2021年度卒業論文配属サポートページ
研究活動のガイダンス
研究室の方針と研究の進め方
-
11/24 ガイダンス
- 教員自己紹介 金子邦彦
-
卒論テーマ
人工知能応用、データベース応用、データベース高速処理、3次元データベース、ビッグデータ処理(センサーによる車両や人流の観測と把握)に関する分野である。
-
実績
科研費多数、研究費のべ1億円以上、論文等数十、教科書3冊、授業担当のべ約20以上、学会や国レベルの委員等の実績、卒論・修論・博士論文実績数十名以上、Webページでの広報等: https://www.kkaneko.jp、YouTubeチャンネルでの広報等である。
-
研究を効率よく、やる気を維持して行うには
- 楽しく、仲間によい影響を与える
- 原理原則、基礎、ものごとの本質をとらえる
- 仮説、実験、考察の手順を踏む。記録が大事である。伝えることも大事である。グループワークも大事である。
-
行事予定
- 7月:中間発表、学会活動(原稿)、11月:学会プレゼン、12月:卒論、卒論プレゼン、3月:学会プレゼン(学会は希望者のみ)
-
9/2 研究室の考え方
対面での活動は中止した。次のことをメールでお伝えした。
-
総括
テーマ決め(興味関心のあるテーマを自分で定める)、目的の設定(課題発見)、調査、実験、結論、考察を行う。分かりやすい説明(ワード、パワーポイント、ポスター)を作成する。質疑を通して、自分を高める(他の人の揚げ足を取ったり、他の人の指摘をすることではない)。データなどの根拠を使って説明する。
-
研究室の9月以降の考え方
-
「毎日学校に来て、自由に自主的に活動する(活動したい)」という考え方について
コロナ対策のため、今年は次のようにしたい。レベル1では、週1回または2回または3回の集合日を定め、仲間同士で自由な情報交換(研究のことも、研究以外のことも)を行う。集合日以外のときに研究室に来るのは問題ないこととする(健康状況調査を各自応じること)。
- 自主的に学び向上するものである。
- 先生が「正解」を与えて、それを作業してもらうものではない。
-
それぞれ形態が違う。
ある人は、調査したり、私の研究室のホームページを見たりして学ぶ。ある人は、写真を撮影したりなどの活動を行う。ある人はプログラムを作ったり、改良したり、他の人が作ったプログラムで学ぶ。ある人は、アイデアを考える。
- 新しい発見を目指していただく。
- 新しい発見を目指せているかどうかについては、各自、自分で点検したり、仲間からの意見を聞いたり、指導教員に自主的に相談すること。
-
とても大切なことは、データや根拠を自分で示すことである。
根拠の無い例:データや根拠なしで、意見やアイデアのみ。例えば「1000枚の画像があればうまく行きそう」というとき、実際に1000枚近い画像を自分で集めてチャレンジするか、あるいは、1000枚も画像を集めずに済む別の研究テーマを考えていただくことになる。研究では、データや根拠を大事にする。
- 失敗は問題としない。質疑で「知らない」と正直に答えることは、関係ないことを答えるよりも良いことである。
- 困っていることがあるとき、先生や他の仲間に聞いてみることは良いことである。勉強の効率が良くなる可能性がある。
-
学校に来て、自分が何を活動するかは、自分自身で決めていただくことになる。
自宅での活動も、行っていただいている(自宅の方が活動しやすいときがある)ことはあろうが、学校に来ての活動は、その良さがある。集合日を定め、お集まりいただくことは続ける。
-
「毎日学校に来て、自由に自主的に活動する(活動したい)」という考え方について
-
総括
研究テーマの検討と基礎
-
6/4 ニューラルネットワークの用途
ニューラルネットワークの用途は次の通りである。
- 分類
- 予測
- 合成(翻訳や、フェイクビデオの合成など)
- 認識(顔認識、物体認識、ポーズの認識など)
分類は、いろいろ種類があるが、「画像分類」について、一連の流れを説明する。
流れ:ニューラルネットワークの作成、学習、検証である。
この流れは、ニューラルネットワークを使い学習するというときは、だいたい同じである。
画像分類のニューラルネットワークは、既存の研究としてCNN(Convolutional Neural Network)(畳み込みニューラルネットワーク)がある。CNNにも様々種類がある。
様々あるCNNは、インターネットでダウンロードして使うことができる。学習済みのCNNを、インターネットでダウンロードして使うこともできる。
-
5/25 研究の基礎
研究室の諸君による提案とフィードバックを行った。皆さんの検討を誇らしく思う。
皆さんの提案は、それぞれ、個性あり、特色のあるものであった。各人の提案の個性を尊重したいため、私が、そのままコピー&ペーストすることは避ける。どのような提案がなされたかの内容を、次のようにまとめ、皆さんとシェアしたい。
人工知能の良さは、コンピュータに学習能力等を持たせる技術であることである。人間の想定を超えた学習がありえる。人工知能の学習のためには、大量のデータが必要であるし、学習に適した優れたデータを必要とする。
-
人工知能、そして、画像処理の基礎となる技術
- ディープニューラルネットワークのモデル
- ディープニューラルネットワークの学習
- ディープニューラルネットワークの学習のためのデータセット
- 機械学習(最近傍、決定木などで、データの自動分類を行う技術)
-
3次元世界のデジタル化
- レーザーレンジファインダ等による計測技術。機器の精度や機器の解像度や機器の計測範囲にも注意を要する。
- 複数画像からの立体再構成(Structure from Motionなど)
- 立体再構成の結果を使った自己位置推定(自分のカメラの位置と向きの推定)、それによる測量
- 質感の再現(画像処理、CGのテクスチャマッピングなど)
-
顔認証、顔識別、画像認識の技術
- 顔識別のための、前処理として、顔のアラインメント
- 顔のランドマーク(眉毛、目、鼻、口、顔の輪郭など)
- 顔のランドマークからの表情判定
- まばたきの識別
- 顔のランドマークや、顔の姿勢を、3次元モデルにリアルタイムに反映させて、3次元モデルを動かしたり、変形する技術
-
人工知能、そして、画像処理の基礎となる技術
-
5/21 宿題について
各自「研究したいこと」を行うには、何の技術を使いますか。そして、その技術がうまく動く「基礎」は何であろうか。
-
5/18 研究テーマの確認
次の問いを、金曜日13時30分までの宿題とする。
各自「研究したいこと」を行うには、何の技術を使いますか。そして、その技術がうまく動く「基礎」は何であろうか。
- 基礎も大事にする。
- 中間発表の材料にもなる。
- 自分が調べたことを、他の人とシェアする体験を行っておく。
- 今後、各自、調査、実験計画、実験準備、考察、目標決めなどの活動を自主的に行っていただくことに変わりない。
各自の研究テーマの確認を行った。人工知能応用、3次元データベースの分野であった。各自が自己考察を開始するきっかけとなることも願っている。
-
5/14 年間スケジュールの確認
皆さんの不安がないこと。楽しく(無用なストレスなく)実験や調査などの取り組みができること。コロナ禍に正しく対応すること。年間スケジュールを再確認すること。卒論のテーマについて、各自で考察すること。
卒業論文と発表
卒業論文の作成
-
11/22 卒業論文提出について
-
卒論で求めることは次の通りである。実験データ、考察、丁寧な説明、元気なプレゼンである。
- 実験データの説明:計測方法、得られた分量、そのときに失敗したこと、もう一度やり直すとしたらどうするか。
- 考察:成功か失敗か。改良するとしたらどうなるか。比較した結果どうなったか。自分なりの工夫。従来の同様の研究の調査結果。
- 丁寧な説明を書くこと。ぜひ練習すること。根拠を付ける。手順の説明を丁寧に書く。グラフや表で示すなどの工夫。
-
大学に来たら試してほしいこと。研究室のパソコンから、次のページにアクセスできるようにしている(無線LANからはアクセスできない)。
https://www.kkaneko.jp/lab/sotu2020/s/
先輩の資料である。大いに参考にすること(コピー&ペーストは不可である)。
- 締め切りの前(3日前くらいまで)に提出すること。読み返して返答する。
-
-
8/11 追加実験とワード原稿
追加実験の上、ワードの原稿を提出すること。
- 追加実験を考えていただくのは必須である。
- さらなる考察、根拠となるデータや調査結果を自分で説明することを意識する。
-
ワードファイルの原稿のテンプレート
https://rentai-chugoku.org/guideline.html で公開されている「Word版」を使用する。
- 1ページでもよいし、2ページでもよい。
- 8/11に金子に提出する(早めに終わるのが楽であるが、間に合わない人は事前に連絡すること)。
- 中間発表でみなさん自身が考えた回答を、ここに含めたり、卒論に含めるのは歓迎である。
中間発表
-
8/6 中間発表について
中間発表で、再発表対象者には連絡が行われた。
-
8/4 中間発表の総括
中間発表の総括、今後のスケジュールなどを説明した。
説明資料: [PDFファイル], [パワーポイントファイル]
-
7/27 中間発表開始
全員が中間発表を開始した。全員がeラーニングの受講を終えた。
-
7/7 中間発表ポスターの書式
中間発表ポスターの書式: https://cerezo.fukuyama-u.ac.jp/ct/course_688085_rptadmpreview_762520
学会発表
-
10/23 中国支部連合大会
中国支部連合大会での学会発表を行った。
-
8/27 法政大学との遠隔セミナー
- 全員研究発表を行った。
- 1人あたり、最大20分程度(質疑込み)。
- ZOOMを用いた実施。
本学からの発表
小寺裕也(コデラ ユウヤ,福山) 福山大学の三次元地図作成 佐藤彰紘(サトウ アキヒロ) (福山) 人物挙動分析のための屋内三次元地図の作成実験 新川涼太(シンカワ リョウタ,福山) 複数顔写真からの3次元モデル構成による3次元アバターの実現 石丸弘樹(イシマル ヒロキ) (福山) 部分隠蔽された顔画像での顔識別とランドマーク検出実験 寺田みのり(テラダ ミノリ,福山) 人工知能による顔情報処理システムと顔分析
-
8/25 登校日、パワーポイント準備
13:30 集合、各自作業開始 14:00ごろ 金子から、簡単な説明(添付のPDFファイル2つと、パワーポイントファイルを使用) その後、各自、卒研を進め、パワーポイントを金子にメール提出(電子メールで)、解散 添付のパワーポイントは、先輩が作ったものである、見本として活用できる。 今日、登校できない人でも、パワーポイントを金子にメール提出(電子メールで)することを、各自で行っていただく。 <説明内容> ・今後のスケジュール 週1回の登校、週2回の配信を再開する 27日のZOOMセミナー(他大学合同)は予定通り行う ・8月25日の進行 予定通り、各自、パワーポイントの準備。楽しんで行うこと。 チェックリスト 1.楽しむ 2.パワーポイントの見本を使う 3.たっぷり、ゆっくり説明する気持ちを持つ ・すべてを説明する気持ちをもつ ・能力向上のため、次を気を付ける 分かりやすい説明になっているか? を自己チェックする。 自分が行いたいこと、実験手順、実験結果、考察について、なるべく詳しく説明を書く。 「添付のワードファイル」の内容を、丸ごと、パワーポイントに載せるのは良いアイデアである。 中間発表のときに自分で答えた内容を、コピーして、整えるのは良いアイデアである。 語りかけるように、「相手が知らないだろう」と思われる難しい言葉などは、丁寧に説明する(語ってもよいし、資料に説明してもよい) 4.パワーポイントをメール提出。明日の夜までにフィードバックする可能性がある(パワーポイントファイルを書き換えて返す場合がある)
3次元データ処理と空間情報
3D都市モデルとオープンデータ
-
11/21 ZOOM配信:3D都市モデル(Project PLATEAU)
関連ページ: https://www.kkaneko.jp/sample/index.html
3D都市モデル(Project PLATEAU)福山市(2020年度)
-
建物のデータ
頂点数: 8,697,252, 三角形ポリゴン数: 7,325,893
-
地形データ (dem)
頂点数: 23,684,818, 三角形ポリゴン数: 47,272,932
-
建物と地形 (dem) の重ね合わせ例
重ね合わせは手作業で行っている。重ね合わせ結果では、建物と道路がずれている。
-
建物のデータ
-
5/11 OpenStreetMapとBlenderで3次元地図
オープンな世界地図OpenStreetMap(自由編集可能な世界地図データベース)をBlenderで利用し、3次元地図を作る。
OpenStreetMapのURL: https://openstreetmap.jp#zoom=7&lat=38.06539&lon=139.04297&layers=B0FF
-
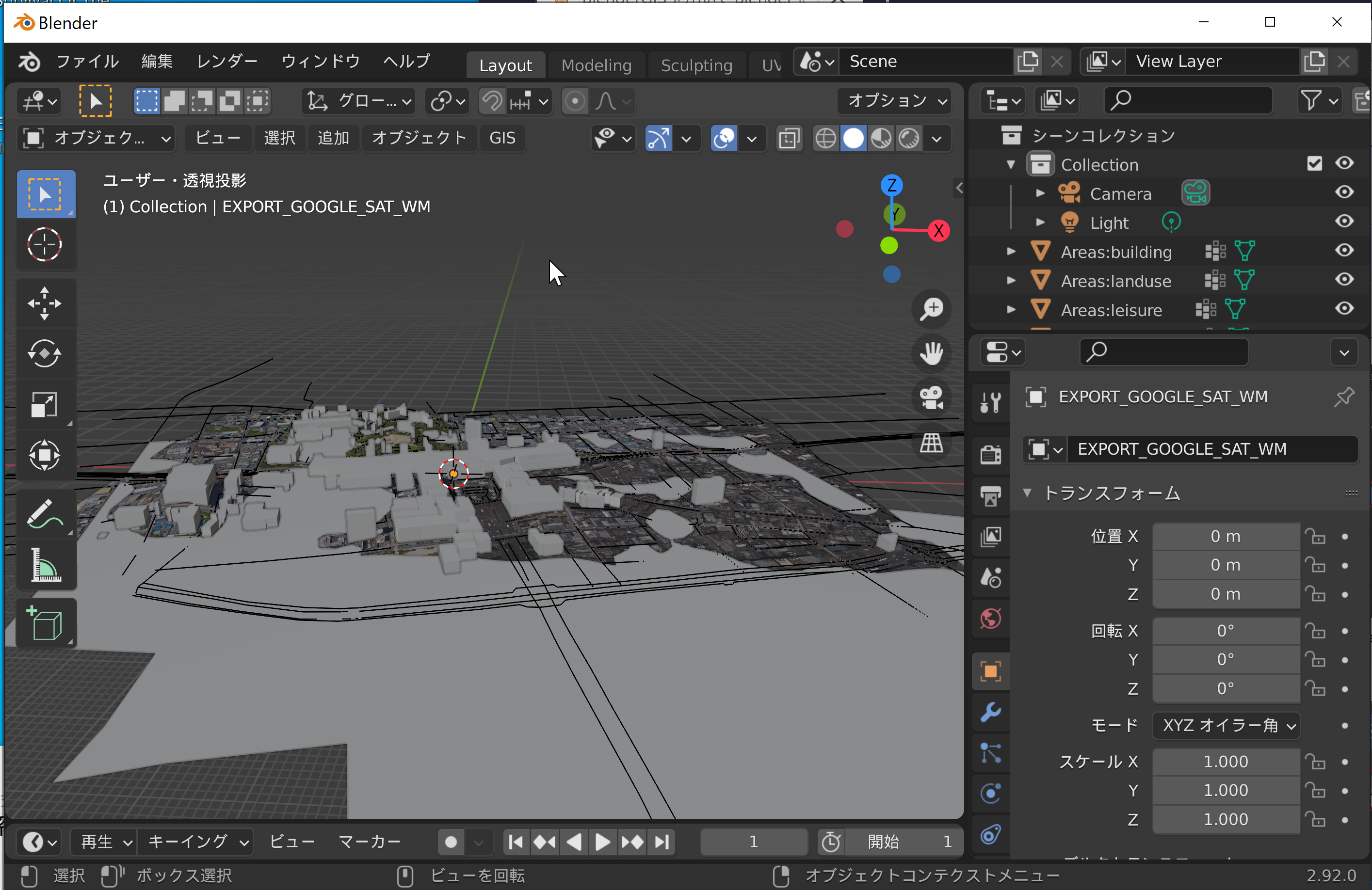
3/23 Blender GISで標高・建物データインポート
オープンデータ(建物や地形のオープンデータ)を活用して、3次元地図を作成する(データの著作権は製作者にあり、適切な利用を心がけること)。
写真からの3次元再構成(SfM・MVS)
-
11/24 3次元データベース、Meshroom説明
3次元データベース,写真からの3次元再構成(写真測量)(Meshroomを使用) [PDF], [パワーポイント]
- テーマ名:3次元データベース,写真からの3次元再構成(写真測量)
- 内容:写真をもとに、立体再構成(写真測量)を行う。
- 事前準備:NVIDIA GPU搭載のパソコンが必要である。
- 基礎:画像の特徴点、Structure from Motion技術
- 実習で行うこと:写真をもとに、立体再構成(写真測量)を行う。
-
実習手順
公開されている次のソフトウェアを使用する(利用条件等は、利用者で確認すること)。
-
宿題あり(授業時間中に実施)
2グループ(または3グループ)でのグループワーク。計画を立てる(何を撮影するか。現地で決めてもよい)。撮影する。撮影結果を提出する(その確認は、次回授業で行うこととする)。撮影枚数は、各グループで50から100枚程度。提出するのは来週火曜日の授業のときとする。
-
11/12 福山大学ビデオ3次元化(SfM, MVS, Meshroom)
福山大学のビデオ、3次元化(SfM(複数画像から3D構造を復元する技術), MVS(多視点画像から高密な3D点を生成する技術))
現時点の成果物
URL: https://www.kkaneko.jp/sample/index.html#3
Meshroom(オープンソースの3D再構成ソフトウェア)での処理結果(1秒あたり4コマの画像に変換ののちMeshroomで処理)
-
10/1 動くオブジェクトの3次元化
オブジェクトの周囲から撮影して、3次元化する立体再構成について説明する。
従来技術(SfM, MVSと言われる)は完成の域にあり、Meshroomというソフトもある。そのとき、オブジェクトは動いてはいけないとなっていた。
2020年発表の技術は、オブジェクトは動いていても大丈夫、スマホで撮影、3次元を推定という技術が登場している。次のページに、実際に作成された動画が公開されているので紹介する。なめらかである。なお、1秒のビデオを処理するのに10分かかるのが目安になるようである。
https://roxanneluo.github.io/Consistent-Video-Depth-Estimation/
-
7/16 Meshroom参考資料
3次元点群処理
-
7/13 Open3Dによる3次元点群処理
3次元点群の表示、ダウンサンプリング、Convex hull、DBSCANクラスタリング、平面のセグメンテーションの例を示す。
3Dモデリングとテクスチャマッピング
-
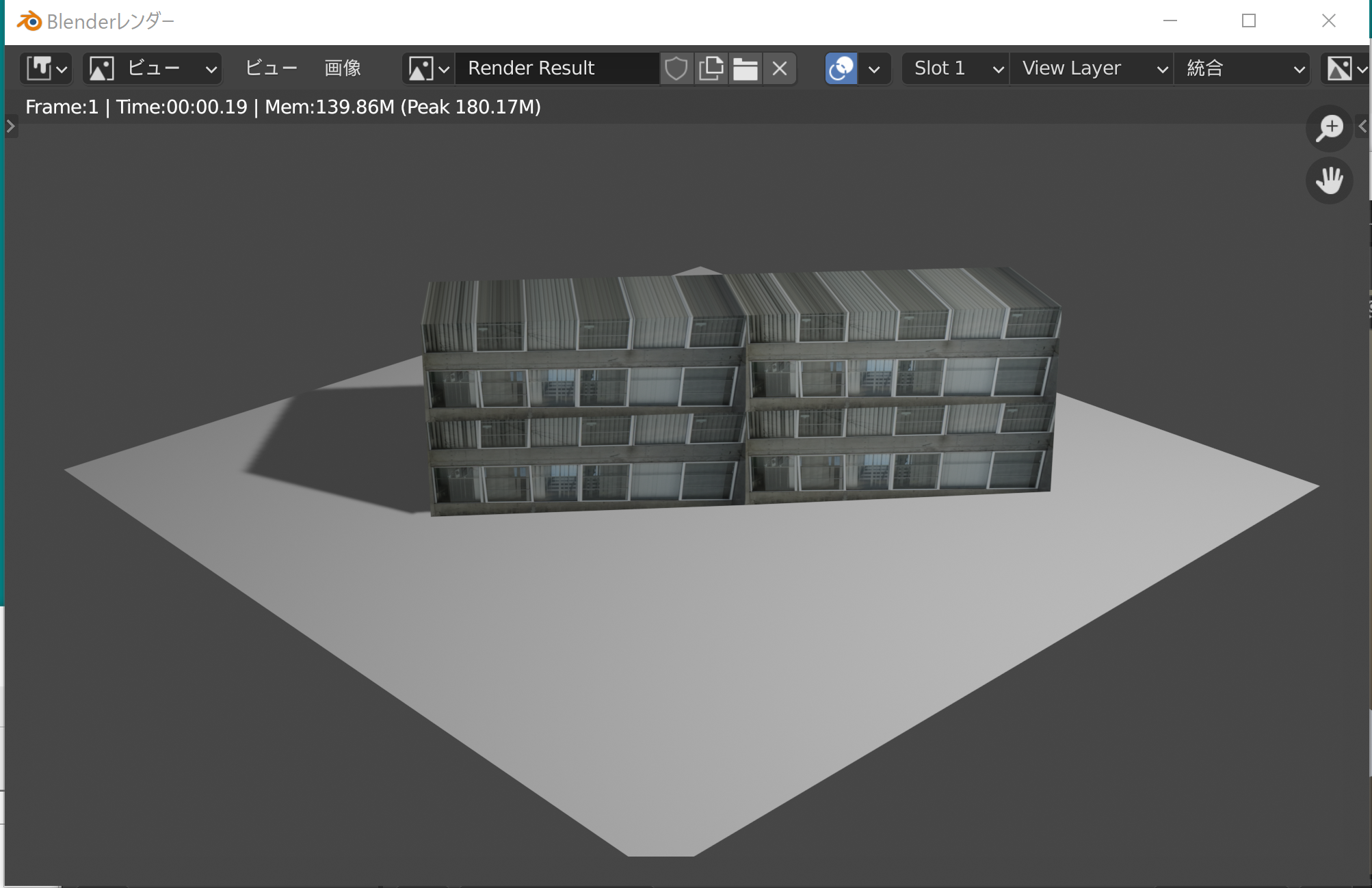
7/30 写真のテクスチャマッピング(Blender)
写真のテクスチャマッピングを行う。写真、Blenderのシェーダーの設定、できた画像は次の通りである。


サイト内の関連ページ
- 福山大学の建物写真: https://www.kkaneko.jp/sample/photo-2017-12-03/index.html
-
Blenderのテクスチャマッピングについて:https://www.kkaneko.jp/db/cg/shadereditor.html
写真を取り込むときは「追加」で「テクスチャ」で「画像テクスチャ」である。
3次元物体検出と姿勢推定
-
10/5 Objectron(3D物体検出・姿勢推定)
3次元の姿勢推定 (Pose Estimation)について説明する。画像から、オブジェクトを検出するとともに、その向きの推定も行う。
Objectron(3D物体検出・姿勢推定用データセット)は、公式ページで、プログラムとデータセットが配布されている。
https://github.com/google-research-datasets/Objectron
Objectronは、Google Colaboratoryで動かすことができる。Google Colaboratoryで動かすときは、コードセルに、次の3行を張り付けて実行する。あとは、公式ページのプログラムのコピー&ペーストで動く。
!pip3 install frozendict !git clone --recursive https://github.com/google-research-datasets/Objectron %cd Objectron
顔認識と顔情報処理
顔検出と顔識別
-
12/1 Dlib機能概要
説明資料: Dlib(機械学習・画像処理ライブラリ)の機能概要 [PDF], [パワーポイント]
顔検出、顔のアラインメント、顔認識、表情や顔の向きの観測について説明する。これらは認証、人数カウント、人流計測、集団様態分析のベースとなる技術である。
- 顔認識の例
-
Dlibを用いた画像分類、物体検出、ランドマーク検出
Dlibは、上で示した「顔認識」の基礎でもある。
- Dlibによる顔検出を行うPythonプログラム(Dlib, Pythonを使用)(Windows上)
- Dlibによる顔のアラインメント、顔データの増量、顔のランドマーク、顔のコード化(Dlib、Pythonを使用)(Windows上)
- 1adrianb/face-alignmentのインストールと動作確認(顔の2次元、3次元のランドマーク)(PyTorch、Python 3.7を使用)(Windows上)
-
表情判定
ezgiakcora/Facial-Expression-Kerasのインストールと動作確認(表情推定)(Dlib、Pythonを使用)(Windows上)
https://github.com/ezgiakcora/Facial-Expression-Keras で公開されている成果物を使用する。 -
顔識別
face_recognitionによる顔検出、顔識別(Dlib、ageitgey/face_recognition、Pythonを使用)(Windows上)
https://github.com/ageitgey/face_recognition で公開されている成果物を使用する。 -
頭部の姿勢推定
-
頭部の姿勢推定を行ってみる
このページで、前半部分(準備の部分)は終えている。スクロールして、「lincolnhard/head-pose-estimationによる頭部の姿勢推定」のところから取り組む(プログラムの書き換えの作業がある)。
-
頭部の姿勢推定を行ってみる
-
瞳孔の検出
-
TobiasRoeddiger/PupilTrackerのインストールと動作確認(瞳孔の検出)(Dlib、Pythonを使用)(Windows上)
このページで、前半部分(準備の部分)は終えている。スクロールして、「TobiasRoeddiger/PupilTrackerによる瞳孔の検知」のところから取り組む(プログラムの書き換えの作業がある)。なお、表示結果では、赤いマークは目の下の中央、緑のマークが瞳孔である。
-
TobiasRoeddiger/PupilTrackerのインストールと動作確認(瞳孔の検出)(Dlib、Pythonを使用)(Windows上)
-
9/10 DeepFace(ArcFace法による顔認識)
DeepFace(多機能な顔認識ライブラリ)は、ArcFace(高精度な顔認識のための深層学習手法)法による顔認識の機能や、顔検出、年齢や性別や表情の推定の機能などを持つ。使い方を説明する。Google Colabを使うが、パソコン(Windows, Linux)でも動く。使い方は、1つのフォルダに認識させたい顔画像をすべて入れ、所定のコマンドを実行する。
ArcFace法は、距離学習の技術の1つである。画像分類において、種類が不定個であるような画像分類に使うことができる技術である。顔のみで動くということではないし、顔の特徴を捉えて工夫されているということもない。
DeepFaceのURL: https://github.com/serengil/deepface
ArcFaceの概要は次の通りである。
- 顔のコード化:顔画像を、数値ベクトル(数値の並び)に変換する。
- 顔のコードについて、同一人物の顔のコードは近くになるように、違う人物の顔のコードは遠くなるように、顔のコードを作り直す。そのときディープラーニングを使う。これを「距離学習」という。
- 距離学習の学習済みモデルを使う。距離学習がなかったときと比べて、顔認識の精度の向上が期待できる。
次のプログラムはGoogle Colaboratoryで動く(コードセルを作り、実行すること)。
!pip3 install deepface !git clone --recursive https://github.com/serengil/deepface from deepface import DeepFace import pandas as pd from deepface import DeepFace import pandas as pd pd.set_option('display.max_rows', None) print(pd.get_option('display.max_rows')) df = DeepFace.find(img_path="./deepface/tests/dataset/img38.jpg", db_path="./deepface/tests/dataset", distance_metric='euclidean') a = df.sort_values('VGG-Face_euclidean') print(a) obj = DeepFace.analyze(img_path = "./deepface/tests/dataset/img38.jpg", actions = ['age', 'gender', 'emotion']) print(obj)ディレクトリ内の全画像ファイルとの顔識別を行い、それぞれの顔画像ファイルとの距離を表示する。
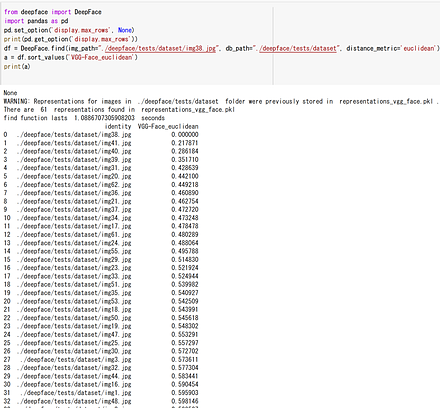
年齢、性別、表情の推定を行う。

-
9/7 SCRFD法によるマスク有り顔検出
SCRFD (Sample and Computation Redistribution for Face Detection)(効率的な顔検出手法)法によるマスク有り顔画像での顔検知について説明する。
ResNet(残差学習を用いた深層ニューラルネットワーク)(ディープニューラルネットワーク、画像分類や物体検知等に利用されている)の改良である。ResNetをベースとしているので、オブジェクトが大きく隠れていても、精度よく物体検出できる。さまざまな大きさの顔を精度良く検知できる工夫、小さな顔についても精度よく検知できる工夫が行われている。
性別と年齢の推定結果を示す。
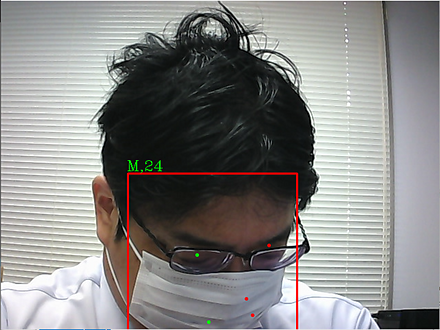
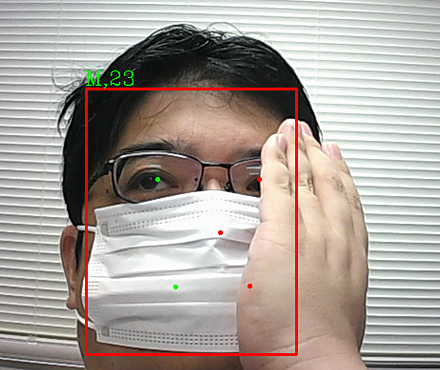

SCRFDの説明:別ページで説明を行っている。
Google Colaboratoryやパソコンでの試用:別ページで説明を行っている。
-
6/25 Dlibによる顔検出・ランドマーク検出
人工知能の代表機能として、画像関係では、画像分類、物体検出、顔検出、トラッキング・ビジョン、顔のランドマーク検出などがある。
次のページを参照すること。
https://www.kkaneko.jp/ai/win/pythondlib.html
Dlibを使っている。Windowsのパソコンでも、少しの準備で動かすことができるものである(準備は、このページの中に書いている)。このページに実行結果を載せている。
画像分類、物体検出、顔検出、トラッキング・ビジョン、顔のランドマーク検出がどういうものだったかを再確認できる。
顔検出、顔のランドマーク検出には、今回のDlibを勧める。別のソフトウェアと組み合わせて、顔識別(2つの顔写真が同一人物かの判定)もできる。
画像分類は、以前見せたMobileNetV2などの方を勧めたい(人によって判断が分かれるであろう)。 https://www.kkaneko.jp/ai/imclassify/cnncifar10.html
物体検出は、他の手法などがある。別の機会に、可能だったら紹介する。
-
6/15 顔のランドマークと顔識別
顔のランドマークと顔識別について説明する。dlib、GitHubのageitgey/face_recognitionを使用する。
https://colab.research.google.com/drive/1epOlnH3HW8nq3A2Oek4FyFnhgaD_cqWP?usp=sharing
顔マスク検出と属性推定
-
11/5 FairFace(性別・年齢推定)
顔からの性別、年齢等の推定について説明する。
FairFace(顔認識の公平性向上を目指したデータセット)(Karkkainen, Kimmo and Joo, Jungseock, FairFace, 2021年発表)では、bias(偏り)のない顔データセットの利用で、性別、年齢等の推定の精度向上ができたとされる。試してみた(公式ページの手順を少し変える必要があった)。
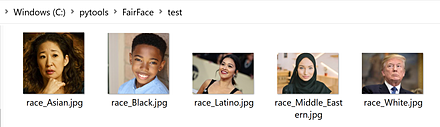
手順は別ページで説明している。
-
9/3 Chandrika Debの顔マスク検出
Chandrika Debの顔マスク検出 (Chandrika Deb's Face Mask Detection) および顔のデータセット: 別ページ »で説明している。
-
9/1 Chandrika Debの顔マスク検出
Chandrika Debの顔マスク検出 (Chandrika Deb's Face Mask Detection) および顔のデータセット: 別ページ »で説明している。
顔の3次元再構成とアラインメント
-
11/12 3DFFA 顔写真からの3次元再構成
3DFFA(顔写真からの3次元顔モデル再構成手法)による顔写真からの3次元再構成について説明する。
3DFFAのデモページのURL: https://colab.research.google.com/drive/1OKciI0ETCpWdRjP-VOGpBulDJojYfgWv#scrollTo=WLlzr74u9a4d
画像ファイルをアップロードし、コードセルに次のように追加する。
img_fp = '/content/127.png' img = cv2.imread(img_fp) plt.imshow(img[..., ::-1])結果は次の通りである。


-
9/14 3次元の顔の再構成(3DDFA_V2)
3次元の顔の再構成 (3D face reconstruction)(画像から3次元の顔形状を復元する技術)は、顔の写った画像から、元の顔の3次元の形を構成することである。
3次元の顔の再構成は、次の2つの種類がある。
- 3次元の変形可能な顔のモデル (3D Morphable Model(統計的な3次元顔モデル)) について、そのパラメータを、画像を使って推定すること。
- dense vertices regression(密な頂点群による3次元形状回帰): denseは「密な」、verticesは「頂点」、regressionは「回帰」である。画像から、顔の3次元データであるポリゴンメッシュを推定する。
3DDFA_V2(高速・高精度な3D顔アライメント手法)は、3次元の顔を再構成するdense vertices regressionの一手法である。論文は、2020年発表である。
-
論文
Jianzhu Guo, Xiangyu Zhu, Yang Yang, Fan Yang, Zhen Lei, Stan Z. Li, Towards Fast, Accurate and Stable 3D Dense Face Alignment, ECCV 2020.
- GitHubのページ: https://github.com/cleardusk/3DDFA_V2
Gradio(機械学習モデルのUIを簡単に作成するライブラリ)での3DDFA_V2のオンライン実行について説明する。
URL: https://github.com/cleardusk/3DDFA_V2
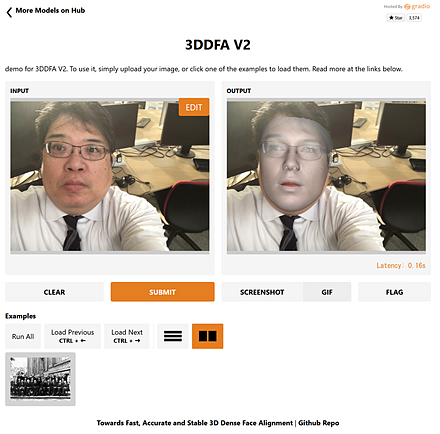
Google Colabでのインストールとオンライン実行について説明する。
URL: https://colab.research.google.com/drive/1OKciI0ETCpWdRjP-VOGpBulDJojYfgWv

結果は /content/3DDFA_V2/examples/results/ にできる。ここには、顔の3次元データであるポリゴンメッシュ(.objファイル)もある。
.objファイルをダウンロードしBlender(オープンソースの3DCGソフトウェア)で表示してみる。
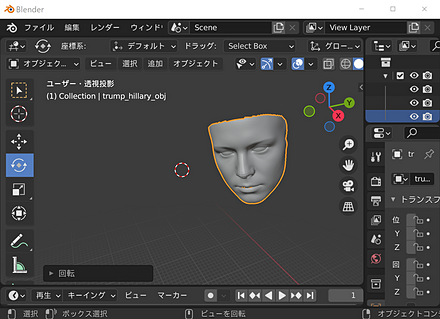
-
8/6 顔のアラインメント(部分隠蔽対応)

当初Dlibで顔情報処理を実験していた。その結果を受けて、「部分隠蔽された顔画像を扱いたい」と仮に目的を定めたとする。その結果、Dlibでなく、部分隠蔽された顔画像に適する他の方法で実験する(そして、他の方法について、自分なりに調査する)ことがありえる。これは、研究テーマの正常な進化である(決して変更や失敗ではない)。
以上を踏まえながら、部分隠蔽された顔画像に適する他の方法を実演する。
出典: How far are we from solving the 2D & 3D Face Alignment problem? (and a dataset of 230,000 3D facial landmarks), Adrian Bulat, Georgios Tzimiropoulos, https://arxiv.org/abs/1703.07332
特徴: Face Alignment Network (FAN)(顔ランドマーク検出ネットワーク)、LS3D-W(大規模3D顔ランドマークデータセット)データセット(サイズ:230,000、ポーズ[-90, 90]、3D)を特徴とする。なお、Dlibは、VGGデータセット(大規模画像認識用データセット)、scrubデータセット、その他作者がインターネットから収集した顔画像合計約3,000,000を使用している。
https://openaccess.thecvf.com/content_ICCV_2017/papers/Bulat_How_Far_Are_ICCV_2017_paper.pdf
次のGoogle Colaboratoryのページを公開している。これで実演する。使用するときは、ランタイムのタイプを「GPU」にして実行すること。
https://colab.research.google.com/drive/1vDHvPQ1O52rdlmczrxBopK1Ke1yFvjBJ?usp=sharing
こうした積み重ねが、新しい考察の発見にもつながっていくものである。考察は自由に考えるものであるが、研究は、どういう用途がありそうか、いままでの実験結果を踏まえ、さらに確認しないといけないことがありそうか、そして、別の方法も調査し、試すべきかなどを自由に考えるものである。
音声駆動型顔アニメーション
-
10/12 LiveSpeechPortraits(音声から顔アニメーション)
顔のモデルについて説明する。
声にあわせて、2次元の顔のモデルを変形させる技術が出てきた。このとき、入力としてシステムに与えられるのは音声のファイルである。

LiveSpeechPortraits(音声から顔アニメーションを生成する技術)
- 公式ページ: https://github.com/YuanxunLu/LiveSpeechPortraits
- 学習済みモデルのダウンロード: https://drive.google.com/drive/folders/1sHc2xEEGwnb0h2rkUhG9sPmOxvRvPVpJ
-
使用法(Google Colaboratory)
- 音声ファイル(wav形式)を準備する。
- Google Colaboratoryで、「ランタイム」、「ランタイムのタイプの変更」と操作し、「GPU」を選ぶ。
-
Google Colaboratoryで次を実行する。インストールを行う。
!git clone https://github.com/YuanxunLu/LiveSpeechPortraits.git %cd LiveSpeechPortraits !apt install -y ffmpeg !pip3 install -r requirements.txt !pip3 install -U numba==0.49.1 librosa==0.7.0 !pip3 install -U opencv-python==4.4.0.46 albumentations==0.5.2 -
学習済みモデル
https://drive.google.com/drive/folders/1sHc2xEEGwnb0h2rkUhG9sPmOxvRvPVpJ からダウンロードし、LiveSpeechPortraits\data 下に置く。
-
デモの実行
結果はresultsの下に、ファイルとして残る。
%cd /content/LiveSpeechPortraits !python3 demo.py --id McStay --driving_audio ./data/Input/1.wav --device cudaこのデモプログラムでは、動画ファイルの生成までが行われる。

物体検出と姿勢推定
物体検出
-
11/9 MMDetection(物体検出、セグメンテーション)
MMDetection(物体検出のためのオープンソースツールボックス)のデモページについて説明する。MMDetectionは2021年発表である。デモページ (Google Colaboratory) は、次のURLである。
次の機能を試すことができる。
-
物体検出の機能がある。
画像の中のオブジェクトを検出し、四角で囲み(場所と大きさ)、種類を判別する。
-
セグメンテーションの機能がある。
画素単位でオブジェクトを切り出す。
- COCOデータセット(大規模な物体検出・セグメンテーション用データセット)で事前学習済み(COCOデータセットは、オブジェクトのカテゴリ数:80)を利用しての物体検出とセグメンテーション。
- 自分の画像を追加しての学習も行っている。
-
物体検出の機能がある。
-
9/24 DETR(物体検出とfine tuning)
物体検出とfine tuning(学習済みモデルを特定タスクに適応させる手法)について説明する。2020年発表のDETR(DEtection TRansformer)(Transformerを用いた物体検出モデル)を使用する。Google Colaboratoryでのオンライン実行を行う。woctezumaのGoogle Colaboratoryのページを使用する。
資料: 資料
-
9/17 YOLOX(物体検出)
物体検出について説明する。2021年発表のYOLOX(高性能なアンカーフリー物体検出モデル)を使用する。高速で動き、精度も良好である。Google Colaboratoryでのオンライン実行を行う。
資料: 資料
-
4/13 TensorFlow 2 Object Detection API
人工知能でできることとして、今まで見ていただいた「分類」のほかに、「一般物体検出」があることを見ていただく。
TensorFlow 2 Object Detection API(TF2用物体検出API)(オブジェクト検出API)、TensorFlowのチュートリアルのプログラムを使用する。
このプログラムでは、CenterNet(アンカーフリーな物体検出モデル) HourGlass104 1024x1024を用いている。そして、COCOデータセット(大規模物体認識データセット)を用いて事前学習済みのものを用いている。
人体・車両の姿勢推定
-
12/8 OpenPose(人体ポーズ、指の形認識)
OpenPose(リアルタイム多人数キーポイント検出ライブラリ)について説明する。人体のポーズ、指の形などをコンピュータが読み取る。様態や人間の意図をコンピュータが判断できる技術の基礎になりえる。
-
人工知能でできること:人体のポーズの認識、指の動き等の認識
-
OpenPoseのセットアップ
自分のパソコンでもインストールできる。
(研究室のパソコンでインストール済みであれば、そのまま使う。インストールがまだであれば、インストールする)
-
OpenPoseの諸機能確認:動作不具合があれば対処する。
人体のポーズの認識、指の動き等の認識について説明する。
資料の「CPU版を使う場合」は行わない(資料のその部分は飛ばすこと)。
- カメラで各自体験する(ここまで終えたら小休止とする)。
-
OpenPoseのセットアップ
-
実験、研究のプロセスや実験データの整備について体験的に学ぶ
-
手や顔の匿名化ができる技術の紹介
手や顔にモザイクをかける。
- JSON(JavaScript Object Notation)(軽量なデータ交換フォーマット)データファイル、OpenPoseでのJSONデータファイルについて説明する。
-
OpenPoseを用いた実験テーマを各グループで定めること。この実験テーマは、今回の授業で使う(次回以降は別のことを行う)。
例1:コンピュータが人数カウント 例2:コンピュータがポーズを読み取り、人間の意図を推定 例3:コンピュータが指の動きを読みとり、人間の意図を推定
-
実験データ収集(グループワーク)
上で定めた「実験テーマ」で実験できるだけのデータを、どのようにして集めますか。実際に集め、そして、考察を行う。考察とは、次のことを考えるプロセスである。
- 実際に集めて発見したこと
- もう一度集めなおすとしたら何を改良できるか
- 実際に集めたデータにどのような誤差があるか
- 別のやり方があるか
- 集めたデータが今後何に使えそうかを自分なりに考える
-
実験データ提出、実験データ公開
同意できる場合には、実験データを学内もしくは世界に公開する。
-
手や顔の匿名化ができる技術の紹介
-
人工知能でできること:人体のポーズの認識、指の動き等の認識
-
10/8 OpenPifPaf(人体・車両の姿勢推定)
人のカウント、車のカウントに興味がある。数を数えたり、全体の流れを見たりである。そのとき、プライバシーには十分に配慮する。顔画像からの年齢や性別の推定は別の技術である。車種の推定も別の技術である。
画像からの、人体の姿勢推定(pose estimation)について説明する。人物追跡(person tracking)の技術は、従来からあった。姿勢推定には2次元のものと3次元のものがあるが、今回の紹介は2次元である。
2021年発表のOpenPifPafを紹介する。
- OpenPifPaf(人や物体の姿勢推定を行う手法)の公式ページ(GitHubのページ)
-
OpenPifPafのチュートリアルの「WholeBody」のページ
人体の姿勢推定について説明する。
Google Colaboratoryで動かすには、次のコマンドをコードセルに書いて動かす。
pipの行はインストールである。wgetの行は画像ファイルのダウンロードである。pythonの行は処理の実行である。
!pip3 install openpifpaf !wget https://upload.wikimedia.org/wikipedia/commons/0/06/Kamil_Vacek_20200627.jpg !python3 -m openpifpaf.predict Kamil_Vacek_20200627.jpg \ --checkpoint=shufflenetv2k30-wholebody --line-width=2 --image-output -
OpenPifPafのチュートリアルの「CarkeyPoints」のページ
乗用車の姿勢推定について説明する。
Google Colaboratoryで動かすには、次のコマンドをコードセルに書いて動かす。
pipの行はインストールである。curlの行は画像ファイルのダウンロードである。pythonの行は処理の実行である。
!pip3 install openpifpaf !curl -O https://upload.wikimedia.org/wikipedia/commons/7/71/Streets_of_Saint_Petersburg%2C_Russia.jpg !python3 -m openpifpaf.predict /content/Streets_of_Saint_Petersburg%2C_Russia.jpg \ --checkpoint=shufflenetv2k16-apollo-24 -o images \ --instance-threshold 0.05 --seed-threshold 0.05 \ --line-width 4 --font-size 0 -
「Fall Detection using Pose Estimation」の記事
人物追跡、転倒検知などについて説明している。
https://towardsdatascience.com/fall-detection-using-pose-estimation-a8f7fd77081d
-
openpifpafのGoogle Colaboratoryのデモ
人物の姿勢推定を行うPythonプログラムである。
https://colab.research.google.com/drive/1H8T4ZE6wc0A9xJE4oGnhgHpUpAH5HL7W
これらの技術等をベースとして、人間の動きだけでなく、車両の動き(車両のドアなどのパーツの細かな構造を見るので、車が前向きか、後ろ向きか、右横向きか、傾いているかの情報をとることができる)の分析も始まっている。
画像生成と画像変換
敵対的生成ネットワーク(GAN)
-
11/16 GAN, StyleGAN
GAN (Generative Adversarial Network)(敵対的生成ネットワーク)では、生成器 (generator) でデータを生成し、識別機 (discriminator) で、生成されたデータが正当か正当でないかを識別する。
TensorFlow Hub(再利用可能な機械学習モジュール群)のGANのデモページ
https://www.tensorflow.org/hub/tutorials/tf_hub_generative_image_module
StyleGAN(高精細な画像を生成するGANの一種)は、Mapping networkとSynthesis networkの2つのネットワークで構成され、従来のGANよりも高精細な画像を生成できるとされている。

StyleGANのSynthesisのAdaIN(適応的インスタンス正規化)に画像を与えることで、生成される画像の特徴を転移 (transfer) することができる。そして、AdaINには、解像度の違うものが複数あり、低い解像度のAdaINに画像を与えると、大きく特徴が変化するように特徴を転移する。高い解像度のAdaINに画像を与えると、小さく特徴が変化する。
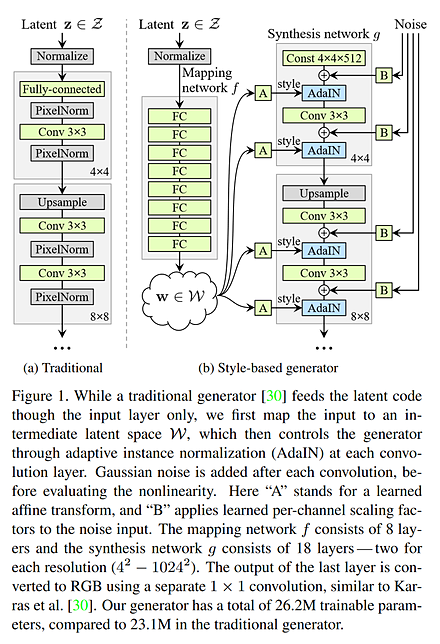
StyleGANの文献: https://arxiv.org/pdf/1812.04948.pdf
従来のStyleGANでは、用途に応じて、アーキテクチャを変えたり、学習法を変える必要があるとされてきた。
次の文献では、単一のアーキテクチャ、単一の学習法でも、StyleGANをさまざまな用途に利用できることが示されている。
StyleGAN of All Trades: Image Manipulation with Only Pretrained StyleGAN
Min Jin Chong, Hsin-Ying Lee, David Forsythこの文献の作者らによる次のGoogle Colaboratory(ブラウザでPythonを実行できる環境)のページでは、次のことを行っている。
https://colab.research.google.com/github/mchong6/SOAT/blob/main/infinity.ipynb#scrollTo=HSaAxHVcDKRv
- パノラマ画像の生成 (panorama generation)
- アニメ風の画像の生成 (Toonification)
- 画像の拡張
- 2画像のマージ (merging 2 images)
- 範囲を選択して、特徴を転移
超解像
-
10/19 TecoGAN(超解像)
TecoGAN(時間的整合性を考慮した超解像GAN)を用いた超解像について説明する。
次をGoogle Colabで実行する。TecoGANのインストール、学習済みモデルのダウンロード、TecoGANの実行と確認を行っている。
!pip3 install tensorflow==1.15 !pip3 install -U keras==2.3.1 !pip3 install git+https://www.github.com/keras-team/keras-contrib.git !git clone https://github.com/thunil/TecoGAN %cd TecoGAN !pip3 install -U -r requirements.txt !python3 runGan.py 0 !python3 runGan.py 1 from IPython.display import Image, display_png display_png(Image('LR/calendar/0001.png')) display_png(Image('results/calendar/output_0001.png'))実行結果のスクリーンショットを原寸で表示する。

セグメンテーションと前景抽出
-
11/26 セマンティックセグメンテーション(UPerNet)
セマンティックセグメンテーション(画素毎に意味ラベルを付与する技術)は、コンピュータが画像を読み取り、画像の中の画素を種類ごとに分類することである。
Unified Perceptual Parsing(多目的画像解析手法)
2018年発表。さまざまな種類の画像について、精度よくセグメンテーションができるとされる手法である。

-
11/2 Salient Object Detection(BASNet)
Salient Object Detection(画像中の顕著な物体を検出する技術)(顕著なオブジェクトの検出)について説明する。
視覚特性の異なるオブジェクトを、画素単位で切り出す。前景と背景の分離に役立つ場合がある。人間がマスクの指定や塗り分け(Trimapなど)を行うことはない。
BASNet(境界を意識した顕著物体検出ネットワーク)は、ディープラーニングにより、Salient Object Detectionを行う一手法である。2019年発表である。
Qin, Xuebin and Zhang, Zichen and Huang, Chenyang and Gao, Chao and Dehghan, Masood and Jagersand, Martin, BASNet: Boundary-Aware Salient Object Detection, The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2019
元画像

BASNet法の結果

-
BASNetプログラムなどのダウンロード
git clone https://github.com/NathanUA/BASNet.git※git(分散型バージョン管理システム)
-
学習済みモデルのダウンロード
公式ページ https://github.com/xuebinqin/BASNet の指示による。学習済みモデル(ファイル名 basenet.pth)は、次で公開されている。ダウンロードし、saved_models/basnet_bsi の下に置く。
https://drive.google.com/open?id=1s52ek_4YTDRt_EOkx1FS53u-vJa0c4nu
-
BASNetの実行
cd BASNet python basnet_test.py -
元画像の表示
from IPython.display import Image,display_jpeg display_jpeg(Image('test_data/test_images/0003.jpg')) display_jpeg(Image('test_data/test_images/0005.jpg')) display_jpeg(Image('test_data/test_images/0010.jpg')) display_jpeg(Image('test_data/test_images/0012.jpg')) display_jpeg(Image('test_data/test_images/BKN06Z000006_W_big.jpg')) -
BASNetの結果の表示
from IPython.display import Image,display_png display_png(Image('test_data/test_results/0003.png')) display_png(Image('test_data/test_results/0005.png')) display_png(Image('test_data/test_results/0010.png')) display_png(Image('test_data/test_results/0012.png')) display_png(Image('test_data/test_results/BKN06Z000006_W_big.png'))
-
BASNetプログラムなどのダウンロード
-
10/29 Trimapからの前景推定(pymatting)
Trimapからの前景の推定について説明する。
trimap(前景・背景・不明領域を示すマスク画像)では、次の3つを考える。前景である画素は白、背景である画素は黒、transitionである画素は灰色の3通りに塗り分けた画像をtrimapという。
- 前景 (foreground)
- 背景 (background)
- transition: どちらであるか判断できないか、細かすぎて、塗り分けが困難な領域
元画像と、そのtrimapを用いて、前景の推定を行う。
元画像
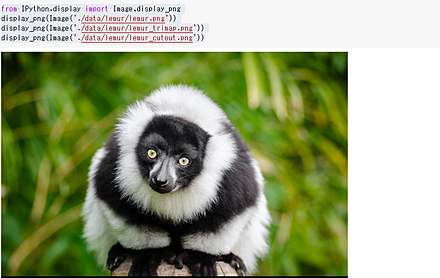
trimap(これは手作業で作成されたもの)と、前景の推定結果(コンピュータが生成)

pymatting(前景抽出ライブラリ)法
- Thomas Germer, Tobias Uelwer, Stefan Conrad, Stefan Harmeling, Fast Multi-Level Foreground Estimation, CoRR, abs/2006.14970v1, 2020.
- ドキュメント: https://pymatting.github.io
- GitHubのページ: https://github.com/pymatting/pymatting
Google Colaboratoryでのインストールと確認を行う。
git clone https://github.com/pymatting/pymatting cd pymatting pip3 uninstall -y folium pip3 install . python3 tests/download_images.py pip3 install -r requirements_tests.txt pytestGoogle Colaboratoryで動かしてみる。コードセルで次を実行する。このプログラムは、公式のドキュメント(https://pymatting.github.io)を使用している。
from pymatting import cutout cutout( # input image path "../data/lemur/lemur.png", # input trimap path "../data/lemur/lemur_trimap.png", # output cutout path "lemur_cutout.png") from IPython.display import Image,display_png display_png(Image('./data/lemur/lemur.png')) display_png(Image('./data/lemur/lemur_trimap.png')) display_png(Image('./data/lemur/lemur_cutout.png'))
画像修復と深度推定
-
10/26 Image Inpainting(LaMa)
Image Inpainting(画像の欠損部分を修復する技術)(イメージ・インペインティング)について説明する。
画像の欠落部分を補う技術である。画像の中の不要な部分を消すときにも役立つ。
LaMa (Large Mask Inpainting)(大規模マスク対応の画像修復モデル)(2021年発表)のデモページ
実行結果の例


-
9/28 monodepth2(深度推定)
単一のカメラでの画像からdepth image(各画素に奥行き情報を持つ画像)を推定する方法としては、ディープラーニングを用いるmonodepth2(単眼カメラ画像から深度を推定する手法)法(2019年発表)が知られる。実行結果は次のようになる。


depth imageは、距離を画像化したものである。
monodepth2法は、普通の画像を距離画像に自動変換する研究である。
monodepth2法の実行手順は別ページで説明している:https://www.kkaneko.jp/tools/man/man.html#depthimage
なお、以前紹介したMeshroomなどを使っても距離画像を作ることができる。
機械学習の基礎と開発環境
ニューラルネットワークの学習
-
6/11 転移学習
転移学習について説明する。
ニューラルネットワークを分類に使うとき、最終層のニューロンの数は、分類数に等しい。学習済みのニューラルネットワークを使うとき、分類数が違うなどの理由で、最終層を取り除いて使うことがある。最終層を取り除いた残りが、「自分が分類したい画像でうまく動くか」の事前確認は簡単なプログラムですばやく行うことができる。
-
6/8 画像データの増量と学習済みモデル
画像データの増量について説明する。
ニューラルネットワークで画像分類を行う。画像データの増量がどういうものか、画像データの増量により分類精度が改善、過学習(訓練データに過剰適合し汎化性能が低い状態)が改善することを見てもらう。
https://www.kkaneko.jp/ai/imclassify/augment.html
画像分類での、学習済みモデルのダウンロードと使用について説明する。
ImageNet(大規模画像データセット)(1000万枚以上の画像データ、約20,000種類の分類済み)で学習済みの学習済みモデルをダウンロード使用する。
-
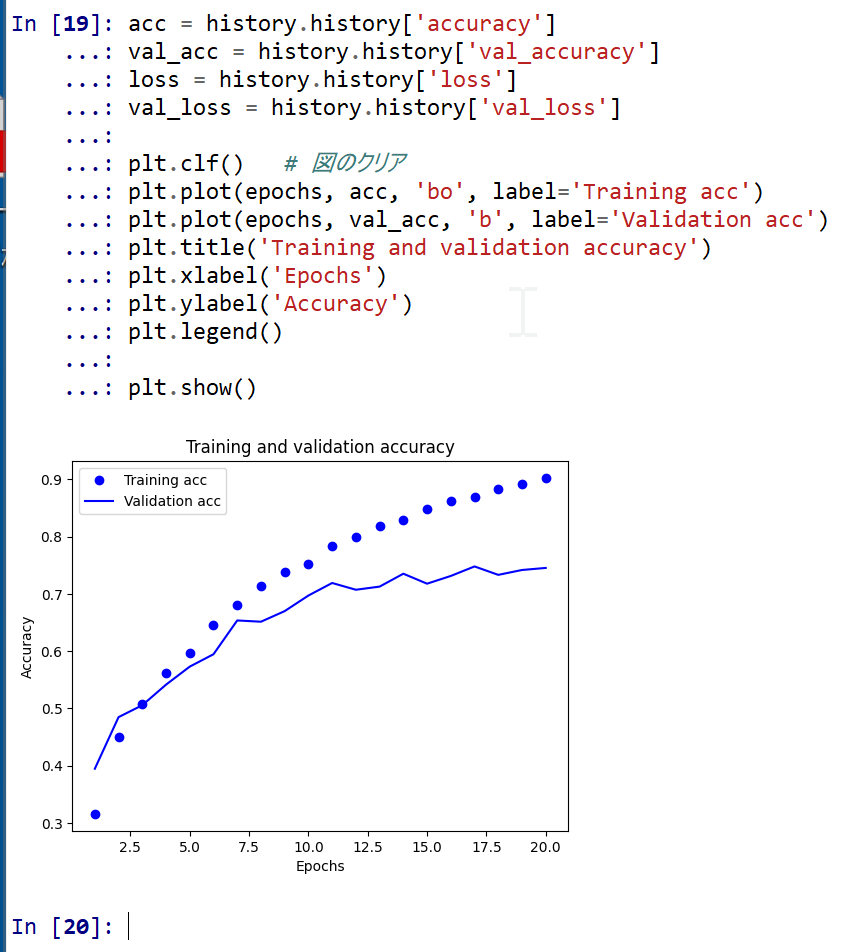
6/1 ニューラルネットワークの学習基礎
ニューラルネットワークの学習の基礎について説明する。
エポック:同一の教師データ(機械学習モデルの訓練用データ)を繰り返し使用して学習する。1回しか使わない場合は学習不足の問題がありえる。そのことを解決する。
過学習(オーバーフィットともいう):教師データの繰り返し使用により、精度は向上するが、検証データでの精度は向上しないか低下する。
過学習の可能性があるため、必ず、検証データでの精度の検証を行う。
過学習の解決について説明する。
-
4/27 次元削減
資料は次の通りである。
-
4/6 データ拡張の効果
人工知能の学習では「データのデータ拡張」が必須である(教師データを数万以上に増量する必要がある)ことを見ていただく。
増量前
増量後
-
3/30 文章の2クラス分類
2クラス分類、モデルの作成と学習と検証(TensorFlow、Keras(高水準ニューラルネットワークAPI)、IMDbデータセット(映画レビューの感情分析用データセット)を使用)

-
3/16 TensorFlowデータセット、モデル学習・検証
ニューラルネットワークの学習を行うときのポイントは、データセットを準備すること、そして、検証を行う(学習不足や過学習がないことを確認する)ことである。
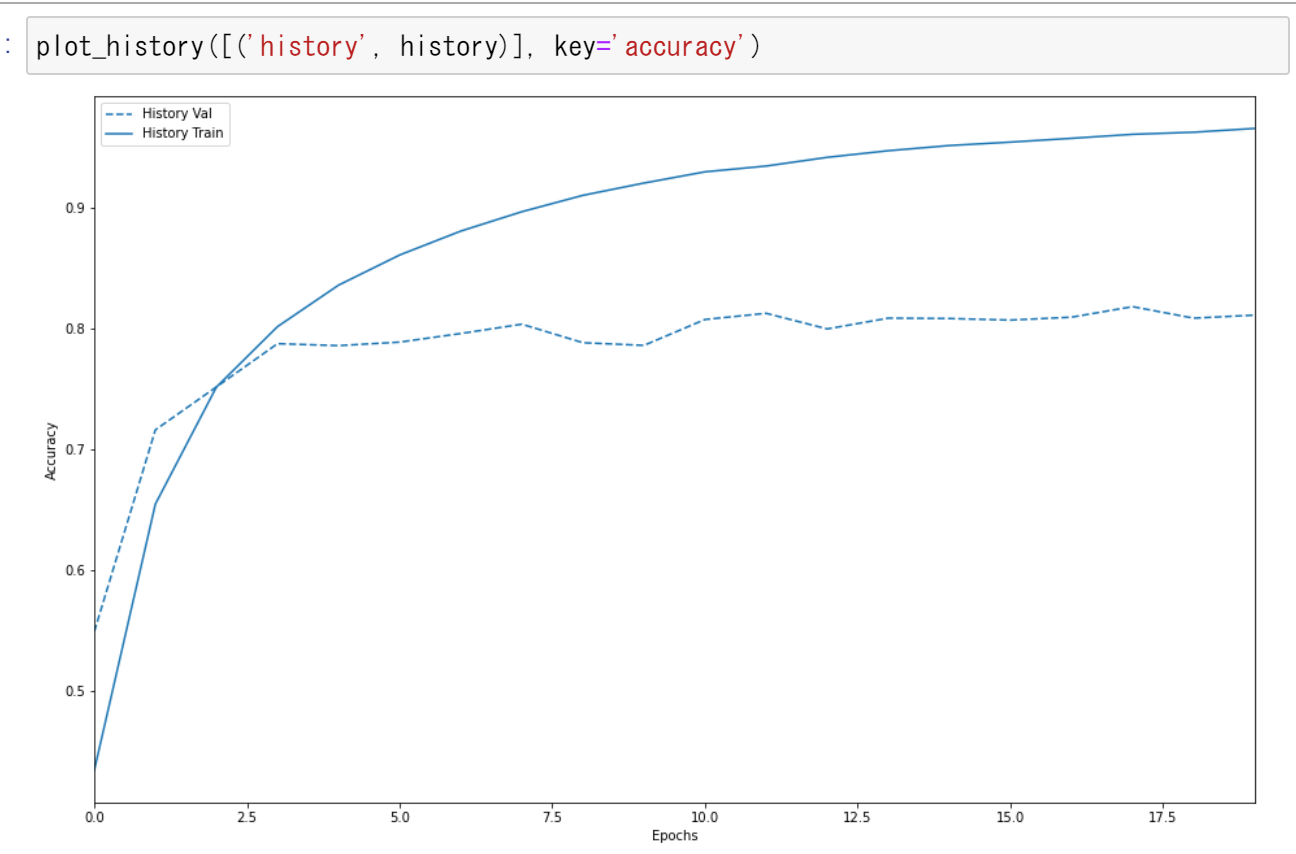
- モデルの作成と学習と検証(学習ではTensorFlowデータセットのMNISTデータセットを使用)(TensorFlowを使用)
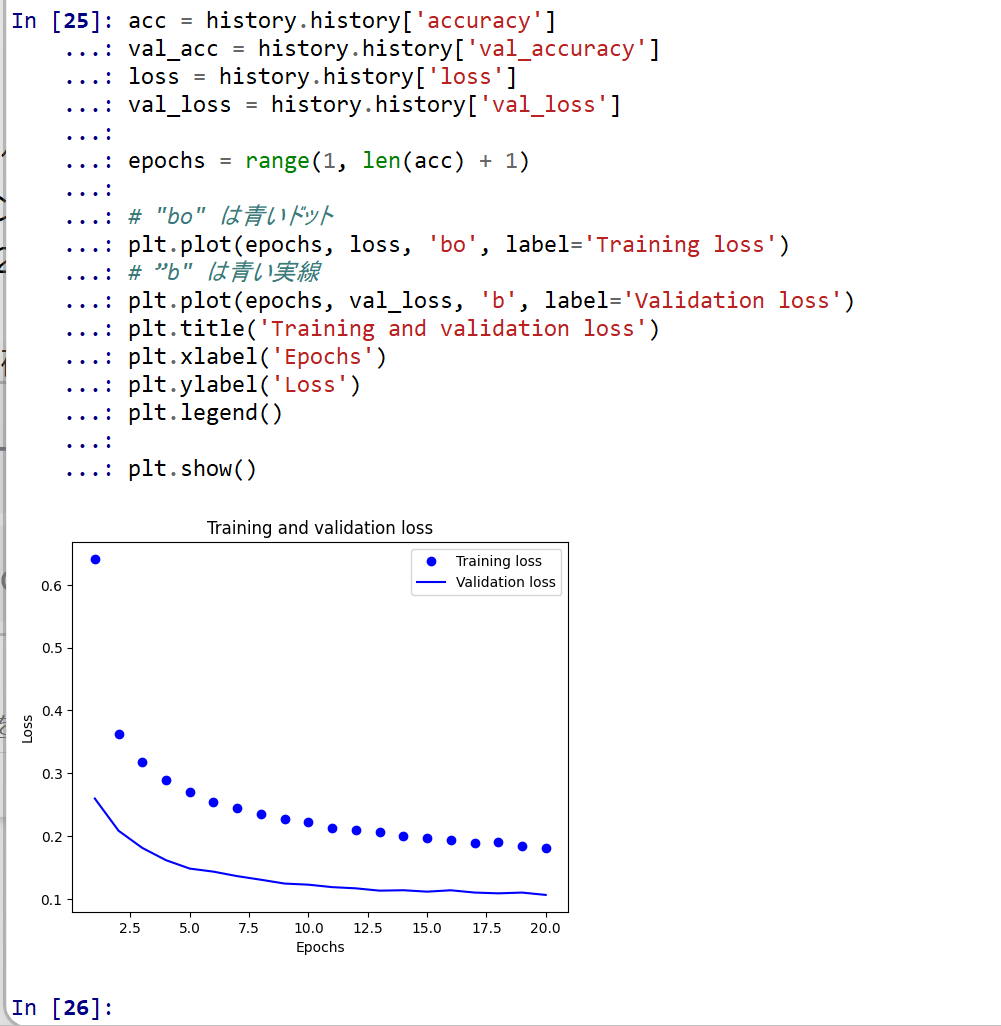
-
3/9 OpenCVを用いた文字検知
簡単なプログラムで動くことを見てもらう。他のプログラムの中に組み込んで使うことも簡単にできることをお伝えしておく。
-
3/2 画像分類(MobileNetV2, ResNet50等)
Google Colaboratoryでのオンラインでの実行などについて説明する。
開発環境とツール
-
6/22 ソースコード(Google Colab)
https://colab.research.google.com/drive/1epOlnH3HW8nq3A2Oek4FyFnhgaD_cqWP#scrollTo=B8PZTOpcYXwF
-
6/17 Google ColaboratoryでWebカメラ使用
資料のURL: https://www.kkaneko.jp/cc/colab/colabwebcam.html
- Google Colaboratoryでは、Pythonのプログラムが動く。Webブラウザで、Google Colaboratoryのサイトを開き、ソースコードを確認、編集しながら、プログラムを動かすことができる。ブラウザのみで動く。メモをつけたり、他の人とシェアもできる。
- ノートパソコンなどには、カメラが付くようになった。Google Colaboratoryで、パソコンのカメラを使うことができる。
- 準備は、Google Colaboratoryの画面で、スニペットをクリック、メニューで「Camera Capture」を選び、「挿入」をクリックする。
-
実行すると、Google Colaboratoryで手元のパソコンのビデオカメラが表示される。
この時点では、手元のパソコンのWebブラウザで、実質JavaScriptのプログラムが動いている。
-
5/7 PythonとSQLの組み合わせ
資料:https://www.kkaneko.jp/de/dbenshu/db1.pdf
大量データの管理について説明する。
数十万行のデータを扱うという機会は、よくある。Excelで数十万行のデータを扱おうとすると、ちょっとした処理で1時間近くかかった、ということもありえる。
そこで、リレーショナルデータベース(関連付けられた表形式データ群)が役に立つ。
リレーショナルデータベースは授業で学んだ。SQL(Structured Query Language)(データベース操作言語)は独特、と思っている人もいるかもしれない。
PythonとSQLの組み合わせを教える。これで、数十万行のデータが入ったファイルをPythonで読み込んで、SQLで簡単に高速処理が簡単にできるスキルが身につく。
実演では、150行のCSV(Comma-Separated Values)(カンマ区切りテキストデータ形式)ファイルを、リレーショナルデータベースに取り込むことがとても簡単にできることを示す(将来、大量データを扱うことになったときに役に立つスキルである)。
- SQL(テーブル定義、行の挿入、問い合わせ)
- Pythonとの連携(Pythonの中でSQLを使う)
- CSVファイルをPythonで読み込み、そして、リレーショナルデータベースを作り、使う。
-
4/20 Python入門
Python(汎用プログラミング言語)について説明する。Pythonは簡単に使うことができるプログラミング言語である。卒業研究でも便利に使っていきたい。
PythonとGoogle Colaboratory: Python入門(全14回、Python TutorとCodeCombatを使用): 別ページ »で説明している。
サイト内の関連ページ
- Python入門: 別ページに準備している
- Windowsでのセットアップ(PythonやPython開発環境のインストールを含む):別ページ »で説明している
- WindowsでのPythonのインストール:別ページ »で説明している
- その他、Pythonについては、Pythonのページに資料を置いている
活動日程
登校日・活動日
-
11/22 登校しての活動
-
11/10 活動日
-
11/3 この日に学校に集合することはなかった。
-
10/18 自主的な活動
-
10/13 自主的な活動
-
5/11 遠隔継続の連絡
- 5月中は、遠隔を継続する。
- 週2回に増やす。火曜の13:30開始と、金曜日の13:30開始。
- 次回は5/14 13:30とする。
- 5/14 13:30の回では、卒業論文テーマ説明を行う(3月にも行った。一部同じ内容であるが、より詳しく話したい)。
- ノートパソコンの貸し出しなどできる。自宅で、実際の作業、実験を開始できるかの相談である(6月も遠隔になる可能性を想定する)。
配信予定
-
11
配信予定
-
11/26, 金曜日:配信予定
セマンティックセグメンテーションについての配信を予定している。
-