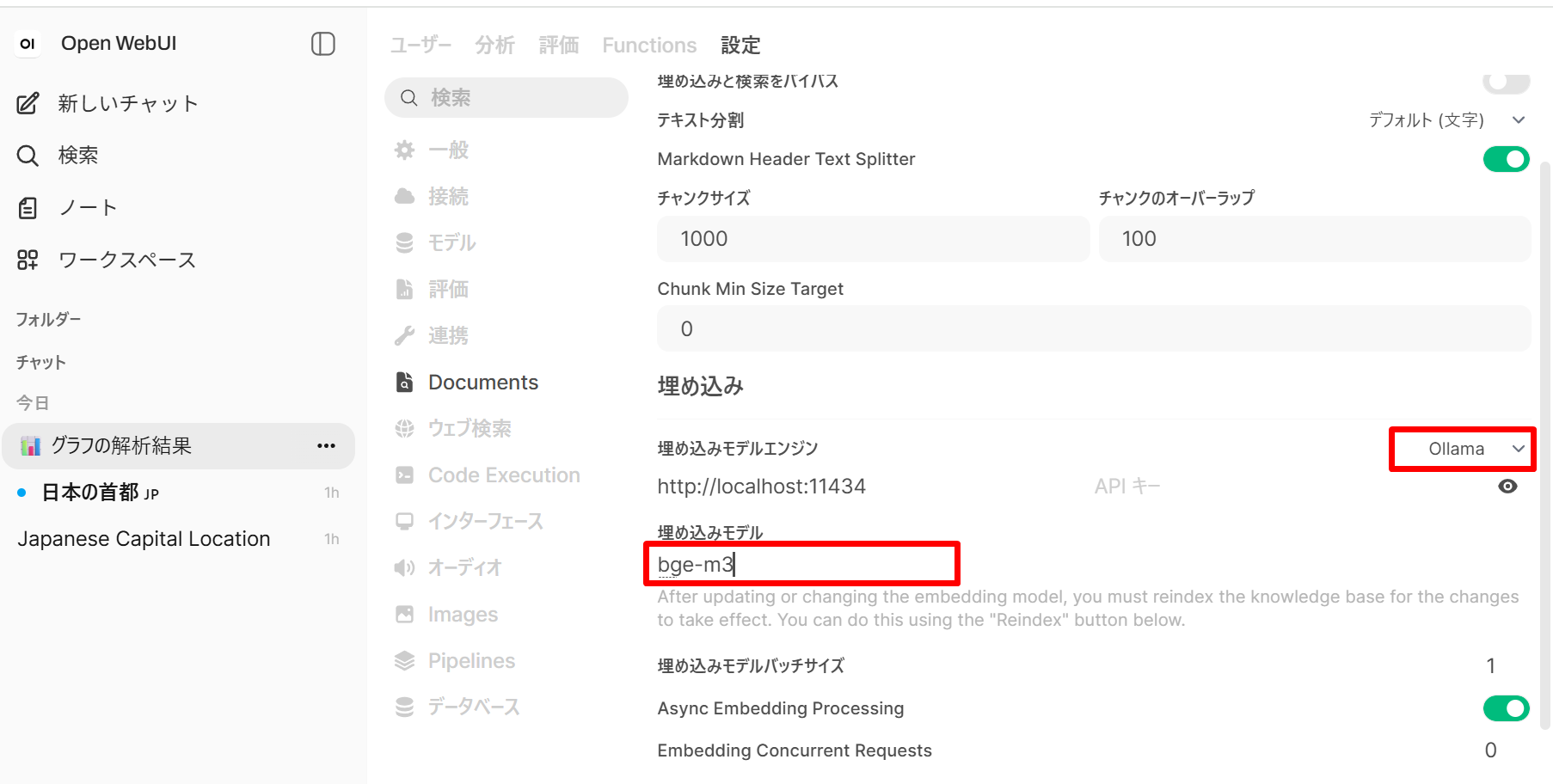
- ハイブリッド検索(Hybrid 検索)(ベクトル検索とキーワード検索を併用する検索方式)をオン、
Enrich Hybrid Search Text(ユーザの質問を LLM で言い換え・拡張してからハイブリッド検索を行う機能。クエリの表現揺れを補い検索精度の向上が期待できる)をオン、
リランクモデル(Reranking Model)に
BAAI/bge-reranker-v2-m3を設定(Hugging Face から自動ダウンロードされる。初回は約 1 GB のダウンロードが発生する)。 トップK(Top K)を5〜10の範囲で設定する(再順位付け後に LLM に渡す上位件数)。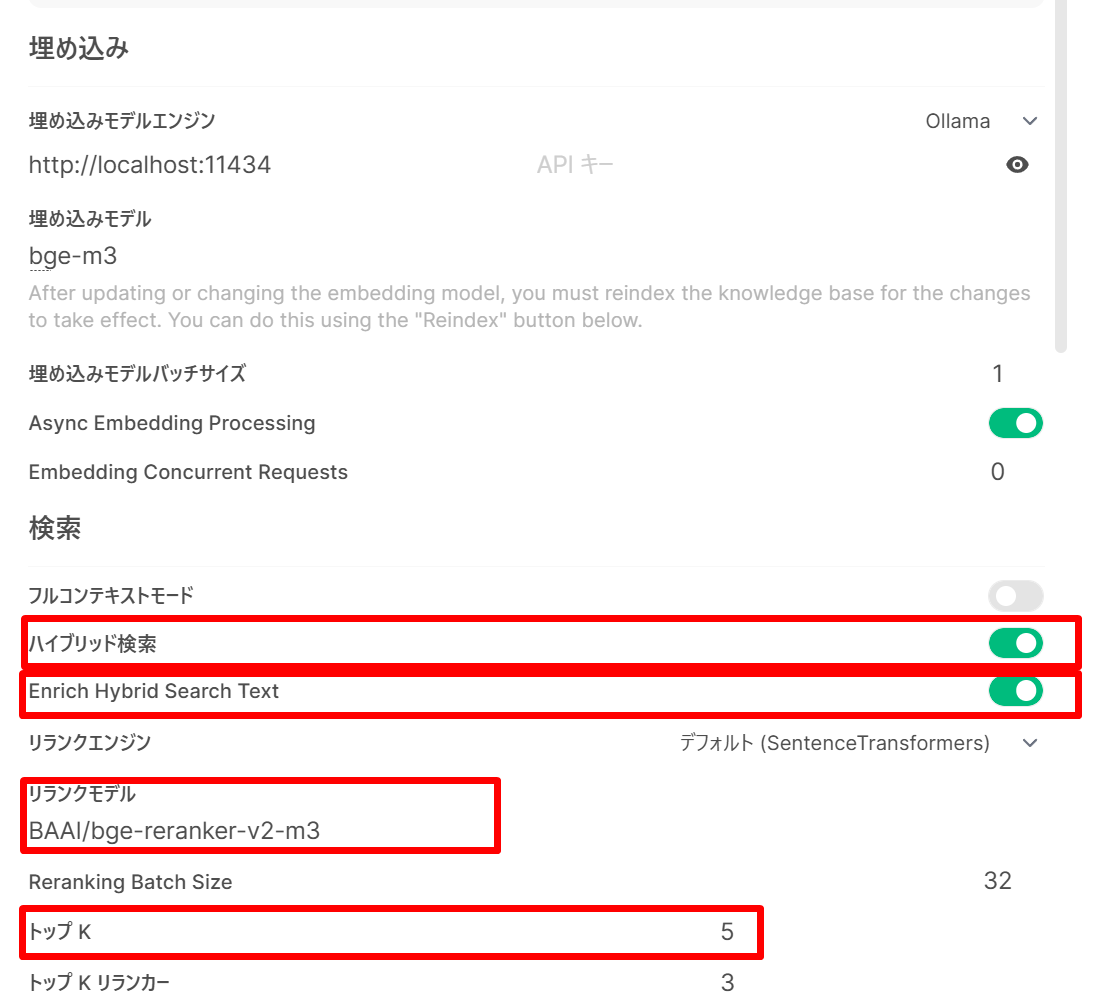
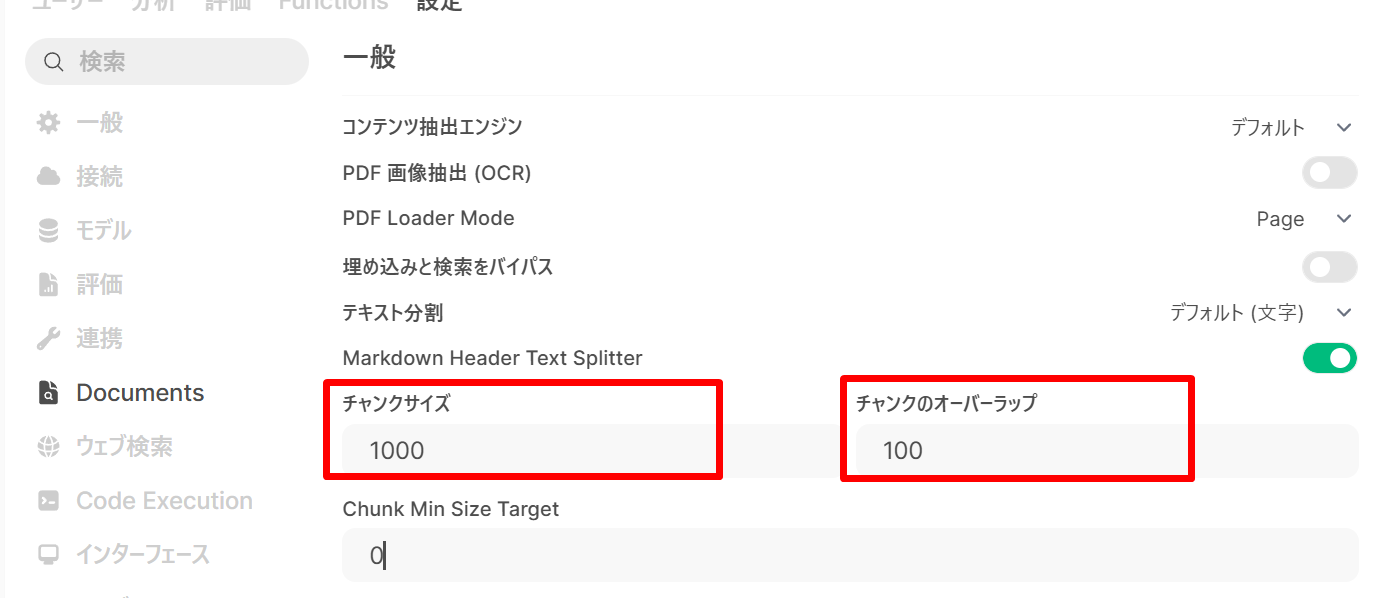
- チャンク(長文を埋め込み計算のために分割した単位)の設定
チャンクサイズ(Chunk Size)を
1000〜1500トークン、 チャンクのオーバーラップ(Chunk Overlap)(チャンク間の重複量。境界で文脈が途切れることを防ぐ)を100〜200トークンに設定する。
- 「Content Extraction Engine」は
Default(Open WebUI 内蔵)のままとする(発展のときに Docling へ切り替える)。 - 「保存(Save)」をクリック。
準備 2:テスト用文書の作成
- メモ帳で以下のような表を含む文書を作成する:
架空商店 月別売上表 月 売上(万円) 来客数(人) 1月 120 300 2月 95 250 3月 150 380 4月 130 340 備考:3月は新商品の発売により売上・来客数ともに最大となった。 - 「ファイル → 名前を付けて保存」で、エンコードを
UTF-8に設定し 保存する。保存のときのファイル名を覚えておく。 - 余裕があれば、図・表を含む PDF も別途用意し、同様にアップロードして比較するとよい(PDF の図・表は標準抽出エンジンでは構造が崩れやすい)。
手順
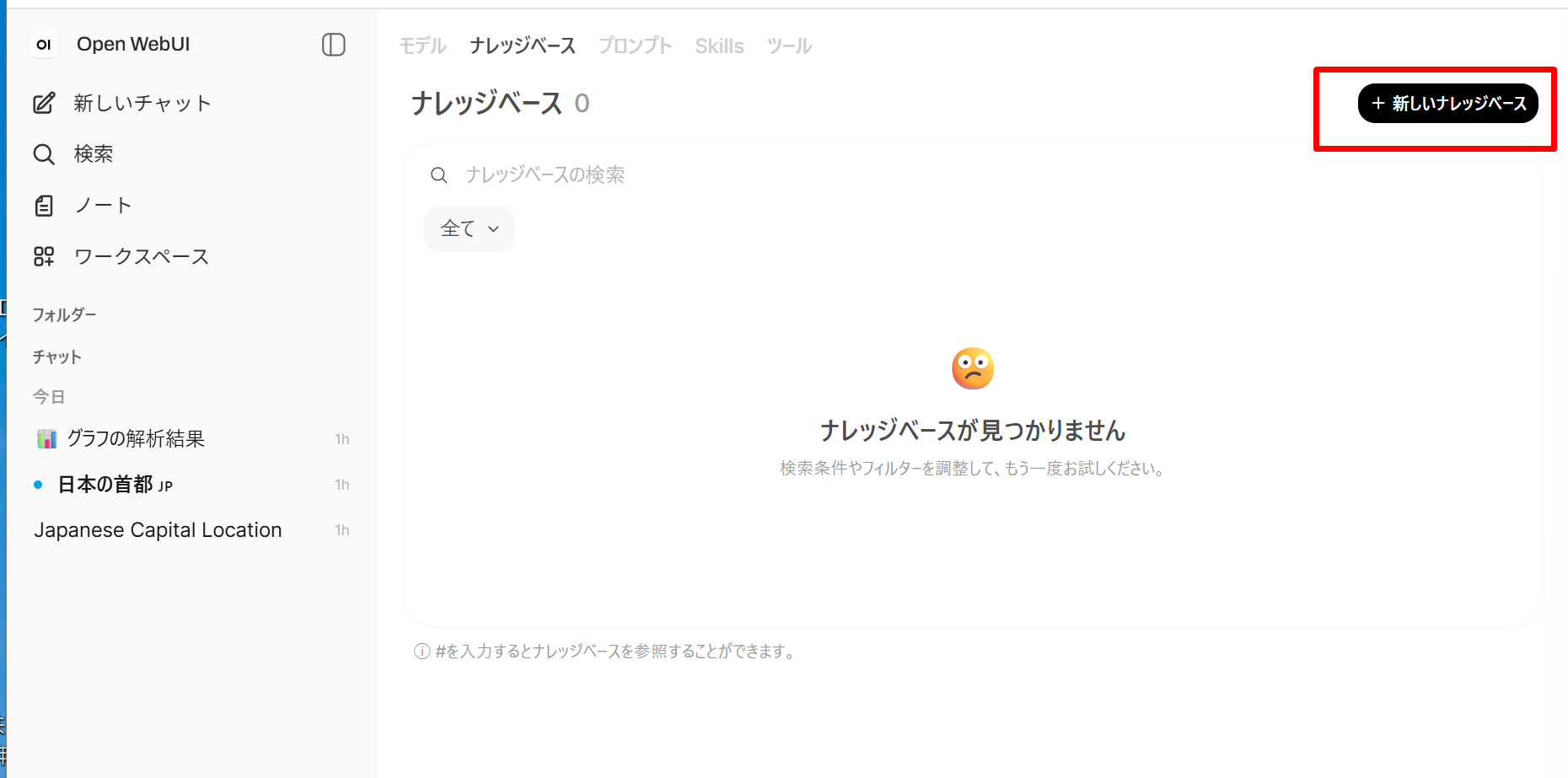
- 画面左側のメニューから「ワークスペース(Workspace)」→「ナレッジベース
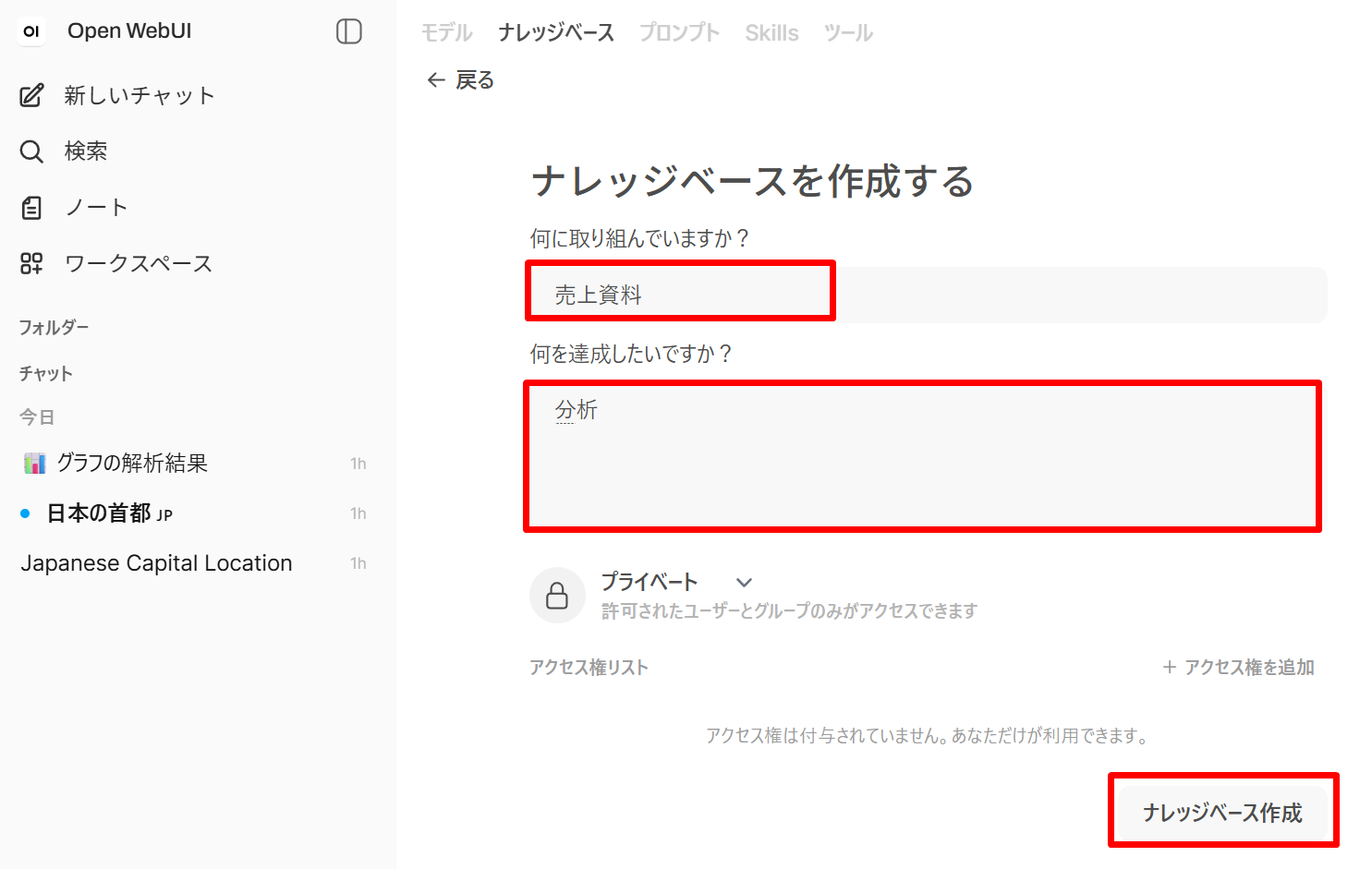
(Knowledge Base)」を開き、「+ 新しいナレッジベース」ボタンで新規 Knowledge を作成する。名前を「売上資料」とする。

- 作成された Knowledge を開き、「ファイルをアップロード」から先ほど作成したファイルをアップロードする。
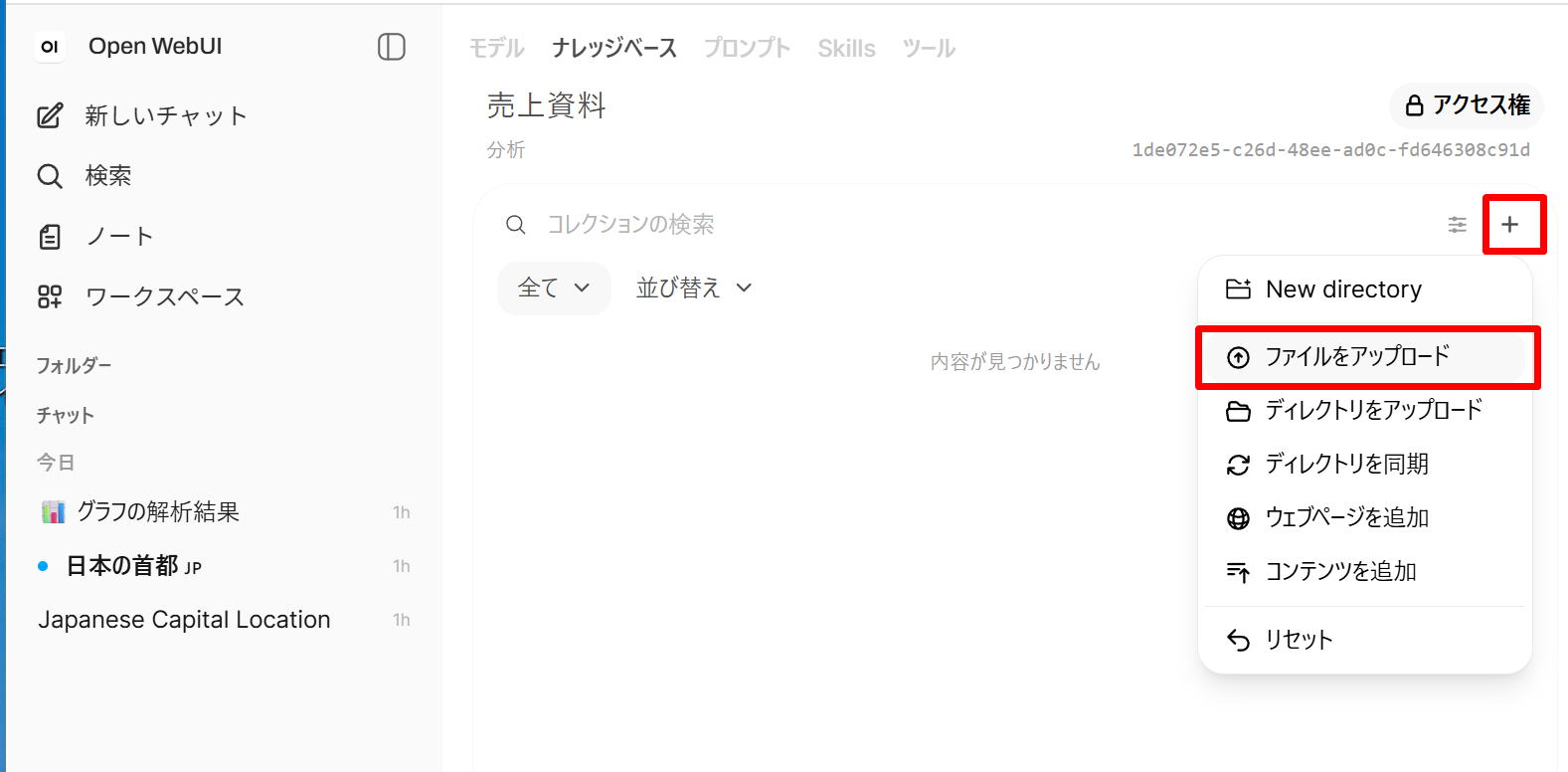
アップロード時に内部で、(a)テキスト抽出、(b)チャンク分割、(c)
bge-m3による埋め込み生成、(d)ChromaDB(Open WebUI 内蔵のベクトルデータベース)へのベクトル登録が順に実行される。完了マークが表示されるまで待つ。 - 左メニューの「新しいチャット(New Chat)」をクリックし、モデルを選択する。
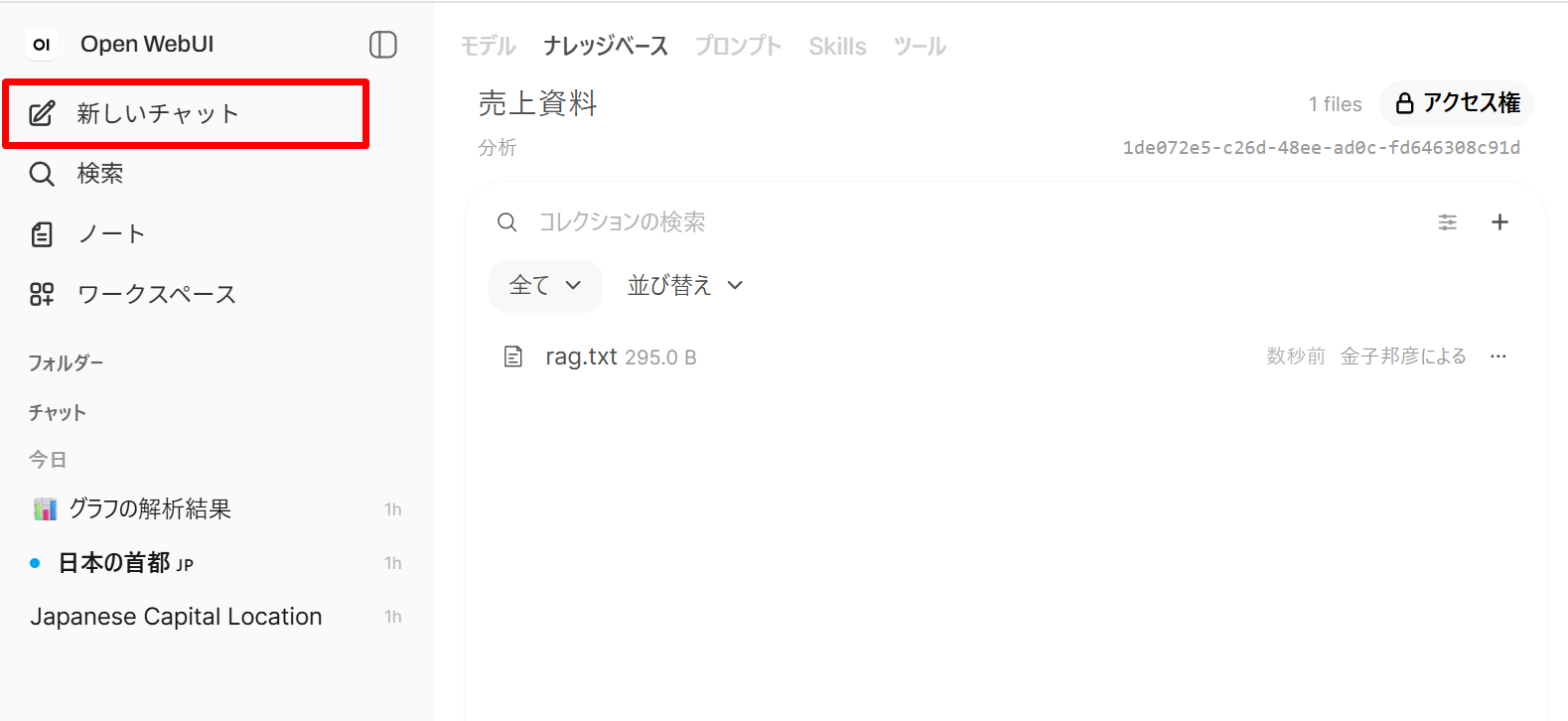
- チャット入力欄で半角の
#を入力し、現れた候補から「売上資料」を選択する。入力欄上部に Knowledge 名のチップ(選択中であることを示すラベル)が表示されることを確認する。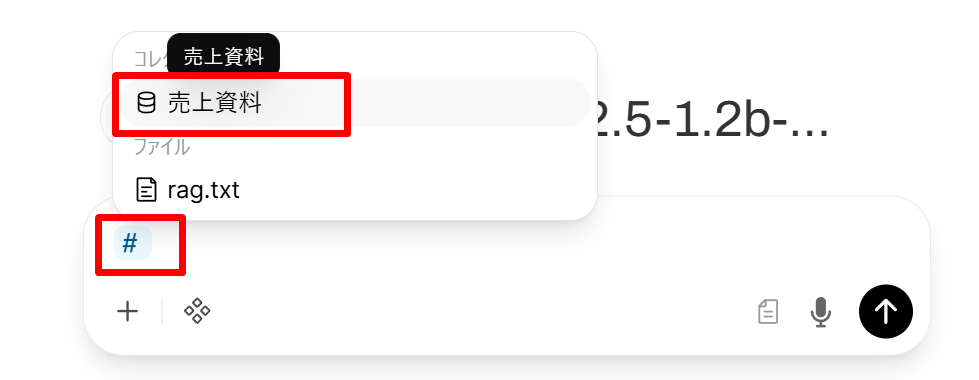
- 以下の質問を順に送信し、応答を確認する:
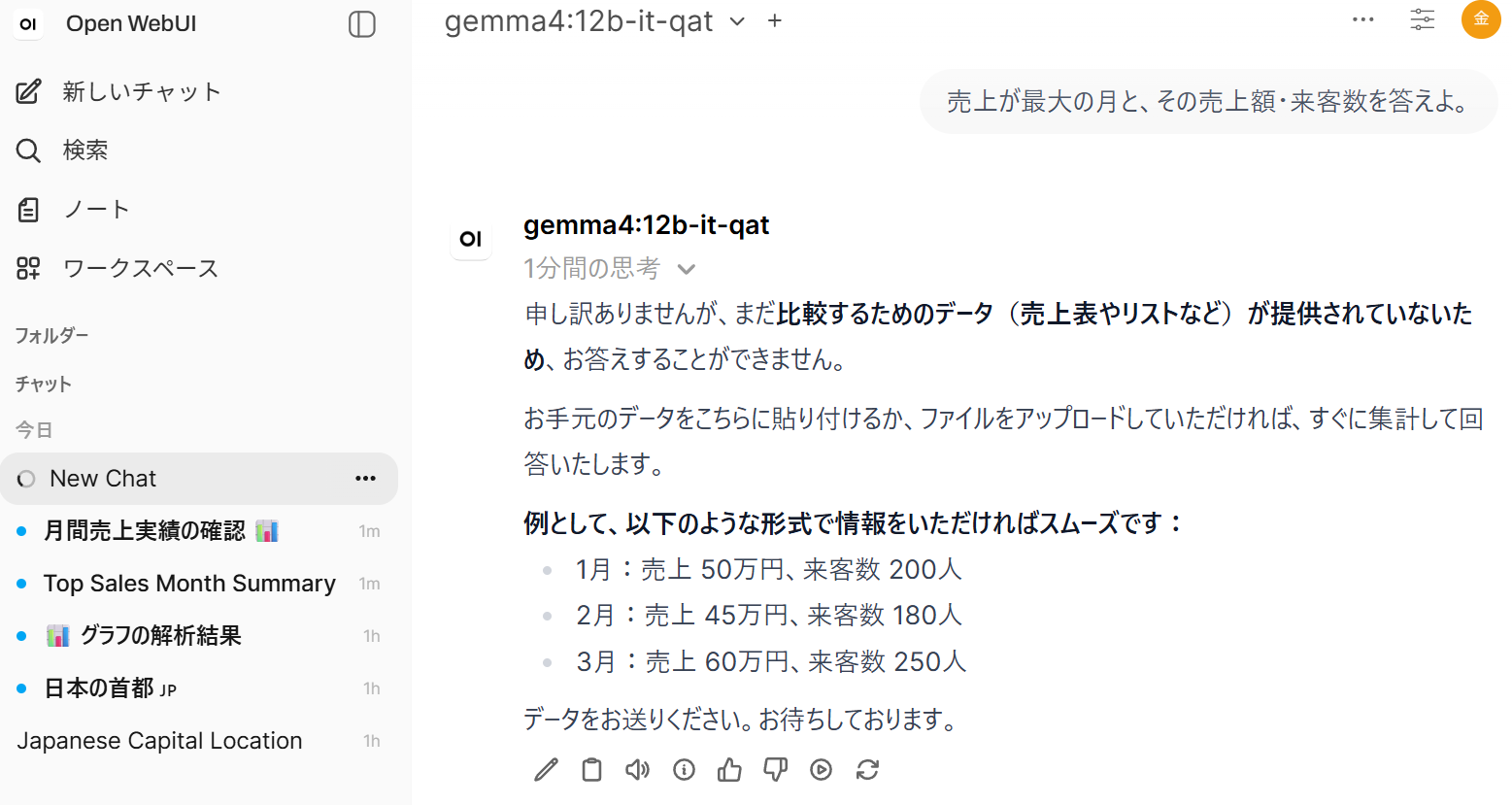
- 質問 A(直接記載):
売上が最大の月と、その売上額・来客数を答えよ。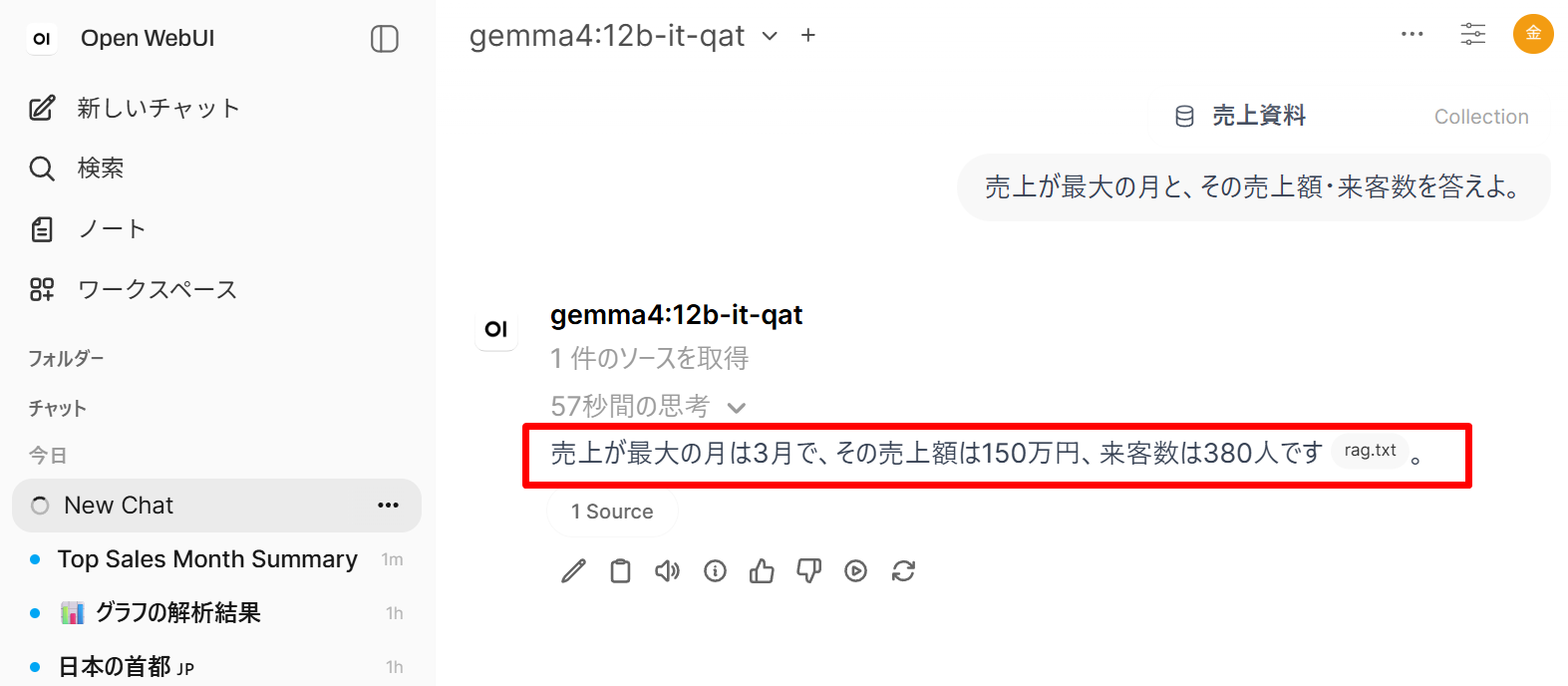
- 質問 B(複数行の参照):
1 月から 4 月までの売上の合計額を求めよ。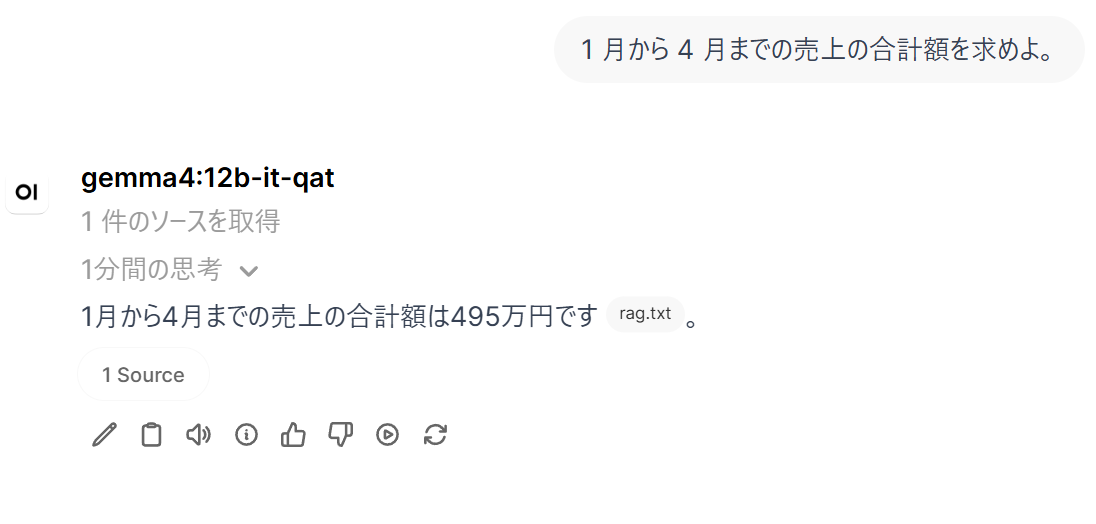
- 質問 A(直接記載):
- 応答に出典表示(参照元のファイル名やチャンクへの参照)が付与される場合は、その表示も確認する。
- 比較のため、「新しいチャット」を開始し、今度は Knowledge を選択せず、同じモデルで同じ質問を送信して応答を比較する。
ヒント
- 初回アップロード時、埋め込み生成のため Ollama の
bge-m3が呼び出される。Ollama サービスが起動していることが必須である。 - Knowledge を選択すると、質問送信時に Knowledge 内の文書チャンクが意味的類似度で検索され、上位 K 件(設定した Top K)がプロンプトに付加される。Knowledge を選択しない場合、モデルは事前学習データのみに基づいて応答するため、架空の表の内容は知り得ない。「情報がない」と返すか、根拠のない内容を生成する(ハルシネーション)かは、モデルとプロンプトに依存する。RAG は、このハルシネーションを抑制する目的でも用いられる。
- 本演習のテキスト形式は、標準抽出エンジンでも比較的扱える。一方、PDF 内の図・表は標準抽出エンジンでは構造(行・列の対応)が崩れやすく、ここに発展節の Docling 導入の意義がある。
考察ポイント
- 質問 A・B について、Knowledge を使用した応答に、文書中の具体的な数値(3 月、150 万円、380 人、合計 495 万円)が正しく反映されているか。
- Knowledge を使用しない応答では、表の内容を答えられず、「情報がない」と返すか、根拠のない数値を生成するか。
- 演習 3(画像を直接見せる)と本演習(RAG 経由でテキスト化された文書を見せる)とで、図・表の扱いにどのような違いがあるか。図そのものの視覚的特徴(色・形・位置関係)は、RAG 経由では失われやすいことを確認できるか。
- PDF の図・表を試した場合、標準抽出エンジンで表の行・列の対応が崩れていないか。崩れている場合、発展節の Docling でどう改善すると予想されるか。
発展:Docling による図表・数式を含む文書の高精度抽出(Docker + docling-serve)
本節は発展ステップである。演習 4 までは Open WebUI の標準(Default)抽出エンジンで完結する。しかし、表・図・グラフ・数式・化学式・図中テキストを含む文書を扱う場合、標準抽出エンジンはこれらの構造を十分に保持できず、表のセルの対応が崩れたり、図中のテキストや数式が取り込まれなかったりする。Docling を Open WebUI の抽出エンジンとして接続すると、表を構造ごと、図中テキストを OCR で、レイアウトを保持したまま取り込めるようになり、RAG の検索・回答精度が向上する。テキスト中心の文書のみを扱う場合は、本節は省略してよい。
Open WebUI で Docling を使うには、Docling を pip install するだけでは不十分で、Docling のサーバ版である docling-serve を別プロセス(Docker コンテナ)として起動し、その URL を Open WebUI に登録する必要がある。Docker は、アプリケーションをコンテナという独立した単位で動かすソフトウェアである。本節では Docker を初めて使用する。
前提条件
- Docker Desktop for Windows がインストールされ、起動していること(次の手順 1 で導入する)。
- Open WebUI が動作していること(演習 2 まで完了していること)。
【手順 1:Docker Desktop のインストール】
管理者権限でコマンドプロンプトを起動する
(手順:Windowsキーまたはスタートメニュー → cmd と入力 → 右クリック → 「管理者として実行」)。
続いて、次を実行する:
REM Docker Desktop のインストール
winget install --id Docker.DockerDesktop -e --silent --disable-interactivity --accept-source-agreements --accept-package-agreements
インストール後、Windows の再起動が必要な場合がある。再起動後、スタートメニューから Docker Desktop を起動し、初回セットアップ(WSL 2 バックエンドの有効化等)を完了させる。
【手順 2:docling-serve コンテナの起動】
Docker Desktop が起動した状態で、新しいコマンドプロンプト(管理者権限不要)を開き、用途に応じて次のいずれかを実行する。コンテナはポート 5001 で待ち受ける。UVICORN_WORKERS=1 は、複数ワーカー時に発生する「Task Not Found」エラーを避けるための設定である。DOCLING_SERVE_MAX_SYNC_WAIT は同期処理の最大待ち時間(秒)で、大きな文書のタイムアウトを防ぐために既定の 120 秒から延長している。
CPU のみの環境(または GPU を使わない場合):
docker run -d --name docling-serve -p 5001:5001 -e DOCLING_SERVE_ENABLE_UI=true -e UVICORN_WORKERS=1 -e DOCLING_SERVE_MAX_SYNC_WAIT=600 quay.io/docling-project/docling-serve
NVIDIA GPU を使う場合(CUDA 対応イメージ。GPU により OCR・レイアウト解析が高速化する):
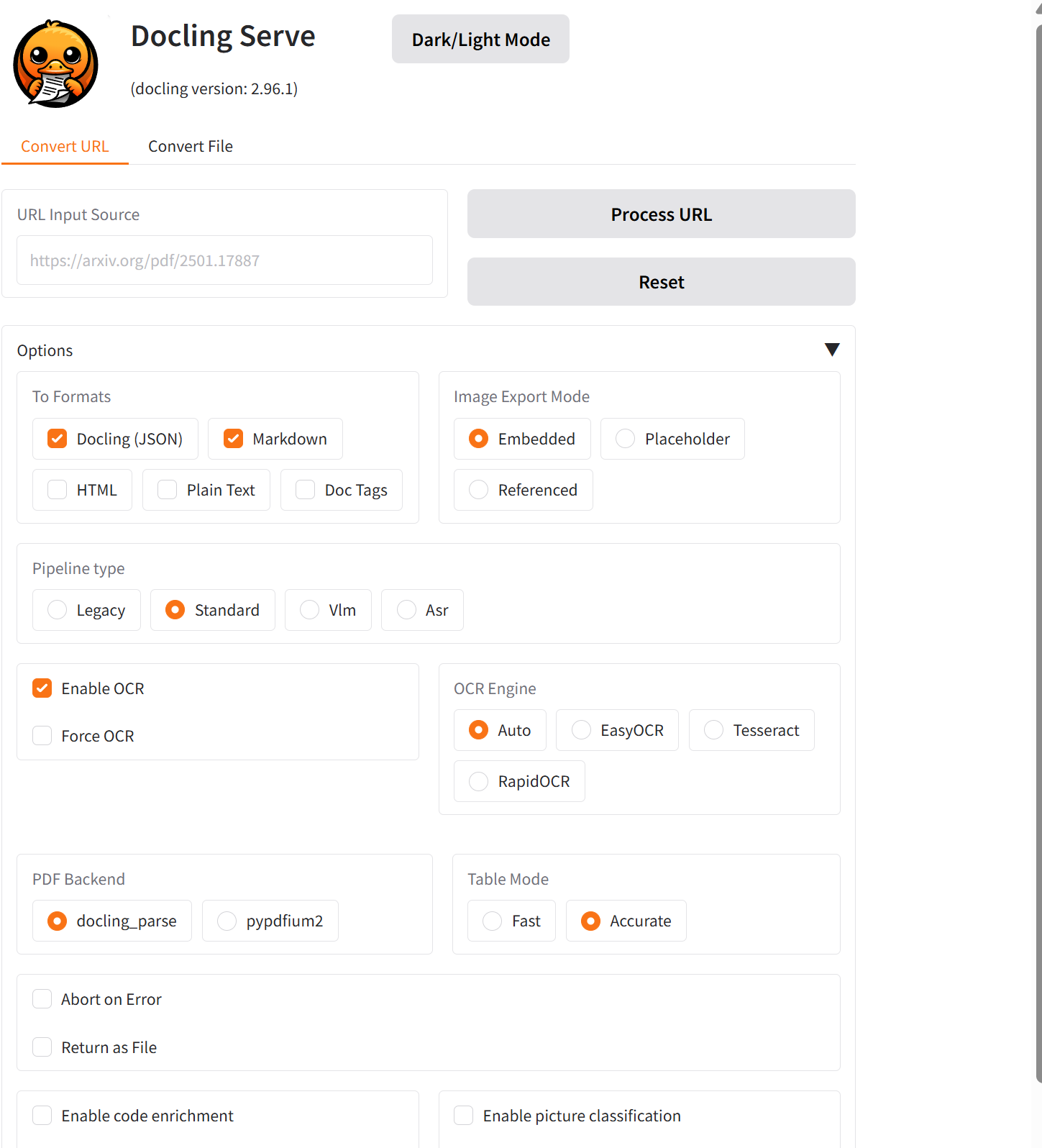
docker run -d --name docling-serve --gpus all -p 5001:5001 -e DOCLING_SERVE_ENABLE_UI=true -e UVICORN_WORKERS=1 -e DOCLING_SERVE_MAX_SYNC_WAIT=600 quay.io/docling-project/docling-serve-cu128起動後、ブラウザで http://localhost:5001/ui を開き、docling-serve の動作確認用 UI が表示されることを確認する(任意で、ここにテスト文書をアップロードして Markdown 出力を確認できる)。
【手順 3:Open WebUI への接続】
- Open WebUI の管理者パネル →
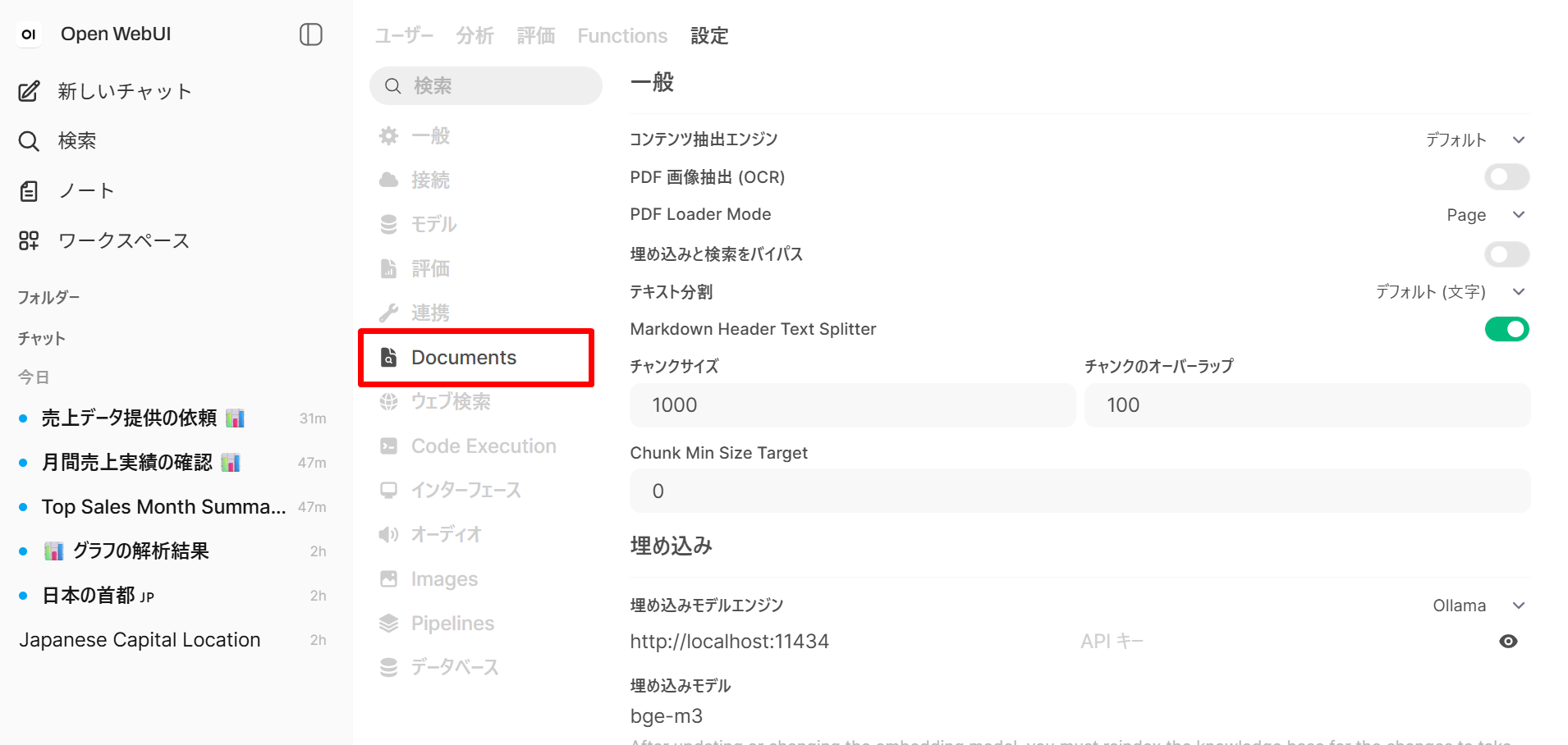
設定 (Settings) → Documents を開く。

- コンテンツ抽出エンジン (Content Extraction Engine)を
DefaultからDoclingに変更する。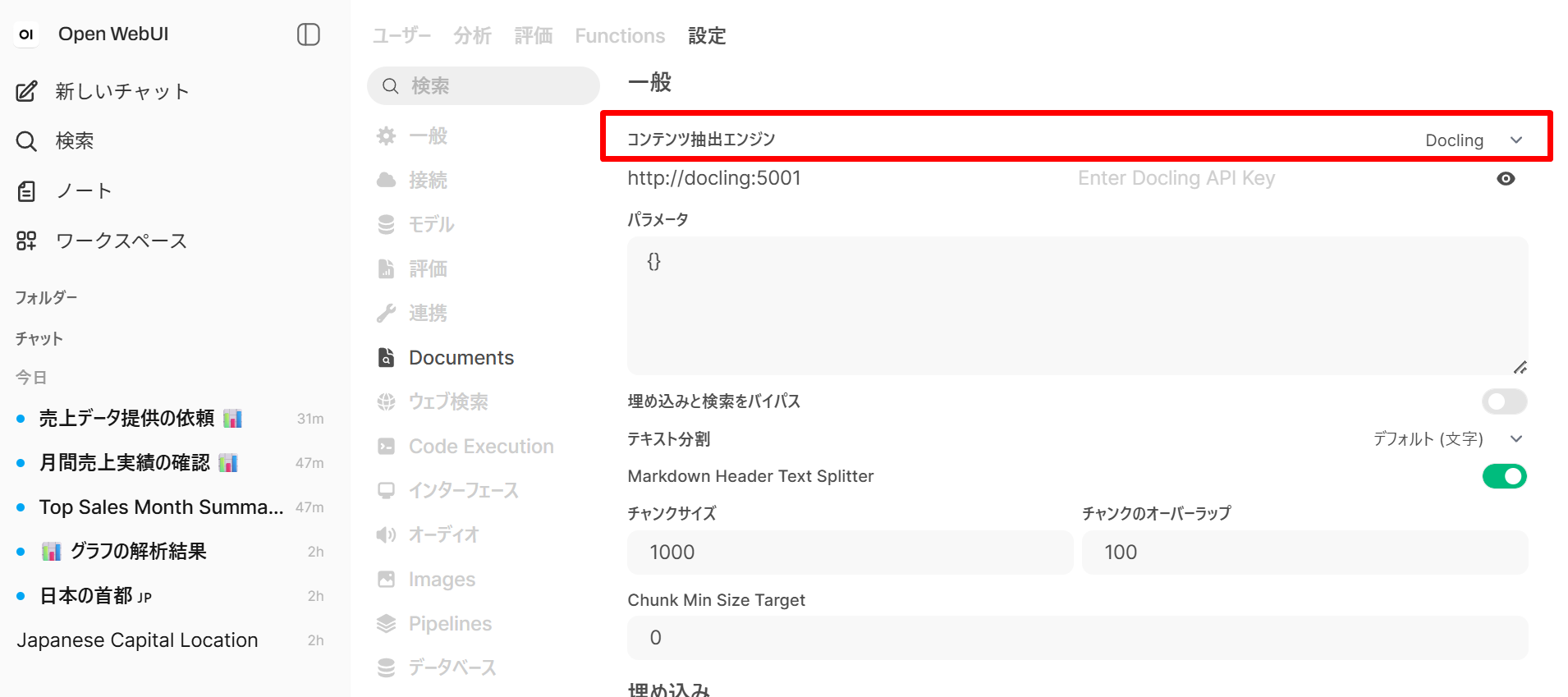
- 表示される Docling のサーバ URL 欄に、Open WebUI を Windows 上でネイティブに動かしているので
http://localhost:5001を入力する。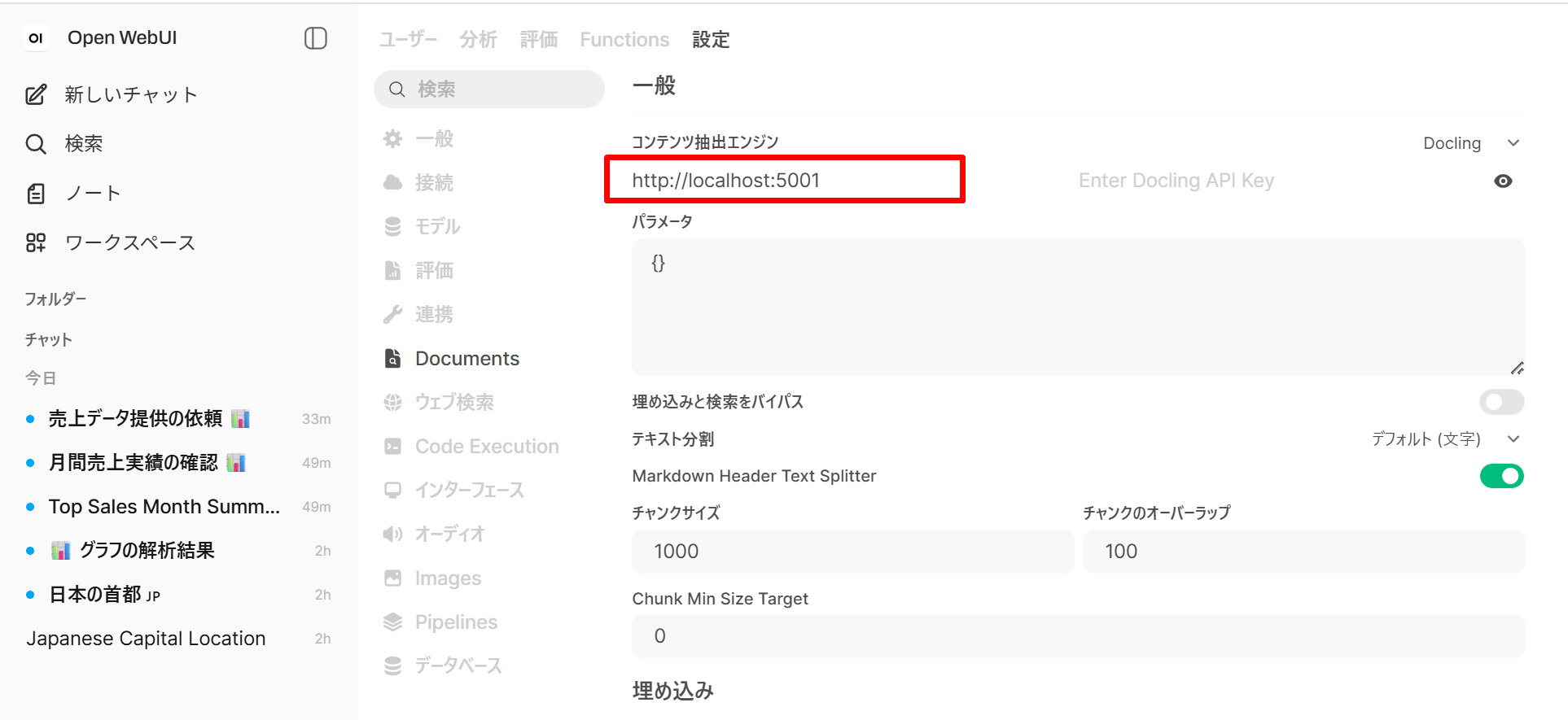
- 必要に応じて、PDF の解析品質・OCR を設定する。Open WebUI の Docling パラメータ設定欄(Open WebUI のバージョンによっては表示される項目名が異なる場合がある。設定画面に当該フィールドが表示されない場合は、Open WebUI のリリースノートを確認すること)に以下のような JSON を設定すると、表を高精度モードで抽出し、日本語の図中テキストを OCR で読み取れる:
{ "do_ocr": true, "pdf_backend": "dlparse_v2", "table_mode": "accurate", "ocr_engine": "tesseract", "ocr_lang": ["jpn", "eng"] }pdf_backendの値は Docling のバージョンによって異なる場合がある。dlparse_v2が現行の代表的な指定値だが、docker logs docling-serveで起動ログを確認するか、Docling のリリースノートで使用中のバージョンに有効なバックエンド名を確認すること。ocr_langは Tesseract では 3 文字コード(日本語jpn、英語eng)で指定する。数式・化学式を多く含む文書ではtable_modeをaccurateにすると構造保持が向上する。 - 「保存(Save)」をクリック。
【手順 4:動作確認】
演習 4 と同じ手順で、今度は表・図・数式を含む PDF を Knowledge にアップロードする。アップロード後、その文書に対して表の数値や図中の項目を問う質問を送り、標準抽出エンジンのとき(演習 4)と比べて応答精度が向上するかを確認する。
ヒント
- docling-serve コンテナを停止するには
docker stop docling-serve、再開するにはdocker start docling-serveを実行する。PC 再起動後は Docker Desktop の起動後にdocker start docling-serveで再開できる。 - 図そのものの内容を文章で説明させたい(Picture Description)場合は、docling-serve に
-e DOCLING_SERVE_ENABLE_REMOTE_SERVICES=trueを付けて起動し、Open WebUI 側で「Describe Pictures in Documents」を有効化して画像説明モデル(ローカルのビジョンモデル、または Ollama 等の API)を設定する。API モードで Ollama を呼ぶ場合のエンドポイントはhttp://host.docker.internal:11434/v1/chat/completions形式である。 - OCR・レイアウト解析は CPU では時間がかかる。図表・数式の多い大量の文書を扱うなら、GPU 対応イメージ(
-cu128)の利用を検討する。
考察ポイント
- 同一の表・図・数式を含む文書を、標準抽出エンジン(演習 4)と Docling(本節)とで取り込んだ場合、RAG の応答精度(表の数値の正確さ、図中項目の参照可否)にどのような差が出るか。
- 演習 3(画像を直接モデルに見せる)・演習 4(標準抽出+RAG)・本節(Docling+RAG)の 3 方式は、図・表・数式を含む文書を扱ううえでそれぞれどのような長所・短所があるか。
付録:他のモデルを試す
本手順では、動作確認用に LFM2.5-1.2B-Instruct を、画像入力と RAG を含む本体の演習に gemma4:e2b-it-qat と gemma4:12b-it-qat を用いた。Ollama を使うと、モデル名を差し替えるだけで他のモデルも同じ手順で試せる(モデルは初回実行時に自動的にダウンロードされる)。Gemma 4 シリーズには、ほかに 26B クラスの MoE(Mixture of Experts、推論ごとに一部のパラメータのみを活性化する構造)モデル(gemma4:26b-a4b-it-qat、約 16GB、メモリ 32GB 以上推奨)や 31B モデル(gemma4:31b-it-qat、約 19GB)も公開されており、ハードウェアに余裕があれば同じ要領で導入できる。これらのモデルタグは Ollama のモデルライブラリページ(https://ollama.com/library)で最新の正式タグ名を確認してから使用すること。