R システムを用いた不偏相関係数行列
このページでは,R システムを用いた不偏相関係数行列の求め方と図解で説明する.
さらに、単純な R の関数の組み合わせを使って不偏相関係数行列を求めるという手順を通して、不偏相関係数行列と R の使い方を深く学びます. (ここでは説明しませんが octave の cor 関数を使った場合も,R と同様の結果が出てきます)
不偏相関係数行列は、 R システムを用いた不偏分散共分散行列のページで説明している.
前準備
R システムのインストール
【関連する外部ページ】
R システムの CRAN の URL: https://cran.r-project.org/
CSVファイルを読み込み,データフレームに格納
- (前準備) 使用する CSV ファイルの作成
Book1.csv をダウンロード (参考: 「外国為替データ(時系列データ)の情報源の紹介」の Web ページ)
以下の説明では、
- Windows の場合: データファイル名: C:\R\Book1.csv
- Linuxの場合: データファイル名: /tmp/Book1.csv
として説明を続ける.
* 自前の CSV ファイルを使うときの注意: read.table() 関数を使うので, 属性名は英語になっていること.属性名は,CSV ファイルの第一行目に書いていること.
- 使用する CSV ファイルの確認
属性名が CSV ファイルの1行目に書かれていることを確認する.
- R の起動
- 「read.table」を用いて,CSV ファイルを R のデータフレームに読み込み
次のコマンドを実行.
◆ Windows での動作手順例
X <- read.table("C:/R/Book1.csv", header=TRUE, sep=",", na.strings="NA", dec=".", strip.white=TRUE);◆ Linux での動作手順例
X <- read.table("/tmp/Book1.csv", header=TRUE, sep=",", na.strings="NA", dec=".", strip.white=TRUE);R の read.table のオプション
- X <- ・・・ 変数 X に読み込むという意味
- C:/R/Book1.csv, "/tmp/Book1.csv" ・・・ 読み込む CSV ファイル名.Windows では区切りには「/」を使うことに注意.
- header="TRUE" または header="FALSE" ・・・ 列ラベルが設定されているか
- seq="," や seq="\" や seq=" " や ・・・ 列を区切る記号(CSV ファイルのときは「seq=","」)
- na.string="NA" ・・・ Not a Number には "NA" を使うという意味
- dec="." ・・・ ファイルで使われている小数点記号(既定値は,ピリオド)
- strip.white=TRUE ・・・ 個々のデータの先頭や末尾にある「空白文字」を取り除いて読み込む
- skip=<行数> ・・・ 読み飛ばし行数
- nrow=<行数> ・・・ 読み込み行数
- (その他のオプション) dec: ファイルで使われている小数点記号を指定できる
- オブジェクト X の確認
次のコマンドを実行.
edit(X);次のコマンドを実行.
str(X)
cor() 関数を使って不偏相関係数行列を求める
- cor() 関数を使って不偏相関係数行列を求める
次のコマンドを実行. データはUSDとEURとAUDの3列(それぞれ3列目と4列目と5列目)なので、 「3:5」と書く.これは「c(3,4,5)」と同じ意味.
不偏相関係数行列が結果として得られる. 結果が3行3列の配列になっている.
cor( X[,3:5] )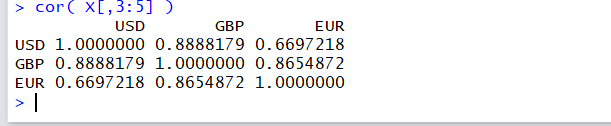
より基本的な関数を使って相関係数を求める手順
概要
R の cor() 関数を使う方法だと、中身がブラックボックスです. 実は,以下の 2 つの R の式が,同じ結果になります. ここでは、確かに同じ結果になることを確認する手順を,図解などで説明する.
- cor() 関数を使って,相関係数を求める R の式
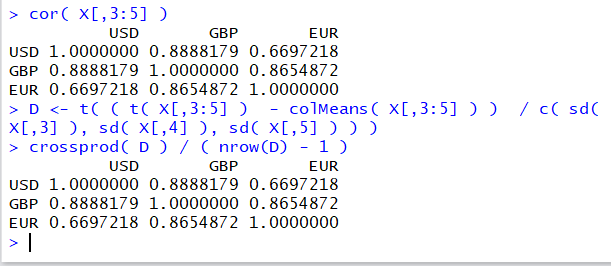
cor( X[,3:5] )
- mean() 関数, t() 関数などを使って,相関係数を求める R の式
crossprod( D ) / ( nrow(D) - 1 ) * この式は「t( D ) %*% t( D ) / ( nrow(D) - 1 )」と同じ意味
但し、D は次の手順で作る. D は,行列 X の各列の平均値を X の各要素から引き,不偏標準偏差で割った後,転置した行列になっている.
D <- t( ( t( X[,3:5] ) - colMeans( X[,3:5] ) ) / c( sd( X[,3] ), sd( X[,4] ), sd( X[,5] ) ) )
手順
上では「crossprod( D ) / ( nrow(D) - 1 )」, 「D <- t( ( t( X[,3:5] ) - mean( X[,3:5] ) ) / sd( X[,3:5]) ) 」のように書きました。 式が複雑なのでこれを一歩一歩確かめて、R の理解を深めます.
- X <- ・・・ 変数 X に読み込むという意味
- C:/R/Book1.csv, "/tmp/Book1.csv" ・・・ 読み込む CSV ファイル名.Windows では区切りには「/」を使うことに注意.
- header="TRUE" または header="FALSE" ・・・ 列ラベルが設定されているか
- seq="," や seq="\" や seq=" " や ・・・ 列を区切る記号(CSV ファイルのときは「seq=","」)
- na.string="NA" ・・・ Not a Number には "NA" を使うという意味
- dec="." ・・・ ファイルで使われている小数点記号(既定値は,ピリオド)
- strip.white=TRUE ・・・ 個々のデータの先頭や末尾にある「空白文字」を取り除いて読み込む
- skip=<行数> ・・・ 読み飛ばし行数
- nrow=<行数> ・・・ 読み込み行数
- (その他のオプション) dec: ファイルで使われている小数点記号を指定できる
- オブジェクト X の確認
次のコマンドを実行.
edit(X);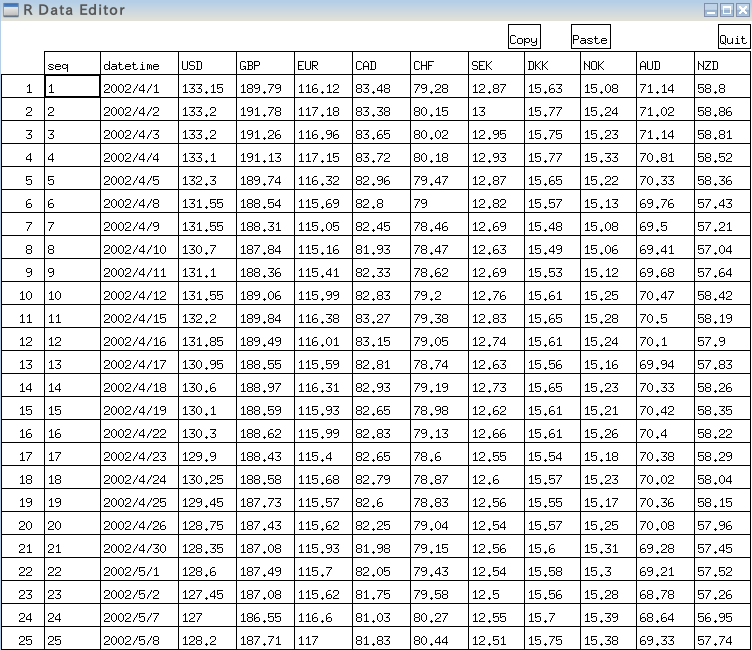
- X の各列の平均を求める
データはUSDとEURとAUDの3列(それぞれ3列目と4列目と5列目)あることに注意して下さい.この 3 列について, 各列ごとに平均を求めます. 「3:5」は「c(3,4,5)」と同じ意味.平均を求めた結果はベクトルになる.
colMeans( X[,3:5] )
- 行列 X の各要素から,X の列の平均値を引く
つまり、次のことを行いたいのです.
- X の3列目の要素全てから,colMeans( X[,3:5] )の第1要素(つまり数)を引く
- X の4列目の要素全てから,colMeans( X[,3:5] )の第2要素(つまり数)を引く
- X の5列目の要素全てから,colMeans( X[,3:5] )の第3要素(つまり数)を引く:
* ここで行っていることは, 変数 X 内の3列目と4列目と5列目がなす「3次元のベクトル集合」の平均が原点になるように,平行移動させる操作とみなすことができる.
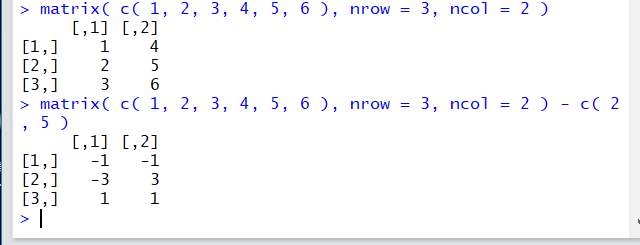
行列からベクトルの引き算を行うとき、リサイクル規則が使われます. ここで、リサイクル規則を、例を使って、簡単に説明する. 次のような,要素 1, 2, 3, 4, 5, 6 が入った3行2列の行列があるとします.
1 4 2 5 3 6
この行列に対して、ベクトル c(2, 5) の引き算を行うと,リサイクル規則から、 ベクトル c(2, 5) が、次のような行列に引き伸ばされる.
2 5 5 2 2 5
matrix( c( 1, 2, 3, 4, 5, 6 ), nrow = 3, ncol = 2 ) matrix( c( 1, 2, 3, 4, 5, 6 ), nrow = 3, ncol = 2 ) - c( 2, 5 )実行結果の例は次の通りです.
今度は,要素 1, 4, 2, 5, 3, 6 が入った2行3列の行列があるとします.
1 2 3 4 5 6
この行列に対して、ベクトル c(2, 5) の引き算を行うと,リサイクル規則から、 ベクトル c(2, 5) が、次のような行列に引き伸ばされる.
2 2 2 5 5 5
matrix( c( 1, 4, 2, 5, 3, 6 ), nrow = 2, ncol = 3 ) matrix( c( 1, 4, 2, 5, 3, 6 ), nrow = 2, ncol = 3 ) - c( 2, 5 )実行結果の例は次の通りです.

行列の行数と,ベクトルの長さが等しいときは, 行列の各要素から,ベクトルの値を引く(行列の行番号と、ベクトルの要素番号が等しい)ことが見て取れます.
「行列の各要素から,列の平均値を引く」こと行ってみる. 行列 X[,3:5] を転置させて,3行610列の行列を作り,列の平均値のベクトル(ベクトルの長さは3)で引き算します. リサイクル規則が使えるので、次のような簡単な式になる.(結果は3行610列の行列です).
* データを転置したいので関数 t() を使う. データはUSDとEURとAUDの3列(それぞれ3列目と4列目と5列目)あることに注意.
D <- t( t( X[,3:5] ) - colMeans( X[,3:5] ) ) edit(D);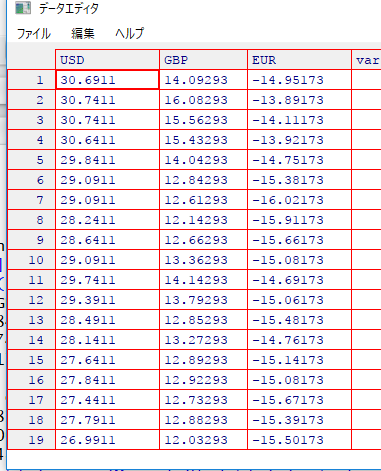
上記の式に少し書き加えて、 各列ごとに平均と標準偏差を求め,その平均と標準データを使って,データ d の基準値を求めて,変数 D に格納することを行う.基準値と言っているのは,
基準値 = ( 元の値 - 元の値の列における平均値 ) / 元の値の列における標準偏差
です.これは,(仮想的な)3次元空間において,先ほどの点の集まりが原点を中心として,分散1になるように分布するように,平行移動と拡大・縮小させる操作とみなすことができる.
D <- t( ( t( X[,3:5] ) - colMeans( X[,3:5] ) ) / c( sd( X[,3] ), sd( X[,4] ), sd( X[,5] ) ) ) edit(D);
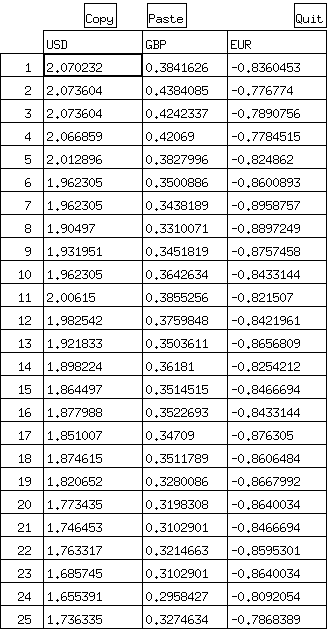
上のように書く代わりに、次のように書いても同じ意味ですが、リサイクル規則を使わないと、書くのが面倒です * 「V[,3] - colMeans(V[,3])」は,「3列目」の全ての要素から「3列目の平均値」を引くという意味.
hoge <- matrix( c( ( ( X[,3] - mean(X[,3]) ) / sd(X[,3]) ), ( ( X[,4] - mean(X[,4]) ) / sd(X[,4]) ), ( ( X[,5] - mean(X[,5]) ) / sd(X[,5]) ) ), nrow = 2834, ncol = 3 ); edit(hoge);
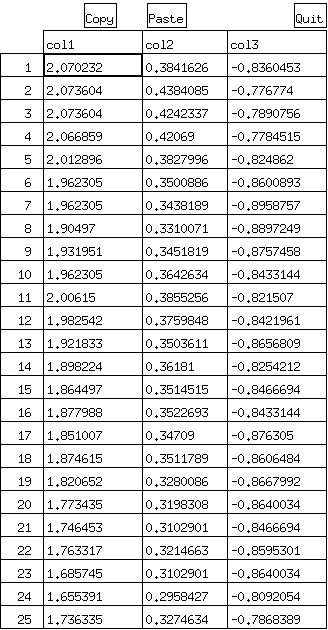
- 相関係数を求める
crossprod() 関数はクロス積(この場合 t(D) %*% D)を求める関数です.D は、610行3列の行列になっていることに注意.
crossprod( D ) / ( nrow(D) - 1 )
次のコマンドを実行.
◆ Windows での動作手順例
X <- read.table("C:/R/Book1.csv", header=TRUE, sep=",", na.strings="NA", dec=".", strip.white=TRUE);
◆ Linux での動作手順例
X <- read.table("/tmp/Book1.csv", header=TRUE, sep=",", na.strings="NA", dec=".", strip.white=TRUE);
オプション
