統計分析のPython実現ガイド
【概要】pandas、SciPy、Matplotlib、statsmodelsを用いた基礎的な統計分析(探索的データ解析と古典的仮説検定)のPython実装ガイドである。記述統計量、ヒストグラム、箱ひげ図、クロス集計表、相関分析、検定(t検定、一元配置分散分析、正規性検定、等分散性検定、カイ二乗独立性検定、Mann-Whitney U検定)、分散分析後の多重比較を扱う。各手法のPythonコードと実行結果を示す。
【本資料の前提】
- 実行環境はWindows PCを前提とする。GPU搭載機・CPUのみのいずれでも本資料のコードは動作する(本分野の処理にGPUは不要)。Linuxの知識は必要としない。
- 掲載コードはpandas、SciPy、Matplotlibの現行版の挙動に基づく。統計量・検定の数値は、以下の計算規約により他ツール(SPSS、R)と一致しない場合がある。
- 歪度・尖度:
scipy.stats.skew()とscipy.stats.kurtosis()は既定でバイアス補正を行わない(bias=True)。kurtosis()は既定で超過尖度(正規分布で0)を返す(fisher=True)。 - 標準偏差:pandasの
std()とdescribe()は既定で不偏(ddof=1)。numpy.std()は既定でddof=0。 - t検定:
stats.ttest_ind()の既定は等分散を仮定する通常のt検定(equal_var=True)。Welch検定にはequal_var=Falseを指定する(Rのt.testは既定でWelch検定)。
- 歪度・尖度:
- 各プログラム例は手法ごとに独立しており、用いるデータも例ごとに異なる。掲載の検定結果は少数または人工データに基づく。検定はp値のみで判断せず、可視化・効果量と併せて評価する。小標本では検出力が低く、大標本では小さな差でも有意になりやすい。
【目次】
統計手法
本資料で扱う手法を内容ごとに列挙する。
- 記述統計量
- ヒストグラム
- 箱ひげ図
- クロス集計表
- 相関分析(Pearson、Spearman)
- 検定(t検定、一元配置分散分析、正規性検定、等分散性検定、カイ二乗独立性検定、Mann-Whitney U検定)
- 分散分析後の多重比較(Tukey HSD)
記述統計量
記述統計量は、データセットの特徴を数値で要約する指標である。データ全体の特性を把握し、分析手法の選択に用いる。
基本的な統計量を以下に示す。
- 平均値:データの中心傾向を示す
- 標準偏差:データのばらつきを示す
- 中央値:データの中心傾向を示す
- 四分位数:分布の位置と広がりを示す
- 最大値:データの上限値
- 最小値:データの下限値
- 分散:データのばらつきを示す
- 歪度:分布の非対称性を示す
- 尖度:分布の尖り具合を示す
用語リスト
- 記述統計量:データの特徴を数値で要約する指標の総称。平均値、標準偏差、中央値などを含む。
- 平均値:データの総和をデータ数で除した値。外れ値の影響を受けやすい。
- 標準偏差:ばらつきの指標。各データ点と平均値との差の二乗平均の平方根。pandasでは既定で不偏(
ddof=1)。 - 中央値:データを昇順に並べたときの中央の値。外れ値の影響を受けにくい。
- 四分位数:データを4等分する境界値。第1四分位数、中央値(第2四分位数)、第3四分位数から成る。外れ値の検出にも用いる。
- 最大値・最小値:データ内の最高値・最低値。両者でデータの範囲を示す。
- 分散:各データ点と平均値の差の二乗の平均。標準偏差の二乗。
- 歪度:分布の非対称性の指標。正規分布で約0、正値は右に裾が長い分布を示す。
scipy.stats.skew()は既定でバイアス補正を行わない。 - 尖度:分布の尖り具合の指標。
scipy.stats.kurtosis()は既定で超過尖度を返し(正規分布で0)、バイアス補正を行わない。 - 検定統計量:検定で算出され、帰無仮説の下での理論分布と比較する値(t値、F値、W統計量など)。この値と分布からp値を求める。
- pandas:データ分析用ライブラリ。
describeで主要統計量を一括算出する。 - 属性:データフレームにおける各列。
- データフレーム:行と列から成る2次元データ構造。pandasの中核機能。
- 外れ値:他から大きく離れた値。分析結果に影響するため適切な処理を要する。
- 分布:データの散らばり方や偏りを示す概念。
- ヒストグラム:データの範囲を区間に分割し、各区間の頻度を棒で表すグラフ。
- 箱ひげ図:中央値、四分位数、最大値、最小値を一度に表示するグラフ。外れ値の検出やグループ間比較に用いる。
- クロス集計表:2つのカテゴリ変数の組み合わせごとの度数を表で示す手法。
- 相関係数:2変数間の関係の強さを示す指標。Pearsonは線形関係、Spearmanは順位に基づく単調関係を測る。
- 帰無仮説:「差がない」「効果がない」と仮定する仮説。検定ではこれを棄却できるかを判断する。
- 有意水準:帰無仮説を棄却する基準となる確率。一般に5%(0.05)または1%(0.01)。p値がこの値を下回ると有意と判断する。
- p値:帰無仮説が真のとき、観測データと同等以上に極端な結果が得られる確率。有意水準未満で有意と判断する。
- 効果量:差や関連の大きさを表す指標(Cohenのd、Cramér's Vなど)。p値とは別に効果の実質的大きさを評価する。
- t検定:2群の平均値の差を評価する検定。帰無仮説は「2群の母平均が等しい」。
- Welchのt検定:等分散を仮定しないt検定。
ttest_ind(equal_var=False)で実行する。 - 等分散性検定(Levene検定):複数群の分散が等しいかを検定する。帰無仮説は「各群の分散が等しい」。
scipy.stats.levene()。 - ノンパラメトリック検定:母集団分布の形状を仮定しない検定。順位や符号を用いる。
- Mann-Whitney U検定:独立2群の分布差を検定するノンパラメトリック検定。Wilcoxon順位和検定と等価。正規性を仮定できない場合のt検定の代替。
scipy.stats.mannwhitneyu()。 - 一元配置分散分析:3群以上の平均値差を同時に検定する手法。
scipy.stats.f_oneway()。 - 多重比較(事後検定):分散分析で有意となった後、どの群間に差があるかを調べる手法。Tukey HSDなど。
statsmodelsで実装する。 - カイ二乗独立性検定:クロス集計表の2変数が独立かを検定する。
scipy.stats.chi2_contingency()。 - Shapiro-Wilk検定:正規性の検定。帰無仮説は「母集団が正規分布に従う」。最低3観測を要し、N>5000ではp値の精度が下がる。
scipy.stats.shapiro()。 - データ分析:収集したデータから情報や知見を抽出するプロセス。
- 統計指標:データの特徴を数値化して表現する指標。
統計処理の比較
同じ統計処理を異なるツールで実行する際のコマンドを比較する。各ツールで既定の挙動が異なる場合がある(特にt検定)。
| 処理内容 | SPSS | R | Python (pandas/scipy/statsmodels) |
|---|---|---|---|
| 記述統計量 | DESCRIPTIVES、FREQUENCIES | summary、sd、skewness、kurtosis | df.describe()、stats.skew()、stats.kurtosis() |
| 頻度表 | FREQUENCIES | table | value_counts() |
| クロス集計表 | CROSSTABS | table | pd.crosstab() |
| 集約 | AGGREGATE | aggregate | groupby().agg() |
| 相関 | CORRELATIONS | cor、cor.test | df.corr()、stats.pearsonr()、stats.spearmanr() |
| 通常のt検定 | T-TEST | t.test(..., var.equal=TRUE) | stats.ttest_ind()(既定) |
| Welchのt検定 | T-TEST | t.test(既定) | stats.ttest_ind(equal_var=False) |
| 等分散性検定 | EXAMINE | leveneTest | stats.levene() |
| 一元配置分散分析 | ONEWAY | aov、oneway.test | stats.f_oneway() |
| 多重比較(Tukey) | POSTHOC | TukeyHSD | pairwise_tukeyhsd() |
| カイ二乗独立性検定 | CROSSTABS /STATISTICS | chisq.test | stats.chi2_contingency() |
| Mann-Whitney U検定 | NPAR TESTS | wilcox.test | stats.mannwhitneyu() |
Pythonのttest_ind()は既定が通常のt検定(equal_var=True)であり、Welch検定にはequal_var=Falseを指定する。Rのt.testは既定でWelch検定を行う。
Pythonプログラム例
記述統計・可視化では以下の成績データを用いる。クロス集計以降の検定では、手法の説明のため例ごとに別データを用いる。
| 科目 | 受講者 | 得点 |
|---|---|---|
| 国語 | A | 90 |
| 国語 | B | 80 |
| 算数 | A | 95 |
| 算数 | B | 90 |
| 理科 | A | 80 |
データフレームの作成
pandasのデータフレームは表形式データの基本構造である。ここでは成績データを辞書から作成し、データフレームへ変換する。
- データ作成:辞書
dataに科目、受講者、得点を格納する。 - データフレームの作成:
pd.DataFrame(data)で変換する。 - データ型の指定:
astype()で「科目」「受講者」をカテゴリ型、「得点」を整数型(int32)にする。カテゴリ型は取り得る値の種類が限られる列でメモリ効率が向上する(効果が顕著になるのは大規模データであり、本例の5行データでは体感できない一般的説明である)。
import pandas as pd
data = {
'科目': ['国語', '国語', '算数', '算数', '理科'],
'受講者': ['A', 'B', 'A', 'B', 'A'],
'得点': [90, 80, 95, 90, 80]
}
df = pd.DataFrame(data)
df = df.astype({'科目': 'category', '受講者': 'category', '得点': 'int32'})
print("基本データ:")
print(df)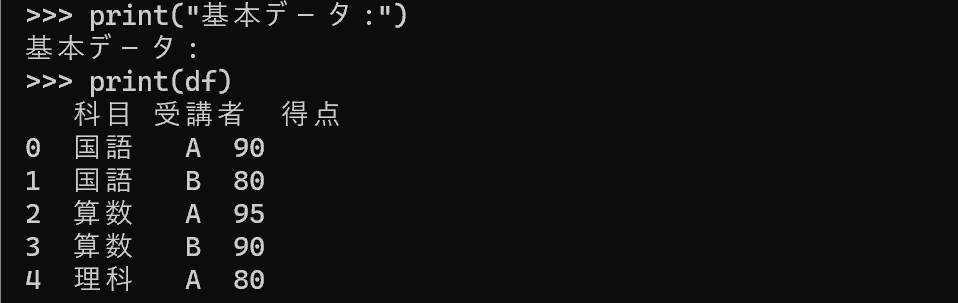
個別の統計量計算
個々の統計量を個別に算出する。特定の統計量のみ必要な場合や、計算過程を確認したい場合に用いる。
- 「得点」に対し、平均、標準偏差、中央値、最大値、最小値、四分位数を算出し、scipyで歪度と尖度を算出する。
ddof=1は分母を「データ数 − 1」とする標本標準偏差(不偏推定)を指定する。pandasのstd()は既定でddof=1だが、numpy.std()は既定でddof=0のため使い分けに注意する。stats.skew()とstats.kurtosis()は既定でバイアス補正を行わない(他ツールと値が異なる場合がある)。
import pandas as pd
from scipy import stats
data = {
'科目': ['国語', '国語', '算数', '算数', '理科'],
'受講者': ['A', 'B', 'A', 'B', 'A'],
'得点': [90, 80, 95, 90, 80]
}
df = pd.DataFrame(data)
df = df.astype({'科目': 'category', '受講者': 'category', '得点': 'int32'})
scores = df['得点']
print("基本統計量:")
print(f"平均値: {scores.mean():.1f}")
print(f"標準偏差(ddof=1): {scores.std(ddof=1):.1f}")
print(f"中央値: {scores.median():.1f}")
print(f"最大値: {scores.max()}")
print(f"最小値: {scores.min()}")
print(f"第1四分位数: {scores.quantile(0.25):.1f}")
print(f"第3四分位数: {scores.quantile(0.75):.1f}")
print(f"歪度: {stats.skew(scores):.3f}")
print(f"尖度(超過尖度): {stats.kurtosis(scores):.3f}")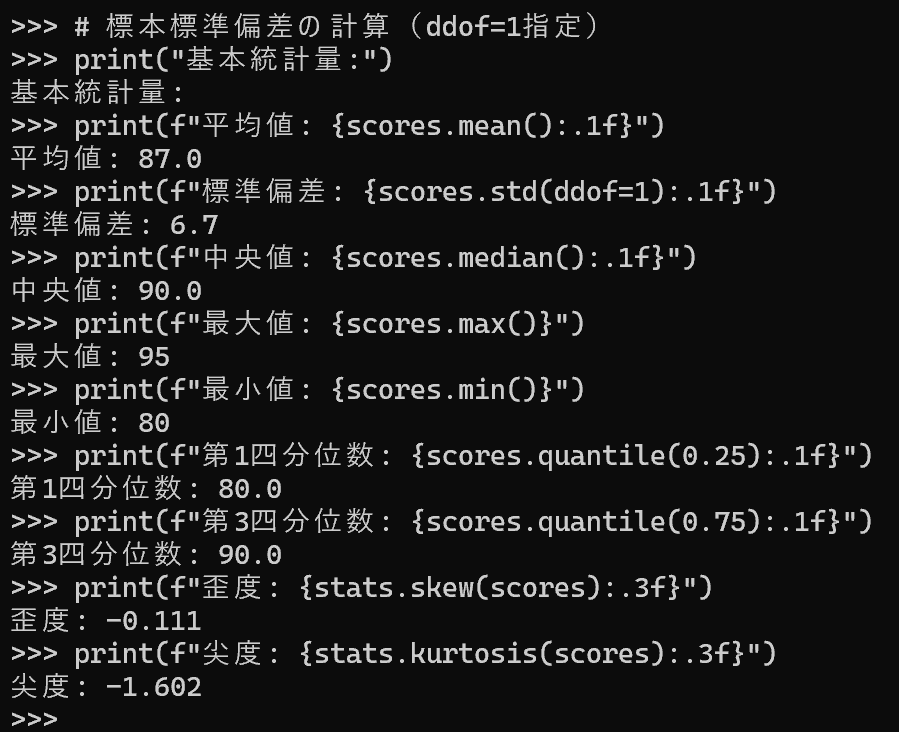
総合的な統計分析
describe()は主要な記述統計量を一括算出する。stdは不偏(ddof=1)で出力される。
- 総合分析:
describe()で全体の基本統計量を一括算出する。 - カテゴリ別分析:
groupby()とdescribe()を組み合わせ、科目ごとの統計量を算出する。カテゴリ型の列でグループ化する際は、出現する組み合わせのみを対象とするためobserved=Trueを指定する。
import pandas as pd
data = {
'科目': ['国語', '国語', '算数', '算数', '理科'],
'受講者': ['A', 'B', 'A', 'B', 'A'],
'得点': [90, 80, 95, 90, 80]
}
df = pd.DataFrame(data)
df = df.astype({'科目': 'category', '受講者': 'category', '得点': 'int32'})
print("総合的な統計量:")
print(df['得点'].describe())
print("\n科目別の統計量:")
print(df.groupby('科目', observed=True)['得点'].describe())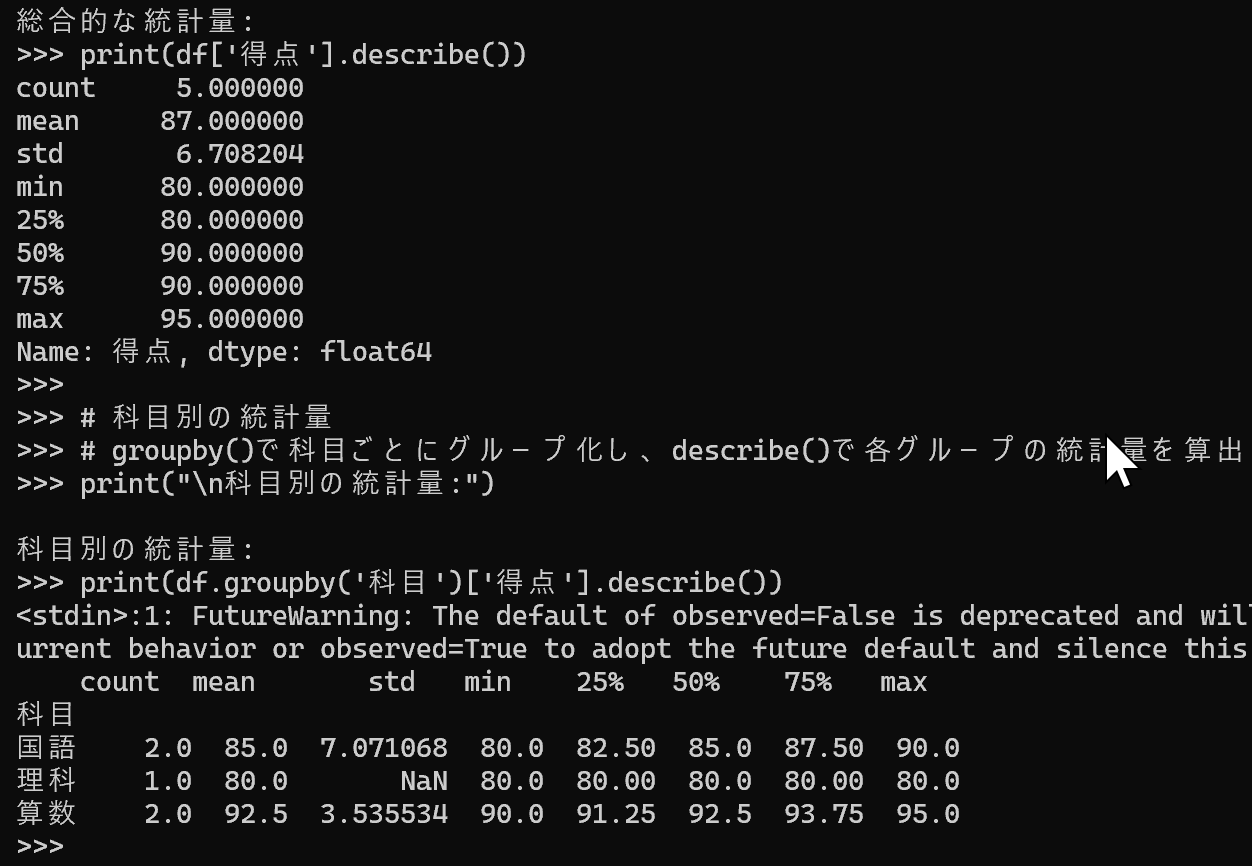
データの可視化(箱ひげ図とヒストグラム)
- 箱ひげ図:pandasの
boxplotで科目別の得点分布を可視化する。中央値、四分位数、外れ値を確認できる。 - ヒストグラム:
plt.histで得点分布を表示する。binsで区間(ビン)の境界を指定する。 - 日本語表示:前掲の
rcParams設定を描画前に行う。
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.family'] = 'Meiryo'
plt.rcParams['axes.unicode_minus'] = False
data = {
'科目': ['国語', '国語', '算数', '算数', '理科'],
'受講者': ['A', 'B', 'A', 'B', 'A'],
'得点': [90, 80, 95, 90, 80]
}
df = pd.DataFrame(data)
df = df.astype({'科目': 'category', '受講者': 'category', '得点': 'int32'})
plt.figure(figsize=(10, 6))
df.boxplot(column='得点', by='科目')
plt.suptitle('')
plt.title('科目別得点分布', pad=15)
plt.ylabel('得点')
plt.grid(True)
plt.savefig('score_distribution.png', bbox_inches='tight')
plt.show()
plt.close()
plt.figure(figsize=(10, 6))
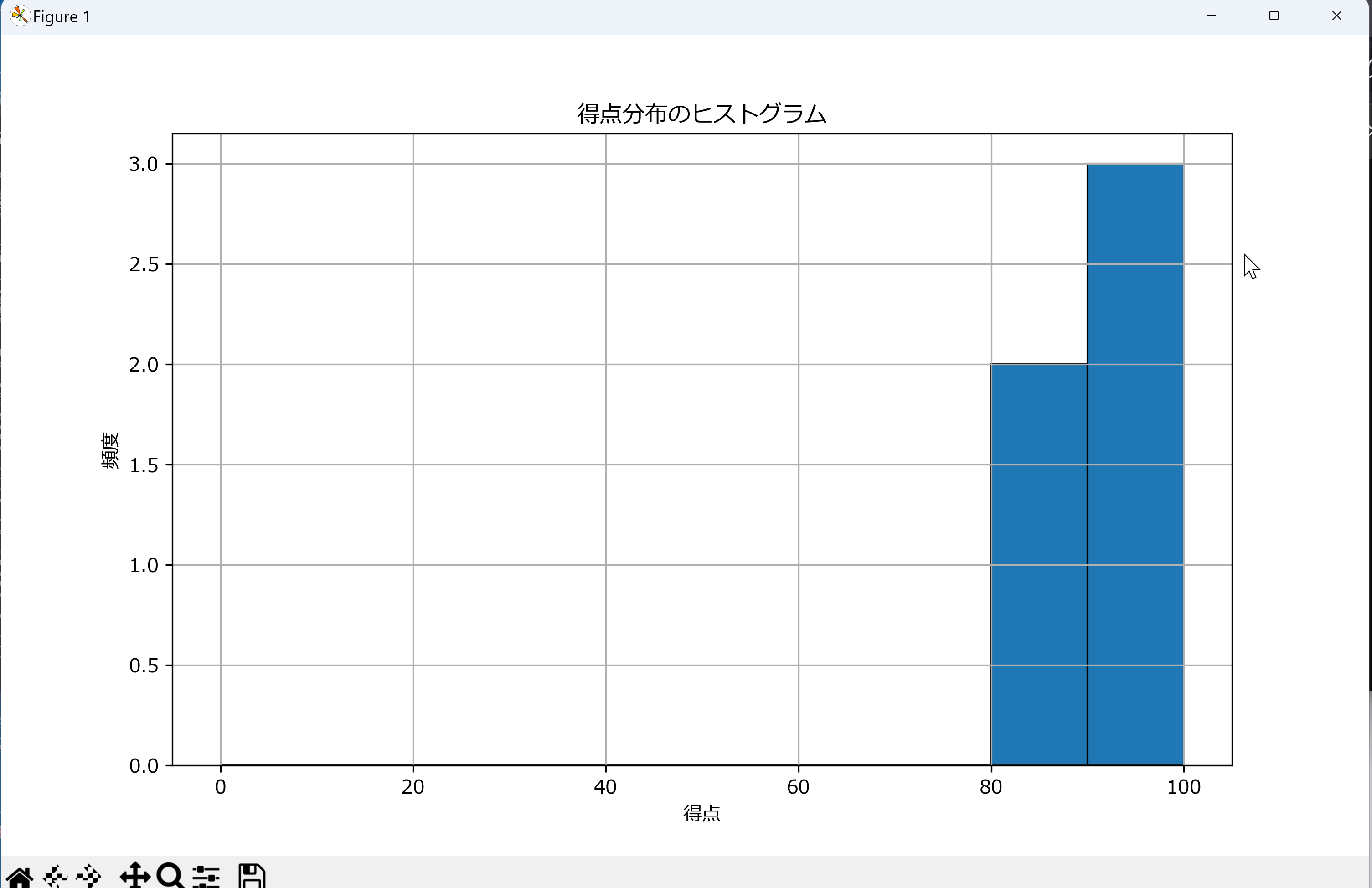
plt.hist(df['得点'], bins=range(0, 101, 10), edgecolor='black')
plt.title('得点分布のヒストグラム')
plt.xlabel('得点')
plt.ylabel('頻度')
plt.grid(True)
plt.savefig('score_histogram.png', bbox_inches='tight')
plt.show()
plt.close()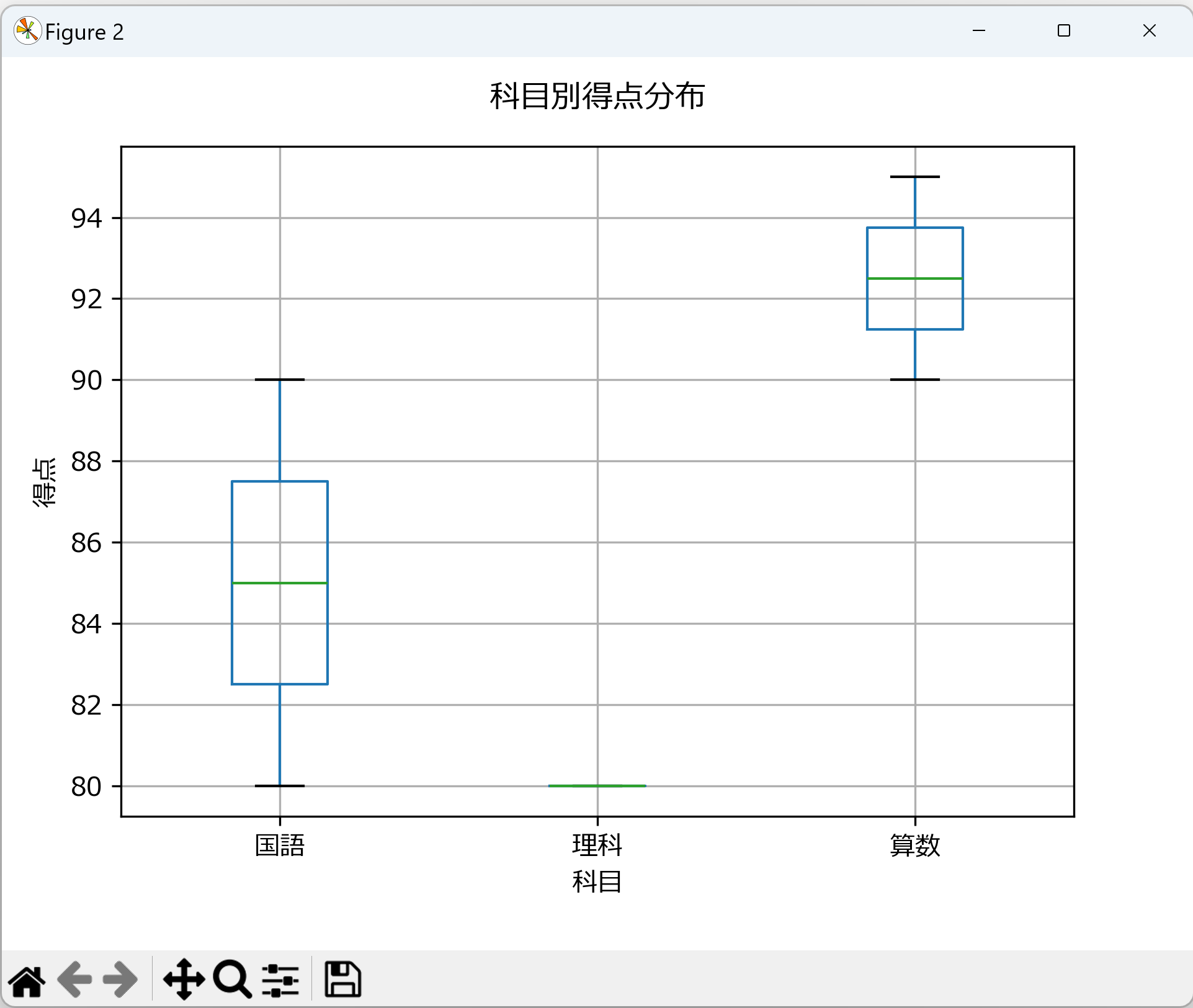
クロス集計表とカイ二乗独立性検定
クロス集計表は2つのカテゴリ変数の組み合わせごとの頻度を表で示す。カイ二乗検定で2変数が独立かを検定し、Cramér's Vで関連の強さ(効果量)を評価する。
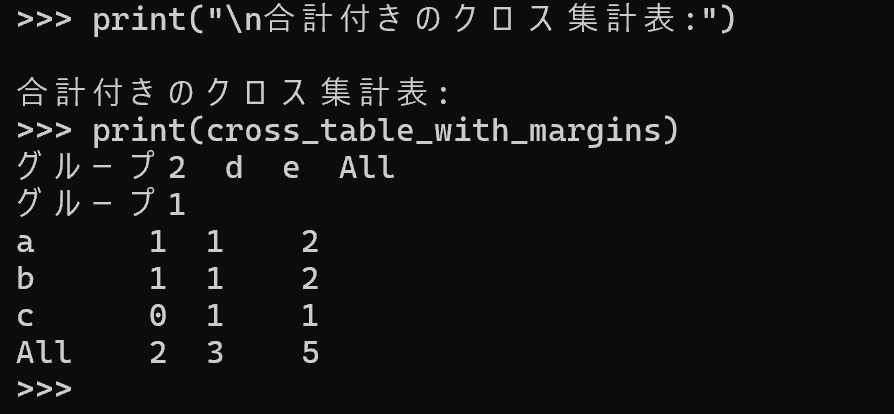
- クロス集計:
pd.crosstabの第1引数が行、第2引数が列となる。 - 合計:
margins=Trueで行・列の合計(名称はAll)が追加される。 - 独立性検定:
stats.chi2_contingencyに集計表(合計を含まないもの)を渡す。戻り値はカイ二乗統計量、p値、自由度、期待度数の順である。
import numpy as np
import pandas as pd
from scipy import stats
data = {
'グループ1': ['a', 'b', 'c', 'a', 'b'],
'グループ2': ['d', 'd', 'e', 'e', 'e']
}
df = pd.DataFrame(data)
cross_table = pd.crosstab(df['グループ1'], df['グループ2'])
print(cross_table)
cross_with_margins = pd.crosstab(df['グループ1'], df['グループ2'], margins=True)
print("\n合計付きクロス集計表(合計の名称はAll):")
print(cross_with_margins)
chi2, p, dof, expected = stats.chi2_contingency(cross_table)
print(f"\nカイ二乗統計量: {chi2:.3f}, p値: {p:.3f}, 自由度: {dof}")
n = cross_table.to_numpy().sum()
r, k = cross_table.shape
cramers_v = np.sqrt(chi2 / (n * (min(r, k) - 1)))
print(f"Cramér's V: {cramers_v:.3f}")このデータは標本数が少なく期待度数も小さいため、検定結果は説明目的の参考値である。
相関分析
連続変数間の関係の強さを相関係数で評価する。Pearsonは線形関係、Spearmanは順位に基づく単調関係を測る。
- 相関行列:
df.corr()で算出する(既定はPearson)。 - 個別の相関係数とp値:
stats.pearsonrとstats.spearmanrで算出する。いずれも戻り値は相関係数とp値の順である。
import pandas as pd
from scipy import stats
df = pd.DataFrame({
'x': [1, 2, 3, 4, 5, 6, 7, 8],
'y': [2, 1, 4, 3, 6, 5, 8, 7]
})
print("Pearson相関行列:")
print(df.corr(method='pearson'))
r_p, p_p = stats.pearsonr(df['x'], df['y'])
r_s, p_s = stats.spearmanr(df['x'], df['y'])
print(f"\nPearson r: {r_p:.3f} (p={p_p:.3f})")
print(f"Spearman r: {r_s:.3f} (p={p_s:.3f})")
等分散性の検定(Levene検定)とt検定
t検定の前に、Levene検定で2群の分散が等しいかを確認する。ここでは分散が等しくない場合にも適用できるWelchのt検定を実装する。
- 再現性:
np.random.seed(42)で乱数のシード(乱数生成の初期値)を固定すると、実行のたびに同じ乱数列が得られる。 - 等分散性検定:
stats.leveneの帰無仮説は「各群の分散が等しい」。 - t検定:
ttest_ind(equal_var=False)でWelch検定を行う。戻り値のTtestResultはstatistic、pvalue、df(自由度)を持つ。 - 解釈:p値が有意水準(一般に0.05)未満であれば、2群の平均値に有意な差があると判断する。
import numpy as np
from scipy import stats
np.random.seed(42)
group1 = np.random.normal(0, 1, 100)
group2 = np.random.normal(0.5, 1, 100)
lev_stat, lev_p = stats.levene(group1, group2)
print(f"Levene検定: 統計量={lev_stat:.3f}, p値={lev_p:.3f}")
res = stats.ttest_ind(group1, group2, equal_var=False)
print(f"t値: {res.statistic:.3f}")
print(f"p値: {res.pvalue:.3f}")
print(f"自由度: {res.df:.1f}")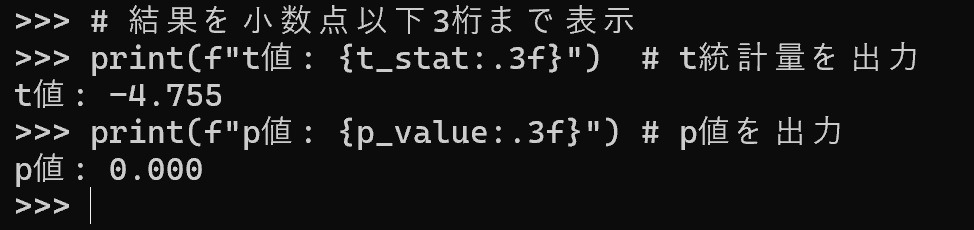
Mann-Whitney U検定(ノンパラメトリック)
正規性が仮定できない場合、t検定の代わりに独立2群のMann-Whitney U検定を用いる(Wilcoxon順位和検定と等価)。
- 実行:
stats.mannwhitneyuに2群のデータを渡す。alternative='two-sided'は両側検定を指定する。 - 解釈:p値が有意水準未満であれば、2群の分布に有意な差があると判断する。
from scipy import stats
group1 = [12, 15, 14, 10, 13, 11]
group2 = [18, 20, 17, 19, 16, 22]
res = stats.mannwhitneyu(group1, group2, alternative='two-sided')
print(f"U統計量: {res.statistic:.3f}")
print(f"p値: {res.pvalue:.3f}")
一元配置分散分析と多重比較(Tukey HSD)
3群以上の平均値の差は一元配置分散分析で検定する。t検定は2群間の比較に限られるため、3群以上にはこの手法を用いる。有意だった場合、どの群間に差があるかをTukey HSD(多重比較)で調べる。
- 分散分析:
stats.f_oneway()を用いる。 - 事後検定:
pairwise_tukeyhsdに値(endog)と群ラベル(groups)を渡す。Tukey HSDは群内分散が等しいことを仮定する。 - 解釈:分散分析のp値が有意水準未満であれば、少なくとも1組の群間に有意な差がある。
import numpy as np
from scipy import stats
from statsmodels.stats.multicomp import pairwise_tukeyhsd
group_a = [3.42, 3.84, 3.96, 3.76]
group_b = [3.17, 3.63, 3.47, 3.44, 3.39]
group_c = [3.64, 3.72, 3.91]
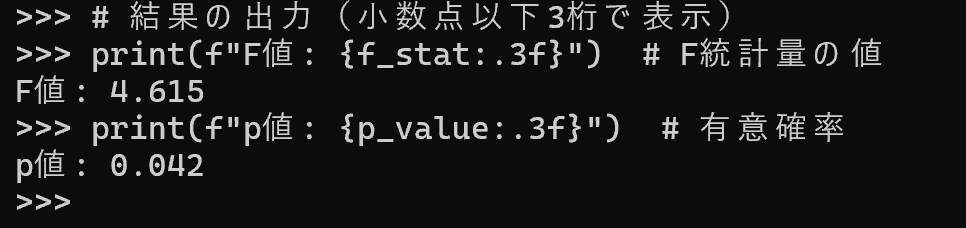
f_stat, p_value = stats.f_oneway(group_a, group_b, group_c)
print(f"F値: {f_stat:.3f}")
print(f"p値: {p_value:.3f}")
values = np.array(group_a + group_b + group_c)
labels = (['A'] * len(group_a)) + (['B'] * len(group_b)) + (['C'] * len(group_c))
tukey = pairwise_tukeyhsd(endog=values, groups=labels, alpha=0.05)
print(tukey)各群が3〜5個と小標本のため、結果は説明目的の参考値である。
正規性の検定(Shapiro-Wilk検定)
t検定や分散分析などのパラメトリック検定は正規性を仮定するため、事前にShapiro-Wilk検定で確認する。
- 実行:
stats.shapiro()を用いる。帰無仮説は「データは正規分布に従う」。最低3観測を要し、N>5000ではp値の精度が下がる。 - 再現性:
np.random.seed(42)で乱数のシードを固定する。 - 解釈:p値が有意水準(一般に0.05)以上であれば、帰無仮説を棄却できず、正規性を否定する根拠がない(正規分布に従うことの証明ではない)。有意水準未満であれば、正規分布に従わない可能性が高く、ノンパラメトリック検定の使用を検討する。小標本では検出力が低く、大標本では小さな差でも有意になりやすいため、ヒストグラムと併せて判断する。
import numpy as np
from scipy import stats
np.random.seed(42)
data = np.random.normal(0, 1, 100)
res = stats.shapiro(data)
print(f"検定統計量(W): {res.statistic:.3f}")
print(f"p値: {res.pvalue:.3f}")
前準備
Python 3.12のインストール(Windows) [クリックして展開]
以下のいずれかの方法でPython 3.12をインストールする。インストール済みの場合、この手順は不要である。
方法1:wingetによるインストール
管理者権限のコマンドプロンプトで以下を実行する。管理者権限のコマンドプロンプトは、Windowsキーまたはスタートメニューから「cmd」と入力し、表示された「コマンドプロンプト」を右クリックして「管理者として実行」を選択して起動する。
winget install --id Python.Python.3.12 -e --scope machine --silent --accept-source-agreements --accept-package-agreements --override "/quiet InstallAllUsers=1 PrependPath=1 Include_test=0 Include_pip=1 Include_launcher=1 InstallLauncherAllUsers=1 TargetDir=\"C:\Program Files\Python312\""
powershell -Command "$p='C:\Program Files\Python312'; $s=\"$p\Scripts\"; $m=[Environment]::GetEnvironmentVariable('Path','Machine'); if($m -notlike \"*$s*\") { [Environment]::SetEnvironmentVariable('Path', \"$p;$s;$m\", 'Machine') }"--scope machineを指定すると全ユーザー向けにインストールされ、管理者権限を要する。インストール完了後、コマンドプロンプトを再起動するとPATHが反映される。
方法2:インストーラーによるインストール
- Python公式サイト(https://www.python.org/downloads/)にアクセスし、Windows用インストーラーをダウンロードする。
- ダウンロードしたインストーラーを実行する。
- 初期画面下部の「Add python.exe to PATH」にチェックを入れてから「Customize installation」を選択する(チェックを入れないと、コマンドプロンプトから
pythonコマンドを実行できない)。 - 「Install Python 3.xx for all users」にチェックを入れ、「Install」をクリックする。
インストールの確認
コマンドプロンプトで以下を実行する。
python --versionバージョン番号(例:Python 3.12.x)が表示されれば成功である。「'python' は、内部コマンドまたは外部コマンドとして認識されていません。」と表示される場合は、インストールが正常に完了していない。
AIエディタWindsurfのインストール(Windows) [クリックして展開]
Pythonプログラムの編集・実行にはAIエディタを用いる。ここではWindsurfをインストールする。インストール済みの場合、この手順は不要である。
管理者権限のコマンドプロンプトで以下を実行する。管理者権限のコマンドプロンプトは、Windowsキーまたはスタートメニューから「cmd」と入力し、表示された「コマンドプロンプト」を右クリックして「管理者として実行」を選択して起動する。
winget install --scope machine --id Codeium.Windsurf -e --silent --disable-interactivity --force --accept-source-agreements --accept-package-agreements --custom "/SP- /SUPPRESSMSGBOXES /NORESTART /CLOSEAPPLICATIONS /DIR=""C:\Program Files\Windsurf"" /MERGETASKS=!runcode,addtopath,associatewithfiles,!desktopicon"
powershell -Command "$env:Path=[System.Environment]::GetEnvironmentVariable('Path','Machine')+';'+[System.Environment]::GetEnvironmentVariable('Path','User'); windsurf --install-extension MS-CEINTL.vscode-language-pack-ja --force; windsurf --install-extension ms-python.python --force; windsurf --install-extension Codeium.windsurfPyright --force"--scope machineを指定すると全ユーザー向けにインストールされ、管理者権限を要する。インストール完了後、コマンドプロンプトを再起動するとPATHが反映される。
Windsurf公式ページ:https://windsurf.com/
必要なPythonライブラリのインストール
- 管理者権限のコマンドプロンプトを起動する。Windowsキーまたはスタートメニューから「
cmd」と入力し、表示された「コマンドプロンプト」を右クリックして「管理者として実行」を選択する。 - 以下のコマンドで必要なライブラリをインストールする。
pip install -U pandas numpy matplotlib scipy statsmodels
Matplotlibの日本語表示設定(Windows)
グラフ内の日本語が文字化けしないよう、描画前に一度だけ以下を設定する。Windows標準の「Meiryo」を用いる(無い場合は「Yu Gothic」または「MS Gothic」を指定する)。
import matplotlib.pyplot as plt
plt.rcParams['font.family'] = 'Meiryo' # 'Yu Gothic' / 'MS Gothic' でも可
plt.rcParams['axes.unicode_minus'] = False # マイナス記号の文字化け防止演習
各演習は、対応するプログラム例のコードを実行し、結果を確認したうえで取り組む。コードは「Pythonプログラム例」の該当節を参照する。
演習1.記述統計量の算出
手順
- 「個別の統計量計算」のコードを実行する。
- 「得点」列の平均値、標準偏差、中央値、第1四分位数、第3四分位数、歪度、尖度を出力する。
- 標準偏差の
ddofを0に変えて再実行し、ddof=1の場合と値を比較する。
ヒント
- 標準偏差は
scores.std(ddof=1)、四分位数はscores.quantile(0.25)とscores.quantile(0.75)で算出する。 - 歪度と尖度は
stats.skew()とstats.kurtosis()で算出する。
考察ポイント
- 平均値と中央値の大小関係から、分布の偏りの向きを読み取る。
- 歪度の符号と、平均値・中央値の大小関係が一致するかを確認する。
ddof=0とddof=1で標準偏差がどちらが大きいかを確認する。
演習2.箱ひげ図とヒストグラムの作成
手順
- 「データの可視化(箱ひげ図とヒストグラム)」のコードを実行する。
- 科目別の箱ひげ図と、得点全体のヒストグラムを出力する。
- ヒストグラムの
binsをrange(0, 101, 5)に変えて再実行する。
ヒント
- 箱ひげ図は
df.boxplot(column='得点', by='科目')で作成する。 binsは区間の境界を表し、range(0, 101, 10)は0から100まで10点刻みを指定する。
考察ポイント
- 箱ひげ図の箱の位置と幅から、科目間の得点傾向の違いを読み取る。
binsの幅を10から5に変えると、分布の見え方がどう変わるかを確認する。
演習3.クロス集計表とカイ二乗独立性検定
手順
- 「クロス集計表とカイ二乗独立性検定」のコードを実行する。
- クロス集計表、合計付きの表、カイ二乗統計量、p値、自由度、Cramér's Vを出力する。
ヒント
- カイ二乗検定には合計を含まない集計表を渡す。
chi2_contingencyの戻り値はカイ二乗統計量、p値、自由度、期待度数の順である。
考察ポイント
- p値と有意水準(0.05)の比較から、2変数が独立かどうかを判断する。
- Cramér's Vの大きさから、関連の強さを読み取る。
演習4.相関分析
手順
- 「相関分析」のコードを実行する。
- Pearson相関行列、Pearson相関係数とp値、Spearman相関係数とp値を出力する。
ヒント
- 相関行列は
df.corr(method='pearson')で算出する。 - 個別の相関係数とp値は
stats.pearsonrとstats.spearmanrで算出し、いずれも相関係数、p値の順で返る。
考察ポイント
- PearsonとSpearmanの値の違いから、関係が線形か単調かを読み取る。
- p値と有意水準(0.05)の比較から、相関が有意かを判断する。
演習5.等分散性検定とt検定
手順
- 「等分散性の検定(Levene検定)とt検定」のコードを実行する。
- Levene検定の統計量とp値、Welchのt検定のt値、p値、自由度を出力する。
ヒント
- 乱数のシードを固定すると、実行のたびに同じ結果が得られる。
- t検定の戻り値
TtestResultはstatistic、pvalue、dfを持つ。
考察ポイント
- Levene検定のp値と有意水準(0.05)の比較から、等分散の仮定が妥当かを判断する。
- t検定のp値と有意水準(0.05)の比較から、2群の平均値に有意な差があるかを判断する。
演習6.分散分析と多重比較
手順
- 「一元配置分散分析と多重比較(Tukey HSD)」のコードを実行する。
- 分散分析のF値とp値、Tukey HSDの結果の表を出力する。
ヒント
- 多重比較には、全群の値を結合した配列(
endog)と、対応する群ラベル(groups)を渡す。
考察ポイント
- 分散分析のp値と有意水準(0.05)の比較から、群間に差があるかを判断する。
- Tukey HSDの表のp値と有意判定から、どの群間に有意な差があるかを読み取る。
演習7.正規性の検定
手順
- 「正規性の検定(Shapiro-Wilk検定)」のコードを実行する。
- 正規分布から生成したデータに対し、統計量Wとp値を出力する。
- サンプル数を
100から20に変えて再実行し、結果を比較する。
ヒント
- Shapiro-Wilk検定の戻り値は統計量Wとp値を持つ。
- サンプル数は
np.random.normal(0, 1, 100)の第3引数で指定する。
考察ポイント
- p値と有意水準(0.05)の比較から、正規性を否定する根拠があるかを判断する。
- サンプル数を100から20に減らすと、p値がどう変わるかを読み取る。