CSV ファイルの読み込み,散布図と近似線,スケールの信頼性(R システムを利用)
前準備
R システムのインストール
【関連する外部ページ】
R システムの CRAN の URL: https://cran.r-project.org/
CSVファイルを読み込み,データフレームに格納
- (前準備) 使用する CSV ファイルの作成
Book1.csv をダウンロード (参考: 「外国為替データ(時系列データ)の情報源の紹介」の Web ページ)
以下の説明では、
- Windows の場合: データファイル名: C:\R\Book1.csv
- Linuxの場合: データファイル名: /tmp/Book1.csv
として説明を続ける.
* 自前の CSV ファイルを使うときの注意: read.table() 関数を使うので, 属性名は英語になっていること.属性名は,CSV ファイルの第一行目に書いていること. - 使用する CSV ファイルの確認
属性名が CSV ファイルの1行目に書かれていることを確認する.
- R の起動
- 「read.table」を用いて,CSV ファイルを R のデータフレームに読み込み
次のコマンドを実行.
◆ Windows での動作手順例
X <- read.table("C:/R/Book1.csv", header=TRUE, sep=",", na.strings="NA", dec=".", strip.white=TRUE);◆ Linux での動作手順例
X <- read.table("/tmp/Book1.csv", header=TRUE, sep=",", na.strings="NA", dec=".", strip.white=TRUE);R の read.table のオプション- X <- ・・・ 変数 X に読み込むという意味
- C:/R/Book1.csv, "/tmp/Book1.csv" ・・・ 読み込む CSV ファイル名.Windows では区切りには「/」を使うことに注意.
- header="TRUE" または header="FALSE" ・・・ 列ラベルが設定されているか
- seq="," や seq="\" や seq=" " や ・・・ 列を区切る記号(CSV ファイルのときは「seq=","」)
- na.string="NA" ・・・ Not a Number には "NA" を使うという意味
- dec="." ・・・ ファイルで使われている小数点記号(既定値は,ピリオド)
- strip.white=TRUE ・・・ 個々のデータの先頭や末尾にある「空白文字」を取り除いて読み込む
- skip=<行数> ・・・ 読み飛ばし行数
- nrow=<行数> ・・・ 読み込み行数
- (その他のオプション) dec: ファイルで使われている小数点記号を指定できる
- オブジェクト X の確認
次のコマンドを実行.
edit(X);次のコマンドを実行.
str(X)
要約統計量
- 要約統計量(summary を使用)
最小値,中央値,平均値,最大値などを表示
summary(X)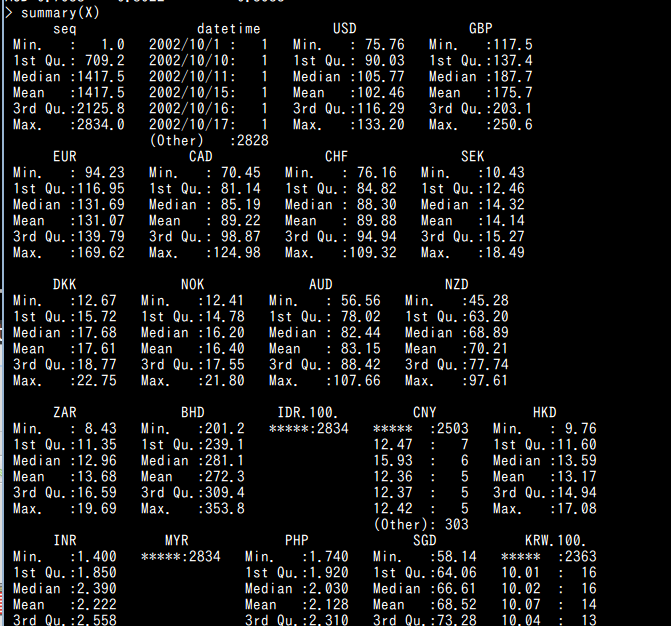
- 要約統計量(numSummary を使用)
平均値,標準偏差などを表示
numSummary( X[,c("USD", "EUR", "AUD")], statistics=c("mean", "sd", "quantiles"), quantiles=c( 0,.25,.5,.75,1 ))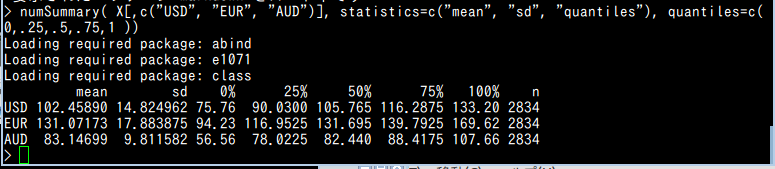
散布図と近似線
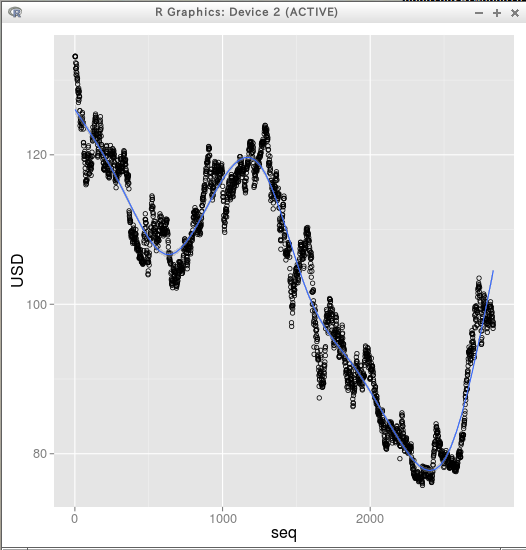
- 「scatterplot」を用いた散布図の描画
要点: 横軸が seq, 縦軸が USD
scatterplot( USD~seq, reg.line=lm, smooth=TRUE, boxplots=FALSE, span=0.5, data=X )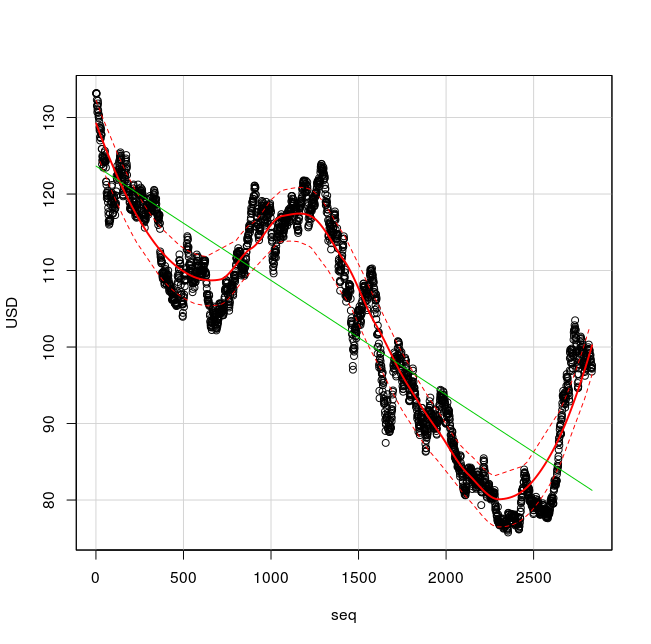
-
library(ggplot2) p <- ggplot(X) p + geom_point( aes(x = seq, y = USD), shape=1) + stat_smooth( aes(x = seq, y = USD) )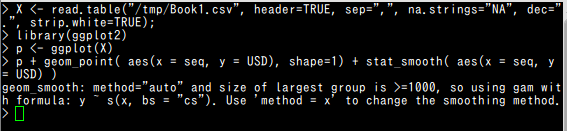
- 「scatterplot」を用いた散布図の描画(分布の平均と分散も図示)
要点: 横軸が seq, 縦軸が USD.分布の平均と分散も図示
scatterplot( USD~seq, reg.line=lm, smooth=TRUE, boxplots='xy', span=0.5, data=X )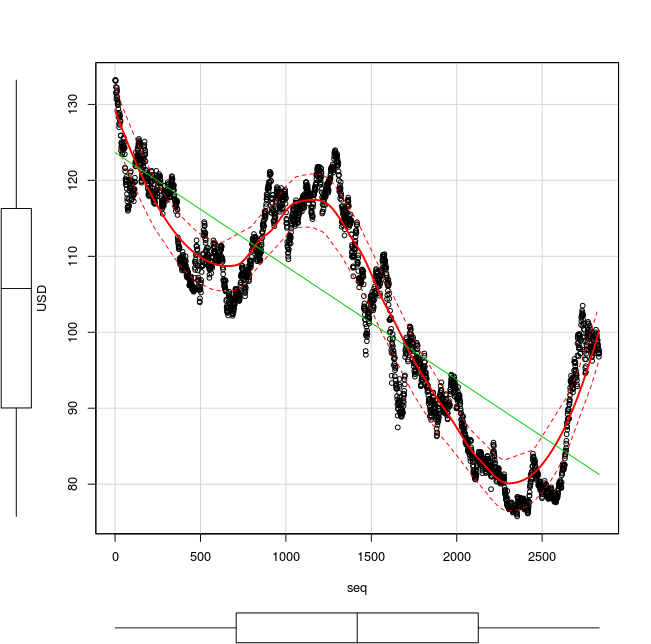
- 散布図行列
scatterplot.matrix( ~seq+USD+EUR+AUD, reg.line=lm, smooth=TRUE, span=0.5, diagonal = 'density', data=X )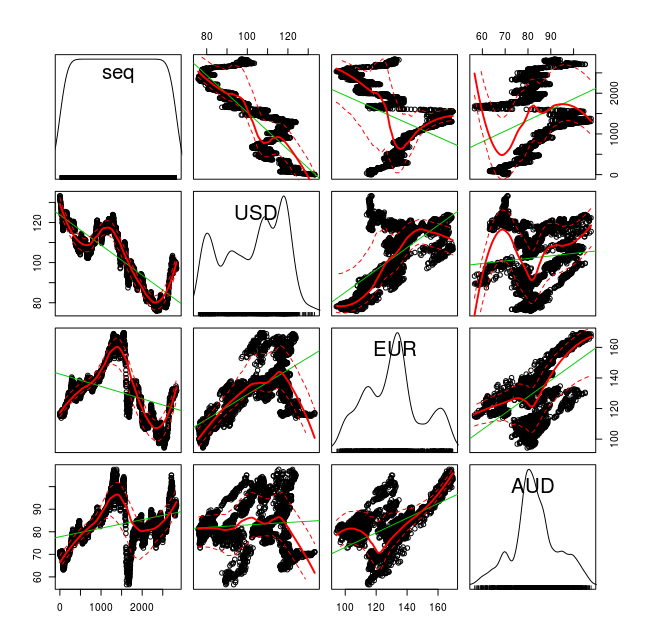
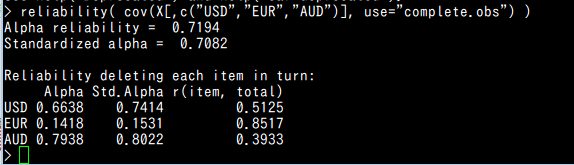
スケールの信頼性
reliability( cov(X[,c("USD","EUR","AUD")], use="complete.obs") )
CSVファイルを読み込み,データフレームに格納
- (前準備) 使用する CSV ファイルの作成
* ここでは Book1.csv をダウンロードし,分かりやすいディレクトリに置く
(参考: 「外国為替データ(時系列データ)の情報源の紹介」の Web ページ)
以下の説明では、
- Windows の場合: データファイル名: C:\R\Book1.csv
- Linuxの場合: データファイル名: /tmp/Book1.csv
として説明を続ける.
* 自前の CSV ファイルを使うときの注意: read.table() 関数を使うので, 属性名は英語になっていること.属性名は,CSV ファイルの第一行目に書いていること. - 使用する CSV ファイルの確認
属性名が CSV ファイルの1行目に書かれていることを確認する.
- R の起動
- 「read.table」を用いて,CSV ファイルを R のデータフレームに読み込み
次のコマンドを実行.
◆ Windows での動作手順例
X <- read.table("C:/R/Book1.csv", header=TRUE, sep=",", na.strings="NA", dec=".", strip.white=TRUE);◆ Linux での動作手順例
X <- read.table("/tmp/Book1.csv", header=TRUE, sep=",", na.strings="NA", dec=".", strip.white=TRUE);オプション
- X <- ・・・ 変数 X に読み込むという意味
- C:/Book1.csv, "/tmp/Book1.csv" ・・・ 読み込む CSV ファイル名.Windows では区切りには「/」を使うことに注意.
- header="TRUE" または header="FALSE" ・・・ 列ラベルが設定されているか
- seq="," や seq="\" や seq=" " や ・・・ 列を区切る記号(CSV ファイルのときは「seq=","」)
- na.string="NA" ・・・ Not a Number には "NA" を使うという意味
- dec="." ・・・ ファイルで使われている小数点記号(既定値は,ピリオド)
- strip.white=TRUE ・・・ 個々のデータの先頭や末尾にある「空白文字」を取り除いて読み込む
- skip=<行数> ・・・ 読み飛ばし行数
- nrow=<行数> ・・・ 読み込み行数
- (その他のオプション) dec: ファイルで使われている小数点記号を指定できる
- オブジェクト X の確認
次のコマンドを実行.
edit(X);次のコマンドを実行.
str(X)
データフレームからのグラフ作成例
- x, y 値を指定しての散布図の作成
x 値を格納したベクトル,y 値を格納したベクトルを引数として plot() 関数を使うと,散布図が描かれます.
この場合「X[,c("属性名")]」のような書き方で,X から列を抜き出して,ベクトルを作る.
- 散布図以外のいろいろなグラフについては,Rでの種々のグラフの Web ページを見てください.
- グラフの調整については,グラフ作成での各種パラメータの Web ページを見てください.
- ggplot については,ggplot の例の Web ページを見てください.
* Iris データセットの散布図の例
plot( iris[,1], iris[,2], col=iris[,5] )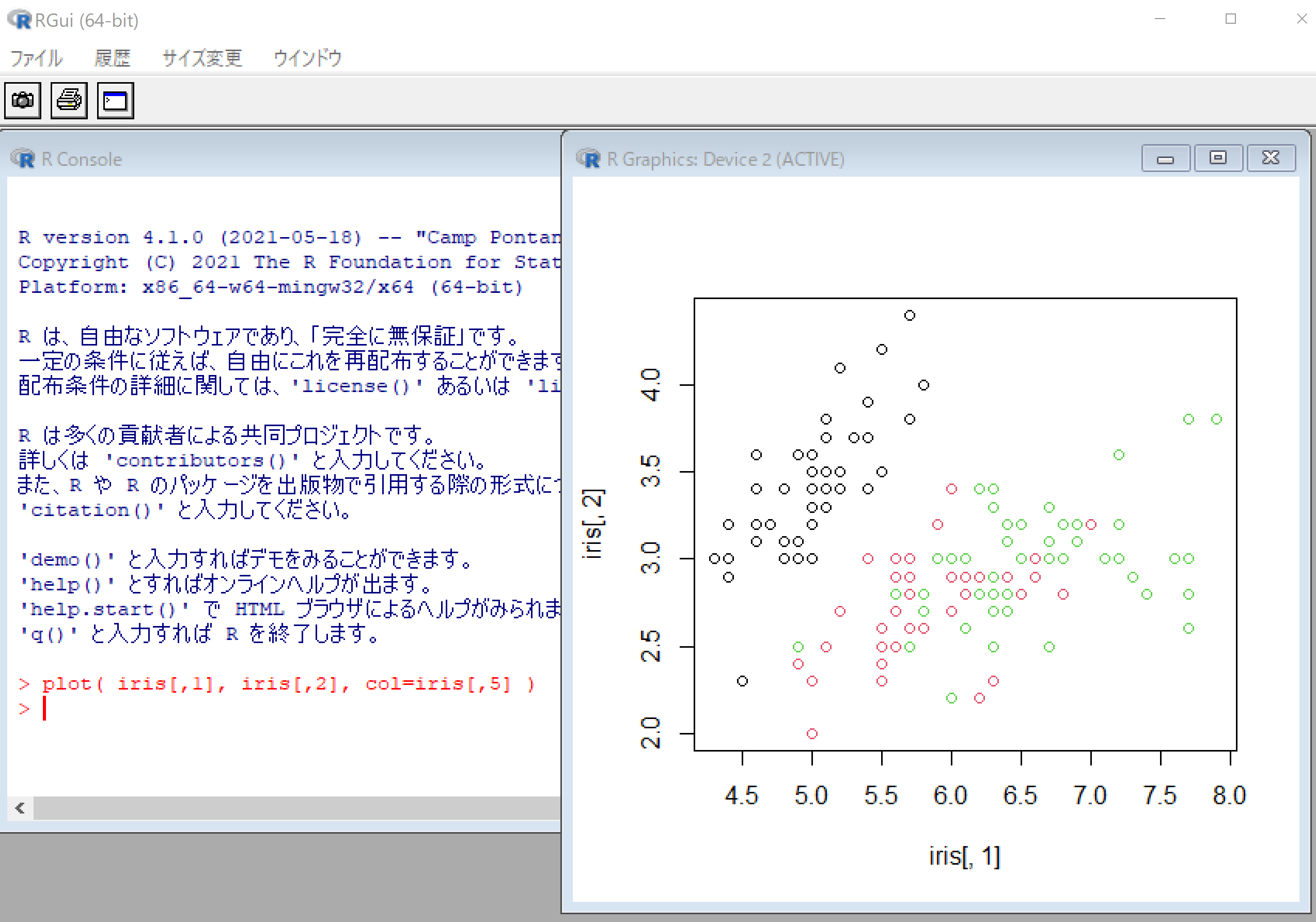
library(ggplot2) p <- ggplot(iris) p + geom_point( aes(x = iris[,1], y = iris[,2], colour = iris[,5]) ) + scale_colour_hue()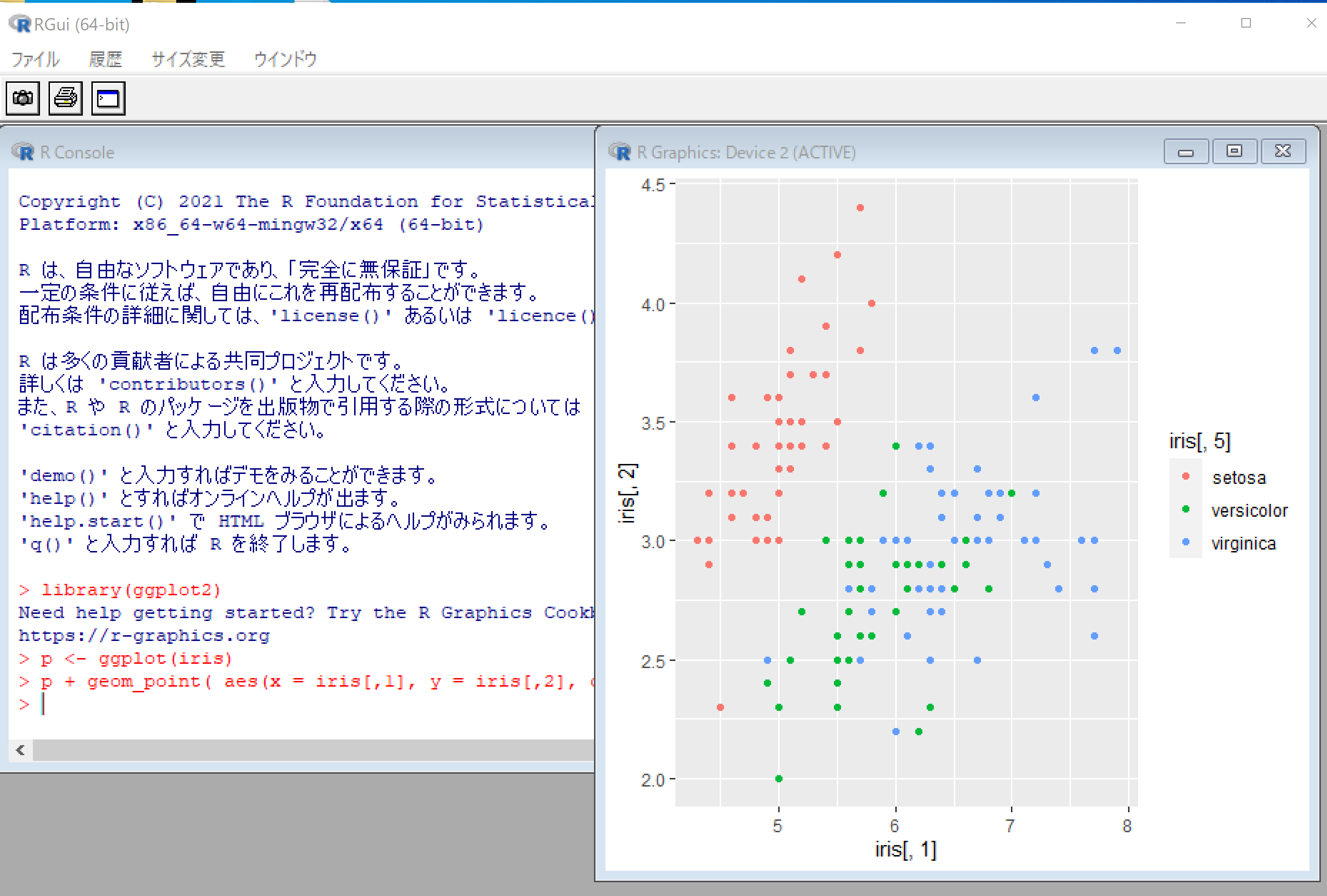
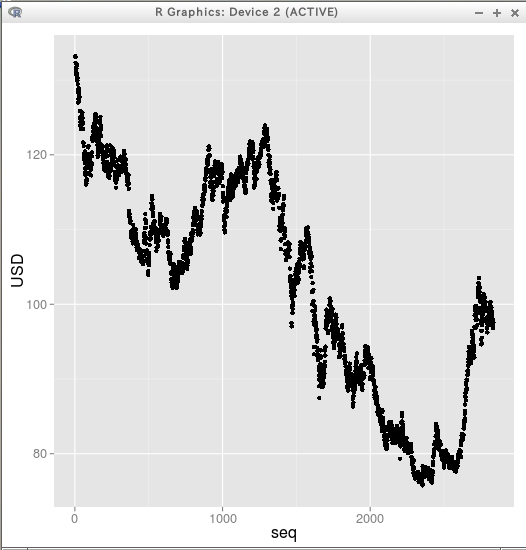
* 外国為替データ(時系列データ) Book1.csv の散布図の例
plot( X[,c("seq")], X[,c("USD")] )
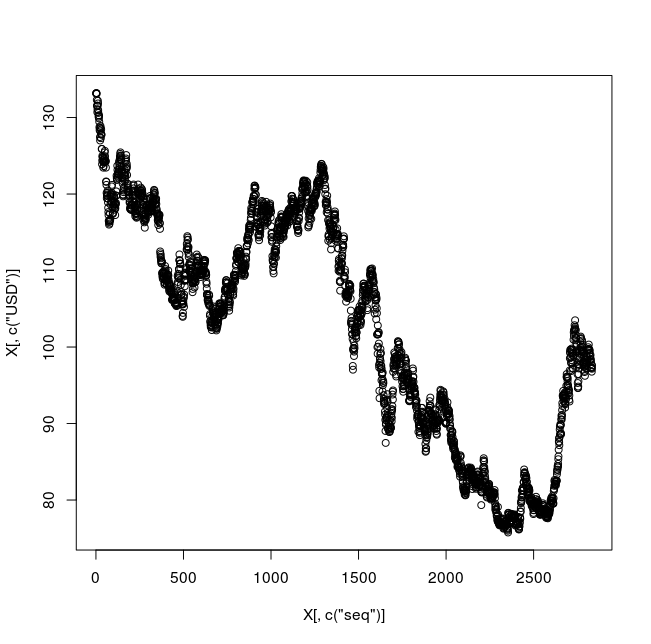
library(ggplot2) p <- ggplot(X) p + geom_point( aes(x = seq, y = USD) )
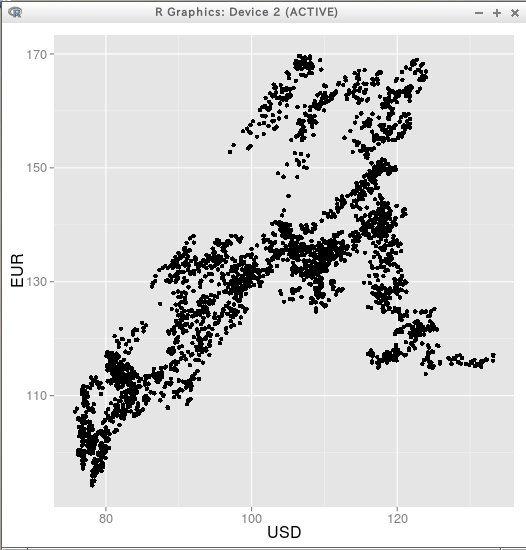
plot( X[,c("USD")], X[,c("EUR")] )
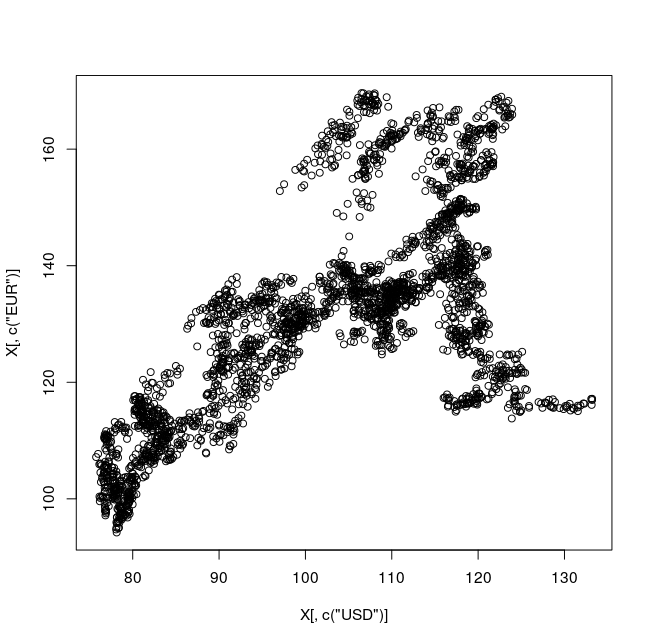
library(ggplot2) p <- ggplot(X) p + geom_point( aes(x = USD, y = EUR) )
重ね書きの例
points() 関数や line() 関数 や legend() 関数や text() 関数を使って,簡単に重ね書きできる.例を示しておきます. 次のような感じになります(文法の詳細には立ち入りません).
* 平滑化の関数は,他にも,smooth.spline(), ksmooth(), supsmu() などが知られている.
線の重ね書き
lines() 関数は,線を重ね書きするもの.
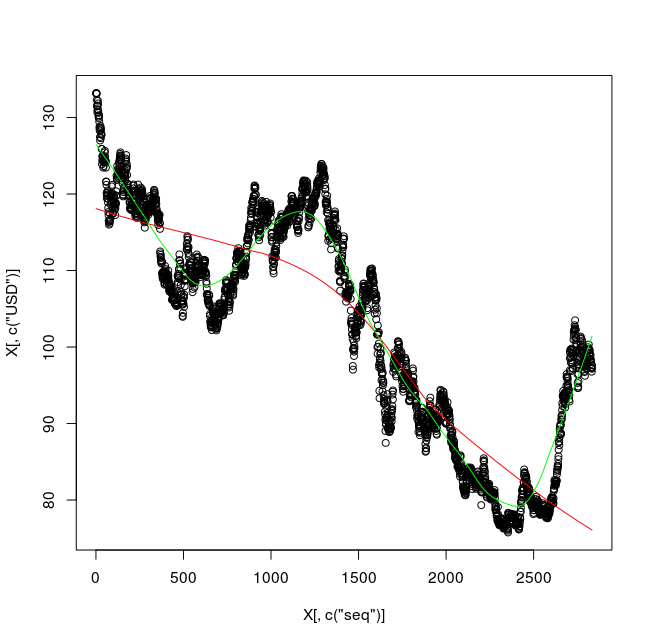
* 外国為替データ(時系列データ) Book1.csv の例
plot( X[,c("seq")], X[,c("USD")] )
lines(lowess( X[,c("seq")], X[,c("USD")] ), col = "red")
lines(lowess( X[,c("seq")], X[,c("USD")], f=0.2 ), col = "green")

メソッドについての説明は,次の公式ページにある. https://rdocumentation.org/packages/ggplot2/versions/3.3.5
library(ggplot2)
p <- ggplot(X)
p + geom_point( aes(x = seq, y = USD) ) + stat_smooth( aes(x = seq, y = USD), method="loess" )

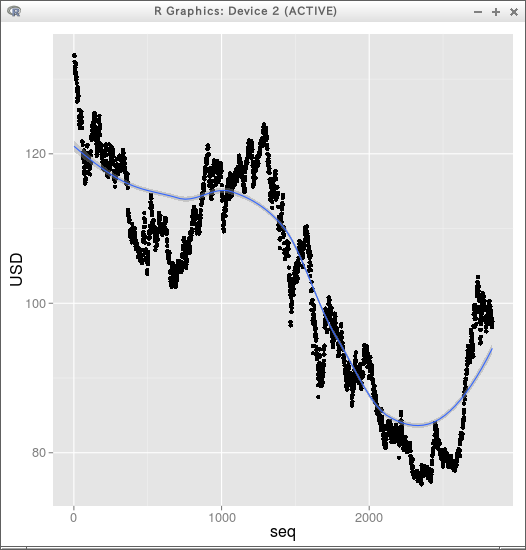
library(ggplot2)
p <- ggplot(X)
p + geom_point( aes(x = seq, y = USD) ) + stat_smooth( aes(x = seq, y = USD), method="loess" )
複数のグラフの重ね描き
「par(new=T)」によりグラフの重ね書きを指示
* 外国為替データ(時系列データ) Book1.csv の例
plot( X[,c("seq")], X[,c("USD")] )
par(new = T)
plot( X[,c("seq")], X[,c("EUR")], pch=0, col=2 )

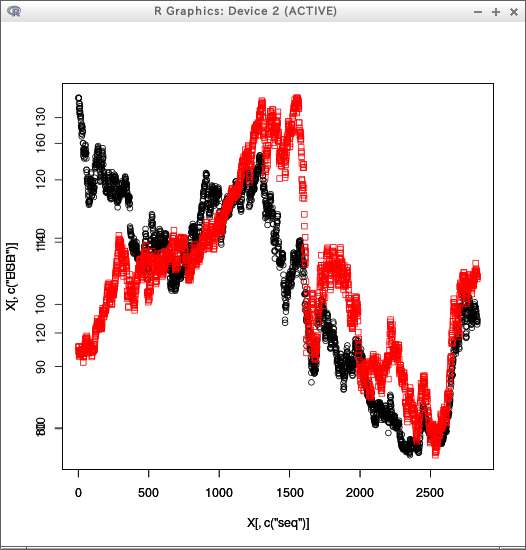
library(ggplot2)
p <- ggplot(X)
p <- p + geom_point( aes(x = seq, y = USD), shape=0 )
p <- p + geom_point( aes(x = seq, y = EUR), shape=1, colour="red" )
p

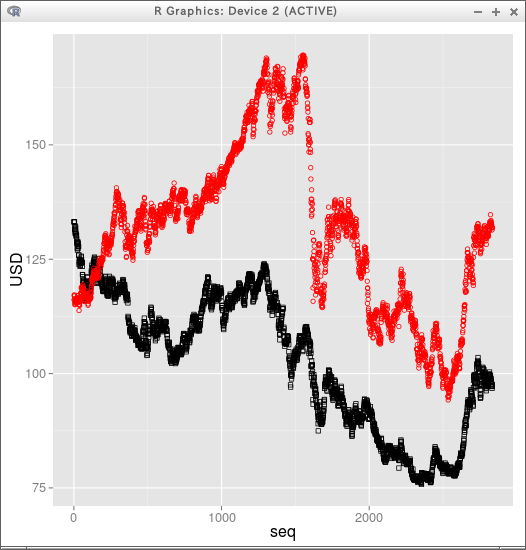
凡例の重ね書き
legend() 関数では,次を指定する.
- x 座標
- y 座標
- 凡例として表示する文字列ベクトル
- オプション
【関連する外部ページ】: http://www.okada.jp.org/RWiki/?%A5%B0%A5%E9%A5%D5%A5%A3%A5%C3%A5%AF%A5%B9%BB%B2%B9%CD%BC%C2%CE%E3%BD%B8%A1%A7%CB%DE%CE%E3 (現存しない)
グラフィックス参考実例集:凡例 (http://www.okada.jp.org/RWiki/?%A5%B0%A5%E9%A5%D5%A5%A3%A5%C3%A5%AF%A5%B9%BB%B2%B9%CD%BC%C2%CE%E3%BD%B8%A1%A7%CB%DE%CE%E3)
plot( X[,c("seq")], X[,c("USD")] )
lines(lowess( X[,c("seq")], X[,c("USD")] ), col = "red")
lines(lowess( X[,c("seq")], X[,c("USD")], f=0.2 ), col = "green")
legend( 5, 105, c( "f = 2/3", "f = 0.2" ), lty = 1, col = c("red", "green") )

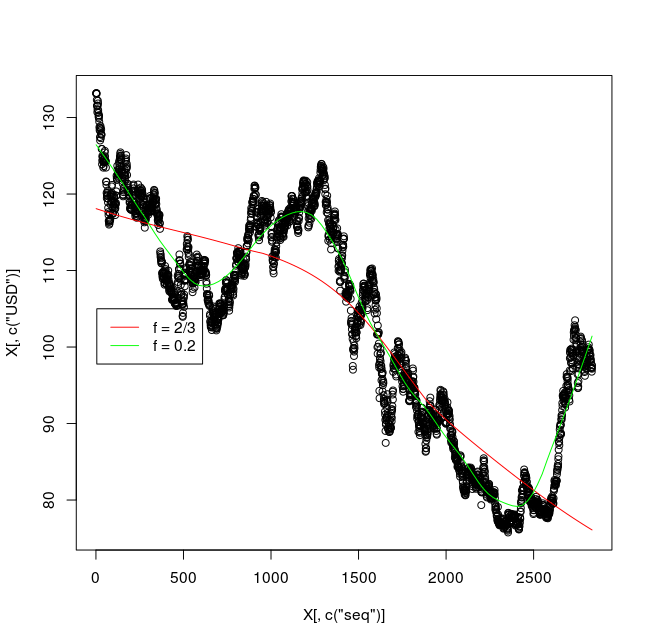
テキストを書くこともできる.
text(locator(1), labels = "ほげほげ")
グラフのファイルへの保存
グラフィカル・デバイスの種類
- postscript pdf pictex : LaTeX/PicTeX ファイル
- png : PNG ファイル
- jpeg : JPEG ファイル
- bmp : BMP ファイル
- windows : Windows
- x11 : UNIX, Linux
など.
詳細は「help(Devices)」で確認できる
グラフィカル・デバイスを用いたグラフのファイルの保存
例えば,PNG ファイルを作りたいときは,最初に「png()」を実行.最後に「dev.off()」で,ファイルを閉じる. すると,作業ディレクトリにファイルができる.作業ディレクトリは,getwd() で分かる.
* png( file="C:\1.png" ) のように,ファイル名を陽に指定する方が分かりやすいでしょう.
◆ Windows での実行手順例 (png ファイルを作成している)
X <- read.table("C:/R/Book1.csv", header=TRUE, sep=",", na.strings="NA", dec=".", strip.white=TRUE);
png("1.png")
plot( X[,c("seq")], X[,c("USD")] )
dev.off()
getwd()
X <- read.table("C:/R/Book1.csv", header=TRUE, sep=",", na.strings="NA", dec=".", strip.white=TRUE);
png("1.png")
library(ggplot2)
p <- ggplot(X)
p + geom_point( aes(x = seq, y = USD) )
dev.off()
getwd()
◆ Ubuntu での実行手順例 (png ファイルを作成している)
X <- read.table("/tmp/Book1.csv", header=TRUE, sep=",", na.strings="NA", dec=".", strip.white=TRUE);
png("1.png")
plot( X[,c("seq")], X[,c("USD")] )
dev.off()
getwd()
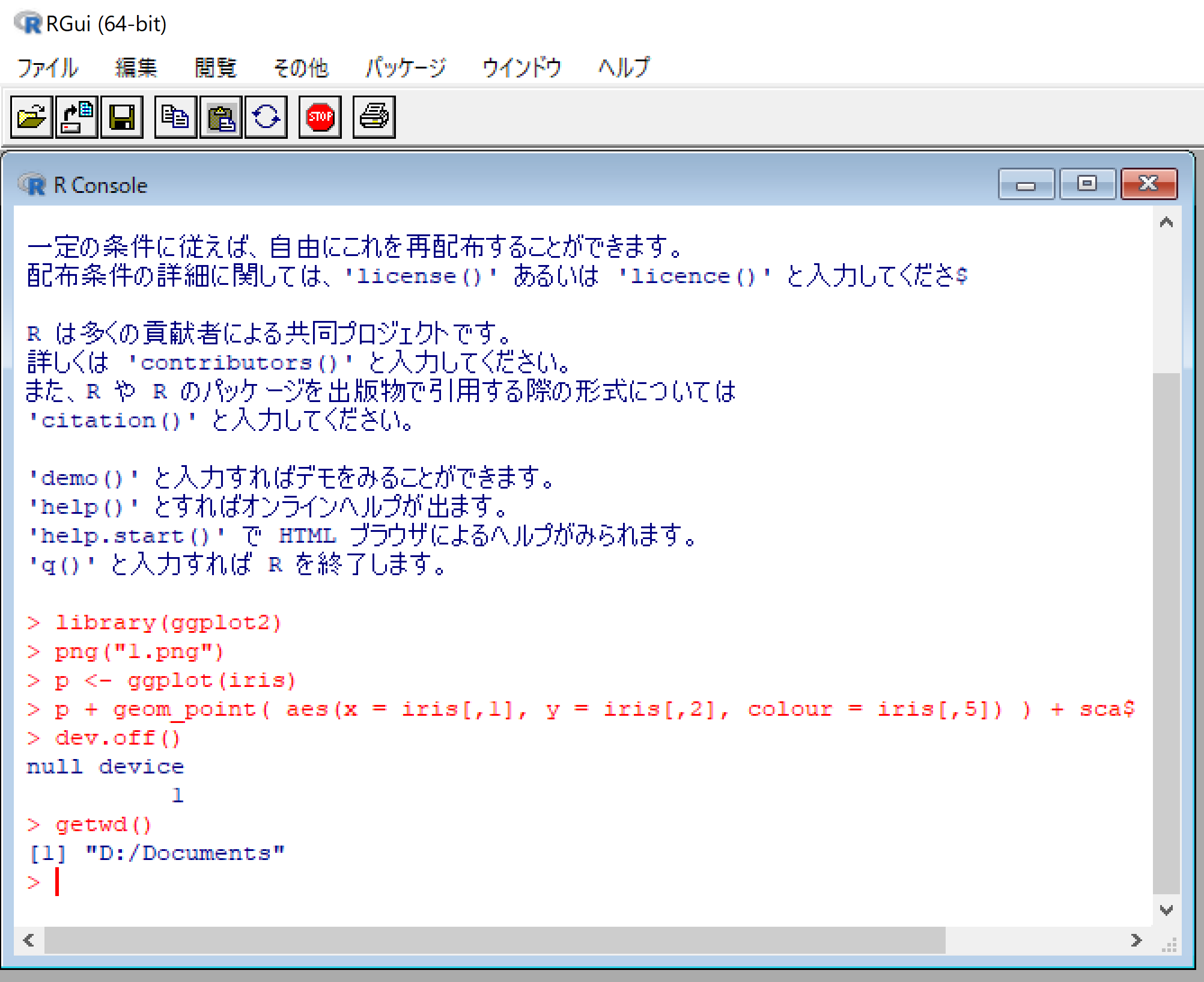
X <- read.table("/tmp/Book1.csv", header=TRUE, sep=",", na.strings="NA", dec=".", strip.white=TRUE);
png("1.png")
library(ggplot2)
p <- ggplot(X)
p + geom_point( aes(x = seq, y = USD) )
dev.off()
getwd()
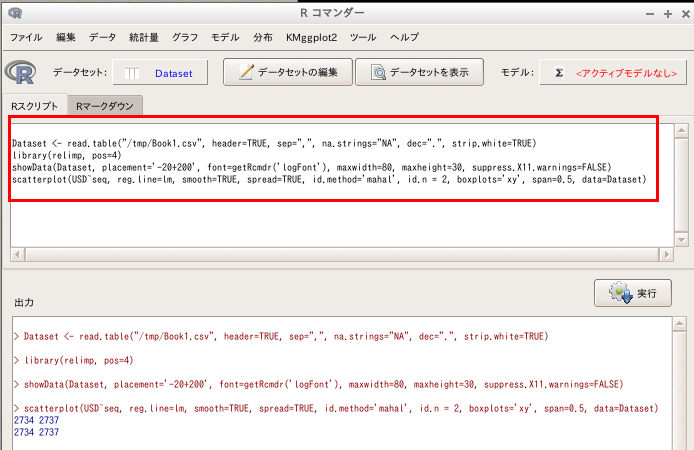
R コマンダーを用いた散布図の作成手順例
グラフの作成には R コマンダーが便利です
- R の起動
- Rcmdr, RcmdrPlugin.KMggplot2 の読み込み
library(Rcmdr) library(RcmdrPlugin.KMggplot2)* このときエラーが出た場合には, 「install.packages("Rcmdr")」, 「install.packages("RcmdrPlugin.KMggplot2")」, のように インストール操作を行うと解決する場合がある - しばらく待つと、Rコマンダーのウィンドウが開く
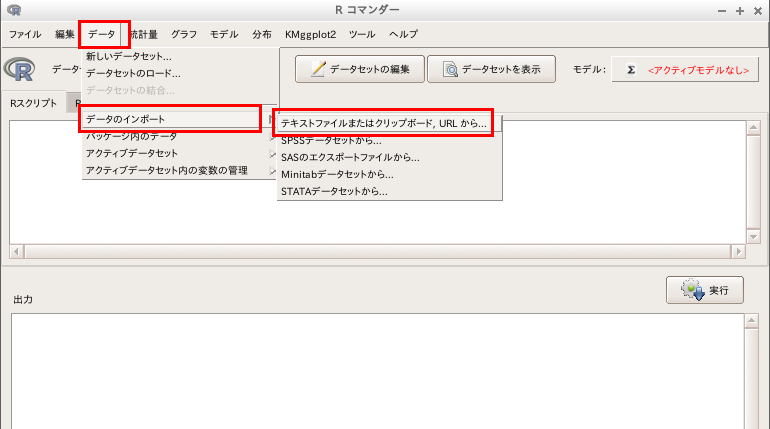
- Rコマンダーで「データ」
→
「データのインポート」と操作する
→
「テキストファイルまたはクリップボード,URLから」と操作する
- データ名、ヘッダーの有無、区切り記号を指定
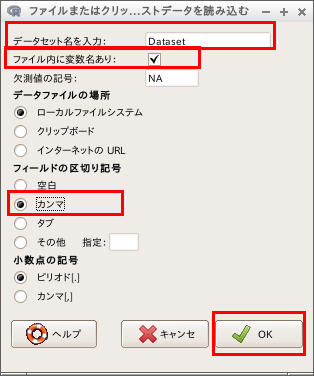
- 読み込みたいファイルのディレクトリとファイル名を指定
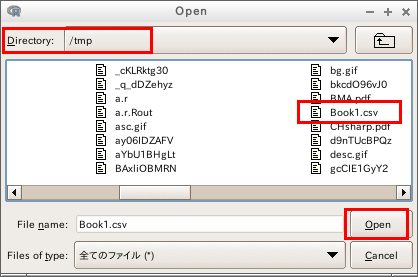
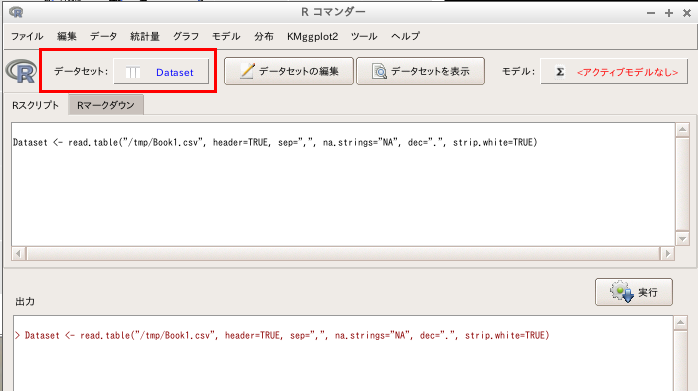
- いま読み込んだファイルのデータ名を選択
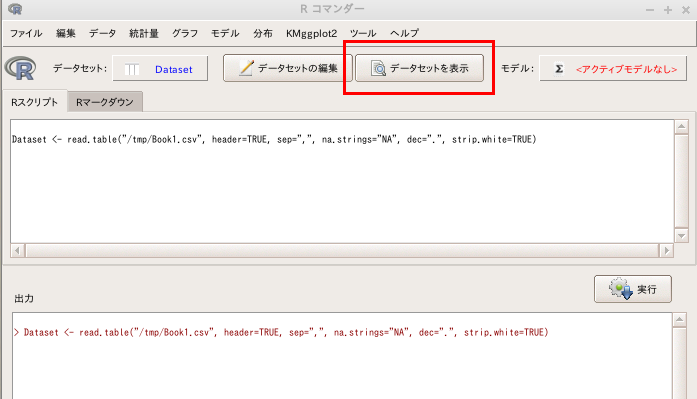
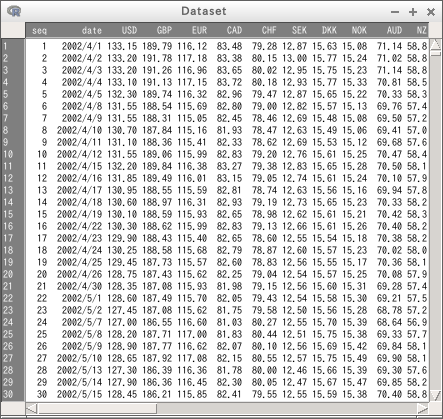
- データセットを表示したい場合には、「データセットを表示」をクリックする
- ggplot() 関数を用いた散布図を作成したい場合は、
「KMggplot2」→「散布図」と操作する
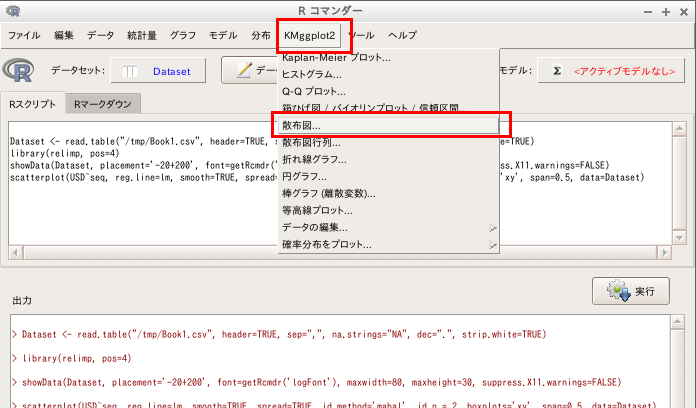
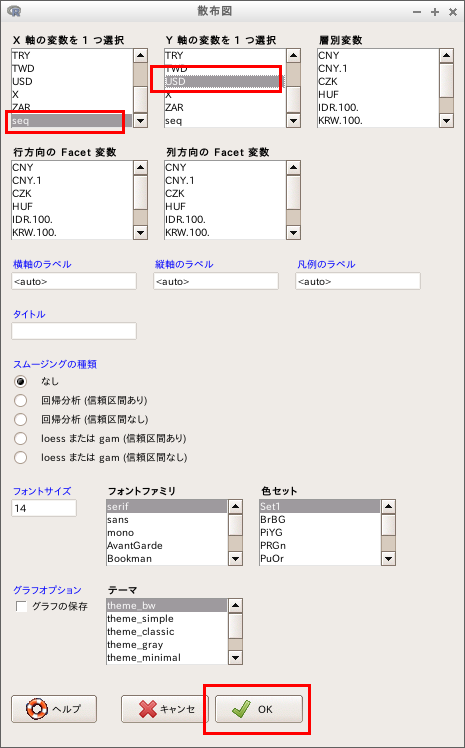
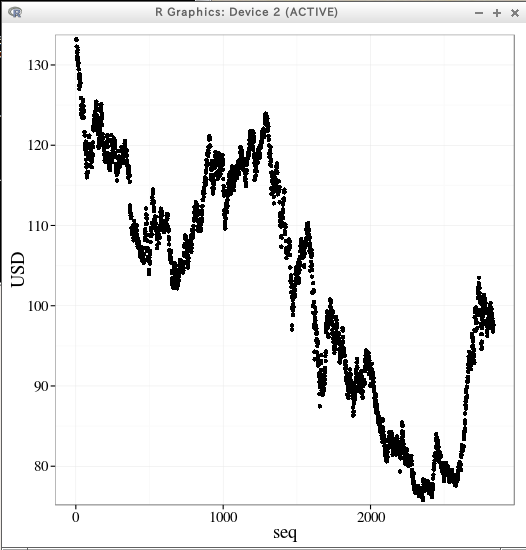
x軸, y軸などの設定を行い 「OK」をクリックすると、散布図が得られる.
- plot() 関数を用いた散布図を作成したい場合は、
「グラフ」→「散布図」と操作する
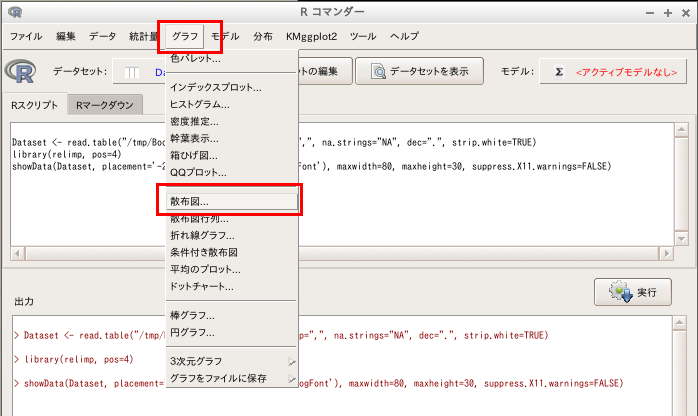
x軸, y軸などの設定を行い 「OK」をクリックすると、散布図が得られる.
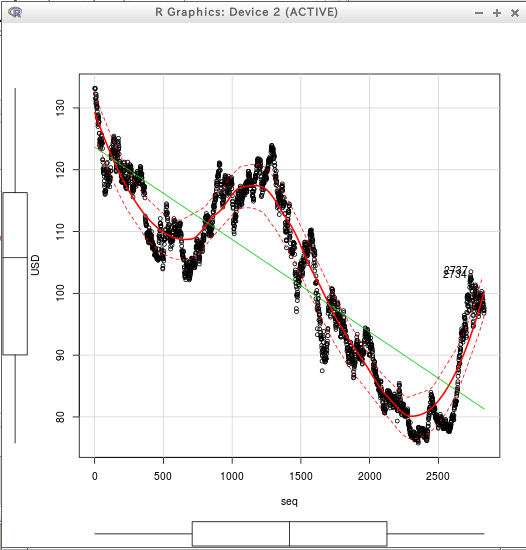
- R のプログラムが作成される.これを記録しておけば、将来、同じ操作を繰り返したくなった時に楽。