時系列データのプロット(Python, matplotlib, seaborn を使用)(Google Colaboratory へのリンク有り)
目次
- 1. エグゼクティブサマリー
- 2. Python 3.12 のインストール
- 3. Python の開発環境 Visual Studio Code のインストールと Python 用の設定
- 4. Python プログラム実行手順
- 5. 必要なライブラリのインストール
- 6. 実行のための準備とその確認手順(Windows 前提)
- 7. 概要・使い方・実行上の注意
- 8. ソースコード
- 9. まとめ
1. エグゼクティブサマリー
numpy の配列に,同一の長さの時系列データが複数入っているとする。そして,別データとして,各時系列データのラベル番号があるとする。 このとき,時系列データを,ラベル番号を使って色分けしてプロットする。
本記事では,FordA データセット(自動車エンジンの動作音をセンサーで計測した時系列データで,特定の不具合の有無を判定する2クラスのデータセット)を題材として,以下の処理を Python(matplotlib, seaborn)で実現する。
- FordA データセット(TSV 形式)をロードし,時系列データとラベル番号を取得する
- ラベル番号ごとにカラーマップ hsv で色分けし,時系列データをプロットする
- 主成分分析(PCA)で時系列データを2次元にマッピングし,散布図としてプロットする
【関連する外部ページ】
Google Colaboratory のページ:
https://colab.research.google.com/drive/1tZmdhdUXMoB_rtQM45u-qgDPo75jTnYZ?usp=sharing
2. Python 3.12 のインストール
3. Python の開発環境 Visual Studio Code のインストールと Python 用の設定
4. Python プログラム実行手順
5. 必要なライブラリのインストール
管理者権限でコマンドプロンプトを起動する
(手順:Windowsキーまたはスタートメニュー → cmd と入力 → 右クリック → 「管理者として実行」)。
起動したコマンドプロンプトで以下を実行する。
python -m pip install -U --no-user pip setuptools numpy pandas matplotlib seaborn scikit-learn scikit-learn-intelex
6. 実行のための準備とその確認手順(Windows 前提)
6.1 プログラムファイルの準備
本記事のプログラムは,Google Colaboratory 上のノートブックとして実行することを想定している。第1章の Google Colaboratory のリンクからノートブックを開き,各セルを順に実行する。
ローカル環境で実行する場合は,第8章のソースコードをテキストエディタ(Visual Studio Code やメモ帳など)に貼り付け,1つのファイルとして保存する(文字コード:UTF-8)。その際,%matplotlib inline は Jupyter/Google Colaboratory 専用のマジックコマンド(ノートブック内に図を表示するための命令)であるため,削除すること。
6.2 実行コマンド
Google Colaboratory では,ノートブック内の各セルを上から順に実行する。
ローカル環境では,コマンドプロンプトでファイルの保存先ディレクトリに移動し,保存したファイルを以下のように実行する(ここではファイル名を main.py とした場合の例)。
python main.py6.3 動作確認チェックリスト
| 確認項目 | 期待される結果 |
|---|---|
| パッケージのインポート | numpy, matplotlib, seaborn, pandas, sklearn が正常にインポートされる |
| FordA データセットのロード | ds_train, ds_test にデータが格納される |
| データの確認(shape の表示) | ds_train[0], ds_train[1], ds_test[0], ds_test[1] の shape が表示される |
| ラベル番号の取得 | classes に重複除去済みのラベル番号が格納される |
| 時系列プロット(top_k=10, alpha=0.1) | ラベル番号ごとに色分けされた時系列データが10本ずつ表示され,凡例と軸ラベルが表示される |
| 時系列プロット(top_k=1, alpha=1) | ラベル番号ごとに1本ずつ不透明で表示される |
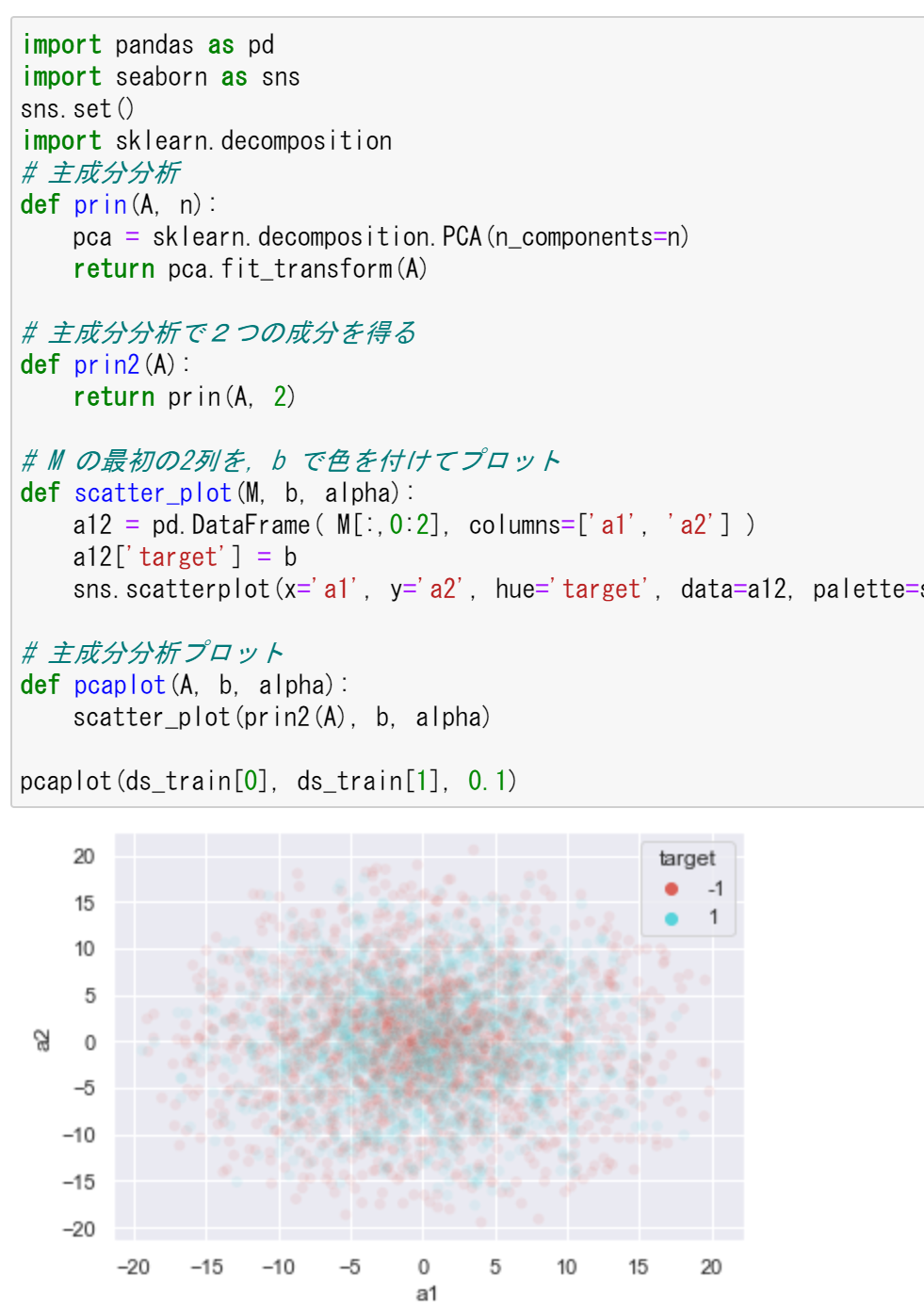
| 主成分分析プロット(ds_train) | ds_train を PCA で2次元にマッピングした散布図がラベルで色分けされて表示される |
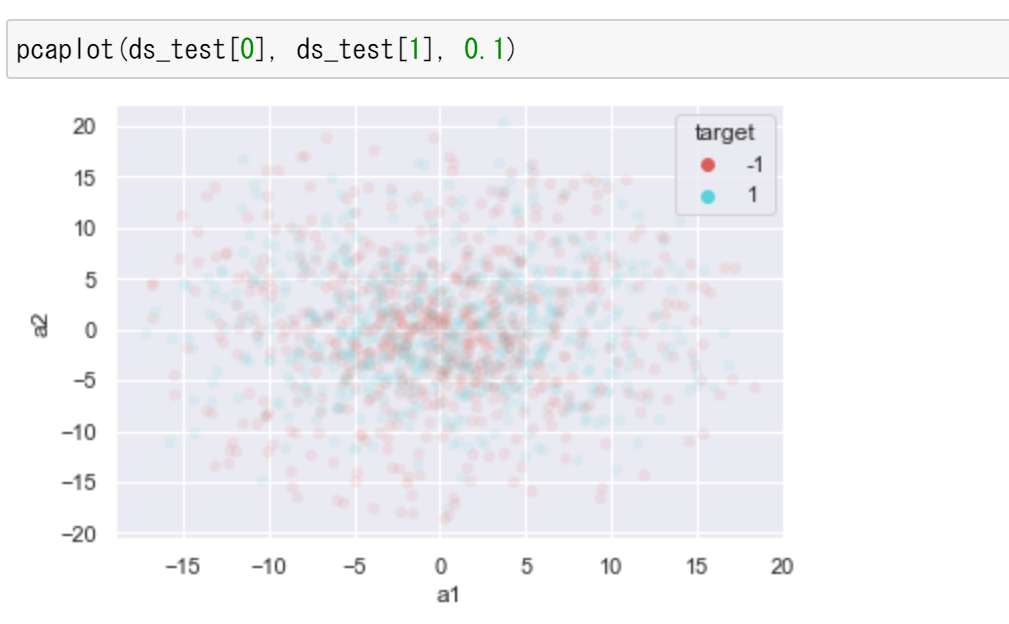
| 主成分分析プロット(ds_test) | ds_test を PCA で2次元にマッピングした散布図がラベルで色分けされて表示される |
7. 概要・使い方・実行上の注意
7.1 FordA データセットの構造
FordA データセットは TSV 形式(タブ区切りのテキスト形式)で提供される。readucr 関数により,各行の第0列をラベル(y),第1列以降を時系列データ(x)として読み込む。データは訓練用(ds_train)とテスト用(ds_test)に分かれている。各時系列の長さは500点であり,ラベルは2種類(-1 と 1)である。
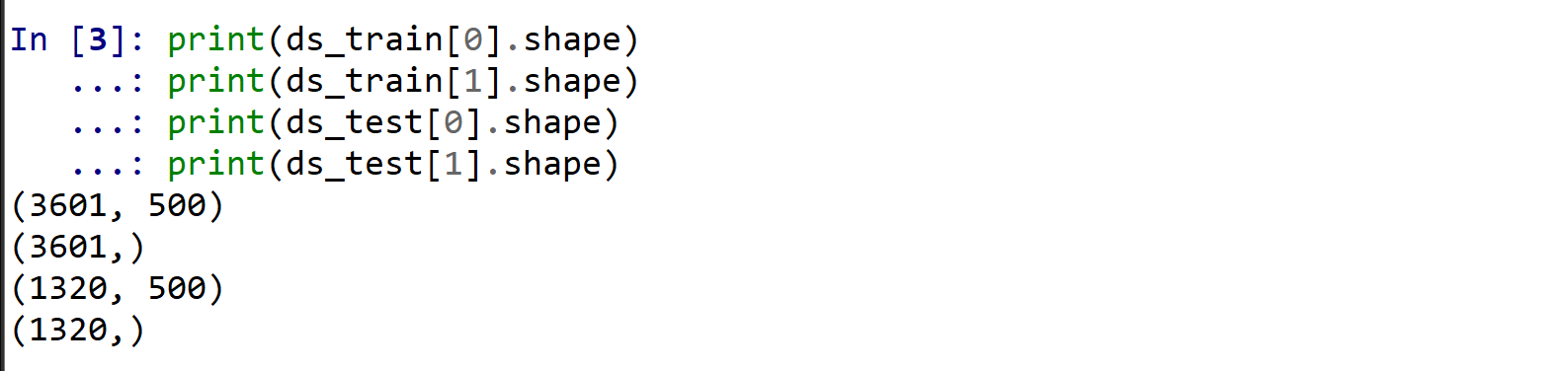
ds_train[1], ds_test[1] からラベル番号を得る。このとき重複を除去する。

7.2 時系列データのプロット
plot_ts 関数は,ラベル付きの時系列データのうち上位 top_k 個をプロットする。色はカラーマップ hsv で割り当て,alpha(透明度。0で完全に透明,1で不透明)を指定する。凡例と軸ラベル(横軸:Time step,縦軸:Value)が表示される。
top_k = 10, alpha = 0.1 の場合:

top_k = 1, alpha = 1 の場合:

7.3 主成分分析の結果である主成分スコアのプロット
ds_train[0], ds_test[0] を主成分分析で2次元にマッピングし,ds_train[1], ds_test[1] を色として散布図を表示する。主成分分析(PCA)は,多次元のデータを情報の損失を抑えながら少数の軸に要約する手法である。
ds_train の主成分分析プロット:
ds_test の主成分分析プロット:
8. ソースコード
8.1 パッケージのインポート
import numpy as np
%matplotlib inline
import matplotlib.pyplot as plt
import matplotlib.cm as cm
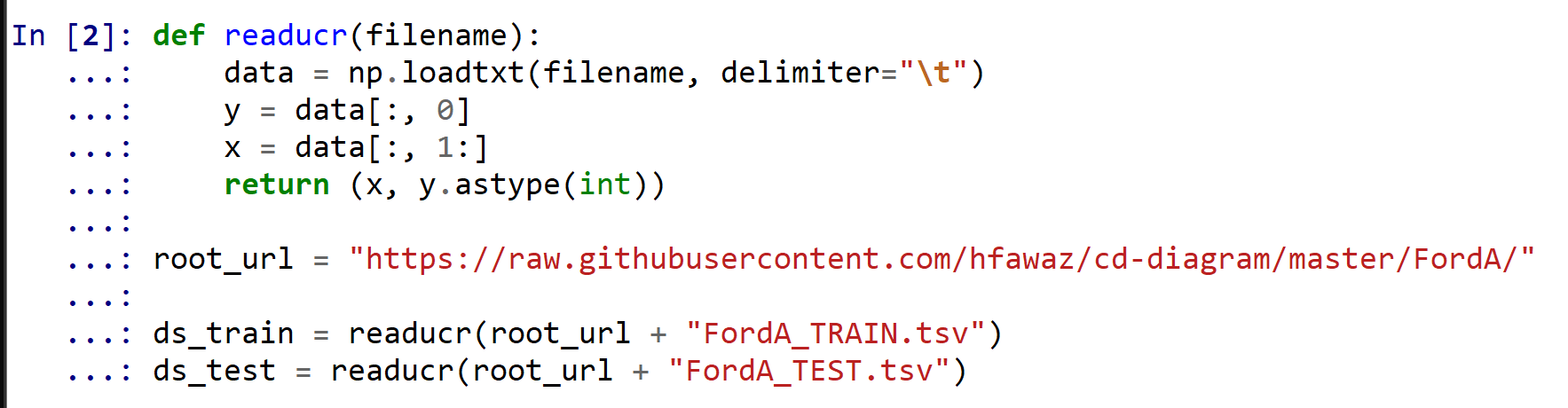
8.2 FordA データセット(TSV 形式ファイル)のロード
FordA データセット(TSV 形式ファイル)をロードする。
def readucr(filename):
data = np.loadtxt(filename, delimiter="\t")
y = data[:, 0]
x = data[:, 1:]
return (x, y.astype(int))
root_url = "https://raw.githubusercontent.com/hfawaz/cd-diagram/master/FordA/"
ds_train = readucr(root_url + "FordA_TRAIN.tsv")
ds_test = readucr(root_url + "FordA_TEST.tsv")
8.3 データの確認
print(ds_train[0].shape)
print(ds_train[1].shape)
print(ds_test[0].shape)
print(ds_test[1].shape)
8.4 ラベル番号の取得
ds_train[1], ds_test[1] からラベル番号を得る。このとき重複を除去する。
classes = np.unique(np.concatenate((ds_train[1], ds_test[1]), axis=0))
8.5 seaborn の準備
import seaborn as sns
sns.set_theme()

8.6 時系列データのプロット
def plot_ts(x, y, classes, top_k, alpha):
"""ラベル付きの時系列データについて,上位 top_k 個をプロットする。色はカラーマップ hsv で色付けし,alpha は透明度を指定する。"""
MI, MA = np.min(classes), np.max(classes)
plt.figure()
for c in classes:
cval = 0.8 * (c - MI) / (MA - MI)
for i in x[y == c][0:top_k]:
plt.plot(i, alpha=alpha, color=cm.hsv(cval), label=f"class {c}")
handles, labels = plt.gca().get_legend_handles_labels()
by_label = dict(zip(labels, handles))
plt.legend(by_label.values(), by_label.keys(), loc="best")
plt.xlabel("Time step")
plt.ylabel("Value")
plt.show()
plot_ts(x = ds_train[0], y = ds_train[1], classes = classes, top_k = 10, alpha = 0.1)
8.7 設定を変えてプロット
plot_ts(x = ds_train[0], y = ds_train[1], classes = classes, top_k = 1, alpha = 1)
8.8 主成分分析の結果である主成分スコアのプロット
ds_train[0], ds_test[0] を主成分分析で2次元にマッピングし, ds_train[1], ds_test[1] を色として使用する。
import pandas as pd
import sklearn.decomposition
def prin2(A):
"""主成分分析で2つの成分を得る"""
return sklearn.decomposition.PCA(n_components=2).fit_transform(A)
def scatter_plot(M, b, alpha):
"""M の最初の2列を,b で色を付けてプロットする"""
a12 = pd.DataFrame(M[:, 0:2], columns=['a1', 'a2'])
a12['target'] = b
sns.scatterplot(x='a1', y='a2', hue='target', data=a12, palette=sns.color_palette("hls", len(np.unique(b))), legend="full", alpha=alpha)
def pcaplot(A, b, alpha):
"""主成分分析の結果をプロットする"""
scatter_plot(prin2(A), b, alpha)
pcaplot(ds_train[0], ds_train[1], 0.1)
pcaplot(ds_test[0], ds_test[1], 0.1)
9. まとめ
9.1 時系列データのラベル別色分けプロット
numpy 配列に格納された同一長の時系列データを,ラベル番号ごとにカラーマップ hsv で色分けし,matplotlib でプロットする。plot_ts 関数で表示本数(top_k)と透明度(alpha)を指定できる。
9.2 FordA データセットの読み込み
FordA データセットは TSV 形式で提供される。readucr 関数で各行の第0列をラベル,第1列以降を時系列データとして読み込み,訓練データとテストデータに分けて取得する。
9.3 ラベル番号の取得と重複除去
ds_train[1] と ds_test[1] を結合し,np.unique で重複を除去してラベル番号一覧を得る。この一覧をプロット時のクラス分類に使用する。
9.4 主成分分析による2次元マッピング
時系列データを主成分分析(PCA)で2次元にマッピングし,散布図としてプロットする。prin2 関数で2つの主成分を得て,scatter_plot 関数で seaborn の scatterplot を用いてラベルごとに色分け表示する。
9.5 seaborn によるプロットスタイル設定
sns.set_theme() で seaborn のデフォルトテーマを適用し,プロットに統一的なスタイルを設定する。散布図では hls カラーパレットでラベルごとの色分けを行う。