Python のまとめ
【概要】
このページは,Python の基礎から応用までの知識と手順をまとめている.Python の起動やインストール方法を Windows と Ubuntu の両方について説明し,複数バージョンの管理やパッケージ管理ツール pip の使い方も解説する.Python の隔離環境 venv や Anaconda3 といった環境設定も記載する.Python プログラムの例として,グラフ描画,画像ファイルの操作,主成分分析,k-means クラスタリングなどを紹介する.Python 開発環境として,Jupyter Notebook,Jupyter Lab,Nteract,Spyder のインストール方法と起動方法を解説する.Python のプログラミング基礎,データ型,モジュールとライブラリ,クラス定義とオブジェクト生成,制御構造,関数定義についても扱う.Python でできること,Python での書き方をすばやく確認できるページである.
【目次】
- 第1章 開発環境のセットアップ
- 第2章 Python 関係のツール
- 第3章 Python 開発環境,Python コンソール
- 第4章 Python の基礎
- 第5章 オブジェクト指向プログラミング
- 第6章 データ構造と配列処理
- 第7章 データの可視化
- 第8章 機械学習フレームワーク
- 第9章 ファイルの選択
- 第10章 画像ファイルの表示,画像ファイルの画像のサイズの取得
- 第11章 ply ファイルの表示
【関連する外部ページ】
- 東京大学の「Pythonプログラミング入門」: https://utokyo-ipp.github.io/IPP_textbook.pdf
- ITmedia 社の「Python チートシート」の記事: https://atmarkit.itmedia.co.jp/ait/articles/2004/20/news015.html
- Python の公式サイト: https://www.python.org
【サイト内の関連情報】
- Windows AI支援Python開発環境構築ガイド: 別ページ »で説明
- AIエディタ Windsurf の活用: 別ページ »で説明
- AIエディタ Cursor ガイド: 別ページ »で説明
- Google Colaboratory: 別ページ »で説明
- Python とプログラミングの基本
別ページ »にまとめ
Google Colaboratory, Paiza.IO を使用
- Python 演習(コードコンバット (Code Combat) を使用) [PDF], [パワーポイント]
- Python 入門(全6回)
Python 入門(全14回,Python Tutor と CodeCombat を使用): 別ページ »で説明
Google Colaboratory を使用.
- Python プログラミング演習(全9回)
別ページ »で説明
Python Tutor, VisuAlgo を使用.
- Windows での Python 処理系と開発環境のインストール
別ページ »で説明
- 機械学習の Python 実現ガイド: 別ページ »で説明
- 行列計算の Python 実現ガイド: 別ページ »で説明
- 統計分析の Python での実現ガイド: 別ページ »で説明
- 音声信号処理の Python 実現ガイド: 別ページ »で説明
- カラー画像処理の Python 実現ガイド: 別ページ »で説明
- Pythonプログラミング講座:基礎から応用まで(授業資料,全15回): 別ページ »で説明
- Pythonプログラミングの例と実践ガイド: 別ページ »で説明
- その他,Python について: 別ページ »にまとめている.
第1章 開発環境のセットアップ
Google Colaboratory でノートブックを開く
Google Colaboratory はオンラインの Python 開発環境である. 使用には Google アカウントが必要である.
Google Colaboratory では,Web ブラウザを用いて次のことができる.
- ノートブックの形式で,Pythonソースコードの編集や実行,実行結果の保存ができる.
- 説明文の編集ができる.説明文には,リンク,添付ファイル,図を含めることができる.
- 「!pip」,「%cd /content」などの,システム操作ができる.
- 共有機能により,第三者がノートブックをダウンロードし,実行できる.編集もできる.
- Google Colaboratory のWebページを開く
https://colab.research.google.com
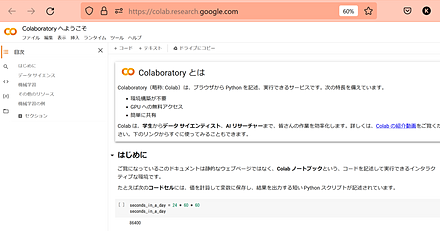
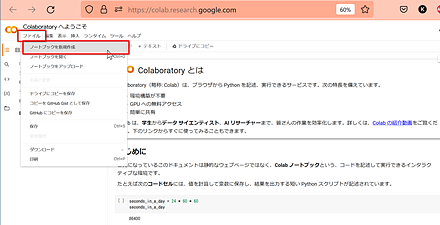
- 「ファイル」で、「ノートブックを新規作成」を選ぶ
- Google アカウントでのログインが求められたときはログインする

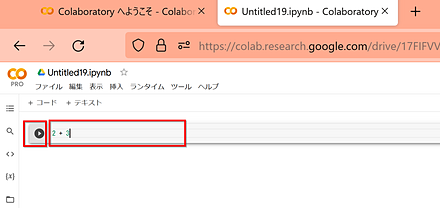
- コードセルの中に Python プログラムを書き、「再生ボタン」をクリック
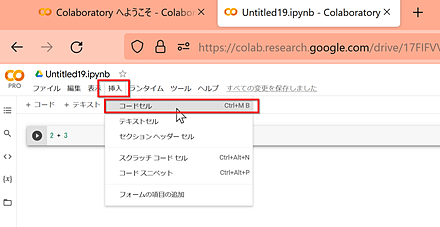
- コードセルを追加したいときは、「挿入」で、「コードセル」をクリック
スライド資料
「Colaboratoryへようこそ」のページのURL: https://colab.research.google.com/notebooks/welcome.ipynb?hl=ja
Google Colaboratory での pip の操作
Google Colaboratoryではpipを次のように操作する.頭に「!」を付ける.
- パッケージのインストール
!pip3 install <パッケージ名>パッケージのバージョン指定を行うときは,「numpy==1.26.4」のようにパッケージ名の後に付ける. - インストール済みパッケージの一覧
!pip3 list - アンインストール
!pip3 uninstall <パッケージ名> - パッケージの情報
!pip3 show <パッケージ名>
Windows での Python の起動
Python のコマンドでの実行
コマンドプロンプトで以下のコマンドを実行する.
python
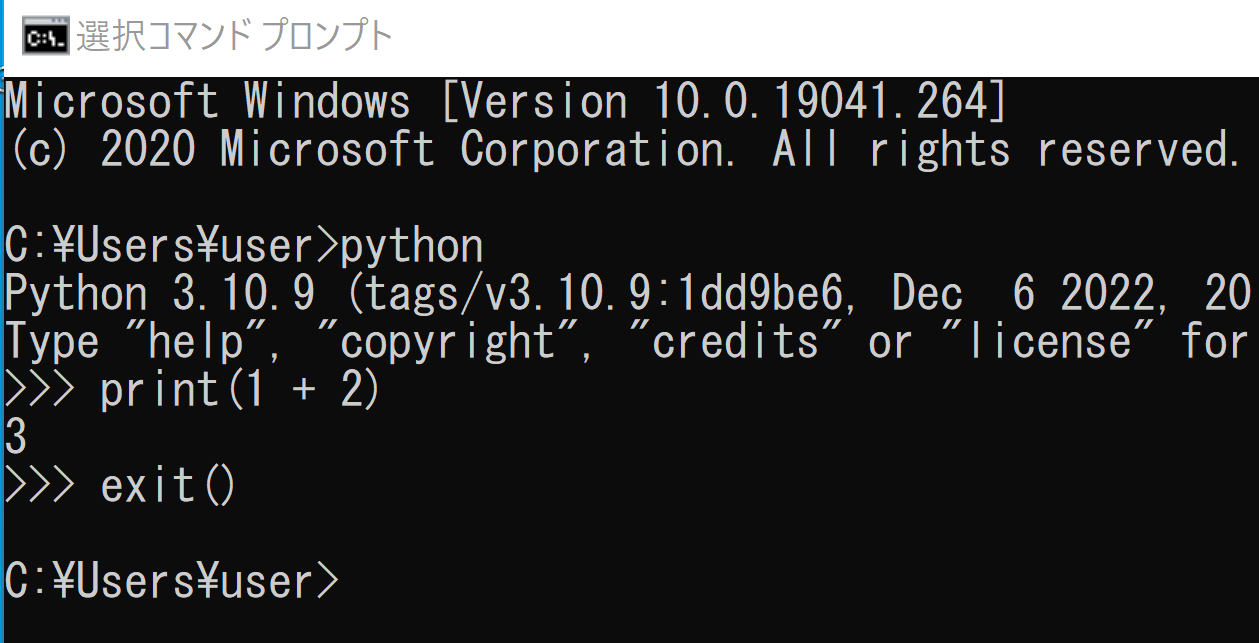
Windowsで複数のPythonをインストールしているときは,環境変数Pathで先頭のPythonが使用される.
Python ランチャー py でのバージョン指定実行
Pythonランチャーを使用すると,バージョンを指定してPythonを実行できる.
py -<Pythonのバージョン>
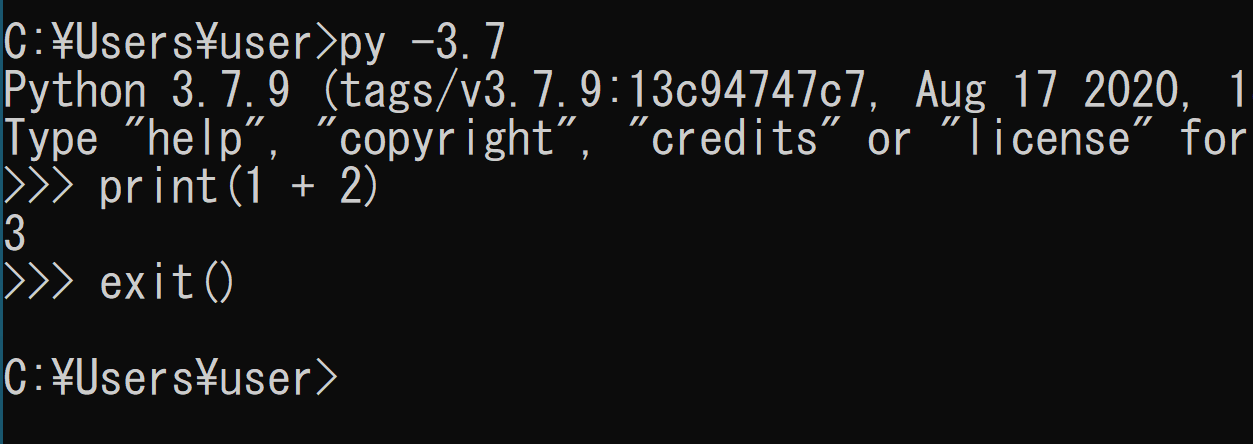
インストールされているPythonのバージョンは「py -0」で確認できる.
venv を使用する場合
venvを使うときは,activateコマンドを実行した後,「python」で起動する.
Windows での Python のインストール
Python 3.12 のインストール(Windows 上)
以下のいずれかの方法で Python 3.12 をインストールする.Python がインストール済みの場合,この手順は不要である.
方法1:winget によるインストール
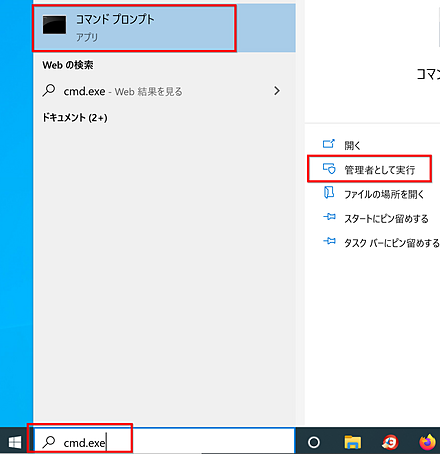
管理者権限でコマンドプロンプトを起動する
(手順:Windowsキーまたはスタートメニュー → cmd と入力 → 右クリック → 「管理者として実行」).次のコマンドを実行する.
winget install --id Python.Python.3.12 -e --scope machine --silent --accept-source-agreements --accept-package-agreements --override "/quiet InstallAllUsers=1 PrependPath=1 Include_test=0 Include_pip=1 Include_launcher=1 InstallLauncherAllUsers=1 TargetDir=\"C:\Program Files\Python312\""
powershell -Command "$p='C:\Program Files\Python312'; $s=\"$p\Scripts\"; $m=[Environment]::GetEnvironmentVariable('Path','Machine'); if($m -notlike \"*$s*\") { [Environment]::SetEnvironmentVariable('Path', \"$p;$s;$m\", 'Machine') }"--scope machine を指定すると,システム全体(全ユーザー向け)にインストールされる.このオプションの実行には管理者権限が必要である.インストール完了後,コマンドプロンプトを再起動すると PATH が反映される.
方法2:インストーラーによるインストール
- Python 公式サイト(https://www.python.org/downloads/)にアクセスし,「Download Python 3.x.x」ボタンから Windows 用インストーラーをダウンロードする.
- ダウンロードしたインストーラーを実行する.
- 初期画面の下部に表示される「Add python.exe to PATH」にチェックを入れてから「Customize installation」を選択する.このチェックを入れ忘れると,コマンドプロンプトから
pythonコマンドを実行できない. - 「Install Python 3.xx for all users」にチェックを入れ,「Install」をクリックする.
インストールの確認
python --versionバージョン番号(例:Python 3.12.x)が表示されればインストール成功である.
Python 3.9 / 3.10 のインストール(従来のインストーラー手順)
- Python 64-bit 版を使用すること.
- Python をシステム領域にインストールすることを推奨する.ユーザー名に日本語が含まれている場合,ユーザ領域へのインストールでは問題が発生する可能性がある.
- TensorFlow 2.10.1 の利用
TensorFlow 2.10.1 は次の Python のバージョンと互換性がある: Python 3.10, Python 3.9, Python 3.8, Python 3.7
この互換性情報は,https://pypi.org/project/tensorflow/2.10/#files で確認できる.
TensorFlow 2.10 は,native-Windows で GPU をサポートする最後のバージョンである(GPU を利用しない CPU 動作は,より新しいバージョンでも可能).
- Windows では,Python の 3.7.x,3.8.x,3.9.x,3.10.x のように,複数のバージョンの Python を同時にインストールできる.
Python 3.9 のインストール(Windows 上)のページ: https://www.kkaneko.jp/tools/win/python.html
YouTube 動画: https://www.youtube.com/watch?v=2MlVmx-yLM8
- TensorFlow のインストール予定がある場合には,次のページで,必要な Python のバージョンを確認する
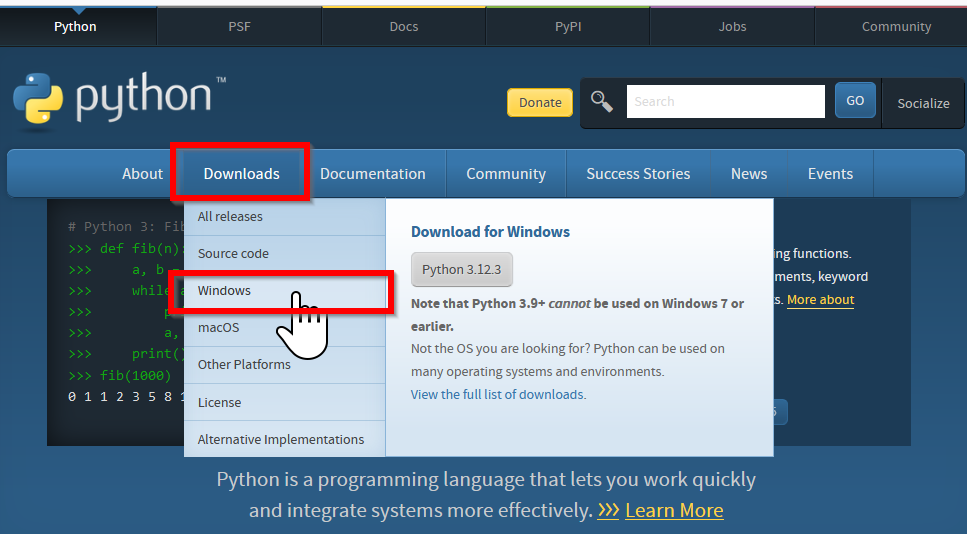
- Python の URL を開く
- Windows 版の Python 3.10 をダウンロード
ページの上の方にある「Downloads」をクリック.「Windows」をクリック
- 「Stable Releases」から,Python のバージョンを選ぶ
ここでは,Python 3.10 系列の最新版を選ぶ.
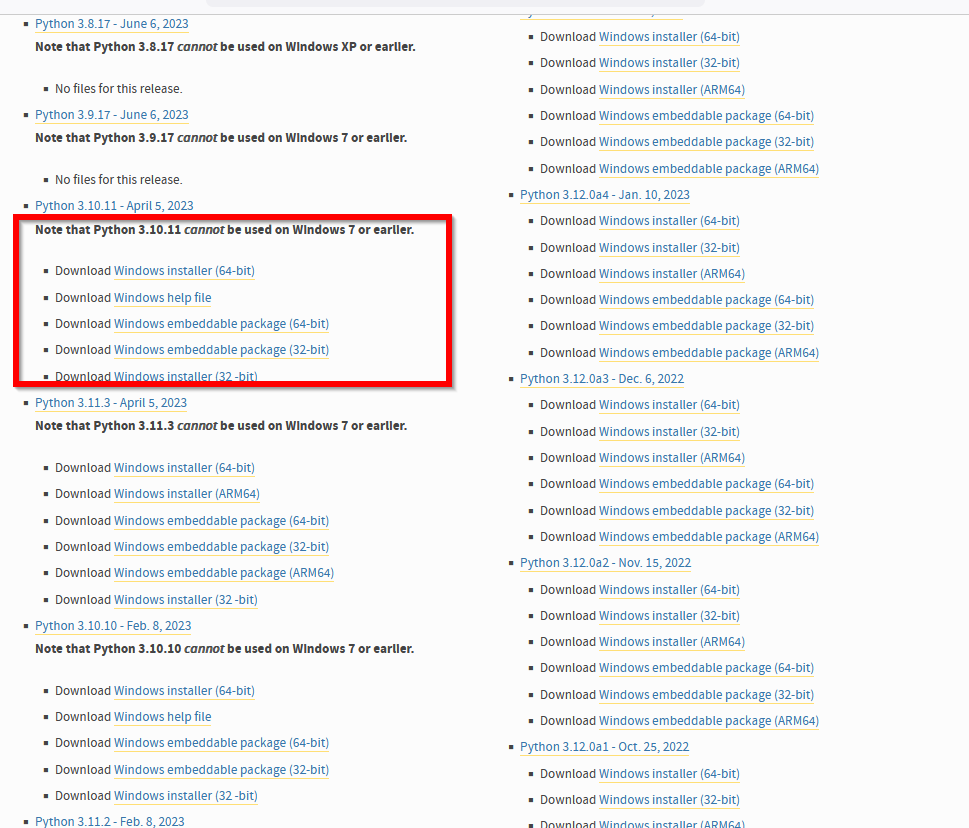
- ファイルの種類を選ぶ.「Windows Installer (64-bit)」を選ぶ
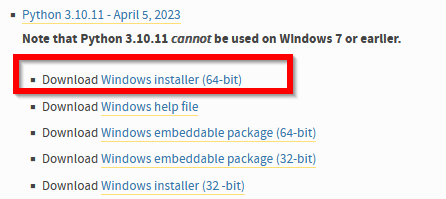
- ダウンロードが始まる

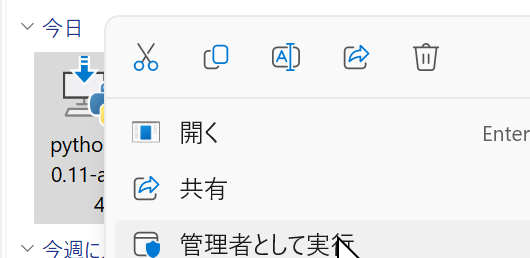
- インストール時の設定
- いまダウンロードした .exe ファイルを右クリック,「管理者として実行」を選ぶ.
- Python ランチャーをインストールするために,「Install launcher for all users (recommended)」をチェック.
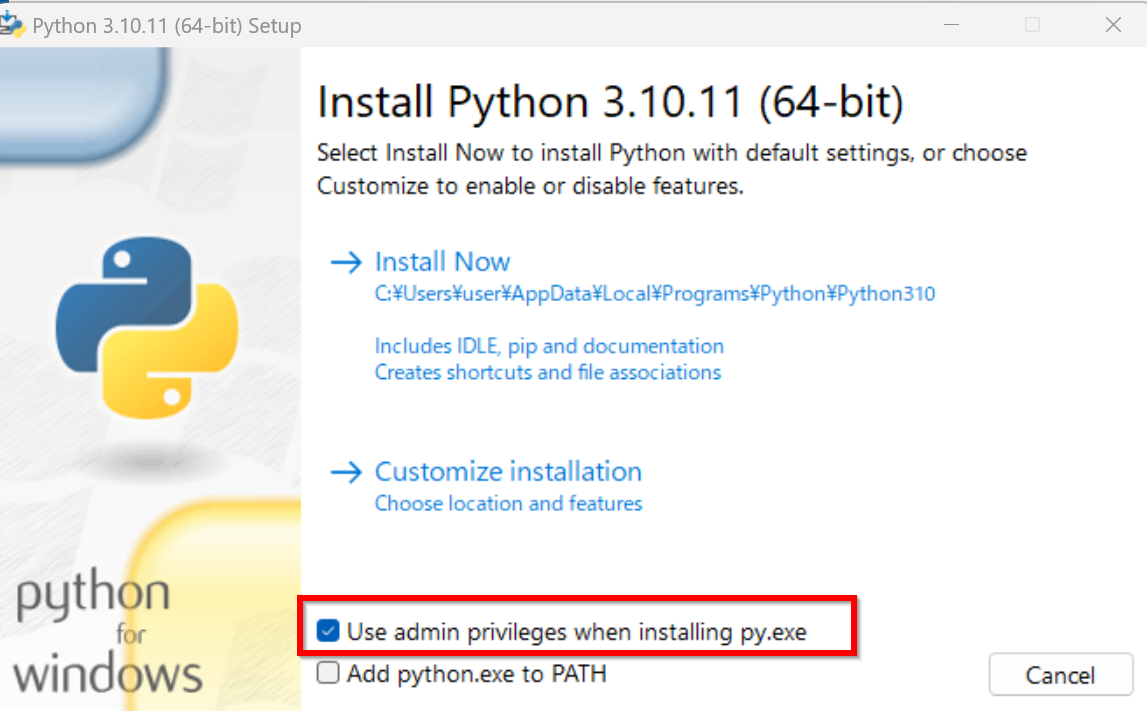 * すでに Python ランチャーをインストール済みのときは,「Install launcher for all users (recommended)」がチェックできないようになっている場合がある.そのときは,チェックせずに進む.
* すでに Python ランチャーをインストール済みのときは,「Install launcher for all users (recommended)」がチェックできないようになっている場合がある.そのときは,チェックせずに進む.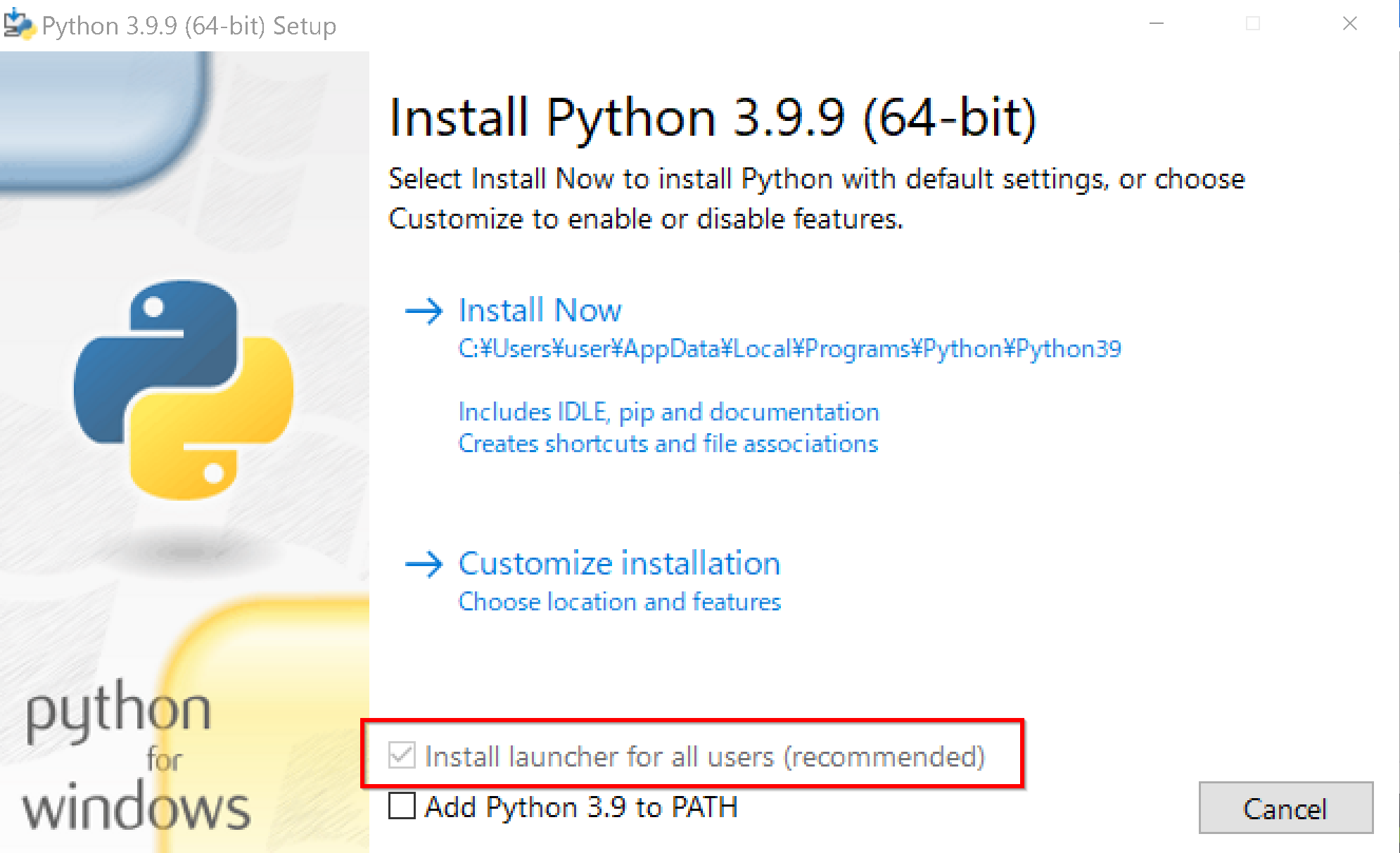
- 「Add Python.exe to PATH」をチェック.
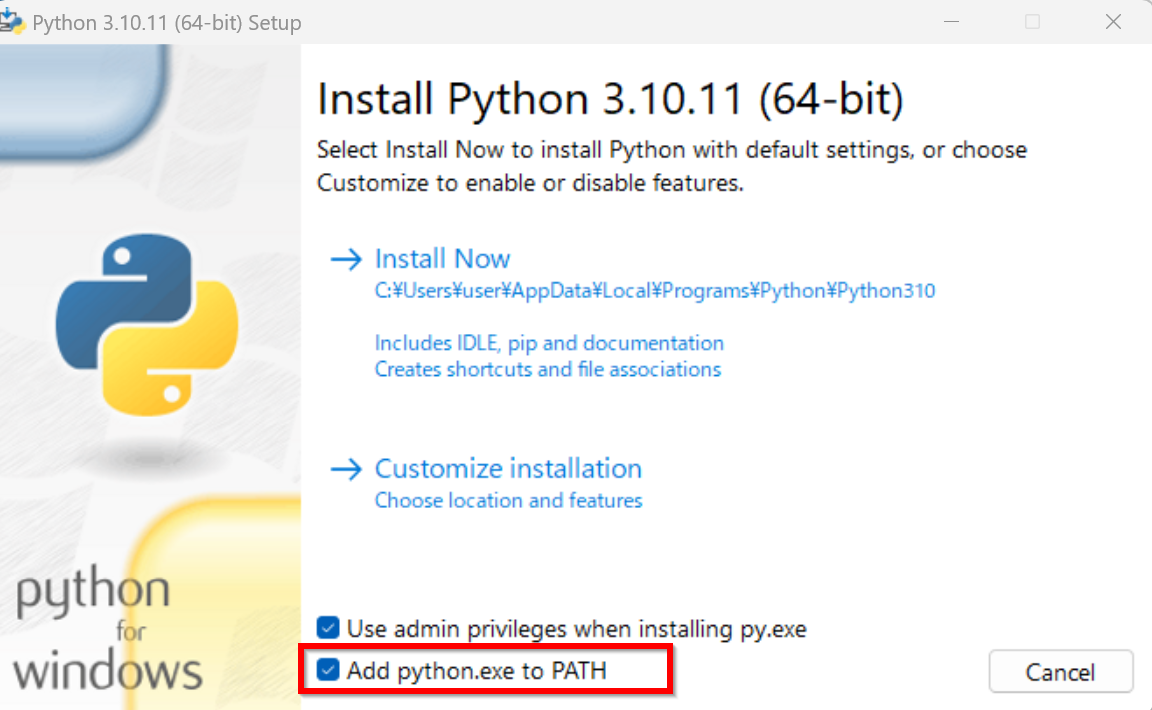
- 「Customize installation」をクリック.
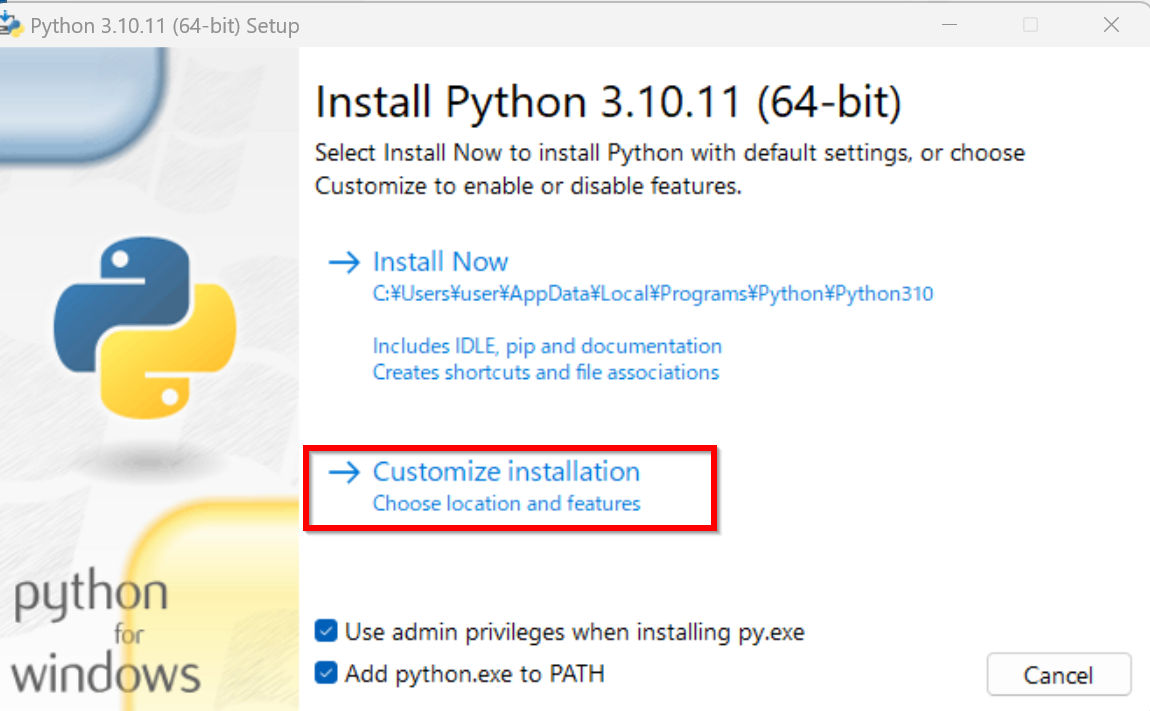
- オプションの機能 (Optional Features) は,既定(デフォルト)のままでよい.「Next」をクリック
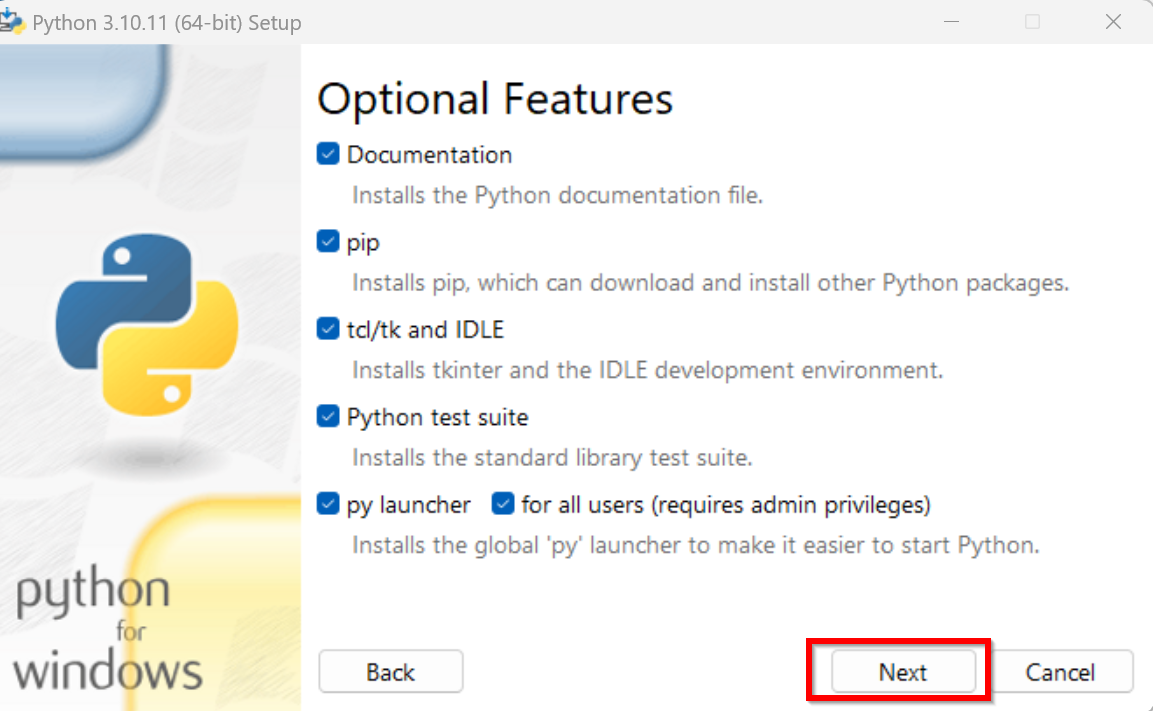
- 「Install Python 3.10 for all users」を選ぶ.
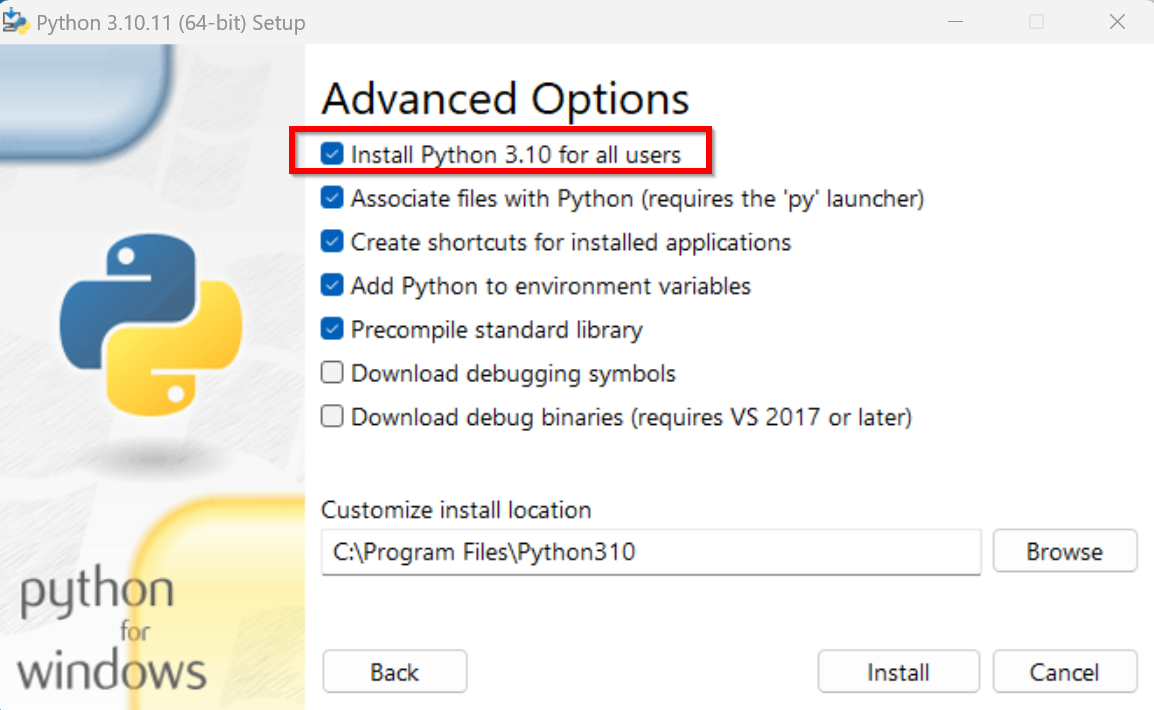
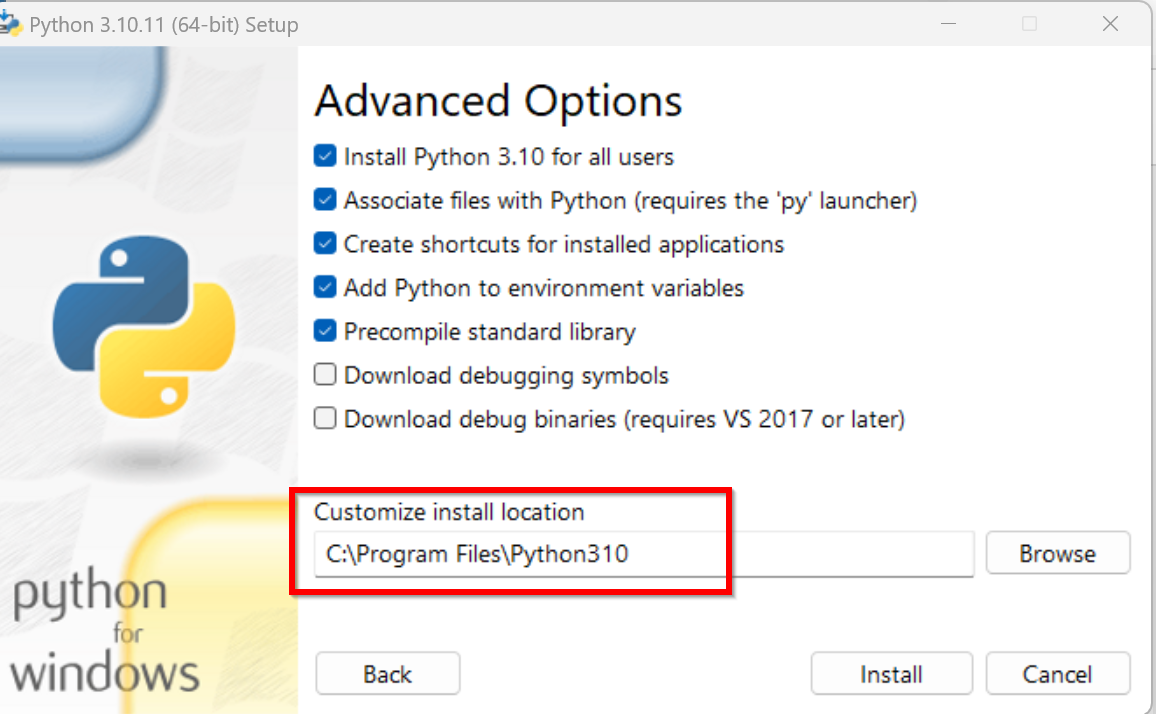
- Python のインストールディレクトリが,「C:\Program Files\Python310」のように自動設定されることを確認.
- 「Install」をクリック
- インストールが始まる
- 「Disable path length limit」が表示される場合がある.クリックして,パス長の制限を解除する.
- インストールが終了したら,「Close」をクリック
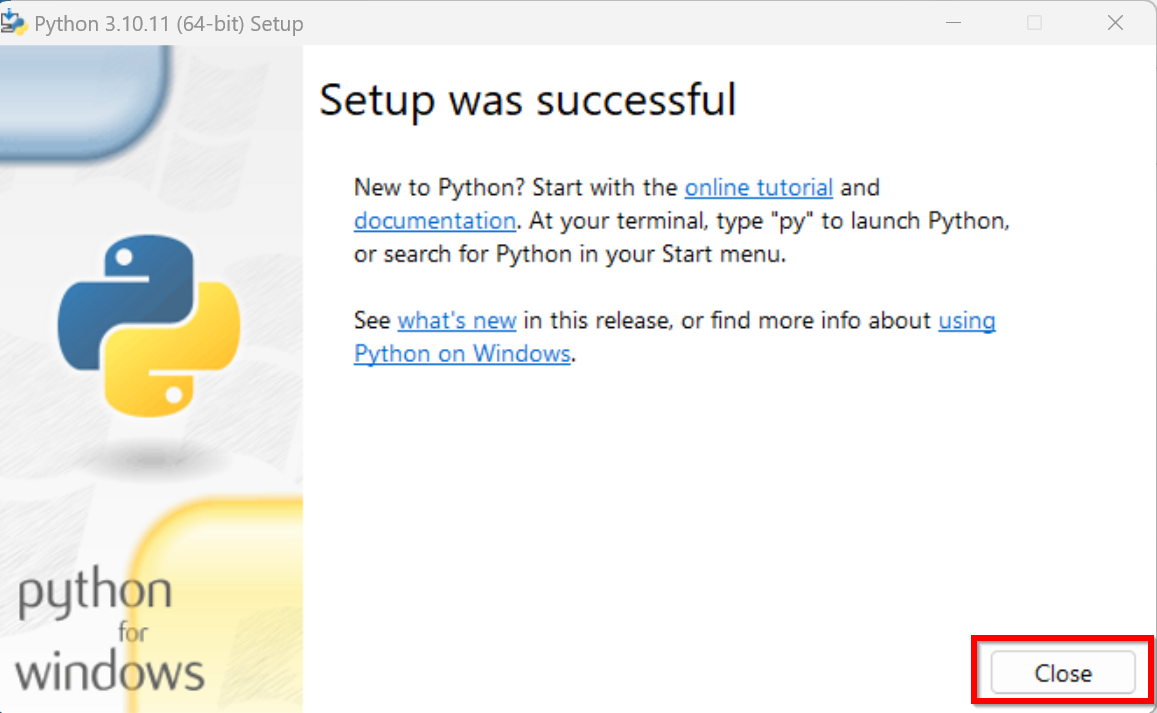
- いまダウンロードした .exe ファイルを右クリック,「管理者として実行」を選ぶ.
- インストールのあと,Windows のスタートメニューに「Python 3.10」が増えていることを確認.
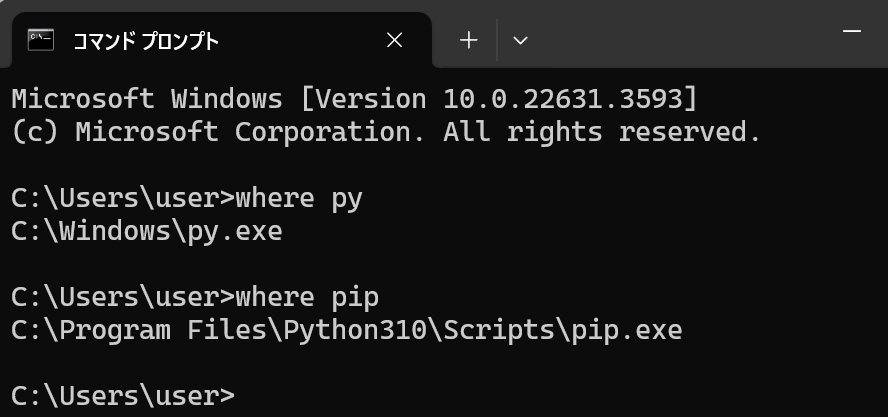
- システムの環境変数 Path の確認のため,新しくコマンドプロンプトを開き,次のコマンドを実行する.
where py where pipwhere py では「C:\Windows\py.exe」が表示され, where pip では「C:\Program Files\Python310\Scripts\pip.exe」が表示されることを確認.
pip と setuptools の更新
- 以下の手順を管理者権限のコマンドプロンプトで実行する
(手順:Windowsキーまたはスタートメニュー →
cmdと入力 → 右クリック → 「管理者として実行」). - 次のコマンドを実行する.
python -m pip install -U --no-user pip setuptools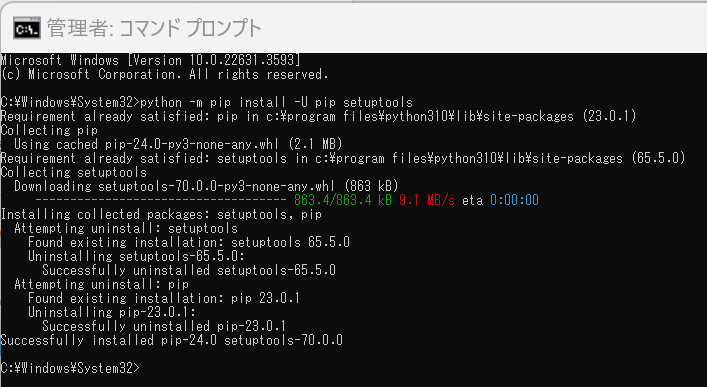
Python に関しての情報取得
- Windows のシステム環境変数 Path を確認する
インストール時に「Add Python ... to PATH」をチェックしたので,Python についての設定が自動で行われる.
- Python にパスが通っていることの確認
where python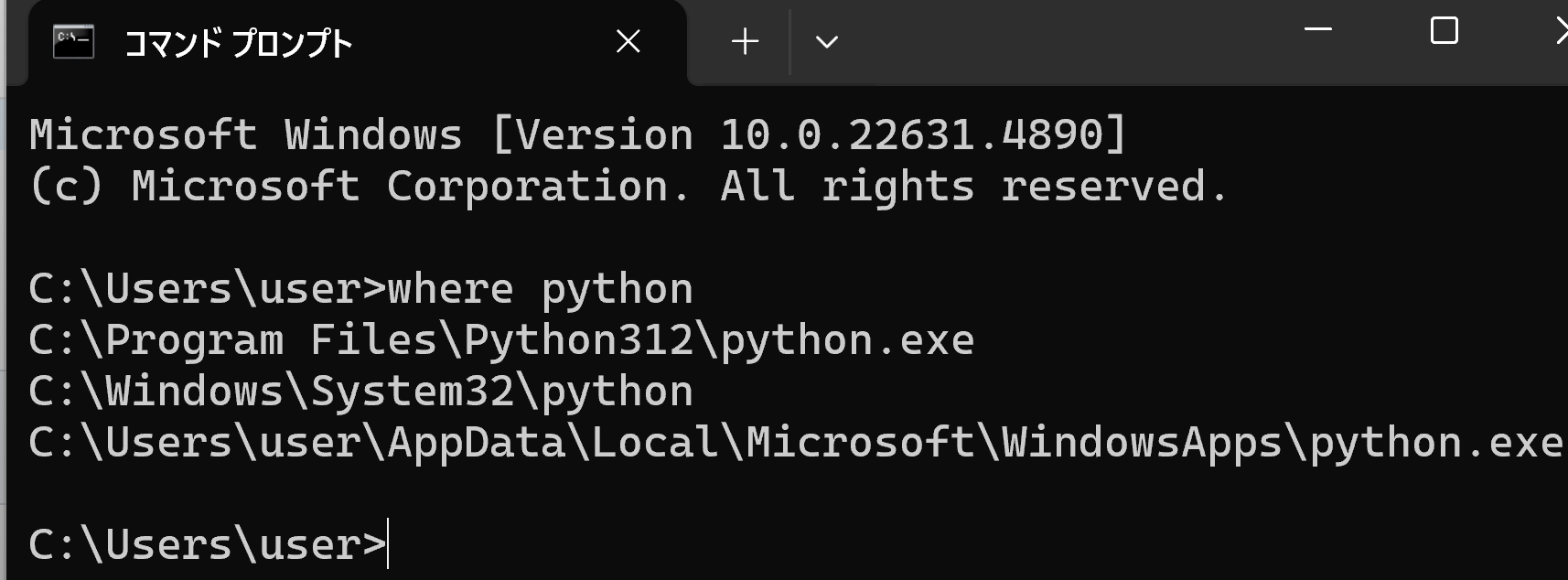
- python のバージョンの確認
python --version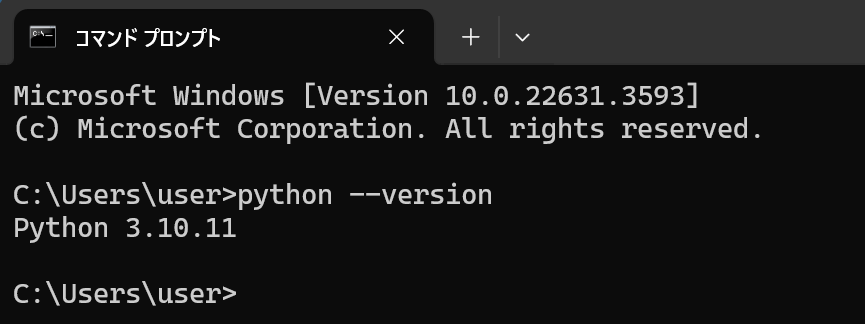
- Python のビルドに用いられたコンパイラのバージョン番号の確認
python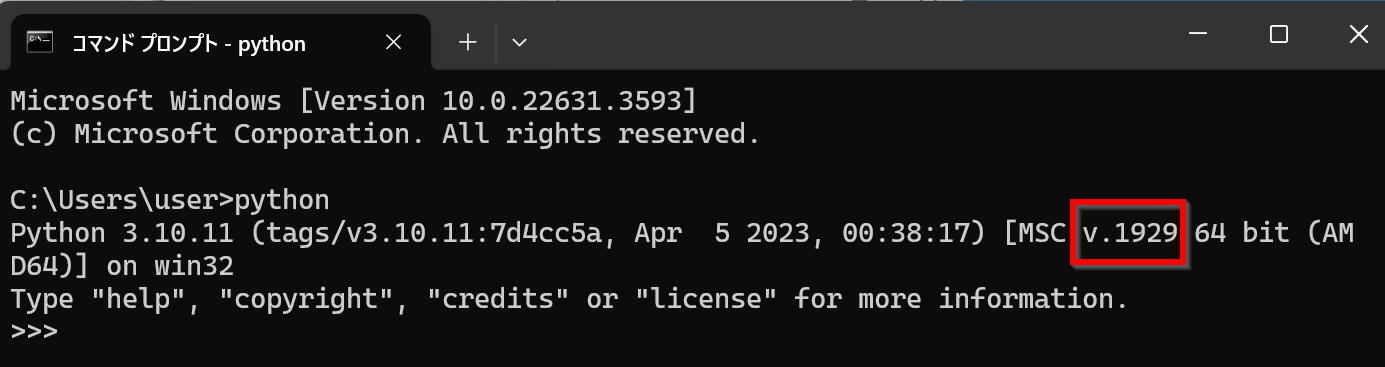
- exit() で終了
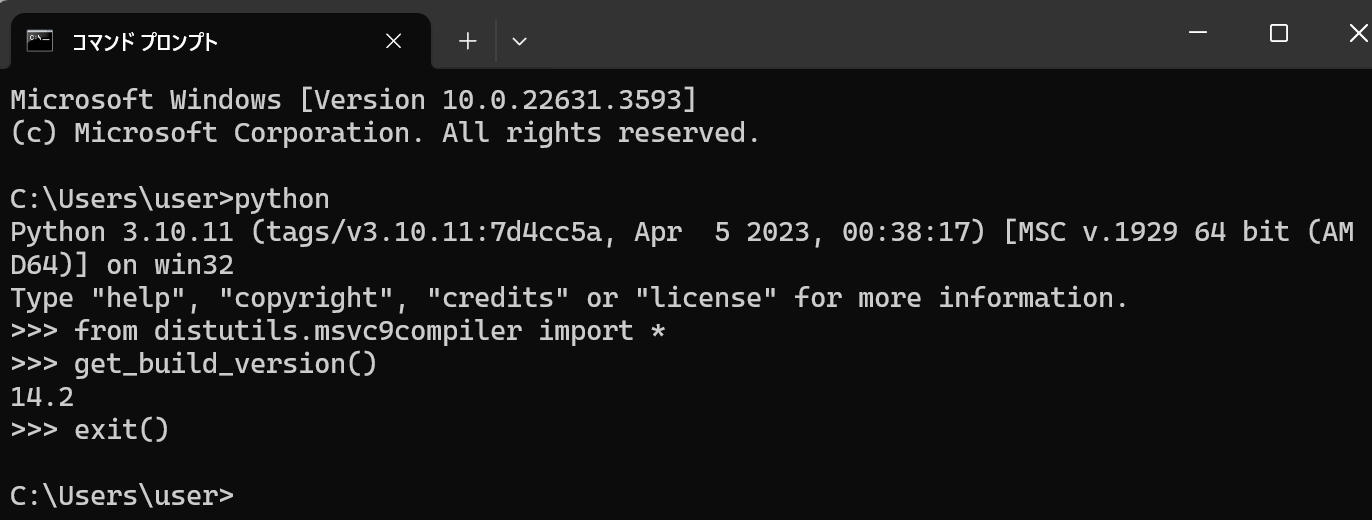
- pip の動作確認
pip list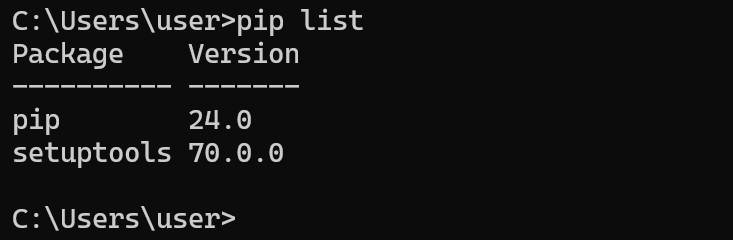
Windows で Python のアンインストール
- まず,Windows で Python のアンインストール操作を行う.
- 次に,Python 関係のファイルの削除を行う.
Windowsでは,コマンドプロンプトを管理者として実行し,次のコマンドを実行する.
この操作は,必ずPythonをすべてアンインストールした後に行うこと.
 次のコマンドは,rmdir で %APPDATA%\Python ディレクトリを再帰的に削除し,次に "C:\Program Files" に移動して Python3 で始まるディレクトリを再帰的に削除する.
次のコマンドは,rmdir で %APPDATA%\Python ディレクトリを再帰的に削除し,次に "C:\Program Files" に移動して Python3 で始まるディレクトリを再帰的に削除する.rmdir /s /q %APPDATA%\Python cd "C:\Program Files" for /F %i in ('dir /ad /b /w Python3*') do rmdir /s /q %i
Windows での複数の Python の同時インストール
Windowsでは,Python の 3.7.x,3.8.x,3.9.x,3.10.x のように,複数のバージョンの Python を同時にインストールできる.
ただし,3.10.4 と 3.10.5 のように,3桁目だけが異なるものは同時にインストールできない(2桁目までが異なるものは同時にインストールできる).
そのときは,環境変数 Path の設定を意識すること.Pythonランチャーである「py」コマンドも利用すること.
Windows の Python ランチャー py
Pythonランチャーは,Windows で動くツールである.複数バージョンの Python を同時にインストールしたときに便利である.
Pythonの起動
Windows のPythonランチャーを用いて,次のように使用する Python のバージョンを指定できる:
- py -3.12
- py -3.10
- py -3.9
- py -3.8
- py -3.7
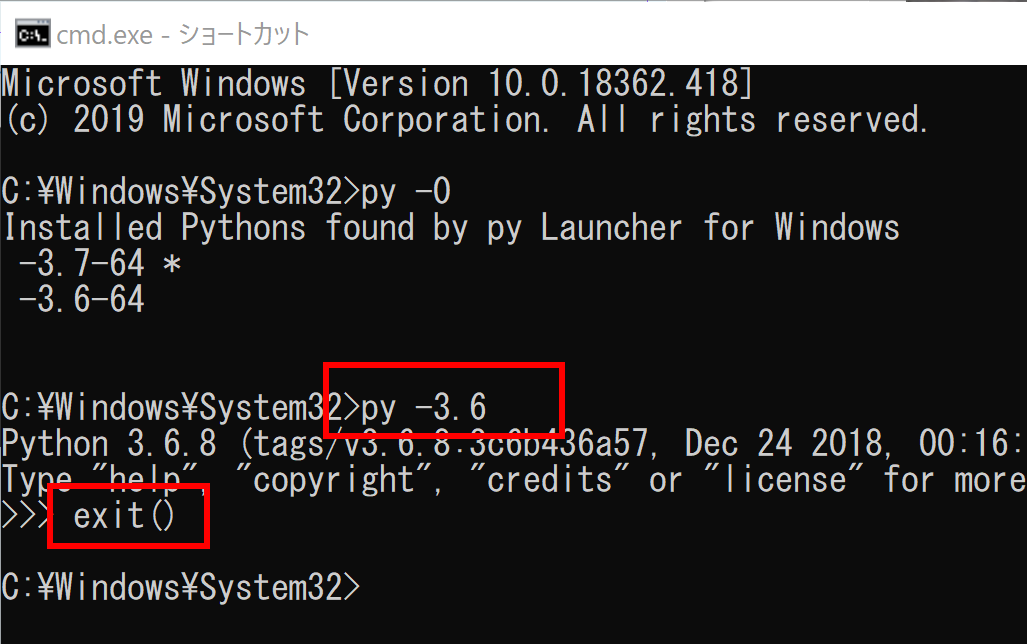
「py」のようにバージョン指定を省略したときは,インストールされている Python の最新バージョンが実行される.
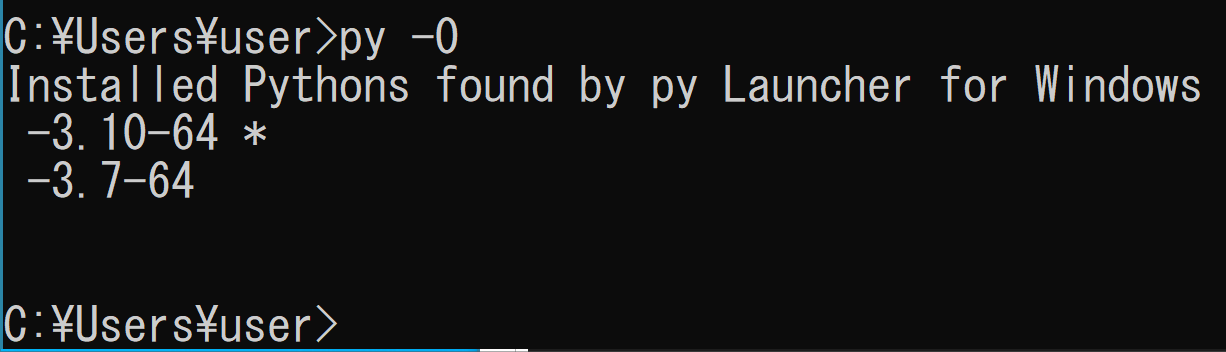
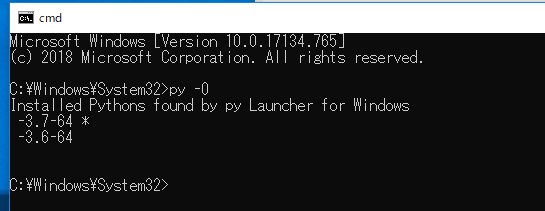
インストールされている Python バージョンの一覧表示
py -0
Ubuntu の Python,Ubuntu での Python のインストール,pip と setuptools の更新
Ubuntu の システム Python
Ubuntu をインストールすると,Ubuntu のシステム Python も同時にインストールされる.Ubuntu の場合はシステム Python を用いる(その場合はインストール不要)か,pyenv などを用いて,システム Python とは隔離した形でインストールする.
Ubuntu のシステム Python を用いるとき,python,pip は,次のコマンドで起動できる:
- python3(Ubuntu のシステム Python)
- sudo pip3(Ubuntu のシステム Python の pip)
次の実行により,「python」や「pip」で「3」を付けなくても済むようになる:
sudo apt -y install python-is-python3
システム Python を使っているときの pip と setuptools の更新(Ubuntu 上)
sudo apt update
sudo apt -y install python3-pip python3-setuptools
Ubuntu での Python のインストール(pyenv を使用)
Ubuntu で,システム Python 以外の Python をインストールするには pyenv の利用が便利である.pyenv は,Linux,macOS で動く Python バージョン管理のツールである.
pyenv のインストール
pyenv の URL: https://github.com/pyenv/pyenv
sudo apt -y update
sudo apt -y install --no-install-recommends make build-essential libssl-dev zlib1g-dev libbz2-dev libreadline-dev libsqlite3-dev wget curl llvm libncurses5-dev xz-utils tk-dev libxml2-dev libxmlsec1-dev libffi-dev liblzma-dev
cd /tmp
curl https://pyenv.run | bash
echo 'export PYENV_ROOT="${HOME}/.pyenv"' >> ~/.bashrc
echo 'if [ -d "${PYENV_ROOT}" ]; then' >> ~/.bashrc
echo ' export PATH=${PYENV_ROOT}/bin:$PATH' >> ~/.bashrc
echo ' eval "$(pyenv init -)"' >> ~/.bashrc
echo ' eval "$(pyenv virtualenv-init -)"' >> ~/.bashrc
echo 'fi' >> ~/.bashrc
exec $SHELL -l
pyenv の利用
# インストール可能なPythonの一覧表示
pyenv install -l
# Pythonのインストール
pyenv install <バージョン指定>
# インストール済みのPythonの確認
pyenv version
# Pythonの有効化
pyenv shell <バージョン指定>
# pyenvのアンインストール
rm -rf ~/.pyenv
Ubuntu での Python の起動
- システム Python の Python バージョン3は,「python3」で起動する.
- pyenv を用いてインストールした Python は,pyenv の設定の後,「python」で起動する.
- venv を使うときは,activate コマンドを実行した後,「python」で起動する.
Python の隔離された環境 venv
Python には,さまざまなパッケージをインストールできる. venv の利用により,Python の仮想環境を作成し,パッケージが異なる複数の Python 環境を共存させることができる.
venv は Python 3 の標準機能である.
詳しい説明は,venv の公式の説明ページ: https://docs.python.org/ja/3/library/venv.html
Python の隔離された環境の新規作成
既定(デフォルト)では,Python の隔離された環境に,システムの site package は含まれない.
Windows:
python -m venv <ディレクトリ名>
py <Pythonのバージョン指定> -m venv <ディレクトリ名>
Ubuntu:
python3 -m venv <ディレクトリ名>
Python の隔離された環境の有効化
Windows:
<ディレクトリ名>\Scripts\activate.bat
Ubuntu:
source <ディレクトリ名>/bin/activate
Python の隔離された環境の無効化
deactivate
Python の仮想環境を扱う(venv を使用)(Windows の場合)
- 前もって Python をインストールしておく.使用している Python のバージョンの確認は,次のコマンドで行う.
python --version - Python の仮想環境の作成
ここでは,venv のためのディレクトリ名「%HOMEPATH%\.venv」を指定して,新しいPython の仮想環境を生成する.
python -m venv %HOMEPATH%\.venv dir /w %HOMEPATH%\.venv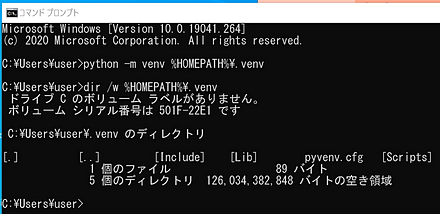
- Python の隔離された環境の有効化
%HOMEPATH%\.venv\Scripts\activate.bat
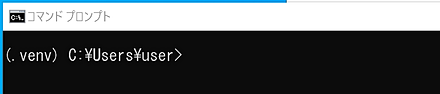
- パッケージを確認する
python -m pip list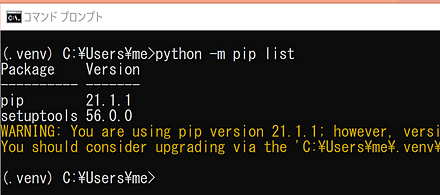
- 現在使用している Python の隔離された環境の無効化
deactivate
Windows の Python ランチャーでバージョン指定して,Python の仮想環境を扱う(venv を使用)
- Python ランチャーで,インストール済みの Python のバージョンを確認
py -0 - 新しい Python の仮想環境の新規作成
「-3.9」は,使用したい Python のバージョンの指定である.
py -3.9 -m venv %HOMEPATH%\.venv dir /w %HOMEPATH%\.venv - Python の隔離された環境の有効化
%HOMEPATH%\.venv\Scripts\activate.bat - Python ランチャーの実行で,先ほど指定した Python のバージョンが実行されることを確認.
py -0 py --version py - python コマンドでも,先ほど指定した Python のバージョンが実行される.
python --version - パッケージを確認する
python -m pip list - 現在使用している Python の隔離された環境の無効化
deactivate
Python の仮想環境を扱う(venv を使用)(Ubuntu の場合)
- python3-venv のインストール
# パッケージリストの情報を更新 sudo apt update sudo apt -y install python3-venv - 使用している システム Python のバージョンの確認
python3 --version
- Python の仮想環境の作成
ここでは,venv のためのディレクトリ名「~/.venv」を指定して,新しいPython の仮想環境を生成する.
python3 -m venv ~/.venv ls -la .venv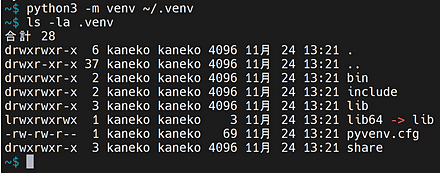
- Python の隔離された環境の有効化
source ~/.venv/bin/activate
- パッケージを確認する
python -m pip list
- 現在使用している Python の隔離された環境の無効化
deactivate
virtualenv,virtualenv-wrapper
virtualenv,virtualenv-wrapper は,Python の仮想環境の作成ができるソフトウェアである.venv が対応していない Python を使いたい場合には,virtualenv,virtualenv-wrapper が便利な場合がある.
virtualenv-wrapper の使い方:
- mkvirtualenv <Python仮想環境名>: Python 仮想環境の新規作成
- workon: Python 仮想環境の一覧表示
- workon <Python仮想環境名>: Python 仮想環境の有効化
- deactivate: いま有効化されている Python 仮想環境の無効化
Windows で virtualenv,virtualenv-wrapper をインストールする手順:
python -m pip install -U --no-user pip setuptools
python -m pip install -U --no-user virtualenv virtualenvwrapper-win
Windows で Python 3 の仮想環境を新規作成するときの操作例:
mkvirtualenv py3
Anaconda3
Anaconda3 は,Anaconda Inc. 社が提供している Python バージョン3のソフトウェアである.言語処理系,開発ツール,パッケージ管理ツール conda,さまざまな Python パッケージから構成されている.
- Spyderは,Python 開発環境である.
- condaは,Python パッケージのインストール,各種ソフトウェアのインストール,新しい Python 環境の作成などを行えるソフトウェアである.
- Anaconda Promptは,コマンドラインインターフェイスである.
- Jupyter Notebookは,対話型のプログラム実行ツールである.
- Anaconda Navigatorは,アプリケーション管理ツールである.
関連する外部ページ
- Anaconda3 の公式ページ: https://www.anaconda.com
- Anaconda3 の公式ダウンロードページ: https://www.anaconda.com/download
- conda 公式のチートシート: https://conda.io/projects/conda/en/latest/user-guide/cheatsheet.html
Anaconda3 のインストール(winget を使用)(Windows 上)
- Windows で,管理者権限でコマンドプロンプトを起動する
(手順:Windowsキーまたはスタートメニュー →
cmdと入力 → 右クリック → 「管理者として実行」). - 次のコマンドを実行する.
winget install --scope machine Anaconda.Anaconda3 powershell -command "$oldpath = [System.Environment]::GetEnvironmentVariable(\"Path\", \"Machine\"); $oldpath += \";C:\ProgramData\Anaconda3;C:\ProgramData\Anaconda3\Scripts\"; [System.Environment]::SetEnvironmentVariable(\"Path\", $oldpath, \"Machine\")"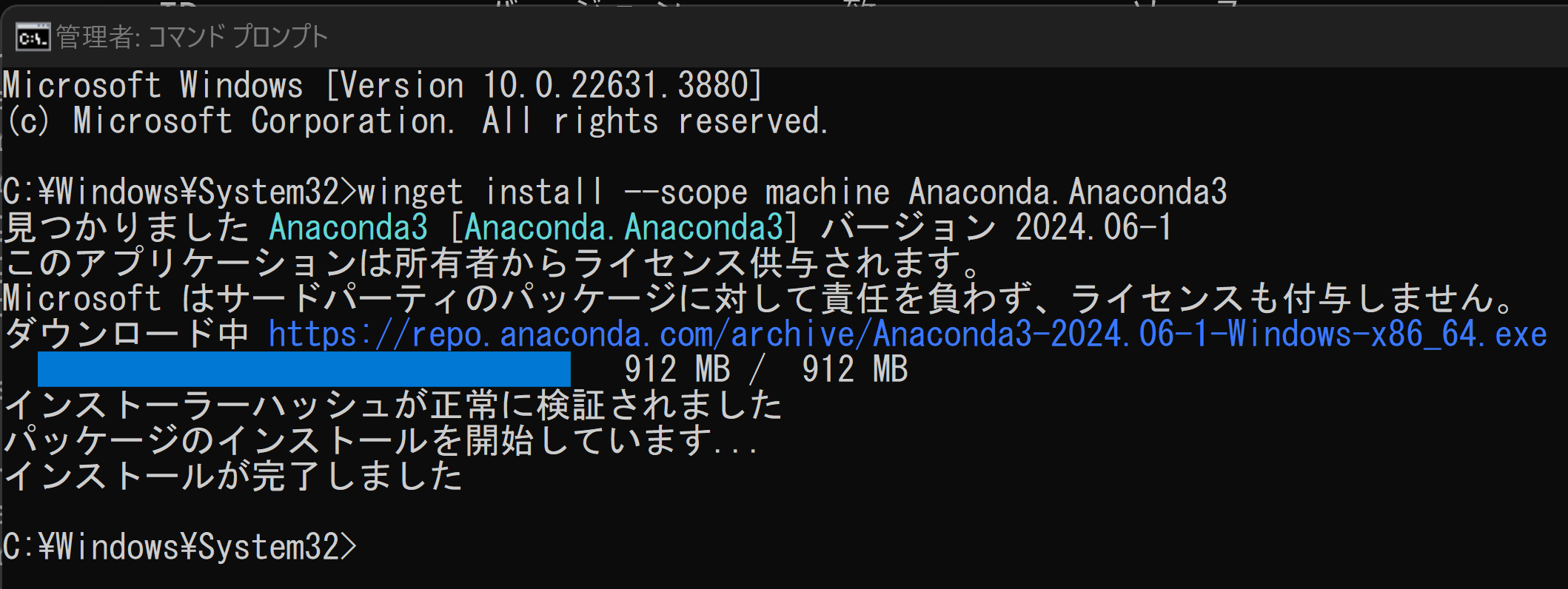
- Windows のスタートメニューに「Anaconda3 (64-bit)」が追加される.
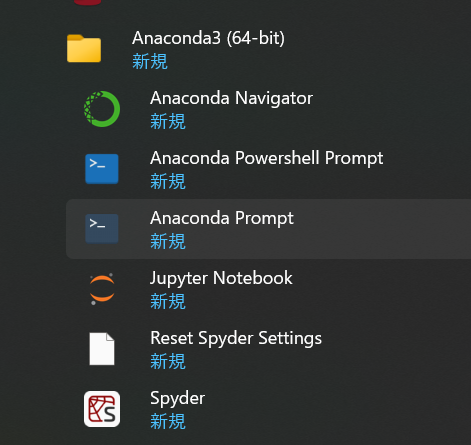
Anaconda Prompt
Anaconda Prompt は,Anaconda3 に同封されたコマンドプロンプトのソフトウェアである.
conda で Python の隔離された環境
conda の利用により,バージョンや搭載パッケージが異なる複数の Python 環境を共存させることができる.
conda create --name py39 python=3.9
Anaconda3 の Python のパスの設定
このサイトでは,システムの環境変数 PATH の先頭部分に,次の5つが設定されているものとして説明している.
C:\ProgramData\Anaconda3 C:\ProgramData\Anaconda3\Library\mingw-w64\bin C:\ProgramData\Anaconda3\Library\usr\bin C:\ProgramData\Anaconda3\Library\bin C:\ProgramData\Anaconda3\Scripts
Windows での Python と Anaconda 内の Python の共存
Anaconda3 内蔵の Python を使いたいときは,py コマンドは使わない.パスを通すか,フルパスで指定するか,Anaconda Prompt を使う.
すでに Python をインストール済みの場合でも,Anaconda3 と両立できる.
- Anaconda3 内の Python は,孤立した Python 環境である.
- Anaconda3 の利用では,Anaconda Prompt,Spyder が便利である(いずれもスタートメニューから起動できる).
- Windows で Python と Anaconda 内の Python が共存する場合,Anaconda3 にパスを通すのは推奨できない.
Anaconda3 では pip を使わないこと.Anaconda3 は pip の使用を想定していない.
Python の種々のバージョン
Python の公式ページ: https://www.python.org/
Jupyter Qt Console, Jupyter ノートブック (Jupyter Notebook), JupyterLab
JupyterLab, Jupyter ノートブック (Jupyter Notebook), Jupyter Qt Console は,Python プログラム作成のための機能を持ったソフトウェアである.
Windows での Jupyter Qt Console, Jupyter ノートブック (Jupyter Notebook), JupyterLab の起動
- Jupyter Qt Console の起動: 「jupyter qtconsole」または「python -m qtconsole」.

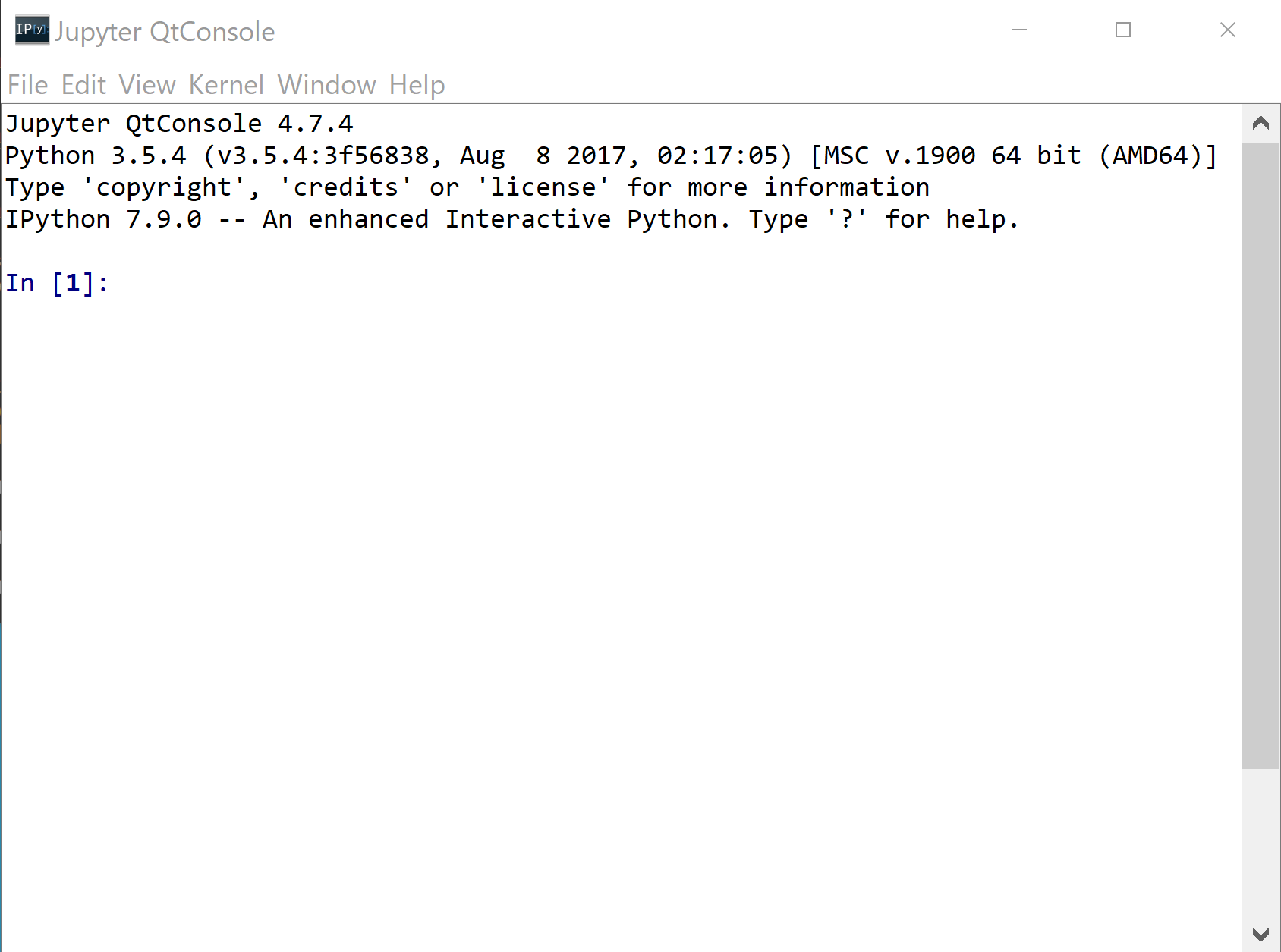
- Jupyter ノートブック (Jupyter Notebook) の起動: 「jupyter notebook」または「python -m notebook」
- JupyterLab の起動: 「jupyter lab」または「python -m jupyterlab」.
- JupyterLab の起動: 「py -<バージョン> -m jupyterlab」.
- Jupyter ノートブック (Jupyter Notebook) の起動: 「py -<バージョン> -m notebook」.
- Jupyter Qt Console の起動: 「py -<バージョン> -m qtconsole」.
Windows での Jupyter Qt Console, Jupyter ノートブック (Jupyter Notebook), JupyterLab のインストール
管理者権限でコマンドプロンプトを起動する
(手順:Windowsキーまたはスタートメニュー → cmd と入力 → 右クリック → 「管理者として実行」).次のコマンドを実行する.
python -m pip install -U --no-user pip setuptools requests notebook==6.5.7 jupyterlab jupyter jupyter-console jupytext PyQt5 nteract_on_jupyter spyder

Ubuntu での Jupyter Qt Console, JupyterLab の起動とインストール
- Jupyter Qt Console の起動: 「jupyter qtconsole」または「python3 -m qtconsole」.
- JupyterLab の起動: 「jupyter lab」または「python3 -m jupyterlab」.
# パッケージリストの情報を更新
sudo apt update
sudo apt -y install python-is-python3 python3-dev python-dev-is-python3 python3-pip python3-setuptools python3-venv build-essential
sudo pip3 uninstall -y ptyprocess sniffio terminado tornado jupyterlab jupyter jupyter-console jupytext nteract_on_jupyter spyder
sudo apt -y install jupyter jupyter-qtconsole spyder3
sudo apt -y install python3-ptyprocess python3-sniffio python3-terminado python3-tornado
sudo pip3 install -U jupyterlab jupyter jupyter-console jupytext nteract_on_jupyter
JupyterLab の起動は「pyenv shell <バージョン>; jupyter lab」, Jupyter Qt Console の起動は「pyenv shell <バージョン>; jupyter qtconsole」.
Jupyter Notebook の保存設定
Jupyter Notebook で,保存のときに .py ファイルと .ipynb ファイルの両方が保存されるように設定する(この設定を行わないときは .ipynb ファイルのみが保存される).
- 次のコマンドで,設定ファイルを生成する
jupyter notebook --generate-config - jupyter/jupyter_notebook_config.py を編集し,末尾に次を追加する
c.NotebookApp.contents_manager_class = "jupytext.TextFileContentsManager"
第2章 Python 関係のツール
pip
pip は Python のパッケージマネージャである.
Windows
- pip の起動は「pip」または「python -m pip」である.
- Windows のユーザ名で日本語を使っているときは,コマンドプロンプトを管理者として実行してから,「pip」または「python -m pip」を実行する.
- venv を使うときは,venv が定める activate を実行した後に「pip」または「python -m pip」を実行する.
Ubuntu
- システム Python を使っていて,隔離した Python 環境を作らない(pyenv,venv なども使っていない)ときは,pip ではなく apt でインストールする.
- pyenv を使うときは,「pyenv shell <バージョン>」のあとに「pip」または「python -m pip」を実行する.
- venv を使うときは,venv が定める activate を実行した後に「pip」または「python -m pip」を実行する.
Python パッケージ・インデックス (PyPI)
パッケージの検索や調査を行うときに,次の URL を使う:
Python パッケージ・インデックス (PyPI) の URL: https://pypi.org/
Google Colaboratory での pip の操作
Google Colaboratory では pip を次のように操作する.頭に「!」を付ける.
- パッケージのインストール
!pip3 install <パッケージ名> - インストール済みパッケージの一覧
!pip3 list - アンインストール
!pip3 uninstall <パッケージ名> - パッケージの情報
!pip3 show <パッケージ名>
Windows での pip の操作
Windows では pip を次のように操作する.
- Python のバージョン指定なし
- パッケージのインストール
pip install <パッケージ名>Windows で,管理者の領域に Python をインストールしている場合には,管理者の権限で実行する.
パッケージのバージョン指定を行うときは,「numpy==1.26.4」のようにパッケージ名の後に付ける. - インストール済みパッケージの一覧
pip list - アンインストール
pip uninstall <パッケージ名> - パッケージの情報
pip show <パッケージ名>
- パッケージのインストール
- Windows の Python ランチャーで Python のバージョン指定
- パッケージのインストール
py -3.10 -m pip install <パッケージ名> (Python 3.10 の pip を使う場合) - インストール済みパッケージの一覧
py -3.10 -m pip list (Python 3.10 の pip を使う場合) - アンインストール
py -3.10 -m pip uninstall <パッケージ名> (Python 3.10 の pip を使う場合) - パッケージの情報
py -3.10 -m pip show <パッケージ名> (Python 3.10 の pip を使う場合)
- パッケージのインストール
Ubuntu での pip の操作
Ubuntu でシステム Python を使う場合は,pip を次のように操作する:
- パッケージのインストール
sudo pip3 install <パッケージ名> (システムPythonを使う場合)Ubuntu では,「sudo pip3 install」でパッケージをインストールする前に,「apt-cache search <キーワード>」で Ubuntu のパッケージを検索し,見つかった場合にはそちらを「apt install <Ubuntu のパッケージ名>」でインストールする. - インストール済みパッケージの一覧
pip3 list (システムPythonを使う場合) - アンインストール
sudo pip3 uninstall <パッケージ名> (システムPythonを使う場合) - パッケージの情報
pip3 show <パッケージ名> (システムPythonを使う場合)
pip と setuptools を最新版に更新
- Windows の場合
Windows では,管理者権限でコマンドプロンプトを起動する (手順:Windowsキーまたはスタートメニュー →
cmdと入力 → 右クリック → 「管理者として実行」).次のコマンドを実行する.python -m pip install -U --no-user pip setuptools - Ubuntu の場合
sudo apt -y upgrade python3-pip python3-setuptools
pip のインストールを手動で行いたい場合
- Windows で get-pip.py を使って pip の更新を行う操作
cd /tmp curl -O https://bootstrap.pypa.io/get-pip.py python get-pip.py - 「Geospatial library wheels for Python on Windows」のページ: https://github.com/cgohlke/geospatial-wheels
Python の setup.py の実行
git clone https://github.com/openai/gym
cd gym
pip install -e .
必要に応じて,次のように操作する:
git clone https://github.com/openai/gym
cd gym
python setup.py build
python setup.py install
python -m pip install --no-user wheel
python setup.py bdist_wheel
Python の build_ext の実行
python -m pip install pillow==6 --global-option="build_ext" --global-option="--disable-jpeg" --global-option="--disable-zlib"
2to3
2to3 は,Python バージョン2用のソースコードを Python バージョン3用に変換するプログラムである:
2to3 -w .
第3章 Python 開発環境,Python コンソール(Jupyter Qt Console,Jupyter ノートブック,Jupyter Lab,Nteract,spyder,PyCharm)
Python,pip,Python 開発環境,Python コンソールのコマンドでの起動
Windows の場合
- python: python
- pip: python -m pip または pip
- Jupyter Qt Console: jupyter qtconsole あるいは python -m qtconsole
- Jupyter ノートブック (Jupyter Notebook): jupyter notebook
- Jupyter Lab: jupyter lab あるいは python -m jupyterlab
- Nteract: jupyter nteract
- Spyder: spyder
Windows の Python ランチャーでバージョン指定する場合
- インストール済み Python のバージョン一覧: py -0
- python: py -3.10 (Python 3.10 を使う場合)
- pip: py -3.10 -m pip (Python 3.10 の pip を使う場合)
- Jupyter Qt Console: py -3.10 -m qtconsole
- Jupyter ノートブック (Jupyter Notebook): py -3.10 -m notebook
- Jupyter Lab: py -3.10 -m jupyterlab
Ubuntu の場合
- python: python3
- pip: sudo pip3
- Jupyter Qt Console: jupyter qtconsole あるいは python3 -m qtconsole
- Jupyter ノートブック (Jupyter Notebook): jupyter notebook
- Jupyter Lab: jupyter lab あるいは python3 -m jupyterlab
- Nteract: jupyter nteract
- Spyder: spyder
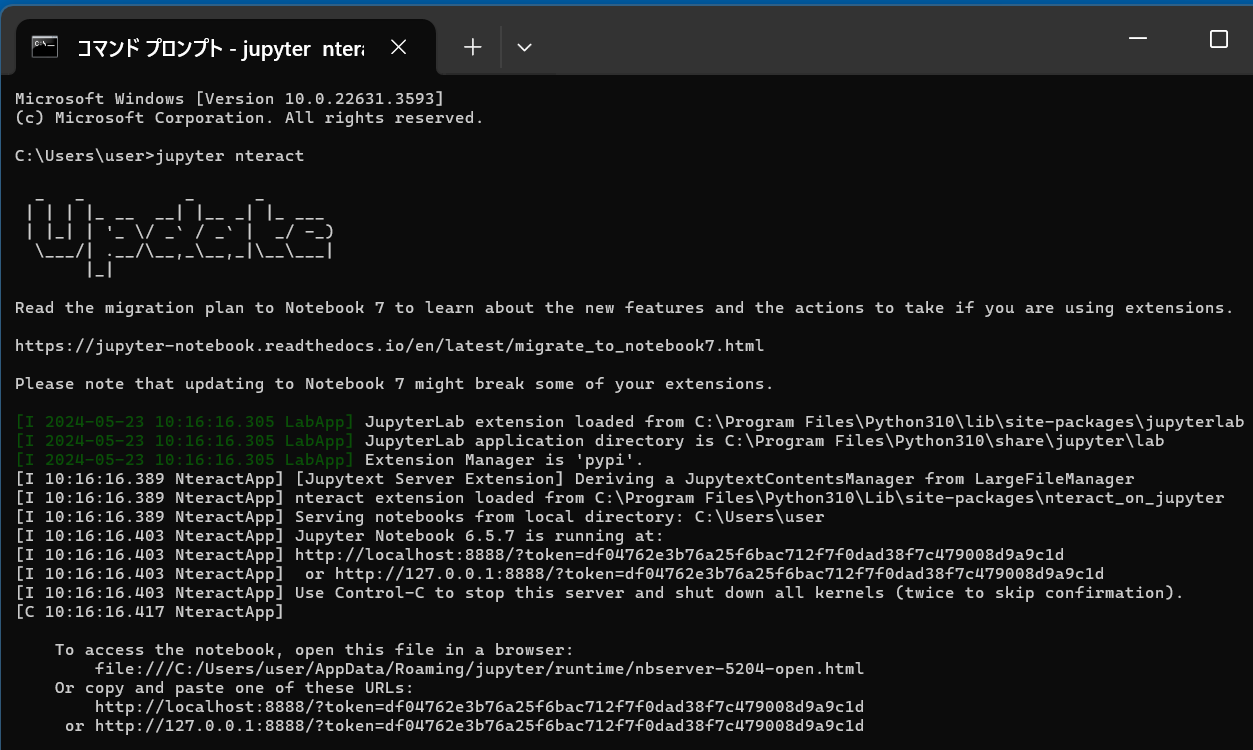
Windows での Python 開発環境として,Jupyter Qt Console,Jupyter ノートブック (Jupyter Notebook),Jupyter Lab,Nteract,spyder のインストール
Windows では,管理者権限でコマンドプロンプトを起動する
(手順:Windowsキーまたはスタートメニュー → cmd と入力 → 右クリック → 「管理者として実行」).次のコマンドを実行する.
python -m pip install -U --no-user pip setuptools requests notebook==6.5.7 jupyterlab jupyter jupyter-console jupytext PyQt5 nteract_on_jupyter spyder
Python ランチャーでバージョン指定する場合(Python 3.10 を使う場合):
py -3.10 -m pip install -U --no-user pip setuptools requests notebook==6.5.7 jupyterlab jupyter jupyter-console jupytext PyQt5 nteract_on_jupyter spyder
Ubuntu での Python 開発環境として,Jupyter Qt Console,Jupyter ノートブック (Jupyter Notebook),Jupyter Lab,Nteract,spyder のインストール
# パッケージリストの情報を更新
sudo apt update
sudo apt -y install python-is-python3 python3-dev python-dev-is-python3 python3-pip python3-setuptools python3-venv build-essential
sudo pip3 uninstall -y ptyprocess sniffio terminado tornado jupyterlab jupyter jupyter-console jupytext nteract_on_jupyter spyder
sudo apt -y install jupyter jupyter-qtconsole spyder3
sudo apt -y install python3-ptyprocess python3-sniffio python3-terminado python3-tornado
sudo pip3 install -U jupyterlab jupyter jupyter-console jupytext nteract_on_jupyter
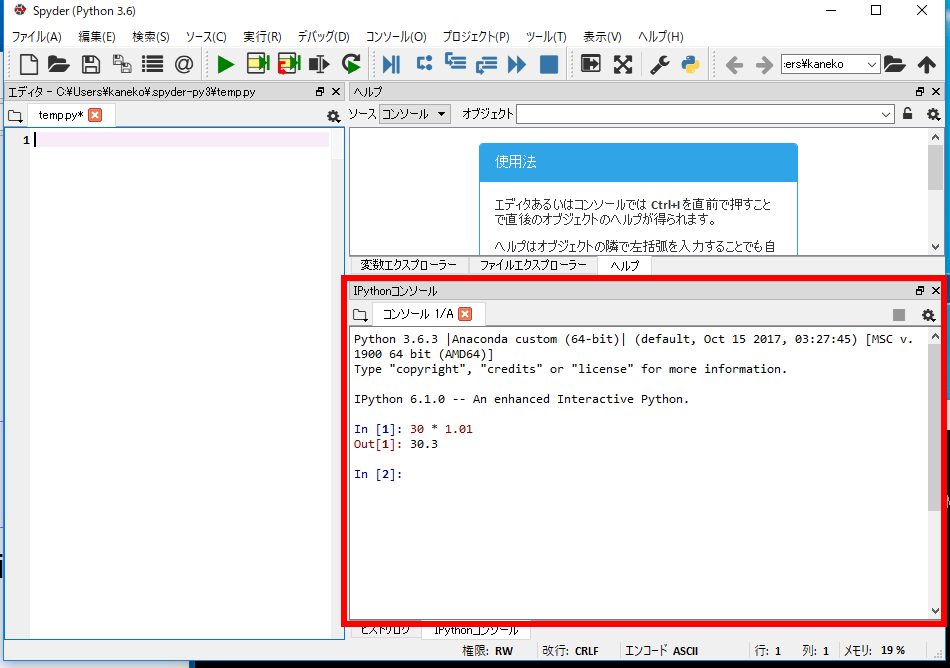
Python コンソール
Python コンソールは,Python のシェルの画面のことである.プロンプトが出て Python のプログラムを受け付け,その実行結果を表示する.
- Jupyter Qt Console: Python コンソールの機能を持つ
- Spyder: Python コンソールの機能を持つ(デフォルトで右下の画面が Python コンソール)
- PyCharm: Python コンソールの機能を持つ
- python: Windows では端末で「python」あるいは「py -3.10(Python 3.10 を使う場合)」を実行して起動する
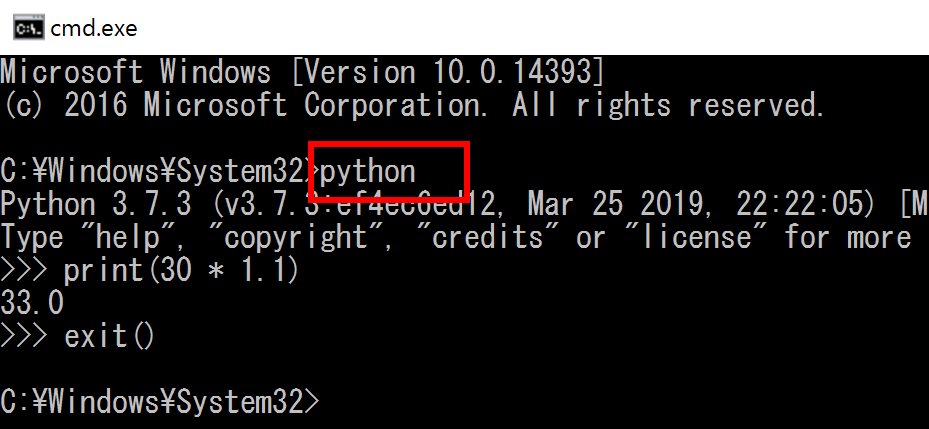
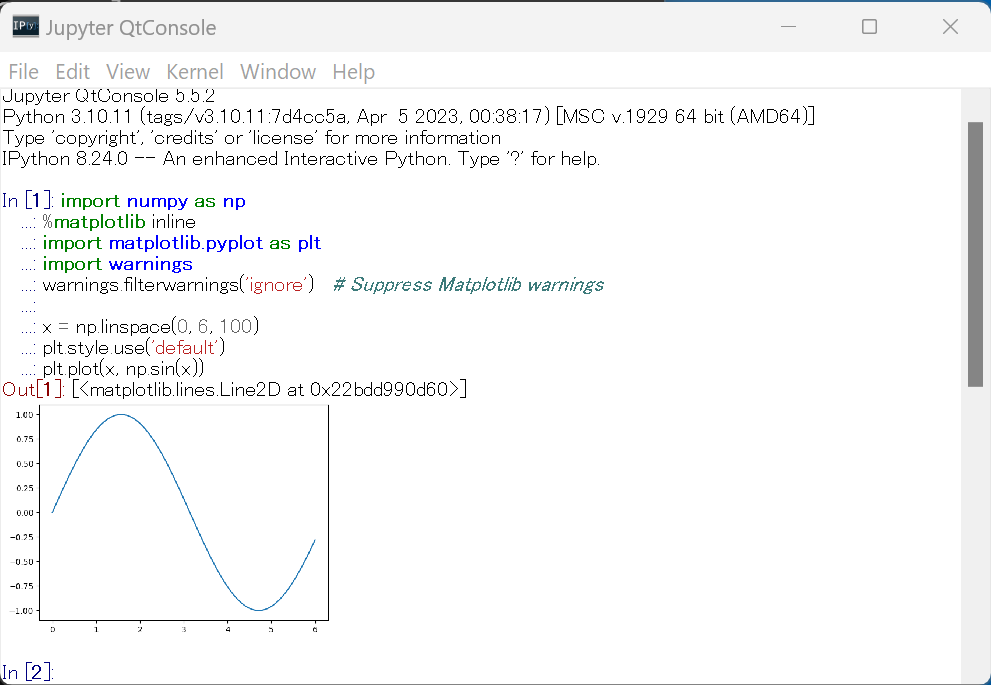
Jupyter Qt Console の実行例
次の Python プログラムを実行してみる(sin 関数のグラフを描画):
import numpy as np
%matplotlib inline
import matplotlib.pyplot as plt
x = np.linspace(0, 6, 100)
plt.style.use('default')
plt.plot(x, np.sin(x))
Jupyter ノートブック (Jupyter Notebook)
Jupyter ノートブックは,Python などのプログラムのソースコードと実行結果を1つのノートとして残す機能を持ったノートブックである.
Jupyter Lab
Jupyter Lab は,Python プログラム作成のための機能を持ったソフトウェアである.
Nteract
Nteract は,Python などのプログラムのソースコードと実行結果を1つのノートとして残す機能を持ったノートブックである.
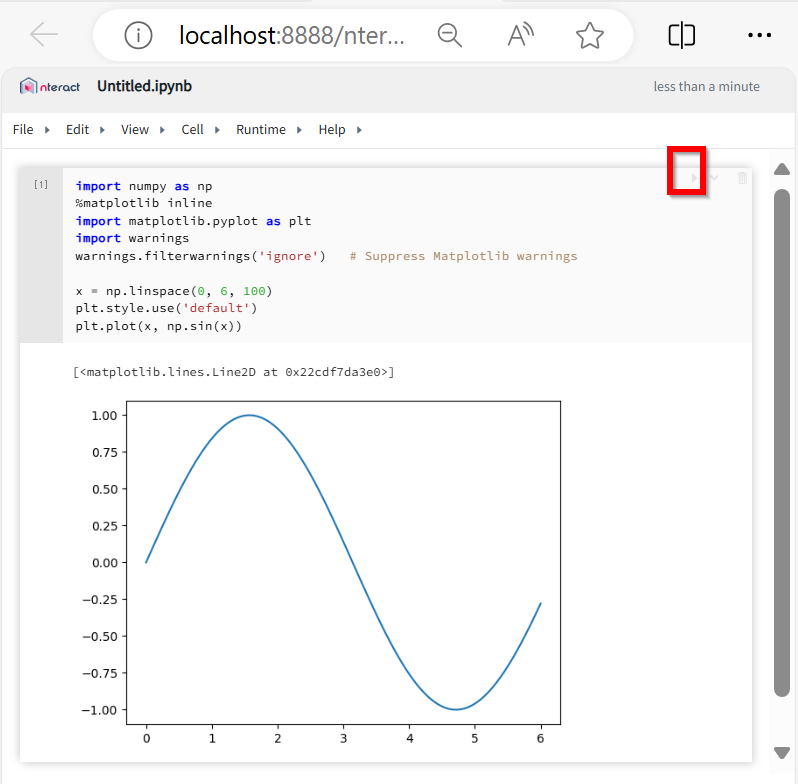
import numpy as np
%matplotlib inline
import matplotlib.pyplot as plt
x = np.linspace(0, 6, 100)
plt.style.use('default')
plt.plot(x, np.sin(x))
PyScripter
PyScripter は,Python プログラム作成のための機能を持ったソフトウェアである.
Windows での PyScripter のインストールは,別ページ »で説明している.
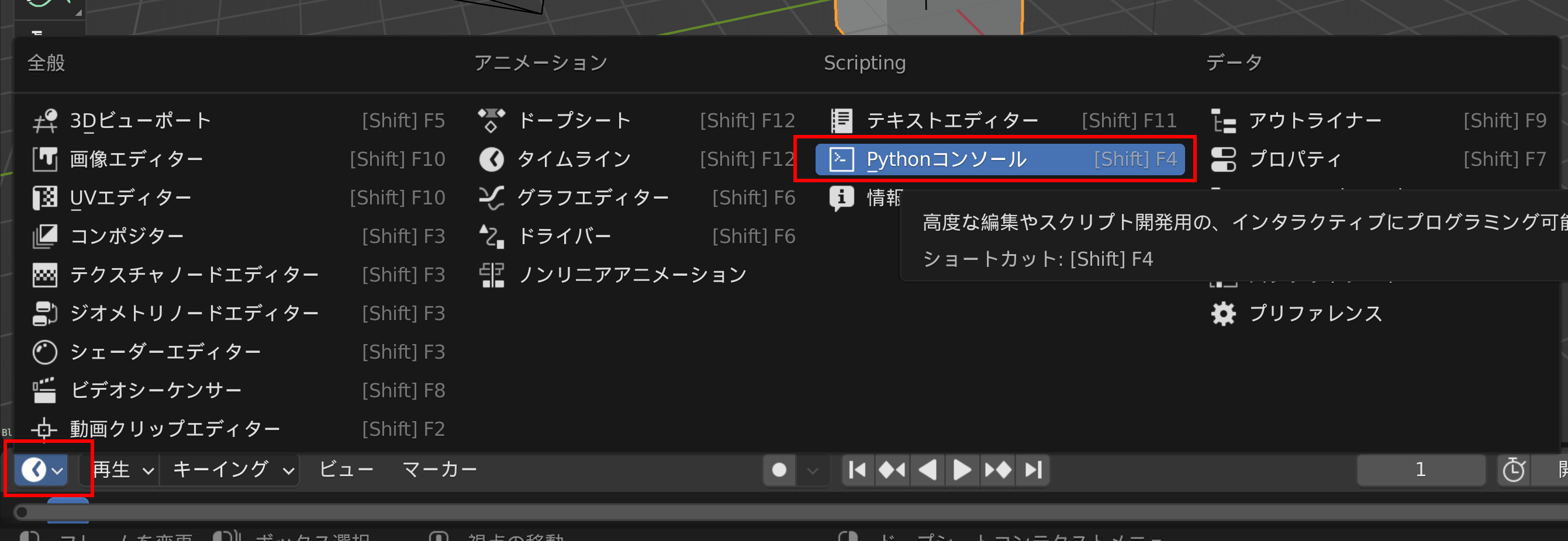
Blender の Python コンソール
Blender に内蔵された Python のコンソールである.Blender 3.0 では次の手順で開くことができる.
画面として「Pythonコンソール」を選ぶ.
spyder
Windows で Anaconda3 をインストールしたときは,スタートメニューの「Anaconda3 (64-bit)」の下に「Spyder」があるので,これを使って実行するのが簡単である.
Ubuntu では「spyder」で実行する.
PyCharm
PyCharm は,Python プログラム作成のための機能を持ったソフトウェアである.次の機能を持つ:
- Python プログラムの編集と実行
- Python コンソール
- Python の仮想環境
【PyCharm Community 版の主な機能】
- 日本語言語パックのプラグイン
操作: Plugins,japanese で検索,「Install」をクリック
- Python コードインスペクション
シンタックスハイライト,整形(コードフォーマッタ),コード解析,修正候補の提示と実行(クイックフィックス)(Alt+Enter を使用),コード補完など
- 検索
検索は SHIFT を2回押す
- ビジュアルなデバッガ
ブレークポイント(マウスで指定可能),変数値の表示など
- リファクタリング
名前の変更,メソッドの抽出など(メニューで実行可能)
- 型ヒント
型ヒントは Alt+Enter を使用
- 単体テストで pytest を使うように設定
File,Settings,Python Integrated tools,Default test runner で「pytest」を設定
第4章 Python の基礎
式と変数
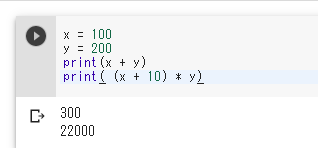
変数は,変化するデータのことである.「x = 100」のように書くと x の値が 100 に変化する.
式の実行結果として値が得られる.式の中に変数名を書くことができる.
x = 100
y = 200
print(x + y)
print( (x + 10) * y)
teihen = 2.5
takasa = 5
print(teihen * takasa / 2)

単純値のデータ型
- キーワード: int, float, Decimal, True, False, bool, None, str, bytes,
list, range, tuple, dict, set
- int: 整数
- float: 浮動小数点数
- bool: ブール値
- str: 文字列
- bytes: バイト列
- 辞書 (dictionary)
dic = {} dic.update( {"kaneko": 30} ) print(dic)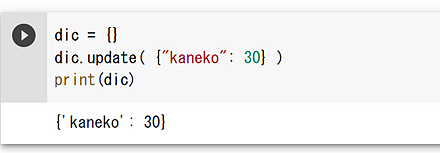
- 名前付きタプル (named tuple)
import collections Point3d = collections.namedtuple('Point3d', 'x y z') p = Point3d(10, 20, 30) print(p)
文字列の演算子
キーワード: +, in, %, split, join, replace, strip, match, format
空白などで区切られたテキストをリストに変換
import re
def removeletters(s):
return re.sub(r':|\||-', ' ', s)
def getdata(s):
m = re.match(r'[0-9]+(b|B|k|K|m|M|g|G|t|T)*', s)
if m:
return m.group()
else:
return ''
s = 'system 07-09 15:00:03| 0 0 100 0 0: 0 0 100 0 0: 0 0 100 0 0: 0 0 100 0 0: 1 0 99 0 0: 0 0 100 0 0: 0 0 100 0 0: 0 0 100 0 0| 0 40k| 173 243 |0.03 0.05 0|1856M 14.1G 1553M 13.1G'
a = removeletters(s)
b = a.split()
print(list(map(getdata, b)))

制御構造(条件分岐,繰り返し)
キーワード: if, elif, else, while, break, for
条件分岐
- 条件分岐
変数の値によって,実行の流れが変わる.
age = 15 if (age <= 12): print(500) else: print(1800)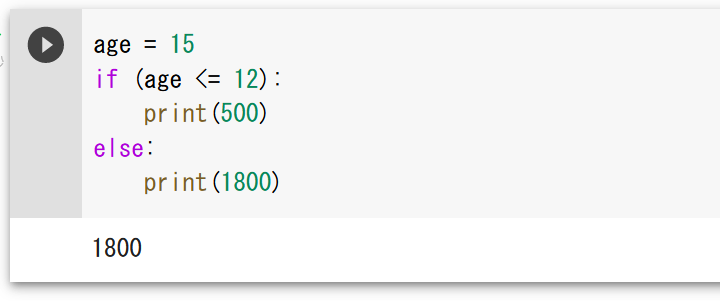
- 多分岐
age = 15 if age <= 12: print(500) elif age <= 15: print(1000) else: print(1800)
繰り返し
- while による繰り返し
b = 8 s = 0 while s < 100: s = s + b print(s)
- for による繰り返し
for i in range(10): print(i)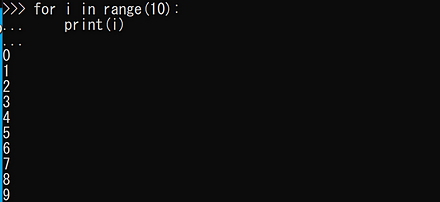
- 月の日数
月の日数についてのデータを作る.うるう年は考えないことにする.
import numpy as np days = np.array([0, 31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31]) print( days[7] ) print( days[9] )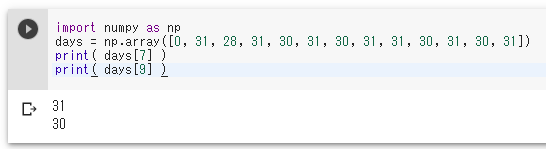
- 物体の落下
for による繰り返し
import numpy as np x = np.array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10]) for t in x: print( (9.8 / 2) * t * t )
- 10倍
for による繰り返し
import numpy as np x = np.array([8, 6, 4, 2, 3]) y = np.array([0, 0, 0, 0, 0]) for i in range(0,5): y[i] = x[i] * 10 print(x) print(y)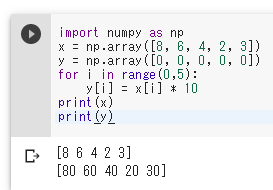
「*」の表示を 18 回繰り返す(* を 18 個並べて表示)
for による繰り返し
import sys
for i in range(18):
sys.stdout.write("*")

関数定義,関数オブジェクト
関数定義は def,戻り値は return.
- アッカーマン関数の定義
def a(m, n): if m == 0: return n + 1 elif n == 0: return a(m-1, 1) else: return a(m-1, a(m, n-1)) print(a(3, 2)) print(a(m = 3, n = 2)) print(a(n = 2, m = 3))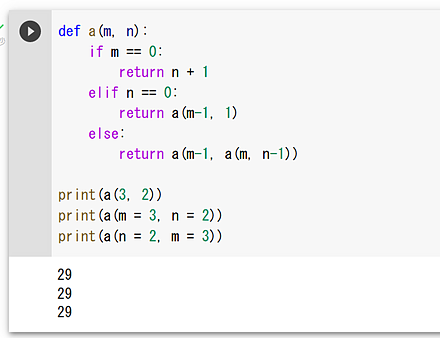
- 既定(デフォルト)値
def a(m, n = 1): if m == 0: return n + 1 elif n == 0: return a(m-1, 1) else: return a(m-1, a(m, n-1)) print(a(3, 1)) print(a(3)) print(a(m = 3))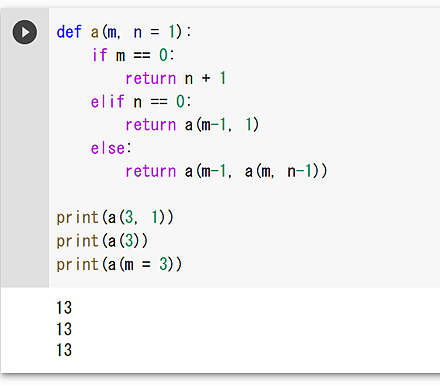
- 関数オブジェクト
f = lambda x: x + 1 print(f(100))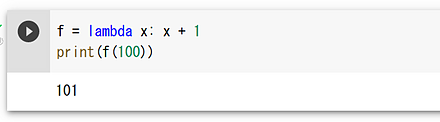
式の抽象化と関数
式の抽象化は,類似した複数の式を,変数を使って1つにまとめることである.
print(100 * 1.08)
print(150 * 1.08)
print(400 * 1.08)
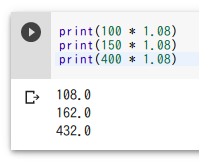
上の3つの式を抽象化すると「a * 1.08」のような式になる.
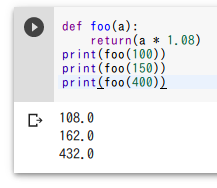
def foo(a):
return a * 1.08
print(foo(100))
print(foo(150))
print(foo(400))
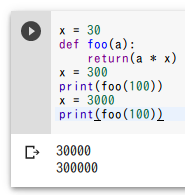
式の評価のタイミング
関数の中の式の評価では,最新の変数値が用いられる.
x = 30
def foo(a):
return(a * x)
x = 300
print(foo(100))
x = 3000
print(foo(100))
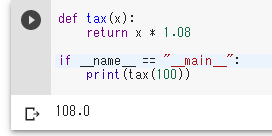
Python のモジュール
Python のモジュールは,1つ以上の関数を1つのファイルに集めたものである.
tax 関数は説明用の例であり,値 1.08 は現行の消費税率とは異なる.
def tax(x):
return x * 1.08
if __name__ == "__main__":
print(tax(100))
import hoge
print(hoge.tax(10))
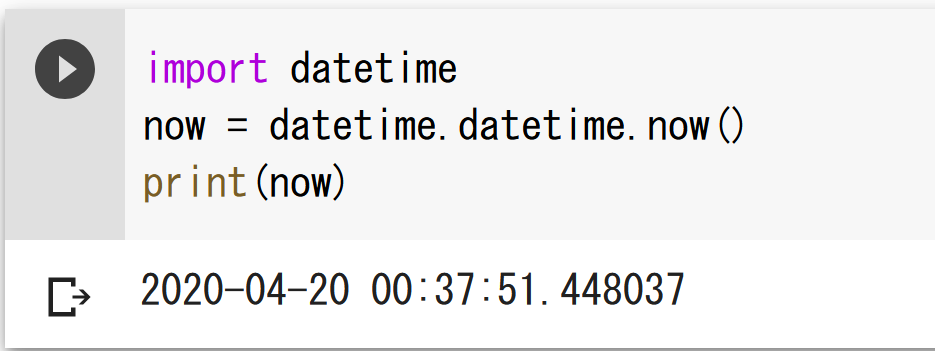
Python のライブラリ
現在の日時
import datetime
now = datetime.datetime.now()
print(now)
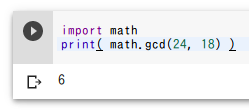
最大公約数
24 と 18 の最大公約数を求める.結果 6 を確認.
import math
print( math.gcd(24, 18) )
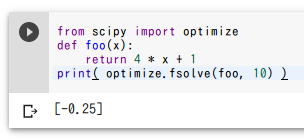
方程式を解く
4x + 1 = 0 を解く.
from scipy import optimize
def foo(x):
return 4 * x + 1
print( optimize.fsolve(foo, 10) )
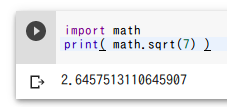
平方根
面積が 7 の正方形の一辺の長さを求める.
import math
print( math.sqrt(7) )
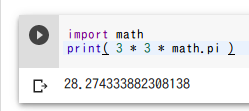
円の面積
半径 3 の円の面積を求める.
import math
print( 3 * 3 * math.pi )
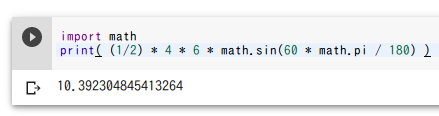
三角形の面積
三角形の2辺の長さが 4 と 6 で,その間の角度が 60 度のとき.
import math
print( (1/2) * 4 * 6 * math.sin(60 * math.pi / 180) )
第5章 オブジェクト指向プログラミング
オブジェクトの生成と削除, 同値, 同一性
プログラミングでのオブジェクトは,コンピュータでの操作や処理の対象となるもののことである.
キーワード: =, del, ==, is
- 同値
a = 123 b = 123 print(a == b)
- 同一性
x = True y = None print(x is True) print(y is None)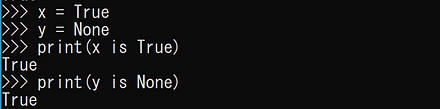
- オブジェクトの生成と削除
最後の「print(c)」の実行では,NameError のエラーメッセージが出る.
c = 123 print(c) del c print(c)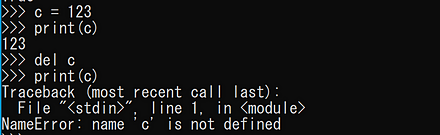
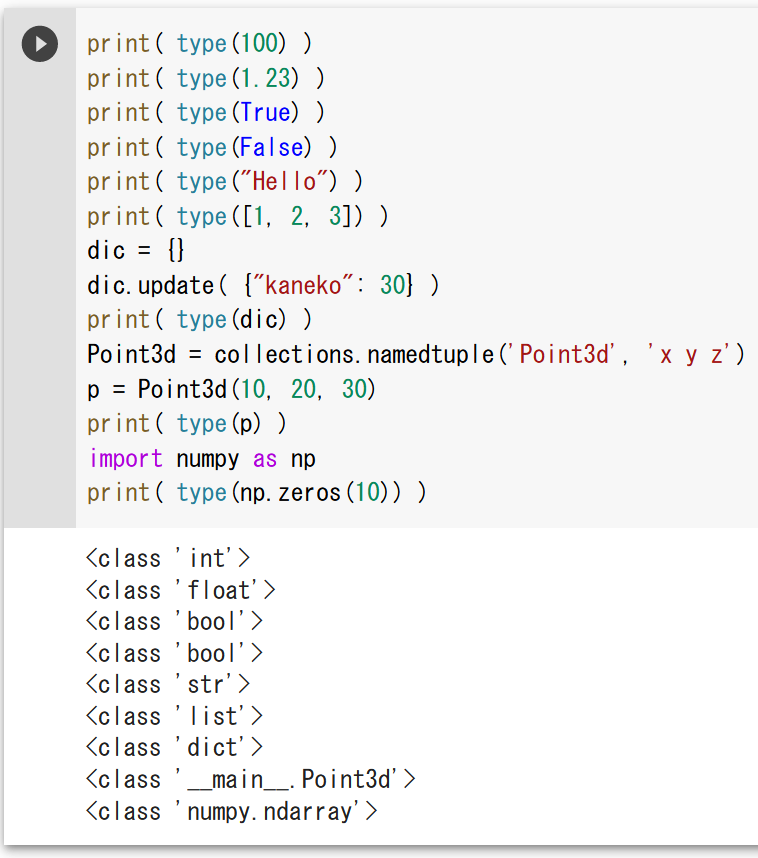
オブジェクトのタイプ(クラス名)の取得
print( type(100) )
print( type(1.23) )
print( type(True) )
print( type(False) )
print( type("Hello") )
print( type([1, 2, 3]) )
dic = {}
dic.update( {"kaneko": 30} )
print( type(dic) )
import collections
Point3d = collections.namedtuple('Point3d', 'x y z')
p = Point3d(10, 20, 30)
print( type(p) )
import numpy as np
print( type(np.zeros(10)) )
クラス定義,オブジェクト生成,属性アクセス
- メソッド: オブジェクトに属する操作や処理
- クラス: 同一種類のオブジェクトの集まり
- クラス定義: あるクラスが持つ属性とメソッドを定めること
- 「.」+属性名: 属性アクセス.メソッド内では self + 「.」で属性にアクセスする
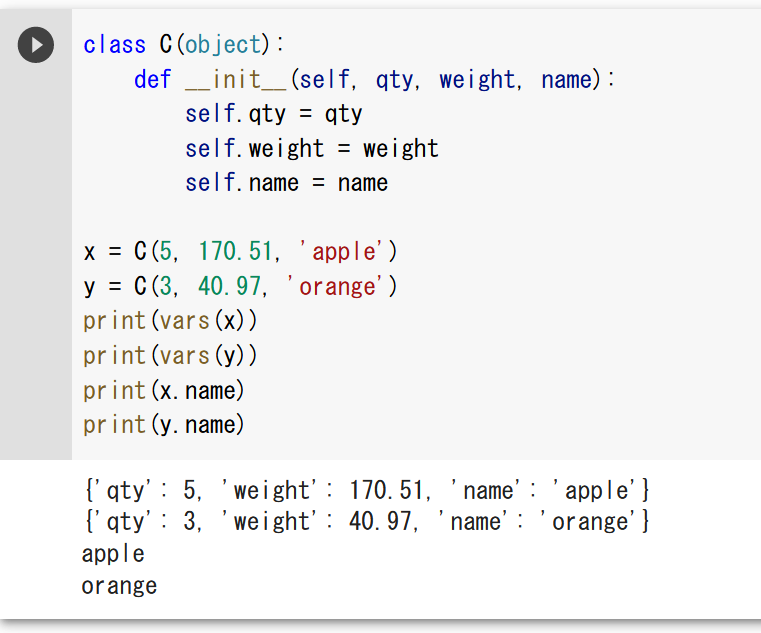
クラス定義,オブジェクト生成,属性アクセスの例
class C(object): のように明示的に object を継承する形式で記述している.これは Python 2 との互換性を意識した書き方であり,Python 3 では class C: と書いても同じ動作をする(Python 3 ではすべてのクラスが暗黙的に object を継承するため).
クラス名: C,属性名: qty, weight, name
class C(object):
def __init__(self, qty, weight, name):
self.qty = qty
self.weight = weight
self.name = name
x = C(5, 170.51, 'apple')
y = C(3, 40.97, 'orange')
print(vars(x))
print(vars(y))
print(x.name)
print(y.name)
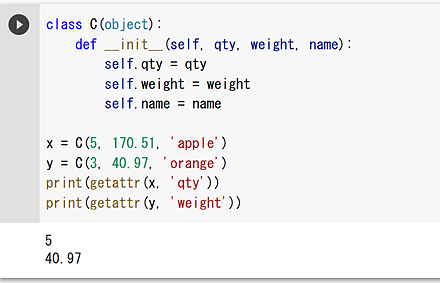
getattr による属性値の取得
class C(object):
def __init__(self, qty, weight, name):
self.qty = qty
self.weight = weight
self.name = name
x = C(5, 170.51, 'apple')
y = C(3, 40.97, 'orange')
print(getattr(x, 'qty'))
print(getattr(y, 'weight'))
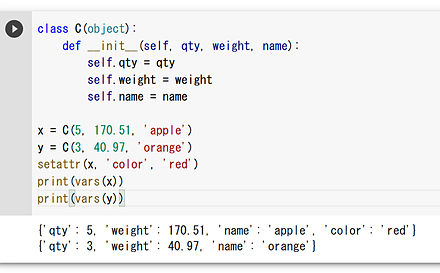
setattr による属性の動的な追加
class C(object):
def __init__(self, qty, weight, name):
self.qty = qty
self.weight = weight
self.name = name
x = C(5, 170.51, 'apple')
y = C(3, 40.97, 'orange')
setattr(x, 'color', 'red')
print(vars(x))
print(vars(y))
コンストラクタでの既定値(デフォルト値)
クラス名: D,属性名: s_hour, s_minute, e_hour, e_minute
class D(object):
def __init__(self, s_hour, s_minute):
self.s_hour = s_hour
self.s_minute = s_minute
self.e_hour = None
self.e_minute = None
z = D(15, 30)
z2 = D(16, 15)
print(vars(z))
print(vars(z2))

メソッド
メソッドの例
- 「.」+メソッド名: メソッドアクセス.メソッド内では self + 「.」で属性やメソッドにアクセスする
class C(object):
def __init__(self, qty, weight, name):
self.qty = qty
self.weight = weight
self.name = name
def total(self):
return self.qty * self.weight
x = C(5, 170.51, 'apple')
print(vars(x))
print(x.total())
help(x)
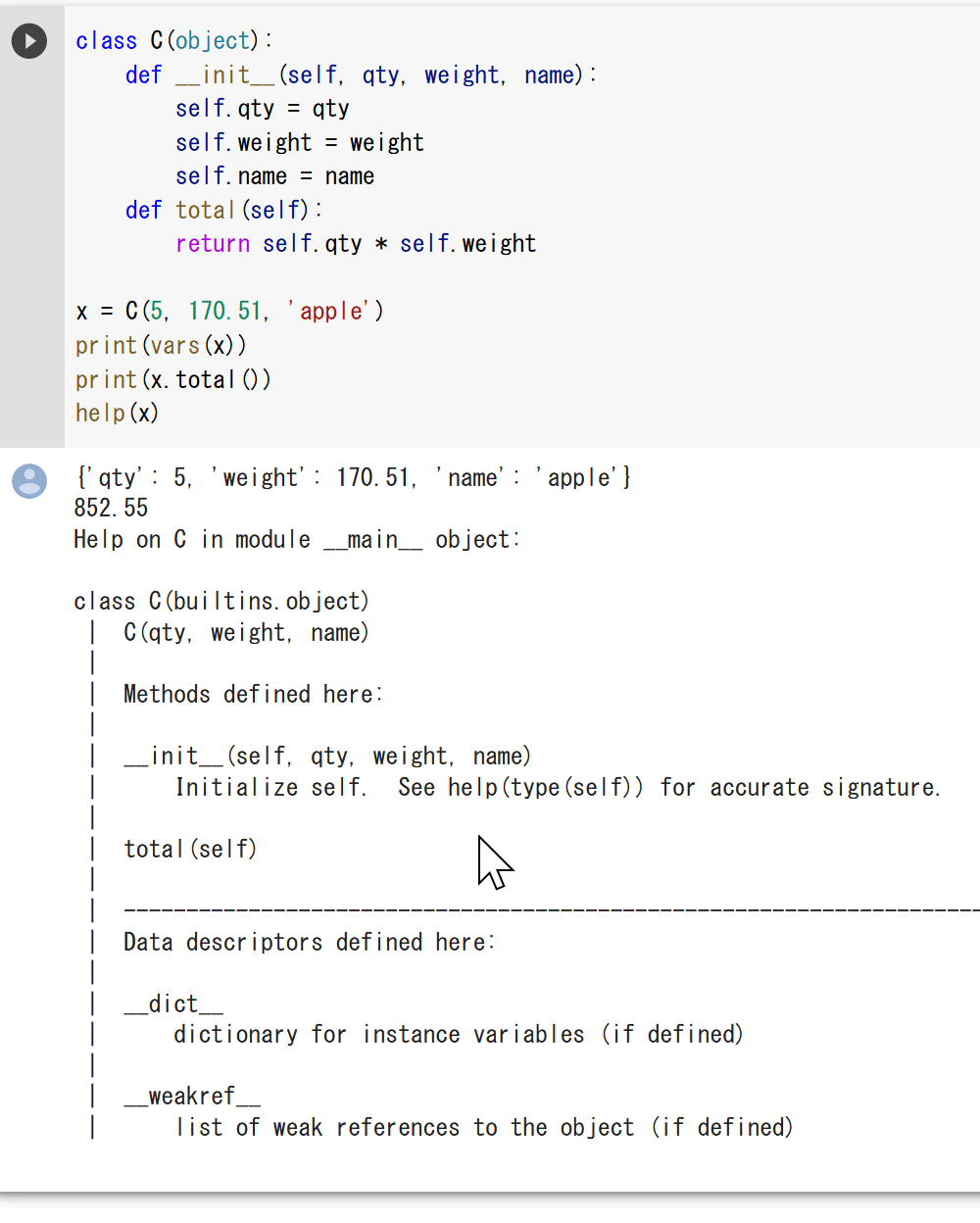
setattr によるメソッドの追加
class C(object):
def __init__(self, qty, weight, name):
self.qty = qty
self.weight = weight
self.name = name
def total(self):
return self.qty * self.weight
x = C(5, 170.51, 'apple')
setattr(C, 'hoge', lambda self: int(self.weight))
print(x.hoge())
help(x)
スーパークラスからの継承
クラス名: C,属性名: qty, weight, name
クラス名: E,属性名: qty, weight, name, price
クラス E は,スーパークラスであるクラス C の属性とメソッドを継承する.
class C(object):
def __init__(self, qty, weight, name):
self.qty = qty
self.weight = weight
self.name = name
def total(self):
return self.qty * self.weight
class E(C):
def __init__(self, qty, weight, name, price):
super(E, self).__init__(qty, weight, name)
self.price = price
def payment(self):
return self.qty * self.price
x2 = E(2, 875.34, 'melon', 500)
print(vars(x2))
print(x2.total())
print(x2.payment())
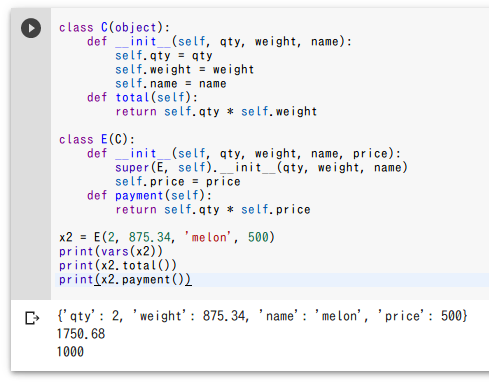
第6章 データ構造と配列処理
リスト
a = [1, 2, 3, 4]
print(a)
type(a)

Python のリストの添字は 0 から開始する.
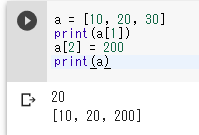
a = [10, 20, 30]
print(a[1])
a[2] = 200
print(a)
numpy 全般
次元数
numpy の1次元の配列の次元数は 1 である(ndim で得る).
1次元の配列の形は (<要素数>,) のように表示される(shape で得る).
import numpy as np
x = np.zeros(10)
print( x.ndim )
print( x.shape )

numpy の2次元の配列の次元数は 2 である.
2次元の配列の形は (<要素数>, <要素数>) のように表示される.
import numpy as np
x = np.zeros((2, 3))
print( x.ndim )
print( x.shape )

データ型と,要素のデータ型
1次元の配列のデータ型は numpy.ndarray である.配列の要素のデータ型は dtype で表示する. 「float64」は浮動小数点数である.
import numpy as np
x = np.zeros(10)
print( type( x ) )
print( x.dtype )

import numpy as np
x = np.zeros((2, 3))
print( type( x ) )
print( x.dtype )

1次元の配列
配列は,データの並びで,それぞれのデータに 0 から始まる番号(添字)が付いている.
1次元の配列の生成
- 0要素
import numpy as np x = np.zeros(10) print(x) print(type(x)) print(x.shape)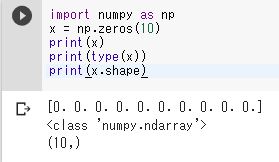
- 1要素
import numpy as np x = np.ones(10) print(x) print(type(x)) print(x.shape)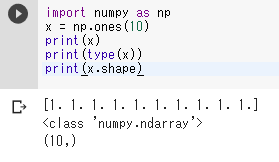
- 乱数.正規分布.平均が0
import numpy as np x = np.random.randn(10) print(x) print(type(x)) print(x.shape)
- 要素指定(要素を並べて書いて配列を作る)
import numpy as np x = np.array([3, 1, 2, 5, 4]) print(x) print(type(x)) print(x.shape)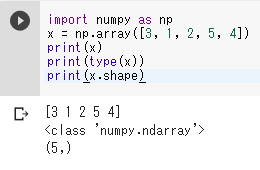
- arange による指定
-5 から開始して、2 ずつ増やし、4 まで
import numpy as np x = np.arange(-5, 4, 2) print(x) print(type(x)) print(x.shape)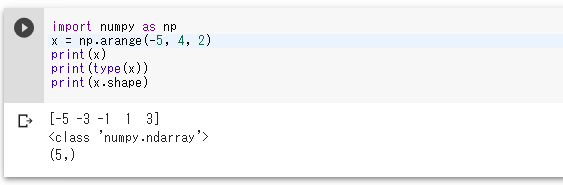
- linspace による指定
-2 から 2 まで、全部で 9 個
import numpy as np x = np.linspace(-2, 2, 9) print(x) print(type(x)) print(x.shape)
合計
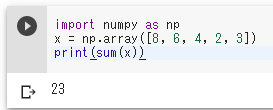
8, 6, 4, 2, 3 というデータについて合計を求める.
import numpy as np
x = np.array([8, 6, 4, 2, 3])
print(sum(x))
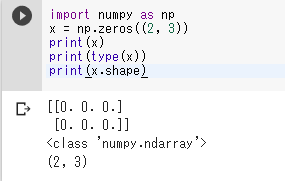
2次元の配列
import numpy as np
x = np.zeros((2, 3))
print(x)
print(type(x))
print(x.shape)
import numpy as np
x = np.ones((2, 3))
print(x)
print(type(x))
print(x.shape)

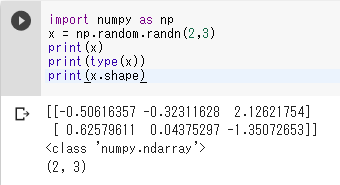
乱数(正規分布)
import numpy as np
x = np.random.randn(2,3)
print(x)
print(type(x))
print(x.shape)
import numpy as np
x = np.random.randn(2,3)
print(x)

2次元の配列の種々の処理
行列の積
時間計測も行う.
import numpy as np
import time
x = np.random.randn(5000, 5000)
y = np.random.randn(5000, 5000)
s = time.time()
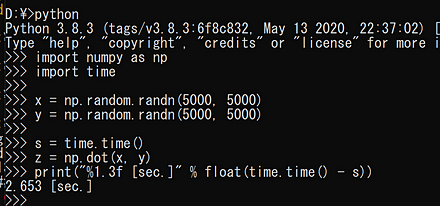
z = np.dot(x, y)
print("%1.3f [sec.]" % float(time.time() - s))
CuPy を用いて行列の積を求める
時間計測も行う.CuPy は GPU を用いた数値計算ライブラリであり,Google Colaboratory の GPU ランタイムなどで利用できる.
- CPU を用いて,行列の積を求める
!pip3 install cupy-cuda12x import numpy as np use_gpu=False if use_gpu: import cupy npcp = cupy else: npcp = np x = npcp.random.random((5000, 5000)) y = npcp.random.random((5000, 5000)) import datetime a = datetime.datetime.now() npcp.dot(x, y) print( (a - datetime.datetime.now()).microseconds )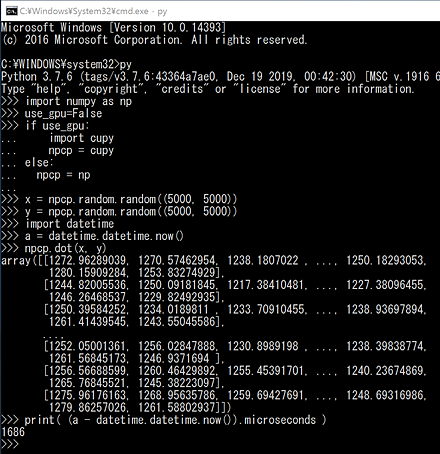
- GPU を用いて,行列の積を求める
上のプログラムと同じで,「use_gpu=False」を「use_gpu=True」に変えただけ.
!pip3 install cupy-cuda12x import numpy as np use_gpu=True if use_gpu: import cupy npcp = cupy else: npcp = np x = npcp.random.random((5000, 5000)) y = npcp.random.random((5000, 5000)) import datetime a = datetime.datetime.now() npcp.dot(x, y) print( (a - datetime.datetime.now()).microseconds )
行列の積,主成分分析,SVD,k-means
- 2000×2000 の乱数行列 X と Y を生成し,それらの行列積を計算する.
- scikit-learn の PCA を使用して,X の主成分分析を行い,2次元に次元削減する.
- NumPy の svd 関数を使用して,X の特異値分解を行う.
- scikit-learn の KMeans を使用して,X に対して10クラスタの k-means クラスタリングを行う.
import time
import numpy
import numpy.linalg
import sklearn.decomposition
import sklearn.cluster
X = numpy.random.rand(2000, 2000)
Y = numpy.random.rand(2000, 2000)
# 行列の積
a = time.time(); Z = numpy.dot(X, Y); print(time.time() - a)
# 主成分分析
pca = sklearn.decomposition.PCA(n_components = 2)
a = time.time(); pca.fit(X); X_pca = pca.transform(X); print(time.time() - a)
# SVD
a = time.time(); U, S, V = numpy.linalg.svd(X); print(time.time() - a)
# k-means
a = time.time()
kmeans_model = sklearn.cluster.KMeans(n_clusters=10, random_state=10).fit(X)
labels = kmeans_model.labels_
print(time.time() - a)
numpy の npz 形式(numpy.ndarray)ファイルの書き出しと読み込み
import numpy as np
np.savez('hoge.npz',a = np.array([1, 2, 3]), b = np.array([1, 2, 3]))
m = np.load('hoge.npz')
print( m['a'] )
print( m['b'] )
2次元配列データの CSV ファイル読み書き
CSV ファイル書き出し.pandas の機能で行う.次のプログラム実行により, ファイル XX.csv と YY.csv ができる.
import numpy as np
import pandas as pd
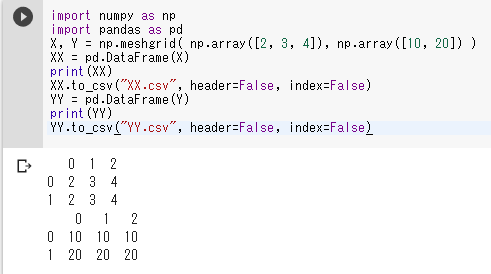
X, Y = np.meshgrid( np.array([2, 3, 4]), np.array([10, 20]) )
XX = pd.DataFrame(X)
print(XX)
XX.to_csv("XX.csv", header=False, index=False)
YY = pd.DataFrame(Y)
print(YY)
YY.to_csv("YY.csv", header=False, index=False)
CSV ファイル読み込み.
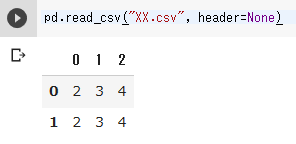
import pandas as pd
pd.read_csv("XX.csv", header=None)
import pandas as pd
pd.read_csv("YY.csv", header=None)

メッシュグリッド
3次元のグラフを作るときや,計算を繰り返すときに便利である.
import numpy as np
X, Y = np.meshgrid( np.array([2, 3, 4]), np.array([10, 20]) )
print(X)
print(type(X))
print(X.shape)
print(Y)
print(type(Y))
print(Y.shape)

配列の次元を増やす
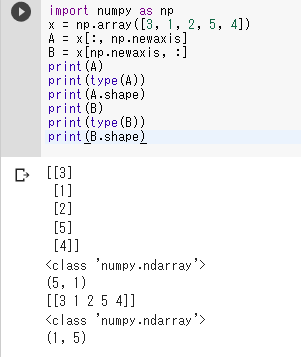
1次元を2次元にする.次のプログラムは,1次元の配列 x を,2次元の配列 A, B に変換する.
import numpy as np
x = np.array([3, 1, 2, 5, 4])
A = x[:, np.newaxis]
B = x[np.newaxis, :]
print(A)
print(type(A))
print(A.shape)
print(B)
print(type(B))
print(B.shape)
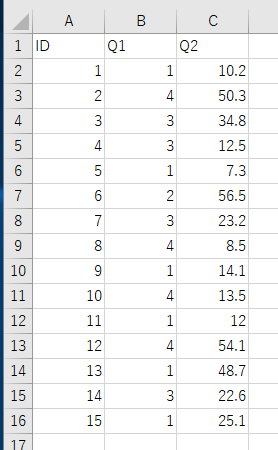
pandas データフレーム
pandas を用いたデータの扱い(CSV ファイル読み込み,散布図,要約統計量,ヒストグラム)を示す.
説明のために,次のようなデータ(CSV ファイル)を使う.ファイル名は enquete.csv
このデータ(CSV ファイル)のダウンロードは,
Windows で管理者権限でコマンドプロンプトを起動し
(手順:Windowsキーまたはスタートメニュー → cmd と入力 → 右クリック → 「管理者として実行」),次のコマンドを実行する.
cd C:\
curl -O https://www.kkaneko.jp/sample/csv/enquete.csv
CSV ファイルの読み込み,確認
- アンケートデータの読み込み
import pandas as pd import seaborn as sns x = pd.read_csv('C:/enquete.csv', encoding='SHIFT-JIS')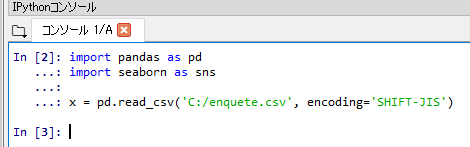
- 読み込んだデータの表示
print(x)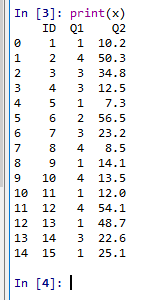
- 読み込んだデータのうち,1列目と2列目の表示
print(x.iloc[:,1]) print(x.iloc[:,2])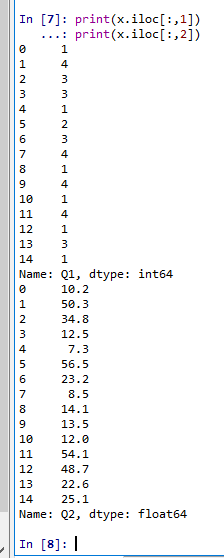
- 読み込んだデータについて,1列目と2列目の散布図
%matplotlib inline import matplotlib.pyplot as plt plt.style.use('ggplot') plt.plot(x.iloc[:,1], x.iloc[:,2], 'ro') plt.show()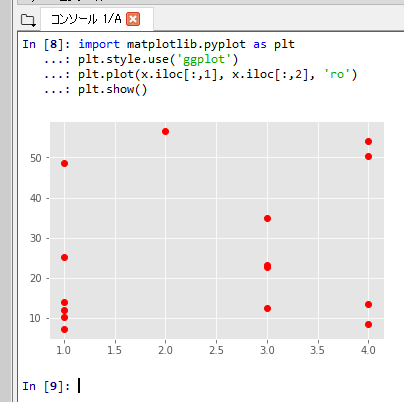
- 各列について,基本的な情報の表示
print(x.head()) print(x.info()) print(x.shape) print(x.ndim) print(x.columns)
- CSV ファイルに書き出し
x.to_csv('hoge.csv', header=True, index=False, encoding='SHIFT-JIS')
各属性の要約統計量(総数,平均,標準偏差,最小,四分位点,中央値,最大)
print(x.describe())

JSON ファイルの書き出しと読み込み
x.to_json('hoge.json') # x は pandas の DataFrame
a = pd.read_json('hoge.json')
pandas.DataFrame のコンストラクタ
- リストから
import pandas as pd pd.DataFrame([1, 2, 3]) - numpy.ndarray から
import numpy as np import pandas as pd pd.DataFrame( np.array([1,2,3]) )import numpy as np import pandas as pd pd.DataFrame( np.array([[1,2,3], [10,20,30], [100,200,300]]) ) - 辞書から
import pandas as pd pd.DataFrame( {'x' : [1, 2, 3], 'y' : [4, 5, 6]} )
ヒストグラムの表示
plt.hist(x.iloc[:,1])
plt.show()
plt.hist(x.iloc[:,2])
plt.show()
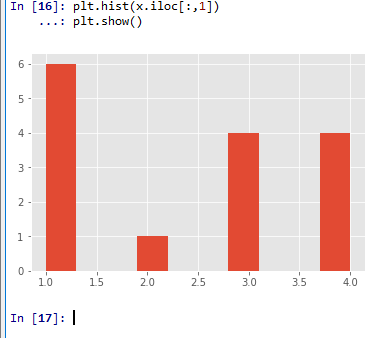
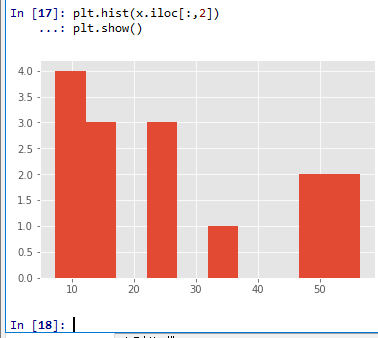
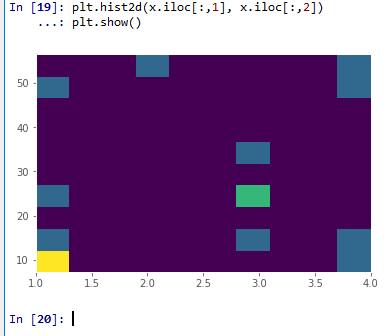
2次元ヒストグラム
plt.hist2d(x.iloc[:,1], x.iloc[:,2])
plt.show()
第7章 データの可視化
IPython.display を用いた画像表示
画像ファイルを読み込んで表示する.
from PIL import Image
Image.open("126.png").show()

IPython.display を使って表示する方法:
from PIL import Image
from IPython.display import display
filename = '127.png'
img = Image.open(filename)
display(img)
Matplotlib を用いたプロット
matplotlib は,オープンソースの Python のプロットライブラリである.
散布図
- x, y からの散布図の作成
%matplotlib inline import matplotlib.pyplot as plt import numpy as np x = [1, 2, 3, 4, 5] y = [2, 4, 1, 3, 5] plt.style.use('ggplot') plt.scatter(x, y)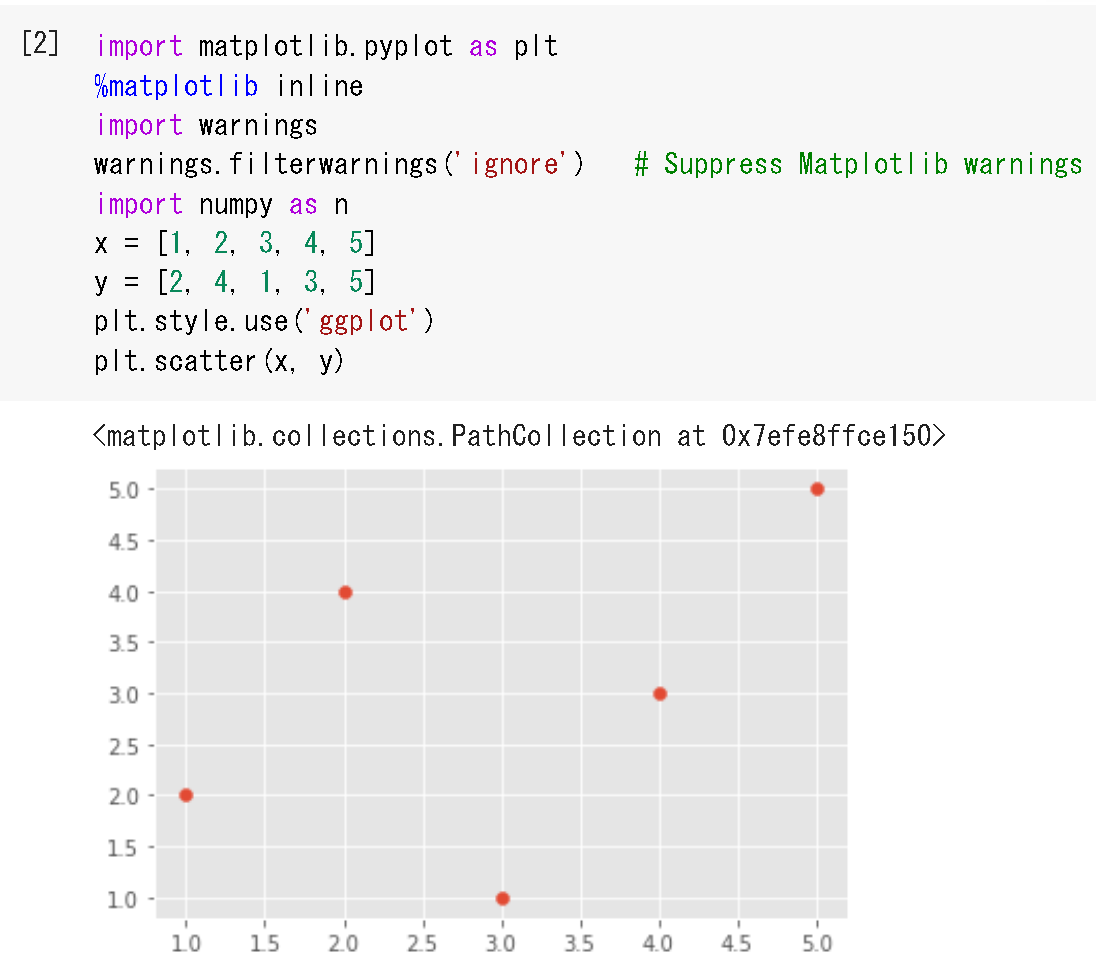
- pandas の2つの属性 x, y からの散布図の作成
import numpy as np import pandas as pd %matplotlib inline import matplotlib.pyplot as plt a = pd.DataFrame( {'x' : [1, 2, 3, 4, 5], 'y' : [2, 4, 1, 3, 5]} ) plt.style.use('ggplot') plt.plot(a['x'], a['y'], 'ro') plt.show()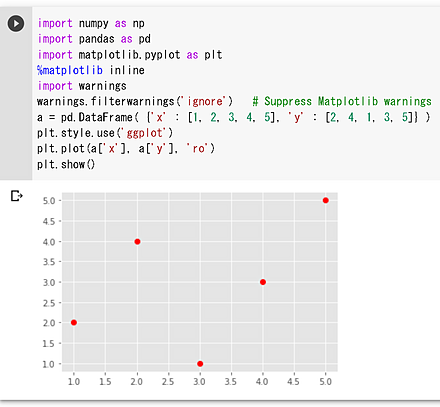
3次元散布図
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
from mpl_toolkits.mplot3d import axes3d
plt.style.use('ggplot')
fig = plt.figure()
ax = fig.add_subplot(111, projection = '3d')
x = [1, 2, 3, 4, 5]
y = [2, 4, 1, 3, 5]
z = [1, 1, 2, 2, 3]
ax.scatter(x, y, z, c='b')
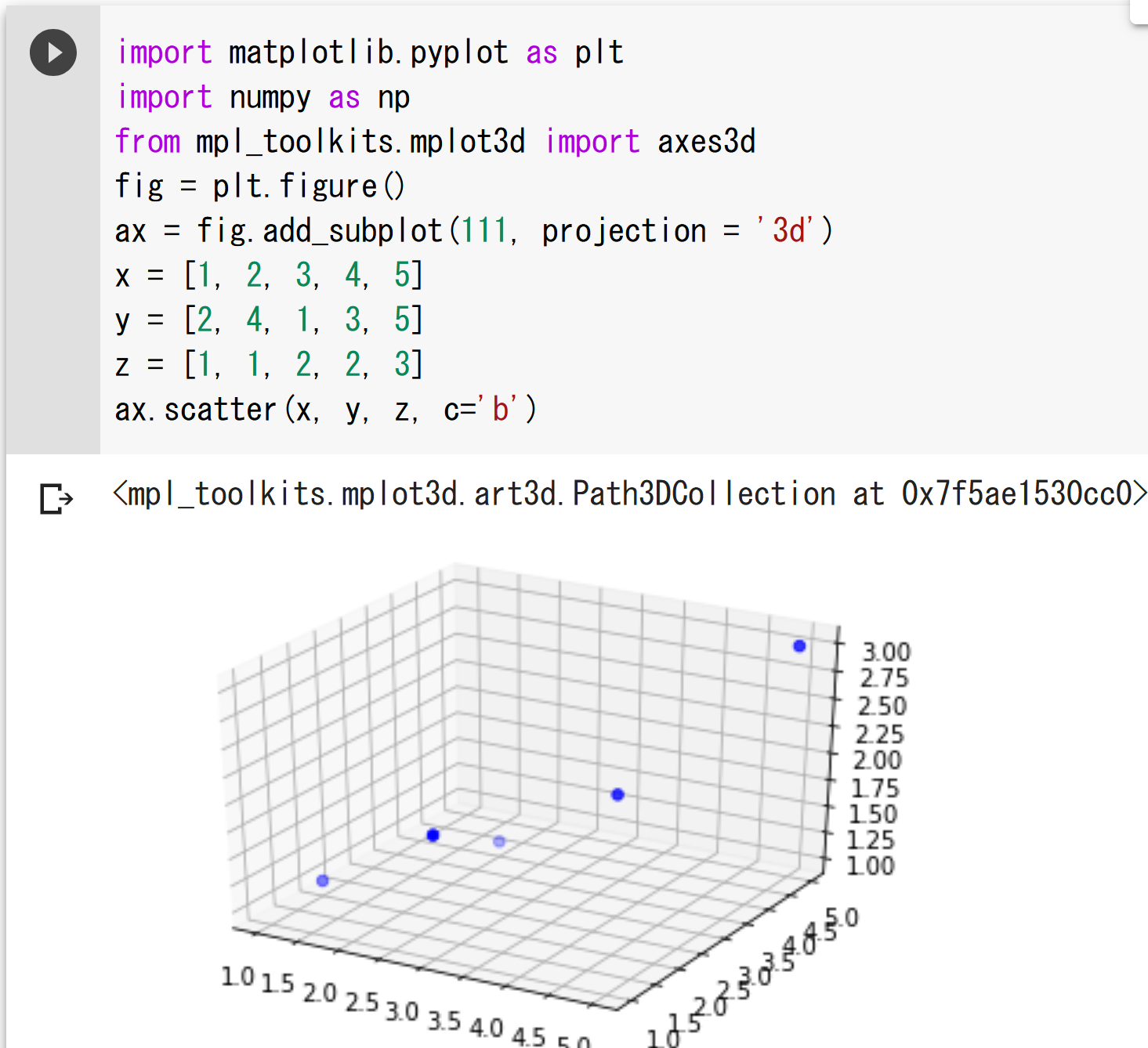
Matplotlib を用いた種々のプロット
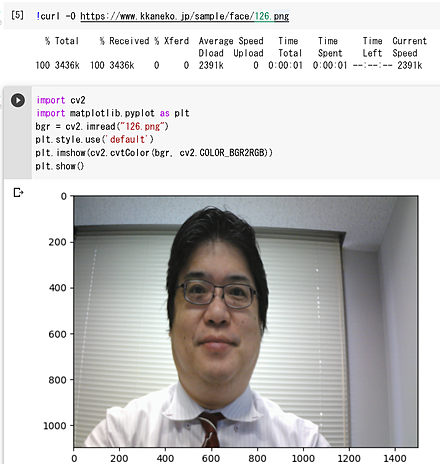
OpenCV 画像の表示
matplotlib を用いて,OpenCV のカラー画像を表示する例:
import cv2
import matplotlib.pyplot as plt
bgr = cv2.imread("126.png")
plt.style.use('default')
plt.imshow(cv2.cvtColor(bgr, cv2.COLOR_BGR2RGB))
plt.show()
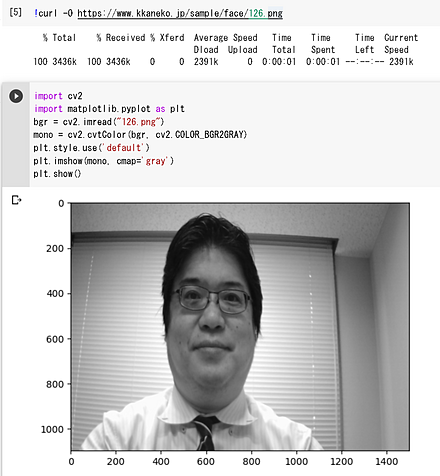
matplotlib を用いて,OpenCV の濃淡画像を表示する例:
import cv2
import matplotlib.pyplot as plt
bgr = cv2.imread("126.png")
mono = cv2.cvtColor(bgr, cv2.COLOR_BGR2GRAY)
plt.style.use('default')
plt.imshow(mono, cmap='gray')
plt.show()
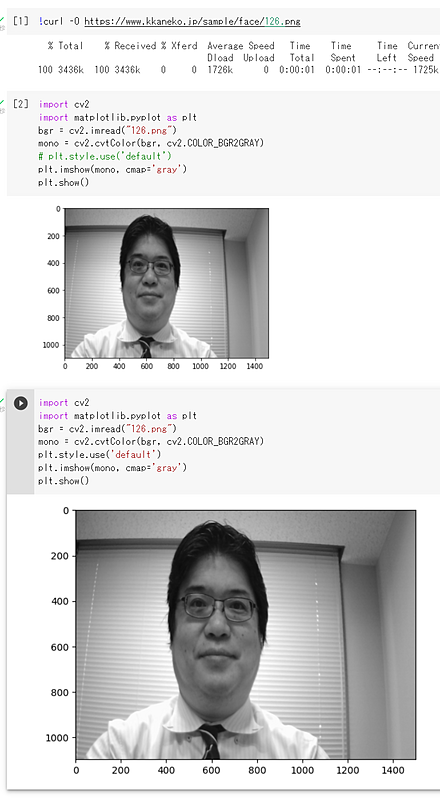
Matplotlib を用いて OpenCV 画像を表示するときに,小さく表示される場合
「plt.style.use('default')」の実行により,Matplotlib での OpenCV 画像の表示が大きくなる.
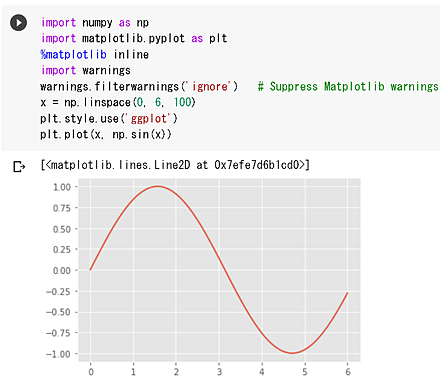
関数のプロット
import numpy as np
%matplotlib inline
import matplotlib.pyplot as plt
x = np.linspace(0, 6, 100)
plt.style.use('ggplot')
plt.plot(x, np.sin(x))
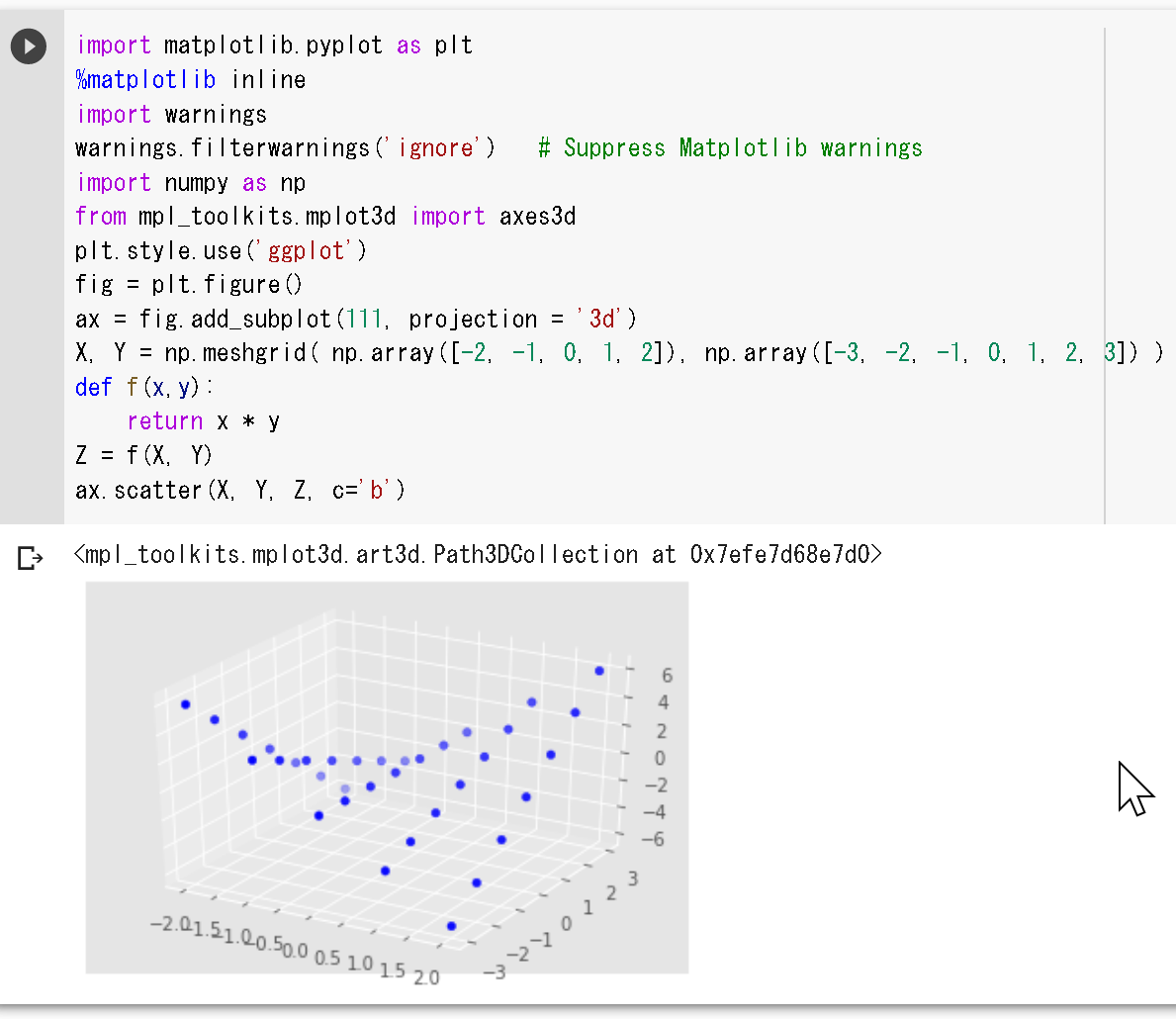
メッシュグリッドと関数の3次元プロット
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
from mpl_toolkits.mplot3d import axes3d
plt.style.use('ggplot')
fig = plt.figure()
ax = fig.add_subplot(111, projection = '3d')
X, Y = np.meshgrid( np.array([-2, -1, 0, 1, 2]), np.array([-3, -2, -1, 0, 1, 2, 3]) )
def f(x,y):
return x * y
Z = f(X, Y)
ax.scatter(X, Y, Z, c='b')
メッシュグリッドと関数の3次元プロット.今度は x1, x2 のソフトマックス関数.
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
from mpl_toolkits.mplot3d import axes3d
plt.style.use('ggplot')
fig = plt.figure()
ax = fig.add_subplot(111, projection = '3d')
X1, X2 = np.meshgrid( np.array([-2, -1, 0, 1, 2]), np.array([-3, -2, -1, 0, 1, 2, 3]) )
def softmax(x):
A = np.exp(x - np.max(x))
return A / A.sum()
def f(x1, x2):
return softmax( np.array([x1, x2]) )
Z = f(X1, X2)
ax.scatter(X1, X2, Z[0], c='b')
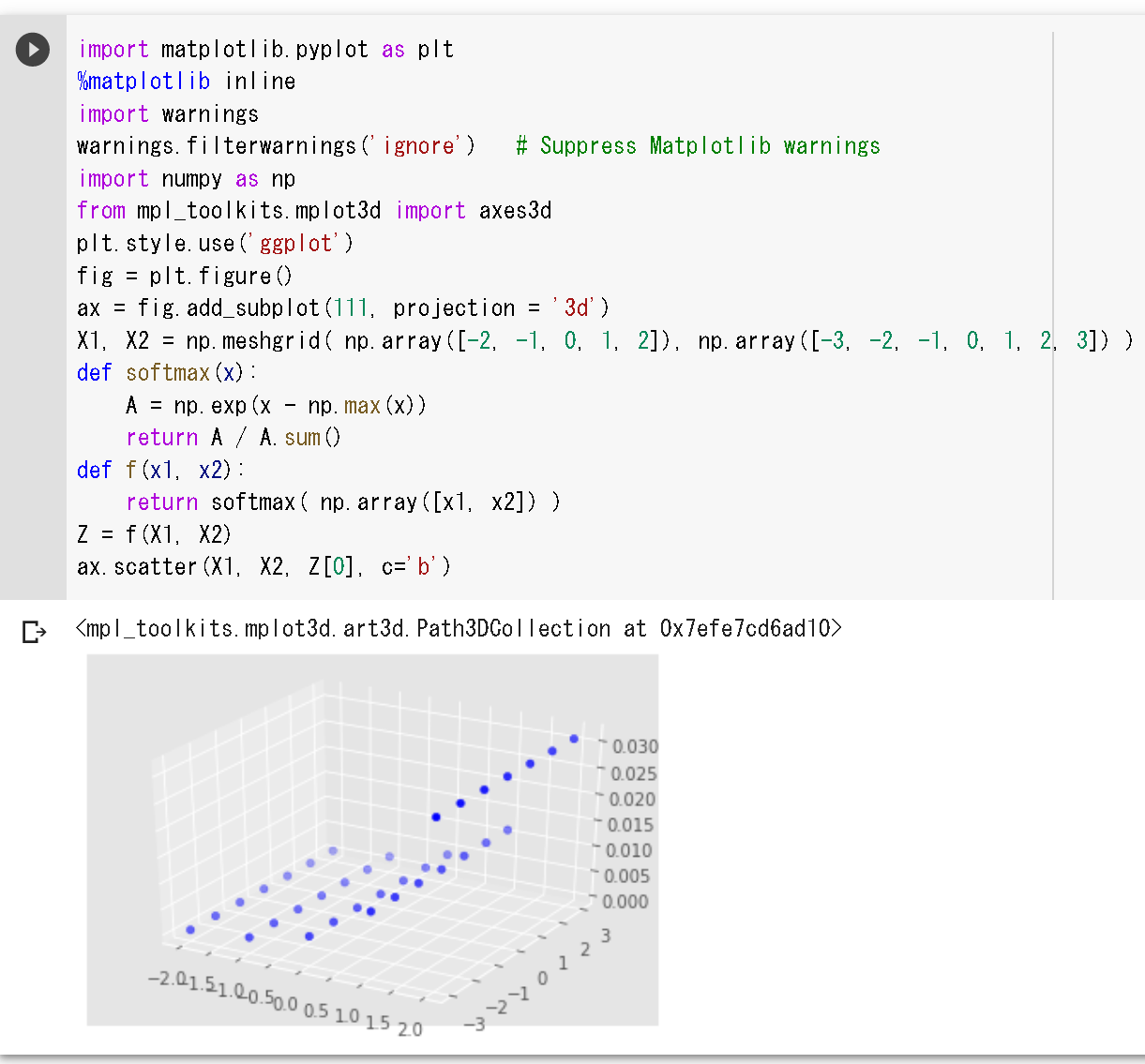
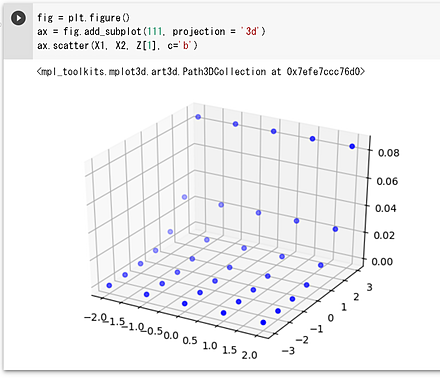
fig = plt.figure()
ax = fig.add_subplot(111, projection = '3d')
ax.scatter(X1, X2, Z[1], c='b')
第8章 機械学習フレームワーク
TensorFlow
TensorFlow は,Google が開発した機械学習フレームワークである.Python,C/C++ 言語から利用可能で,CPU,GPU,TPU 上で動作する.TensorFlow の特徴として「データフローグラフ」がある.これは「データの流れ」を表現するもので,グラフの節点は演算(オペレーション)を,エッジはデータ(テンソル)の流れを表す.TensorFlow を使用することで,音声,画像,テキスト,ビデオなど多様なデータを扱う機械学習アプリケーションの開発ができる.
TensorFlow のプログラム例 - 行列の足し算
import tensorflow as tf
import numpy as np
a = tf.constant( np.reshape([1, 1, 1, 1, 1, 1], (2, 3) ) )
b = tf.constant( np.reshape( [1, 2, 3, 4, 5, 6], (2, 3) ) )
c = tf.add(a, b)
print(c)

Keras
Keras は,TensorFlow を用いたディープラーニング(深層学習)でのモデルの構築と訓練を行うためのソフトウェアである.
用語集
- Keras のモデルは,複数の層が組み合わさったものである.単純に層を積み重ねたもの(シーケンシャル)や,複雑な構成のもの(グラフ)がある.
- Keras の層には,活性化関数,層の重みの種類(カーネル,バイアスなど)を設定できる.
- Keras の層には,全結合,畳み込み(コンボリューション)などの種類がある.
- 学習のために,オプティマイザの設定を行う.
- Keras のモデルの構成やオプティマイザの設定は保存できる.
- 学習の結果は結合の重みになる.結合の重みも保存できる.
ニューラルネットワークのデモサイト: http://playground.tensorflow.org
手順
-
パッケージのインポートなど
from __future__ import absolute_import, division, print_function, unicode_literals # TensorFlow と tf.keras のインポート import tensorflow as tf import tensorflow_datasets as tfds from tensorflow import keras # ヘルパーライブラリのインポート import numpy as np %matplotlib inline import matplotlib.pyplot as plt print(tf.__version__)
- 画像データセット MNIST の準備
x_train: サイズ 28 × 28 の 60000枚の濃淡画像
y_train: 60000枚の濃淡画像それぞれの種類番号(0 から 9 のどれか)
x_test: サイズ 28 × 28 の 10000枚の濃淡画像
y_test: 10000枚の濃淡画像それぞれの種類番号(0 から 9 のどれか)
mnist, metadata = tfds.load( name="mnist", as_supervised=False, with_info=True, batch_size = -1) train, test = mnist['train'], mnist['test'] print(metadata) x_train, y_train = train["image"].numpy().astype("float32") / 255.0, train["label"] x_test, y_test = test["image"].numpy().astype("float32") / 255.0, test["label"]
- 画像データセット MNIST の確認表示
plt.style.use('default') plt.figure(figsize=(10,10)) for i in range(25): plt.subplot(5,5,i+1) plt.xticks([]) plt.yticks([]) plt.grid(False) image, label = train["image"][i], train["label"][i] plt.imshow(image.numpy()[:, :, 0].astype(np.float32), cmap='gray') plt.xlabel(label.numpy()) plt.show()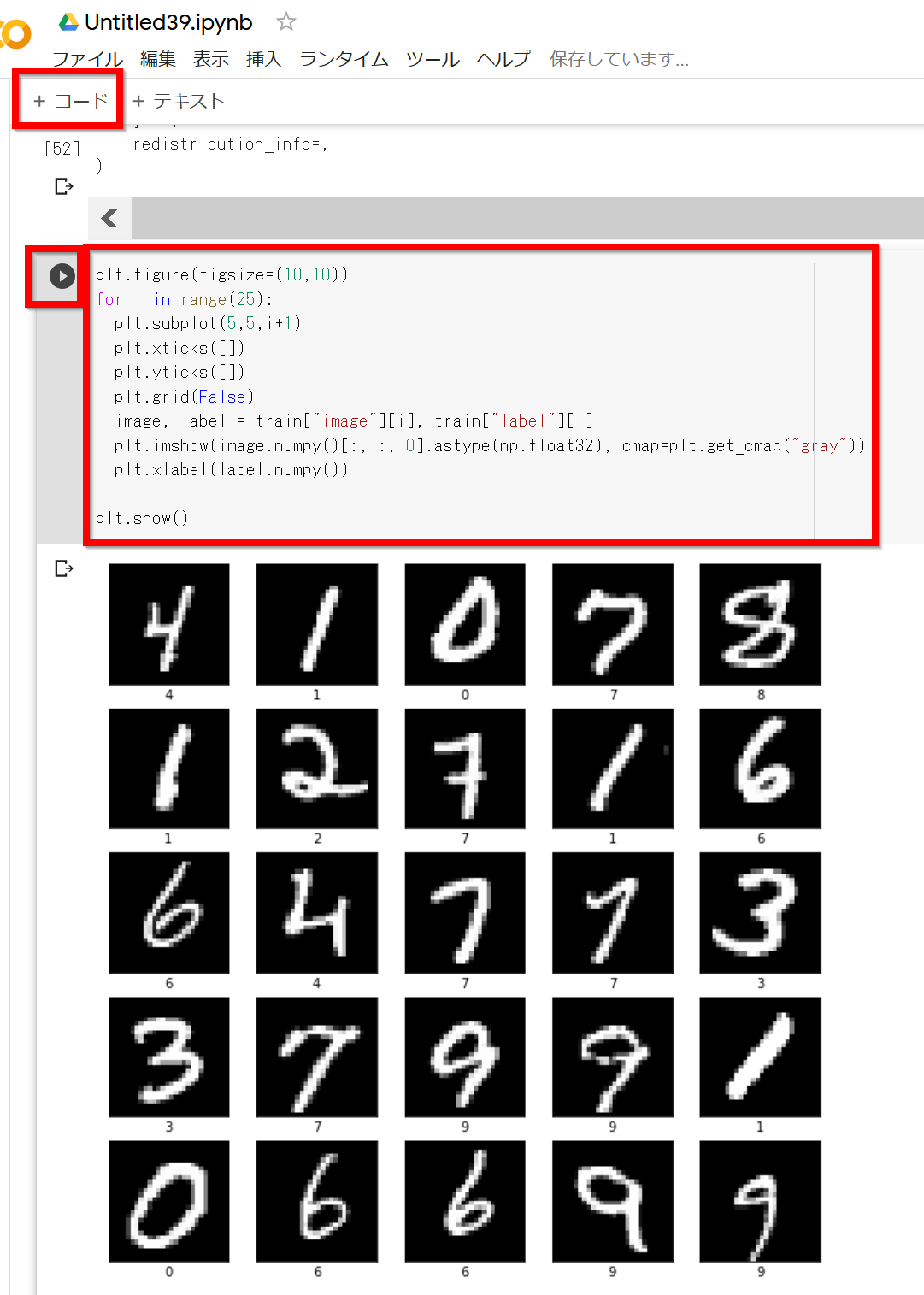
- 「サイズ 28 × 28 の 60000枚の濃淡画像」であることを確認
配列の形: 60000×28×28
次元: 3
print( x_train.shape ) print( x_train.ndim )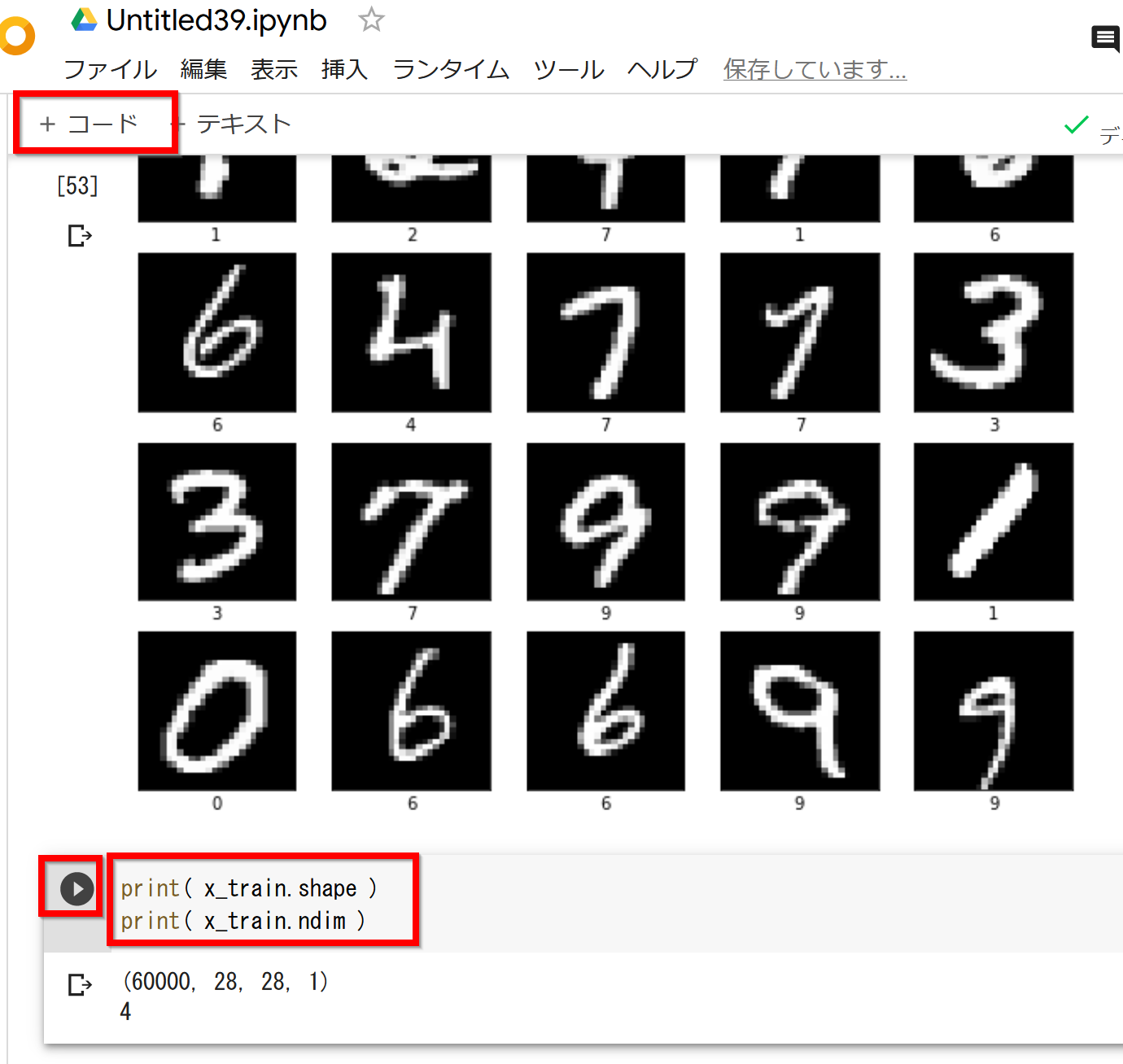
- ディープニューラルネットワークのモデルの作成
m = tf.keras.Sequential() m.add(tf.keras.layers.Flatten(input_shape=(28, 28, 1))) m.add(tf.keras.layers.Dense(units=128, activation='relu')) m.add(tf.keras.layers.Dropout(rate=0.2)) m.add(tf.keras.layers.Dense(units=10, activation='softmax')) m.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.001), loss='sparse_categorical_crossentropy', metrics=['accuracy'])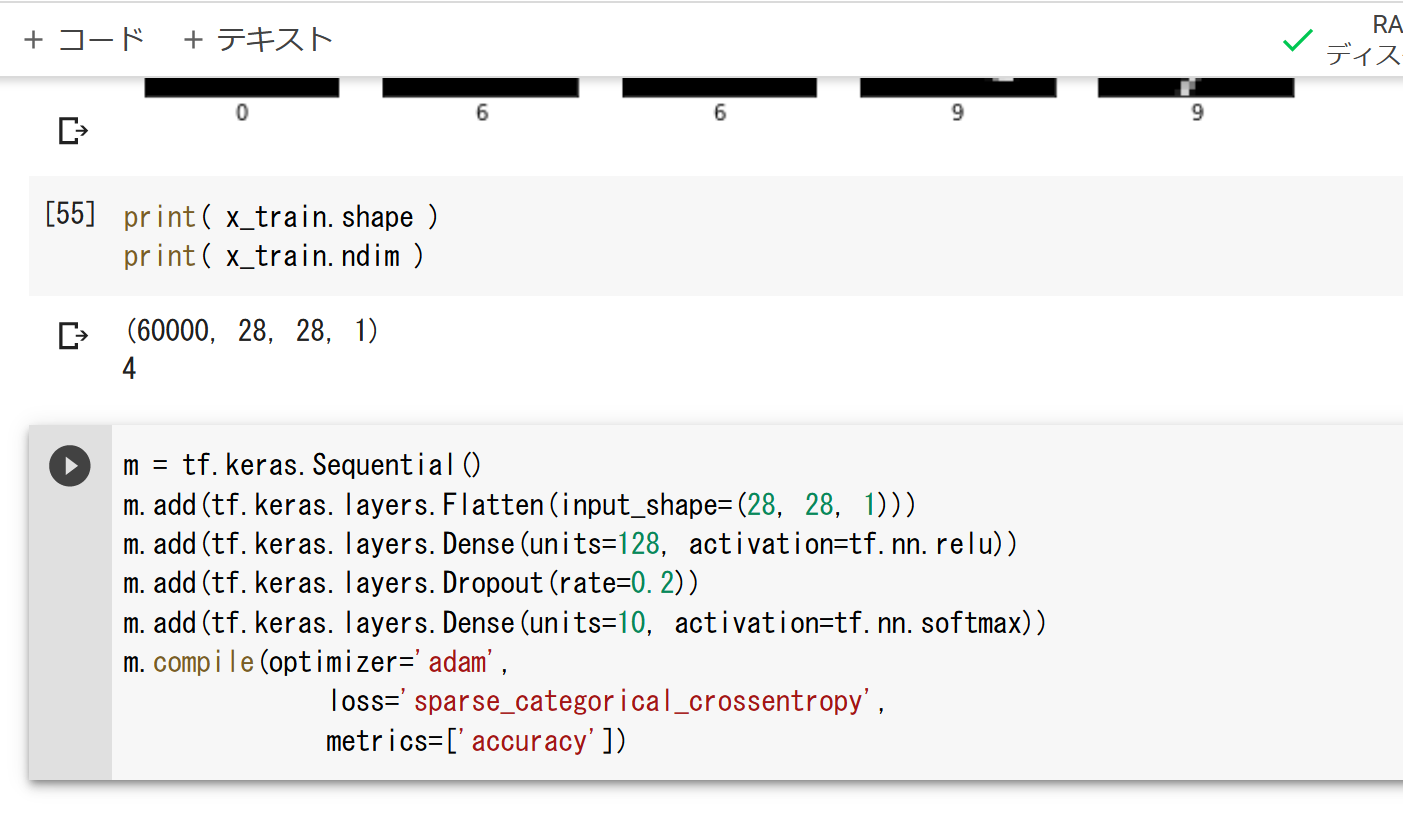
- ニューラルネットワークの確認表示
print(m.summary())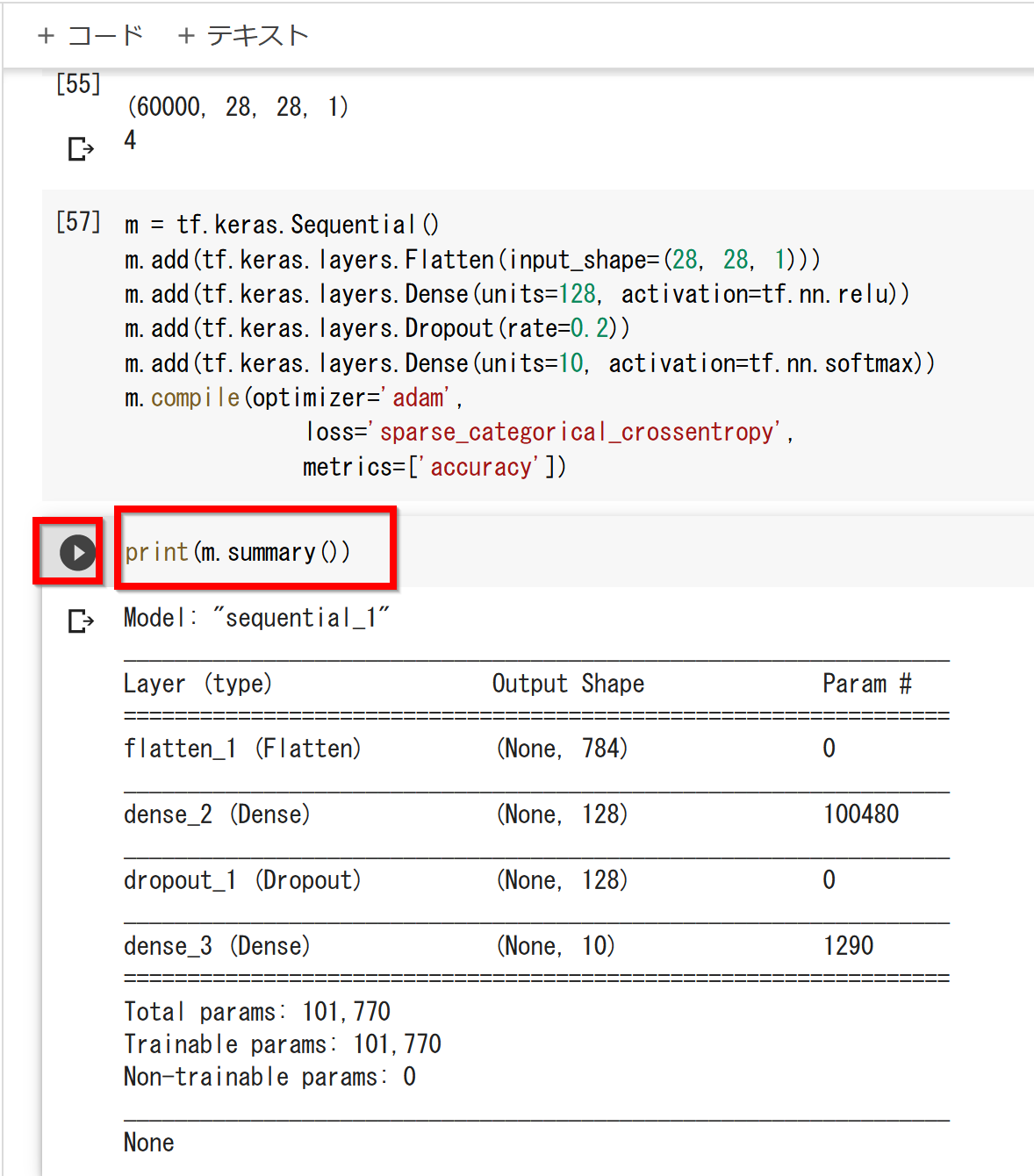
- ニューラルネットワークの学習を行う
history = m.fit(x_train, y_train, epochs=50)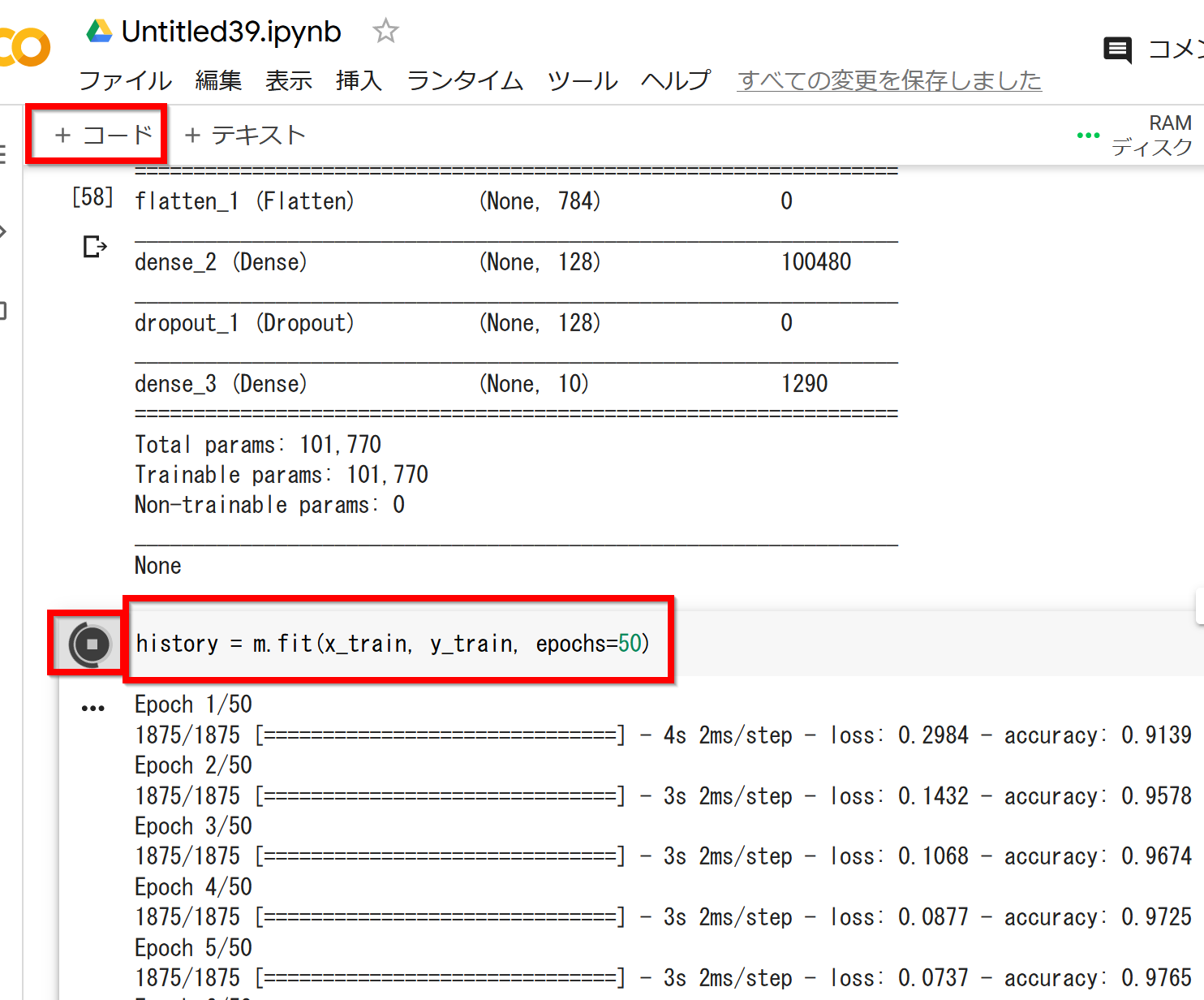
- 検証用データで検証する
print( m.evaluate(x_test, y_test, verbose=2) )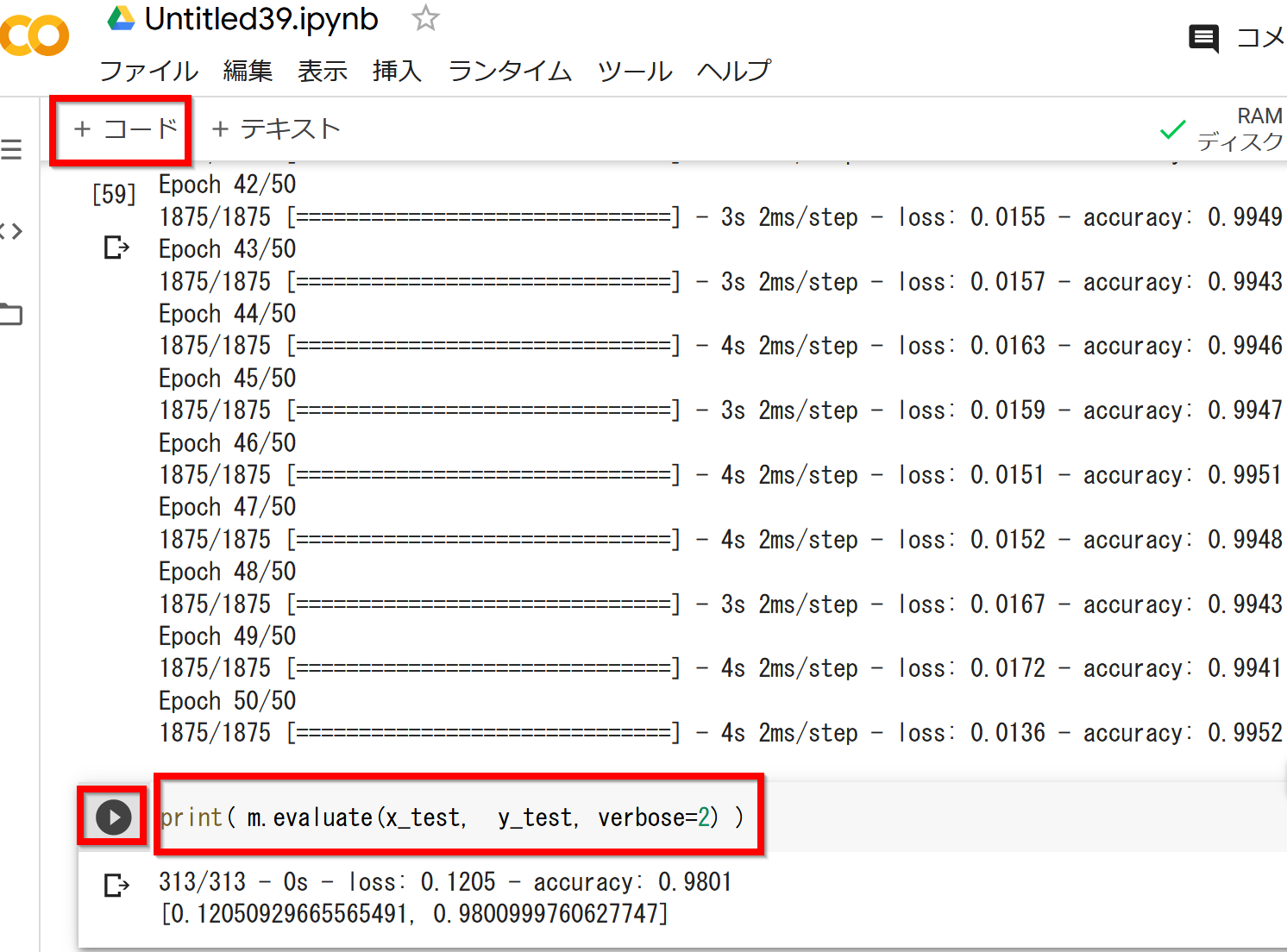
- ニューラルネットワークを使ってみる
predictions = m.predict(x_test) print(predictions[0])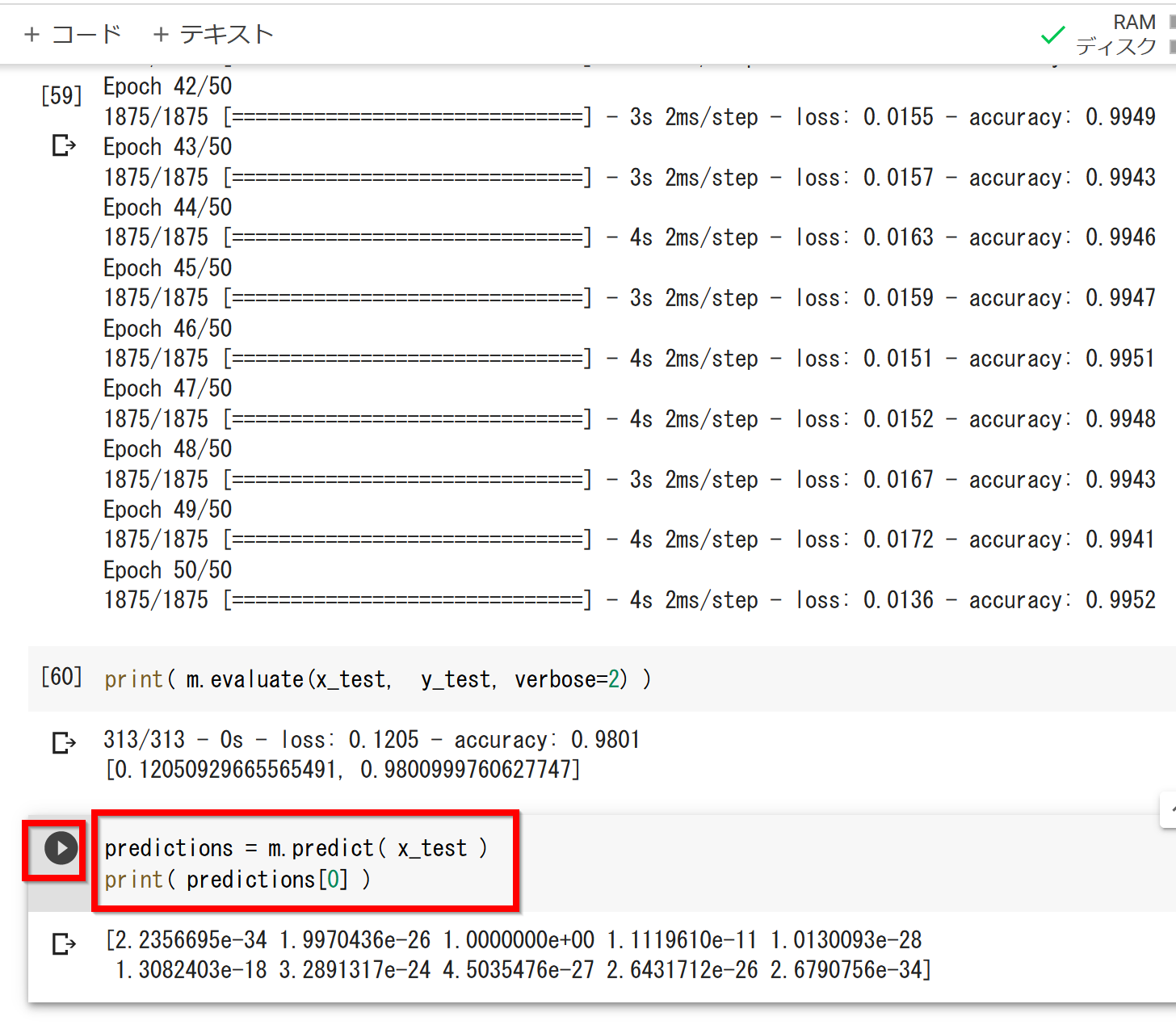
- 正解表示
print(y_test[0])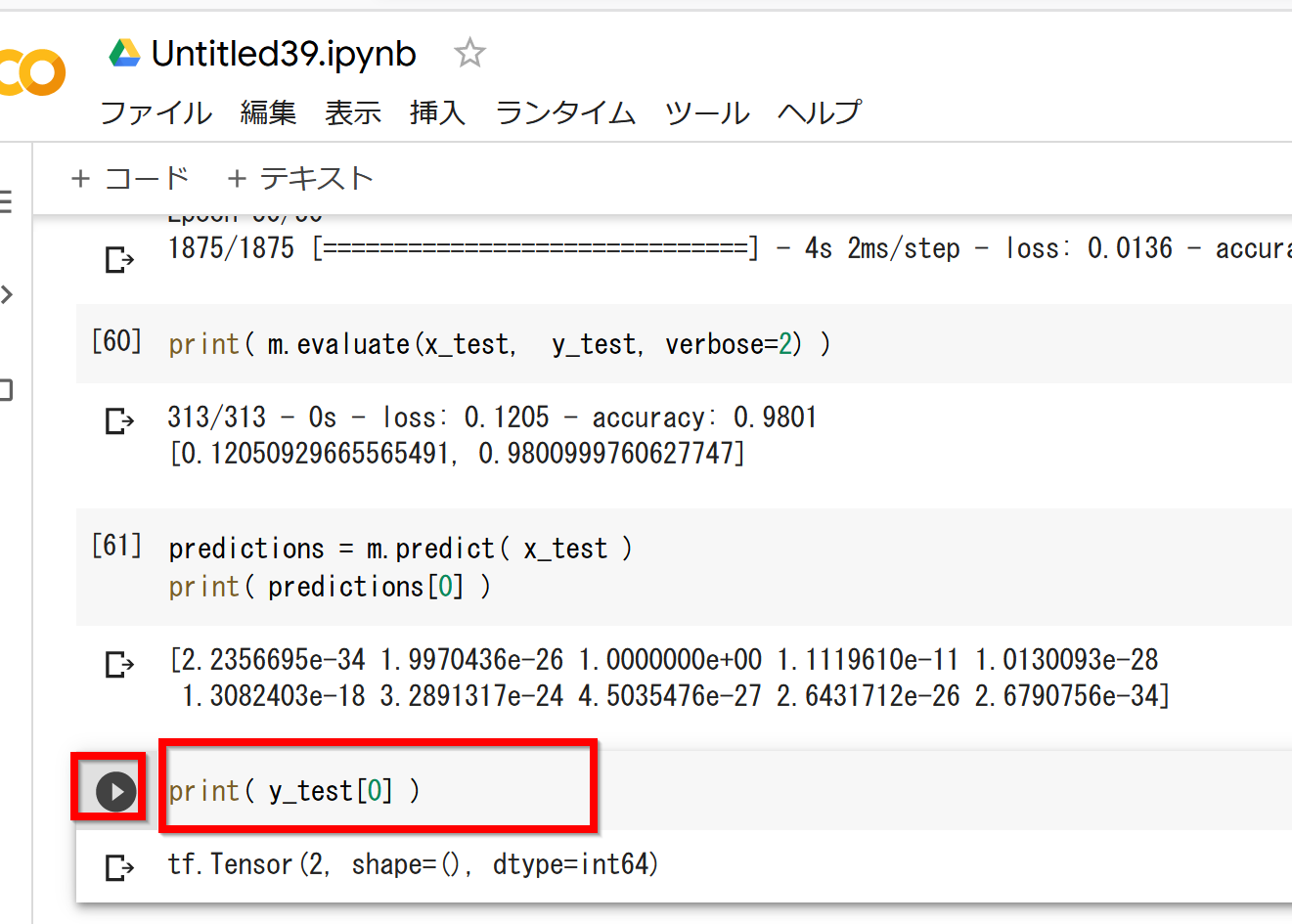
ニューラルネットワークによる画像分類(InceptionV3)
- このページでは次の画像を使う
2071.png のようなファイル名で保存しておく

- 画像のアップロード操作
- ファイルをアップロードするため,「ファイル」を選ぶ
- 「アップロード」を選ぶ
- アップロードしたいファイルを選ぶ

- ファイルをアップロードするため,「ファイル」を選ぶ
- InceptionV3 を使うプログラム.Keras のサイトで公開されているものを少し書き換えて使用する.
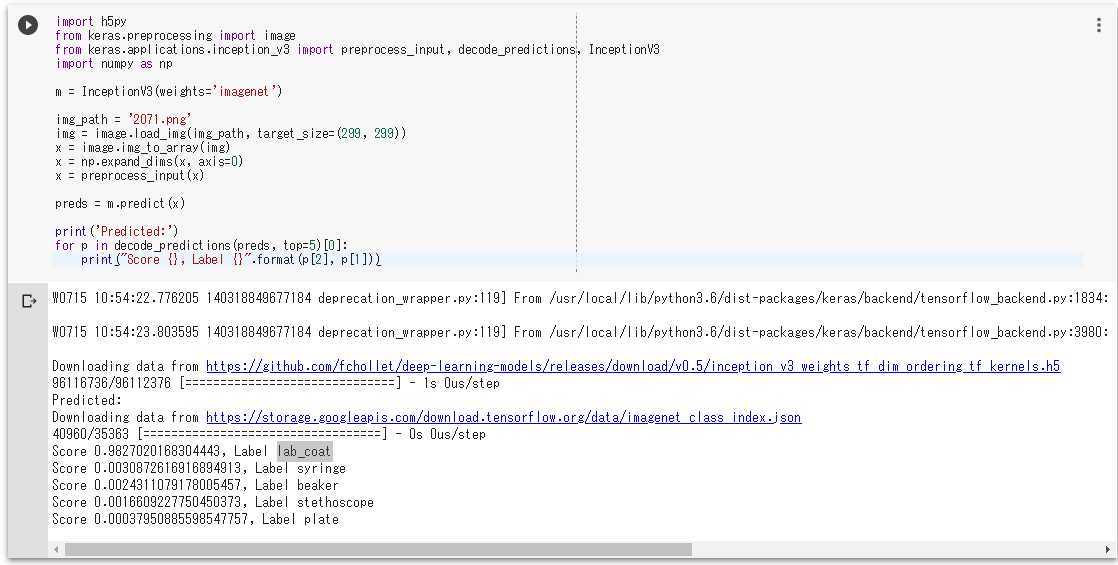
from tensorflow.keras.preprocessing import image from tensorflow.keras.applications.inception_v3 import preprocess_input, decode_predictions, InceptionV3 import numpy as np m = InceptionV3(weights='imagenet') img_path = '2071.png' img = image.load_img(img_path, target_size=(299, 299)) x = image.img_to_array(img) x = np.expand_dims(x, axis=0) x = preprocess_input(x) preds = m.predict(x) print('Predicted:') for p in decode_predictions(preds, top=5)[0]: print("Score {}, Label {}".format(p[2], p[1]))画像分類の結果(lab_coat, syringe, beaker, stethoscope, plate)と,それぞれの確率が表示される.
ConvNeXt による画像分類
ImageNet で学習済みの ConvNeXtBase モデルを用いた画像分類を行う.
- パソコン接続のカメラを使用するので準備しておく.
- 前準備として opencv-python のインストールを行う.
python -m pip install -U --no-user opencv-python opencv-contrib-python - エディタを起動し,次のプログラムを保存する(メモ帳を用いる場合は a.py のようなファイル名で保存して実行).このプログラムは,TensorFlow,ConvNeXtBase モデルを用いて,カメラから取得した画像をリアルタイムで画像分類する:
import tensorflow as tf from tensorflow.keras.applications import ConvNeXtBase import numpy as np import time import cv2 def set_gpu_config(): physical_devices = tf.config.list_physical_devices('GPU') if len(physical_devices) > 0: print("GPU available:", physical_devices) for device in physical_devices: tf.config.experimental.set_memory_growth(device, True) else: print("No GPU found. Running on CPU.") def preprocess_image(img): img = cv2.resize(img, (224, 224)) img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) img = np.expand_dims(img, axis=0) img = tf.keras.applications.convnext.preprocess_input(img) return img def load_model(): return ConvNeXtBase(weights='imagenet') def classify_camera_frames(model): cap = cv2.VideoCapture(0) while cap.isOpened(): ret, frame = cap.read() if not ret: break img = preprocess_image(frame) start_time = time.perf_counter() preds = model.predict(img) end_time = time.perf_counter() prediction_time = end_time - start_time top_pred_index = np.argmax(preds) class_label = tf.keras.applications.convnext.decode_predictions(preds, top=1)[0][0][1] confidence = preds[0][top_pred_index] cv2.putText(frame, f"Class: {class_label}", (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 0.9, (0, 255, 0), 2) cv2.putText(frame, f"Confidence: {confidence:.4f}", (10, 70), cv2.FONT_HERSHEY_SIMPLEX, 0.9, (0, 255, 0), 2) cv2.putText(frame, f"Time: {prediction_time:.4f} seconds", (10, 110), cv2.FONT_HERSHEY_SIMPLEX, 0.9, (0, 255, 0), 2) cv2.imshow("Camera Classification", frame) if cv2.waitKey(1) & 0xFF == ord('q'): break cap.release() cv2.destroyAllWindows() def main(): set_gpu_config() model = load_model() classify_camera_frames(model) if __name__ == '__main__': main()
- Python プログラムの実行を行う.
python a.py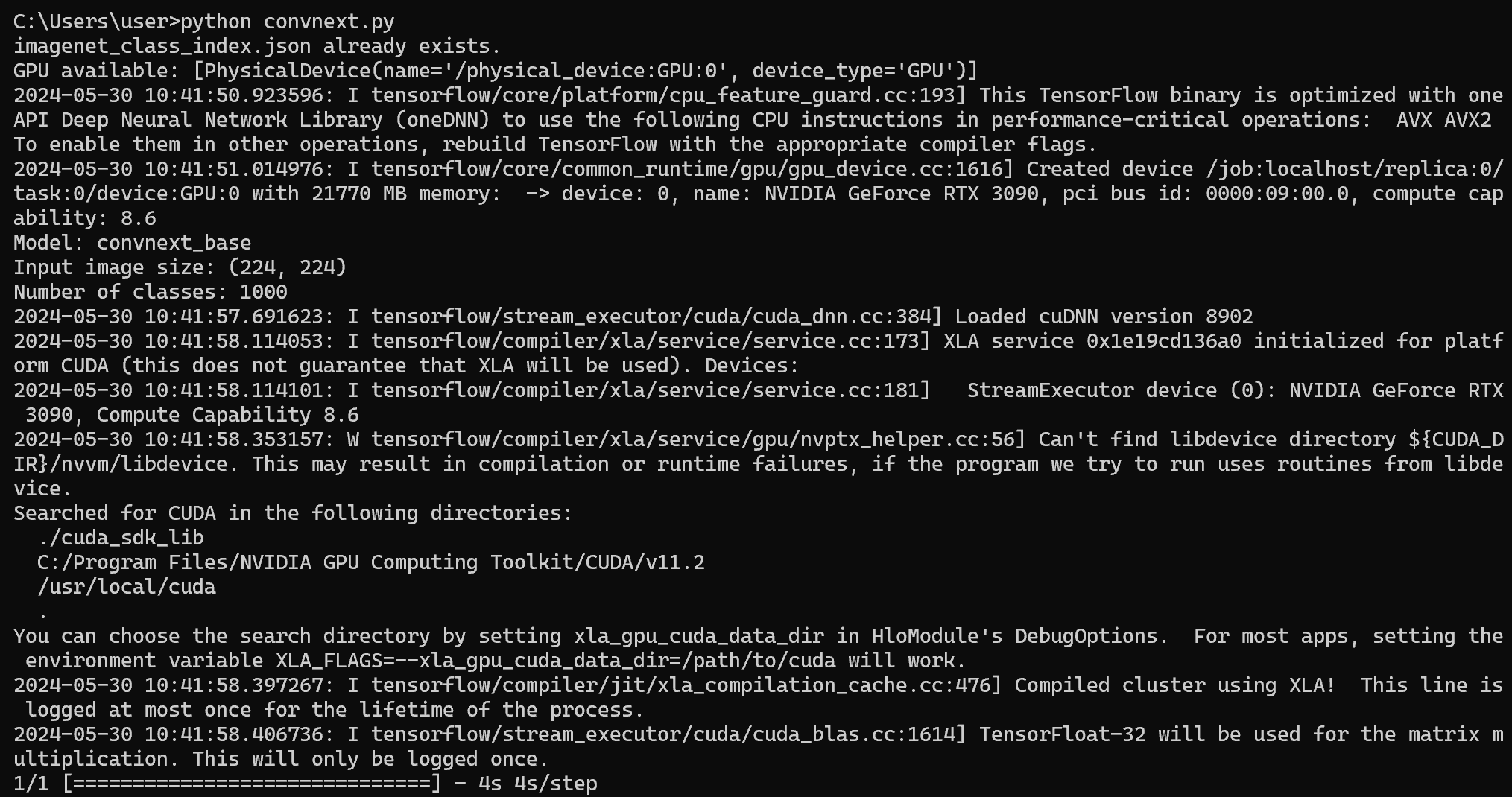
- 結果の確認を行う.終了は q キーである.

第9章 ファイルの選択
ファイルダイアログ(tkinter を使用)
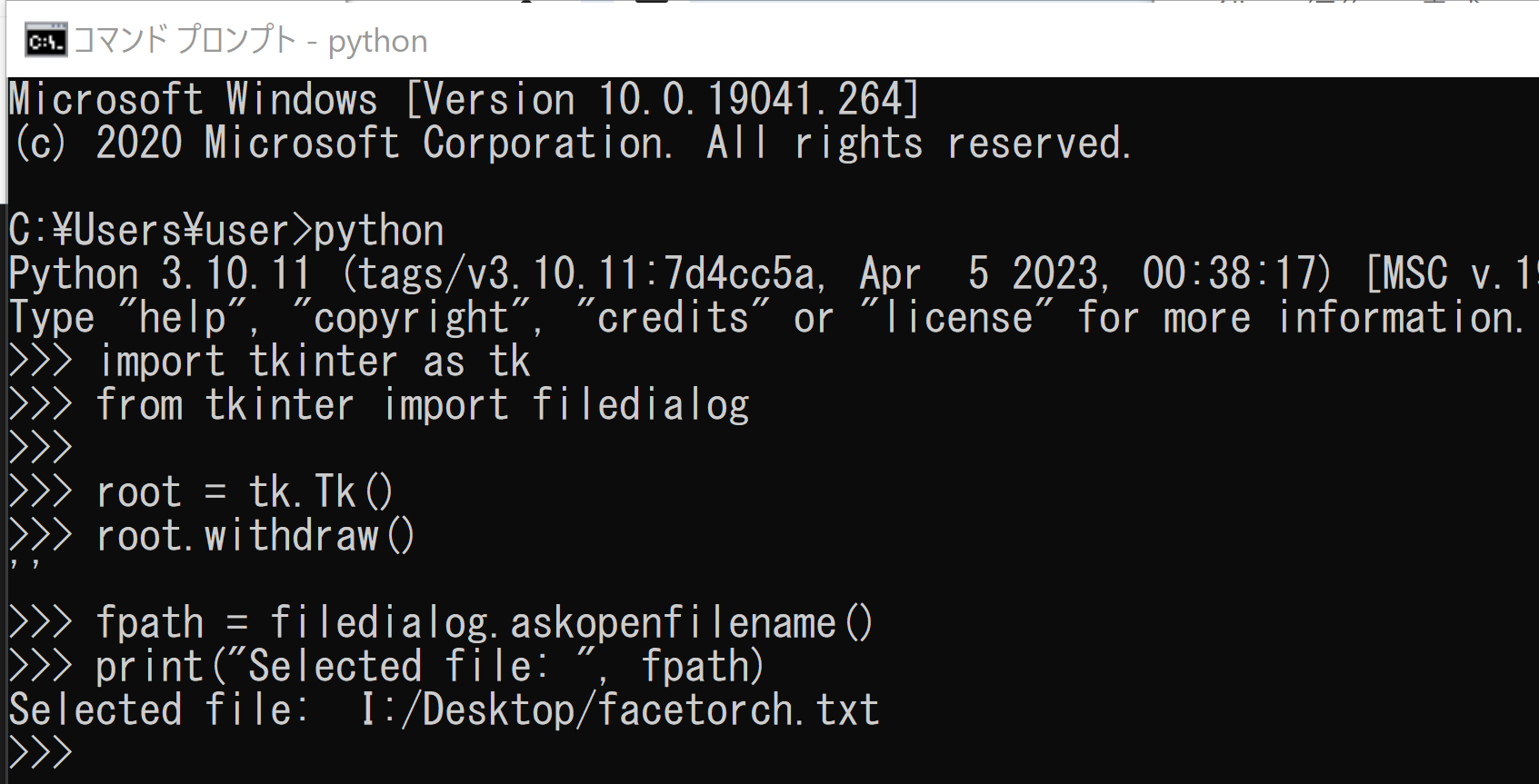
次の Python プログラムは,tkinter の filedialog を使用し,ファイルを選択するためのダイアログを表示する:
import tkinter as tk
from tkinter import filedialog
root = tk.Tk()
root.withdraw()
fpath = filedialog.askopenfilename()
print("Selected file: ", fpath)
次の Python プログラムは,tkinter の filedialog を使用し,複数のファイルを選択するためのダイアログを表示する:
import tkinter as tk
from tkinter import filedialog
root = tk.Tk()
root.withdraw()
fpaths = filedialog.askopenfilenames()
for fpath in root.tk.splitlist(fpaths):
print("Selected file: ", fpath)
ファイルを複数選択(gooey を使用)
「python -m pip install -U --no-user gooey」でインストールを行っておく.
from gooey import Gooey, GooeyParser
@Gooey(required_cols=0)
def main():
parser = GooeyParser(description='Process something.')
parser.add_argument('-i', '--infiles', nargs='*', metavar='InFiles', help='Choose one file or more-than-on files!', widget="MultiFileChooser")
parser.add_argument('-n', '--name', metavar='Name', help='Enter some text!')
parser.add_argument('-f', '--foo', metavar='Flag 1', action='store_true', help='I turn things on and off')
parser.add_argument('-b', '--bar', metavar='Flag 2', action='store_true', help='I turn things on and off')
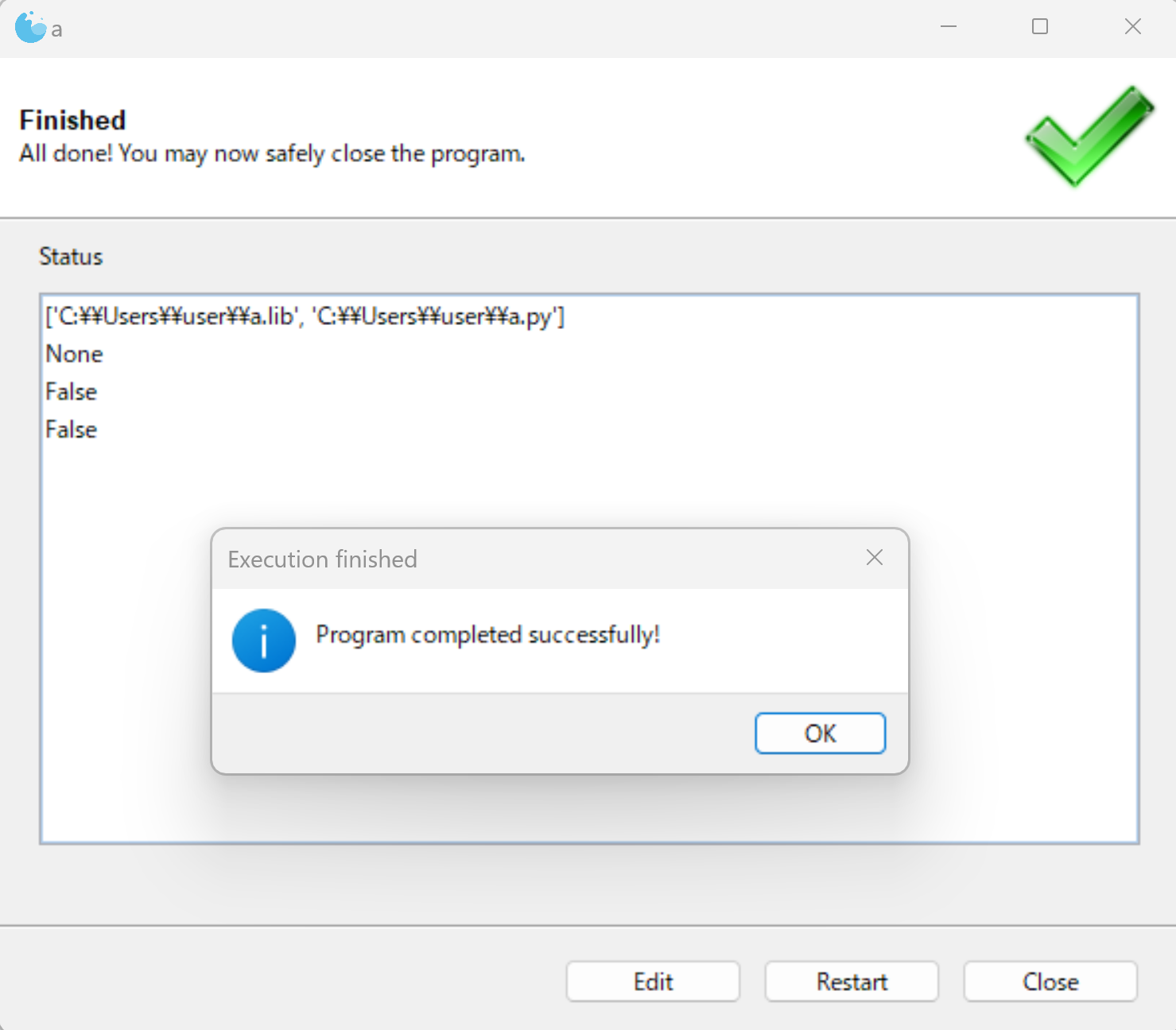
a = parser.parse_args()
print(a.infiles)
print(a.name)
print(a.foo)
print(a.bar)
if __name__ == '__main__':
main()
第10章 画像ファイルの表示,画像ファイルの画像のサイズの取得
PIL の show を使用して画像ファイルを表示する:
from PIL import Image
Image.open('1.png').show()
Matplotlib を使用して画像ファイルを表示する:
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
img = mpimg.imread('1.png')
plt.imshow(img)
plt.show()
PIL を使用して画像のサイズを取得する:
from PIL import Image
image_path = '1.png'
width, height = Image.open(image_path).size
print(width, height)
第11章 ply ファイルの表示
次のプログラムは,ファイルダイアログにより ply ファイルを1つ選択ののち表示を行う.マウスの左クリックとマウス移動により回転でき,マウスホイールにより前後移動する.
import pygame
from pygame.locals import *
from OpenGL.GL import *
from OpenGL.GLUT import *
from OpenGL.GLU import *
from plyfile import PlyData, PlyElement
# PLYファイルを読み込む
import tkinter as tk
from tkinter import filedialog
root = tk.Tk()
root.withdraw()
fpath = filedialog.askopenfilename()
plydata = PlyData.read(fpath)
vertex_data = plydata['vertex'].data
face_data = plydata['face'].data
# 頂点と面をリストとして取得
vertices = [list(elem) for elem in vertex_data]
faces = [face[0] for face in face_data]
# PygameとOpenGLを初期化
pygame.init()
display = (800, 600)
pygame.display.set_mode(display, DOUBLEBUF | OPENGL)
gluPerspective(45, (display[0] / display[1]), 0.1, 50.0)
glTranslatef(0.0, 0.0, -5)
# マウス操作のための変数
rotation_enabled = False
rotation_start = (0, 0)
zoom = 0.0
# メインループ
while True:
for event in pygame.event.get():
if event.type == pygame.QUIT:
pygame.quit()
quit()
elif event.type == pygame.MOUSEBUTTONDOWN:
if event.button == 1: # 左クリック
rotation_enabled = True
rotation_start = pygame.mouse.get_pos()
elif event.button == 4: # ホイール回転(上方向)
zoom = 1
elif event.button == 5: # ホイール回転(下方向)
zoom = -1
elif event.type == pygame.MOUSEBUTTONUP:
if event.button == 1: # 左クリック解除
rotation_enabled = False
elif event.type == pygame.MOUSEMOTION:
if rotation_enabled:
dx = event.pos[0] - rotation_start[0]
dy = event.pos[1] - rotation_start[1]
glRotatef(dx, 0, 1, 0) # y軸周りに回転
glRotatef(dy, 1, 0, 0) # x軸周りに回転
rotation_start = event.pos
glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT)
# 視点の移動範囲を制限
max_zoom = 5.0
min_zoom = -5.0
zoom = max(min_zoom, min(max_zoom, zoom))
glTranslatef(0.0, 0.0, -zoom)
zoom = 0
glBegin(GL_TRIANGLES)
for face in faces:
for vertex_i in face:
glVertex3fv(vertices[vertex_i][:3])
glEnd()
pygame.display.flip()
pygame.time.wait(10)