人工知能の基礎(全15回)
大学で使用した自作の資料等を,手直しの上公開している. クリエイティブ・コモンズ BY NC SA.
【目次】
- aa-1. データサイエンス・AIでできること、社会の変化(人工知能社会の到来、最新の技術、産業の変化、社会や生活の変化など)
- aa-2. データサイエンス・AIの事例、技術(散布図、データの分布や密度、AIによる分類や特徴抽出や生成など)
- aa-3. 実データによるデータサイエンス・AIの演習(オープンデータ、政府統計データ、クロス集計表、相関
- aa-4. 機械学習,ニューラルネットワーク
- aa-5. 深層学習(ディープラーニング)
- aa-6. 画像分類システム
- aa-7. 学習と検証,学習不足,過学習,学習曲線
- aa-8. 人工知能とコンピュータビジョン
- aa-9. 遷移関数、知的なゲーム世界の実現
- aa-10. 遷移関数、探索、総当たり
- aa-11. パス、木、発見的探索
- aa-12. プロダクションシステム,知識表現,推論エンジン
- aa-13. 述語、Prolog
- aa-14. 自然言語処理
- aa-15. 全体まとめ,発展
その他の関連資料
【サイト内の関連ページ】
資料
aa-1. データサイエンス・AIでできること、社会の変化
人工知能は,コンピュータが人間のような知的能力を持つことを目指す技術である。 データから自ら学習する機械学習と,人間が書いたルールや知識を用いる知的なITシステムに大別される。 応用分野は,画像分類・顔検知・セグメンテーション,対話型AI,自動翻訳,データ分析と予測,GANによる画像合成など多岐にわたる。 学習データに偏りがあると結果にも偏りが出るため利用には注意が必要である。
スライド資料
[PDF], [パワーポイント] (同じ内容, クリックしてダウンロード)
動画
概要
人工知能(AI)はコンピュータが知的能力を持つ技術で、思考、判断、学習などの機能を有する。
AIは医療、金融、製造、農業など幅広い分野で用いられ、仕事の補助や代行といった役割を果たす。
AIの種類には機械学習や知的なITシステムがあり、用途によって選択する。
AIによる合成や生成は偽情報の拡散や倫理的な問題を引き起こす可能性があるため、注意が必要である。
AIの技術は急激に進歩してる。AIが引き起こす社会への影響や倫理的な問題も注視が必要である。
AIの発達は人間がよりクリエイティブになるためのツールともなり得る。
以下の演習では,説明部分で学んだAIの概念を,オンラインデモを通じて体験する.各デモの結果を観察し,考察すること.
ブラウザの種類・バージョンによっては動作しない可能性もある。
習っていない言葉(例:隠れ層)などが出てくるが、将来の授業で説明予定なので心配しないでほしい。演習8から11は注意書きを確認の上で実行してほしい。
説明の「ニューラルネットワークの基本構造」に対応する演習である.畳み込みニューラルネットワーク(CNN)の内部構造を3Dで可視化し,各層がどのように入力を処理しているかを観察する. URL: https://adamharley.com/nn_vis/cnn/3d.html 操作手順 観察と考察 説明の「ニューラルネットワークの基本構造」に対応する演習である.ニューラルネットワークの構造やパラメータを変更しながら,学習過程の変化を観察する. URL: https://playground.tensorflow.org 操作手順 観察と考察 説明の「探索による問題解決」に対応する演習である.探索アルゴリズムが経路を見つける過程を可視化し,コンピュータによる探索の仕組みを理解する. URL: https://qiao.github.io/PathFinding.js/visual/ 操作手順 観察と考察 説明の「自動翻訳サービス」に対応する演習である.AIによる自動翻訳の精度と自然さを体験する. URL: https://www.deepl.com/ja/translator 操作手順 観察と考察 説明の「人間の下書きをAIが清書する」に対応する演習である.手描きの下書きをAIが認識し,候補イラストを提示する仕組みを体験する. URL: https://www.autodraw.com/ 操作手順 観察と考察 説明の「AIでスケッチを増やす」に対応する演習である.VAEにより,描いたスケッチに似たスケッチを複数生成する技術を体験する. URL: https://magenta.tensorflow.org/assets/sketch_rnn_demo/multi_vae.html 操作手順 観察と考察 説明の「手書きの線画から画像を生成する」に対応する演習である.pix2pix(GAN技術)を使用して,手書きの線画からカラー画像を生成する技術を体験する. URL: https://mitmedialab.github.io/GAN-play/ 操作手順 観察と考察
ここから先は、余裕のある人向け(自分でWebカメラや画像ファイルを準備して、自力で進める人向け)である。
演習8〜11はWebカメラや画像ファイルが必要である(どちらになるかは演習によって違う). 説明の「訓練データと学習の仕組み」に対応する演習である.自分のデータで訓練データの作成,学習,推論の一連の流れを体験する. URL: https://teachablemachine.withgoogle.com/ 操作手順 観察と考察 説明の「画像分類」に対応する演習である.画像をアップロードし,AIによるラベル付けや物体検出を体験する. URL: https://cloud.google.com/vision/docs/drag-and-drop 操作手順 観察と考察 説明の「顔検知」「顔のキーポイント検出」「表情の自動判定」に対応する演習である.1つのデモで顔に関する複数のAI技術を体験する. URL: https://modern-face-api.vercel.app/ 操作手順 観察と考察 説明の「人体の姿勢の読み取り」に対応する演習である.人体の関節位置を検出し,骨格を可視化する技術を体験する. URL: https://huggingface.co/spaces/hysts/mediapipe-pose-estimation 操作手順 観察と考察
[演習の詳細を表示するには、この行をクリックしてください]
演習について
演習1. CNN 3D Visualization(Adam Harley)(機械学習・ニューラルネットワーク)
演習2. TensorFlow Playground(機械学習・ニューラルネットワーク)
演習3. PathFinding.js Visual(知的なITシステム)
演習4. DeepL(AIでできること)
演習5. AutoDraw(Google)(AIによる合成)
演習6. Sketch RNN VAE Demo(Magenta)(AIによる合成)
演習7. GAN-play(MIT Media Lab)(AIによる合成)
演習8. Teachable Machine(Google)(機械学習・ニューラルネットワーク)
演習9. Google Cloud Vision API Demo(AIでできること)
演習10. Modern Face API Demo(AIでできること)
演習11. MediaPipe Pose Estimation(Hugging Face)(AIでできること)
aa-2. データサイエンス・AIの事例、技術
データサイエンスは,データから有益な情報を導き出すための学問である。散布図やヒストグラムなどでデータを可視化する。 機械学習は,コンピュータがデータを使用して学習し知的能力を向上させる技術で,パターンや関係性を自動で発見する。 機械学習には,正解の組を用いる教師あり学習のほか教師なし学習や強化学習があり,代表的手法にディープラーニングがある。 いずれもデータに基づく技術である。結果に100%の正確性は保証されず,データの選択・前処理に注意が必要である。
スライド資料
動画
[YouTube動画]
以下の演習では,説明部分で学んだデータサイエンス、機械学習の概念をについて理解を深める.
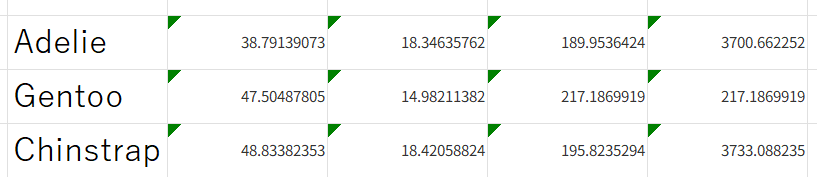
ペンギン3種類のデータを使い,Excelの関数で合計と平均を求める演習である.種類ごとの平均を比較することで,種類による体の特徴の違いを数値で把握する. 使用データ:penguins.xls 操作手順
H2に「くちばしの長さ(mm)」,I2に「くちばしの深さ(mm)」,J2に「フリッパーの長さ(mm)」,K2に「体重(g)」の平均が求まっていることを確認する。
I3,J3,K3も同様に行う。I3に「=AVERAGE(C153:C275)」,J3に「=AVERAGE(D153:D275)」,K3に「=AVERAGE(D153:D275)」と入力する
I4,J4,K4も同様に行う。
I4に「=AVERAGE(C276:C343)」,J4に「=AVERAGE(D276:D343)」,K4に「=AVERAGE(E276:E343)」と入力する
左から順に、「くちばしの長さ(mm)」,「くちばしの深さ(mm)」,「フリッパーの長さ(mm)」,「体重(g)」の平均
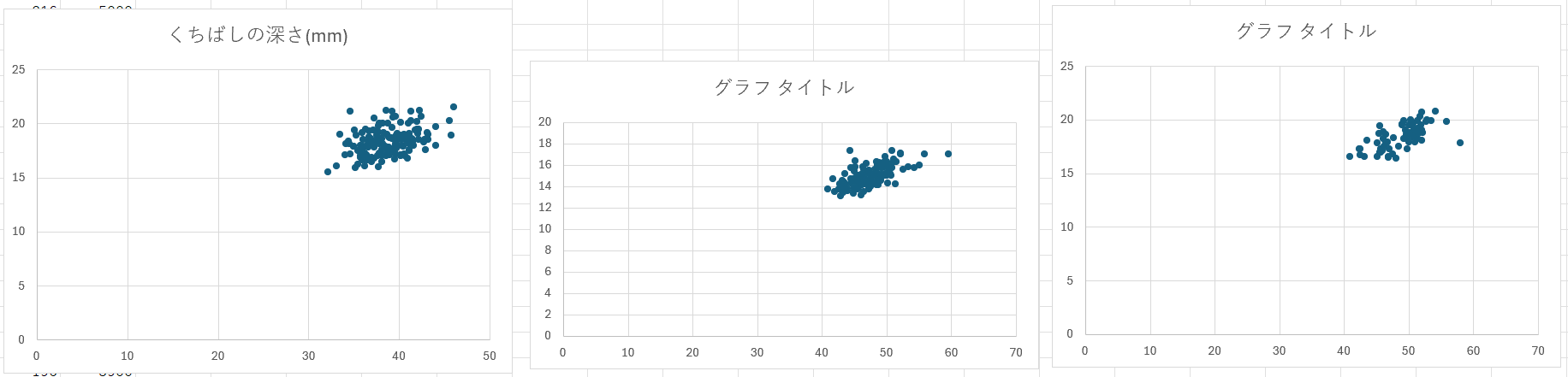
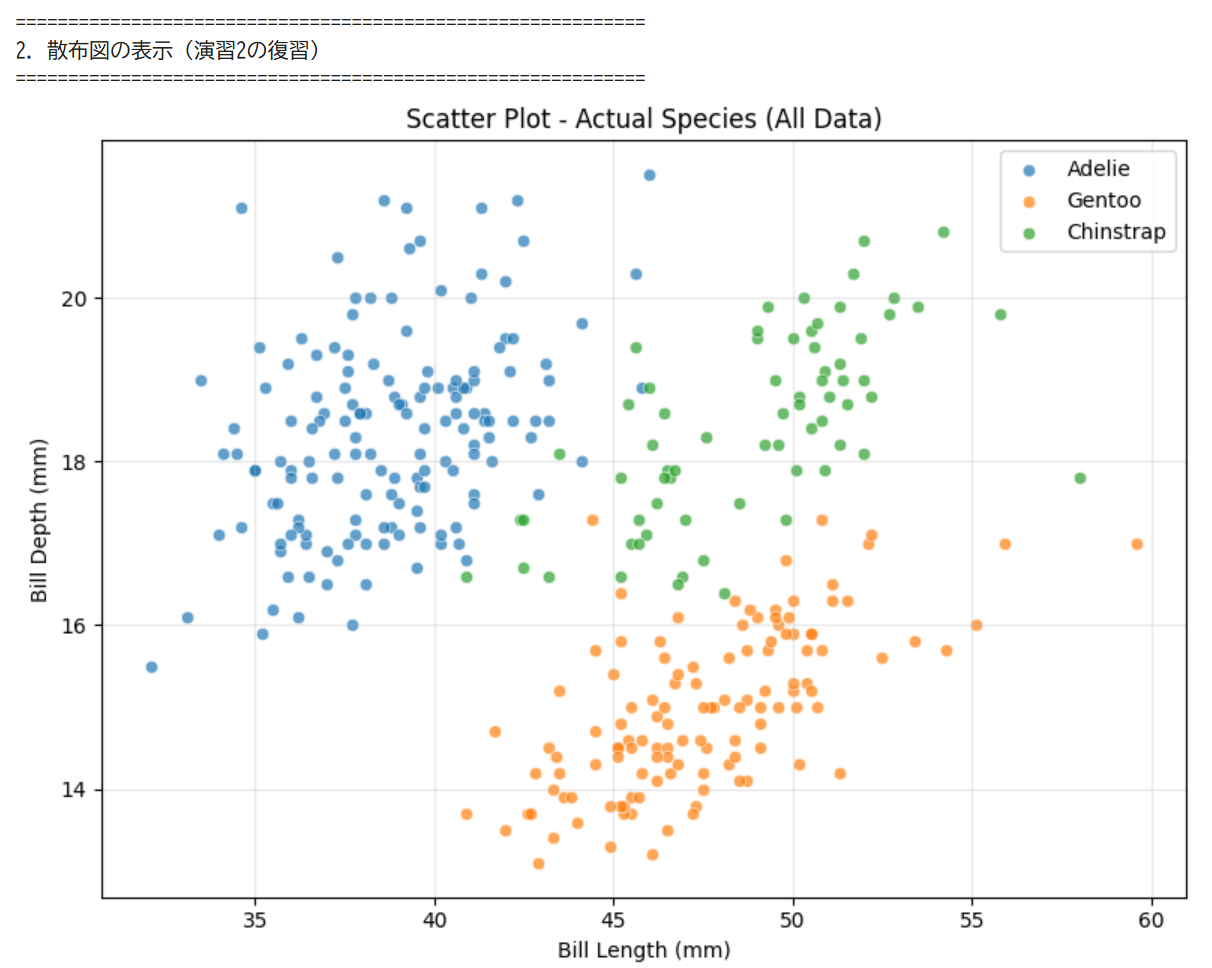
観察と考察 ペンギン3種類のデータを使い,Excelで散布図を作成する演習である.2つの特徴量を横軸と縦軸にとり,種類ごとのデータの分布やかたまりを視覚的に確認する. 使用データ:penguins.xls(演習1と同じファイルをそのまま使用する) 操作手順
結果
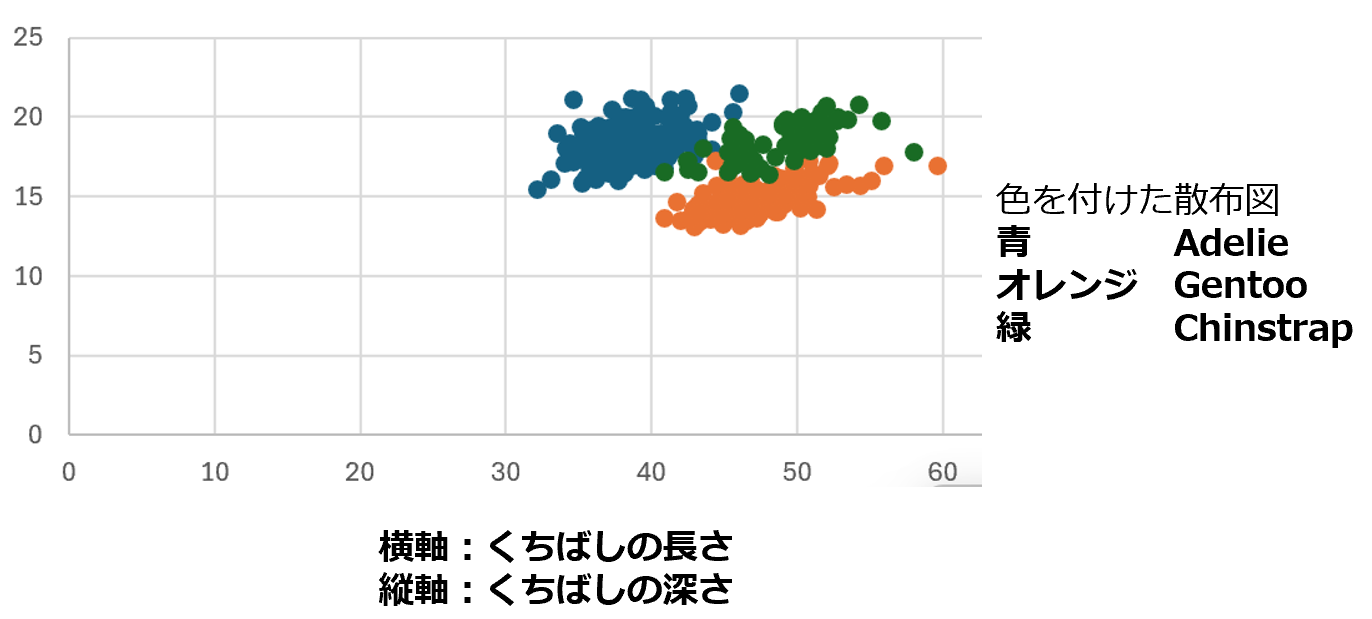
参考(色分けして1枚にしたもの)
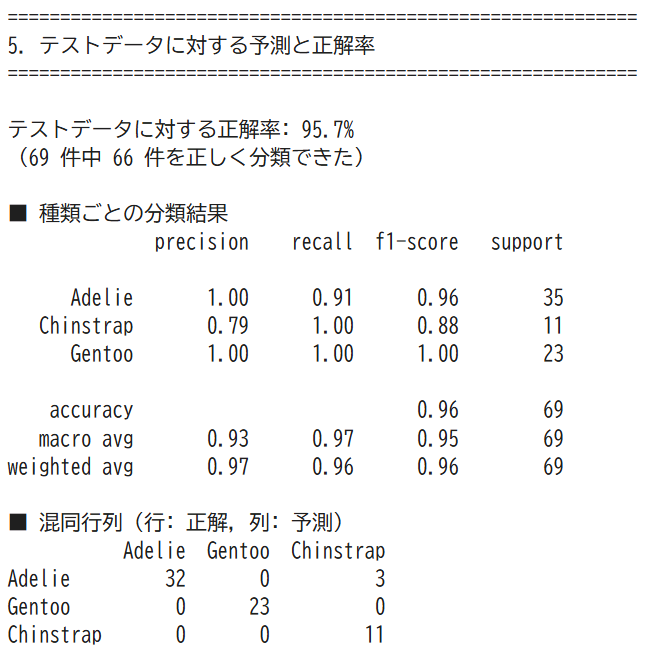
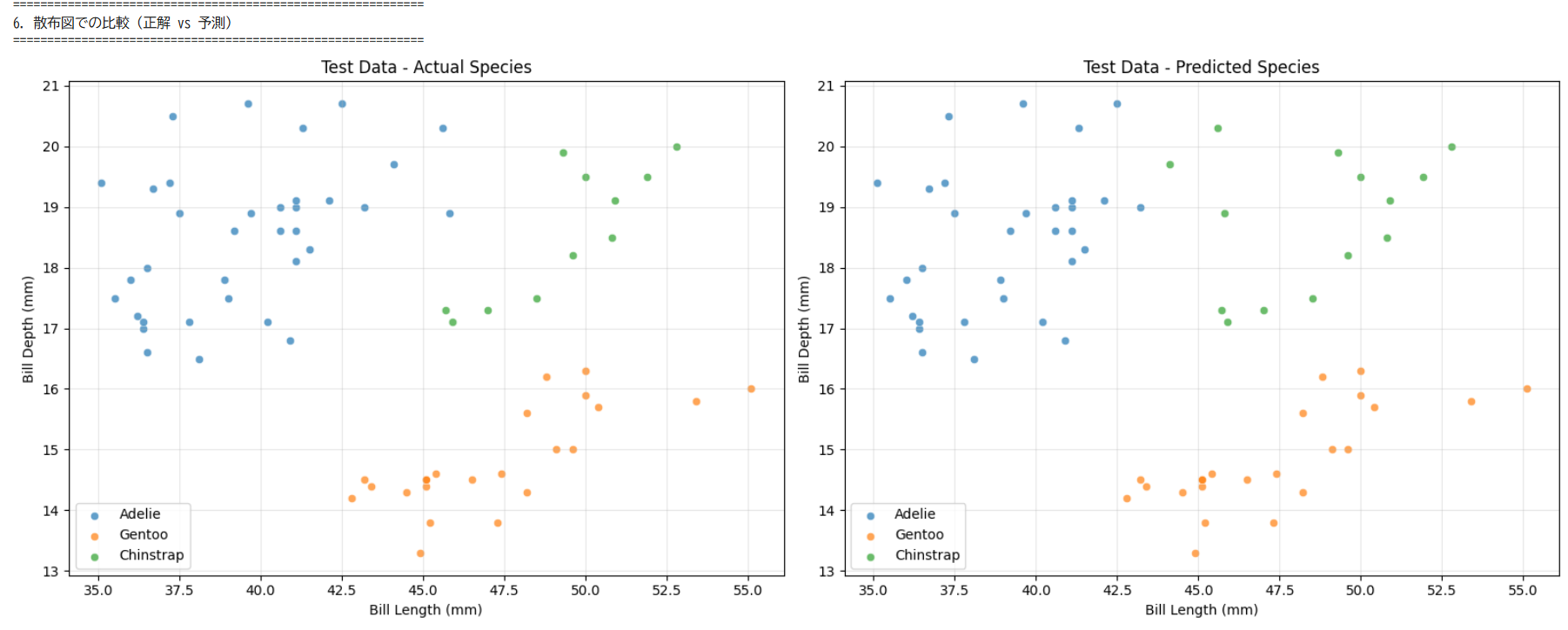
観察と考察 ペンギン3種類の体重データを使い,Excelでヒストグラムを作成する演習である.データの散らばり方(分布)を可視化し,平均だけでは分からない特徴を読み取る. 使用データ:penguins.xls(演習1,2と同じファイルをそのまま使用する) 操作手順 観察と考察 演習1〜3と同じペンギンのデータを使い,機械学習(教師あり学習)でペンギンの種類を自動分類する様子を観察する演習である.演習2の散布図で人間が目で確認した「種類ごとのかたまり」を,コンピュータが自動で分類する仕組みを体験する. 使用データ:penguins.xls(演習1〜3と同じファイル) 実行の流れ 左が実データ。右が機械学習による予測(3種を予測)
観察と考察
[演習で用いたパーマーペンギンデータの準備手順]
演習のパーマーペンギンデータの準備手順を説明しているものであり、各自の演習として取り組む必要はない
スライド資料と演習手順の資料は,https://www.kkaneko.jp/mi/index.html で,各回の授業開始時刻までに掲載します。
セレッソのコースニュースで授業に関するお知らせを配信します。また,小テスト機能で課題を出します。あわせて確認してください。
本科目の資料は,以下の2種類で構成されています。
[演習の詳細を表示するには、この行をクリックしてください]
演習について
演習1. 平均(Excel)
演習2. 散布図(Excel)
演習3. ヒストグラム(Excel)
演習4. 機械学習によるペンギンの種類の自動分類(Google Colab)


https://raw.githubusercontent.com/allisonhorst/palmerpenguins/master/inst/extdata/penguins.csv
第3回. 実データによるデータサイエンス・AIの演習
オープンデータには,政府統計e-Stat,気象データ,GTFS形式の公共交通データ,AED設置場所,感染症動向データなどがある。 利用時は,データの品質や信頼性の確認,著作権の尊重,出典の明示,公開者が定める利用条件の遵守が必要である。 クロス集計表は2つの変数の組み合わせごとに人数等を集計した表である。相関係数は2つの変数の関係の強さを表す数値である。 分析の前に散布図でデータの分布を確認し,サンプル数やデータの偏りの確認も必要である。
スライド資料
[PDF], [パワーポイント] (同じ内容, クリックしてダウンロード)
以下の演習では,説明部分で学んだデータサイエンス・AIの概念を,オンラインデモを通じて体験,さらに,各自データをダウンロードしてExcelを用いて分析する.
演習1と演習2は、「自分が知らなかった事実」を1つでも見つけることが目的である。
演習3と演習4と演習5は、「自分でデータを取得し、自分で分析し、自分で考える」ことを行う。
いずれも、データ分析者としてスキルを磨くことになる。
質問は英語で与える必要がある。
翻訳サイトDeepL:
https://www.deepl.com/ja/translatorを必要に応じて活用して欲しい
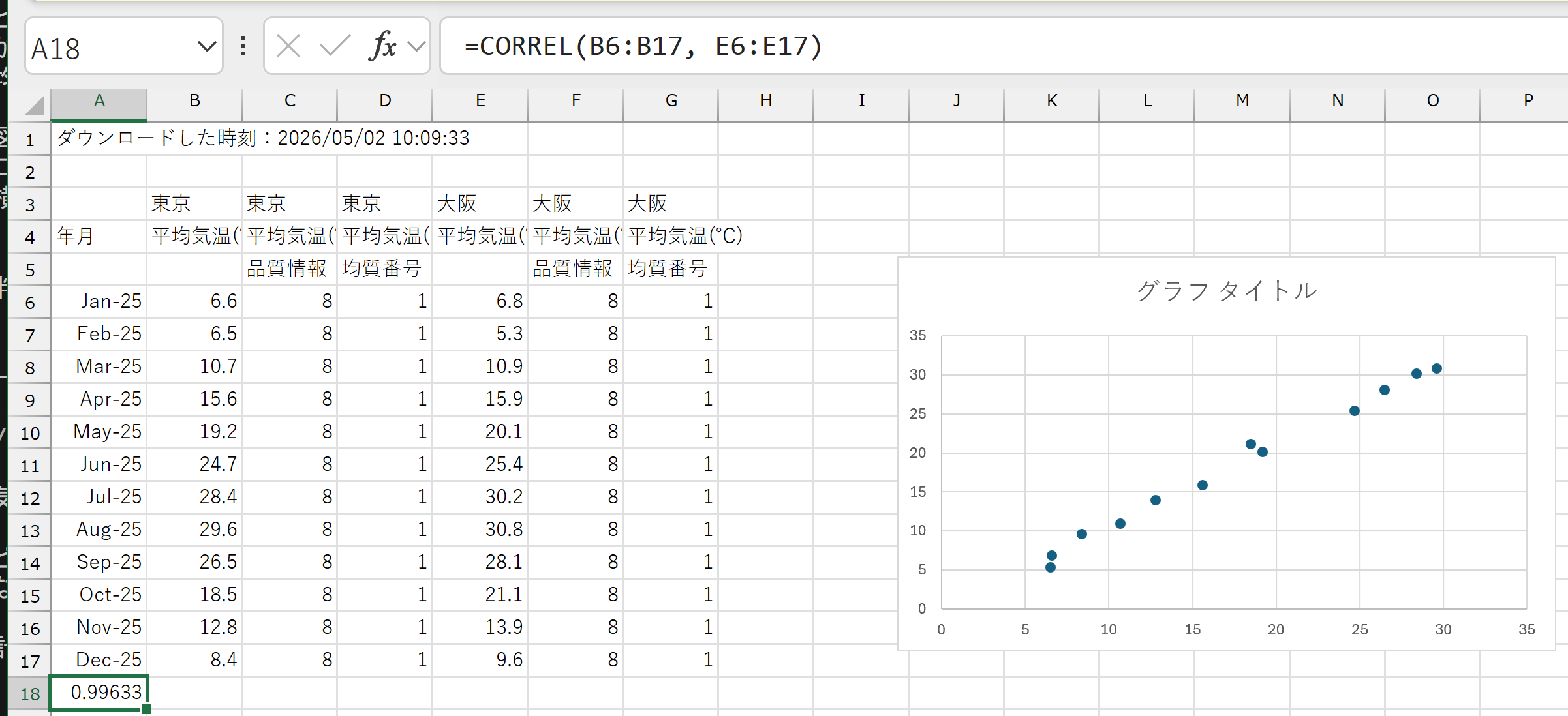
画面が英語で読みにくい場合は、以下の手順でページ全体を日本語に翻訳できる。 手順A:ページ上の文字のない場所(余白)を右クリックする。 手順B:表示されたメニューから「日本語に翻訳」を選ぶ。 手順C:ページ全体が日本語に切り替わる。元の英語に戻したい場合は、アドレスバー右側に表示される翻訳アイコン(丸の中にGの形)をクリックし、「英語」を選ぶ。 注意:Googleの翻訳では、専門用語や固有名詞が不自然な日本語になる場合がある。意味が分かりにくい箇所は、元の英語表示に戻して確認するとよい。 概要 Google Data Commonsは、世界各国の公的機関(日本の国勢調査、米国国勢調査局、世界銀行、WHO、CDC等)が公開する統計データを1か所に集めたオープンデータプラットフォームである。検索欄に英語で質問を入力すると、大規模言語モデル(LLM:Large Language Models、大量のテキストで学習した言語処理AI)が質問を解釈し、統計を地図やグラフで自動的に可視化(データをグラフや地図で見える形にすること)する。 操作手順 手順1:ブラウザで https://datacommons.org/ にアクセスする。 手順2:画面の上部中央の検索欄をクリックする。 手順3:以下のいずれかの質問例をコピーして検索欄に貼り付け、Enterキーを押す。 それぞれの意味は、1つ目が「日本の人口推移」、2つ目が「日本とG7各国の平均寿命比較」、3つ目が「東京の失業率」である。トップページに表示される質問例(Sample questions)をクリックして試してもよい。 手順4:画面に折れ線グラフ・地図・ランキング表などが、データに応じて自動生成されることを確認する。 手順5:グラフ付近にある「About this data」をクリックすると、どの公的機関のオープンデータが使われているかを確認できる。 手順6:画面左上の「DC」のロゴをクリックしてトップページに戻り、別の質問で手順3から繰り返す。最低3つの質問を試す。 体験のポイント 「質問文」の意味をAIが理解し、適切なデータが選択されている。「Unemployment rate in Tokyo (東京の失業率)」のような質問では、このサイトがデータを取得できず結果が得られない。「Unemployment rate in Japan (日本の失業率)」のように変えて試してみる 概要 Gapminder Toolsは、スウェーデンのGapminder Foundation(非営利団体)が運営する世界統計の可視化ツールである。世界銀行、WHO、国連等が公開するオープンデータを用いて、各国の所得・平均寿命・人口等を動くバブルチャートで表示する。時間軸スライダーを動かすと、1800年から現在までの各国の変化をアニメーションで見ることができる。データが存在しない年の値は、前後の年から推定するアルゴリズム(欠損値補完)で埋められている。 操作手順 手順1:ブラウザで https://www.gapminder.org/tools/ にアクセスする。 手順2:初期画面でバブルチャートが表示されることを確認する。画面上部のタブが「Bubbles」になっていることを確認する。 手順3:画面右側の国名リストで「Japan」を探してクリックする、または検索欄に「Japan」と入力する。日本のバブルがハイライト表示される。 手順4:画面下部の再生ボタン(▶)をクリックし、1800年から現在までのアニメーションを見る。日本のバブルがどのように動くかに注目する。 手順5:アニメーション終了後、時間軸スライダーを左右に動かし、日本の軌跡を確認する。 手順6:横軸または縦軸のラベルはメニュー(「Income」「Life expectancy」等)担っている。別の指標に変える。例として「Children per woman」(女性1人あたりの子どもの数)や「CO2 emissions」(CO2排出量)を選ぶ。 手順7:画面下部のボタンで「Bubbles」から「Maps」(地図)、「Ranks」(順位)などに切り替え、同じデータを別の形式で見る。 手順8:横軸や縦軸のラベルを変更。気になる指標について、日本と他国(例:韓国、米国、ブラジル)を比べてみる。 体験のポイント 「所得が上がると平均寿命も延びる」等の相関関係(2つの指標が連動して変化する関係)を、200年分のデータで自分の目で確かめる。 どのサイトの演習でも、相関係数の計算は以下の手順で行う。 手順E1:2列のデータをExcelに用意する(例:A列に指標1、B列に指標2)。1行目は見出しとし、2行目以降にデータを置く。 手順E2:空きセルを選び、 手順E3:Enterキーを押すと、−1から1までの値が表示される。1に近ければ正の相関、−1に近ければ負の相関、0に近ければ相関がほぼないとみなす。 手順E4:2列のデータを選び、「挿入」→「散布図」で散布図を描き、点の並びを目で確かめる。 概要 気象庁が運営する、全国の観測地点の気温・降水量・日照時間等をCSVでダウンロードできるサイトである。観測地点・観測項目・期間を画面上で選ぶだけでデータを取り出せる。登録不要である。 操作手順 手順1:ブラウザで https://www.data.jma.go.jp/risk/obsdl/ にアクセスする。 手順2:画面上部の「地点を選ぶ」をクリックする。都道府県の地図から「東京都」を選び、表示された地点の中から「東京」にチェックを入れる。
「他の都道府県を選ぶ」をクリック。続けて「大阪府」を選び、「大阪」にチェックを入れる。画面右上の「選択済みのデータ量」のバーが上限(100%)を超えないことを確認する。 手順3:「項目を選ぶ」をクリックする。「データの種類」で「月別値」を選び、項目一覧から「月平均気温」にチェックを入れる。 手順4:「期間を選ぶ」をクリックし、「連続した期間で表示する」を選び、年と付きを指定する(例:2025年1月から、2025年12月まで)。 手順5:画面右上の「CSVファイルをダウンロード」ボタンをクリックする。ダウンロードしたCSVをExcelで開く。 手順6:東京の月平均気温と大阪の月平均気温が12か月分並んでいることを確認する。冒頭にヘッダー行が複数行入っている。データ行の先頭を確認する。共通手順E1〜E4に従って平均気温の相関係数を計算。
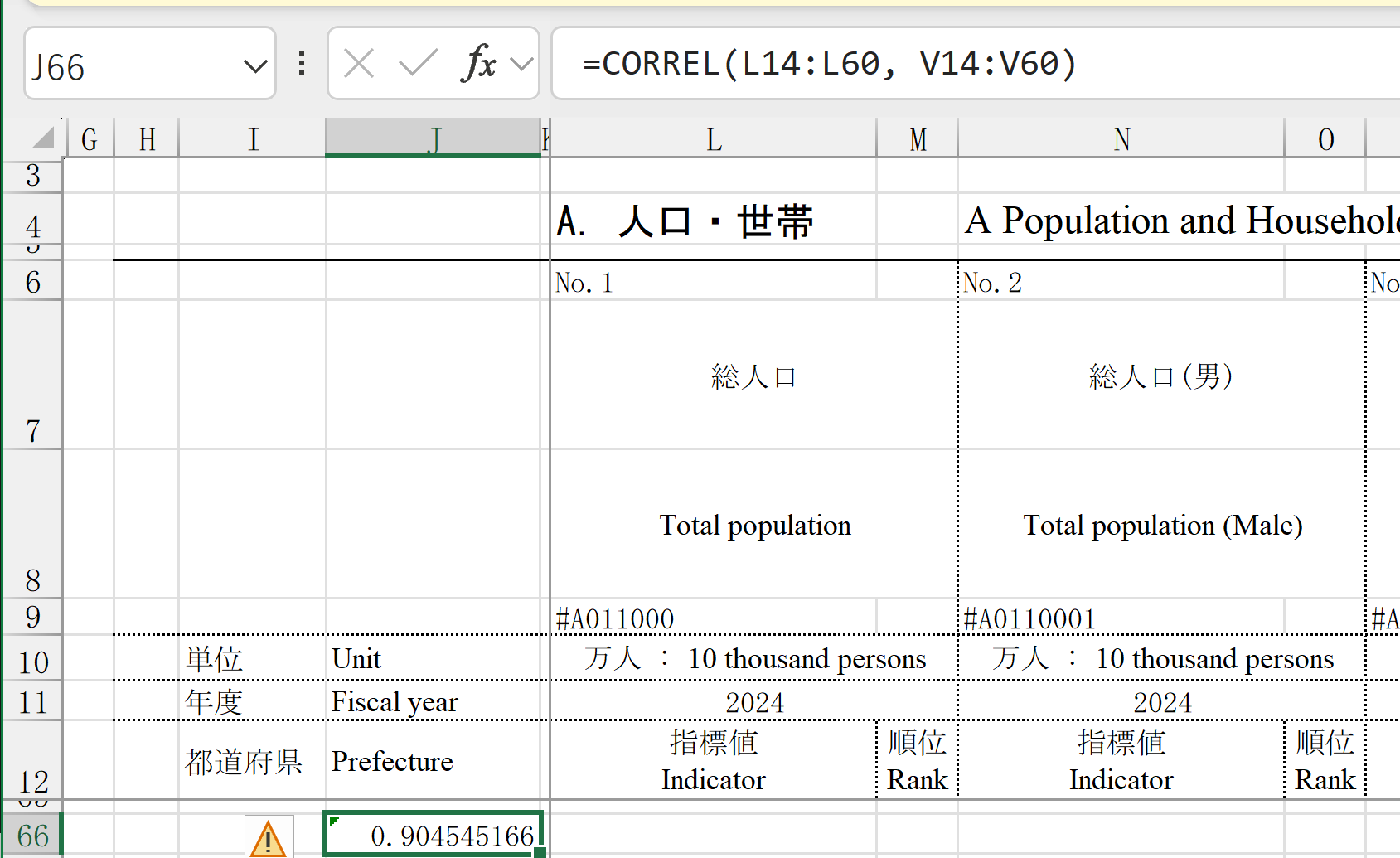
そして、散布図を描く。散布図では、最初に東京の気温12ヶ月分を範囲選択。その次にCTRLキー(コントロールキー)を押しながら、大阪の気温12ヶ月分を範囲選択。これで縦軸と横軸のデータが選択できたので、「挿入」で「散布図》を選ぶ 手順7:相関係数の値から判断(正の相関・負の相関・相関がほぼない)を行う。 手順8:気温以外の他のデータ、東京や大阪以外でも試してみる。 体験のポイント 日本国内の2地点の月平均気温は、季節変動が共通するため正の強い相関(1に近い値)を示すことが多い。余裕があれば、項目を「月降水量」に変えて同じ手順を繰り返し、気温ほど強い相関は出ないことを確かめる。この違いから「何が連動し、何が連動しないか」を自分の目で確かめる。 概要 総務省統計局が毎年刊行している、47都道府県別の統計データ集である。人口、産業、教育、医療、住宅など多数の指標がまとめられ、e-Stat上でExcelファイルとして公開されている。ダウンロードしたExcelには47都道府県×多数の指標が表として並んでおり、相関係数の計算にそのまま使える。登録不要である。 操作手順 手順1:ブラウザで https://www.stat.go.jp/data/k-sugata/index.html にアクセスする。 手順2:右側のメニューで「本書の内容」をクリック。そして、「I 社会生活統計指標」のリンクをクリックする。e-Statの統計表一覧ページに移る。 手順3:一覧の中から関心のある分野のExcelファイル(例:「A 人口・世帯」「E 健康・医療」等)を選び(クリック)、次のページで「表示・ダウンロード」の下のボタンをクリックする。Excel ファイルなどがダウンロードされる。初めて扱う場合は「A 人口・世帯」がわかりやすいだろう。 手順4:ダウンロードしたファイルを開く。「A 人口・世帯」の場合は、シートには47都道府県が行に、指標が列に並んだ表が現れる。冒頭の数行は見出しや説明である。データ行の先頭を確認する。 手順5:興味のある2つの指標を選ぶ。初めて扱う場合は「A 人口・世帯」の「総人口」と「総面積1km2あたり人口密度」がわかりやすい。 手順6:共通手順E1〜E4に従って相関係数を計算。「A 人口・世帯」の「総人口」と「総面積1km2あたり人口密度」の場合は、式は、次のようになる。
そして、前の演習3と同じ手順で、散布図を作成。 手順8:相関係数の値から判断を行う。 体験のポイント
各人の興味に応じて、複数の種類のデータをダウンロード(例:都道府県別の人口、都道府県別の医師数)し、コピー&ペーストにより、1つのExcel のシートの中に2つの異なるデータを並べ、相関係数を計算したり、散布図を作成。
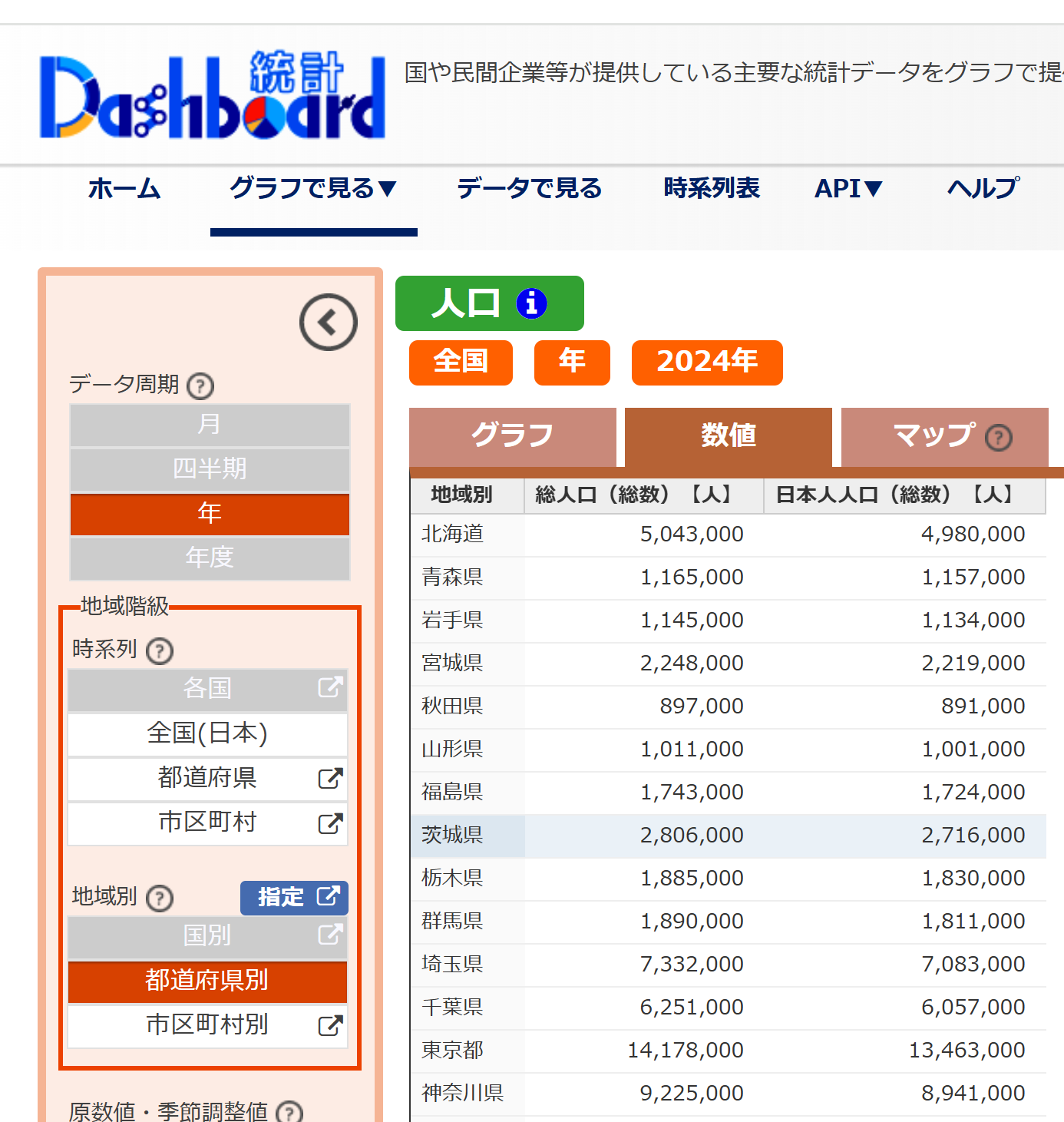
量的に比例する指標は、強い正の相関(1に近い値)を示すことが多い。「比率どうし」(例:高齢化率と持ち家比率)を選ぶと、より興味深い発見が得られる。相関があるからといって因果関係があるとは限らない点に注意する。 概要 政府統計の総合窓口(e-Stat)と連動した、指標ごとのグラフ・ランキングに特化したサイトである。分野別の指標を選び、47都道府県の値をグラフや表で確認できる。登録不要である。 操作手順 手順1:ブラウザで https://dashboard.e-stat.go.jp/ にアクセスする。 手順2:画面上部のメニュー「グラフで見る」にカーソルを合わせ、サブメニューから分野(例:「人口・世帯」)を選ぶ。または同じサブメニューにある「都道府県へ」をクリックして都道府県別の指標一覧を直接開いてもよい。 手順3:分野内の指標一覧から、都道府県別に比較できる指標(例:「総人口」)を選ぶ。 手順4:グラフが表示されたら、
今度は、
画面の左側にあるメニューでデータ周期として「年」を選び、下の地域別で「都道府県別」などを選ぶ。 手順5:グラフが表示されるので確認する。上のタブで「数値」を選ぶ。表示された表を選択してコピーし、Excelに貼り付ける。画面にダウンロードボタン(CSVなど)がある場合はそれを使ってもよい。 手順6:同じ要領で、別の指標(例:「(季節調整値)完全失業率」)を取得し、同じExcelシートに貼り付ける。都道府県名の並びを必ず揃える。 手順7:共通手順E1〜E4に従って相関係数を計算。そして、散布図を作成。 手順8:相関係数の値から判断を行う。 体験のポイント 演習④で扱った指標とは別の組合せ(例:人口×失業率、人口×新設住宅着工戸数)を試すと、意外な結果が得られることがある。相関係数が0.3程度の場合、「相関があるとは言い切れない」と判断する慎重さが必要である。
[演習の詳細を表示するには、この行をクリックしてください]
演習について
翻訳サイト
Chromeブラウザの翻訳機能の使い方
演習① 質問を理解するAI 「Data Commons」
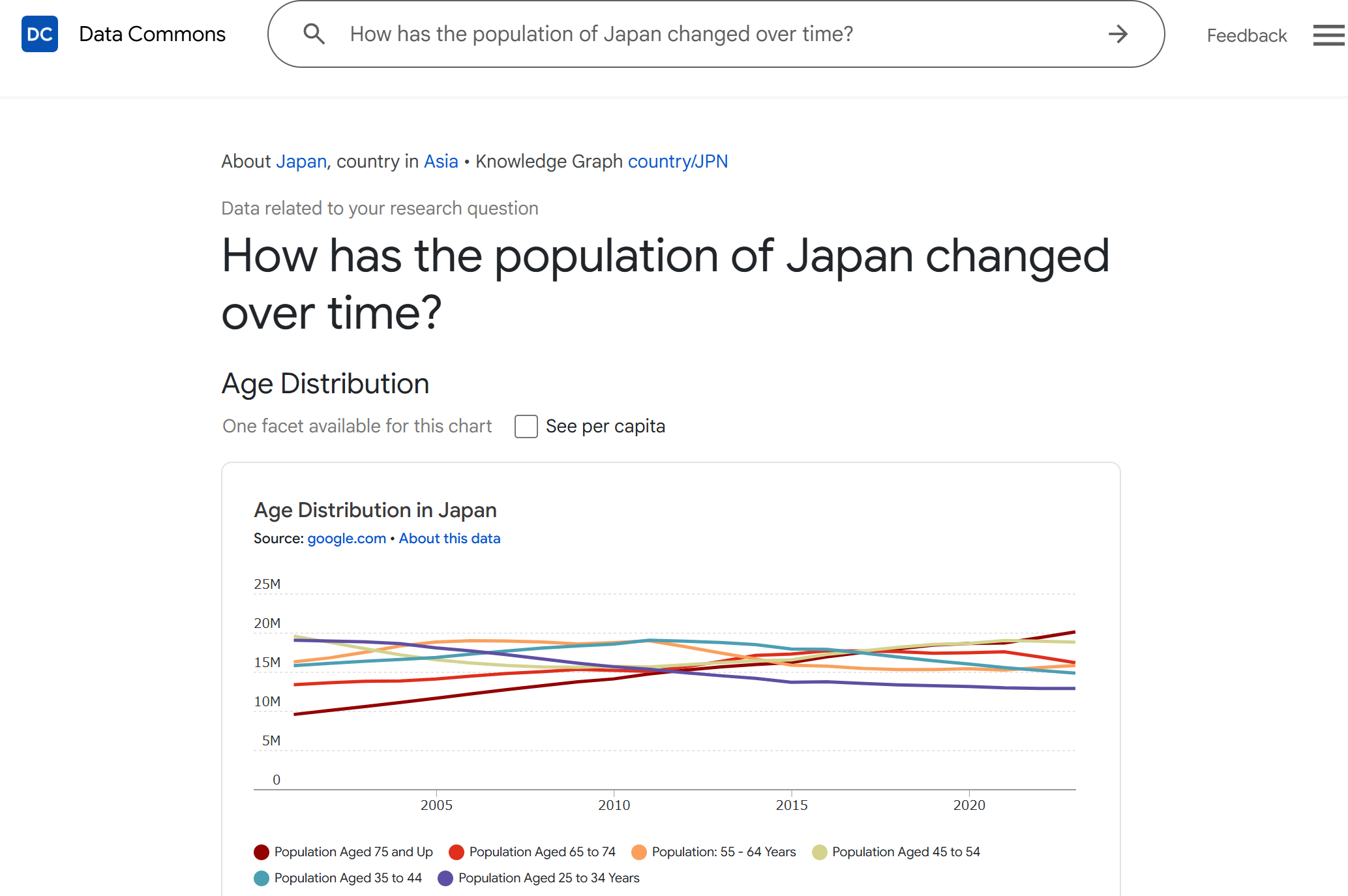
How has the population of Japan changed over time?Life expectancy in Japan compared to other G7 countriesUnemployment rate in Tokyo演習② データの隙間を埋めるAI 「Gapminder」
Excelで相関係数を求める手順
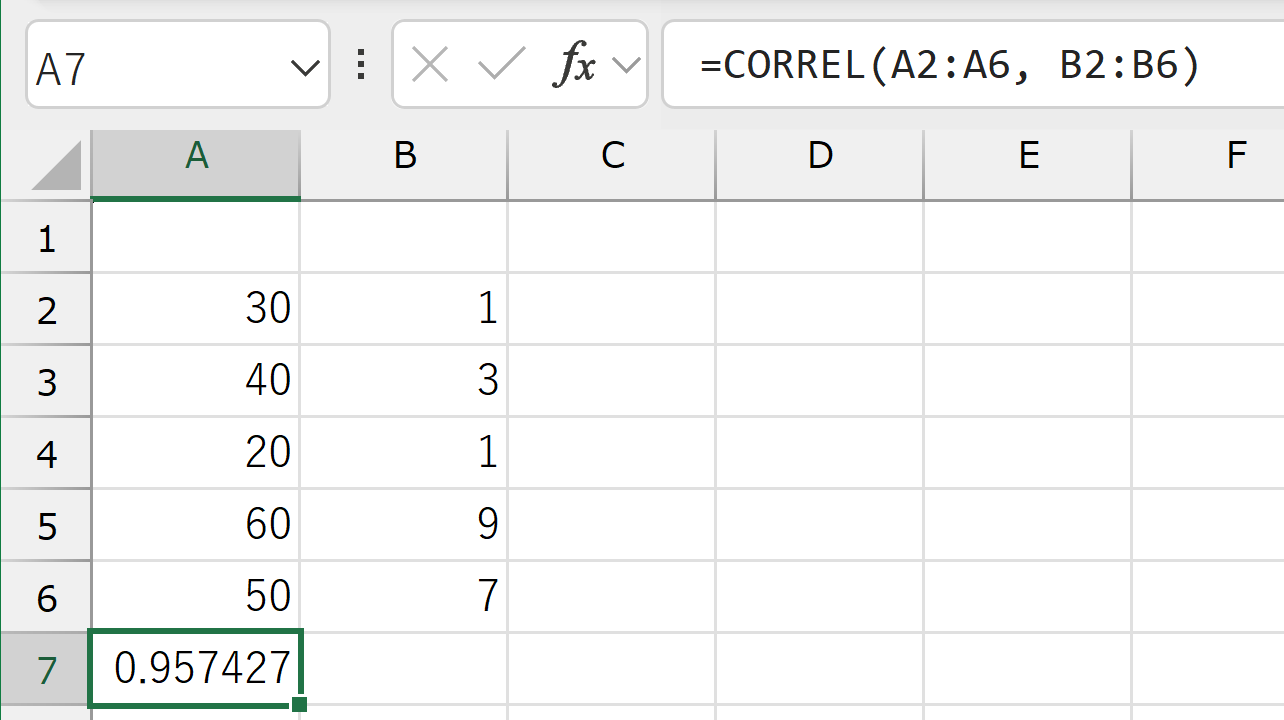
=CORREL(A2:A48, B2:B48) のように入力する。範囲は自分のデータ件数に合わせて変える。演習③ 過去の気象データ・ダウンロードと相関の分析
演習④ 総務省統計局「統計でみる都道府県のすがた」から相関の分析
=CORREL(L14:L60, V14:V60)
演習⑤ e-Stat「統計ダッシュボード」から相関の分析
aa-4. 機械学習,ニューラルネットワーク
機械学習は,コンピュータがデータを使用して学習し知的能力を向上させる技術で,データからパターンや関係性を自動で発見する。 入力と正解の組(例:手書き数字画像と数字ラベル)を訓練データとして用いる方式を教師あり学習と呼び,他に教師なし学習や強化学習がある。 ニューラルネットワークは脳のニューロンを模した構造で,入力の重みづけ,合計とバイアス,活性化関数の適用を経て順伝播する。 その学習は予測と正解の誤差を小さくする最適化であり,バックプロパゲーションにより各層の重みとバイアスを更新する。
スライド資料
[PDF], [パワーポイント] (同じ内容, クリックしてダウンロード)
画面が英語で読みにくい場合は、以下の手順でページ全体を日本語に翻訳できる。 手順A:ページ上の文字のない場所(余白)を右クリックする。 手順B:表示されたメニューから「日本語に翻訳」を選ぶ。 手順C:ページ全体が日本語に切り替わる。元の英語に戻したい場合は、アドレスバー右側に表示される翻訳アイコン(丸の中にGの形)をクリックし、「英語」を選ぶ。 注意:Googleの翻訳では、専門用語や固有名詞が不自然な日本語になる場合がある。意味が分かりにくい箇所は、元の英語表示に戻して確認するとよい。 Quick, Draw! は,Googleが公開する機械学習の体験サイトであり,登録不要で利用可能である.ユーザが描いた絵を,ニューラルネットワークがリアルタイムで分類する.本演習では,機械学習が持つ知的能力(分類,認識)を体験することを目的とする. Quick, Draw! のサイト:https://quickdraw.withgoogle.com/ 操作手順 Quick, Draw! のサイト:https://quickdraw.withgoogle.com/ ヒント 考察ポイント Neural Network Playground は,カリフォルニア大学サンディエゴ校(UCSD)のCCoMが公開するWebサイトであり,登録不要で利用可能である.ニューラルネットワークの最小構成を体験できる.ニューロンの数を1個から変化させながら,分類の境目の形状がどのように変化するかを観察できる.本演習では,「ニューラルネットワークは,ニューロンがネットワークを形成する」という仕組みを,最小構成で確認することを目的とする. Neural Network Playground:https://www.ccom.ucsd.edu/~cdeotte/programs/neuralnetwork.html 注意:本サイトは英語で表示される.操作要素はスライダーとボタンのみであり,英語が不得意でも操作に支障はない. 操作手順 Neural Network Playground:https://www.ccom.ucsd.edu/~cdeotte/programs/neuralnetwork.html ヒント 考察ポイント A Machine Learning Playground(Scienxlab版)は,ニューラルネットワークの学習過程を対話的に可視化するWebサイトであり,登録不要で利用可能である.ニューロンの数,活性化関数,学習の速さなどを変更して,学習をリアルタイムに実行できる.本演習では,「入力の重みづけ,合計とバイアス,活性化関数の適用」「ニューラルネットワークのパラメータ(重みやバイアス)を最適化する」という仕組みを総合的に体験する. A Machine Learning Playground:https://playground.scienxlab.org/ 本サイトは,Googleが公開する TensorFlow Playground(https://playground.tensorflow.org/)の拡張版である.UIと基本操作は原版と同一であり,活性化関数の種類と利用できるデータの追加などの拡張が施されている.他の教材や書籍で「TensorFlow Playground」という名称に出会った際は,同系統のツールである.原版も同じ操作方法で利用できる. 事前準備:演習②を先に体験しておくと理解しやすい. 注意:本サイトは英語で表示される.操作要素は主にボタンとドロップダウンメニューであり,英語が不得意でも直感的に操作できる. 操作手順 A Machine Learning Playground:https://playground.scienxlab.org/ ヒント 考察ポイント
スライド資料と演習手順の資料は,https://www.kkaneko.jp/mi/index.html で,各回の授業開始時刻までに掲載します。
セレッソのコースニュースで授業に関するお知らせを配信します。また,小テスト機能で課題を出します。あわせて確認してください。
本科目の資料は,以下の2種類で構成されています。
[演習の詳細を表示するには、この行をクリックしてください]
Chromeブラウザの翻訳機能の使い方

演習① Quick, Draw! の体験


カヌー)が表示される.「OK」をクリックして開始する.
演習② Neural Network Playground の体験

H=9 と表示されたスライダーを確認する.H は,ネットワーク内部のニューロンの数を表す.H=1)まで動かす.ニューロンが1個のみとなり,分類の境目が直線1本になることを観察する.H=2,H=3,H=4 と増やしていく.分類の境目が,直線の組み合わせから複雑な形状に変化していく様子を観察する.H=9)まで動かす.赤と青の点の配置にもよるが、曲線的で複雑な分類の境目が形成されることを観察する.
H=1)と,多くした場合(H=9)とで,それぞれ,どのようなデータが正しく分類できるかを考察する.演習③ A Machine Learning Playground の体験

aa-5. 深層学習(ディープラーニング)
【トピックス】
人工知能, ニューラルネットワーク, ディープラーニング, ユニット, 活性化, 結合の重み, 活性化関数, 伝搬, ニューラルネットワークを用いた分類, ニューラルネットワークを用いた学習
【概要】
ニューラルネットワークは、複数のユニットが結合し、各ユニットは入力の重み付けや活性化関数の適用を行う。 構造は、層構造で全結合のものが最もシンプルで、データは入力から出力への一方向に流れ、各層のユニットは全結合される。 結合の重みやバイアスの調整により望みの出力を得る。 ディープニューラルネットワークは層が多いニューラルネットワークで、多層でも学習が成功するためのさまざまな工夫が必要とされる。
【関連するページ等】
- YouTube 動画 https://www.youtube.com/watch?v=spEQ_kztHAQ
【関連する外部ページ】
- Office 365 オンライン版 https://portal.office.com
- TensorFlow の仕組み https://playground.tensorflow.org
Excel ファイル(各自の演習に活用)
- 活性化関数: 53.xlsx
aa-6. 画像分類システム
【トピックス】
人工知能, 画像と画素, 濃淡画像のデータ, ニューラルネットワークを用いた分類, 画像分類システム, ニューラルネットワークの作成, 学習, 画像分類
【概要】
画像分類システムは、画像を特定のカテゴリに分類するもので、 手書き文字認識やパターン認識等に応用される。 画像分類は、ニューラルネットワークを使用して可能である。 ニューラルネットワークは機械学習の一種で、パターンや関連性を学習する。 画像分類システムでは、ニューラルネットワークの最終層のユニットで最も活性度の高いものを選択するという仕組みで分類が行われる。 画像分類システムは広範に活用されており、具体的な学習はTensorFlowの公式チュートリアル等を通じて可能である。
【関連するページ等】
- 手書き文字認識(Google Colaboratory) 実行結果とプログラムと説明を見るだけなら, Google アカウントは不要 https://colab.research.google.com/drive/1IfArIvhh-FsvJIE9YTNO8T44Qhpi0rIJ?usp=sharing
- YouTube 動画 https://www.youtube.com/watch?v=WYoevH_C1Is
【関連する外部ページ】
- 画像分類(TensorFlowの公式チュートリアル) 左側のメニューで「KerasによるMLの基本」を展開し, 「基本的な画像分類」をクリック 画像を10種類に分類。訓練データは60,000枚の画像と正解。検証データは10,000枚の画像と正解 https://www.tensorflow.org/tutorials
aa-7. 学習と検証,学習不足,過学習,学習曲線
【トピックス】
人工知能, 機械学習, 汎化, 汎化の失敗, 学習の繰り返し, 学習曲線
【概要】
機械学習は訓練データから学習し、未知のデータに対しても適切に処理できる「汎化」能力を持つ。 学習の過程は、訓練データでの誤差を減らすよう重み調整し繰り返すものだが、過学習となり未知データでの誤答が増える場合がある。 そのため、検証データを用いて過学習の確認が必要で、学習曲線はその一助となる。 最近の技術進展により過学習防止の技術が進展している。過学習の防止には大量データによる学習も大切である、コンピュータの高速化も一定の助けとなっている。
【関連するページ等】
- 手書き文字認識(Google Colaboratory) 実行結果とプログラムと説明を見るだけなら, Google アカウントは不要 https://colab.research.google.com/drive/1IfArIvhh-FsvJIE9YTNO8T44Qhpi0rIJ?usp=sharing
- YouTube 動画 https://www.youtube.com/watch?v=Qh-pu3Fvvuc
【関連する外部ページ】
- オーバーフィットとアンダーフィット(TensorFlowの公式チュートリアル) https://www.tensorflow.org/tutorials/keras/overfit_and_underfit?hl=ja
aa-8. 人工知能とコンピュータビジョン
【トピックス】
人工知能, コンピュータビジョン, 畳み込み, プーリング, 畳み込みニューラルネットワーク, 物体検出, セグメンテーション, 顔情報処理, 姿勢推定
【概要】
コンピュータビジョンはコンピュータが実世界を理解・活用する技術で、 画像理解、物体検出、セグメンテーションなどが重要な要素である。 ディープニューラルネットワークや畳み込みにより、これらの精度向上が進んでいる。 畳み込みはデータとカーネルを重ね合わせて一つの値にまとめる手法である。 コンピュータビジョンは他にもある。 顔情報処理は顔検出、顔ランドマーク、顔のコード化、顔識別などがあり、 本人確認や表情推定、年齢判定など多岐にわたり利用される。 姿勢推定は人体の姿勢をAIで把握する技術で、 状況把握、行動予測、行動検知、危険察知などに応用される。
【関連するページ等】
- 畳み込みニューラルネットワーク, 学習, 検証, 学習曲線について https://colab.research.google.com/drive/18IPPkY96Oc6jkYD2su4cFgWcoYAskLo_?usp=sharing
- YouTube 動画 https://www.youtube.com/watch?v=8e6YqUl32gQ
【関連する外部ページ】
- CNN Explainer ジョージア工科大学 Polo Club 畳み込み層などの仕組みをビジュアルに学ぶことができるサイト https://poloclub.github.io/cnn-explainer/
- OneFormer のデモサイト 画像のセグメンテーション https://huggingface.co/spaces/shi-labs/OneFormer
- コンピュータビジョンのデモサイト https://cloud.google.com/vision/docs/drag-and-drop
aa-9. 遷移関数、知的なゲーム世界の実現
【トピックス】
人工知能の種類、知的なゲームのルール、状態空間表現
YouTube 動画: https://www.youtube.com/watch?v=ftSktLFJ3y4
- 知的なゲームのルール,コンピュータプレイヤーがゲームに参加,状態空間表現
- 知的なゲーム(ゲームのルールと勝利条件が定まっているもの)で, コンピュータが,ゲームのプレイヤーになる.
- そのための基礎として「状態空間表現」という方法を使い,コンピュータでもゲームのルールを扱えるようにすることを学ぶ.
- 9-3. ゲームのルールのプログラミング
【関連する外部ページ】
OnlineGDB の URL: https://www.onlinegdb.com/
右上の「language」で「Python 3」を選ぶこと.
プログラムの実行開始は「Run」,実行停止は「Stop」
Python プログラムのソースコード
a = 0 while(True): print('a = %d' % a) r = int(input()) if (r == 1) and (a < 21): a = a + 1 if (r == 2) and (a < 21): a = a + 2 if (r == 3) and (a < 21): a = a + 3- 9-4. コンピュータ・プレイヤーがゲームに参加
GDB online: https://www.onlinegdb.com/右上の「language」で「Python 3」を選ぶこと.
プログラムの実行開始は「Run」,実行停止は「Stop」
Python プログラムのソースコード
def computer(a): if( a == 1 ): return 3 elif( a == 2 ): return 2 elif( a == 3 ): return 1 elif( a == 5 ): return 3 elif( a == 6 ): return 2 elif( a == 7 ): return 1 elif( a == 9 ): return 3 elif( a == 10 ): return 2 elif( a == 11 ): return 1 elif( a == 13 ): return 3 elif( a == 14 ): return 2 elif( a == 15 ): return 1 elif( a == 17 ): return 3 elif( a == 18 ): return 2 elif( a == 19 ): return 1 else: return 0 def move(a, r): if (r == 1) and (a < 21): a = a + 1 if (r == 2) and (a < 21): a = a + 2 if (r == 3) and (a < 21): a = a + 3 return a a = 0 while(True): print('a = %d' % a) r = int(input()) a = move(a, r) print('a = %d' % a) r = computer(a) print('computer: %d' % r) a = move(a, r)aa-10. 遷移関数、探索、総当たり
【トピックス】
総当たり、総当たりのパス、状態空間表現での総当たり、パスと木、Python による総当たり
YouTube 動画: https://www.youtube.com/watch?v=o_Ms27QaSsg
この回で学ぶこと.- 総当たりにより,正解を探索する.
- 総当たりは「正解を確実に探索できる方法」とも考えることができる.
- 状態空間表現(世界の状態が変数で表されている)でのルールをもとに 変数値を変化させてゴール(目的とする変数の値)に至ることを探索.
- 10-4. 状態空間表現での総当たりをコンピュータで動かす
GDB online: https://www.onlinegdb.com/
右上の「language」で「Python 3」を選ぶこと.
プログラムの実行開始は「Run」,実行停止は「Stop」
Python プログラムのソースコード
import itertools import sys def move(x, y, r): success = False if (r == 1) and (x < 1): x = x + 1 success = True if (r == 2) and (x > 0): x = x - 1 success = True if (r == 3) and (y < 2): y = y + 1 success = True if (r == 4) and (y > 0): y = y - 1 success = True return(x, y, success) nsteps = 3 seq = [1, 2, 3, 4] success = False for j in list(itertools.product(seq, repeat=nsteps)): x, y = 0, 0 for i in j: x, y, success = move(x, y, i) if(not(success)): break if(success): print("%s %d %d" % (str(j), x, y))- 10-6. 2つの水差しを総当たりで扱う
GDB online: https://www.onlinegdb.com/右上の「language」で「Python 3」を選ぶこと.
プログラムの実行開始は「Run」,実行停止は「Stop」
Python プログラムのソースコード
パスの長さ 2 で,総当りで調べるプログラム
- 2つの水差し(4リットルと,3リットル).
- 初期状態: x=0, y=0
import itertools import sys def move(x, y, r): success = False if (r == 1) and (x < 4): x = 4 success = True if (r == 2) and (x > 0): x = 0 success = True if (r == 3) and ((x + y) >= 3) and (y < 3): x, y = x + y - 3, 3 success = True if (r == 4) and ((x + y) <= 3) and (x > 0): x, y = 0, x + y success = True if (r == 5) and (y < 3): y = 3 success = True if (r == 6) and (y > 0): x = 0 success = True if (r == 7) and ((x + y) >= 4) and (x < 4): x, y = 4, x + y - 4 success = True if (r == 8) and ((x + y) <= 4) and (y > 0): x, y = x + y, 0 success = True return(x, y, success) nsteps = 2 seq = [1, 2, 3, 4, 5, 6, 7, 8] success = False for j in list(itertools.product(seq, repeat=nsteps)): x, y = 0, 0 for i in j: x, y, success = move(x, y, i) if(not(success)): break if(success): print("%s %d %d" % (str(j), x, y))- 10-6. 2つの水差しを総当たりで扱う
パスの長さ 3 の総当りにより,ゴール状態にできるかを調べるプログラム
- 2つの水差し(4リットルと,3リットル).
- 初期状態: x=0, y=0
- ゴール状態: x=3, y=0
import itertools import sys nsteps = 3 goal = (3, 0) path=[1,2,3,4,5,6,7,8] for j in list(itertools.product(path, repeat=nsteps)): x, y = 0, 0 for i in j: if i == 1 and x < 4: x, y = 4, y elif i == 2 and y < 3: x, y = x, 3 elif i == 3 and x > 0: x, y = 0, y elif i == 4 and y > 0: x, y = x, 0 elif i == 5 and (x + y) >= 3 and y < 3: x, y = x + y - 3, 3 elif i == 6 and (x + y) >= 4 and x < 4: x, y = 4, x + y - 4 elif i == 7 and (x + y) <= 3 and x < 0: x, y = 0, x + y elif i == 8 and (x + y) <= 4 and y > 0: x, y = x + y, 0 if ( goal == (x, y) ): print("%s %d %d" % (str(j), x, y))aa-11. パス、木、発見的探索
YouTube 動画: https://www.youtube.com/watch?v=72AKU8Nh8tY
この回で学ぶこと- パス,木,グラフは,情報を見通し良く扱えるための考え方
- 総当たりはすべての経路(パス)を試すもの.経路 (パス)の情報を見通し良く扱うには,木が有効.
- 探索は,木の中のスタートの場所と,ゴールの状態 を指定して経路(パス)を探す.
- 探索は,正解に至る経路(パス)があるのであれば,必ず経路(パス)を見つけることができる.
- 探索には,種々の方法があるが,正解に至る経路(パス)があるのであれば,必ず経路(パス)を見つけることができることに変わりはない.
外部ページへのリンク(作者に感謝します).- VisuAlgo の URL: https://visualgo.net/ja
最小全域木を選ぶ.全域木は,グラフの全ノードを網羅する木
- qito.github.io の URL: https://qiao.github.io/PathFinding.js/visual/
迷路作成,A* 法と総当たりでの迷路探索の違いを見る
- https://www.growingwiththeweb.com/projects/pathfinding-visualiser/
- パスと木
aa-12. プロダクションシステム,知識表現,推論エンジン
YouTube 動画: https://www.youtube.com/watch?v=72AKU8Nh8tY
この回で学ぶこと.プロダクションシステム
- 作業領域
作業領域には「知識」のデータを置く。知識は、変化するものである。 知識は、次のような形で書くことができる。
['体毛', 'ある']
['肉食', 'する']
- 推論エンジン
ルールを用いて作業領域を変化させるという推論を行う
- ルール
ルールは既存の知識から新しい知識を生み出したり、知識を変化させるためのルールである。 次のように書くことができる。
'体毛' = 'ある'→ ['種類', '哺乳類']
'種類' = '哺乳類' and '肉食' = 'する' → ['種類', '肉食動物']
- 12-1. 知識表現
m = {'x': 0, 'y': 0} print(m) - 12-2. 知識表現の例
m = {'taimou': True, 'nikusyoku': True} print(m) - 12-3 プロダクションシステム
m = {'taimou': True, 'nikusyoku': True} def rule(m): changed = False if m['taimou'] == True: m['syurui'] = 'honyurui' changed = True if m['syurui'] == 'honyurui' and m['nikusyoku'] == True: m['syurui'] = 'nikusyokudoubutsu' changed = True print('----start----') print(m) while(True): if rule(m) != True: break print('----finished----') print(m) - 12-4. 知識表現のバリエーション
m = {'ichiro': {'has': 'ball'}, 'jiro': {'has': 'none'}, 'saburo': {'has': 'none'}} print(m)別のプログラム
m = {'ichiro': {'has': 'ball'}, 'jiro': {'has': 'none'}, 'saburo': {'has': 'none'}} def rule(m): changed = False if m['ichiro']['has'] == 'ball': m['ichiro']['has'] = 'none' m['jiro']['has'] = 'ball' changed = True return changed print('----start----') print(m) while(True): if rule(m) != True: break print('----finished----') print(m)
aa-13. 述語、Prolog
今回の授業で学ぶこと.- 事実を述語の形で書くことができる.述語は,1項,あるいは,複数項の関係のこと
- john は男である
male(john). 1項
- mike は john の親である
parent(mike, john). 2項
複数項のときは,カンマで区切る
- john は男である
- 述語でのルールの例
X が Y の parent (親) ならば, Y は X の child (子供) である
child(Y, X) :- parent(X, Y).
X,Y は変数
- Prolog
Prolog では,問い合わせに対し事実との照合や推論を行う. 問い合わせでは, 値 false, trueを回答したり, 変数値 X = hanako, X = taro を回答する能力を持つ
aa-14. 自然言語処理
この回で学ぶこと- 自然言語処理
人間の言葉を、コンピュータが処理すること
- 自然言語処理の種類
- 単語の切り出し
- 品詞の判定
- 構文解析(係り受けなどの関係の分析)
- 意味解析
aa-15. 全体まとめ,発展
Python プログラムのソースコードなど
- ニューラルネットワークを作るプログラム (Python)
import tensorflow as tf import keras from keras.models import Sequential m = Sequential() from keras.layers import Dense, Activation, Dropout import keras.optimizers m.add(Dense(units=64, activation='relu'))', input_dim=4)) m.add(Dense(units=3, activation='softmax'))')) m.compile(loss=keras.losses.categorical_crossentropy, optimizer=keras.optimizers.SGD(lr=0.01, momentum=0.9, nesterov=True))ニューラルネットワークの確認表示 (Python)
print(m.summary())
ニューラルネットワークの学習を行うプログラム (Python)
import numpy as np x = np.array( [[0, 0, 0, 0], [0, 0, 0, 1], [0, 0, 1, 0], [0, 0, 1, 1], [0, 1, 0, 0], [0, 1, 0, 1], [0, 1, 1, 0], [0, 1, 1, 1], [1, 0, 0, 0], [1, 0, 0, 1], [1, 0, 1, 0], [1, 0, 1, 1], [1, 1, 0, 0], [1, 1, 0, 1], [1, 1, 1, 0], [1, 1, 1, 1]]) y = np.array( [0, 0, 0, 2, 0, 1, 0, 0, 0, 0, 1, 0, 2, 0, 0, 0]) m.fit(x, keras.utils.to_categorical(y), epochs=500)
ニューラルネットワークによる分類 (Python)
m.predict( np.array([[0, 1, 0, 1]]) )m.predict( np.array([[1, 0, 1, 0]]) )m.predict( np.array([[1, 1, 0, 0]]) )
m.predict( np.array([[0, 0, 1, 1]]) )
第1層と第2層の間の結合の重みを表示 (Python)
m.get_weights()[2]- 11. グラフと全域木
外部ページへのリンク(作者に感謝します).- VisuAlgo の URL: https://visualgo.net/ja
最小全域木を選ぶ.全域木は,グラフの全ノードを網羅する木
- 11. A*法の実演(迷路作成,A*法と総当たりでの探索の違い)
外部ページへのリンク(作者に感謝します).- qito.github.io の URL: https://qiao.github.io/PathFinding.js/visual/
迷路作成,A* 法と総当たりでの迷路探索の違いを見る
- https://www.growingwiththeweb.com/projects/pathfinding-visualiser/
- パスと木
GDB online: https://www.onlinegdb.com/右上の「language」で「Python 3」を選ぶこと.
プログラムの実行開始は「Run」,実行停止は「Stop」
m = [['x', 0], [y', 0]] print(m)- 13. Prolog の実演
外部ページへのリンク(作者に感謝します).- SWISH のページ: https://swish.swi-prolog.org/
Prolog プログラムのソースコード
human(hanako). human(taro). think(X) :- human(X).- 13. Prolog の実演(true, false を得る問い合わせ)
外部ページへのリンク(作者に感謝します).- SWISH のページ: https://swish.swi-prolog.org/
Prolog プログラムのソースコード
male(ali). female(zeyn). female(anne). parent(ali, anne). parent(zeyn, anne). child(Y, X) :- parent(X, Y).- 15. 強化学習
強化学習により,コンピュータは,迷路からの脱出に上達する.
迷路は配列(アレイ)で作っている.サイズは 9 × 9. 値「1」は壁で,値「0」が通路.迷路の出口は,一番右下の「0」としている.
下のプログラムでは 200回の学習を繰り返している
強化学習による迷路脱出プログラム.「下に行くべき」のスコア算出 (Python)
import numpy as np from scipy import * import sys, time from pybrain.rl.environments.mazes import Maze, MDPMazeTask from pybrain.rl.learners.valuebased import ActionValueTable from pybrain.rl.agents import LearningAgent from pybrain.rl.learners import Q, SARSA from pybrain.rl.experiments import Experiment from pybrain.rl.environments import Task structure = array([[1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 0, 0, 1, 0, 0, 0, 0, 1], [1, 0, 0, 1, 0, 0, 1, 0, 1], [1, 0, 0, 1, 0, 0, 1, 0, 1], [1, 0, 0, 1, 0, 1, 1, 0, 1], [1, 0, 0, 0, 0, 0, 1, 0, 1], [1, 1, 1, 1, 1, 1, 1, 0, 1], [1, 0, 0, 0, 0, 0, 0, 0, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1]]) environment = Maze(structure, (7, 7)) controller = ActionValueTable(81, 4) controller.initialize(1.) learner = Q() agent = LearningAgent(controller, learner) task = MDPMazeTask(environment) experiment = Experiment(task, agent) for i in range(200): experiment.doInteractions(100) agent.learn() agent.reset() print( np.round( controller.params.reshape(81,4)[:,0].reshape(9,9), 2) )強化学習による迷路脱出プログラム.「右に行くべき」のスコア算出
import numpy as np from scipy import * import sys, time from pybrain.rl.environments.mazes import Maze, MDPMazeTask from pybrain.rl.learners.valuebased import ActionValueTable from pybrain.rl.agents import LearningAgent from pybrain.rl.learners import Q, SARSA from pybrain.rl.experiments import Experiment from pybrain.rl.environments import Task structure = array([[1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 0, 0, 1, 0, 0, 0, 0, 1], [1, 0, 0, 1, 0, 0, 1, 0, 1], [1, 0, 0, 1, 0, 0, 1, 0, 1], [1, 0, 0, 1, 0, 1, 1, 0, 1], [1, 0, 0, 0, 0, 0, 1, 0, 1], [1, 1, 1, 1, 1, 1, 1, 0, 1], [1, 0, 0, 0, 0, 0, 0, 0, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1]]) environment = Maze(structure, (7, 7)) controller = ActionValueTable(81, 4) controller.initialize(1.) learner = Q() agent = LearningAgent(controller, learner) task = MDPMazeTask(environment) experiment = Experiment(task, agent) for i in range(200): experiment.doInteractions(100) agent.learn() agent.reset() print( np.round( controller.params.reshape(81,4)[:,1].reshape(9,9), 2) )
人工知能デモサイトの紹介
- スタイル変換
- AutoDraw, https://www.autodraw.com/
- Variational AutoEncoder https://magenta.tensorflow.org/sketch-rnn-demo
- edges2cats: https://affinelayer.com/pixsrv/index.html
- 画像分類: https://clarifai.com/demo
- 11. グラフと全域木
- 10-6. 2つの水差しを総当たりで扱う
- 9-4. コンピュータ・プレイヤーがゲームに参加