OpenAI Gym, Gym Atari のインストール
OpenAI は、強化学習のツールキット.
このページでは,インストール手順を示す.
謝辞:OpenAI Gym の作者に感謝します
前準備
Python 3.12 のインストール(Windows 上) [クリックして展開]
以下のいずれかの方法で Python 3.12 をインストールする。Python がインストール済みの場合、この手順は不要である。
方法1:winget によるインストール
管理者権限のコマンドプロンプトで以下を実行する。管理者権限のコマンドプロンプトを起動するには、Windows キーまたはスタートメニューから「cmd」と入力し、表示された「コマンドプロンプト」を右クリックして「管理者として実行」を選択する。
winget install --id Python.Python.3.12 -e --scope machine --silent --accept-source-agreements --accept-package-agreements --override "/quiet InstallAllUsers=1 PrependPath=1 Include_test=0 Include_pip=1 Include_launcher=1 InstallLauncherAllUsers=1 TargetDir=\"C:\Program Files\Python312\""
powershell -Command "$p='C:\Program Files\Python312'; $s=\"$p\Scripts\"; $m=[Environment]::GetEnvironmentVariable('Path','Machine'); if($m -notlike \"*$s*\") { [Environment]::SetEnvironmentVariable('Path', \"$p;$s;$m\", 'Machine') }"--scope machine を指定することで、システム全体(全ユーザー向け)にインストールされる。このオプションの実行には管理者権限が必要である。インストール完了後、コマンドプロンプトを再起動すると PATH が自動的に設定される。
方法2:インストーラーによるインストール
- Python 公式サイト(https://www.python.org/downloads/)にアクセスし、「Download Python 3.x.x」ボタンから Windows 用インストーラーをダウンロードする。
- ダウンロードしたインストーラーを実行する。
- 初期画面の下部に表示される「Add python.exe to PATH」に必ずチェックを入れてから「Customize installation」を選択する。このチェックを入れ忘れると、コマンドプロンプトから
pythonコマンドを実行できない。 - 「Install Python 3.xx for all users」にチェックを入れ、「Install」をクリックする。
インストールの確認
コマンドプロンプトで以下を実行する。
python --versionバージョン番号(例:Python 3.12.x)が表示されればインストール成功である。「'python' は、内部コマンドまたは外部コマンドとして認識されていません。」と表示される場合は、インストールが正常に完了していない。
Git のインストール(Windows 上)
Gitは,バージョン管理システム.ソースコードの管理や複数人での共同に役立つ.
【サイト内の関連ページ】 Windows での Git のインストール: 別ページ »で説明
【関連する外部ページ】 Git の公式ページ: https://git-scm.com/
OpenAI Gym, Gym Atari のインストール
- Window でコマンドプロンプトを実行
- OpenAI Gym のダウンロード
ダウンロードに,gitを用いる.
mkdir c:\pytools cd c:\pytools rmdir /s /q gym git clone https://github.com/openai/gym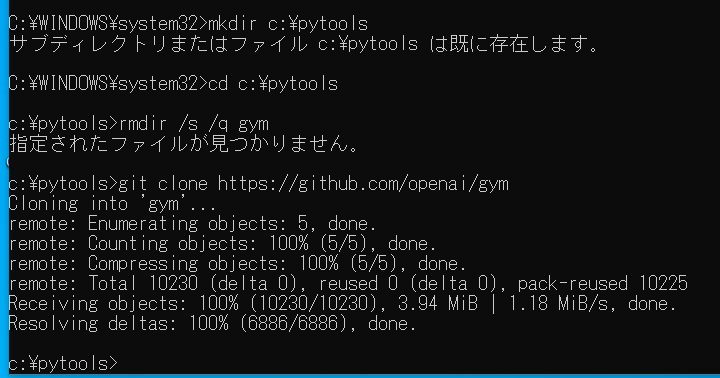
- OpenAI Gym のインストール
* 「pip install ...」は,Pythonのライブラリをインストールするための操作. Ubuntu でシステム の python3 を使っているときは,「pip install ...」の代わりに「sudo pip3 install ...」のように操作すること.
cd c:\pytools cd gym pip install -e .
- OpenAI Gym のバージョン確認
バージョン番号が表示されれば OK.下の図とは違うバージョンが表示されることがある.
python -c "import gym; print( gym.__version__ )"
- Gym Atari のインストール
pip install gym[atari]
試しに動かしてみる
python
SpaceInvaders-v0
import gym
env = gym.make('SpaceInvaders-v0')
observation = env.reset()
for i_episode in range(20):
observation = env.reset()
for t in range(100):
env.render()
print(observation)
action = env.action_space.sample()
observation, reward, done, info = env.step(action)
if done:
print("Episode finished after {} timesteps".format(t+1))
break
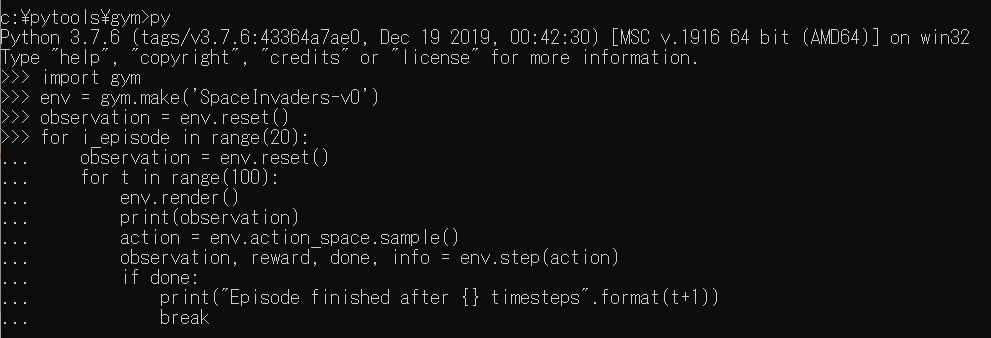
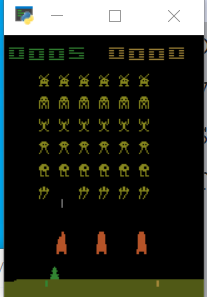
CartPole-v0
import gym
env = gym.make('CartPole-v0')
observation = env.reset()
for i_episode in range(20):
observation = env.reset()
for t in range(100):
env.render()
print(observation)
action = env.action_space.sample()
observation, reward, done, info = env.step(action)
if done:
print("Episode finished after {} timesteps".format(t+1))
break
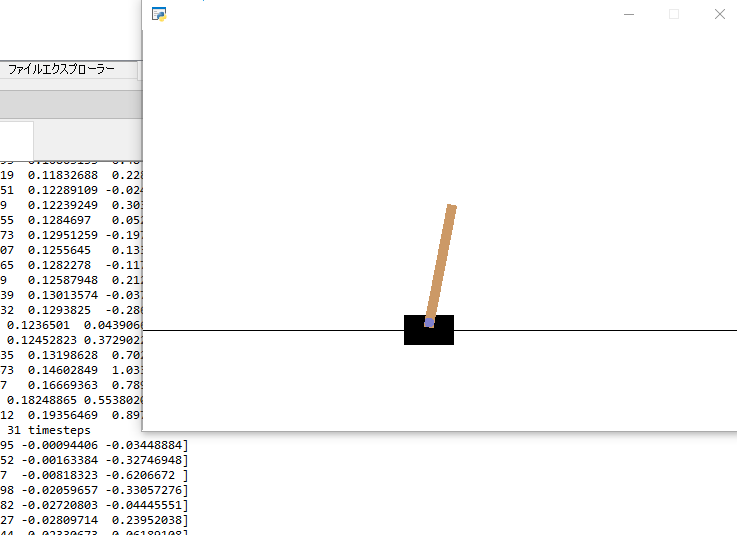
Copy-v0
import gym
env = gym.make('Copy-v0')
observation = env.reset()
for i_episode in range(20):
observation = env.reset()
for t in range(100):
env.render()
print(observation)
action = env.action_space.sample() # your agent here (this takes random actions)
observation, reward, done, info = env.step(action)
if done:
print("Episode finished after {} timesteps".format(t+1))
break

toy_text
import gym
env = gym.make('FrozenLake-v0')
observation = env.reset()
for i_episode in range(20):
observation = env.reset()
for t in range(100):
env.render()
print(observation)
action = env.action_space.sample() # your agent here (this takes random actions)
observation, reward, done, info = env.step(action)
if done:
print("Episode finished after {} timesteps".format(t+1))
break
