2023年度 金子邦彦研究室 サポートページ
本ページは、金子邦彦研究室に所属する学生(情報工学演習II受講生および卒業研究生)を対象としたサポートページである。
対象科目
- 情報工学演習II(3年生・研究室仮配属生)
- 卒業研究(4年生・研究室本配属生)
目次
共通事項
研究テーマ(プロジェクト)
AI、データサイエンス、3次元処理を軸に、実社会の課題解決を目指す。以下のテーマから、興味と適性に合わせて選ぶ。
- 斜め画像の画像理解とAI利用(ドライブレコーダー等の斜め画像の認識精度改善)
- 低品質ビデオの画像理解(手振れ・振動のある映像の補正と解析)
- 植生変化観測とAI利用(航空写真等を用いた変化量の数値化・定点観測)
- ネットワークカメラシステムと顔情報処理(エッジAIによる人流カウント・顔認証)
- 自動翻訳・音声翻訳システム(Whisper/ChatGPT APIを用いた対話システム構築)
- 3次元姿勢データベースとAI活用(ポーズ撮影とAI姿勢推定、Blenderによる再現)
- 3次元デジタルアーカイブ「福山の再現」(観光名所の3次元化と自動化プロセスの構築)
質問方法
対面またはメールで質問できる。
研究室関連資料
情報工学演習II(3年生向け)
演習の位置づけ
「情報工学演習II」は、4年次の卒業研究およびエンジニアとしてのキャリアを見据え、「与えられた問題を解く」段階から「自ら課題を見つけ、解決する」段階へシフトするためのトレーニング期間である。
活動の基本情報
Web資料(メインページ)
演習の資料は以下のWebサイトで公開している。ブックマークしておくこと。
URL: https://www.kkaneko.jp/a/2023.html
【アクセス制限について】
大学の無線LANからはアクセスできない。自宅などの学外ネットワーク、または学内の有線LAN接続PCからアクセスすること。
課題提出先(セレッソ)
課題は「金子邦彦研究室」のレポート機能で提出する。
URL: https://cerezo.fukuyama-u.ac.jp/ct/course_1001435_queryadm_examlist
実施概要
- 日時: 4時限(14:50〜16:20)
- 場所: 3号館3階 03305室(対面実施時)
- 持参物: 充電済みのノートパソコン(必須)
学習リソースと演習内容
本演習では、Google Colaboratory(ブラウザ上でPythonを実行できる環境)や各種ツールを使用する。以下のリンクから教材やコードにアクセスし、実際に手を動かして学ぶ。
【前半】AI・データサイエンス基礎(Google Colab)
環境構築不要でPythonとAIを動かす。
- 画像分類の基礎
https://colab.research.google.com/drive/1O9V9UwlWS-kJTQau42kIIcxyOpJQr5-G?usp=sharing
- 生成AI・GAN(Generative Adversarial Network:敵対的生成ネットワーク)
画像の生成、フェイク画像、DCGAN(畳み込み層を用いたGAN)の学習など。
https://colab.research.google.com/drive/1hymsnPNkc0Ra3HfklhNEcSDWGbafQEx7?usp=sharing
- オートエンコーダ(Auto Encoder:入力データを圧縮・復元するニューラルネットワーク)
https://colab.research.google.com/drive/1HQ8pmFVJFq5uhBEfkBhRvsXaDUXssoo9?usp=sharing
- データマネジメント・前処理(Pandas)
CSVファイル操作、外れ値処理、学習・検証データの準備。
https://colab.research.google.com/drive/1oUtNxZsm81Bwm2dxblRF2a51bhkElFNz?usp=sharing
- データサイエンス基礎
正規化(データを一定の範囲に変換)、Zスコア(平均0・標準偏差1に標準化した値)、One-hotエンコーディング(カテゴリを0と1のベクトルで表現)など。
https://colab.research.google.com/drive/1mnRH7AKLhUryqK2ar7XgAffW-dHj7R-N?usp=sharing
【中盤】セグメンテーション(画像認識の応用)
セグメンテーションとは、画像内の各ピクセルを分類し、物体の領域を特定する技術である。
- 物体検出・インスタンスセグメンテーション(個々の物体を区別して領域分割)
https://colab.research.google.com/drive/1QpShUUrOdWHAjkbb-BBuwg8iXmHXv3ff?usp=sharing
- パノプティックセグメンテーション(物体と背景の両方を統合的に分割)の実践
【後半】3次元処理・CG制作(要インストール)
高性能なPC推奨。インストールや撮影は各自で行う。
- Meshroom(Photogrammetry:複数の写真から3次元モデルを生成する技術)
写真から3次元モデルを作成する。「TRY MESHROOM NOW」からダウンロードする。
- MeshLab(3Dメッシュ処理)
obj形式ファイルの閲覧・加工に使用する。「Win64」を選択する。
- Blender(3DCG制作)
モデリング、アニメーション作成に使用する。Microsoft Storeからも入手可能。
インストール方法: https://www.kkaneko.jp/db/cg/blenderinst.html
基本機能紹介: https://www.kkaneko.jp/db/cg/blenderintro.html
作成・レンダリング: https://www.kkaneko.jp/db/cg/blender.html
【自主学習】Pythonプログラミング詳細資料
プログラミングの基礎を深く学びたい場合は、以下の資料を活用する。
https://www.kkaneko.jp/pro/po/index.html
成績評価(GPA基準)
定期試験は行わず、毎回の課題(小テスト・レポート)で評価する。課題に取り組むことで、専門スキルが身につき、就職活動でアピールできる実績となる。
- GPA 4: 全提出かつ、内容・分量が優れている(独自の考察がある)。
- GPA 3: 1回程度の未提出があるが、提出分は優れている。
- GPA 2: 2回程度の未提出があるが、提出分は優れている。
締め切り: 原則1週間以内
今後のスケジュール(就職活動・進学準備)
3年次の2月・3月は、キャリア形成において重要な時期である。
- 2月下旬: ZOOM配信開始(メールで連絡する)
- 3月中旬(10日〜20日頃): 登校日(午後1時間程度)
就職・進学に向けた準備
本演習での経験を「ガクチカ(学生時代に力を入れたこと)」として語れるよう整理しておくこと。面接で具体的な実績を説明できることが、採用につながる。
- 自己分析: 志望動機、長所、自己PR等の文章化(200字程度)。
- 専門スキル: 「Pythonで〇〇のシステムを構築した」「〇〇の課題をデータ分析で解決した」という具体的実績を作る。
- マインド: 粘り強く継続する姿勢を持つこと。
到達目標
この演習を通して、以下の状態を目指す。
- 専門性の自覚: 自分が何を専門(AI、データ、3D等)にしているか説明できる。
- 技術の習得: 広く深い技術知識を持ち、実際に手を動かして実装できる。
- 社会課題解決: 技術をどう社会に役立てるか、自ら考察できる。
- 研究基礎力: 4年次の卒業研究、学会発表に向けた自信をつける。
卒業研究(4年生向け)
受講準備
研究室のパソコンを使用する。
自身のパソコンで研究する場合は、下記のページを参考にセットアップする。興味のある学生は挑戦を推奨する。
https://www.kkaneko.jp/tools/win/tools.html
集合時間
火曜日の10時50分、木曜日の10時50分。
(学生のみの活動となる場合がある)
受講上の注意
- 中間発表(7月予定)、学会発表準備と発表(7月、10月、1〜2月)、卒論提出(12月予定)、卒論プレゼン(12月予定)を予定する。
- 課題:集合時に指示する。
自主的な調査・学習と、実験手順・実験結果・考察を根拠やデータとともに説明する活動を重視する。
集合してミーティング等を行った後、各自で自主活動を行う。活動時間は2〜3時間以上を目安とする。集合時間以外でも自主的に登校する場合がある。必要に応じて、集合時間以外の登校を求める場合がある。欠席した場合は自身で補うか、教員と相談のうえ補充する。卒業論文では公認欠席の考え方は採用しない。
- 出欠は、教員が様子を確認している。
- 進路指導や連絡のため、学生に電子メールで連絡することがある。
- 成績評価
日頃の登校しての活動状況、中間発表、学会発表準備と発表、卒論提出、卒論プレゼンなどから判断する。
卒業研究の評価は、他の授業とは異なる。研究を楽しみ、熱中し、自主的に取り組み、自立することが大切である。成長できたか、基本的なルール(卒業論文のプレゼンの制限時間、中間発表や卒業論文の分量、書き方、締め切り、内容についてのルール)を守ったかが評価の対象となる。
GPAスコア(学業成績評価指標の一つ)2の目安
登校してのグループ活動に問題がない。自主的に調査し、実験計画を立て、実験し、工夫を行っている。修得できた専門知識、使用している技術(アルゴリズムや仕組み)の説明、実験手順の説明、行った工夫について、他の教員に説明でき、質問に答えることができる。中間発表のポスターや卒業論文や卒業論文のプレゼンについては、分量や内容についてルールを守っている。卒業論文のプレゼンについては時間制限(4分50秒から5分10秒程度で発表を終えることを目安)を守ることができている。
GPAスコア4の目安
次の点で優れていること。
- 専門知識:専門的な知識や技術を、自主的に学んでいる。仲間に教えたり、仲間から教わったりしている。
- 調査・分析能力:直面した課題について、関連する情報を収集しながら、解決に取り組んでいる。困ったときは仲間や教員に相談している。
- プログラミング:研究で使用するプログラムについて、工夫ができる。そのためにPython言語(汎用プログラミング言語)の理解と、実践能力の成長に意欲的である。
- マネジメント:宿題などは早めに終えて余裕を持ち、時間を有効に活用している。締め切り前には確認したり、教員に前もって質問したりなどで、ミスを減らすように努力している。
- コミュニケーション:仲間や教員に説明ができる。他の人とともに高めあうことができる。学会発表や、チーム内の意見交換(人の話を聞いたり、意見を言うことができる)に積極的である。
- 問題解決能力:失敗してもあきらめずに、論理的に、実験結果や調査結果などを積み重ねながら、解決策を見つける。AI(人工知能)やデータベース(構造化された情報の集まり)の研究では、データのとり方を工夫したり、プログラム内の設定を工夫したり、プログラムのアルゴリズムを工夫したり、今までのやり方に固執せずに、別のやり方を試したりなどに、自律的に、意欲的に挑戦する。困ったときは、仲間や教員に助けてもらうことが大切である。研究で使っているプログラムについて、仕組みを理解しておくことも大切である。
授業計画
- 4〜5月:研究スキルの基礎(調査、実験、専門知識やスキル)、コミュニケーションの開始(インプットとアウトプット)、IT活用スキル
- 6〜7月:自主制作(プログラミングやデータの工夫)、実験の繰り返し、調査・分析、将来計画立案
- 7月:中間発表、学会発表の準備
- 8月:課題発見と課題解決、技術理解、根拠提供、論理的思考、学会発表
- 9〜11月:ITシステム制作、制作物の調査・分析、説明力、客観的な評価
- 12月:卒業論文執筆、卒論プレゼン
- 1〜2月:仕上げ、学会発表
卒業研究の関連資料
- 卒業研究のメリット、心構え:PDFファイル, パワーポイントファイル
- 情報工学演習II、情報工学演習III、卒業研究の進め方や卒業論文の書き方の説明: 別ページにある。
フィードバック 10/11 の発表に対して
(10/18 については待っていてほしい)
学生の研究テーマは興味深く、多岐にわたる内容である。それぞれの研究がさらに進展することを期待する。
アドバイスは、研究力を高め、卒業研究の満足感を高めるためのものである。アドバイスの通りに研究する必要はなく、常に自身で考え行動し、楽しく研究することが大切である。研究の満足感を上げるためには、リサーチや実験を辛抱強く繰り返すことも大切である。
各自の発表のまとめも記載しているので、他の人の研究を知り参考にしたり、「自身の研究を分かりやすく発表したい」ときに活用すること。
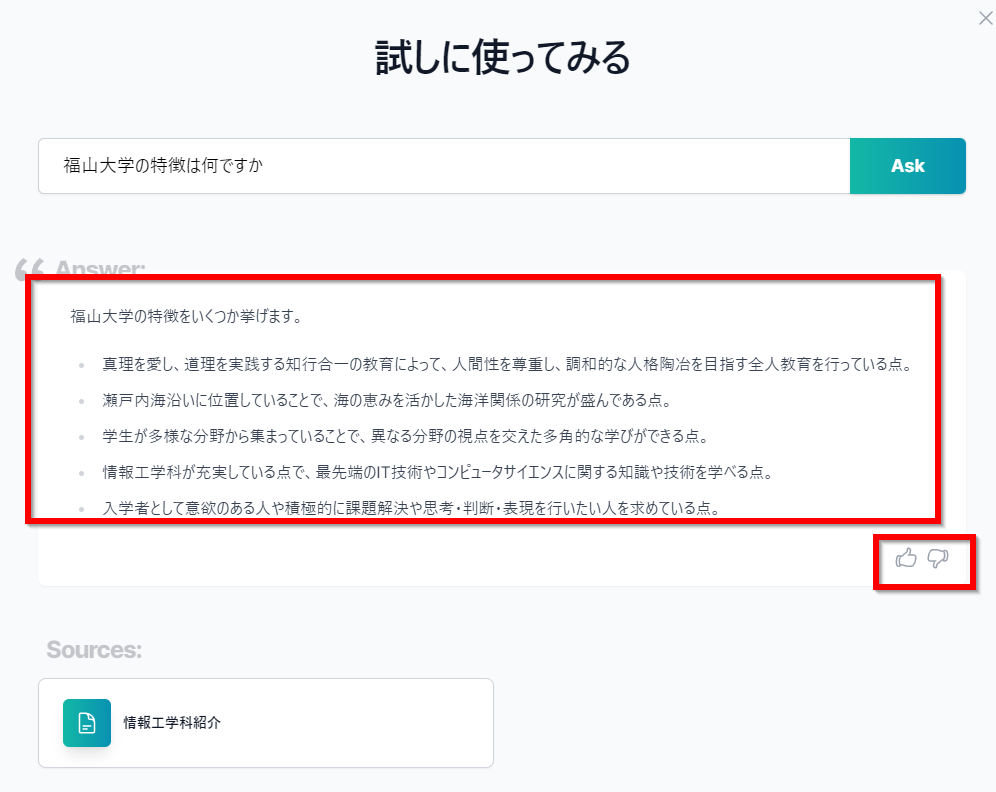
- 福山大学のDocsBot(文書から自動で応答するAI)について
- DocsBotを使用して簡単な応答が可能である。
- DocsBotの動作方法を学習する。
- 根拠の少ない返答やハルシネーション(AIが事実でない情報を生成する現象)を確認する。
- プロンプトエンジニアリング(AIへの指示を最適化する技術)の探求を検討する。
良いポイント: DocsBotで実験を行い、具体的な問題点を特定している。今後の研究の方向性が明確になっている。
アドバイス: ハルシネーションや根拠の少ない返答の原因を特定するために、さまざまな質問を与え、ふるまいを観察してみる。
- AIナンバープレート認識の精度向上について
- 夜間の写真の精度を研究する。
- Easy OCR(光学文字認識ライブラリ)を使用して暗い画像での実験を実施する。
- ヒストグラム均等化(画像のコントラスト改善手法)を試み、数字の部分での精度向上を確認する。
良いポイント:実際の問題(夜間のナンバープレート認識)を定め、具体的な技術(ヒストグラム均等化)を使用して解決を試みている。夜間のナンバープレート認識は有用性が高い研究である。
アドバイス:他の画像前処理技術(例: ガンマ補正(画像の明るさ調整手法))も試して、夜間の画像の品質を向上させ、認識精度の変化を確認することもできる。
- ゲーム内の宝箱作成に関する研究
- Blender(オープンソース3DCGソフト)でのモデル作成とUnreal Engine(高性能ゲーム開発エンジン)でのアニメーション実装。
- ゲーム性を高めるための追加要素を検討する。
- 友人へのフィードバック収集を計画する。
良いポイント: Unreal Engineを使用して実装を行っている。今後、ユーザーのフィードバックを取り入れる計画を持っている。第三者のフィードバックを受けることで、さらなる発展が期待できる。
アドバイス: プレイヤーの反応や感想を具体的に集めていく。ITやAIの技術を使った具体的なゲームコンテンツ制作にも挑戦し、自作したゲームコンテンツについてのプレイヤーの反応や感想も集めてみる。
- 顔のランドマーク検出(顔の特徴点を見つける技術)について
- リアルタイムでの検出の困難さ。
- 静止画での実験を実施する。
- 動画やカメラを使用した検出を計画中である。
良いポイント: 静止画での実験を行い、基本的な技術の理解と検証が進んでいる。リアルタイム検出への挑戦を計画している。
アドバイス: InsightFace(顔認識ライブラリの一つ)を使用しているようである。さまざまなシチュエーションの顔検出を行い、実際の環境での考察を試みる。ランドマークを使った応用(表情推定、個人識別)のリサーチも考えてみる。
- 行動追跡技術の研究
- アルバイト先での動画収集。
- 人物の識別技術を試みる。
- 人物の追跡に関する問題点の確認。
良いポイント: 実際のシチュエーションの動画を使用して実験を行い、複数人の追跡の追加実験を予定している。実際の環境での応用を意識していることも良いポイントである。
アドバイス: ディープラーニング(深層学習:多層のニューラル網)を用いた追跡手法(例: DeepSORT(物体追跡アルゴリズム)、10/24 の回の Cutie(ビデオオブジェクトセグメンテーションAI))を導入し、精度の向上を考察してみる。
- YOLO(リアルタイム物体検出アルゴリズム)を使用した道路標識の検出
- 約10種類、約3000枚の画像を学習する。
- 遠くの標識の検出の困難さを確認する。
- ドライブレコーダーでのリアルタイム検出を計画する。
良いポイント: 大量の画像データを用いて学習を実施し、実際の道路環境で標識の検出を行い、問題点を特定している。実データを使い問題点を特定していることは、現実の問題解決につながる研究である。
アドバイス: 遠くの小さな標識に対する検出精度向上については、「アンカーボックス(物体検出で基準となる矩形)のサイズ」や「アスペクト比(矩形の縦横比)の調整」が役立つというような過去の研究を自身でリサーチする。
- Stable Diffusion(画像生成AIモデル)の使用に関する研究
- キャラクターのポーズ生成。
- コントロールネット(画像生成AIの制御技術)の使用。
- サンプルに基づく画像生成の試み。
良いポイント: サンプルを使用して比較実験を行い、具体的な問題点を探索し、技術の向上を目指す研究である。
アドバイス: サンプルとして与える棒人間の描き方のバリエーションを試してみる。Stable Diffusion のバリエーションをリサーチしてみる。
毎回の活動記録
昨年の卒論ファイルのうち4名分:昨年の卒論ファイル(研究室のパソコンからアクセスできる)
Transformer(自然言語処理等で使われる深層学習モデル)を扱うプログラム:
https://colab.research.google.com/drive/1L9n5E0_BTRy1q0jE1I2xT3MTuSpceVSY?usp=sharing
1. 4/13 10:50- - 卒業研究開始とオリエンテーション
研究を開始する。卒業研究説明を行う。
【研究室の記事,資料】
- 金子邦彦研究室紹介:[PDF], [パワーポイント]
- 情報工学科の特色:[PDF]
- 情報工学科説明:[PDF], [パワーポイント]
- 4年生へのアドバイス、次の資料のページ44からページ59:[PDF], [パワーポイント]
- 金子研究室のパソコンは自由利用(全員でシェアする)。特定の座席は決めない。
- 集合時間: 火曜日の10時50分、木曜日の10時50分
- 就職活動:まだ間に合う。頑張ること。履歴書を書く。志望理由は「技術系(IT分野)の専門職を志望」の一択を推奨する。アピールポイントは次を参考にすること。
- 技術力に自信がある
大学では IT に関する専門知識を学び、プログラミング、データベース、ネットワーク、人工知能などの技術力を習得してきた。これらの技術力は、就職後役立つものであり、自身の成長や業務遂行に必要である。(自信を持って自身が習得した技術力をアピールすること。その技術力をどのように活かすか、どのような業務やプロジェクトで活躍できるかを考えること)。
- 課題解決能力に自信がある
課題解決能力は、ITの仕事でも、とても重要なスキルの一つである。学生時代に、プログラム作成や、ITシステム制作など、大学の宿題、自主制作、卒業研究などを通して、さまざまな課題に直面し、解決した経験があるということは、大きなアピール・ポイントになる。(その際には、自身がどのように課題に直面し、自力で、あるいは仲間や教員と相談しながら、どのように解決したのかを具体的に伝えること)。
- コミュニケーション能力に自信がある
ITの仕事では、顧客やチームメンバーとのコミュニケーションが欠かせない。いままでの授業や卒業研究での、グループでのプロジェクト活動を通じて、自主的に勉強を行い、学んだことや考察したこと、調査・実験結果を仲間や教員と共有することで、コミュニケーション能力を向上させた体験は、大きなアピール・ポイントである。(また、今後もコミュニケーション能力を磨くために、どのような取り組みをしていくかを考えること)。
- 技術力に自信がある
- 大学院進学準備(福山大学の情報処理工学専攻は、6月推薦入試:面接、GPA 3.3 以上、8月と冬:ペーパーテストのいずれか)
【宿題の目的と注意点】
- 研究スキルのアップのため、調査力、実験力、考察力を高めてもらう。
- 内容: 各自でプログラムを動かす。プログラムは教員や仲間と一緒に準備する。プログラムを動作させるためのデータは自身で準備する。アウトプット(実験手順の説明、プログラムで行っていることの調査、実験結果の説明、自身でどう工夫したら、結果がどう変化したか)も自身で準備し、他の仲間や教員に向けてアウトプットしていく。実験手順や実験結果の説明の書き方などは、練習が必要なので教員から教わる。
- 自主的な活動が大切である。
- グループでの活動を大歓迎である。考え方や価値観が異なるので、面白い。面白さ、仲間との刺激も大切である。
【宿題】 1ヶ月間のテーマ選び
各自、テーマを選んで、メールで提出すること(締切: 火曜日まで)。
そして、次回の集まりで、自身で選んだテーマについて、他の仲間に説明すること(面白そう、やってみたいと思った理由。何の役に立ちそうか。なぜ、興味を持ったか)。
テーマ案
- 画像の画像理解、AI利用
- 揺れるビデオ、古いビデオの画像理解、AI利用
- 河川や野山の植生変化観測、AI利用
- ネットワークカメラシステム、顔情報処理、AI活用
- チャットボット、自動翻訳、音声合成システム、音声認識システムの活用
- 未来予測(渋滞予測など)、AI活用
- 3次元姿勢のデータベース、AI活用
- 3次元の福山市の再現
その他の重要事項
- 健康診断を受けること。まだ間に合う。いずれ必要である。
- 就活用の履歴書を書くこと。まだ間に合う。
2. 4/18 10:50- - 研究テーマ選びとレポート作成
研究テーマ選びを考える。研究レポートの書き方。
チームワークの重要性: 各自がアウトプットする。チームワークが大切である。チーム内で、役割分担は行っても良い。そのために、チームメンバーの中で、スキル、得意分野などを把握し、活用することも考える。チーム内のコミュニケーション手段やツールも考える。
【各自のアウトプット】
テーマ選びと理由の明確化。アウトプットしやすい自身なりのやり方を自身で考察する。研究の意義や価値を意識する。
【今後1ヶ月間の活動のテーマ】
石原:「対話によるデータアクセス」、「3次元再構成」
小林:「画像理解」
曽根田:「3次元の福山市の再現」、「3次元再構成」
檀上:「未来予測、AI活用」
中村:「画像理解」
宮:「未来予測、変化要因の分析」
森井:「画像理解」
自身で選んだテーマについて、他の仲間に説明すること(面白そう、やってみたいと思った理由。何の役に立ちそうか。なぜ、興味を持ったか)。
【研究室の記事,資料】
- 卒業研究の心構え。研究テーマ選びを考える。研究レポートの書き方。次の資料のページ7から17。PDFファイル, パワーポイントファイル(卒業研究のメリット、心構え)
【宿題】
- 次の資料のページ7からページ17を復習する。PDFファイル, パワーポイントファイル(卒業研究のメリット、心構え)
卒業研究のメリット、心構え:PDFファイル, パワーポイントファイル
各自の研究テーマに関する調査を自身で行い、興味関心を確認する。締切: 4月20日まで。
- 最新技術、流行(1から2年以内の記事)
- 関連する学問分野の知識
- 研究を通して社会に貢献する可能性について
4月20日に各自、みんなの前で口頭説明することにより、アウトプットする。チームワークを歓迎する。
3. 4/20 10:50- - 研究の基礎とPython活用
「研究」について知る。Python を活用する。
【各自のアウトプット】
研究テーマの調査について。次の資料のページ7から12の部分、PDFファイル, パワーポイントファイル(卒業研究のメリット、心構え)。
各自の研究テーマに関する調査を自身で行い、自身の興味関心を確認するという宿題であった。
- 最新技術、流行(1から2年以内の記事)
- 関連する学問分野の知識
- 研究を通して社会に貢献する可能性について
各自、次の分野を踏まえ、口頭でアウトプットしてもらう。
各自の発表内容
石原:「対話によるデータアクセス」 チャットボット chatGPT を勉強してみたい。GPT-4(今年最新)。顧客からの問い合わせ対応や業務効率化。AI応用。福山大学の複雑な何かにこたえることができるチャットボットを作ってみたい。
小林:「画像理解」 画像理解。センシング。便利なのはいいが、AI の悪用が気になる。AI の誤作動を発生させるような攻撃があることを知り、AI の弱点を実験していきたい。
曽根田:「3次元の福山市の再現」、「3次元再構成」
檀上:「未来予測、AI活用」 未来予測。交通事故で役に立っている。自転車のヘルメットの義務化のニュースがあった、ヘルメットを要因として、事故の軽減の結果が得られる。世界のコンテストで交通事故関連のデータが公開されているらしいので、調べてみたい。面白そうである。
中村:「画像理解」 画像理解。画像の意味を理解する技術、物体検出(物体の位置や大きさを検出)、セグメンテーション(物体の境界や形)。画像理解は、周りの道路標識を理解するなどで、自動運転に役に立つ。自動運転について研究してみたい。
宮:「未来予測、変化要因の分析」 自身なりに考察、調査中である。
森井:「画像理解」 画像理解 画像分類、物体検出、セグメンテーションがある。CNN、Transformer などを利用。自動運転で活用されている。状況判断に利用。医療ではX線やMRIの解析に利用されている。まずは、画像理解の仕組みを知ること、画像のよる状況判断の仕組みを知ることから開始したい。
【研究室の記事,資料】
- 「研究」について知る。Python を活用する。次の資料のページ13から23。PDFファイル, パワーポイントファイル(卒業研究のメリット、心構え)
- Python の基礎
- プログラミングの基礎と Python 言語入門:創造的なデジタルスキル [PDF], [パワーポイント], [HTML(HyperText Markup Language:ウェブページ記述言語)]
- 式、変数 [PDF], [パワーポイント], [HTML]
- 計算誤差、データの種類 [PDF], [パワーポイント], [HTML]
- 式の抽象化と関数 [PDF], [パワーポイント], [HTML]
Pythonプログラムの実行方法: コマンドプロンプト、python コマンド、jupyter qtconsole(対話型Python実行環境), spyder(Python統合開発環境)。
【宿題】
- この活動を受けて、各自、今後1ヶ月で何を行ってみたいかを考察する。音声認識、音声合成、AIの能力を知るか。物体検出してみるとき何を対象にするか。
各自、いま、何を学び、何を作り上げてみたいか、何を体験してみたいのか、さらに詳しく話すことができるように準備(4月25日に各自、話してもらう)。各自のさらなる調査を希望する(1から2年以内の最新技術、関連する学問分野の知識、自身が体験してみたいこと、研究を通して社会に貢献する可能性について)。
- 研究室では、パソコンで Python プログラムを動かす(パソコンで動かす、Google Colaboratory など補助的に使う)という方針である。
Python 実行スキルの習得
研究室のパソコン利用を推奨する。(自身のパソコンで Python を動かすためにはインストールが必要である。興味のある人は質問すること)。
- python コマンドで python プログラムを実行する。コマンドプロンプトを開き、次のコマンドを実行する。
python print(1 + 2) exit() - jupyter qtconsole で python プログラムを実行する。コマンドプロンプトを開き、次のコマンドを実行する。
python -m jupyter qtconsole次のプログラムを実行する。
次のプログラムは、NumPy(Pythonの数値計算ライブラリ)と Matplotlib(Pythonのグラフ描画ライブラリ)を使用して、0から6までの範囲のsin関数のグラフを描画する。warnings モジュールを使用して Matplotlib の警告表示を抑制し、Matplotlib では、デフォルトのスタイルを使用する。
import numpy as np %matplotlib inline import matplotlib.pyplot as plt import warnings warnings.filterwarnings('ignore') # Suppress Matplotlib warnings x = np.linspace(0, 6, 100) plt.style.use('default') plt.plot(x, np.sin(x))実行で問題なかったかを確認(スキル習得の自己確認)。
Python プログラミングの基礎に興味のある人は、次のページを活用するなどで、各自で補充すること。
- python コマンドで python プログラムを実行する。コマンドプロンプトを開き、次のコマンドを実行する。
4. 4/25 10:50- - 最新技術のインストールと体験
研究のためのより良い行動。各自の自己研鑽。研究室のパソコンに何がインストールされているか。
重要性: 最新技術をパソコンにインストールし、操作できる実力は、将来、自身で学び挑戦し成長する基礎になる。
【各自のアウトプット】
各自、いま、何を学び、何を作り上げてみたいか、何を体験してみたいのか、さらに詳しく話すことができるように準備(4月25日に各自、話してもらう。)という宿題であった。各自のさらなる調査を希望する(1から2年以内の最新技術、関連する学問分野の知識、自身が体験してみたいこと、研究を通して社会に貢献する可能性について)。
各自のテーマ
石原:「対話によるデータアクセス」、「3次元再構成」
小林:「画像理解」
曽根田:「3次元の福山市の再現」、「3次元再構成」
檀上:「未来予測、AI活用」
中村:「画像理解」
宮:「未来予測、変化要因の分析」
森井:「画像理解」
【研究室の記事,資料】
- 研究のためのより良い行動。各自の自己研鑽。次の資料のページ24から34。PDFファイル, パワーポイントファイル(卒業研究のメリット、心構え)
【宿題】
- まずは、研究室ホームページを参照する
AI、3D技術、データベースの技術情報。
- 興味を持った技術をインストールして試してみる
自身で探すこと自体も宿題である。最新技術を実践的に体験する。数は自由(多くても良いし、1つか2つをじっくりでも良い)。
- 既にインストール済みのソフト(前ページ)は、再インストールする必要はない
- オンラインデモのページも活用すること
- 4月27日,5月2日に口頭で、他の仲間に披露(パソコンを利用可)
5. 4/27 10:50- - 自主学習と活動報告
引き続き、自己研鑽力、パソコン活用スキルを目指す。
各自からのアウトプット:各自が学んだり、活動していること。
【研究室の記事,資料】
- オンラインサービス(人工知能関連):https://www.kkaneko.jp/ai/online/index.html
- オンラインサービス(プログラミング関連):https://www.kkaneko.jp/cc/onlineservice/index.html
- Windows で動く人工知能関係 Pythonアプリケーション、オープンソースソフトウエア): https://www.kkaneko.jp/ai/win/index.html
- Windows でのインストールと動作確認(3次元関係): https://www.kkaneko.jp/db/win/index.html
【外部ページ】
- chatGPT: https://openai.com/index/chatgpt
- DeepL翻訳(高性能機械翻訳サービス): https://www.deepl.com/ja/translator
6. 5/2 10:50- - 自主学習と活動報告
引き続き、自己研鑽力、パソコン活用スキルを目指す。
【各自のアウトプット】
各自が学んだり、活動していること。
7. 5/7 10:50- - YOLOv7による物体検出実習
実験の実施(結果、考察、手順の説明を目指す)。ChatBot などの対話型AIの適切な活用、引き続き、自己研鑽力、パソコン活用スキル。Windowsパソコンでの物体検出 YOLOv7。
【研究室の記事,資料】
- 実験の実施(結果、考察、手順の説明を目指す)。ChatBot などの対話型AIの適切な活用:次の資料のページ35から53。PDFファイル, パワーポイントファイル(卒業研究のメリット、心構え)
- Windowsパソコンでの物体検出 YOLOv7 https://www.kkaneko.jp/ai/labo/yolov8pose.html
パソコンのカメラについて物体検出を行い、確認表示する。
python detect.py --weights yolov7.pt --conf 0.25 --img-size 1024 --source 0
【外部ページ】
- chatGPT: https://openai.com/index/chatgpt
【宿題】
引き続き、次の資料のページ35から53。PDFファイル, パワーポイントファイル をよく読み、ChatGPT の活用、実験の実施、ICT スキルの自主的な取得を進めること。仲間の助けを積極的に求めること。
8. 5/9 10:50- - ChatGPTと質問応答システム
ChatGPT
【研究室の記事,資料】
- 質問応答(QA)システム、DocsBot にファイルをアップロードし、質問応答システムをオンライン実行(チャットボットによる質問応答システム)
メリット: 大量の文書から必要な情報を自動抽出し、ユーザーの質問に回答できる。
【外部ページ】
- DocsBot AI のページ: https://docsbot.ai/
- chatGPT のページ: https://openai.com/index/chatgpt
【宿題】
引き続き、次の資料のページ35から53。PDFファイル, パワーポイントファイル をよく読み、ChatGPT の活用、実験の実施、ICT スキルの自主的な取得を進めること。仲間の助けを積極的に求めること。
補足説明
- 楽しく熱中して取り組むことができるという気持ちを大切にすること
- 今後も使い続けたい技術、ソフトを発見したときは、各自でメモすること。他の人ともシェアすること
- 次の態度を希望する
うまく動いた部分を分析し、その利用価値や改善点を考えること、そして、他の人とアイデアを共有する人を歓迎する。
失敗やうまく動かなかった部分だけに焦点を当てず、全体を俯瞰して学びを得ることが重要である。
9. 5/16 10:50- - セマンティックセグメンテーション
セグメンテーション
セグメンテーションに関する説明など:sotu2023-05-16.pptx
次の資料の関係部分を説明する。PDFファイル, パワーポイントファイル をよく読み、
【研究室の記事,資料】
- セマンティック・セグメンテーション(MMSegmentation(セマンティックセグメンテーション用ツールキット)のインストールと動作確認)(PyTorch,Python を使用)(Windows 上)
メリット: 画像を意味のある領域に分割できる。自動運転、医療画像解析などに応用される。

- 4年生へのアドバイス、次の資料のページ44からページ59:[PDF], [パワーポイント]
外部リンク:
OneFormer(統一的画像セグメンテーションAI): https://huggingface.co/spaces/shi-labs/OneFormer
10. 5/18 10:50- - 画像補正と線分検知
画像補正、線分検知
安否確認訓練の説明 説明資料
【資料】 PDFファイル, パワーポイントファイル
【研究室の記事,資料】
- chasank/Image-Rectification のインストールと画像補正の実行(画像補正)(Python を使用)(Windows 上)
メリット: 歪んだ画像を補正し、正確な測定や分析が可能になる。


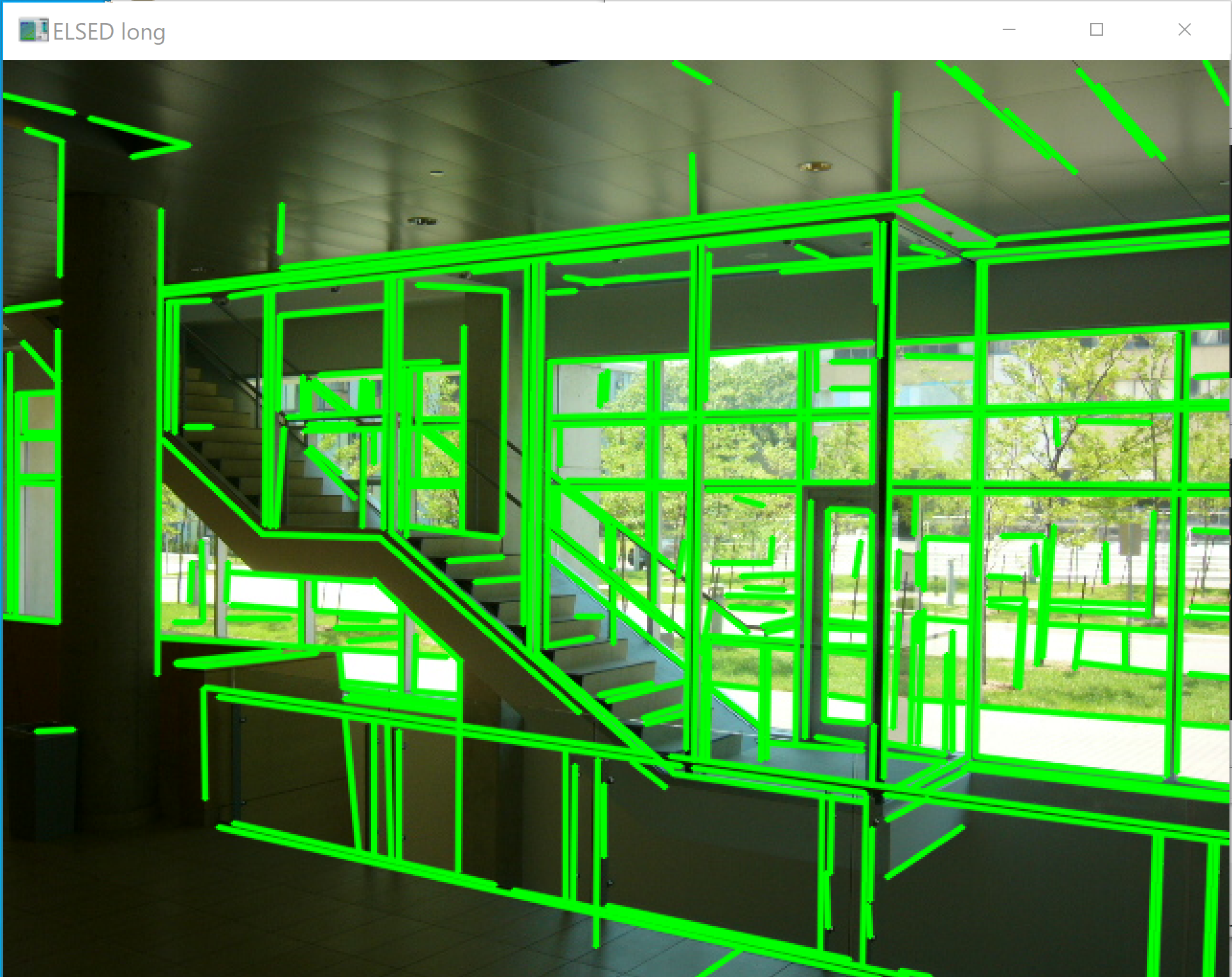
- ELSED(高速線分検出アルゴリズム)のインストールと動作確認(線分検知)(Build Tools(ソフトウェア開発用ツール群), Python を使用)(Windows 上)
メリット: 画像から直線成分を高速に抽出できる。建築物の認識や文書解析に有用。
11. 5/23 10:50- - 企業訪問と情報交換
某社人事教育担当者が訪問する。メーカーでの仕事内容、教育等を含め情報交換すること。
【研究室の記事,資料】
12. 5/25 10:50- - Unreal Engine 5の紹介
Unreal Engine 5 の紹介。3次元ビデオゲーム、3次元のアプリを制作するとき役立つ。
【研究室の記事,資料】
- Unreal Engine 5 のインストールと基本機能: [PDF], [パワーポイント]
Unreal Engine 5 の動作画面など:[PDF] のページ21から26
インストール準備
- Epic Games アカウントのサインアップ:国、氏名、ディスプレイネーム、メールアドレス、パスワードの登録が必要である
- Epic Games Launcher (Epic ゲームズ・ランチャー)のインストール
インストール手順: Epic Games アカウントのサインアップしてから、Epic Games Launcher (Epic ゲームズ・ランチャー)をインストールし、そして、Epic Games Launcher (Epic ゲームズ・ランチャー)を起動し、その中のメニューで、Unreal Engine 5 をインストールする。
- Unreal Engine 5 での物理シミュレーション:[PDF], [パワーポイント]
- レベルブループリント(ビジュアルな操作でゲームをデザインし制作):[PDF], [パワーポイント]
- その他 Unreal Engine 5 の基本機能や基本操作について:別ページ »にまとめている
13. 5/29 10:50- - テキスト検出の実習
テキスト検出の回
研究の考え方: 卒業研究では、ICTの基本スキル、自主的活動、問題解決を行ってもらう。実験は「失敗した」と決めつけるのではなく、「うまく行った範囲で何の役に立つかを考え、実行してみる」か「成功するまで、辛抱強く継続する」かを考えてもらうもの。
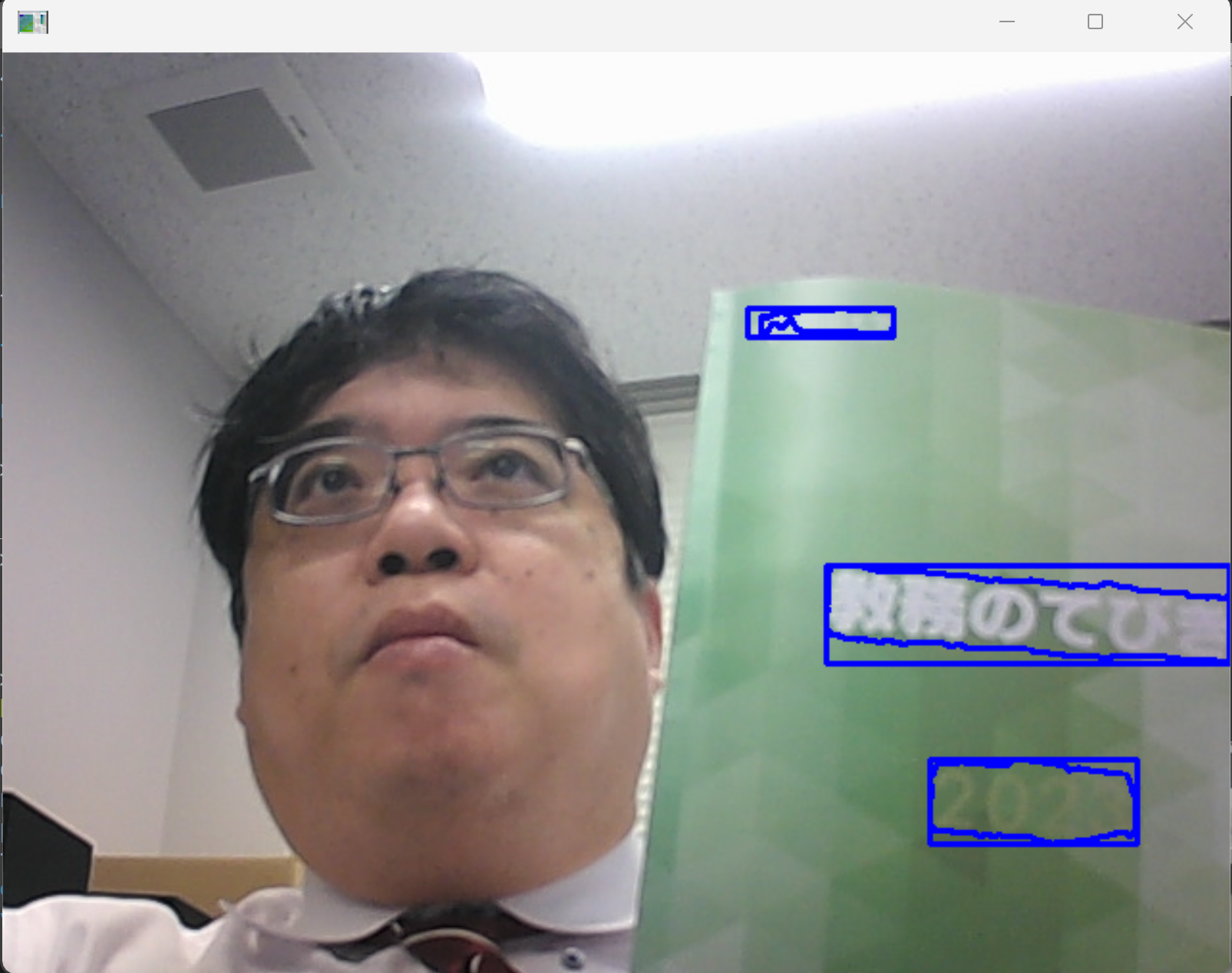
【研究室の記事,資料】 Unified Scene Text Detection(統一的シーン文字検出AI)のインストールとテスト実行(テキスト検出)(Python,TensorFlow を使用)(Windows 上)
応用例: 看板の自動認識、文書のデジタル化など。
テキスト検出

テキスト検出
14. 5/31 10:50- - 消失点推定の実習
消失点推定の回
【研究室の記事,資料】 neurvps(消失点推定AIモデル)のインストールと動作確認(消失点推定)(Python,PyTorch を使用)(Windows 上)
応用例: 画像からの3次元復元、建築物の形状推定など。
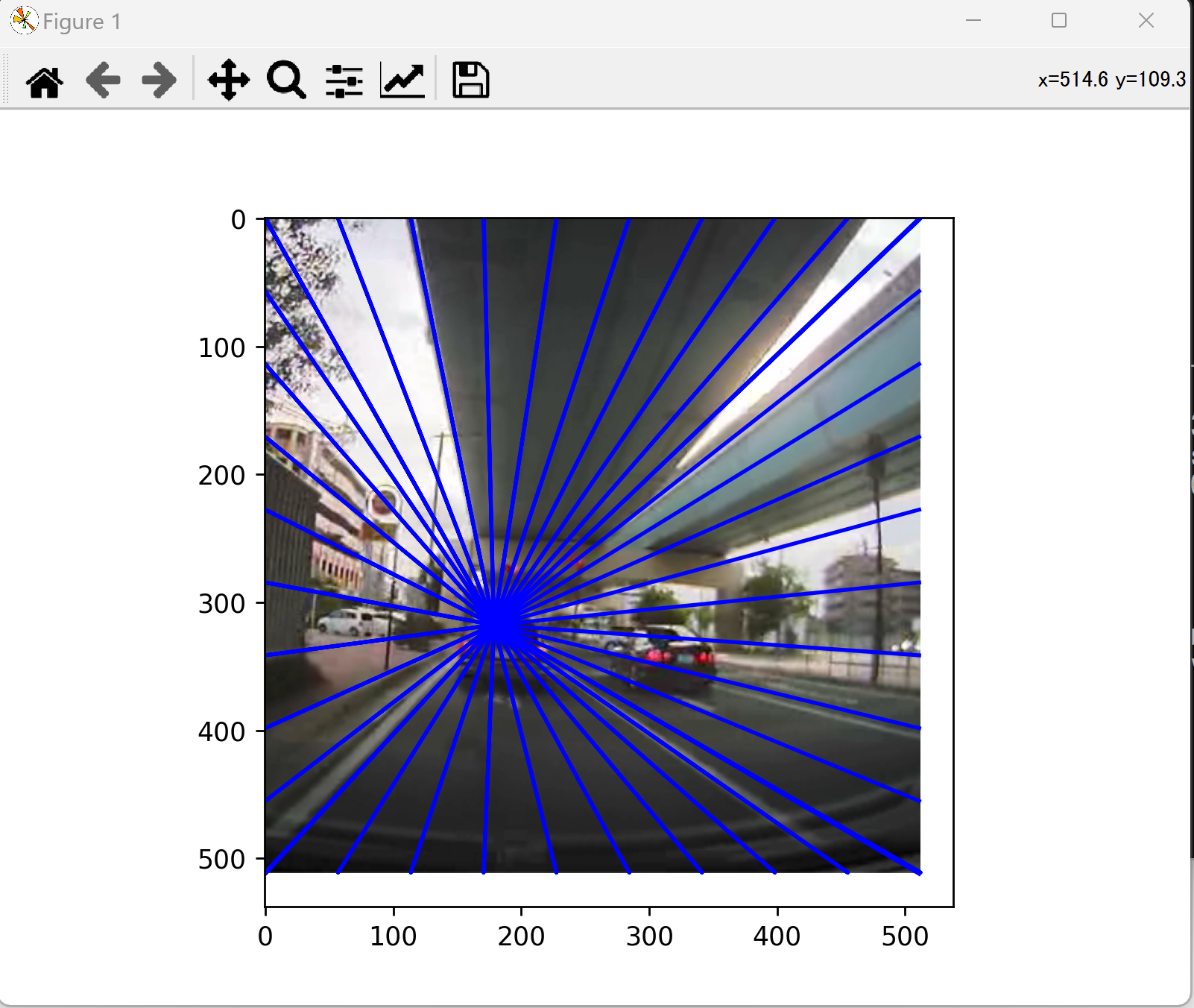
宿題: 6月7日は、各自発表とする。
自身が楽しいと思えることについて発表する。
具体的な経験、体験を伝えてもらう。
今後やりたいこと、自身の研究が何の役に立ちそうか、自身で解いてみたい課題は何か。
15. 6/5 10:50- - 物体検出の実習
物体検出の回
【研究室の記事,資料】 物体検出の実行(UniDet(統一的物体検出モデル),PyTorch, Python を使用)(Windows 上)
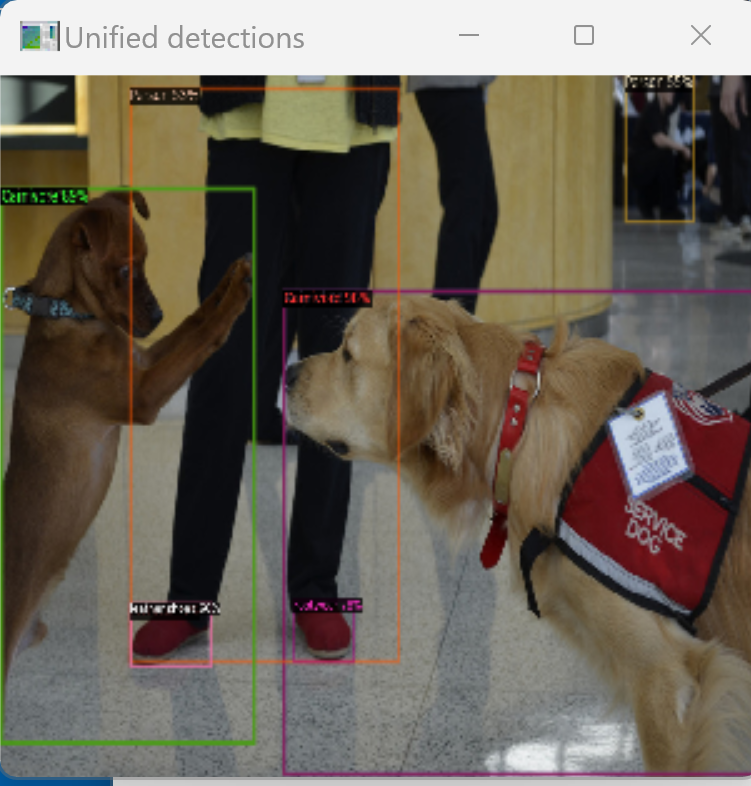
16. 6/8 10:50- - 各自のアウトプット発表
発表形式: 問題、仮説、実験手順、結果、考察。引用文献。
意識すべきこと: 具体的に。わかりやすく伝える。失敗は気にしない。テーマは自身の興味を持つものを選ぶ。解決困難な課題や、すでに解決済みの課題を選んでしまっている場合は、自身で納得のいくまでやり抜いてから気づくというのも良いし、教員や仲間から事前にアドバイスを得るのも良い。解決可能な課題を見つけ、熱中して取り組むことが理想である。研究は何が終われば終了ということはなく、粘り強く活動を継続することになる。
各自のテーマ
石原:「対話によるデータアクセス」、「3次元再構成」
小林:「画像理解」
曽根田:「3次元の福山市の再現」、「3次元再構成」
檀上:「未来予測、AI活用」
中村:「画像理解」
宮:「未来予測、変化要因の分析」
森井:「画像理解」
17. 6/13 10:50- - プログラミングとAIの理解深化
プログラミングとAIについて理解を深め、自信を高める。作業の自動化、実験などでも役に立つ。自己アピール、自身に自信を持つことも大切である。
18. 6/15 10:50- - 自主学習日(Dlib表情推定)
自由参加である。金子は欠席する。
- Dlib のインストールと実行(表情推定など):別ページ »で説明
更新情報: うまく動かなくなっていたので、動くように記載を変更した。
19. 6/20 10:50- - 3次元データ生成とゼロショット物体検出
- プロンプト(文章)からの3次元データの生成:別ページ »で説明
メリット: テキストから3Dモデルを生成できるため、ゲーム開発やVR/ARコンテンツ制作の効率化に役立つ。
- ゼロショットの物体検出(Grounding DINO(自由形式テキストで物体検出AI),Python,PyTorch を使用)(Windows 上): 別ページ »で説明
メリット: 事前学習なしで自由なテキスト指示により物体を検出できる。柔軟性が高く、様々な対象に対応可能。
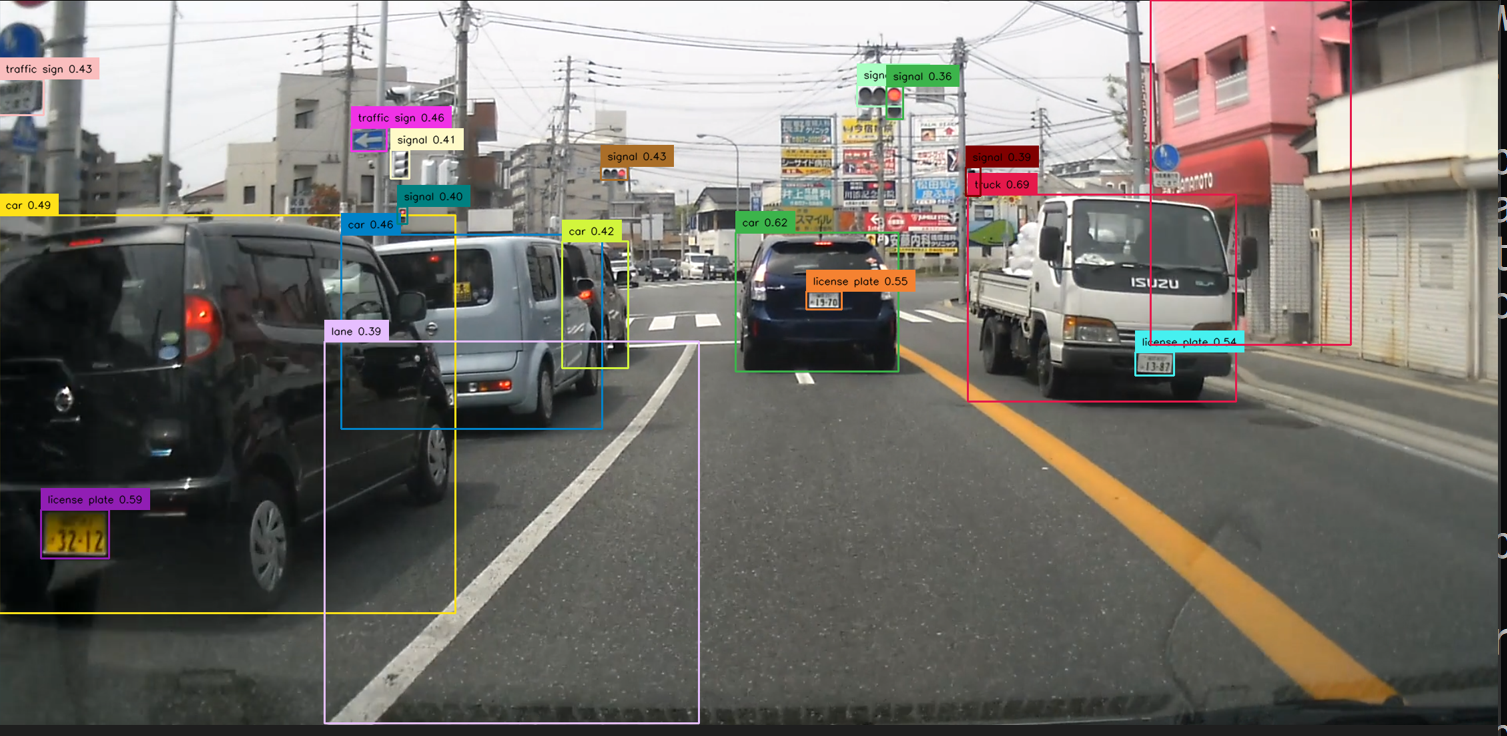
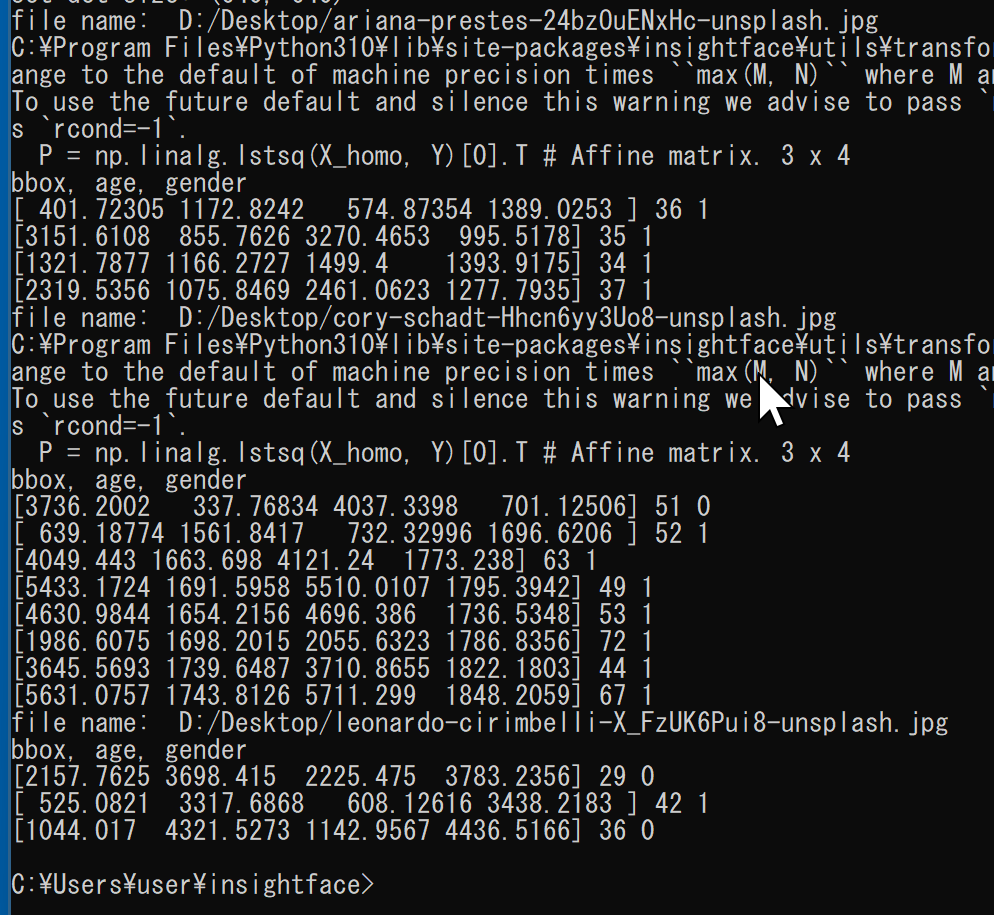
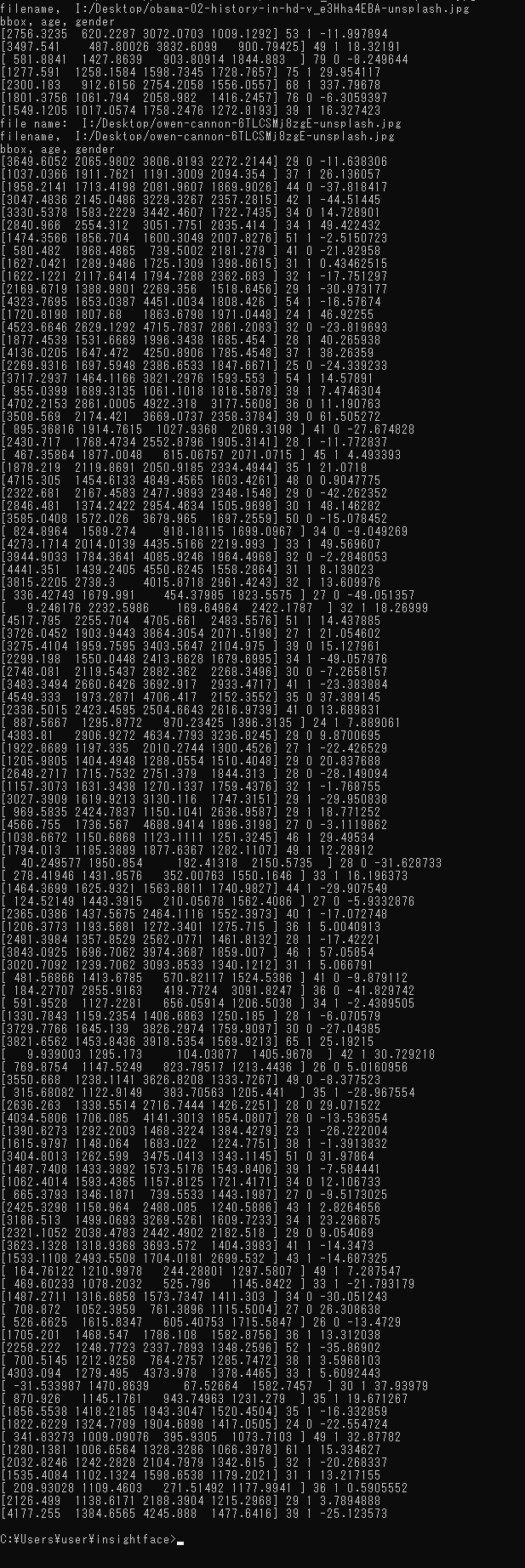
20. 6/22 10:50- - InsightFaceによる顔分析
顔検出、年齢と性別の推定、顔識別、人体検出: 別ページ »で説明
応用例: セキュリティシステム、顧客分析、アプリケーションの個人化など。


21. 6/27 10:50- - FastSAMの紹介(自主学習日)
6月27日(火曜日)は金子は欠席する。自由参加とする。
SAM (segment anything)は、自由なプロンプトを英語で指定して、セグメンテーションを行う技術である。
そのうち、FastSAM(高速化されたSAM)について、FastSAM のインストールと動作確認(セグメンテーション)(PyTorch を使用)(Windows 上)を、別ページ »で説明する。
全体のセグメンテーション

「the yellow dog」というプロンプトを指定してセグメンテーション

22. 6/29 10:50- - 自主学習日
6月29日(火曜日)は金子は最初2から3分だけ出席する。自由参加とする。
来週には、各自発表の計画がある。
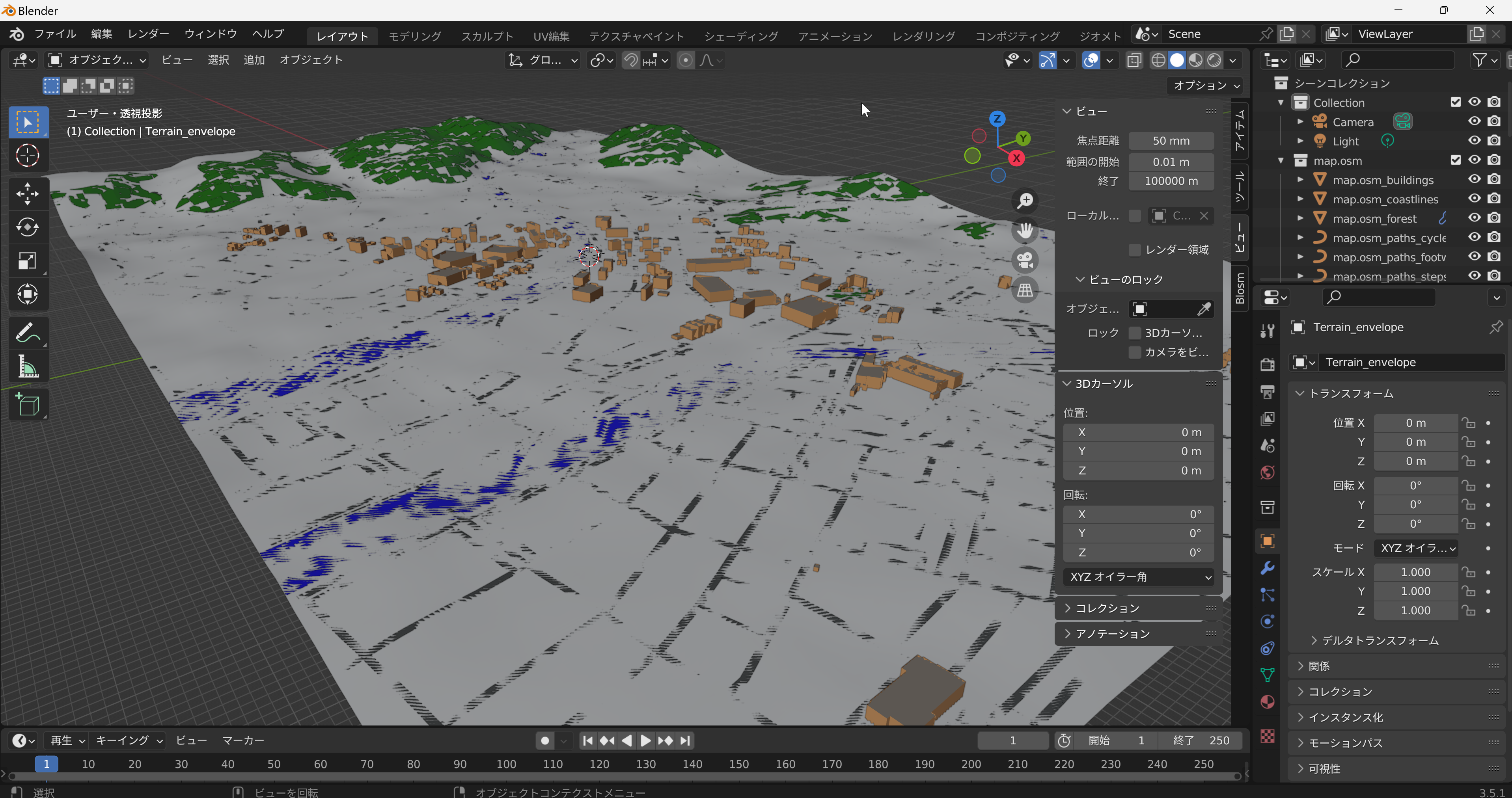
23. 7/11 10:50- - Blosm for Blenderのインストールと中間発表の準備
Blosm for Blenderのインストール手順
- https://prochitecture.gumroad.com/l/blender-osm
- ZIP ファイルをダウンロードする
- ZIP ファイル(blosm.zip)をBlender でアドオンとしてインストールする
OpenStreetMap(自由編集可能な世界地図データ)福山大学周辺。一部の建物、道路、地形、水域を確認できる。
中間発表の案内
https://cerezo.fukuyama-u.ac.jp/ct/course_342000_news_1361123?action=status
- 課題解決: 適切で解決可能な課題を選択し、自立的に進行することが重要である。無理な課題を選ばず、自身が卒業までに実施したいものを選ぶように心がけること。複数選んでおくことが大切である。
- 技術理解: 自身で必要な技術について調査し、理解することが必要である。少なくとも2つ以上の技術について調査し、理解しておくこと。自身が利用している技術について、仕組みやメリットや利用上の注意点を理解しておくことが大切である。
- 根拠提供: しっかりとした考察が必要で、実験手順や結果の説明には具体的な根拠を提供することが求められる。
教員とのコミュニケーションが必要である。
24. 7/13 10:50- - Google Tile APIとBlosmの活用
Blosm for Blender(Blender用OSMデータ連携アドオン)で Google Tile API(Google Mapsの地図タイルAPI)のデータをダウンロード。福山市の3次元データをパソコンの Blender で表示。
注意: 基本は全世界ダウンロード可能。サービスは登録が必要で所定の料金が必要である。
Google Tile API, 福山市中心街、最高品質でダウンロード
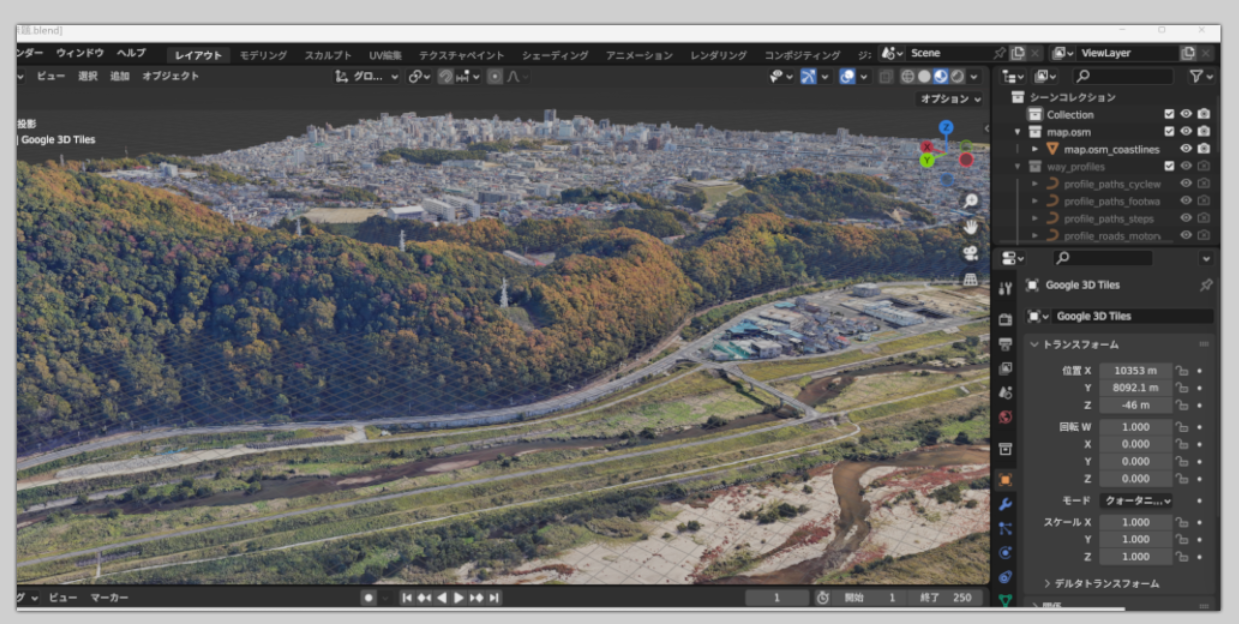
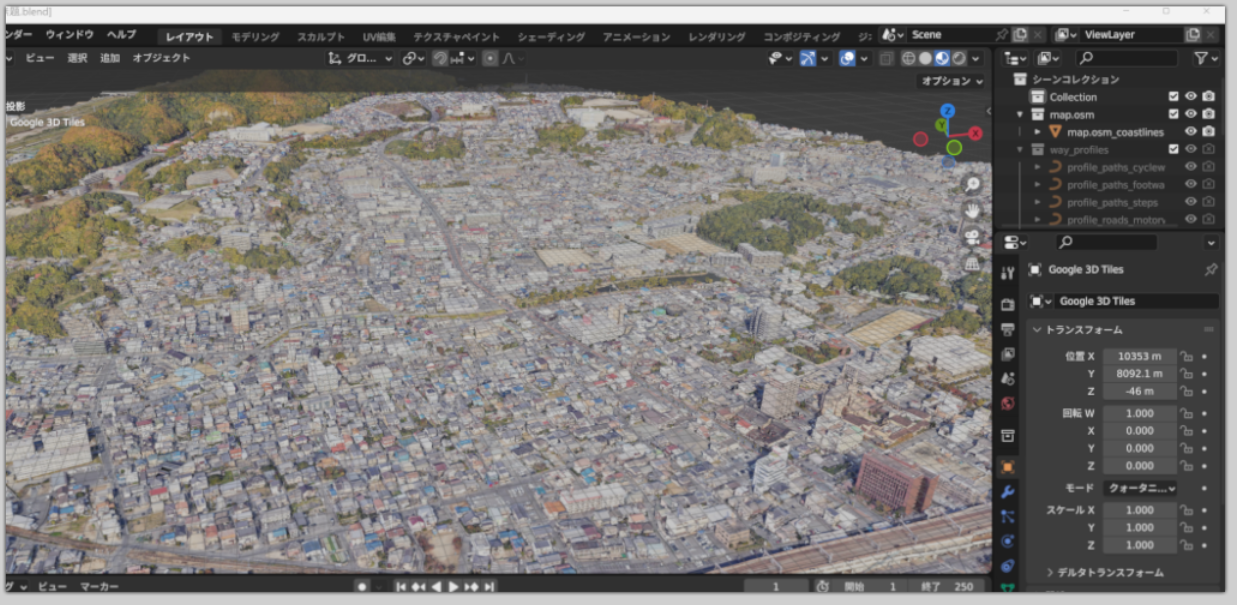
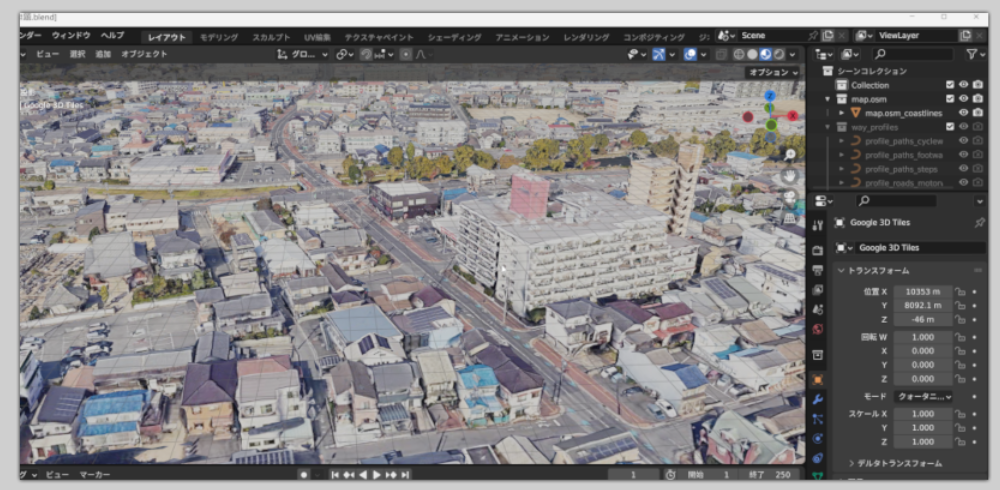
以上の画像についての表示: Map data ©2023 Google
その根拠: sample/lab/fukuyamacity.blend
25. 7/18 10:50- - 画像生成AIの実験
- プロンプトからの画像生成
Stable Diffusion XL, SDXL 0.9: A Leap Forward in AI Image Generation のオンラインデモ
https://clipdrop.co/text-to-image (clipdrop: 画像編集AIサービス)
- さまざまな画像生成、画像編集
説明資料:

- 画像の変換 Instruct-pix2pix (オンラインデモ)
プロンプトを用いた画像の変換
26. 7/20 10:50- - 日本語大規模言語モデルの紹介
日本語の大規模言語モデルについて追加説明した。現時点の技術に不足があるように感じたとしても、各自「課題解決」、「技術理解」、「根拠提供」をポスター準備で考えてほしいと伝えた。来週、再来週も全員活動し、各自で工夫を進めていくことにより、課題解決力、自主性、挑戦力を発揮してもらう。
7月25日は各自ポスターを読み上げて説明する。他の仲間に伝えることを行ってもらう。ポスターファイルは、このページで公開していく。
- パソコンで言語モデルを動かす
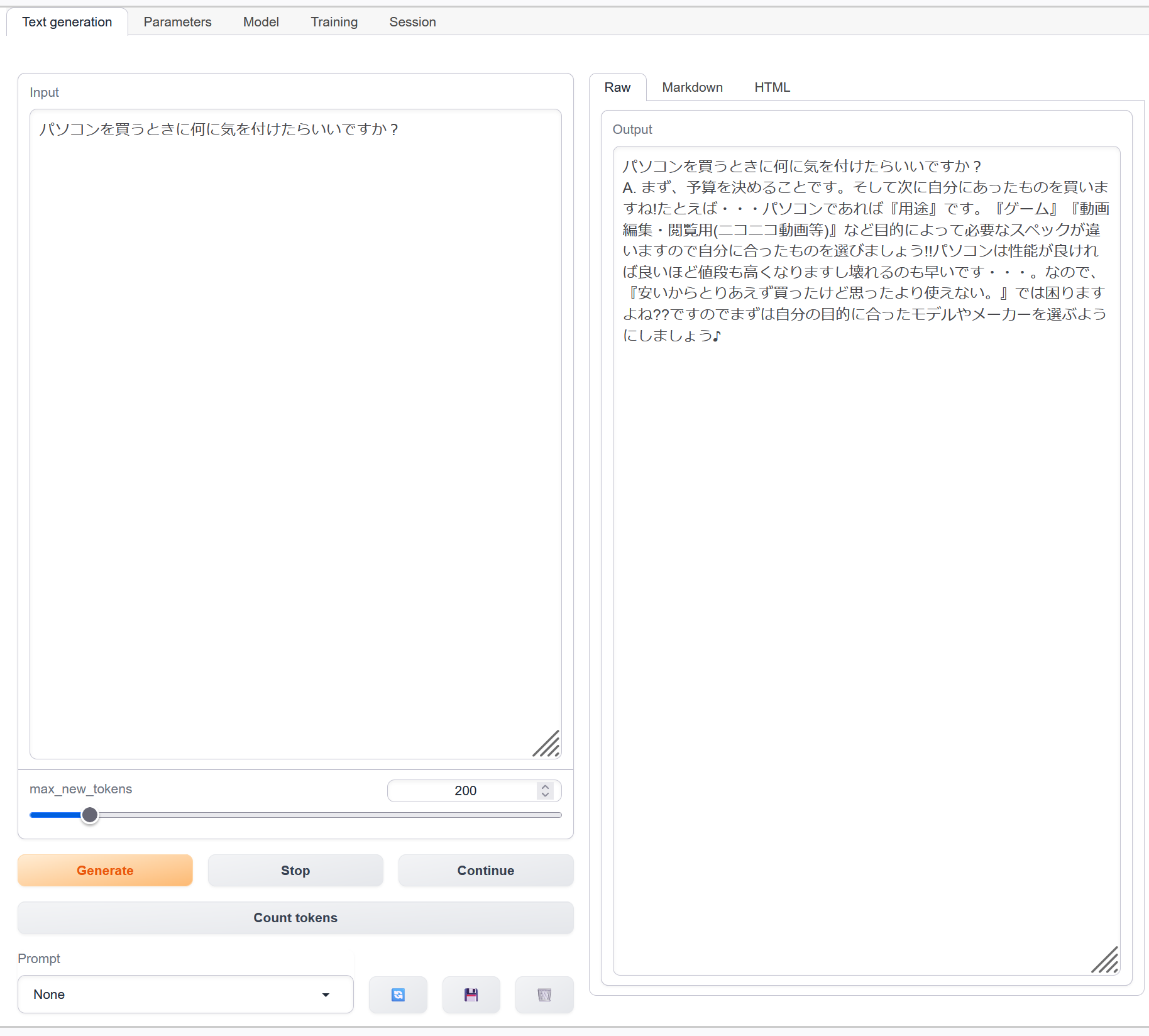
27. 7/25 10:50- - ポスター発表とグループワーク
- ポスターファイルを他の学生に説明(グループワーク)
https://cerezo.fukuyama-u.ac.jp/ct/course_342000_news_1361123
- 「課題解決」、「技術理解」、「根拠提供」について各自検討、指導教員とディスカッション
- ポスターファイルを差し替えることは可能である。注意: 誤字を見つけた場合、未記入のものがある場合(「参考文献」を未記入の場合など)は必ず差し替えること。
- 各自、来週まで、追加実験に集中し、「課題解決」、「技術理解」、「根拠提供」の説明を充実させた学会発表原稿を作成すること。
期間: 7月25日から8月10日まで
28. 7/27 10:50- - ポスターフィードバック
ポスターに関するフィードバックを実施した。
29. 8/1 10:50- - ポスター提出と学会原稿作成
- 提出物: ポスターのパワーポイントファイルを金子宛に送付
- 次を確認する
各自、追加実験に集中し、「課題解決」、「技術理解」、「根拠提供」の説明を充実させた学会発表原稿を作成すること。
期間: 7月25日から8月10日まで
- 原稿(アクセス制限あり)
- 檀上 朋希,金子 邦彦,人工知能による表情の明確化,作成中,rentai2023-template-word-dan.docx
概要: 人工知能(AI)を用いての顔検知と顔の表情推定の研究である。将来は、ビデオ会議で、好印象を与える方法を研究する。リアルタイムで顔の表情を検出・評価するシステムをWindows パソコンに実装した。PythonとDlib(機械学習ライブラリ、顔検出等)を用いて、7つの異なる表情を識別し、その確率を数値表示できる。Windows パソコンで動作し、0.01から0.06秒の間隔でリアルタイムに表情推定できることを確認した。大きな表情の変化は検出できるが、微細な変化は難しいことが分かり、今後 Dlib 以外の方法も評価する予定である。最終的には、表情変換(altering face expressions)の技術を用いて、オンライン会議での表情を適切に伝え、相手に好印象を与えることを目指す。
- 讃岐 宗純,金子 邦彦,生成AIを用いた創造的なイラスト構図生成,作成中,rentai2023-template-word-to.docx
- 石原 俊祈,金子 邦彦,カスタマイズされたチャットボットによる質問応答システム,rentai230082, 作成中: rentai2023-template-word-ishi.docx
概要: 福山大学に関する質問応答システムの開発を行った。このシステムは、UglyRobotのDocsBot AI(文書からチャットボット作成サービス)を利用し、カスタマイズされたチャットボットを活用することにより、福山大学に関する情報に答える能力を有している。開発ではDocsBot AIを設定し、福山大学に関する資料をアップロードしてカスタマイズを行った。実際の動作テストで、大学の学部の情報や住所についての質問に対して回答が得られることが確認できた。ただし、チャットボットの回答の多様性に関しては調整が必要で、プロンプトの工夫を通じて改善を試みた。
- 曽根田 翔真,金子 邦彦,現実世界を再現した3次元のゲーム世界の構築,rentai230090, 作成中: rentai2023-template-word-sone.docx
概要: 現実世界を再現した3次元のゲーム世界の構築を行っている。この研究では、国土交通省が提供する3D都市モデル「PLATEAU」(日本全国の3D都市モデル)、Google Earth API(Google Earthデータ利用インターフェース)、およびテキストや画像から3次元モデルを生成する技術「Shap-e」(テキストや画像から3Dモデル生成AI)を組み合わせてゲーム世界を製作している。具体的には、PLATEAUから福山大学周辺の地形と建物を取得し、Shap-eを用いて植物やオブジェクトを生成、Google Earth APIで都心部の詳細な3Dモデルを取得した。ゲームのシステムやキャラクターのアニメーションはUnreal Engine 5(高性能ゲーム開発エンジン)とBlenderを使用して制作され、結果としてより現実に近い3次元ゲーム世界を実現した。
- 中村 槙吾,金子 邦彦,人工知能による道路標識認識システム,rentai230081, 作成中: rentai2023-template-word-nakamura.docx
概要: 2022年に約16,000件の道路標識違反による交通事故が発生したことを受け、100種類以上の日本の道路標識をAIで高精度に検出するシステムの開発を目指している。最初に、3種類、180枚の道路標識画像を使用し、YOLOv8で学習を行ったところ、画像が小さかったり一部が隠れている場合の道路標識の誤検出が多いことを確認した。そこで、画像データセットを20倍に拡張し、再学習を実行した。その結果、誤検出は少し増加したものの、全体の検出率は約96%まで向上し、改善を確認した。
- 小林 朝陽,金子 邦彦,rentai230073, 作成中: lab/rentai2023-template-word-kobayashi.docx
- 森井 亮磨,金子 邦彦,顔検出と人物特定による人物の探索,rentai230088: lab/rentai2023-template-word-morii.docx
- 宮 祥昭,金子 邦彦,学生食堂と給食のメニュー分析,rentai230089, 作成中: lab/rentai2023-template-word-miya.docx
- 檀上 朋希,金子 邦彦,人工知能による表情の明確化,作成中,rentai2023-template-word-dan.docx
- ポスター(各自の研究テーマ)
5420004.pptx - DocsBotを利用して福山大学に関する情報に的確に回答するチャットボットの研究開発
5420027.pptx - Google Earth や国土交通省が提供する3D都市モデル「PLATEAU」から地形と建物を使用し、カスタマイズしてリアルなゲーム世界を構築。人工知能の導入が、新しいゲームの面白さ(ゲーム体験や機能)をもたらす可能性を探求している。
5420030.pptx - オンライン会議上での表情の誤解を防ぐために、リアルタイムでの表情推定を行い、オンライン会議の質を向上させることを目指している。現在は、PythonとDlibを用いて、7種類の表情を判別するシステムを作り実験し、微妙な表情の認識や、より好印象な表情へ画像を置き換えること目指している。
5420033.pptx - 人工知能を活用して道路標識の種類を検出するシステムを研究開発。YOLOv8を使用し、一定の精度で検出ができることを確認した。
5420050.pptx - 学生食堂の提供メニューの分析と改善を行い、利用者の好みや健康に合った食事選択を支援する。
- 中間発表での「教員からの質問」は各自対応する。全員分に答えること。
- 就職活動の案内
内定を得た人: 次を提出する
https://cerezo.fukuyama-u.ac.jp/ct/course_1079468_report_1317734
(記入例)7月22日:A社より内定
未内定の人: 次を提出するか、金子宛のメールでもよい
https://cerezo.fukuyama-u.ac.jp/ct/course_1079468_report_1317734
(記入例)就職課訪問済み、履歴書等の作成済み、今までのエントリー:3社、IT系を中心に活動中
(記入例)7月は期末試験と単位取得に集中。活動休止。8月から再開、頑張る
- 学内企業説明会のお知らせ(タカヤ株式会社)
日時: 8月2日(水)13:10~14:10 場所: 1号館1階 011002教室(予定) 企業名: タカヤ株式会社 所在地: 岡山県井原市井原町661-1 事業内容: 電子機器関連製品の企画・開発・調達・製造ほか 職種: 設計開発職・システムエンジニア・生産技術職・総合事務職 (設計開発職のみ理工系学生限定) 対象: 全学部全学科 [https://www.takaya.co.jp/] 卒業生が活躍している企業である。 希望する学生は、就職課に申込むこと(電話084-936-1333)。 なお、学内で行う単独企業説明会については、セレッソにも掲載しているので見ること。
30. 8/3 10:50- - 画像拡張(Data Augmentation)の重要性
- 画像の拡張について
重要性: AIで画像の学習をしている人は必見である。データ拡張により、学習データを増やし、モデルの精度向上と過学習の防止が期待できる。
推奨: 今日にでも拡張を開始してみること。
画像の増量を行う Python プログラム(Python,opencv-python(画像処理ライブラリ)を使用)(Windows 上): 別ページ »で説明

31. 8/8 10:50- - 学会発表準備と中間発表への対応
重要事項
1. 中間発表への質問回答は8月10日が締め切りである。
2. 学会発表の準備を各自にお願いしている。
学会発表準備の手順
①「課題解決」、「技術理解」、「根拠提供」を進める ・自身が何を工夫したか、工夫前後の変化をデータやスクリーンショットで示す ・研究を楽しむこと ②原稿作成 著者: 本人、金子邦彦の2名 次のページの「Word版」を使用: https://rentai-chugoku.org/guideline.html ③ワードファイルを金子あてに送付 確認に2から3日かかる場合がある。共同執筆する。 ④オンライン申し込み https://rentai-chugoku.org/apply.html 締切: 8月24日昼頃まで 注意: メールアドレスの入力ミスに注意 【申込時の記入事項】 ・申込者氏名: 本人の氏名 ・E-mail: 大学のメールアドレス(重要な連絡が届く) ・発表部門: AI(ニューラルネット)を研究で使っている人 第一希望: 26. 計算機応用 第二希望: 24. ニューラルネット それ以外の人 第一希望: 26. 計算機応用 第二希望: 25. 情報処理 ・著者数: 2 ・著者1: 本人の氏名,福山大学,工学部,大学のメールアドレス ・著者2: 金子 邦彦,福山大学,工学部,kaneko@fukuyama-u.ac.jp ・講演者(発表者): 著者1(本人) ・学会選択: 電子情報通信学会 ・状態: 手続き中 ・学生/一般: 学生 ・連絡責任著者: 著者2(金子) ・役職: 教授 ・郵便番号: 7290292 ・住所: 広島県福山市東村町字三蔵985-1福山大学工学部情報工学科 ⑤8月24日10時50分の集合時に困っていることを確認 ⑥追加実験(8月下旬) 「課題解決」「技術理解」「根拠提供」を進めるため、追加実験を依頼する場合がある。 プレゼンと卒論で活用する。 ⑦プレゼン発表 日時: 10月28日(土)9:00 - 17:15 形式: ZOOM + パワーポイント 推奨: 学校に来て発表(機材準備が容易)、スーツ着用 発表時間: 8分 注意: 急用の場合は連絡すること(代理発表可能) プレゼン能力は12月予定の卒論発表会でも役立つ。
- チャットボットアプリケーションのプログラム(Python,LangChain,OpenAI API を使用)(Windows 上)別ページ »で説明
Windows パソコンでチャットボットを動かす。注意: OpenAI APIは登録が必要で、基本有料のサービスである。
- プロンプトからの画像生成
Stable Diffusion XL (SDXL) バージョン 1.0をパソコンにインストールして動作。
Stable Diffusion XL 1.0 (SDXL 1.0) のインストール、画像生成(txt2img)、画像変換(img2img)、APIを利用して複数画像を一括生成(AUTOMATIC1111,Python,PyTorch を使用)(Windows 上): 別ページ »で説明




















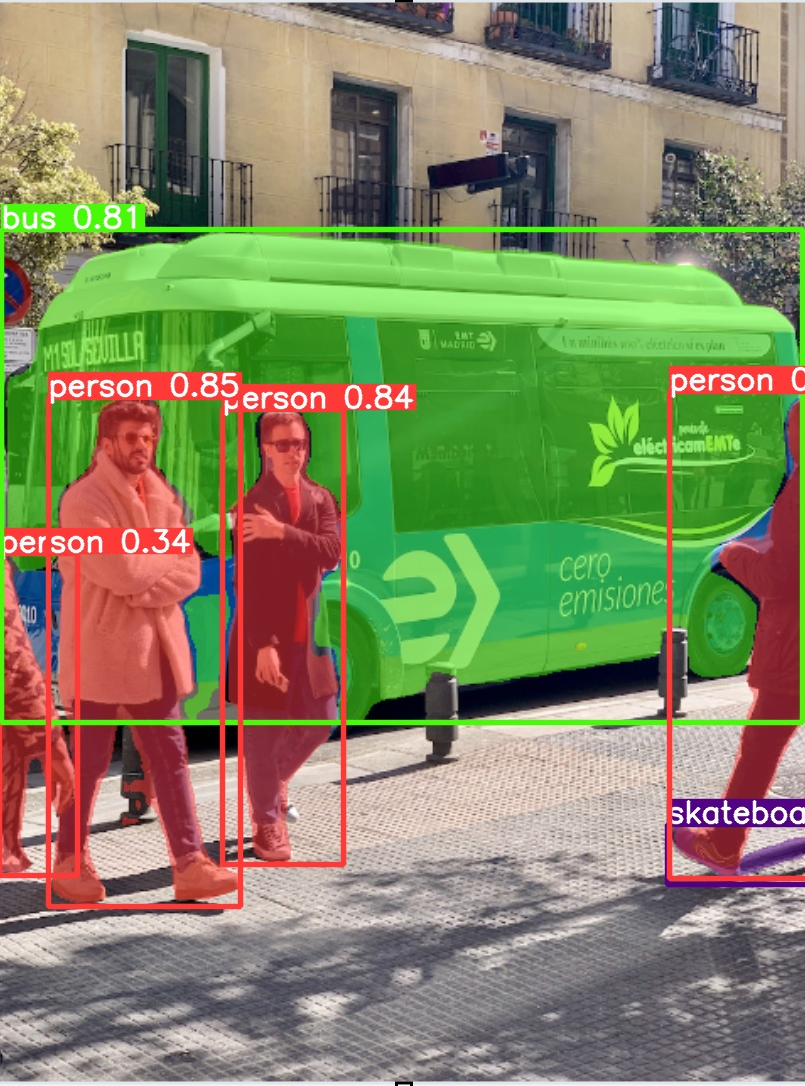
32. 8/10 10:50- - YOLOv8による物体検出と転移学習
重要性: 転移学習により、少ないデータで高精度なモデルを構築できる。実用的なAIシステム開発に不可欠な技術である。


33. 8/24 10:50- - Fooocusによる画像生成
- Fooocus(簡易操作の画像生成AIツール)のインストール、Stable Diffusion XL (SDXL)(高性能画像生成AIモデル)による画像生成の実行(Fooocus,Stable Diffusion XL,PyTorch,Python を使用)(Windows 上)別ページ »で説明
メリット: 複雑な設定なしで高品質な画像を生成できる。デザイン作業の効率化に有効。
34. 8/29 10:50- - 表情推定技術の比較検証
複数の表情推定技術を比較検証した。表情推定は、ビデオ会議での感情理解や、顧客満足度分析などに応用できる。
- DeepFace(顔属性分析ライブラリ)
DeepFace の文献
Serengil, Sefik Ilkin and Ozpinar, Alper, HyperExtended LightFace: A Facial Attribute Analysis Framework, 2021 International Conference on Engineering and Emerging Technologies (ICEET), pp.1-4, 2021.
準備
Windows で、コマンドプロンプトを管理者として実行し、次のコマンドを実行する。
python -m pip install deepface
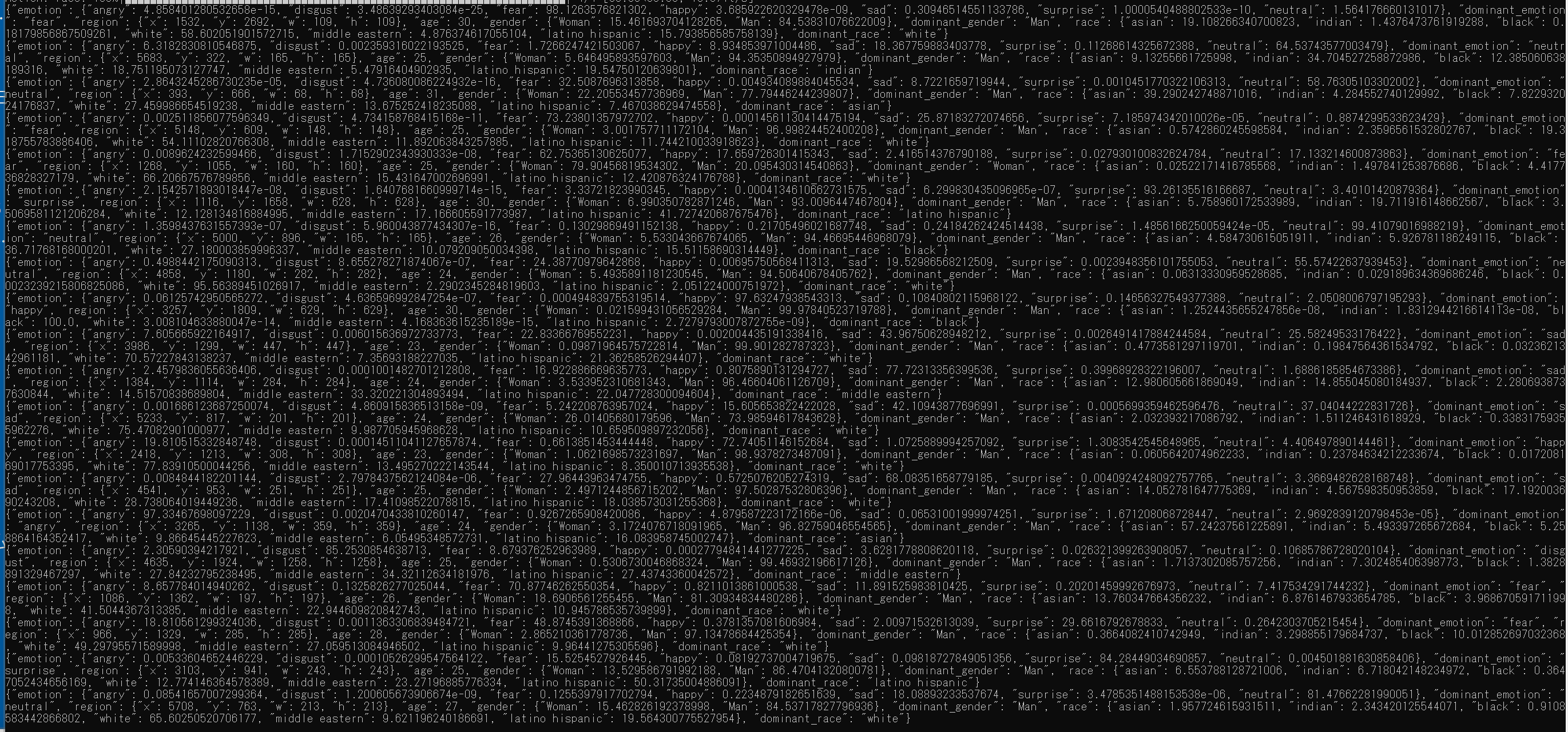
表情推定は次のコマンドで行う。
deepface analyze 1.jpg
1.jpg は次の画像である。

表情、年齢、性別の推定結果
- facetorch(PyTorchベースの顔分析ツールキット)
facetorch のインストールと実行(顔検出、表情推定など): 別ページ »で説明

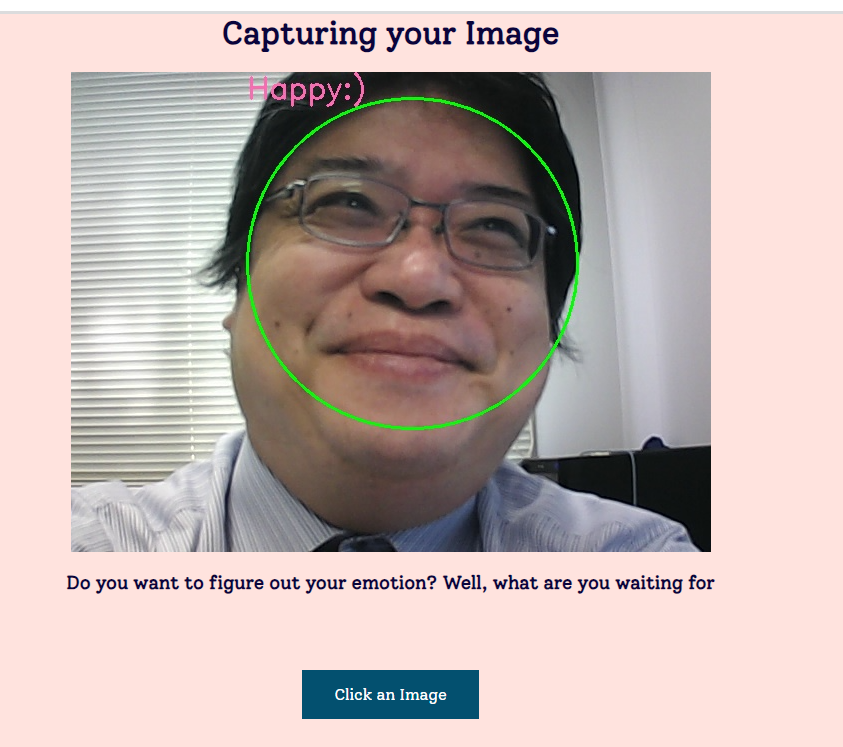
- SanjayMarreddi/Emotion-Investigator
顔検出と表情推定(SanjayMarreddi/Emotion-Investigator,Python,TensorFlow(機械学習用オープンソースライブラリ)を使用)(Windows 上)別ページ »で説明


35. 8/31 10:50- - MOT(Multiple Object Tracking)の復習
MOT は、動画での物体検出やセグメンテーションにおいて、異なるフレームでの結果に対して、同一オブジェクトには同一番号を与える仕組みである。
yolo_tracking のインストールと使用法
https://www.kkaneko.jp/ai/labo/yolov11pose.html
yolo_tracking でのトラッキング・ビジョンの実行結果


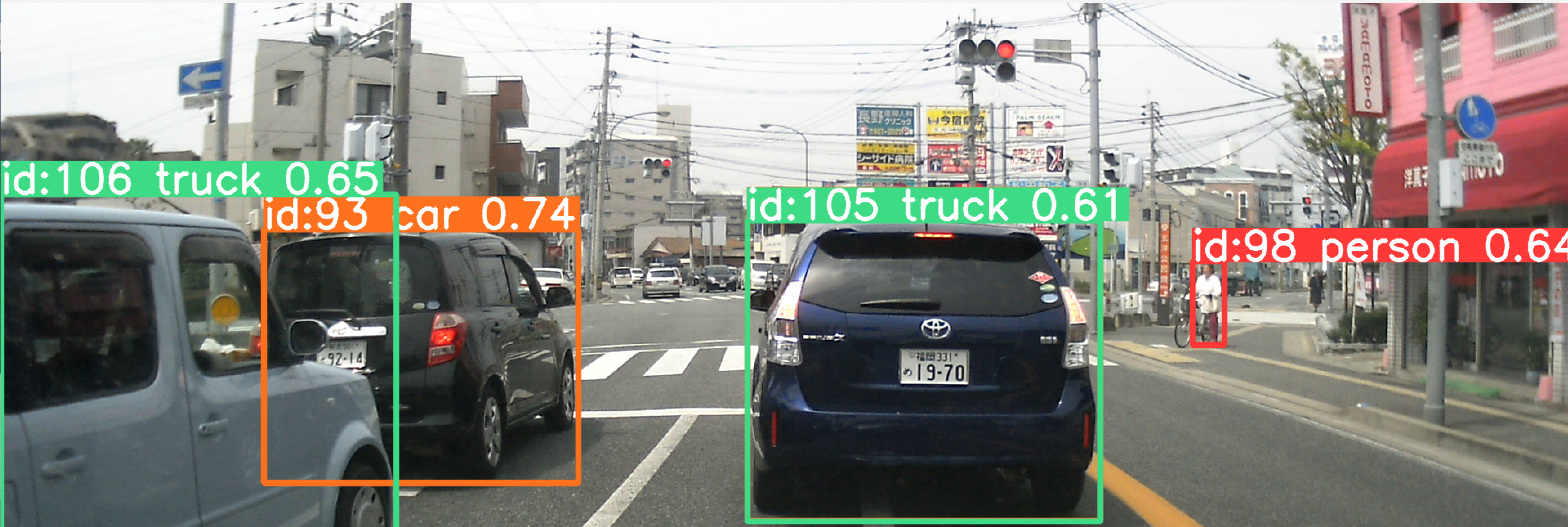



36. 9/5 10:50- - ゼロショットビデオオブジェクトセグメンテーション
ゼロショットのビデオオブジェクトセグメンテーション技術を検証した。事前学習なしで動画内の物体を検出・分割できる。
動画を与えると物体検出、インスタンスセグメンテーションが行われる。
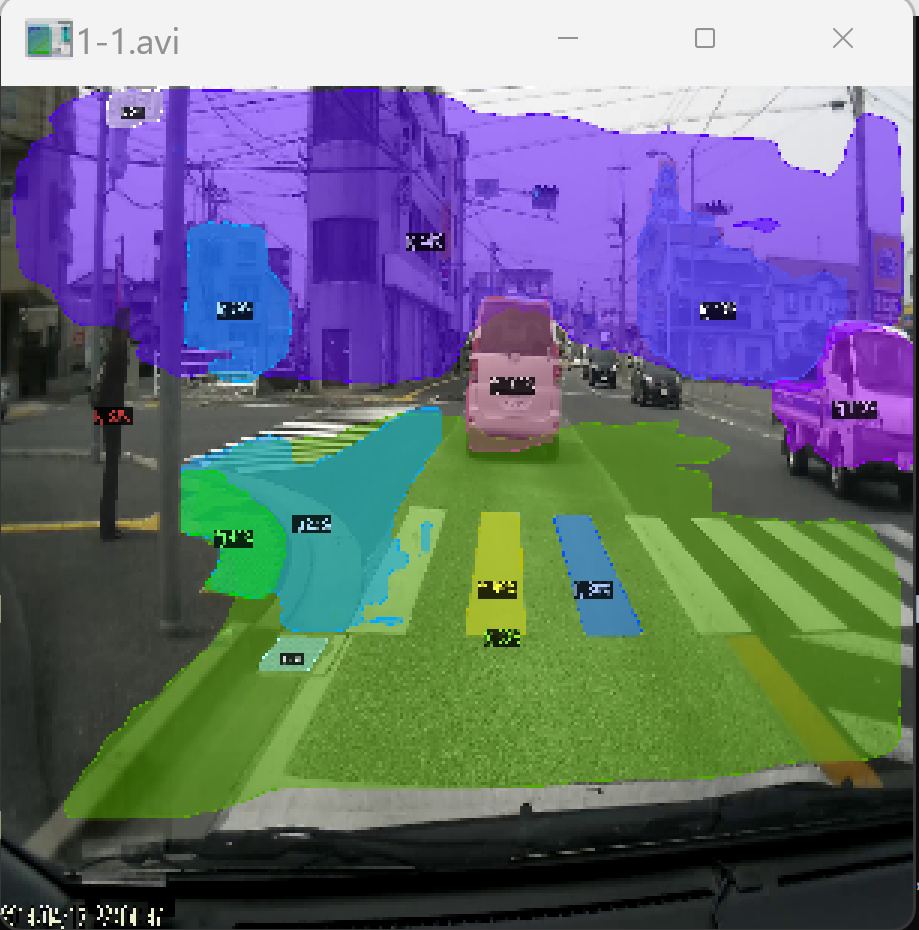

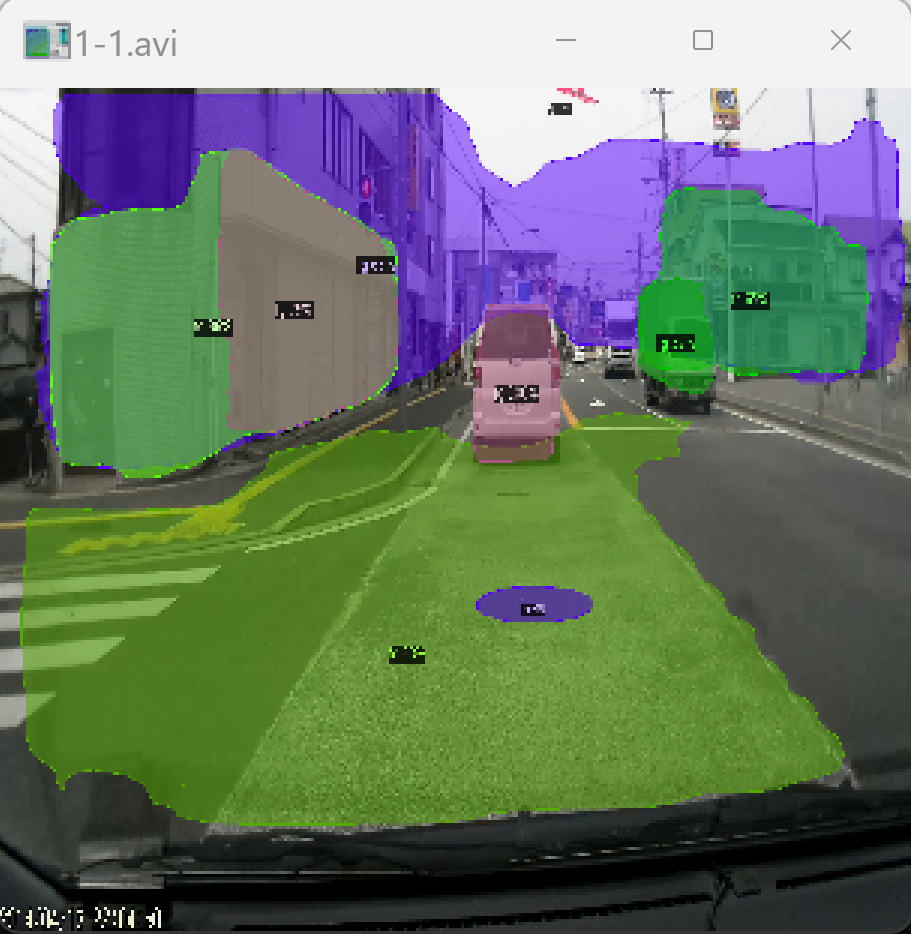

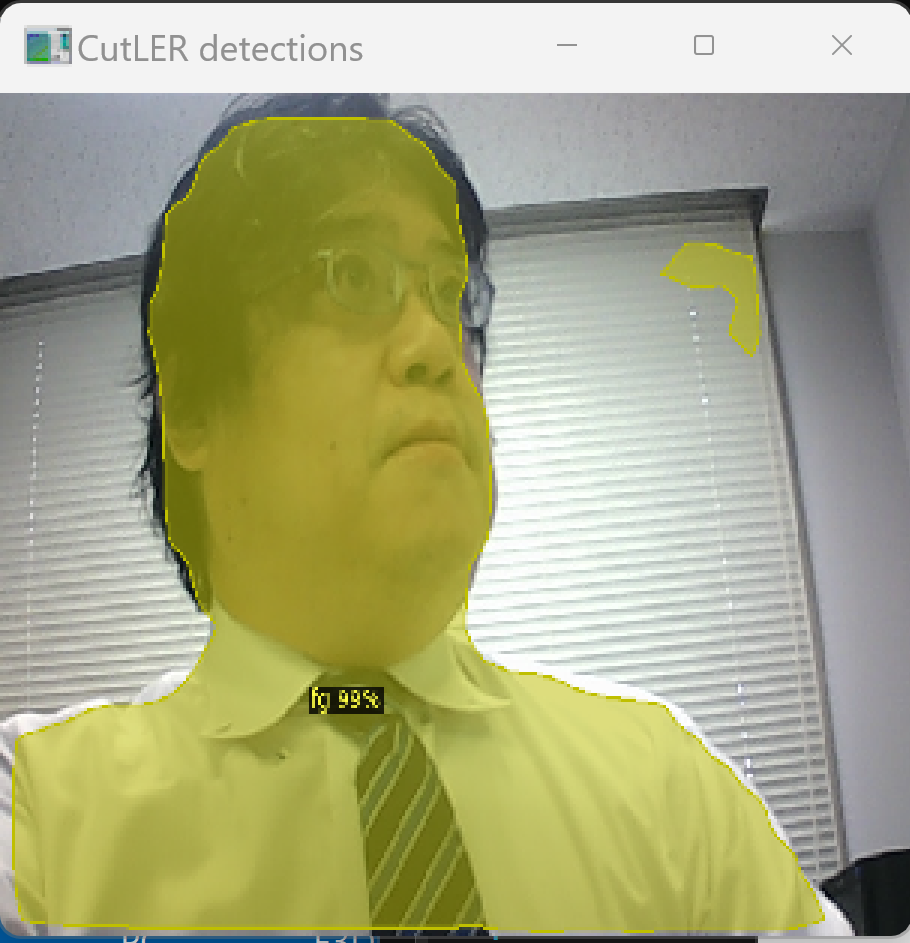
実行結果の動画:cutlerwebcam.mp4
Windows 上のインストールと実行
公式の Google Colaboratory 上のデモページ: https://colab.research.google.com/drive/18nIqkBr68TkK8dHdarxTco6svHUJGggY?usp=sharing#scrollTo=RyXr0xsZB897
37. 9/7 10:50- - 質問応答システムとファクトチェック
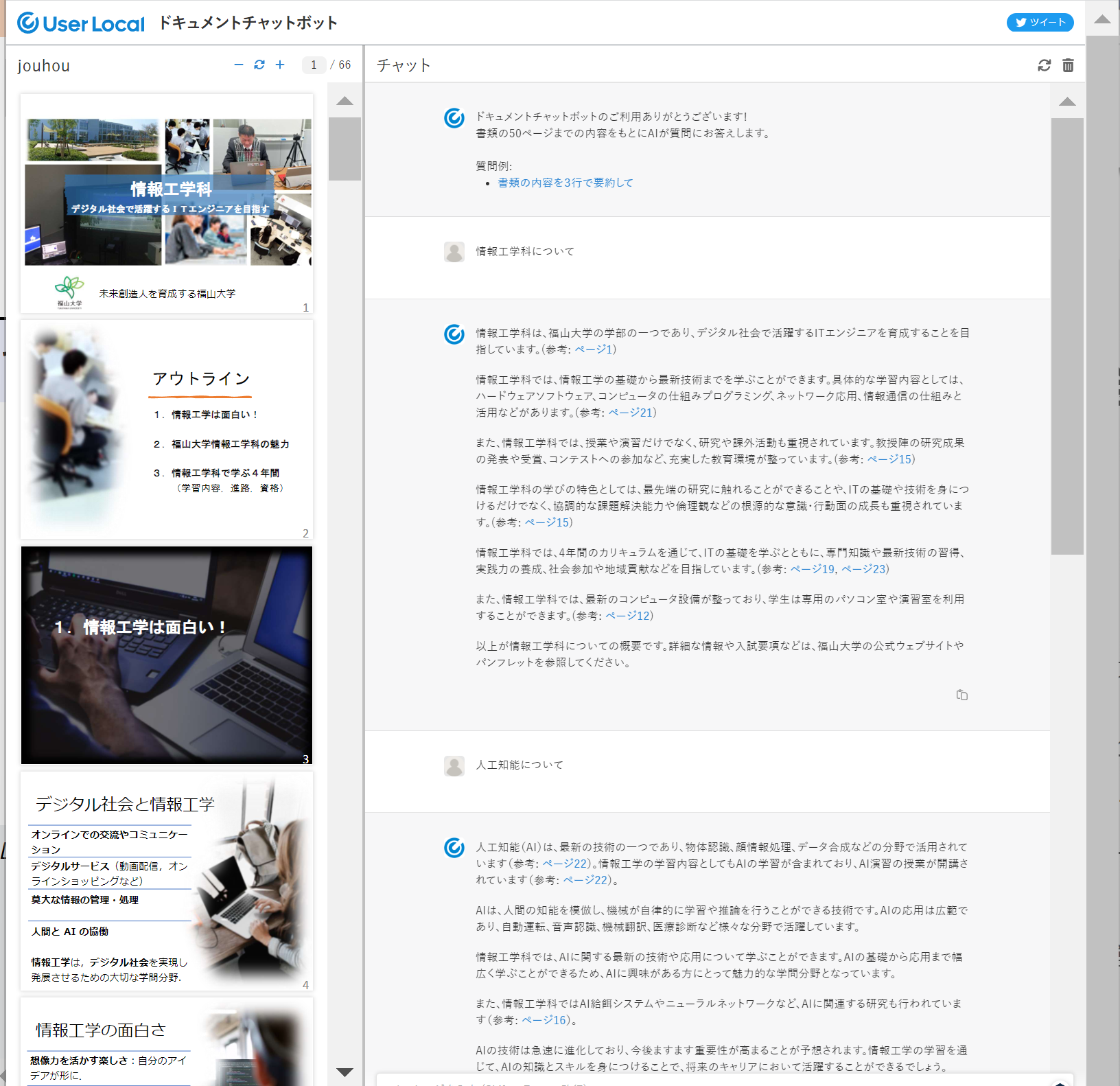
- ドキュメント・チャットにファイルをアップロードし、質問応答システムをオンライン実行(チャットボットによる質問応答システム): 別ページ »で説明
メリット: 大量の文書から必要な情報を素早く抽出できる。
- ChatGPT の回答のファクトチェック(factool(ChatGPT等の回答の事実検証ツール),Python を使用)(Windows 上): 別ページ »で説明
重要性: AIの回答を鵜呑みにせず、事実確認する習慣が重要である。
ChatGPT の回答の中の「徳川家康は日本のほとんどを統制下に置いた」が「徳川家康は日本の一部を統制下に置いた」に修正されている。

38. 9/12 10:50- - Open Interpreterの活用
ChatGPT へのコマンドや Python プログラムからのアクセス(Open Interpreter(自然言語でPC操作するAIツール),Python を使用)(Windows 上)別ページ »で説明
メリット: 自然言語での指示により、プログラミング作業を効率化できる。

39. 9/14 10:50- - MOT(Multiple Object Tracking)の理解と実装
MOT は、動画での物体検出やセグメンテーションにおいて、異なるフレームでの結果に対して、同一オブジェクトには同一番号を与える仕組みである。これにより、動画全体を通じて各物体を一貫して追跡できる。
- yolo_tracking(YOLOを用いた物体追跡システム)のオンラインデモのページ(Google Colaboratory)
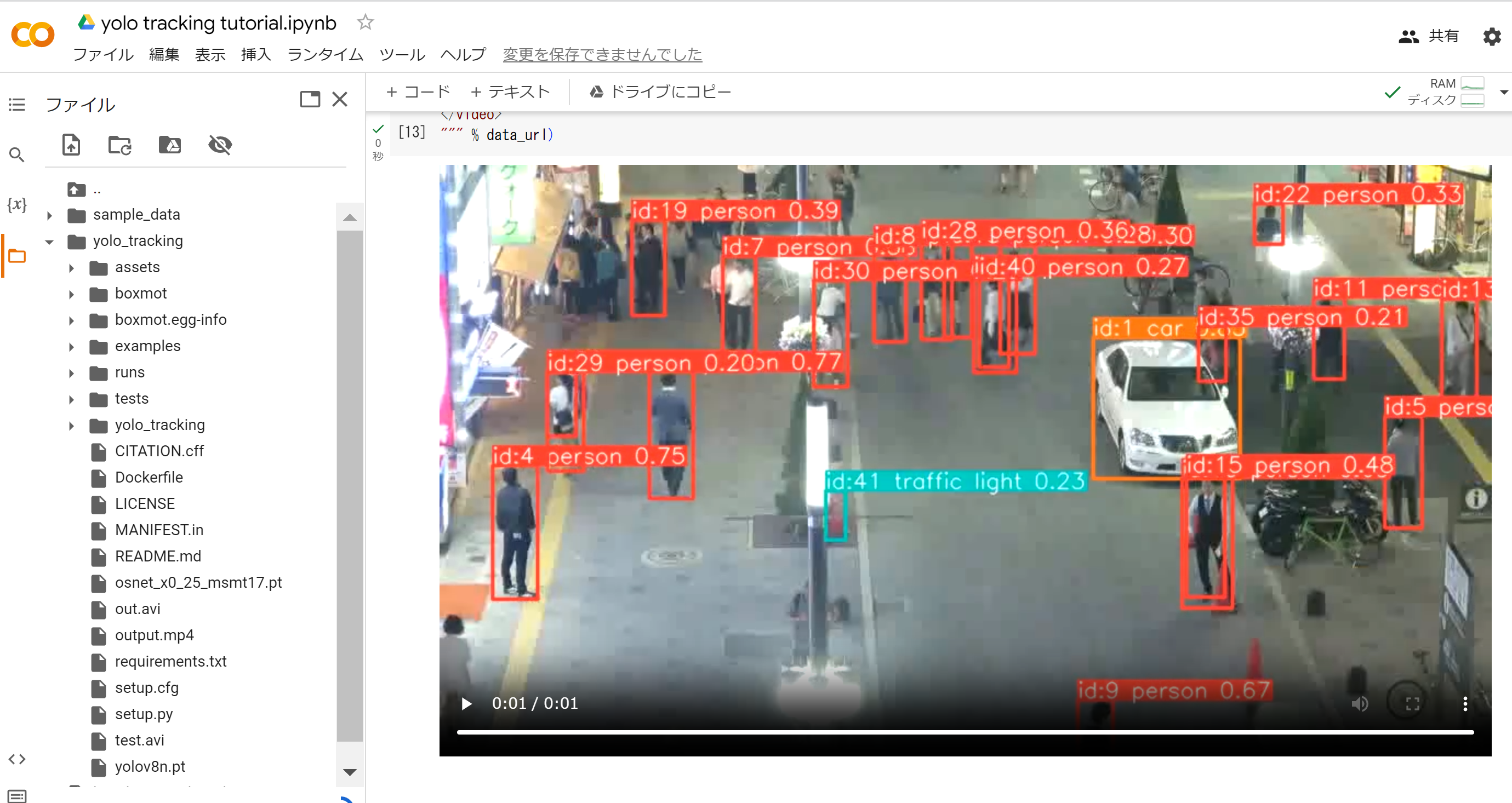
使い方: 動画ファイルをアップロードできる。アップロード後、コードセル内のファイル名を書き換える。

結果が保存されるディレクトリを確認する。

このディレクトリから、動画などの結果をダウンロードできる。

結果の動画ファイル:kaneko_sample_video.avi
- yolo_tracking のインストールと使用法、実行結果
yolo_tracking のインストールと使用法
https://www.kkaneko.jp/ai/labo/yolov11pose.html
yolo_tracking でのトラッキング・ビジョンの実行結果
40. 9/19 (1回目) 10:50- - 画像復元技術の検証
画像復元(劣化した画像の品質を改善する技術)の検証を行った。古い写真の修復や、低解像度画像の高解像度化に活用できる。
元画像と処理結果


画像復元(DiffBIR(拡散モデルを用いた画像復元AI),Python,PyTorch を使用)(Windows 上): 別ページ »で説明
41. 9/19 (2回目) 10:50- - ポイントトラッキングの実装
ポイントトラッキング(動画内の特定点を追跡する技術)を実装した。動画内の任意の点を指定すると、その点の動きを追跡できる。スポーツ解析や動作分析に応用可能である。


ポイント・トラッキング(co-tracker(ポイント追跡AIモデル),Python を使用)(Windows 上)別ページ »で説明
42. 9/25 10:50- - ゼロショットセグメンテーションの実験
ゼロショットのセグメンテーション技術を実験した。この技術は、事前学習なしで画像中の物体を分割できるため、新しい対象物に対しても柔軟に対応できる利点がある。医療画像解析や製造業での品質検査など、多様な応用が期待される。




ゼロショットのセグメンテーション(HQ-SAM(高品質なSAMの改良版),Python,PyTorch を使用)(Windows 上): 別ページ »で説明
43. 9/26 10:50- - 複数オブジェクトトラッキング(MOT)の実装
複数オブジェクトのトラッキング(MOT)(動画内で複数の対象を追跡する技術)を実装した。この技術により、動画内の複数の物体を同時に追跡し、それぞれに固有のIDを付与できる。応用例として、混雑した場所での人流解析や、交通監視システムでの車両追跡などがある。
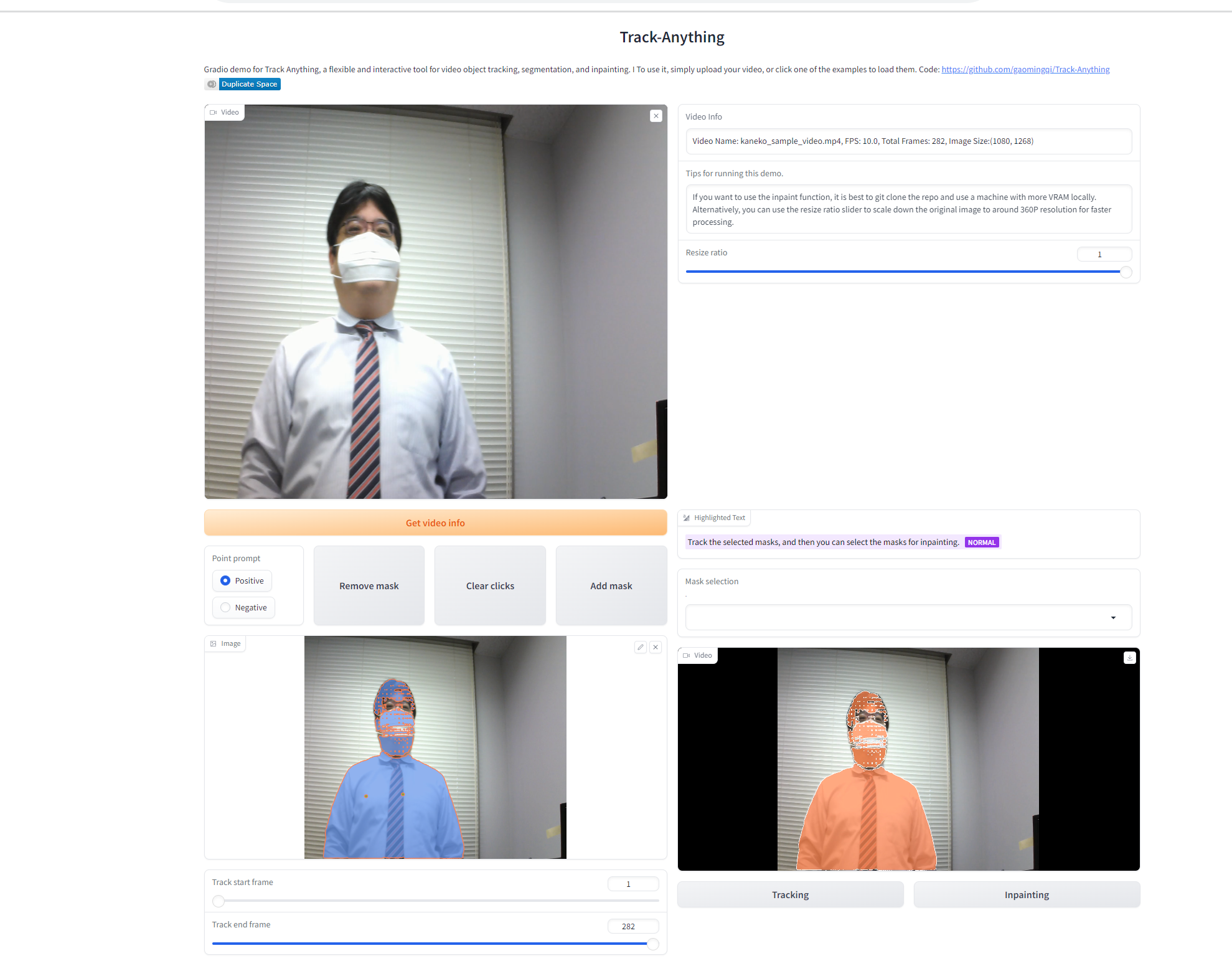
結果を保存した動画ファイル:trackanything.mp4
オブジェクト・トラッキングとセグメンテーション(Track Anything(汎用的な物体追跡・セグメンテーションAI),Python,PyTorch を使用)(Windows 上): 別ページ »で説明
44. 10/3 10:50- - Image-to-3Dと研究姿勢
写真からの立体データの生成(Image-to-3D(画像から3Dモデル生成技術))
写真1枚から、テクスチャ付きの立体データを生成する。
DreamGaussian(高速3D生成AIモデル) の Image-to-3D の公式のオンラインデモ(Google Colaboratory): https://colab.research.google.com/drive/1sLpYmmLS209-e5eHgcuqdryFRRO6ZhFS?usp=sharing
写真1枚から、テクスチャ付きの立体データを生成する。
元画像の例

中間結果

最終結果
スクリーンショット

処理結果(3次元データ): b.obj, b.mtl, b_albedo.png
{kind=link}
処理結果のスクリーンショット(動画):
使い方のヒント
- Google Colaboratory を使用している。
- 前準備として画像ファイルを準備する。ファイル名は英語が良い(a.jpg, b.png のように)。
- 上のページで「ランタイム」、「すべてのセルを実行」で実行開始する。途中で、画像ファイルを1つアップロードする。
- 無料版のGoogle Colaboratoryを使っている場合などは、GPU のメモリ不足でエラーが出る場合がある。エラーが出た場合、「ランタイム」、「すべてのセルを実行」で実行を1、2回程度繰り返すと、うまく行く場合が多い。実行のたびに、GPU のメモリの量が変わり、GPUのメモリが多く割り当てられる場合があるためである。
研究を進める中で、先行研究や、教員や仲間のアドバイスに基づいて行動することは良いことである。しかし大切なことは、先行研究や他の人のアドバイスがすべてではないということである。もし先行研究や他の人のアドバイスでうまくいかなかったとしても、それで終わりではない。そこで「終わり」にするのは、成長や可能性をそこで閉ざしてしまうことになる。学びの過程では、自身で考察し、さまざまな方法を試すことが大切である。そのとき、失敗は避けることができない。失敗から学ぶことが大切だと思ってほしい。失敗から、次に生かす知識やスキルが増えていく。研究では、まだ解明されていない謎に挑戦するものである。もし先行研究や他の人のアドバイスでうまくいかなかったことを、次の行動に生かしてほしい。そのような態度は、研究の成功と満足感につながる。自己アピールや自信をつけるためにも大切である。
プレッシャーに負けないように、小さなゴールを立てて、成長を実感すること。
登校して個人ワークに取り組むことは、気分転換、環境変化にもなり、やる気アップにつながる。規則正しい生活、趣味の没頭などのリフレッシュも大切である。
「少しだけやってみる」という考え方も大切である。それだけで、勉強や課題を継続できるきっかけをつかむことができる場合も多い。
いろいろな方法を試すこと。
面談
全員と面談する。進路関係。
面談用のシート: sheet2.docx
データベース研究室 課題
実験を通じて、技術の理解を深め、卒業研究や就職活動でアピールできる実績を作る。
- 期限
各自で実験を実施し、結果を得て考察する。来週の火曜日または水曜日に実験についての説明を行うこと。
- 実験テーマ
実験テーマは各自で自由に選ぶこと。
- 実施の注意点
- プログラムがうまく動かない可能性も考慮して、早めに実験を開始すること。
- プログラムがうまく動かないなどのときは、質問をする、別の方法を試すなど、柔軟に対応すること。
- 説明内容
- 実験手順と結果を具体的に説明すると、理解が深まる。
- 期待通りの結果が得られなかった場合も、その発見や感想を共有すること。
- 評価の観点
- 自主性、計画力、研究能力(実験、結果、考察)
- コミュニケーション能力
- 論理的思考
- 説明、プレゼンテーションスキル
- プレゼンテーション形式
口頭発表でもよく、パワーポイントを使用しても構わない(自身の行いやすい方を選ぶこと)。
- 注意
- 基本的には来週水曜日に説明を行うこと。
- 水曜日に欠席する場合は、火曜日に説明が可能である。
45. 10/4 10:50- - Text-to-3D
AI に関するオンラインデモのリンク集: https://www.kkaneko.jp/ai/online/index.html
Text-to-3D(テキストから3Dモデル生成技術)の公式のオンラインデモ(Google Colaboratory): https://colab.research.google.com/github/camenduru/dreamgaussian-colab/blob/main/dreamgaussian_colab.ipynb
Google Colaboratory なので、各自で修正して実行可能である。処理結果(3次元データ)は、簡単な操作でダウンロードできる。

処理結果(3次元データ): icecream_mesh.obj, icecream_mesh.mtl, icecream_mesh_albedo.png, icecream_model.ply
{kind=link}
処理結果のスクリーンショット(動画)(リンクが切れていたので修正した): icecream.mp4
46. 10/10 10:50- - 日本語対応LLMと個人発表
日本語対応のLLM、チャットボット(ELYZA-japanese-Llama-2-7b(日本語対応大規模言語モデル)、transformer、Python、PyTorch を使用)(Windows 上): 別ページ »で説明
卒業研究のメリット、心構え: [PDF], [パワーポイント]
個人発表
47. 10/10 10:50- - 研究の進め方アドバイス
行動を開始するためのアドバイス
- 興味を持つ: 好きなテーマを選ぶ。
- 小さな一歩から: 簡単なところから始める。
- 仲間を作る: 同じ目標の人と一緒にやると効果的である。
行動を持続するためのアドバイス
- 自身を褒める: 小さな成功も大きな一歩である。
- 習慣化する: 毎日少しずつやることが大事である。
- 進捗を記録する: どれだけ進んだかを書き留める。
発表についてのアドバイス
- シンプルな言葉で話す。
- 質問や意見は成長のチャンスとして受け入れる。
- 自信を持ち、計画的に行動する。
実験結果の報告
- 目的: 何を確認したくて、何を解明したくて実験しているか。
- データ: 得られた数値や観察点。
- 解釈: 何がうまくいき、何がうまくいかなかったか。
- 次の行動: 結果から学び取るべきこと、そのための次のステップ。
フィードバックの受け取り
- 質問を歓迎する。
- 良い点と改善点を受け入れる。
自立的に前進する
- 新しいことを学び続ける。
- 計画を立てて行動する。
資料作成のアドバイス
- 表やグラフでデータを視覚的に示す。
- 統計手法(平均、近似直線、検定等)を活用する。
- 用語と数値は簡潔かつ一貫して記載する。
- グラフにはタイトル、軸ラベル、凡例をつける。
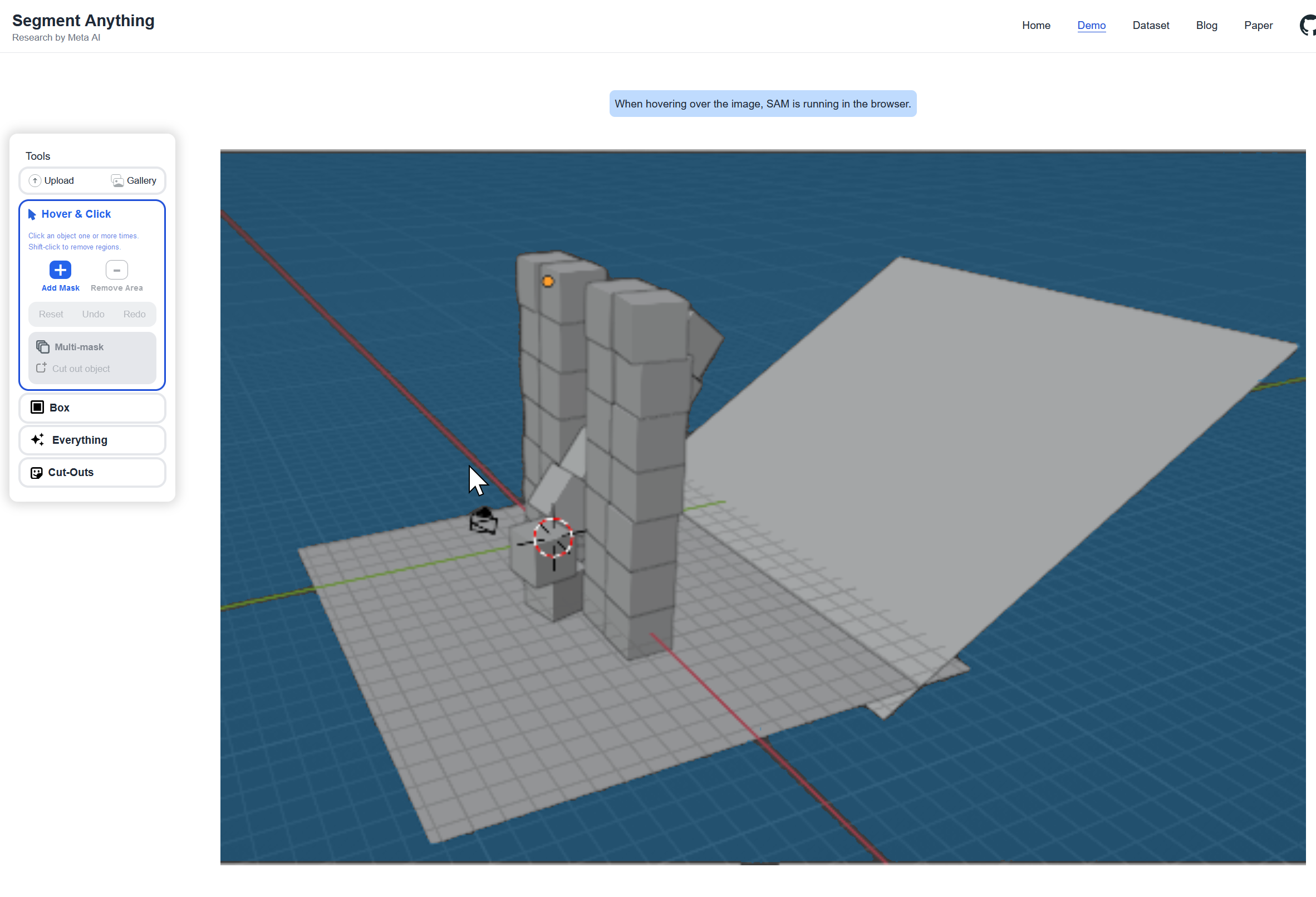
48. 10/11 10:50- - ゼロショットのセグメンテーション
SAM (ゼロショットセグメンテーション(事前学習なし特定対象の領域分割))のオンラインデモ
https://segment-anything.com/demo#
「Upload an image」により、画像のアップロードが可能である。
49. 10/18 10:50- - 画像分類と学会発表準備
timm(PyTorch画像モデルライブラリ)、Python を使用。画像分類に使用するモデルをプログラム内で簡単に選択可能である。下は、最近のモデルである eva02 を使用。
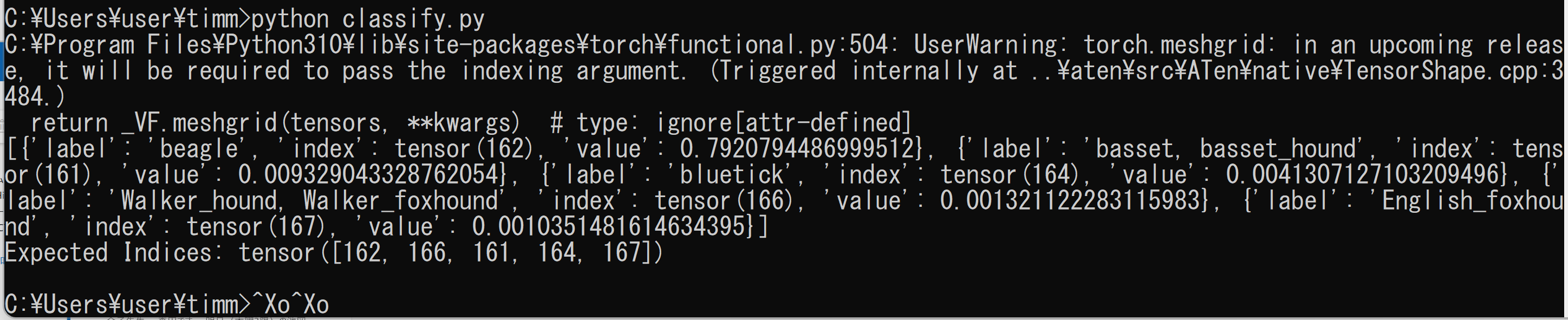
説明ページ: 画像分類の実行(timm のインストールと動作確認)(Python、PyTorch を使用)(Windows 上)
案内
- 目的: 何を確認したくて、何を解明したくて実験しているか。
- データ: 得られた数値や観察点。
- 解釈: 何がうまくいき、何がうまくいかなかったか。
- 次の行動: 結果から学び取るべきこと、そのための次のステップ。
案内
2023年度(第74回)電気・情報関連学会中国支部連合大会
発表10分、質疑3分
https://rentai-chugoku.org/cfp.html
パワーポイントファイルのテンプレート template.pptx (卒業論文発表でこのファイルを使用しても問題ない)
プレゼンテーションの構成の例
発表の構成を整理しておくことで、聴衆に伝わりやすくなり、質疑応答にも自信を持って対応できる。
- イントロダクション (1分)
- 最初のページで、氏名と「福山大学工学部」を言う。
- 研究の背景と重要性。
- 全体の流れの概要を予告する。
- 目的 (2分)
- 実験を行う目的。
- 解明したい問題点。
- 期待する成果や影響。
- 実験方法 (2分)
- 使用したAI技術とその選定理由。
- 実験設計。
- データ収集方法。
- データ (3分)
- 得られた数値や観察点。
- グラフやチャートでの可視化。
- 重要な発見。
- 解釈、結論、考察、次の行動 (2分)
- データから何が読み取れるか。
- 何がうまくいき、何がうまくいかなかったのか。
- 結果に対する考えや解釈。
- 結果から学び取るべきこと。
- 次に取るべきステップや改善点(ただし、自身が行う次の行動に限って説明すること)。
なお、スライドの各ページのタイトルは、上を気にすることなく、自由につけてよい。内容を表すタイトルが良い。
書き方で気をつけること
プレゼンテーションでは、文章の書き方に気をつけて、準備に十分な時間をかける。具体的でわかりやすい説明を心がけることで、聴衆の理解が深まり、質疑応答もスムーズになる。
- 目的の説明
- 良くない例: "本研究では深層学習の画像認識についての研究である。"
曖昧で、具体性が欠けている。
- 良い例: "本研究の目的は、深層学習を用いて画像認識の精度を5%向上させることである。"
具体的な数値や目標が明示されている。
- 良くない例: "本研究では深層学習の画像認識についての研究である。"
- 実験方法の説明
- 良くない例: "自身でインターネットで顔のデータを集めた。"
何をどうしたのかが不明である。
- 良い例: "データ収集のために、URL ●● から、オープンソースの画像データセット ○○ 枚を用いた。"
方法が明確で、説得力がある。
- 良くない例: "自身でインターネットで顔のデータを集めた。"
- データの解説
- 良くない例: "うまくいく場合とうまくいかない場合があった。撮影の仕方が影響していた。"
何がどれほど良好なのかが不明瞭である。
- 良い例: "撮影のときに正面から撮影する場合5枚と、斜めから撮影する場合5枚で比較すると、画像認識の精度が平均で4.8%向上した。"
結果が具体的な数値で示されている。
- 良くない例: "うまくいく場合とうまくいかない場合があった。撮影の仕方が影響していた。"
- 次の行動
- 良くない例: "実験で使うデータを増やす必要がある。"
具体的な行動計画が見えない。
- 良い例: "11月までに、●●のデータを●個増やし、同じ方法で再実験して確認する。その結果を用いて ○○ を確認する。"
- 良くない例: "実験で使うデータを増やす必要がある。"
一般的な注意点
- 練習、練習、練習(練習の繰り返し)。
時間内に説明ができるように何度も練習する。
- 明瞭な言葉遣い。
専門用語を避け、誰にでも理解できる言葉を使う。
- 視覚的要素。
スライドは補助であり、主役は発表者である。スライドに過度なアニメーションや装飾は避ける。
項目ごとの注意点
- 目的
具体的かつ明確に。目的を具体的に明瞭に示すことで、その後の説明がやりやすくなる。
- 実験方法
シンプルな説明を行う。必要以上の詳細は避け、主要な手法となるポイントだけを強調する。
- データ
複雑なデータはシンプルな形(グラフや表)で視覚化する。見た人がすぐに理解できるように。
- 解釈
主観的な意見は含めないこと。データに基づいた客観的な解釈を心がける。
- 次の行動
実行可能かつ具体的な行動計画を提示する。
プレゼンテーション当日
- 備品チェック。
パソコン、マイクなど、必要な機材が動作するか事前に確認する。
- 時間管理。
発表が長引かないように、時計やタイマーで時間を厳守する。発表時間は10分である。
- 対応力。
質疑応答で予期せぬ質問が来た場合も、冷静に対処する気持ちを持つ。
マナー
- 10分を超えて発表しないこと。
- 服装はスーツを推奨する。
50. 10/24 10:50- - ビデオオブジェクトセグメンテーション
Cutie のビデオオブジェクトセグメンテーションのデモ(Google Colaboratory のページ)
公式の Google Colaboratory 上のデモページ: https://colab.research.google.com/drive/1yo43XTbjxuWA7XgCUO9qxAi7wBI6HzvP?usp=sharing#scrollTo=qYv3kbaQT2w4
URL: https://hkchengrex.github.io/Cutie



案内
1. 進路について
2. 明日のリハーサルについて
下に(10/18 の回のところ)注意事項を記載しているので、繰り返し、読んでおくこと。
- シンプルな言葉で話す。
- 話題を絞り込む: 自身の研究について話す。イントロダクション、目的、実験方法、データ、解釈、結論、考察。
- 目的: 何を確認したくて、何を解明したくて実験しているか。
- データ: 得られた数値や観察点。
- 解釈: 何がうまくいき、何がうまくいかなかったか。
- ビジュアルを活用: 図、表、グラフ、スクリーンショットを使う。
データは、表やグラフでビジュアルに示し、色付け、必要な統計処理を行う(平均、近似線、検定)。細かすぎる値は四捨五入する。
- 具体例を用いて説明する。
- リハーサルを重ねる: プレゼンの流れ、タイミングを自己確認しておく。
- 自信を持ち計画的に行動する。
- 自身の言葉で熱意を持って伝える。
- 意見や質問は、成長のチャンスとして受け入れる。
51. 10/25 10:50- - 発表リハーサル
全員により発表リハーサルを実施した。
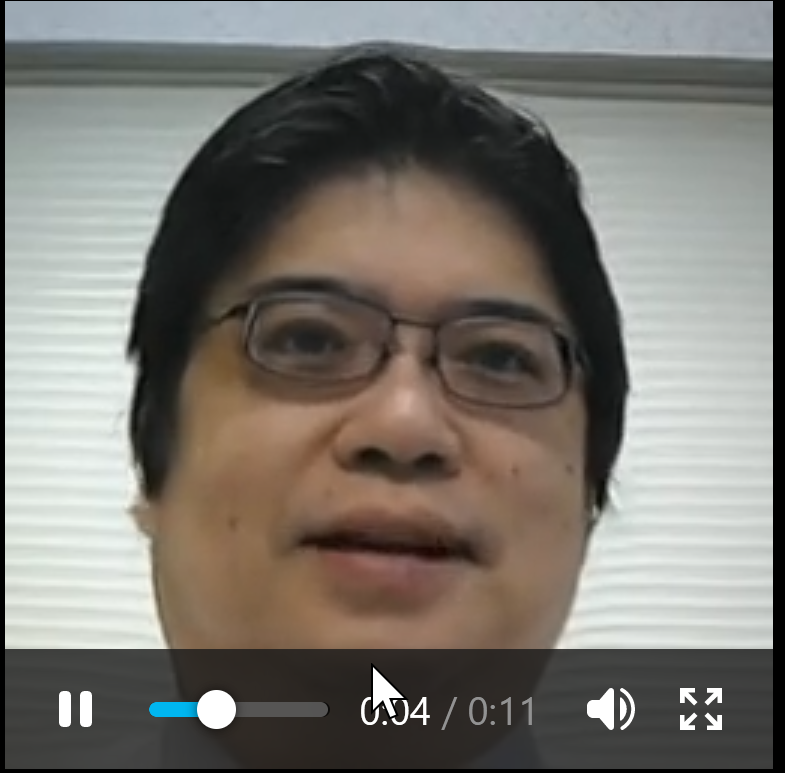
52. 10/31 10:50- - 発声動画の生成
発声動画の生成
音声と画像ファイルから発声動画を生成するなど
左が元画像、右が生成された動画

使用した音声
【サイト内の関連ページ】
【関連する外部ページ】
- 公式の GitHub のページ: https://github.com/OpenTalker/SadTalker
- 公式の WebUIのデモページ: https://colab.research.google.com/github/camenduru/stable-diffusion-webui-colab/blob/main/video/stable/stable_diffusion_1_5_video_webui_colab.ipynb
- 公式の HuggingFace のデモページ: https://huggingface.co/spaces/vinthony/SadTalker
- 公式のデモ動画 https://user-images.githubusercontent.com/4397546/231495639-5d4bb925-ea64-4a36-a519-6389917dac29.mp4
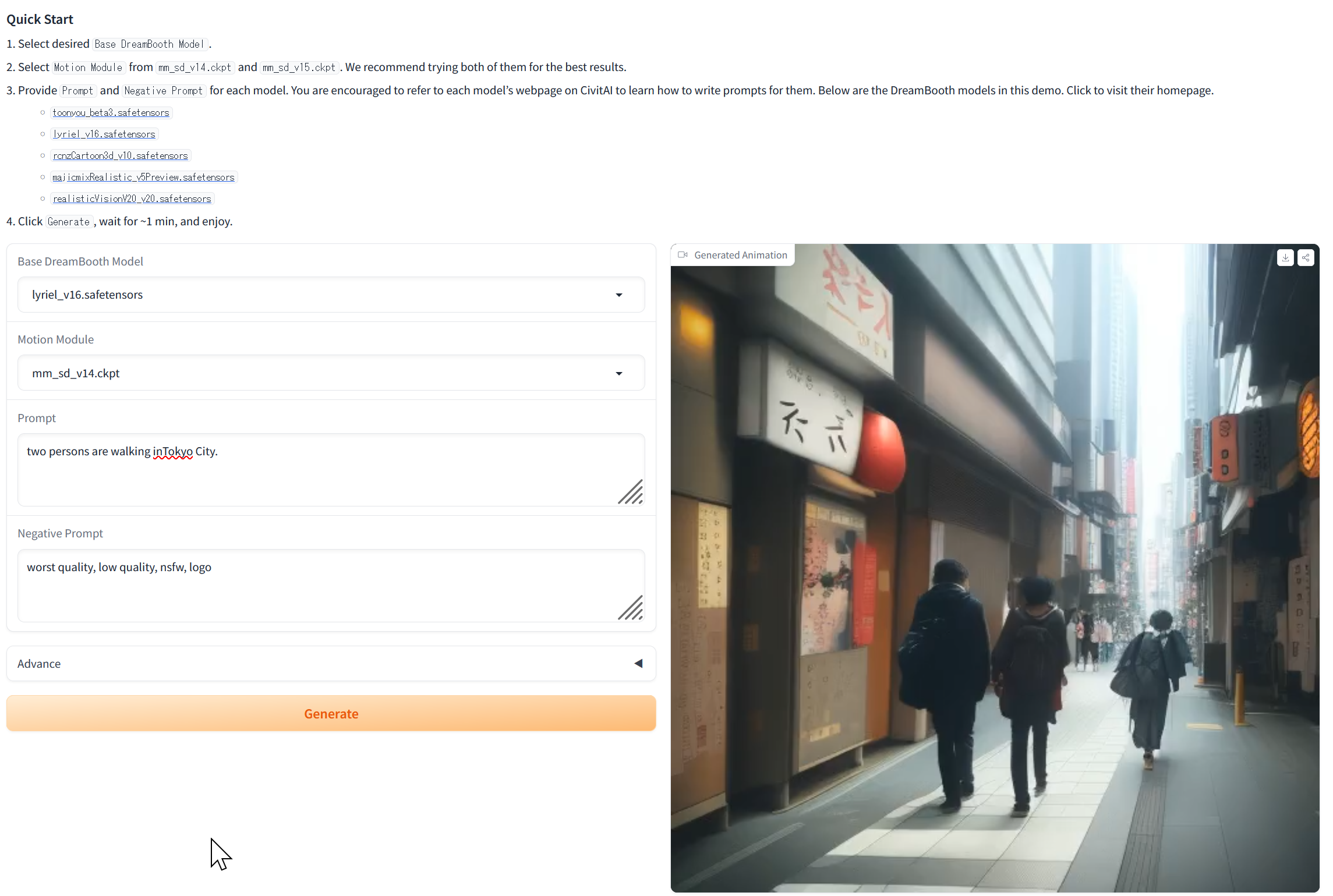
53. 11/1 10:50- - 発声動画の生成
プロンプトからの動画生成
次のサイトは Stable Diffusion を使用して、プロンプトから2秒程度の動画を生成する。
https://huggingface.co/spaces/guoyww/AnimateDiff (AnimateDiff: テキストから動画を生成するAI)
https://openxlab.org.cn/apps/detail/Masbfca/AnimateDiff
54. 11/7 10:50- - ビジュアルな質問応答
55. 11/8 10:50- - テキスト生成モデルとチャットモデル
テキスト生成モデルとチャットモデルの基本概念とChatGPT(対話型AIモデル)の特徴を紹介する。テキスト生成モデルは任意の入力から新たなテキストを生成し、チャットモデルは人間との対話を目的としてリアルタイムの応答を生成する。ChatGPTはチャットモデルの一種であり、テキスト生成モデルの能力も持ち、対話から学習し応答を改善する能力を持つ。また、OpenAI API(OpenAIのAIモデル利用インターフェース)キーを取得することで、OpenAIのモデルにアクセスできる。ChatGPTとLangChain(言語モデルアプリ開発フレームワーク)を利用したいくつかのプログラムの実行手順も説明している。まず、ライブラリのインストールや環境設定ファイルの作成を行う。プログラムは、LangChainの公式サイトのものを一部変更して使用している。メモリを用いたチャットモデルや検索拡張生成(RAG)(外部情報検索と連携する文章生成)を利用する方法も説明している。
説明資料: 2023-11-08.pdf, 2023-11-08.pptx
56. 11/16 10:50- - 顔情報処理
オンラインデモ。実行のためにカメラ付きのパソコンを準備すること。
https://visagetechnologies.com/demo/
ミヨシ電子株式会社からのメッセージがあった。情報工学の人材を求めているとのことである。https://www.miyoshi.elec.co.jp/information/business/business_top.html
卒業研究についての情報工学科からの案内を、各自、再度読んでおくこと。
https://cerezo.fukuyama-u.ac.jp/ct/course_342000_news_1430607
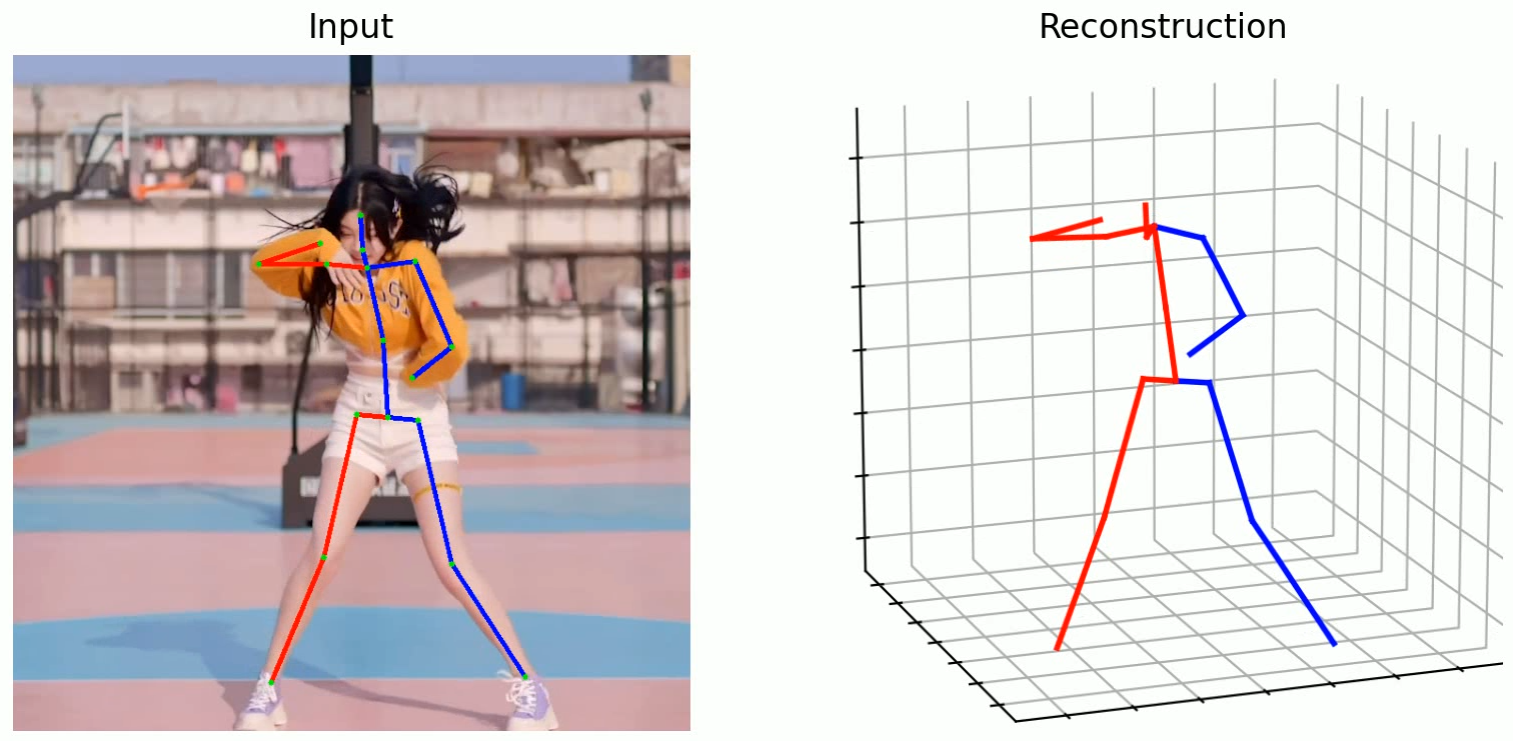
57. 11/21 10:50- - 人体の姿勢推定
動画: 動画
【資料】
【サイト内の関連ページ】
人体の3次元位置推定(MHFormer(人体の3次元姿勢推定AIモデル)、Python、PyTorch を使用)(Windows 上): 別ページ »で説明
58. 11/22 10:50- - 対話AI
【資料】 [PDF]
【関連する外部ページ】
WebLangChain(ウェブ情報利用の言語モデル連携): https://weblangchain.vercel.app/
59. 11/28 10:50- - Concept Sliders
【概要】
「Concept Sliders」(拡散モデルの精密制御技術)は、拡散モデルを用いた画像生成において、テキストプロンプトの変更だけでは難しい属性の精密な制御を可能にする新技術である。従来の方法では、画像の全体的な構造が大きく変わることが問題であったが、Concept Slidersは特定の概念に対応するパラメータ方向を学習し、画像の特定の属性を増減させることで、視覚的な内容の変更、現実感の向上、手の歪みの修正などの応用が可能になる。この技術により、画像生成の制御が容易になり、複数のSlidersを組み合わせることで、複雑な制御が実現できる。
【文献】
Rohit Gandikota, Joanna Materzynska, Tingrui Zhou, Antonio Torralba, David Bau, Concept Sliders: LoRA(大規模モデルの低負荷チューニング)Adaptors for Precise Control in Diffusion Models, arXiv:2311.12092v1, 2023.
【関連する外部ページ】
- 公式ページ: https://sliders.baulab.info/
- 学習済みモデル: https://sliders.baulab.info/weights/xl_sliders/
- GitHub のページ: https://github.com/rohitgandikota/sliders
- デモ: https://colab.research.google.com/github/rohitgandikota/sliders/blob/main/demo_concept_sliders.ipynb



60. 11/29 10:50- - 動作認識
MMAction2(動作認識のためのAIツールキット)は動作検出、動作認識の機能を持つ。
【サイト内の関連ページ】
次のページでは、Kinetics-400(動作認識用大規模データセット)で学習済みのモデルを用いた動作認識のプログラムを示している。
動作認識を行う Python プログラム(MMAction、Python、PyTorch を使用)(Windows 上): 別ページ »で説明
実行結果の例
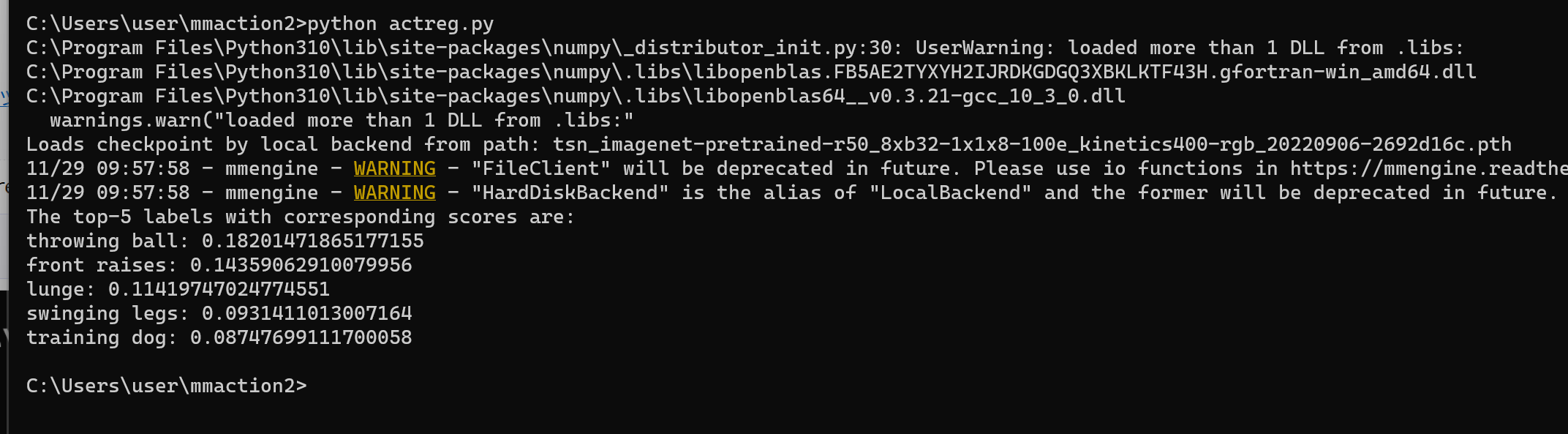
上の実行結果を得た動画ファイル
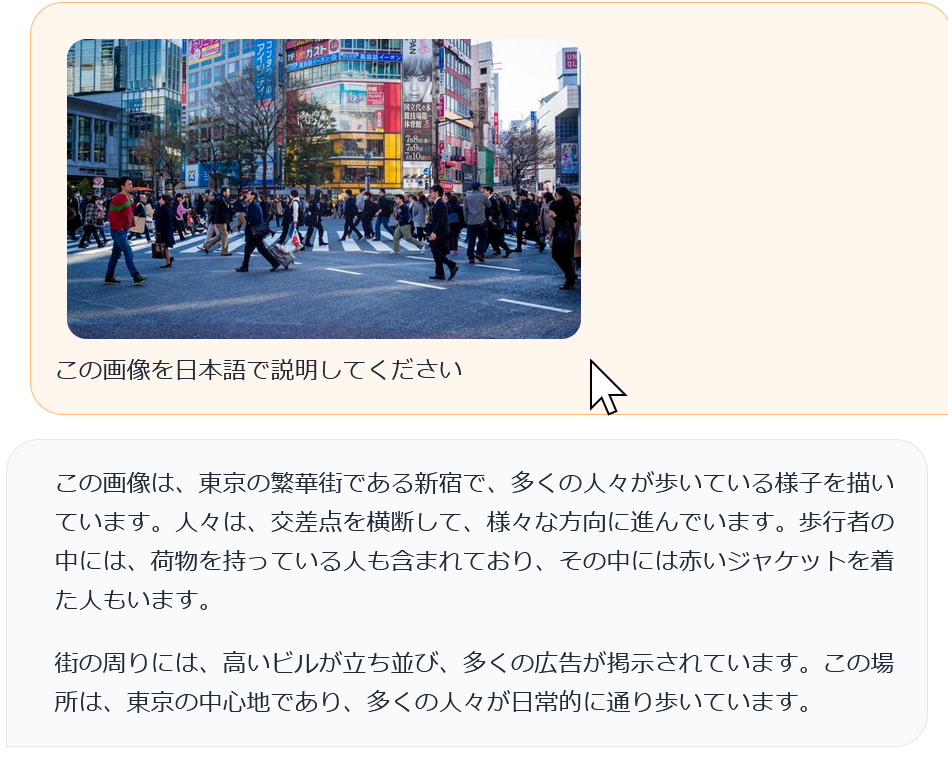
61. 12/5 10:50- - LLaVA
- LLaVA(多モーダル大規模言語モデル)の公式デモ(llava-v1.5-13b): https://llava.hliu.cc/
- Hugging Face の LLaVA の公式デモ(llava-v1.5-13b-4bit): https://huggingface.co/spaces/badayvedat/LLaVA
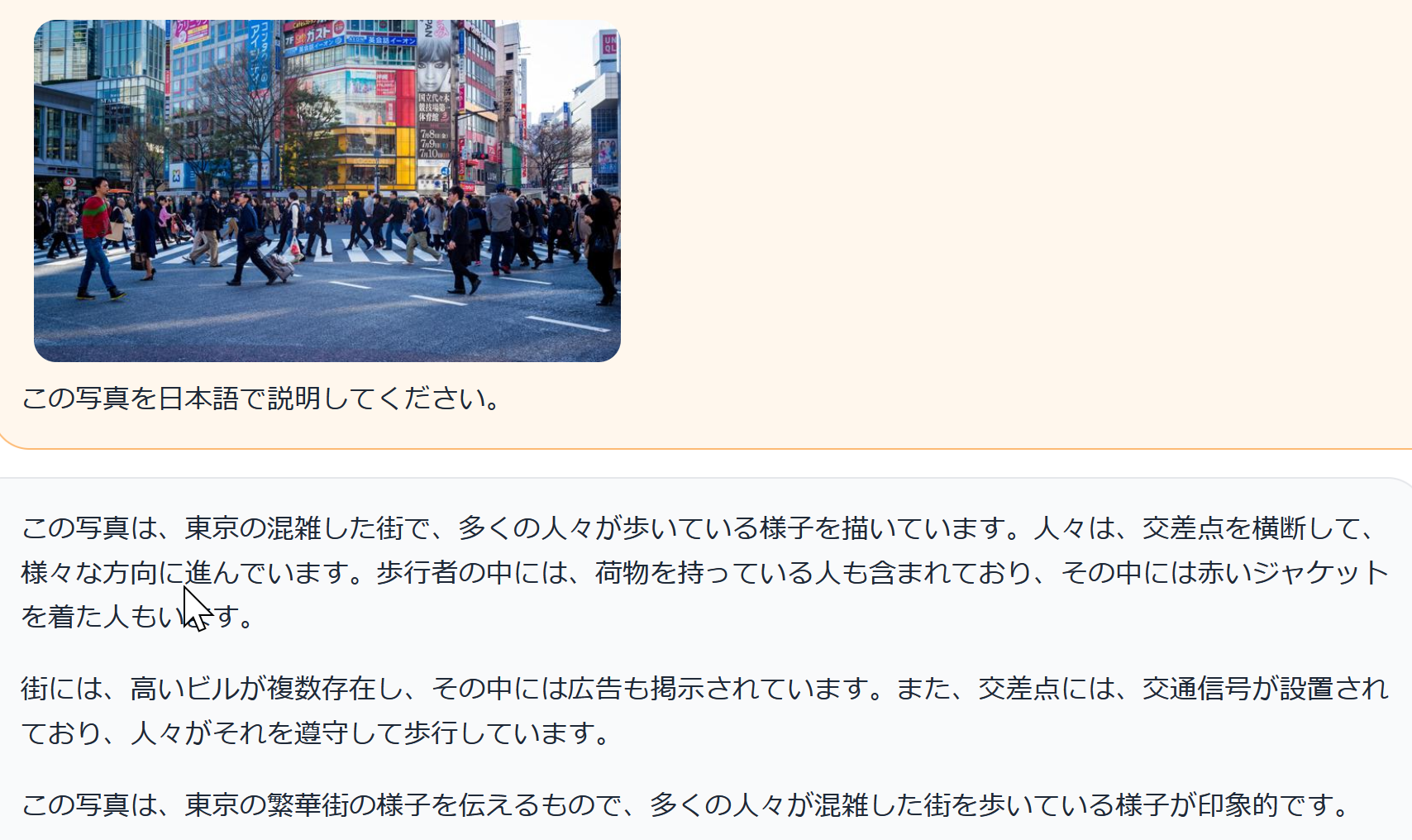
LLaVAは、多モーダルな大規模言語モデル(Large Language Model)に特化しており、視覚と言語の両方のデータを効率的に処理できるように設計されている。このフレームワークは、既存の多モーダルモデルをさらに強化するための改良が施されている。LLaVAは二つの主要な特長を持つ。一つ目は、多層パーセプトロン(multilayer perceptron; MLP)(基本的なニューラル網構造)を使用した視覚-言語クロスモーダルコネクタである。これにより、視覚と言語のデータが効率的に統合される。二つ目は、視覚的質問応答(Visual Question Answering; VQA)(画像内容に関する質問に答えるAI)データの追加である。これにより、モデルは視覚的な情報に基づいて質問に答える能力が向上する。
論文
Liu, Haotian and Li, Chunyuan and Li, Yuheng and Lee, Yong Jae, Improved Baselines with Visual Instruction Tuning, arXiv:2310.03744, 2023.
Liu, Haotian and Li, Chunyuan and Wu, Qingyang and Lee, Yong Jae, Visual Instruction Tuning, arXiv:2304.08485, 2023.
62. 12/6 10:50- - モノクロ画像からの深度推定 (Depth Estimation)
AdelaiDepth(単眼画像からの深度推定手法)




【概要】
単一の画像からの深度推定(単眼深度推定)と、3次元シーンの再構成に関する一手法である。従来の単眼深度推定では、未知の深度シフト (depth shift) と、未知のカメラ焦点距離により、正確な結果が得られないとしている。本手法では、この問題の解決のために、単眼深度推定ののち、3次元点群エンコーダを使用して深度シフトとカメラ焦点距離を推定する二段階フレームワークを提案している。仕組みとしては、深度予測モジュールと点群再構築モジュールから構成されている。深度予測モジュールは畳み込みニューラルネットワークを利用して、単眼深度推定を行う。点群再構築モジュールは、ポイントクラウドエンコーダネットワークを活用して、深度シフトとカメラ焦点距離の調整係数を推定する。実験結果からは、ポイントクラウド再構築モジュールが単一の画像から正確な3D形状を回復できること、および深度予測モジュールが良好な推定結果を得ることが確認された。
デモページで画像をアップロードして試すことができる。
AdelaiDepth の Google Colaboratory のデモページ(AdelaiDepth ResNet101): https://colab.research.google.com/drive/1rDLZBtiUgsFJrrL-xOgTVWxj6PMK9swq?usp=sharing
AdelaiDepth の GitHub のページ: https://github.com/aim-uofa/AdelaiDepth
63. 12/12 10:50- - 高解像度の画像生成AI
DemoFusion(高解像度画像生成フレームワーク)
DemoFusion: Democratising High-Resolution Image Generation With No $$$, Ruoyi Du, Dongliang Chang, Timothy Hospedales, Yi-Zhe Song, Zhanyu Ma, arXiv:2311.16973v1, 2023.
https://arxiv.org/pdf/2311.16973v1.pdf
DemoFusionは、潜在拡散モデル(LDM)(高品質な画像生成AI手法)を活用し、高解像度画像の生成を目指す新しいフレームワークである。この論文では、プログレッシブアップスケーリング(段階的に解像度を上げる手法)、スキップ残差、拡張サンプリングを用いて、高解像度画像を生成するDemoFusionを提案している。実験結果からは、追加の学習を必要とせずに、高解像度画像生成の品質を向上させることが可能であることが示されている。DemoFusion を用いることにより、ユーザーは初期段階で低解像度の画像をプレビューし、レイアウトやスタイルに満足した後、高解像度へと進むことができる。
次のデモのページでは、画像と、画像を正しく具体的に説明する「プロンプト」を与えることにより、高解像度化を行う。
https://huggingface.co/spaces/radames/Enhance-This-DemoFusion-SDXL
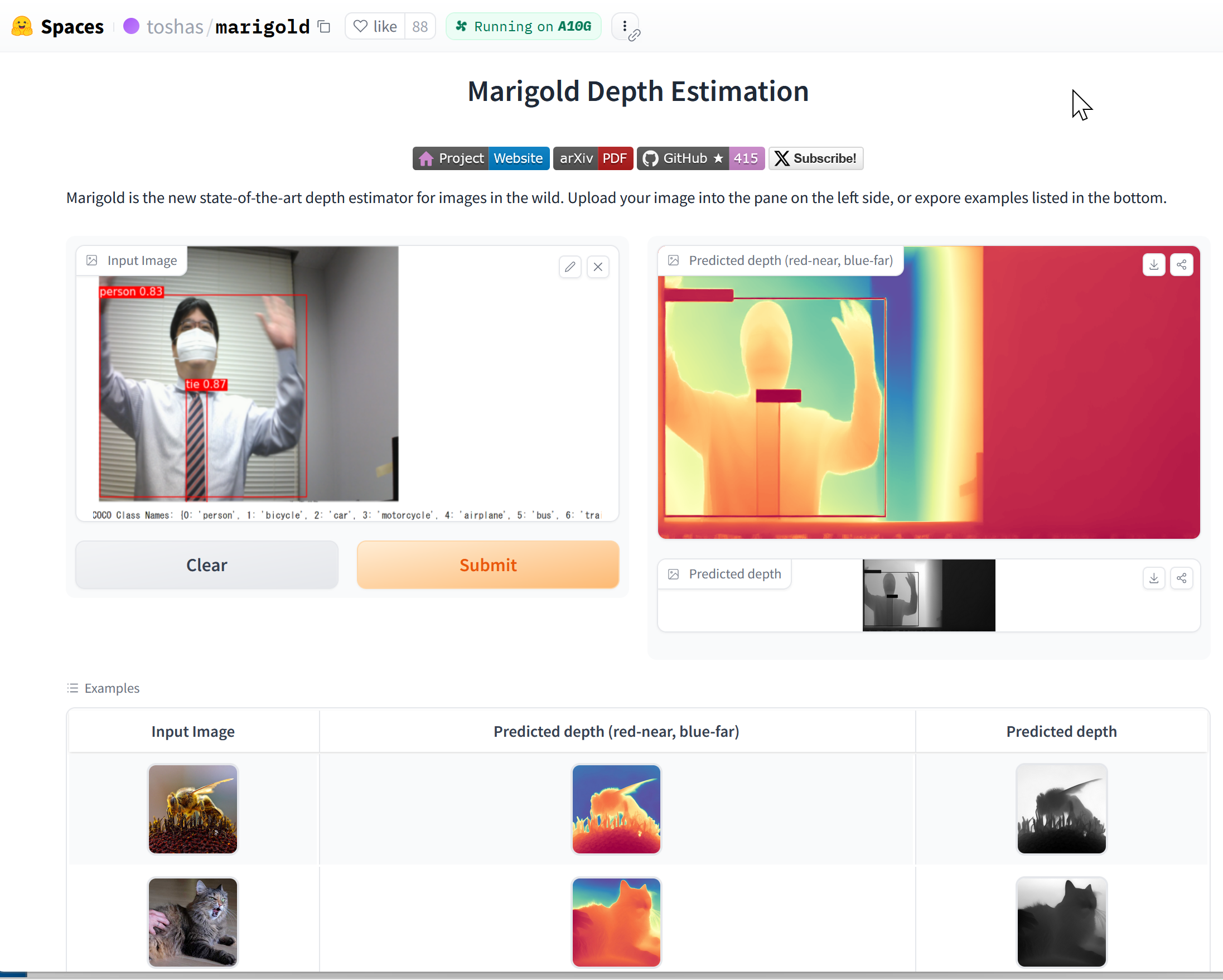
64. 12/13 10:50- - 深度推定
Marigold Depth Estimation(単眼画像からの奥行き推定AI)
65. 12/13 10:50- - Alpha-CLIP
Alpha-CLIP(特定領域に注目するCLIP改良版)
Zeyi Sun, Ye Fang, Tong Wu, Pan Zhang, Yuhang Zang, Shu Kong, Yuanjun Xiong, Dahua Lin, Jiaqi Wang, Alpha-CLIP: A CLIP Model Focusing on Wherever You Want, arXiv:2312.03818v1, 2023.
CLIP(画像とテキストを関連付けるAI)は、画像とテキストからセマンティックな特徴を抽出するモデルである。これは、テキストと画像の内容を関連付けることで、画像内のオブジェクトやシーンを理解するのに役立つ。Alpha-CLIPは、CLIPの改良版で、特に画像の特定の関心領域(Interest Region)に焦点を当てることができる。これにより、画像全体ではなく、特定の部分の詳細な理解や、その部分に対する精密な制御が可能になる。Alpha-CLIPは、追加のアルファチャンネルを通じて関心領域を指定し、これらの領域に関連するテキストとペアになった大量のデータで微調整される。これにより、モデルは特定の領域に焦点を合わせながらも、画像全体のコンテキストを維持することができる。実験では、Alpha-CLIPは画像認識、マルチモーダル大規模言語モデル、2D生成、3Dコンピュータグラフィックス(3DCG:3次元空間の画像を生成する技術)生成などのタスクで、従来のCLIPモデルを上回る性能を示した。Alpha-CLIPをDiffusionモデルと組み合わせることで、画像の変化タスクにおいて、制御可能なコンテンツ生成が可能になる。これは、従来のCLIPモデルでは困難だった、複雑な画像からの主題抽出や、特定の領域に焦点を当てた画像生成を可能にする。
https://arxiv.org/pdf/2312.03818v1.pdf
HuggingFace のデモページ: https://huggingface.co/spaces/Zery/Alpha_CLIP_ImgVar
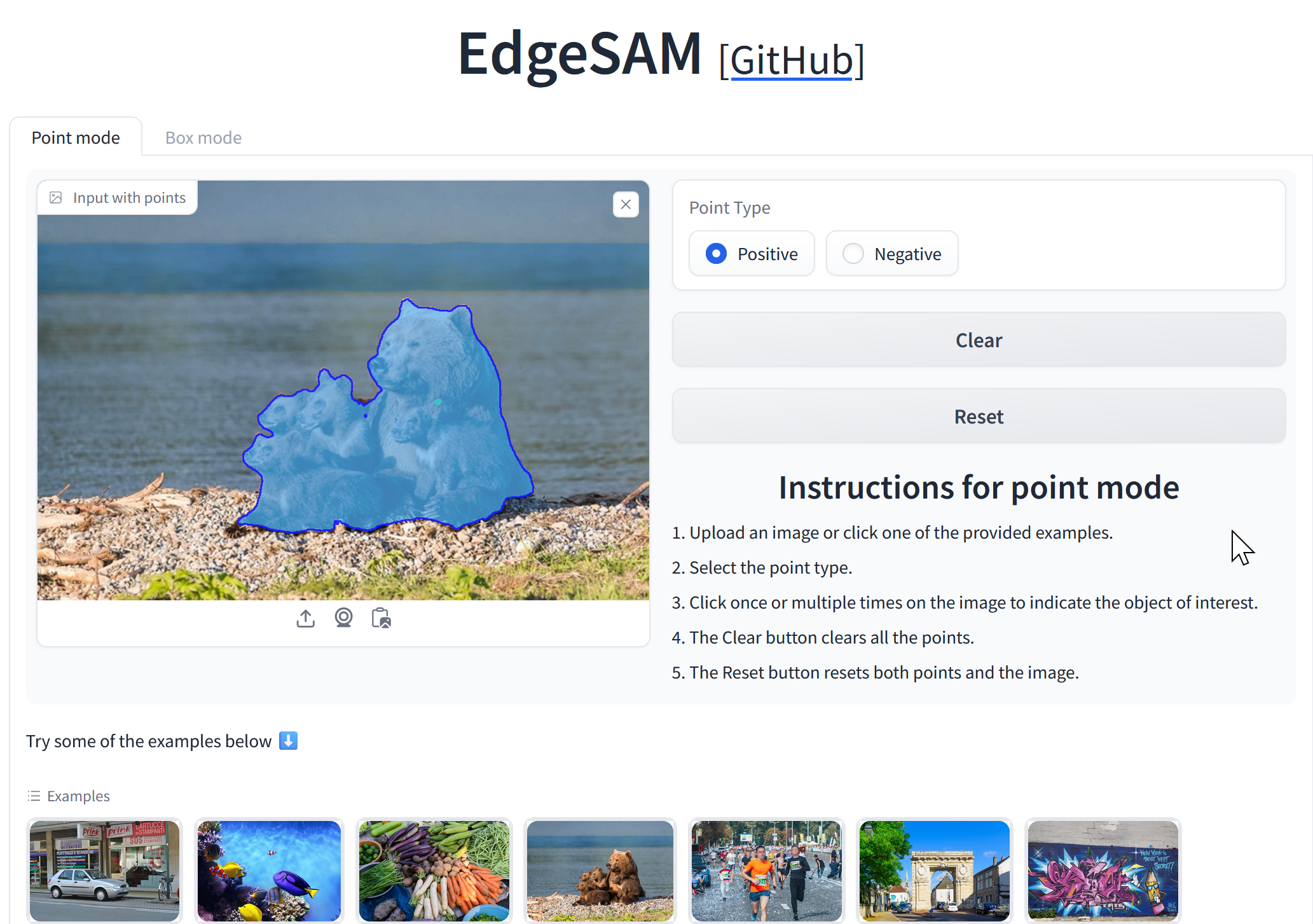
66. 12/20 10:50- - Segment Anything
EdgeSAM
【文献】
Segment Anything Model(SAM)(汎用画像セグメンテーションモデル)は、スマートフォンなどのエッジデバイスで効率的に動作することを目的としている。SAMにおける画像エンコーダはVision Transformer(ViT)(画像認識用Transformer)を基にしていたが、エッジデバイスに適した畳み込みニューラルネットワーク(CNN)(画像処理に強いニューラル網)ベースのものに変更された。この変更においても、SAMのエンコーダ・デコーダアーキテクチャは保持されている。さらに、プロンプトエンコーダとマスクデコーダの両方を蒸留(distillation)(機械学習で知識を小型モデルに継承)プロセスに含めることで、プロンプトとマスク生成の間の複雑な相互作用を効果的に扱う工夫が行われている。実験では、EdgeSAMはSAMよりも高速であり、元のSAMと匹敵する精度を実現していることを示している。
文献
Chong Zhou, Xiangtai Li, Chen Change Loy, Bo Dai, EdgeSAM: Prompt-In-the-Loop Distillation for On-Device Deployment of SAM, arXiv:2312.06660v1, 2023.
https://arxiv.org/pdf/2312.06660v1.pdf
【関連する外部ページ】
- 公式のデモ: https://huggingface.co/spaces/chongzhou/EdgeSAM
- Paper with Code: https://paperswithcode.com/paper/edgesam-prompt-in-the-loop-distillation-for