Open Street Map データセット (OpenStreetMap data set)
◆ 作成するSQLite 3 データベース: osmdb
前準備
使用するソフトウェア
あらかじめ決めておく事項
このページでは,データベースの作成を行いますので, 作成するデータベースのデータベース名を決めておくこと. このページでは,次のように書く.
- データベース名: osmdb
データベース名は,自由に決めてよいが,半角文字(つまり英字と英記号)を使い,スペースを含まないこと,
OSM データのダウンロードと CSV ファイル形式への変換 (Download OSM data and Generate CSV Files)
<要点> 緯度、経度等を次のように設定
130.21688103675842, 33.59656025053064, 500, 500
◆ bash プログラム
#
# download OSM data and generate CSV files
#
cat >/tmp/a.$$.r <<-RCOMMAND
#
library(stats)
library(graphics)
library(datasets)
library(ggplot2)
library(xts)
library(chron)
library(osmar)
src <- osmsource_api()
bb <- center_bbox(130.21688103675842, 33.59656025053064, 500, 500)
ua <- get_osm(bb, source = src)
#
osm_nodes <- ua\$nodes\$attrs[c("id", "visible", "timestamp", "version", "changeset", "user", "uid", "lat", "lon")]
names(osm_nodes) <- c("node_id", "visible", "timestamp", "version", "changeset", "user", "uid", "lat", "lon")
osm_node_tags <- ua\$nodes\$tags[c("id", "k", "v")]
names(osm_node_tags) <- c("node_id", "key", "value")
# あとでCSVファイルを読み込むときに「,」が邪魔になるので
osm_node_tags\$value <- gsub(",", "", osm_node_tags\$value)
#
osm_ways <- ua\$ways\$attrs[c("id", "visible", "timestamp", "version", "changeset", "user", "uid")]
names(osm_ways) <- c("way_id", "visible", "timestamp", "version", "changeset", "user", "uid")
osm_way_tags <- ua\$ways\$tags[c("id", "k", "v")]
names(osm_way_tags) <- c("way_id", "key", "value")
# あとでCSVファイルを読み込むときに「,」が邪魔になるので
osm_way_tags\$value <- gsub(",", "", osm_way_tags\$value)
#
way_nodes <- ua\$ways\$refs[c("id", "ref")]
names(way_nodes) <- c("way_id", "node_id")
#
osm_relations <- ua\$relations\$attrs[c("id", "visible", "timestamp", "version", "changeset", "user", "uid")]
names(osm_relations) <- c("relation_id", "visible", "timestamp", "version", "changeset", "user", "uid")
osm_relation_tags <- ua\$relations\$tags[c("id", "k", "v")]
names(osm_relation_tags) <- c("relation_id", "key", "value")
# あとでCSVファイルを読み込むときに「,」が邪魔になるので
osm_relation_tags\$value <- gsub(",", "", osm_relation_tags\$value)
relation_way_nodes <- ua\$relations\$refs[c("id", "type", "ref", "role")]
names(relation_way_nodes) <- c("relation_id", "type", "ref", "role")
#
write.csv(osm_nodes, file="/tmp/osm_nodes.csv", row.names=FALSE)
write.csv(osm_node_tags, file="/tmp/osm_node_tags.csv", row.names=FALSE)
write.csv(osm_ways, file="/tmp/osm_ways.csv", row.names=FALSE)
write.csv(osm_way_tags, file="/tmp/osm_way_tags.csv", row.names=FALSE)
write.csv(way_nodes, file="/tmp/osm_way_nodes.csv", row.names=FALSE)
write.csv(osm_relations, file="/tmp/osm_relations.csv", row.names=FALSE)
write.csv(osm_relation_tags, file="/tmp/osm_relation_tags.csv", row.names=FALSE)
write.csv(relation_way_nodes, file="/tmp/osm_relation_way_nodes.csv", row.names=FALSE)
RCOMMAND
cat /tmp/a.$$.r | r
CSV ファイルの表示 (View OSM CSV files)
- node の緯度、経度
◆ R プログラム
require(data.table) require(ggplot2) nodes <- data.table( read.csv("/tmp/osm_nodes.csv", header=TRUE, as.is=TRUE) ) ggplot(nodes, aes(x=lat, y=lon)) + geom_point() # または tkplot(x=nodes$lat, y=nodes$lon)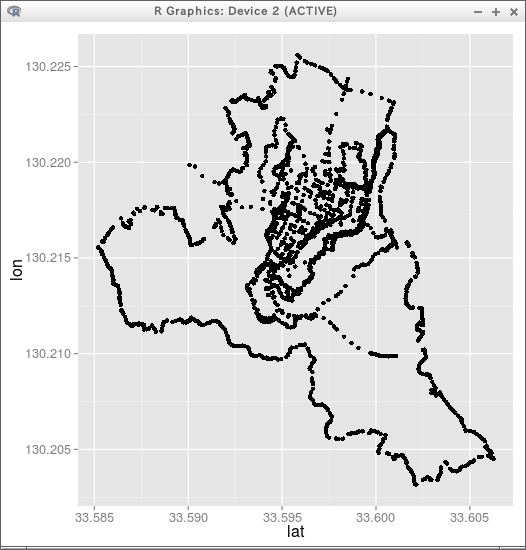
リレーショナルデータベースの生成
作成したCSVファイルを、いったん、作業用のテーブルに格納する. 作業用のテーブルを使って、最終的に欲しいテーブルを作る.
- テーブル定義
OSM データ(元の OSM データを表現するテーブル)
- osm_nodes(node_id, visible, timestamp, version, changeset, user, uid, lat, lon)
- osm_node_tags(node_id, key, value)
- osm_ways(way_id, visible, timestamp, version, changeset, user, uid)
- osm_way_tags(node_id, key, value)
- osm_way_nodes(seq, way_id, node_id)
- osm_relations(relation_id, visible, timestamp, version, changeset, user, uid)
- osm_relation_tags(relation_id, key, value)
OSM 派生データ
- nodes(node_id, lat, lon, classification, feature, name, degree)
# classification and features are not implemented, see http://wiki.openstreetmap.org/wiki/Map_Features
# 1-to-1 (nodes, osm_nodes)
# 1-to-n (nodes, osm_node_tags) - ways(way_id, is_open, classification, feature, name)
# open polyline or closed polyline or area
# classification and features are not implemented, see http://wiki.openstreetmap.org/wiki/Map_Features
# 1-to-1 (ways, osm_ways)
# 1-to-n (ways, osm_way_tags) - relations(way_id, type)
◆ bash プログラム
#!/bin/bash rm -f /tmp/osmdb # cat >/tmp/a.$$.sql <<-SQL drop table classification; SQL cat /tmp/a.$$.sql | sqlite3 /tmp/osmdb # cat >/tmp/a.$$.sql <<-SQL create table classification ( name text ); SQL cat /tmp/a.$$.sql | sqlite3 /tmp/osmdb # cat >/tmp/a.$$.sql <<-SQL drop table osm_nodes; SQL cat /tmp/a.$$.sql | sqlite3 /tmp/osmdb # cat >/tmp/a.$$.sql <<-SQL create table osm_nodes ( node_id int, visible text, timestamp datetime, version integer, changeset integer, user text, uid integer, lat real, lon real ); SQL cat /tmp/a.$$.sql | sqlite3 /tmp/osmdb # cat >/tmp/a.$$.sql <<-SQL drop table osm_node_tags; SQL cat /tmp/a.$$.sql | sqlite3 /tmp/osmdb # cat >/tmp/a.$$.sql <<-SQL create table osm_node_tags ( node_id integer, key text, value text ); SQL cat /tmp/a.$$.sql | sqlite3 /tmp/osmdb # cat >/tmp/a.$$.sql <<-SQL drop table osm_ways; SQL cat /tmp/a.$$.sql | sqlite3 /tmp/osmdb # cat >/tmp/a.$$.sql <<-SQL create table osm_ways ( way_id int, visible text, timestamp datetime, version integer, changeset integer, user text, uid integer ); SQL cat /tmp/a.$$.sql | sqlite3 /tmp/osmdb # cat >/tmp/a.$$.sql <<-SQL drop table osm_way_tags; SQL cat /tmp/a.$$.sql | sqlite3 /tmp/osmdb # cat >/tmp/a.$$.sql <<-SQL create table osm_way_tags ( way_id integer, key text, value text ); SQL cat /tmp/a.$$.sql | sqlite3 /tmp/osmdb # cat >/tmp/a.$$.sql <<-SQL drop table osm_way_nodes; SQL cat /tmp/a.$$.sql | sqlite3 /tmp/osmdb # cat >/tmp/a.$$.sql <<-SQL create table osm_way_nodes ( seq integer PRIMARY KEY autoincrement not null, way_id integer, node_id integer ); SQL cat /tmp/a.$$.sql | sqlite3 /tmp/osmdb # cat >/tmp/a.$$.sql <<-SQL drop table osm_relations; SQL cat /tmp/a.$$.sql | sqlite3 /tmp/osmdb # cat >/tmp/a.$$.sql <<-SQL create table osm_relations ( relation_id int, visible text, timestamp datetime, version integer, changeset integer, user text, uid integer ); SQL cat /tmp/a.$$.sql | sqlite3 /tmp/osmdb # cat >/tmp/a.$$.sql <<-SQL drop table osm_relation_tags; SQL cat /tmp/a.$$.sql | sqlite3 /tmp/osmdb # cat >/tmp/a.$$.sql <<-SQL create table osm_relation_tags ( relation_id integer, key text, value text ); SQL cat /tmp/a.$$.sql | sqlite3 /tmp/osmdb # cat >/tmp/a.$$.sql <<-SQL drop table nodes; SQL cat /tmp/a.$$.sql | sqlite3 /tmp/osmdb # cat >/tmp/a.$$.sql <<-SQL create table nodes ( node_id integer PRIMARY KEY autoincrement not null, lat real not null, lon real not null, classification text, feature text, name text, degree integer ); SQL cat /tmp/a.$$.sql | sqlite3 /tmp/osmdb # cat >/tmp/a.$$.sql <<-SQL drop table ways; SQL cat /tmp/a.$$.sql | sqlite3 /tmp/osmdb # cat >/tmp/a.$$.sql <<-SQL create table ways ( way_id integer PRIMARY KEY autoincrement not null, classification text, feature text, name text, is_open integer ); SQL cat /tmp/a.$$.sql | sqlite3 /tmp/osmdb - テーブル classification の作成
参考 http://wiki.openstreetmap.org/wiki/Map_Features
cat > /tmp/a.$$.csv <<-CSV "aerialway" "aeroway" "amenity" "barrier" "boundary" "building" "craft" "mmergency" "geological" "highway" "historic" "landuse" "leisure" "man made" "military" "natural" "office" "places" "power" "public transport" "railway" "route" "shop" "sport" "tourism" "waterway" CSV # cat >/tmp/a.$$.sql <<-SQL .mode csv .import /tmp/a.$$.csv classification vacuum; SQL cat /tmp/a.$$.sql | sqlite3 /tmp/osmdb # echo 'select * from classification limit 10;' | sqlite3 /tmp/osmdb - テーブル osm_nodes の作成
◆ bash プログラム
#!/bin/bash # /tmp/osm_nodes.csv tail -n +2 /tmp/osm_nodes.csv | nkf -w > /tmp/osm_nodes_uft8.csv cat >/tmp/a.$$.sql <<-SQL .mode csv .import /tmp/osm_nodes_uft8.csv osm_nodes vacuum; SQL cat /tmp/a.$$.sql | sqlite3 /tmp/osmdb # echo 'select * from osm_nodes limit 10;' | sqlite3 /tmp/osmdb - テーブル osm_node_tags の作成
◆ bash プログラム
#!/bin/bash # /tmp/osm_node_tags.csv tail -n +2 /tmp/osm_node_tags.csv | nkf -w > /tmp/osm_node_tags_uft8.csv cat >/tmp/a.$$.sql <<-SQL .mode csv .import /tmp/osm_node_tags_uft8.csv osm_node_tags vacuum; SQL cat /tmp/a.$$.sql | sqlite3 /tmp/osmdb # echo 'select * from osm_node_tags limit 10;' | sqlite3 /tmp/osmdbclassficationテーブルのname属性に記載されている値は、osm_node_tags テーブルでは各nodeごとにたかだか1回しか現れないことの確認。
cat >/tmp/a.$$.sql <<-SQL create table T as select * from classification, osm_node_tags where classification.name = osm_node_tags.key; select node_id, count(*) from T group by node_id having count(*) > 1; drop table T; vacuum; SQL cat /tmp/a.$$.sql | sqlite3 /tmp/osmdb
osm_node_tags テーブルでは, key の値が「"name"」であるような行は、各nodeごとにたかだか1回しか現れないことの確認。
cat >/tmp/a.$$.sql <<-SQL create table T as select * from osm_node_tags where osm_node_tags.key = '"name"'; select node_id, count(*) from T group by node_id having count(*) > 1; drop table T; vacuum; SQL cat /tmp/a.$$.sql | sqlite3 /tmp/osmdb
- テーブル osm_ways の作成
◆ bash プログラム
#!/bin/bash # /tmp/osm_ways.csv tail -n +2 /tmp/osm_ways.csv | nkf -w > /tmp/osm_ways_uft8.csv cat >/tmp/a.$$.sql <<-SQL .mode csv .import /tmp/osm_ways_uft8.csv osm_ways vacuum; SQL cat /tmp/a.$$.sql | sqlite3 /tmp/osmdb # echo 'select * from osm_ways limit 10;' | sqlite3 /tmp/osmdb - テーブル osm_way_tags の作成
◆ bash プログラム
#!/bin/bash # /tmp/osm_way_tags.csv tail -n +2 /tmp/osm_way_tags.csv | nkf -w > /tmp/osm_way_tags_uft8.csv cat >/tmp/a.$$.sql <<-SQL .mode csv .import /tmp/osm_way_tags_uft8.csv osm_way_tags vacuum; SQL cat /tmp/a.$$.sql | sqlite3 /tmp/osmdb # echo 'select * from osm_way_tags limit 10;' | sqlite3 /tmp/osmdb
classficationテーブルのname属性に記載されている値は、osm_way_tags テーブルでは各wayごとにたかだか1回しか現れないかの確認。実は2回現れるものがある.
cat >/tmp/a.$$.sql <<-SQL create table T as select * from classification, osm_way_tags where classification.name = osm_way_tags.key; select way_id, count(*) from T group by way_id having count(*) > 1; drop table T; vacuum; SQL cat /tmp/a.$$.sql | sqlite3 /tmp/osmdb
osm_way_tags テーブルでは, key の値が「"name"」であるような行は、各wayごとにたかだか1回しか現れないことの確認。
cat >/tmp/a.$$.sql <<-SQL create table T as select * from osm_way_tags where osm_way_tags.key = '"name"'; select way_id, count(*) from T group by way_id having count(*) > 1; drop table T; vacuum; SQL cat /tmp/a.$$.sql | sqlite3 /tmp/osmdb
- テーブル osm_way_nodes の作成
◆ bash プログラム
一度、テーブルに読み込んで、その後通し番号 seq を生成.
#!/bin/bash # /tmp/osm_way_nodes.csv tail -n +2 /tmp/osm_way_nodes.csv | nkf -w > /tmp/osm_way_nodes_uft8.csv cat >/tmp/a.$$.sql <<-SQL create table T ( way_id integer, node_id integer ); .mode csv .import /tmp/osm_way_nodes_uft8.csv T insert into osm_way_nodes(way_id, node_id) select way_id, node_id from T; drop table T; vacuum; SQL cat /tmp/a.$$.sql | sqlite3 /tmp/osmdb # echo 'select * from osm_way_nodes limit 10;' | sqlite3 /tmp/osmdb
- テーブル osm_relations の作成
◆ bash プログラム
#!/bin/bash # /tmp/osm_relations.csv tail -n +2 /tmp/osm_relations.csv | nkf -w > /tmp/osm_relations_uft8.csv cat >/tmp/a.$$.sql <<-SQL .mode csv .import /tmp/osm_relations_uft8.csv osm_relations vacuum; SQL cat /tmp/a.$$.sql | sqlite3 /tmp/osmdb # echo 'select * from osm_relations limit 10;' | sqlite3 /tmp/osmdb
- テーブル osm_relation_tags の作成
◆ bash プログラム
#!/bin/bash # /tmp/osm_relation_tags.csv tail -n +2 /tmp/osm_relation_tags.csv | nkf -w > /tmp/osm_relation_tags_uft8.csv cat >/tmp/a.$$.sql <<-SQL .mode csv .import /tmp/osm_relation_tags_uft8.csv osm_relation_tags vacuum; SQL cat /tmp/a.$$.sql | sqlite3 /tmp/osmdb # echo 'select * from osm_relation_tags limit 10;' | sqlite3 /tmp/osmdb
classficationテーブルのname属性に記載されている値は、osm_relation_tags テーブルでは各relationごとにたかだか1回しか現れないかの確認。実は2回現れるものがある.
cat >/tmp/a.$$.sql <<-SQL create table T as select * from classification, osm_relation_tags where classification.name = osm_relation_tags.key; select relation_id, count(*) from T group by relation_id having count(*) > 1; drop table T; vacuum; SQL cat /tmp/a.$$.sql | sqlite3 /tmp/osmdb
osm_relation_tags テーブルでは, key の値が「"name"」であるような行は、各relationごとにたかだか1回しか現れないことの確認。
cat >/tmp/a.$$.sql <<-SQL create table T as select * from osm_relation_tags where osm_relation_tags.key = '"name"'; select relation_id, count(*) from T group by relation_id having count(*) > 1; drop table T; vacuum; SQL cat /tmp/a.$$.sql | sqlite3 /tmp/osmdb
- テーブル nodes の作成
◆ bash プログラム
#!/bin/bash cat >/tmp/a.$$.sql <<-SQL create table R as select osm_node_tags.node_id as node_id, osm_node_tags.key as key, osm_node_tags.value as value from classification, osm_node_tags where classification.name = osm_node_tags.key; create table S as select osm_node_tags.node_id as node_id, osm_node_tags.key as key, osm_node_tags.value as value from osm_node_tags where osm_node_tags.key = '"name"'; create table T as select osm_nodes.node_id as node_id, osm_nodes.lat as lat, osm_nodes.lon as lon, R.key as classification, R.value as feature from osm_nodes left outer join R on osm_nodes.node_id = R.node_id; create table U as select T.node_id as node_id, T.lat as lat, T.lon as lon, T.classification as classification, T.feature as feature, S.value as name from T left outer join S on T.node_id = S.node_id; insert into nodes(node_id, lat, lon, classification, feature, name) select node_id, lat, lon, classification, feature, name from U; drop table R; drop table S; drop table T; drop table U; vacuum; SQL cat /tmp/a.$$.sql | sqlite3 /tmp/osmdb # echo 'select * from nodes limit 10;' | sqlite3 /tmp/osmdb - テーブル ways の作成
◆ bash プログラム
#!/bin/bash cat >/tmp/a.$$.sql <<-SQL create table R as select osm_way_tags.way_id as way_id, osm_way_tags.key as key, osm_way_tags.value as value from classification, osm_way_tags where classification.name = osm_way_tags.key; create table S as select osm_way_tags.way_id as way_id, osm_way_tags.key as key, osm_way_tags.value as value from osm_way_tags where osm_way_tags.key = '"name"'; create table T as select osm_ways.way_id as way_id, osm_ways.lat as lat, osm_ways.lon as lon, R.key as classification, R.value as feature from osm_ways left outer join R on osm_ways.way_id = R.way_id; create table U as select T.way_id as way_id, T.lat as lat, T.lon as lon, T.classification as classification, T.feature as feature, S.value as name from T left outer join S on T.way_id = S.way_id; insert into ways(way_id, lat, lon, classification, feature, name) select way_id, lat, lon, classification, feature, name from U; drop table R; drop table S; drop table T; drop table U; vacuum; SQL cat /tmp/a.$$.sql | sqlite3 /tmp/osmdb # echo 'select * from ways limit 10;' | sqlite3 /tmp/osmdb