CIFAR10, CIFAR100, MNIST, Fashion MNIST データセットの主成分分析プロット(Python, tensorflow_datasets, scikit-learn, seaborn, matplotlib を使用)
1. サマリー
Keras に付属のデータセットに主成分分析(PCA)を適用し,第1主成分スコアと第2主成分スコアをプロットする.対象データセットは CIFAR10,CIFAR100,MNIST,Fashion MNIST の4種類である.tensorflow_datasets によるデータのロード,scikit-learn による主成分分析,seaborn および matplotlib による散布図の描画を行い,各主成分の寄与率および累積寄与率を出力する.
主成分分析は,多数の次元を持つデータを,情報の損失を抑えながら少数の次元へ変換する手法である(次元削減).本記事では画像1枚を数百〜数千次元のベクトルとして扱い,これを2次元へ削減する.2次元へ削減すると,各画像を平面上の1点として散布図に描画でき,データの分布構造やクラスごとのまとまりを視覚的に把握できる.
【関連する外部ページ】
Keras に付属のデータセットに関する Web ページ: https://keras.io/api/datasets/
Google Colaboratory のページ:
https://colab.research.google.com/drive/1Blm3l62DN_4dqUoltwhq-sdtsfr7ZaiU?usp=sharing
2. 前準備(必要ソフトウェアの入手)
本記事の主成分分析プロットを実行するために必要な事前準備を説明する.本記事の処理は CPU のみで動作するため,GPU 関連のソフトウェアは不要である.
Python 3.12 のインストール
Pythonのインストールを行い、Pythonのプログラムを実行する環境を整える。扱う環境は、Windows搭載パソコンである。金子研究室では、Python 3.12.10を推奨する。
[Windows での Python 3.12 のインストール手順を見るには、ここをクリック]
Windows での Python 3.12 のインストール
以下のいずれかの方法でPython 3.12をインストールする。Pythonがインストール済みの場合、この手順は不要である。
方法 1:winget によるインストール
【インストールコマンドの実行方法】
管理者権限でコマンドプロンプトを起動する(手順:Windowsキーまたはスタートメニュー → cmd と入力 → 右クリック → 「管理者として実行」)。そして、コマンド全体をコマンドプロンプトにコピー&ペーストする。
--scope machine を指定することで、システム全体(全ユーザー向け)にインストールされる。このオプションの実行には管理者権限が必要である。インストール完了後、コマンドプロンプトを再起動するとPATHが反映される。
REM Python 3.12 をシステム領域にインストール
winget install --id Python.Python.3.12 -e --scope machine --silent --accept-source-agreements --accept-package-agreements --override "/quiet InstallAllUsers=1 PrependPath=1 Include_test=0 Include_pip=1 Include_launcher=1 InstallLauncherAllUsers=1 TargetDir=\"C:\Program Files\Python312\""
REM Python と Scripts を PATH 先頭に追加
powershell -NoProfile -Command "$p='C:\Program Files\Python312'; $s=\"$p\Scripts\"; $c=[Environment]::GetEnvironmentVariable('Path','Machine'); if((Test-Path $p) -and (';'+$c+';' -notlike \"*;$p;*\") -and (';'+$c+';' -notlike \"*;$s;*\")){[Environment]::SetEnvironmentVariable('Path',\"$p;$s;$c\",'Machine')}"
方法 2:インストーラーによるインストール
- Python公式サイト(https://www.python.org/downloads/)にアクセスし、「Download Python 3.x.x」ボタンからWindows用インストーラーをダウンロードする。
- ダウンロードしたインストーラーを実行する。
- 初期画面の下部に表示される「Add python.exe to PATH」にチェックを入れてから「Customize installation」を選択する。このチェックを入れ忘れると、コマンドプロンプトから
pythonコマンドを実行できない。 - 「Install Python 3.xx for all users」にチェックを入れ、「Install」をクリックする。
インストールの確認
コマンドプロンプトで以下を実行する。
python --versionバージョン番号(例:Python 3.12.x)が表示されればインストール成功である。「'python' は、内部コマンドまたは外部コマンドとして認識されていません。」と表示される場合は、インストールが正常に完了していない。
Python の開発環境 Visual Studio Code のインストールと Python 用の設定
Python の開発環境Visual Studio Code(プログラムを編集するソフトウェア。以下、VS Code)を整える。
[Windows での Visual Studio Code のインストールと Python 用の設定手順を見るには、ここをクリック]
Windows での Visual Studio Code のインストールと Python 用の設定手順
1. VS Code と拡張機能のインストール
以下のコマンドにより,既存の VS Code を削除し,全ユーザー共有の設定で再インストールしたうえで,拡張機能(VS Code に機能を追加するソフトウェア)をまとめて導入する.
【インストールコマンドの実行方法】
管理者権限でコマンドプロンプトを起動する(手順:Windows キーまたはスタートメニュー → cmd と入力 → 右クリック → 「管理者として実行」)。そして,コマンド全体をコマンドプロンプトにコピー&ペーストする。
インストールコマンド
REM ============================================================
REM Microsoft Visual Studio Code
REM ============================================================
winget uninstall -e --id Microsoft.VisualStudioCode --silent --disable-interactivity --accept-source-agreements
rmdir /s /q C:\ProgramData\vscode-extensions 2>nul
rmdir /s /q "%APPDATA%\Code" 2>nul
rmdir /s /q "%USERPROFILE%\.vscode" 2>nul
rmdir /s /q "%LOCALAPPDATA%\Microsoft\vscode-update" 2>nul
REM VS Code をシステム領域に新規インストール
winget install --scope machine --id Microsoft.VisualStudioCode -e --silent --accept-source-agreements --accept-package-agreements
REM 全ユーザー共有の拡張機能フォルダ
mkdir C:\ProgramData\vscode-extensions 2>nul
icacls "C:\ProgramData\vscode-extensions" /grant "Everyone:(OI)(CI)M" /T
REM スタートメニューのショートカットを --extensions-dir 付きで再作成
rmdir /s /q "C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code" 2>nul
del "C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code.lnk" 2>nul
powershell -NoProfile -Command "$s=New-Object -ComObject WScript.Shell; $lnk=$s.CreateShortcut('C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code.lnk'); $lnk.TargetPath='C:\Program Files\Microsoft VS Code\Code.exe'; $lnk.Arguments='--extensions-dir \"C:\ProgramData\vscode-extensions\"'; $lnk.Save()"
REM ショートカットの検証
powershell -NoProfile -Command "$s=New-Object -ComObject WScript.Shell; $lnk=$s.CreateShortcut('C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio Code.lnk'); Write-Host 'TargetPath:' $lnk.TargetPath; Write-Host 'Arguments:' $lnk.Arguments"
REM ファイル / フォルダ右クリックの「Code で開く」を登録
reg add "HKLM\SOFTWARE\Classes\*\shell\VSCode\command" /ve /d "\"C:\Program Files\Microsoft VS Code\Code.exe\" --extensions-dir \"C:\ProgramData\vscode-extensions\" \"%1\"" /f
reg add "HKLM\SOFTWARE\Classes\Directory\shell\VSCode\command" /ve /d "\"C:\Program Files\Microsoft VS Code\Code.exe\" --extensions-dir \"C:\ProgramData\vscode-extensions\" \"%1\"" /f
reg add "HKLM\SOFTWARE\Classes\Directory\Background\shell\VSCode\command" /ve /d "\"C:\Program Files\Microsoft VS Code\Code.exe\" --extensions-dir \"C:\ProgramData\vscode-extensions\" \"%V\"" /f
REM --extensions-dir 付きで起動する code.cmd ラッパを作成
REM (%* を echo で書くと対話的 cmd で失われるため、PowerShell で [char]37+'*' を書き出す)
powershell -NoProfile -Command "$pct=[char]37; $q=[char]34; $c='@echo off'+[char]13+[char]10+$q+'C:\Program Files\Microsoft VS Code\bin\code.cmd'+$q+' --extensions-dir '+$q+'C:\ProgramData\vscode-extensions'+$q+' '+$pct+'*'+[char]13+[char]10; [IO.File]::WriteAllText('C:\ProgramData\vscode-extensions\vscode.cmd',$c,[Text.Encoding]::ASCII)"
REM 拡張機能のインストール
set "CODE=C:\Program Files\Microsoft VS Code\bin\code.cmd"
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --uninstall-extension GitHub.copilot
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --uninstall-extension GitHub.copilot-chat
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension ms-python.python
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension ms-python.vscode-pylance
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension ms-python.debugpy
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension MS-CEINTL.vscode-language-pack-ja
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension saoudrizwan.claude-dev
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension rust-lang.rust-analyzer
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension tamasfe.even-better-toml
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension anthropic.claude-code
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --install-extension almenon.arepl
"%CODE%" --extensions-dir "C:\ProgramData\vscode-extensions" --list-extensions --show-versions
echo === セットアップ完了 ===
2. Python インタプリタの選択
同一マシンに複数の Python がインストールされている場合,VS Code で使用する Python 本体(インタプリタ:Python プログラムを解釈・実行するソフトウェア)を選択する必要がある.
- コマンドパレット(コマンド名で機能を呼び出す VS Code の入力欄)を開く(
Ctrl+Shift+P) Python: Select Interpreterと入力する
- 表示される一覧から,使用する Python(例:
C:\Program Files\Python312\python.exe)を選択する.
Python プログラム実行手順
[Windows での Python プログラム実行手順を見るには、ここをクリック]
Windows での Python 実行手順(Visual Studio Codeを使用)
プログラムファイルの作成と保存
- 左サイドバーの「エクスプローラー」アイコン(
Ctrl+Shift+E)をクリックする
- 「NO FOLDER OPENED」(作業対象フォルダが未選択の状態)と表示される場合は,「Open Folder」をクリックし,プログラムを保存するフォルダを選択する
続いて「フォルダを信用するか」を確認する画面(フォルダ内のコードを実行してよいか確認する VS Code の仕組み)が表示されるので,チェックして Yes を選択する
- フォルダ名の右側に表示される「新しいファイル」アイコンをクリックする
- ファイル名(例:
aitask.py.ファイル名は何でも良い)を入力しEnterを押す.拡張子は.py(Python ファイルを示す拡張子)とする
- 実行したいコードを選択し,
Ctrl+Cでコピーする.VS Code のエディタ領域にCtrl+Vで貼り付ける Ctrl+Sで保存する
プログラムの実行
- エディタ右上の三角形「▷」アイコン(Run Python File:現在開いている Python ファイルを実行するボタン)をクリックする.または,エディタ上で右クリックし「ターミナルで Python ファイルを実行」を選択する
- VS Code 下部のターミナル(コマンドの入出力を表示する画面)に,実行結果(
print関数の出力等)が表示される
- tkinter(Python 標準の GUI ライブラリ)のファイル選択ダイアログを使うプログラムを実行した場合は,ダイアログが開くので対象画像を選択する
- VS Code 下部のターミナルで実行結果を確認する.OpenCV ウィンドウ(OpenCV が画像を表示するために開く専用ウィンドウ)が開いた場合はそちらも確認する.OpenCV ウィンドウは,マウスクリックでウィンドウをアクティブ(操作対象の状態)にしてからキーを押すと終了する


TensorFlow,tensorflow_datasets のインストール [クリックして展開]
管理者権限のコマンドプロンプトで以下を実行する。管理者権限のコマンドプロンプトを起動するには、Windows キーまたはスタートメニューから「cmd」と入力し、表示された「コマンドプロンプト」を右クリックして「管理者として実行」を選択する。1行目で既存の関連パッケージを削除し、2行目で TensorFlow と tensorflow_datasets をインストールする。
python -m pip uninstall -y tensorflow tensorflow-cpu tensorflow-gpu tensorflow-intel tensorflow-text tensorflow-estimator tf-models-official tf_slim tensorflow_datasets tensorflow-hub keras keras-tuner keras-visualizer
python -m pip install -U tensorflow tensorflow_datasets
numpy, pandas, seaborn, matplotlib, scikit-learn のインストール [クリックして展開]
管理者権限のコマンドプロンプトで以下を実行する。管理者権限のコマンドプロンプトを起動するには、Windows キーまたはスタートメニューから「cmd」と入力し、表示された「コマンドプロンプト」を右クリックして「管理者として実行」を選択する。
python -m pip install -U pip setuptools numpy pandas matplotlib seaborn scikit-learn scikit-learn-intelex
3. 実行のための準備とその確認手順(Windows 前提)
3.1 プログラムファイルの準備
本記事のコードは Jupyter Notebook(.ipynb)形式での実行を前提としている.以下のいずれかの方法で準備する.方法1はブラウザ上で実行するため Windows 固有の準備を必要とせず,方法2は前章でインストールしたローカル環境で実行する.
方法1:Google Colaboratory を使用する場合
第1章に掲載した Google Colaboratory のリンクからノートブックを開き,Google アカウントでログインする.
方法2:ローカル環境で Jupyter Notebook を使用する場合
第5章のソースコードを Jupyter Notebook 上で順番にセルへ入力する.または,テキストエディタ(Visual Studio Codeやメモ帳など)で pca_plot.py として保存し(文字コード:UTF-8),%matplotlib inline の行を削除したうえで Python スクリプトとして実行する.
3.2 実行コマンド
Google Colaboratory または Jupyter Notebook を使用する場合は,各セルを上から順に Shift+Enter で実行する.
Python スクリプトとして実行する場合は,コマンドプロンプトでファイルの保存先ディレクトリに移動し,以下を実行する.
python pca_plot.py3.3 動作確認チェックリスト
| 確認項目 | 期待される結果 |
|---|---|
| 前準備セル(インポートと関数定義)の実行 | エラーなく完了し,prin,pcaplot,load_dataset の各関数が定義される |
| CIFAR10 データセットのロード | メタデータ,x_train, x_test, y_train, y_test の型・形状・最大値・最小値が表示される |
| CIFAR10 の主成分分析プロット | フラット化後の形状が表示され,10クラスの色分け散布図と寄与率が出力される |
| CIFAR100 データセットのロード | メタデータ,x_train, x_test, y_train, y_test の型・形状・最大値・最小値が表示される |
| CIFAR100 の主成分分析プロット | フラット化後の形状が表示され,100クラスの色分け散布図と寄与率が出力される |
| MNIST データセットのロード | メタデータ,x_train, x_test, y_train, y_test の型・形状・最大値・最小値が表示される |
| MNIST の主成分分析プロット | フラット化後の形状が表示され,10クラスの色分け散布図と寄与率が出力される |
| Fashion MNIST データセットのロード | メタデータ,x_train, x_test, y_train, y_test の型・形状・最大値・最小値が表示される |
| Fashion MNIST の主成分分析プロット | フラット化後の形状が表示され,10クラスの色分け散布図と寄与率が出力される |
4. 概要・使い方・実行上の注意
データセットの概要
本記事で使用する4種類のデータセットは,いずれも Keras に付属のデータセットであり,tensorflow_datasets を通じてロードする.
- CIFAR10 データセット:10クラスのカラー画像(32×32×3)で構成される.訓練データ50,000枚,テストデータ10,000枚を含む.
- CIFAR100 データセット:100クラスのカラー画像(32×32×3)で構成される.訓練データ50,000枚,テストデータ10,000枚を含む.
- MNIST データセット:手書き数字(0〜9)のグレースケール画像(28×28×1)で構成される.訓練データ60,000枚,テストデータ10,000枚を含む.
- Fashion MNIST データセット:衣類等10カテゴリのグレースケール画像(28×28×1)で構成される.訓練データ60,000枚,テストデータ10,000枚を含む.
処理の流れ
各データセットに対して,以下の手順で主成分分析プロットを行う.
まず,tfds.load でデータセットをロードし,訓練データおよびテストデータの画像とラベルを取得する.画像データは numpy 配列に変換し,ピクセル値を 0〜255 から 0〜1 に正規化する.この変換と正規化は load_dataset 関数の内部で行う.load_dataset は x_train, y_train, x_test, y_test の順で4つの値を返す.
次に,多次元の画像配列を reshape でフラット化する.フラット化は load_dataset の外側で行う.CIFAR10 および CIFAR100 は 32×32×3 = 3,072 次元,MNIST および Fashion MNIST は 28×28×1 = 784 次元のベクトルとなる.
フラット化した訓練データとテストデータを結合し,scikit-learn の PCA で2成分に次元削減する.得られた第1主成分スコアと第2主成分スコアを用いて,seaborn の scatterplot でクラスラベルごとに色分けした散布図を描画する.あわせて,第1主成分および第2主成分の寄与率(explained variance ratio,各主成分が元データの分散を説明する割合)と累積寄与率を出力する.
実行上の注意
コード中の %matplotlib inline は Jupyter Notebook 用のマジックコマンド(セルの出力先などを制御する命令)であるため,Python スクリプトとして実行する場合は削除する.
tfds.load で batch_size = -1 を指定しているため,データセット全体が一度にメモリ上にロードされる.フラット化後の配列は,CIFAR10・CIFAR100 で約 0.7 GB,MNIST・Fashion MNIST で約 0.2 GB である.主成分分析の計算で内部的に同程度のコピーが生じるため,数 GB の空きメモリがあれば実行できる.
散布図の alpha 値(透過度)は 0.1 に設定している.データ点数が多いため,透過度を低く設定することで,点が重なった領域の密度を把握できる.
CIFAR10・CIFAR100 のような自然画像では,第1・第2主成分の累積寄与率は低い値にとどまる.これは元データの分散が多数の主成分に分散しているためであり,主成分分析の性質上想定される結果である.累積寄与率が低い場合,2次元の散布図は元データの一部の特徴のみを表していることを意味する.
5. ソースコード
主成分分析プロットの前準備
以下のコードで,主成分分析を行う prin,散布図を描画する pcaplot,データセットをロードする load_dataset の3つの関数を定義する.これらは第6章の各演習で共通して使用する.
import numpy as np
import pandas as pd
import seaborn as sns
import sklearn.decomposition
import matplotlib.pyplot as plt
sns.set()
%matplotlib inline
def prin(A, n):
"""主成分分析を行い,変換後の配列と寄与率を返す"""
pca = sklearn.decomposition.PCA(n_components=n)
transformed = pca.fit_transform(A)
return transformed, pca.explained_variance_ratio_
def pcaplot(A, b, alpha, title=""):
"""主成分分析で第1・第2主成分スコアを算出し,散布図をプロットする"""
M, ratio = prin(A, 2)
a12 = pd.DataFrame(M[:, 0:2], columns=['a1', 'a2'])
a12['target'] = b
sns.scatterplot(x='a1', y='a2', hue='target', data=a12, palette=sns.color_palette("hls", np.max(b) + 1), legend="full", alpha=alpha)
if title:
plt.title(title)
print(f"第1主成分の寄与率: {ratio[0]:.4f}, 第2主成分の寄与率: {ratio[1]:.4f}, 累積寄与率: {ratio[0]+ratio[1]:.4f}")
def load_dataset(name):
"""tensorflow_datasets からデータセットをロードし,numpy 配列として返す"""
import tensorflow_datasets as tfds
ds, metadata = tfds.load(name, with_info=True, shuffle_files=True, as_supervised=True, batch_size=-1)
x_train, y_train = ds['train'][0].numpy().astype("float32") / 255.0, ds['train'][1].numpy()
x_test, y_test = ds['test'][0].numpy().astype("float32") / 255.0, ds['test'][1].numpy()
print(metadata)
print(type(x_train), x_train.shape, np.max(x_train), np.min(x_train))
print(type(x_test), x_test.shape, np.max(x_test), np.min(x_test))
print(type(y_train), y_train.shape, np.max(y_train), np.min(y_train))
print(type(y_test), y_test.shape, np.max(y_test), np.min(y_test))
return x_train, y_train, x_test, y_test

6. 演習
各演習は,前章で定義した load_dataset,pcaplot を用いて,1つのデータセットに対する主成分分析プロットを行う.4つの演習は手順が共通であり,対象データセット名のみが異なる.以下に示す各図は,対応するコードを実行したときの出力結果である.
演習1.CIFAR10 データセットの主成分分析プロット
手順
- CIFAR10 データセットをロードする。
x_train, y_train, x_test, y_test = load_dataset('cifar10')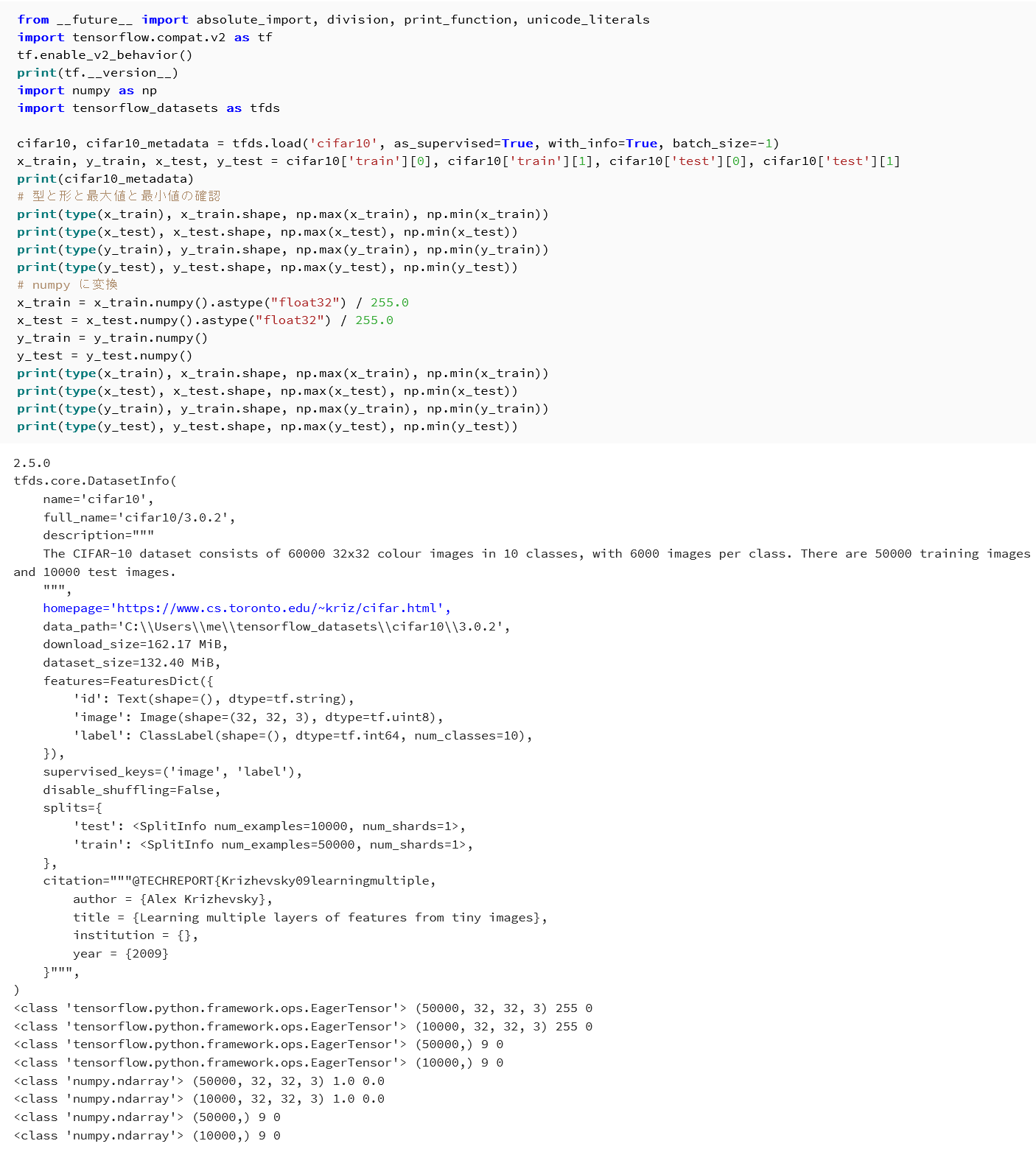
- 訓練データとテストデータをフラット化し,結合して主成分分析プロットを行う。
x_train_flat = x_train.reshape(x_train.shape[0], -1) x_test_flat = x_test.reshape(x_test.shape[0], -1) print(x_train_flat.shape) print(x_test_flat.shape) pcaplot(np.concatenate((x_train_flat, x_test_flat)), np.concatenate((y_train, y_test)), 0.1, "CIFAR10 PCA")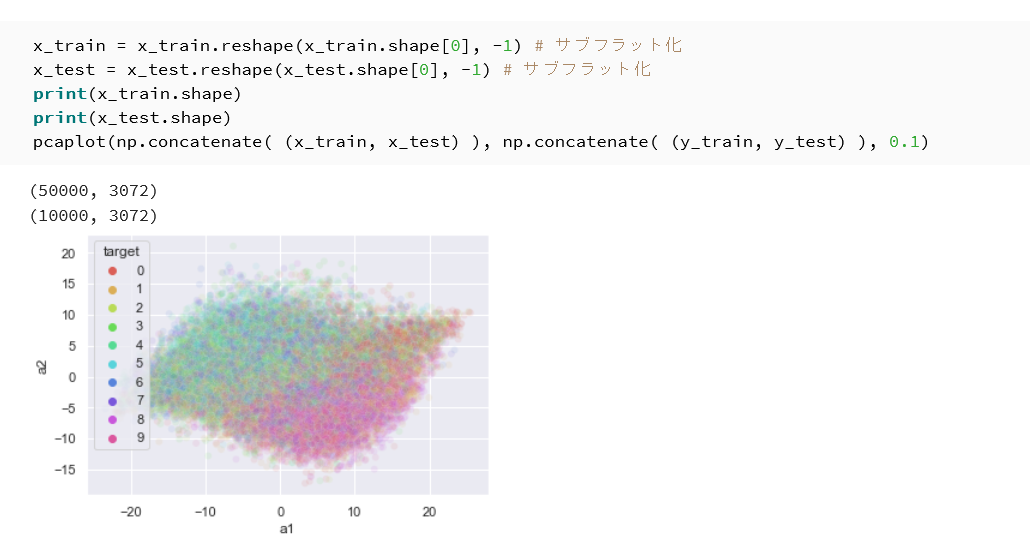
ヒント
-
reshapeの第2引数-1は,残りの次元数を自動的に計算する指定である。32×32×3 の画像は 3,072 次元のベクトルになる。 - CIFAR10 は10クラスであるため,散布図は10色で色分けされる。
考察ポイント
- 出力された第1・第2主成分の寄与率と累積寄与率を確認する。
- 散布図上で,10クラスが分離しているか,重なっているかを確認する。
演習2.CIFAR100 データセットの主成分分析プロット
手順
- CIFAR100 データセットをロードする。
x_train, y_train, x_test, y_test = load_dataset('cifar100')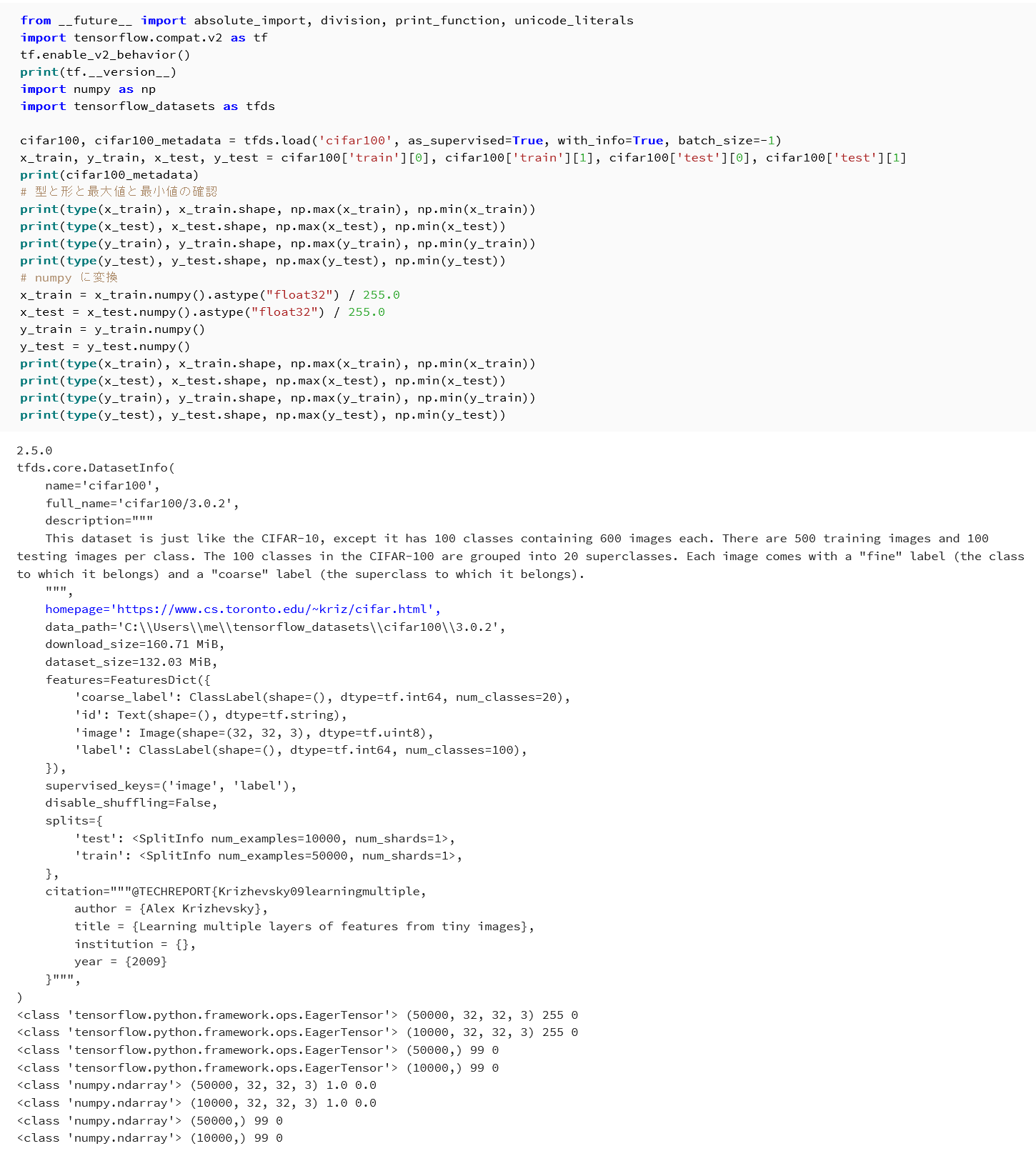
- 訓練データとテストデータをフラット化し,結合して主成分分析プロットを行う。
x_train_flat = x_train.reshape(x_train.shape[0], -1) x_test_flat = x_test.reshape(x_test.shape[0], -1) print(x_train_flat.shape) print(x_test_flat.shape) pcaplot(np.concatenate((x_train_flat, x_test_flat)), np.concatenate((y_train, y_test)), 0.1, "CIFAR100 PCA")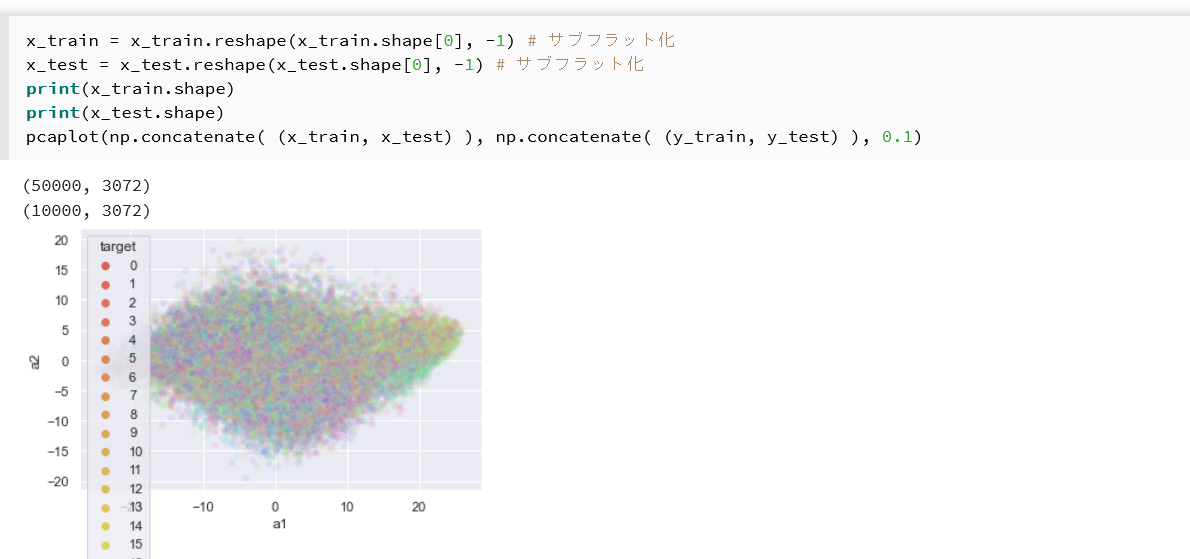
ヒント
- CIFAR100 は CIFAR10 と画像サイズが同じ(32×32×3)であるため,フラット化後の次元数も同じ 3,072 次元である。
- CIFAR100 は100クラスであるため,散布図は100色で色分けされる。
考察ポイント
- 演習1(CIFAR10)と比べ,クラス数が増えたときに散布図の見え方がどう変わるかを確認する。
- 累積寄与率が CIFAR10 とどの程度異なるかを確認する。
演習3.MNIST データセットの主成分分析プロット
手順
- MNIST データセットをロードする。
x_train, y_train, x_test, y_test = load_dataset('mnist')
- 訓練データとテストデータをフラット化し,結合して主成分分析プロットを行う。
x_train_flat = x_train.reshape(x_train.shape[0], -1) x_test_flat = x_test.reshape(x_test.shape[0], -1) print(x_train_flat.shape) print(x_test_flat.shape) pcaplot(np.concatenate((x_train_flat, x_test_flat)), np.concatenate((y_train, y_test)), 0.1, "MNIST PCA")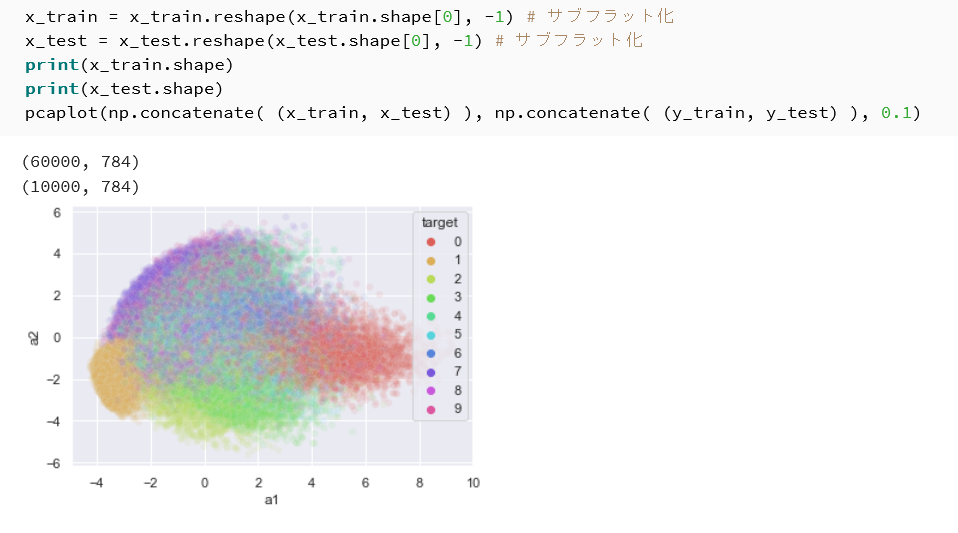
ヒント
- MNIST はグレースケール画像(28×28×1)であるため,フラット化後は 784 次元のベクトルである。
- MNIST は手書き数字0〜9の10クラスであるため,散布図は10色で色分けされる。
考察ポイント
- 累積寄与率が CIFAR10・CIFAR100 と比べて高いか低いかを確認する。
- 散布図上で,数字のクラスがどの程度分離しているかを確認する。
演習4.Fashion MNIST データセットの主成分分析プロット
手順
- Fashion MNIST データセットをロードする。
x_train, y_train, x_test, y_test = load_dataset('fashion_mnist')
- 訓練データとテストデータをフラット化し,結合して主成分分析プロットを行う。
x_train_flat = x_train.reshape(x_train.shape[0], -1) x_test_flat = x_test.reshape(x_test.shape[0], -1) print(x_train_flat.shape) print(x_test_flat.shape) pcaplot(np.concatenate((x_train_flat, x_test_flat)), np.concatenate((y_train, y_test)), 0.1, "Fashion MNIST PCA")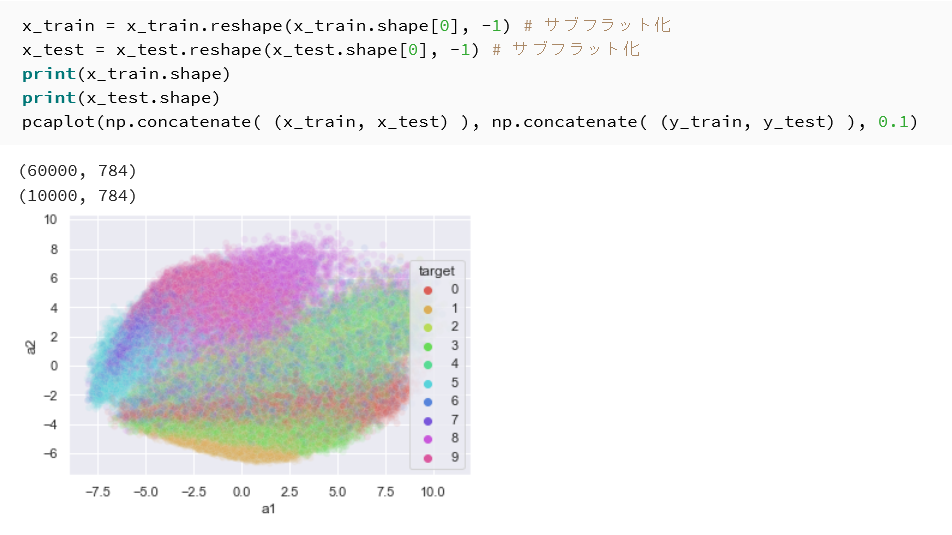
ヒント
- Fashion MNIST は MNIST と画像サイズが同じ(28×28×1)であるため,フラット化後の次元数も同じ 784 次元である。
- Fashion MNIST は衣類等10カテゴリの10クラスであるため,散布図は10色で色分けされる。
考察ポイント
- 演習3(MNIST)と比べ,同じ次元数・同じクラス数でクラスの分離の度合いがどう異なるかを確認する。
- 4つのデータセットの累積寄与率を並べ,画像の種類による違いを確認する。
7. まとめ
主成分分析(PCA)による次元削減
scikit-learn の PCA を用いて高次元の画像データを2次元に削減し,第1主成分スコアと第2主成分スコアで表現する.これにより,データの分布構造を2次元平面上で把握できる.
寄与率による主成分の評価
寄与率(explained variance ratio)は,各主成分が元データの分散を説明する割合を示す指標である.第1主成分および第2主成分の寄与率と累積寄与率を確認することで,2次元プロットが元データの特徴を保持する程度を定量的に評価できる.
画像データのフラット化
主成分分析を適用するために,多次元の画像配列を reshape でフラット化する.CIFAR10 および CIFAR100 は 3,072 次元,MNIST および Fashion MNIST は 784 次元のベクトルに変換する.
tensorflow_datasets によるデータセットのロード
tfds.load で CIFAR10,CIFAR100,MNIST,Fashion MNIST の各データセットをロードする.batch_size = -1 によりデータセット全体を一括取得し,numpy 配列に変換してピクセル値を 0〜1 に正規化する.
seaborn による散布図の描画
seaborn の scatterplot で,第1主成分と第2主成分のスコアをクラスラベルごとに色分けした散布図として描画する.alpha=0.1 の透過度設定により,点が重なった領域の密度を把握できる.