Rでのテキストファイル読み出しと書き込み
- テキストファイルの読み出し
- テキストファイルの書き込み
- 書式付の出力など
前準備
R システムのインストール
【関連する外部ページ】
R システムの CRAN の URL: https://cran.r-project.org/
テキストファイルの読み出し
テキストファイルの読み出しについては,read.table() と scan() の2つを紹介しておきます.
- テキストファイルからのデータフレームの読み出し: read.table(), read.csv()
主な引数は次の通り
read.tableでの既定値 read.csvでの既定値 file ファイル名 header ファイルの1行目に変数名が書かれているか?(TRUE または FALSE) FALSE TRUE sep 列を区切る記号 空白文字、タブ、改行、CR , (カンマ) quote ファイルで使われている引用符 \"' \" dec ファイルで使われている小数点記号 . . fill 長さをそろえるか? !blank.lines.skip TRUE comment.char コメントに使用する文字 # "" skip 読み飛ばし行数 0 0 nrow 読み込み行数 (ファイルの最後まで) (ファイルの最後まで) 実行結果の例
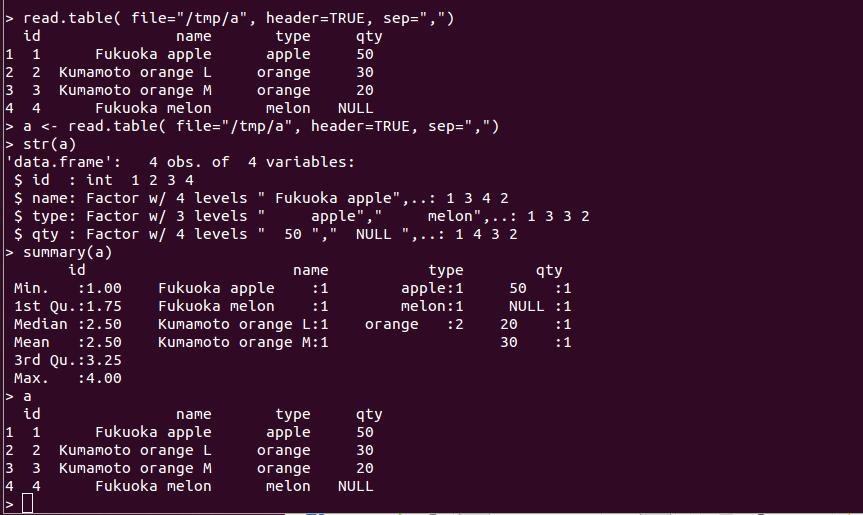
rm -f /tmp/a echo "id, name, type, qty" > /tmp/a echo " 1, Fukuoka apple, apple, 50 " >> /tmp/a echo " 2, Kumamoto orange L, orange, 30 " >> /tmp/a echo " 3, Kumamoto orange M, orange, 20 " >> /tmp/a echo " 4, Fukuoka melon, melon, NULL " >> /tmp/a R a <- read.table( file="/tmp/a", header=TRUE, sep=",")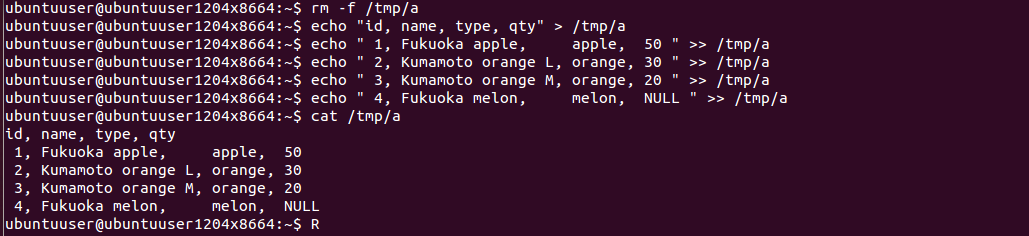
* CSV ファイルを読み込んだ後の使用例については「データフレームからの散布図作成,画像ファイルに保存(R システム,ggplot2,plot を使用)」のページを参考にしてください.
- テキストファイルからの読み出し scan()
scan() 関数は,同じ型のデータが入っているテキストファイルからの読み込み. つまり,文字列と数値が混ざったようなテキストファイルには向かない.
x <- scan("C:/hoge3.txt") x y <- matrix( scan("C:/hoge3.txt"), ncol = 2 ) y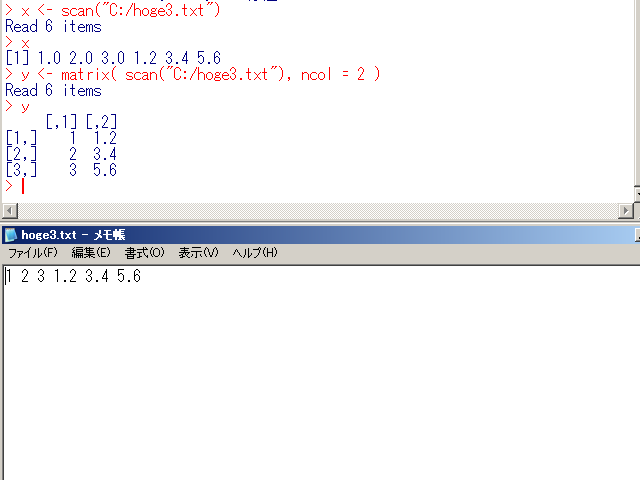
テキストファイルからの読み出しの例 - xls ファイルの読み出し: read.xls()
library(gregmisc) d <- read.xls("a.xls") - xlsx ファイルの読み出し: read.xlsx()
- 前準備
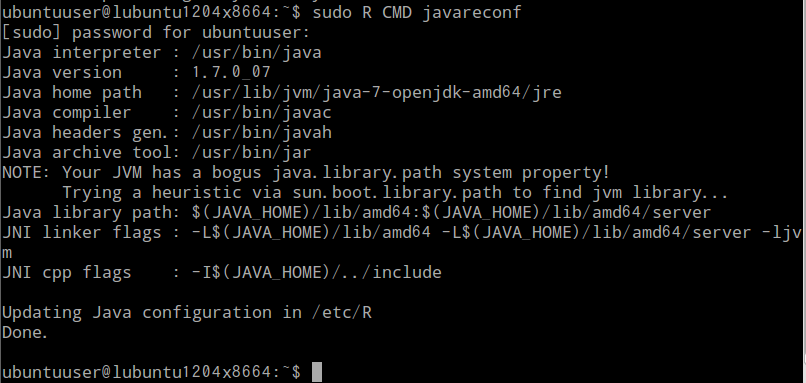
- 端末で「sudo R CMD javareconf」を実行
- /etc/ld.so.conf の書き換え
◇ 設定例: 次の1行を追加
/usr/lib/jvm/java-8-oracle/jre/lib/amd64/jamvm
- パッケージのインストール
install.packages("rJava") install.packages("xlsx")
R で次のコマンドを実行
- 端末で「sudo R CMD javareconf」を実行
- 使ってみる
ファイル名: a.xlsx, シート番号: 1 を読み込む例.
library(xlsx) d >- read.xlsx("a.xlsx", 1)
- 前準備
テキストファイルの書き込み
- テキストファイルへのデータフレームの書き込み write.table()
引数は,read.table() と類似しているので,ここでは省略します(read.table() を見てください).
- テキストファイルへの書き込み: write
読み出しの関数 scan() と対応する関数. つまり,write で書き込んだ行列のデータは,scan を使って,簡単にテキストファイルから読み込める. 主要なパラメータは,次の通り.
- file: ファイル名
- sep: 列を区切る記号

行列のファイルへの書き込みと読み出しの例
書式付の出力など
- 書式付きでの標準出力 sprintf
見やすい形で表示したい場合に使う. 書式の書き方は C 言語と同じ.オブジェクトが,文字列に変換されて出力されることに注意.
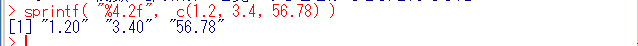
ベクトルの出力の例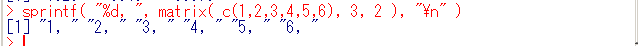
行列の出力の例(行列を出力すると,行列はベクトル化される) - 標準出力,あるいはファイルへの書き込み cat
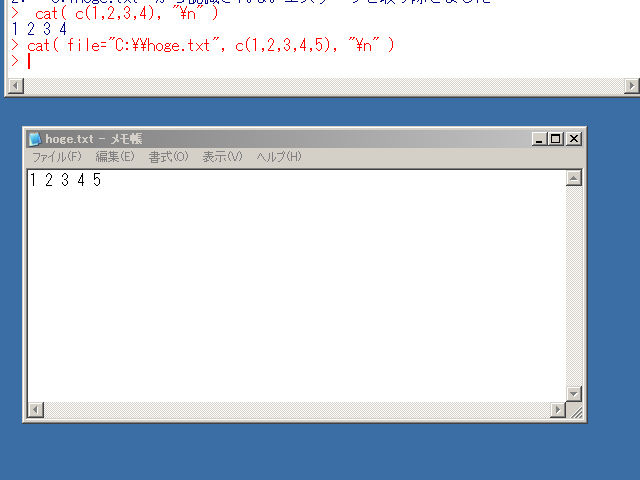
ベクトルの出力の例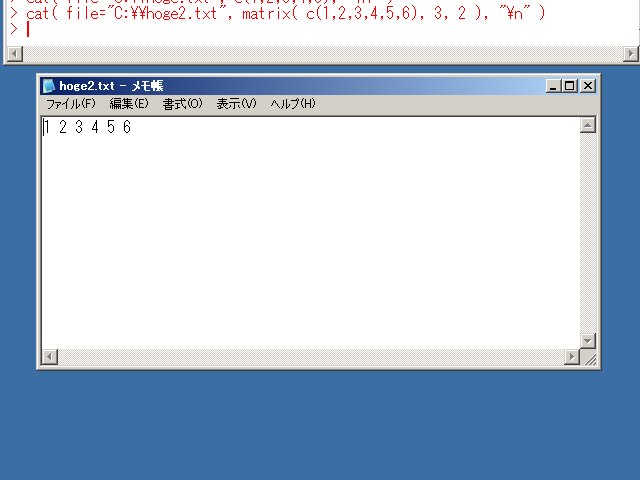
行列の出力の例(行列をファイルに出力すると,行列はベクトル化される)
(参考)read.table のマニュアル
Usage
read.table(file, header = FALSE, sep = "", quote = "\"'",
dec = ".", row.names, col.names,
as.is = !stringsAsFactors,
na.strings = "NA", colClasses = NA, nrows = -1,
skip = 0, check.names = TRUE, fill = !blank.lines.skip,
strip.white = FALSE, blank.lines.skip = TRUE,
comment.char = "#",
allowEscapes = FALSE, flush = FALSE,
stringsAsFactors = default.stringsAsFactors(),
encoding = "unknown")
"
Arguments
- file the name of the file which the data are to be read from. Each row of the table appears as one line of the file. If it does not contain an absolute path, the file name is relative to the current working directory, getwd(). Tilde-expansion is performed where supported. Alternatively, file can be a readable text-mode connection (which will be opened for reading if necessary, and if so closed (and hence destroyed) at the end of the function call). (If stdin() is used, the prompts for lines may be somewhat confusing. Terminate input with a blank line or an EOF signal, Ctrl-D on Unix and Ctrl-Z on Windows. Any pushback on stdin() will be cleared before return.) file can also be a complete URL. To read a data file not in the current encoding (for example a Latin-1 file in a UTF-8 locale or conversely) use a file connection setting the encoding argument.
- header a logical value indicating whether the file contains the names of the variables as its first line. If missing, the value is determined from the file format: header is set to TRUE if and only if the first row contains one fewer field than the number of columns.
- sep the field separator character. Values on each line of the file are separated by this character. If sep = "" (the default for read.table) the separator is ‘white space’, that is one or more spaces, tabs, newlines or carriage returns.
- quote the set of quoting characters. To disable quoting altogether, use quote = "". See scan for the behaviour on quotes embedded in quotes. Quoting is only considered for columns read as character, which is all of them unless colClasses is specified.
- dec the character used in the file for decimal points.
- row.names a vector of row names. This can be a vector giving the actual row names, or a single number giving the column of the table which contains the row names, or character string giving the name of the table column containing the row names. If there is a header and the first row contains one fewer field than the number of columns, the first column in the input is used for the row names. Otherwise if row.names is missing, the rows are numbered. Using row.names = NULL forces row numbering. Missing or NULL row.names generate row names that are considered to be ‘automatic’ (and not preserved by as.matrix).
- col.names a vector of optional names for the variables. The default is to use "V" followed by the column number.
- as.is the default behavior of read.table is to convert character variables (which are not converted to logical, numeric or complex) to factors. The variable as.is controls the conversion of columns not otherwise specified by colClasses. Its value is either a vector of logicals (values are recycled if necessary), or a vector of numeric or character indices which specify which columns should not be converted to factors. Note: to suppress all conversions including those of numeric columns, set colClasses = "character". Note that as.is is specified per column (not per variable) and so includes the column of row names (if any) and any columns to be skipped.
- na.strings a character vector of strings which are to be interpreted as NA values. Blank fields are also considered to be missing values in logical, integer, numeric and complex fields.
- colClasses character. A vector of classes to be assumed for the columns. Recycled as necessary, or if the character vector is named, unspecified values are taken to be NA. Possible values are NA (when type.convert is used), "NULL" (when the column is skipped), one of the atomic vector classes (logical, integer, numeric, complex, character, raw), or "factor", "Date" or "POSIXct". Otherwise there needs to be an as method (from package methods) for conversion from "character" to the specified formal class. Note that colClasses is specified per column (not per variable) and so includes the column of row names (if any).
- nrows integer: the maximum number of rows to read in. Negative and other invalid values are ignored.
- skip integer: the number of lines of the data file to skip before beginning to read data.
- check.names logical. If TRUE then the names of the variables in the data frame are checked to ensure that they are syntactically valid variable names. If necessary they are adjusted (by make.names) so that they are, and also to ensure that there are no duplicates.
- fill logical. If TRUE then in case the rows have unequal length, blank fields are implicitly added. See ‘Details’.
- strip.white logical. Used only when sep has been specified, and allows the stripping of leading and trailing white space from character fields (numeric fields are always stripped). See scan for further details, remembering that the columns may include the row names.
- blank.lines.skip logical: if TRUE blank lines in the input are ignored.
- comment.char character: a character vector of length one containing a single character or an empty string. Use "" to turn off the interpretation of comments altogether.
- allowEscapes logical. Should C-style escapes such as \n be processed or read verbatim (the default)? Note that if not within quotes these could be interpreted as a delimiter (but not as a comment character). For more details see scan.
- flush logical: if TRUE, scan will flush to the end of the line after reading the last of the fields requested. This allows putting comments after the last field.
- stringsAsFactors logical: should character vectors be converted to factors? Note that this is overridden bu as.is and colClasses, both of which allow finer control.
- encoding encoding to be assumed for input strings. It is used to mark character strings as known to be in Latin-1 or UTF-8: it is not used to re-encode the input. For an example of how to do so, see the examples under file.
- ... Further arguments to be passed to read.table.
References
Chambers, J. M. (1992) Data for models. Chapter 3 of Statistical Models in S eds J. M. Chambers and T. J. Hastie, Wadsworth & Brooks/Cole.